Achieve high-quality data labeling 10x faster
Annotate and review images, videos, audio, text and DICOM files faster using custom workflows, AI-assisted automation, and human-in-the-loop evaluation in the Encord platform.
“Setting up our labeling process with our previous solution took nearly two months and required extensive support. With Encord, we were operational in just two weeks, and then we went on vacation and got back, and the data was good.”

Rammohan Adabala
Principal Product Manager
Orchestrate automated labelling and human-in-the-loop workflows
Everything you need to label, build, and align, all in one place.
 Text
Text Audio
Audio Video
Video Image
Image Document
Document LiDAR
LiDAR DICOM
DICOM Geospatial
Geospatial HTML
HTML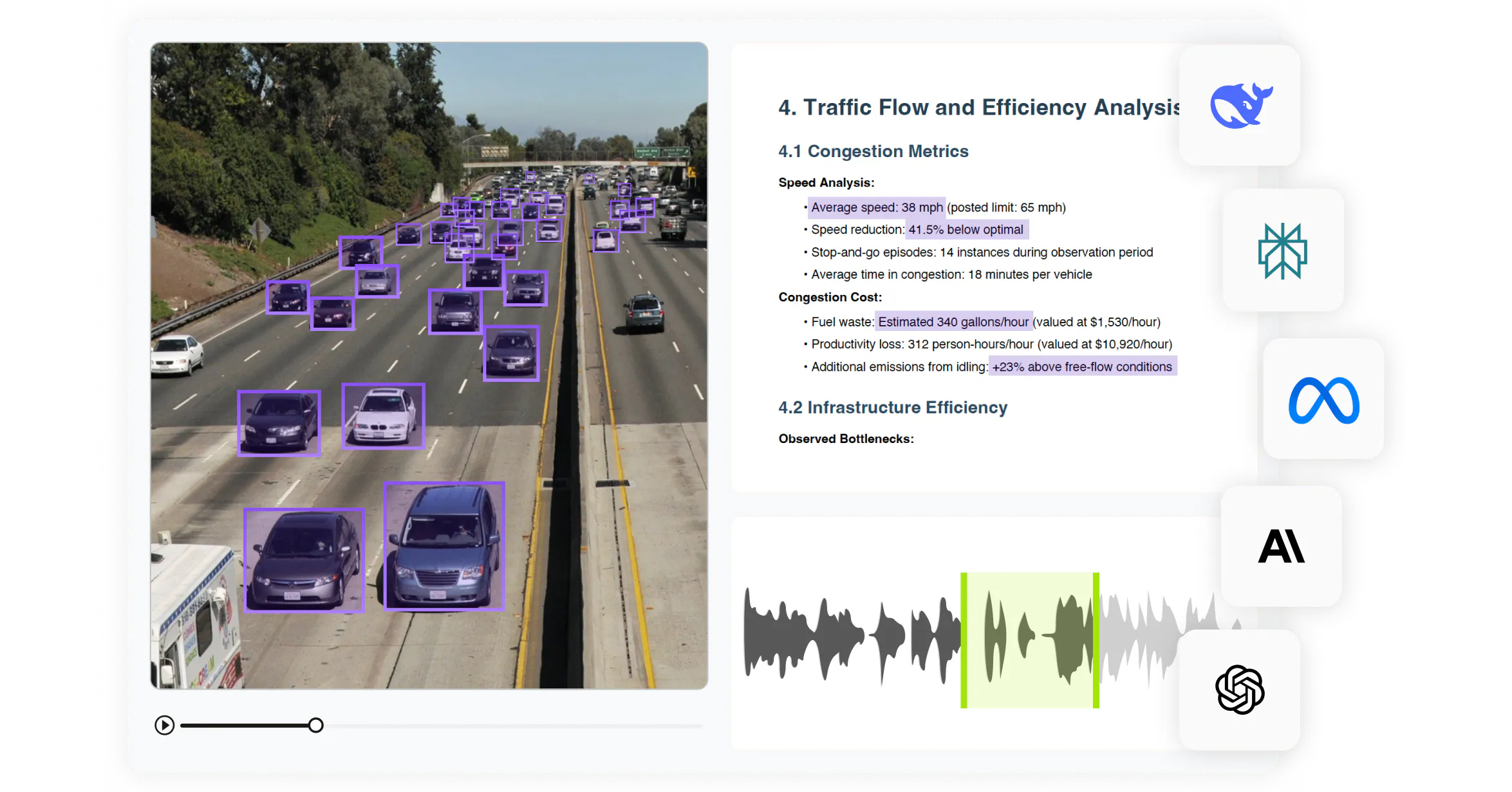
Generate multimodal
labels, fast
Manage and automate labelling, track lineage, and scale annotation operations with full visibility.
Generate multimodal
labels, fast
Manage and automate labelling, track lineage, and scale annotation operations with full visibility.
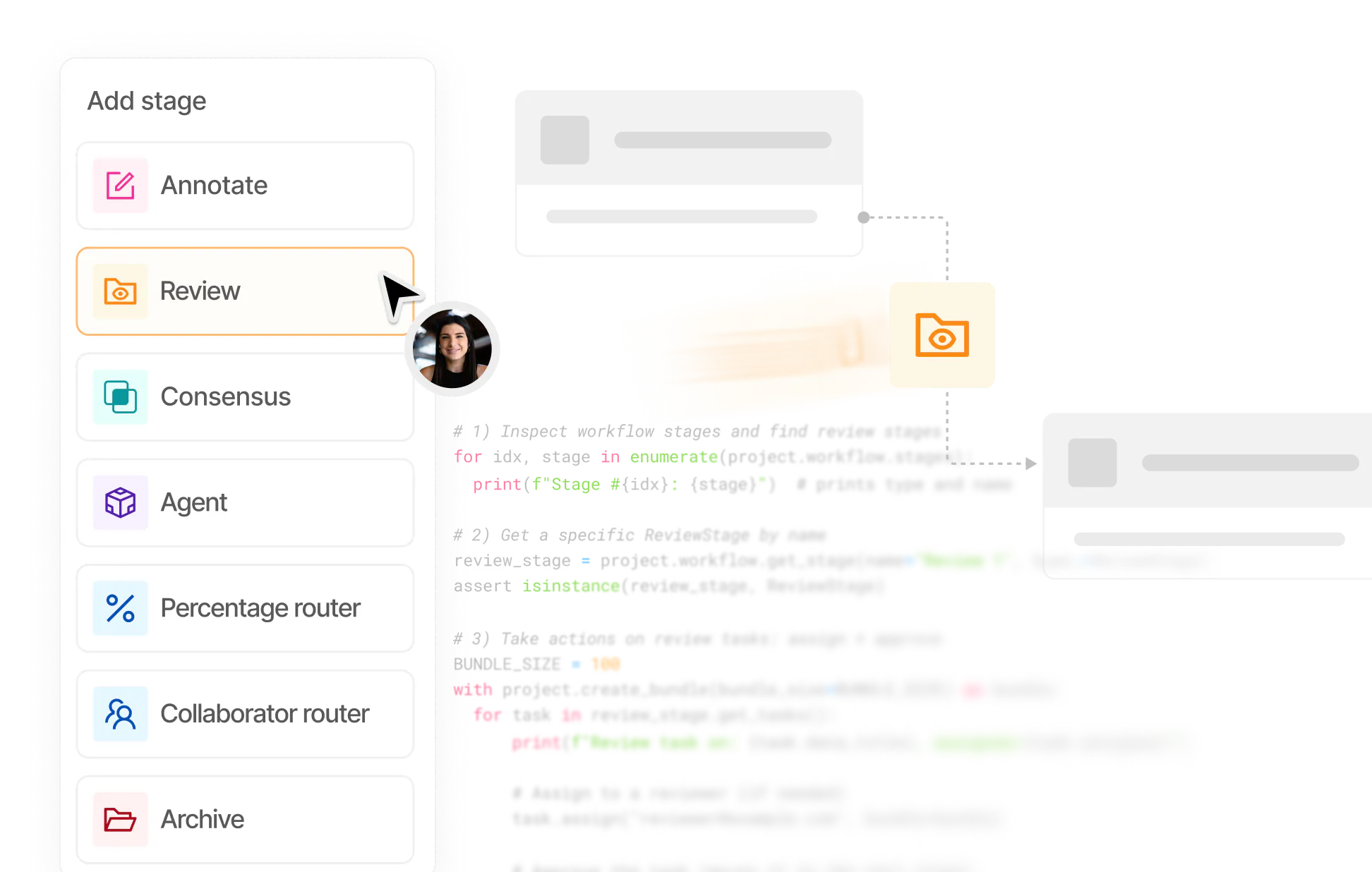
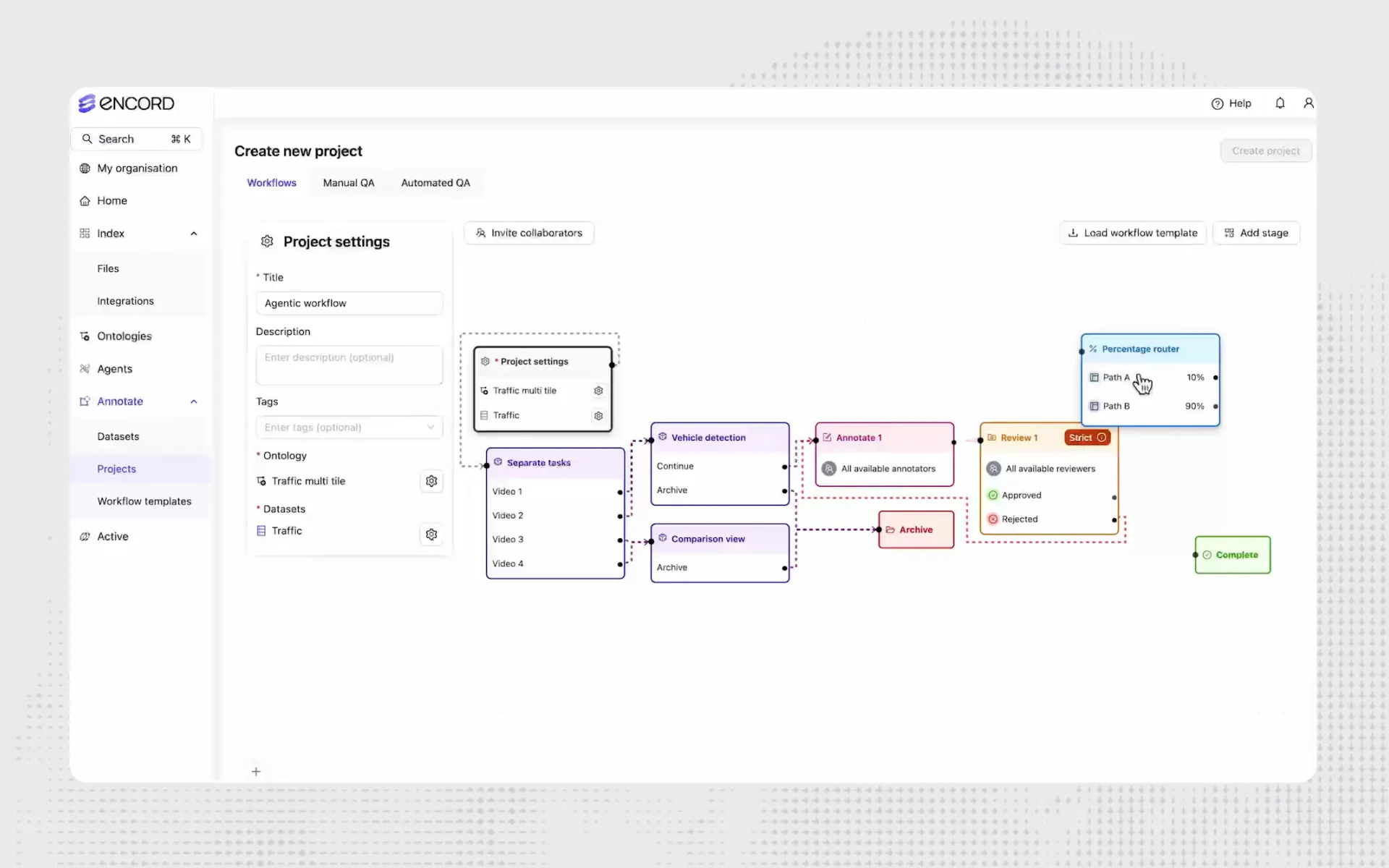
Set up flexible workflows and streamline annotation
Ensure quality control with customizable data workflows and multi-stage reviews. Assign roles, labeling tasks, and manage project completion.
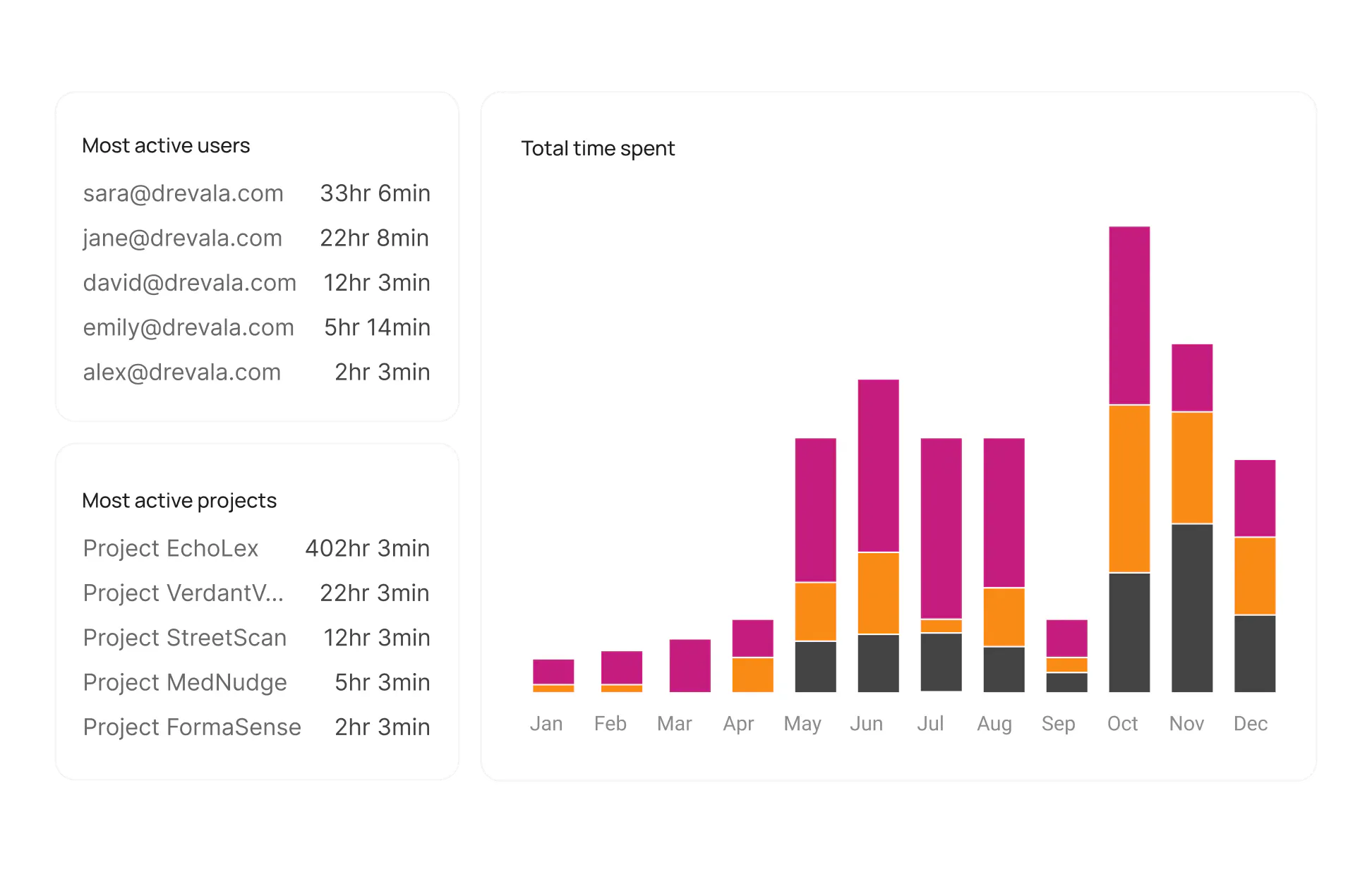
Monitor and analyze real-time performance analytics
Real-time dashboard for tracking both project progress and the performance of team members/labelers

Customize ontologies for every use case
Create multiple nested classifications with advanced labeling ontologies to establish accurate ground truth datasets.
Customize ontologies for every use case
Create multiple nested classifications with advanced labeling ontologies to establish accurate ground truth datasets.
Accurately label computer vision, audio, text, and medical data
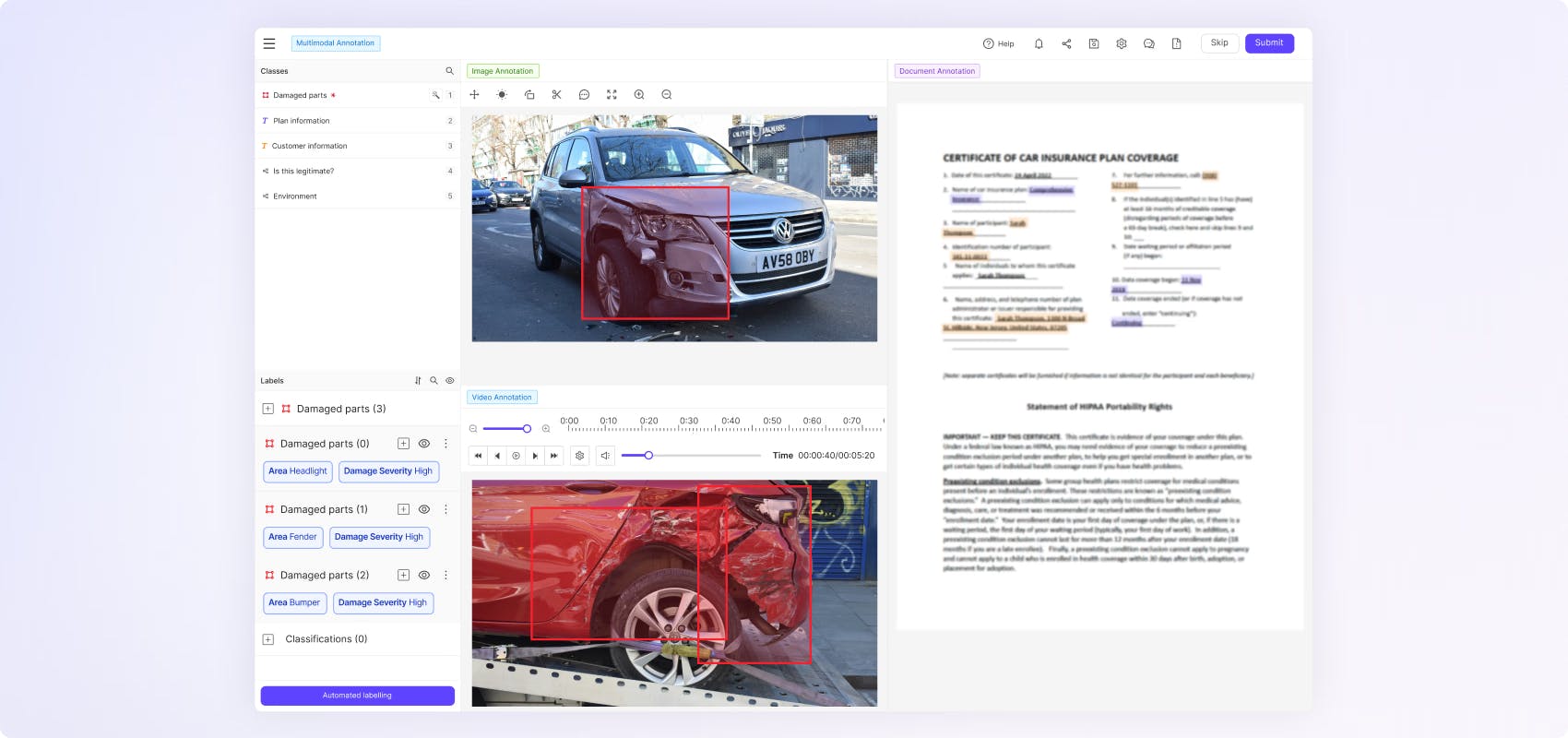
Customize annotation layouts to enable any multimodal data labeling workflow. Leverage multimodal context to achieve high-quality training data at scale.
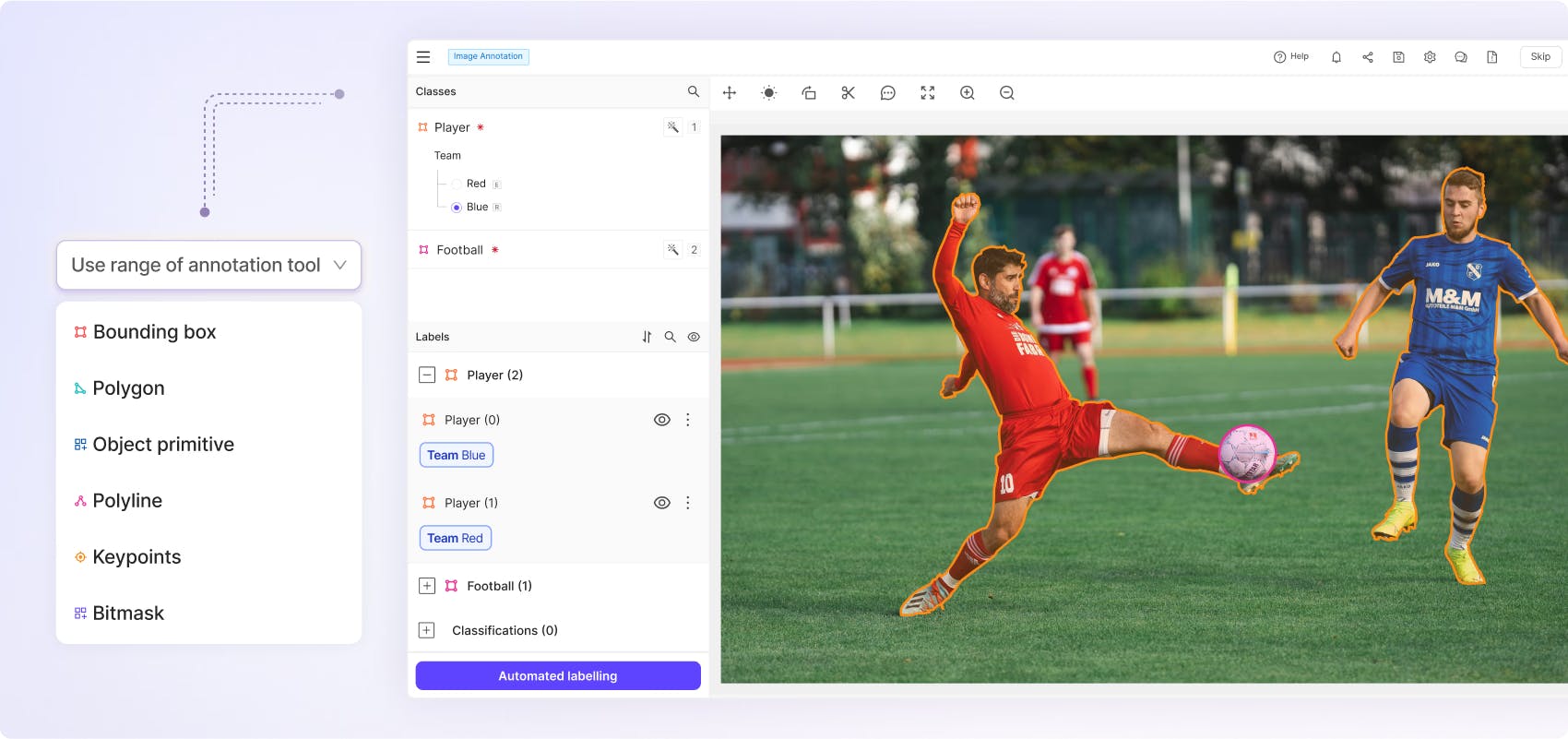
Label any image accurately using range of annotation tooling including bounding boxes, polylines, polygons, object primitives, keypoints and bitmasks. Use SAM 2 natively within Encord to accurately detect, segment and classify objects within images 10x faster.
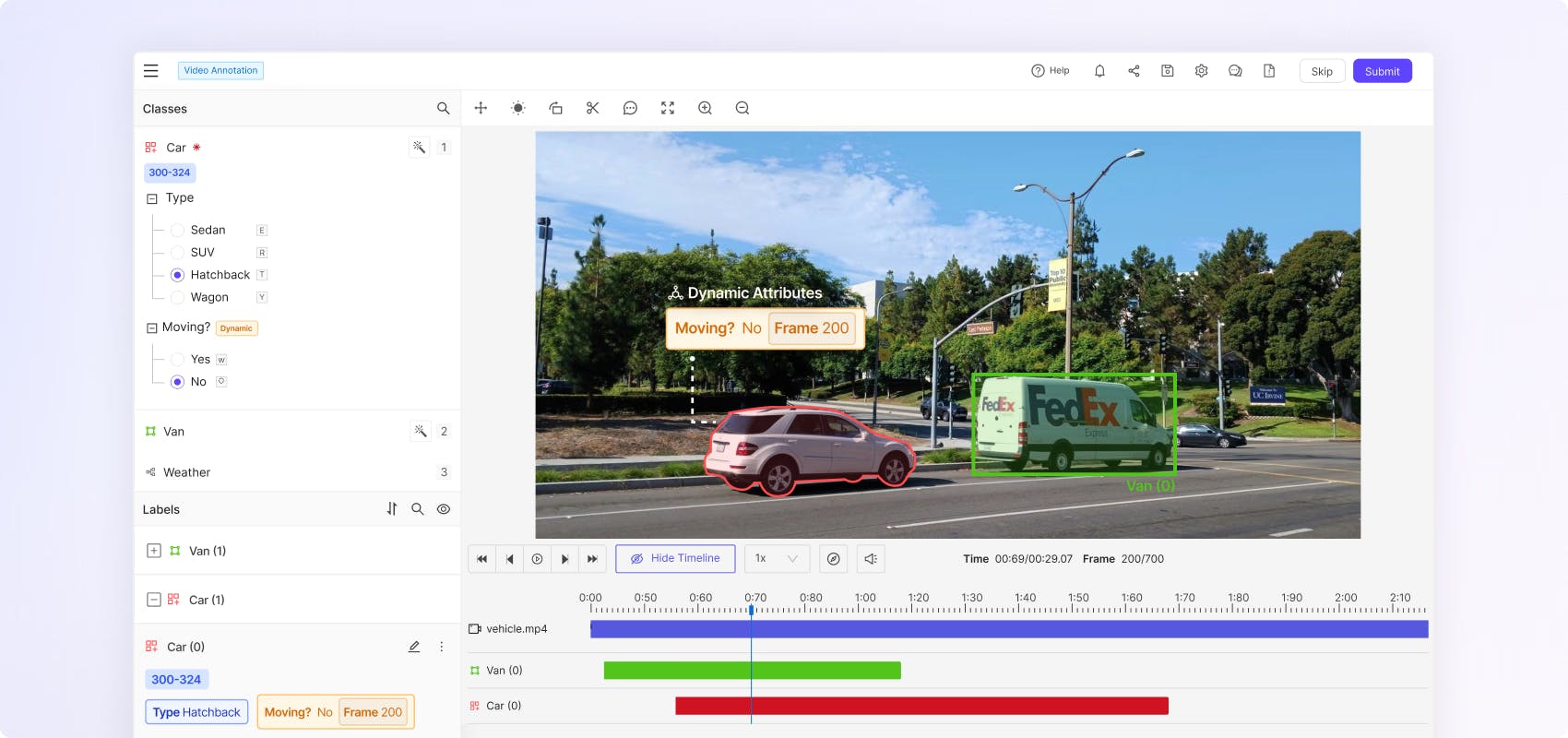
Preserve temporal context and avoid frame synchronization issues by eliminating frame splitting with a video-native annotation platform. Automatically segment and track objects using SAM 2.
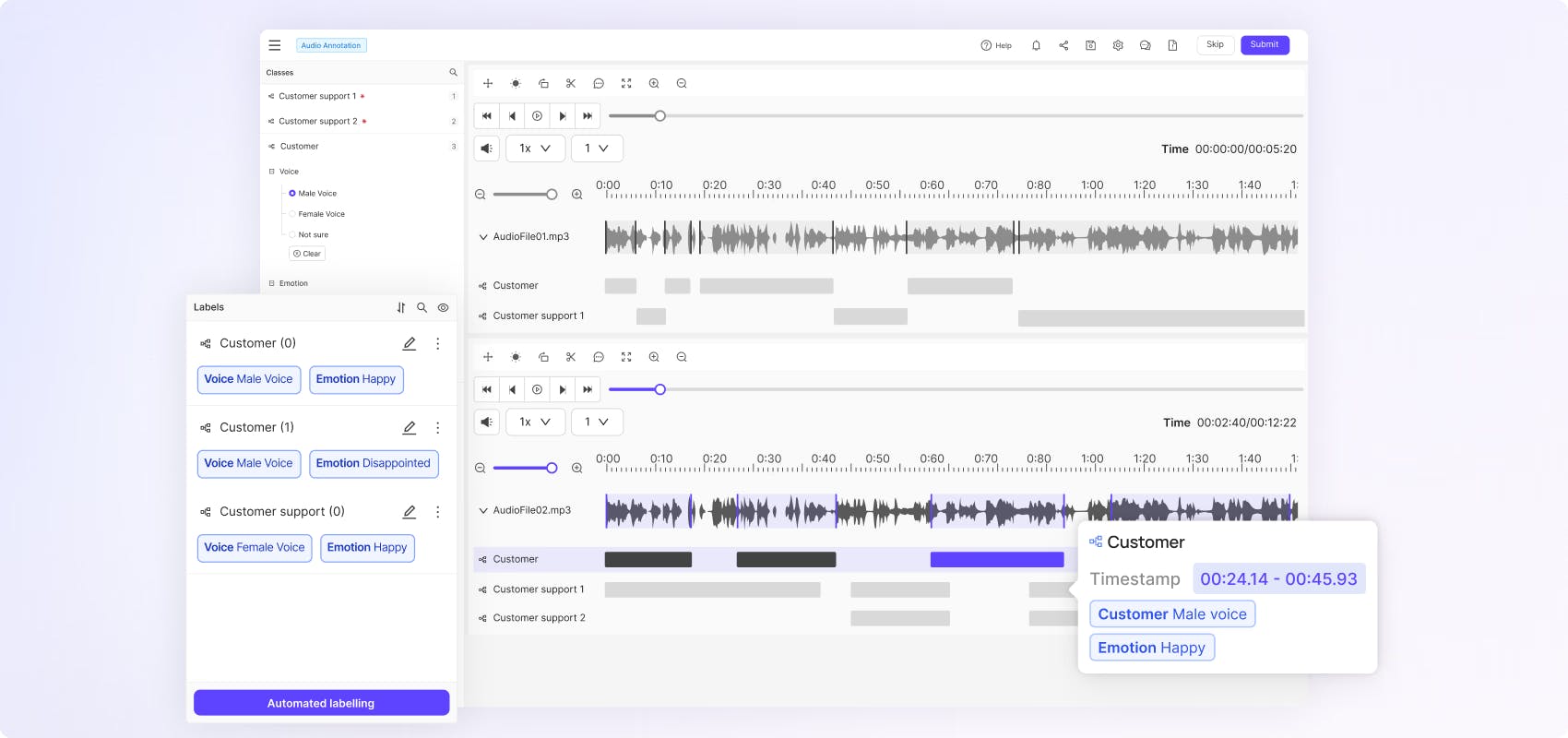
Use multi-channel annotation, nested ontologies and customizable attribute classes to label complex audio files with extreme precision down to the millisecond.

Streamline medical imaging AI workflows with 3D annotations for enhanced accuracy and multi-plane views for comprehensive annotation.
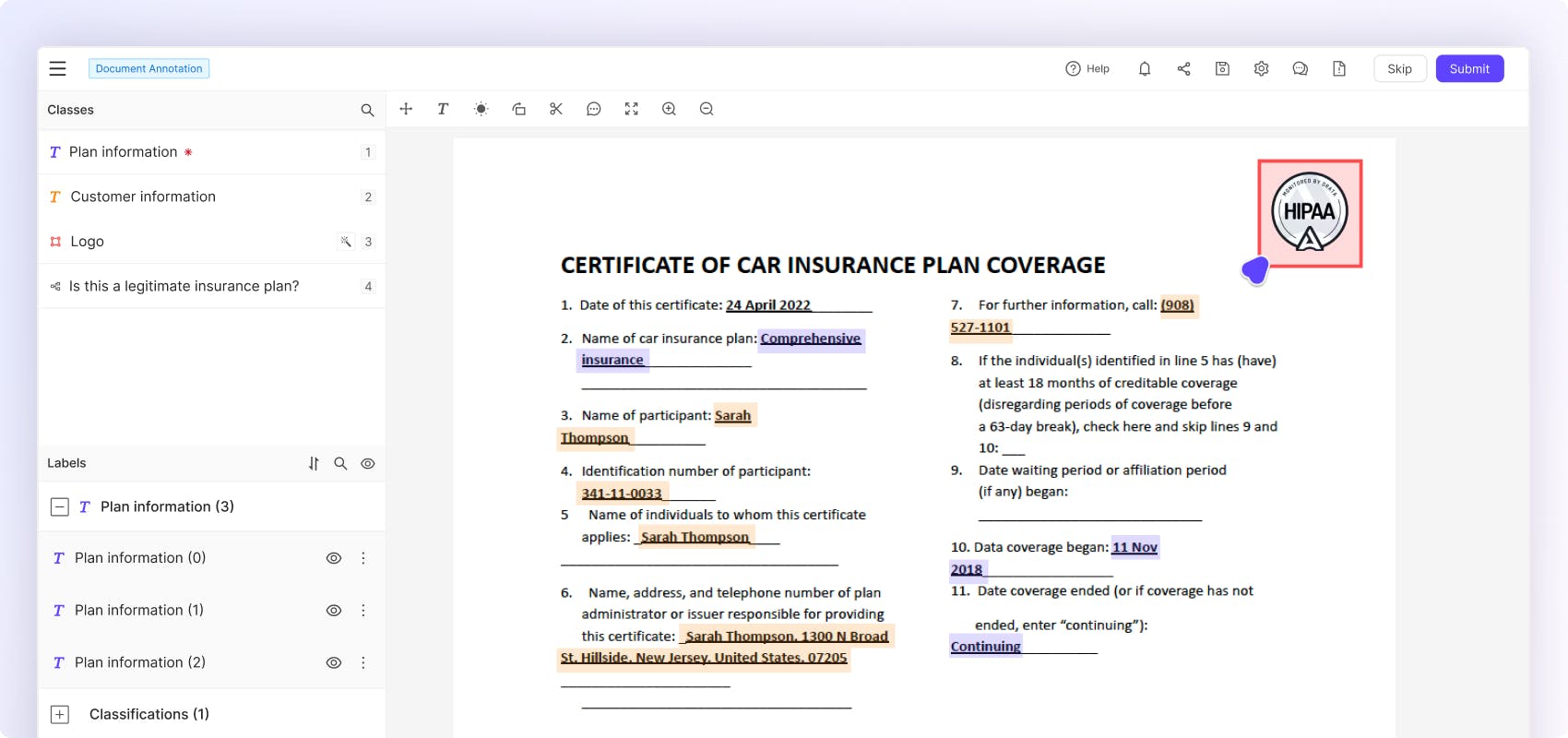
Flexibly label text data using intuitive text highlight tooling as well as bounding boxes for multimodal content within documents and text files.
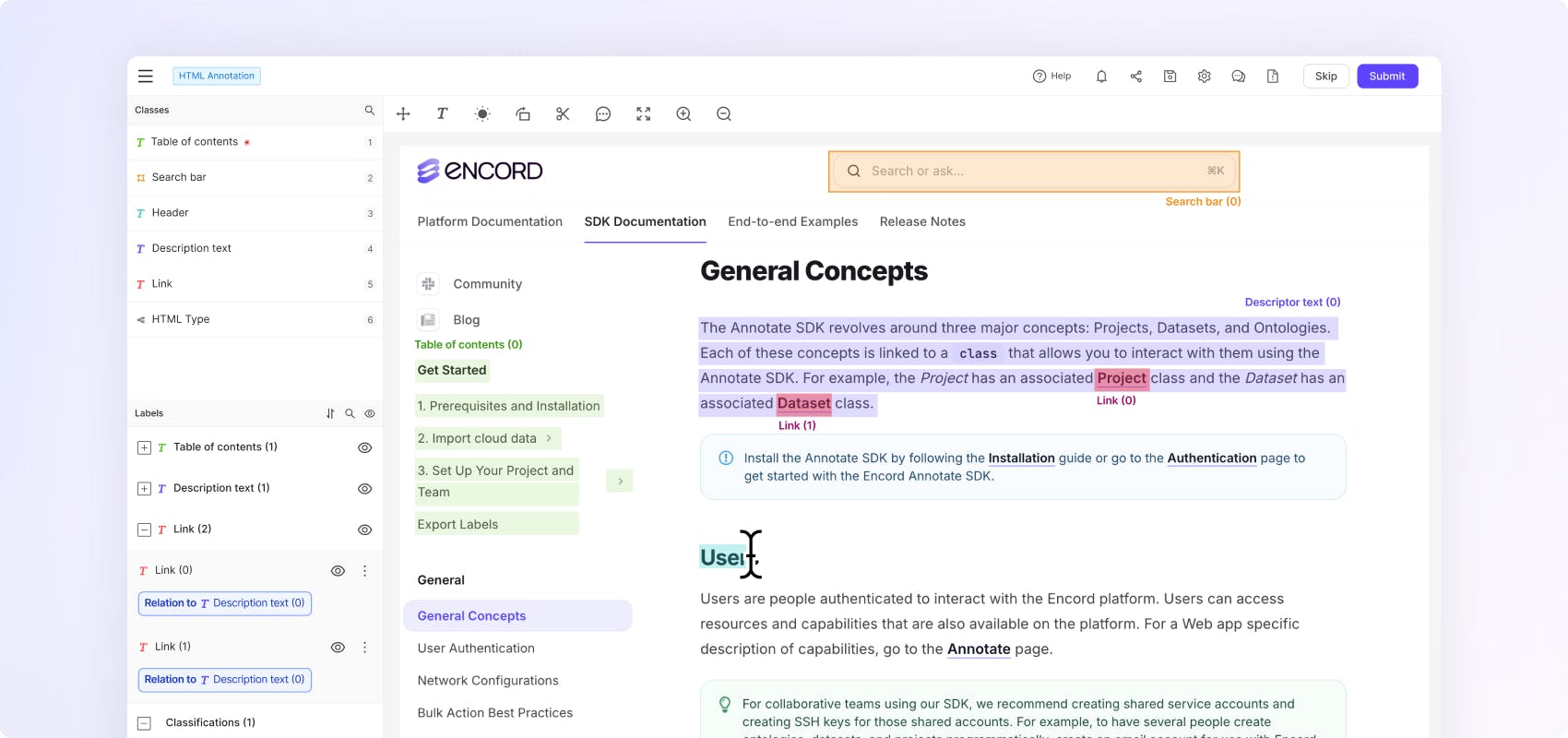
Use intuitive text highlighting and file classification to label HTML files with ease.
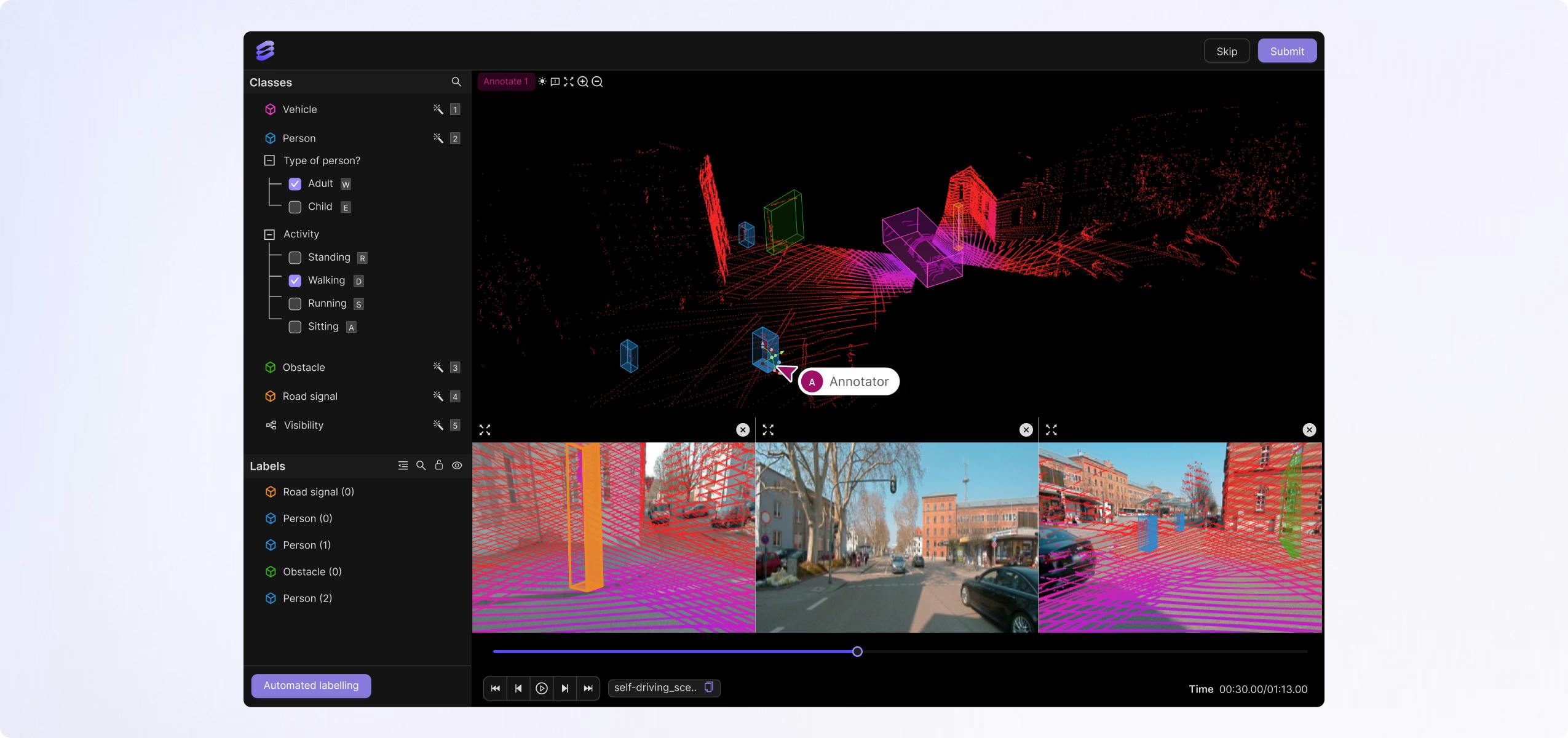
Master complex 3D scenes with all sensors unified on a timeline for ADAS, autonomous vehicles and drone use cases. From raw sensor data, point clouds from LiDAR, and multiple camera angles, you can manage, search, curate, label your data and test models with ease.
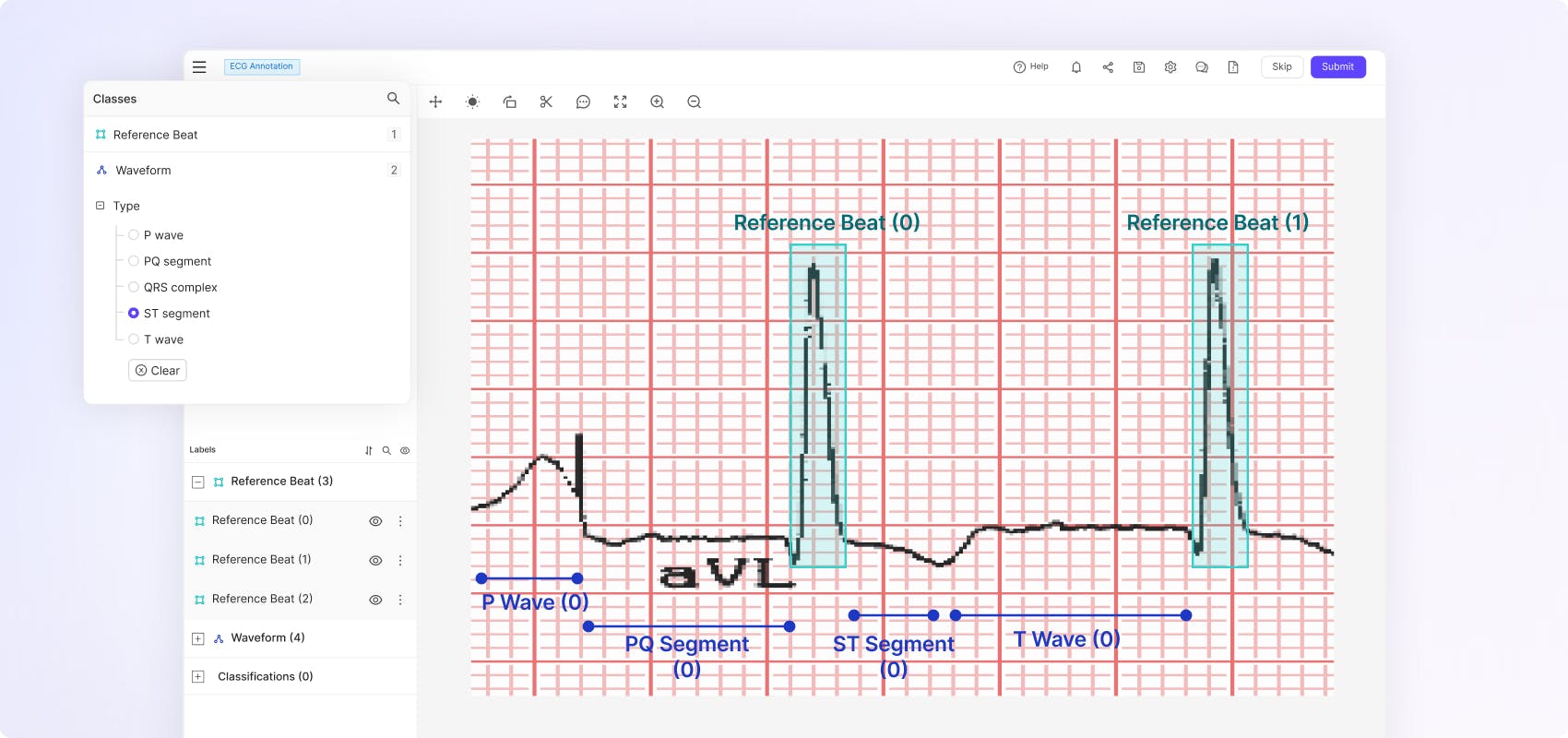
Accurately annotate rendered ECG with a PACS-style interface and use nested ontologies to capture detail.
Frequently asked questions
Multimodal data labeling is the process of annotating various data types—including images, videos, audio, text, and medical data—within a single workflow to improve AI model training.
Encord leverages AI-assisted Human-in-the-Loop workflows, automation tools, and customizable annotation layouts to accelerate data labeling by up to 3x while ensuring high accuracy.
Encord serves industries such as healthcare, autonomous vehicles, security, robotics, insurance, finance, and AI research by providing high-quality training data for production-grade AI models.
Encord supports annotation for images, videos, audio, text, DICOM (medical imaging), HTML documents, and more.
Yes, Encord integrates with AI models like GPT-4o, LLaMa 3.2, and Gemini 1.5 Flash, as well as custom machine learning models, to automate and accelerate data labeling pipelines.
Yes, Encord offers fully customizable workflows with role-based access, task assignments, and workflow automation for increased labeling efficiency.
Enterprise-grade.
Built for scale.
Designed for reliable AI.
Built for scale.
Designed for reliable AI.
API/SDK-first. Zero data migration. Your data stays in your cloud.
Visit trust center


Get the data right
300+ of the best AI teams in the world use Encord. Join them.