Label text faster with multimodal context
Accurately label documents and text files alongside multimodal data to train and fine-tune high-performing NLP Models and LLMs.
Achieve high quality document and text annotation with granular tooling
Classify and annotate whole files as well as specific text and content within files with functionality to suit any use case.
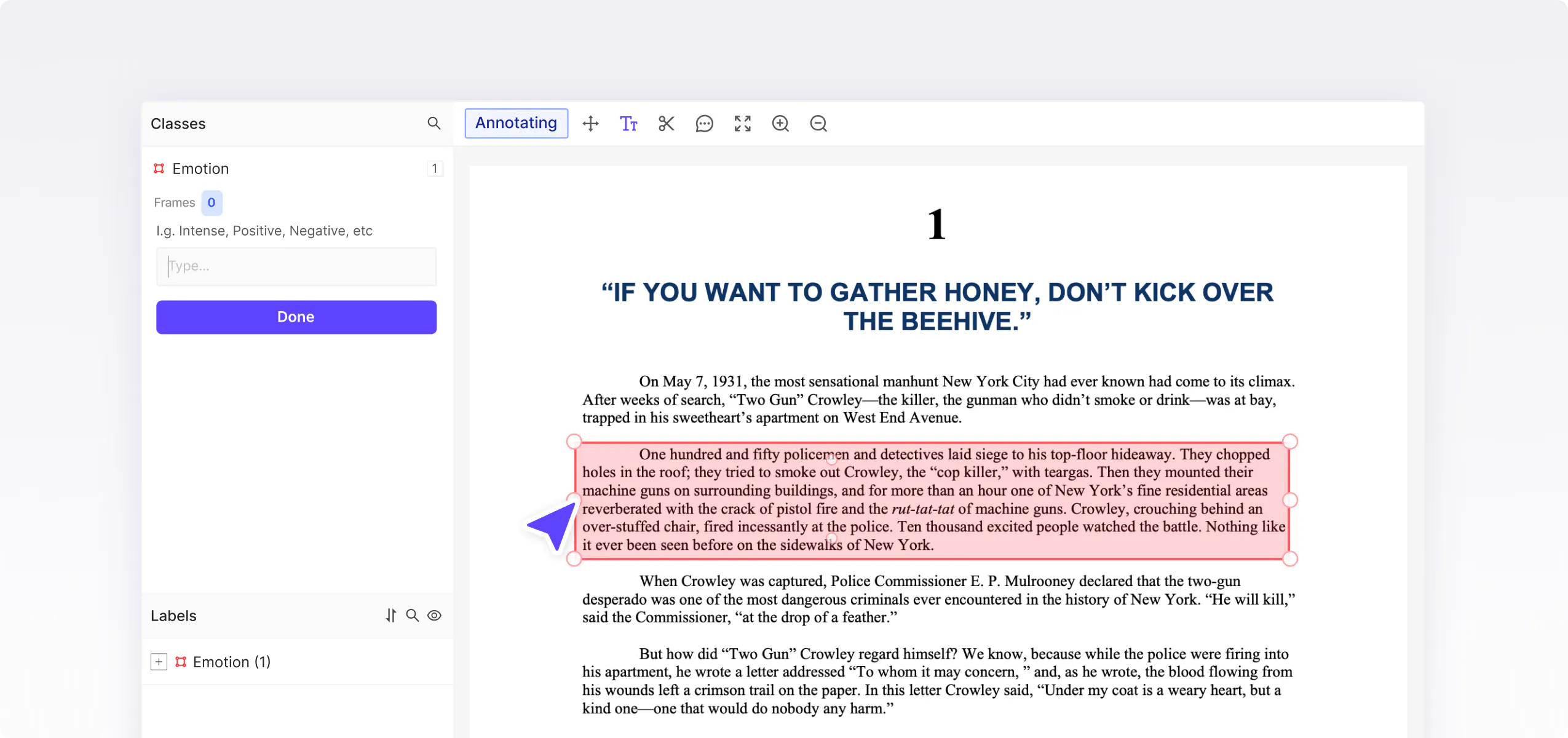
Categorize whole files or specific text strings and content into predefined topics or groups.

Identify and classify named entities within documents, such as people, organizations, locations, dates, and times.

Verify the quality of text extracted from PDFs using OCR or other techniques.
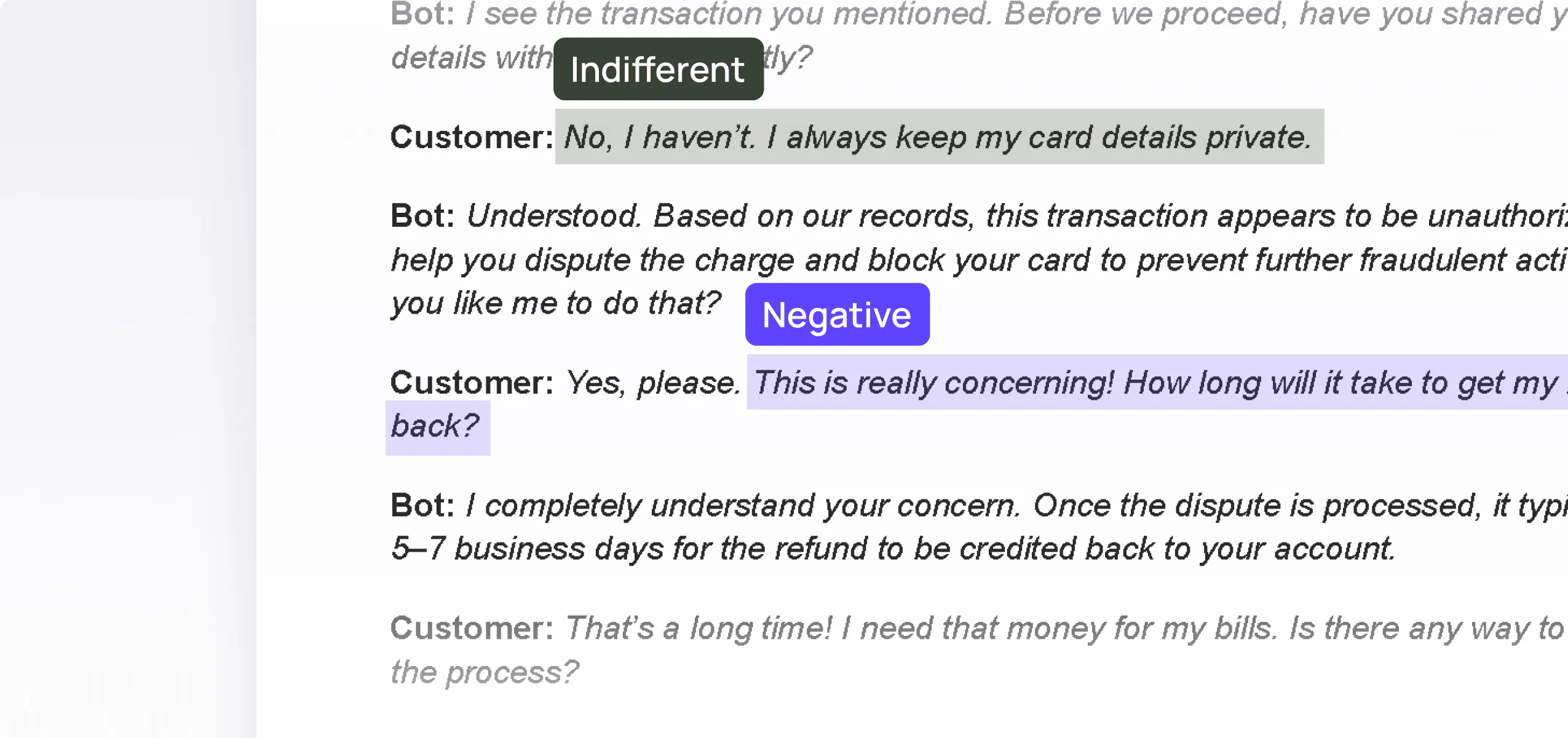
Label sentiment conveyed in words or sentences, including emotions such as positive, unhappy or indifferent.
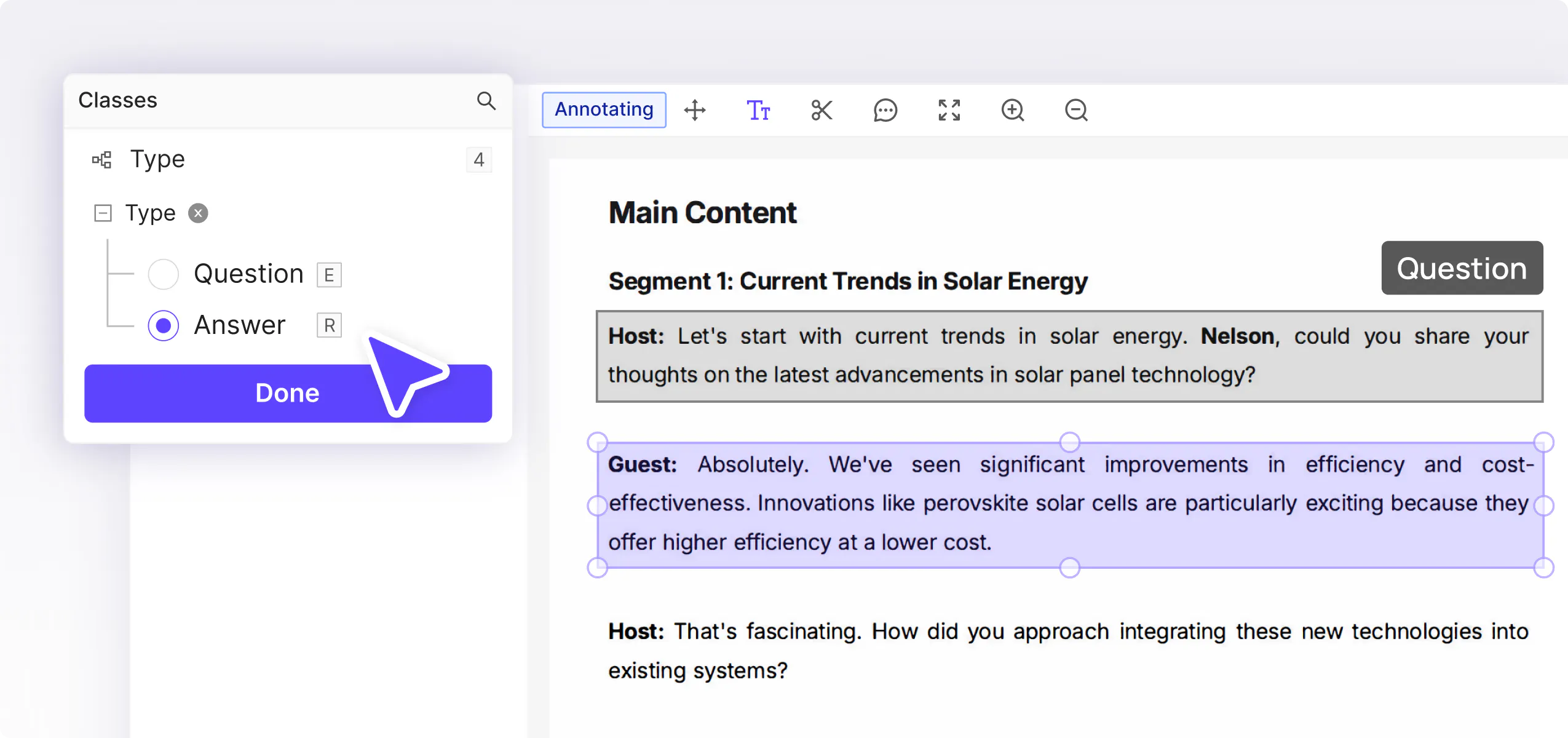
Categorize sections of text to reflect answers to questions about document content.
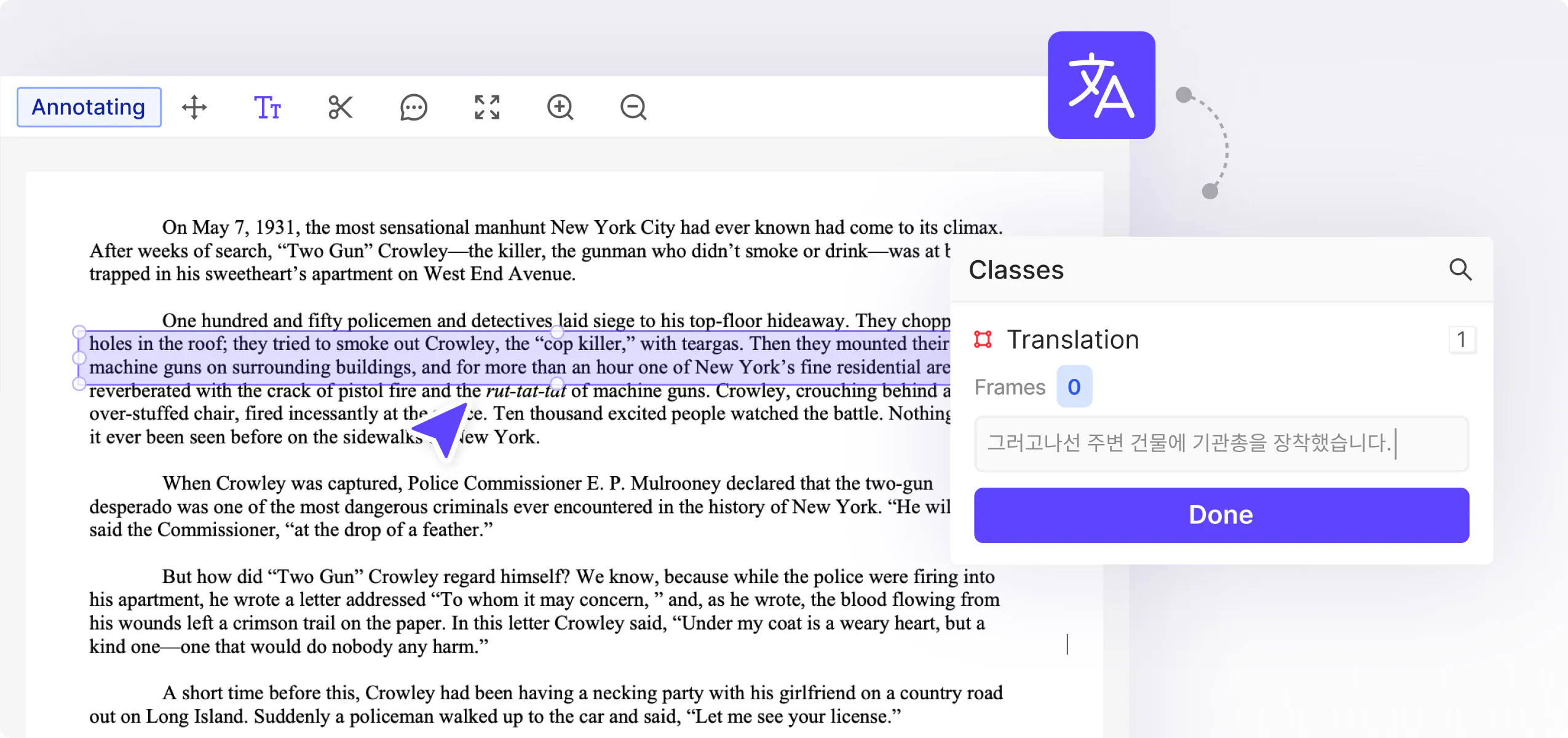
Use free text fields to seamlessly label and translate text.
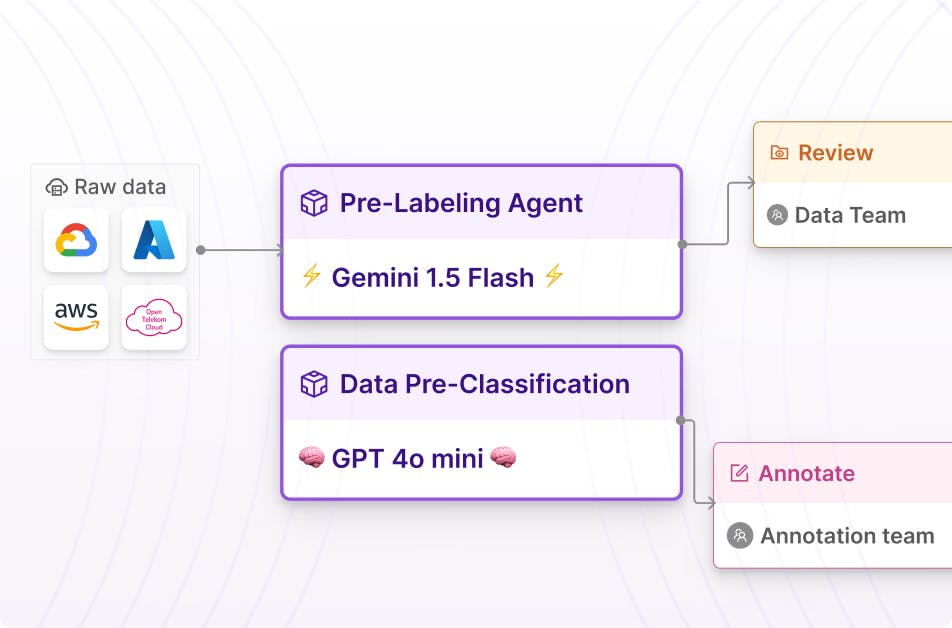
Customize text annotation workflows with Agents
Integrate SOTA models such as GPT4o, Gemini Pro 1.5 and more into data workflows to automate and accelerate document annotation processes. Auto-label or preclassify text content to save labeling resource or auto-sort millions of files to streamline data preparation workflows.
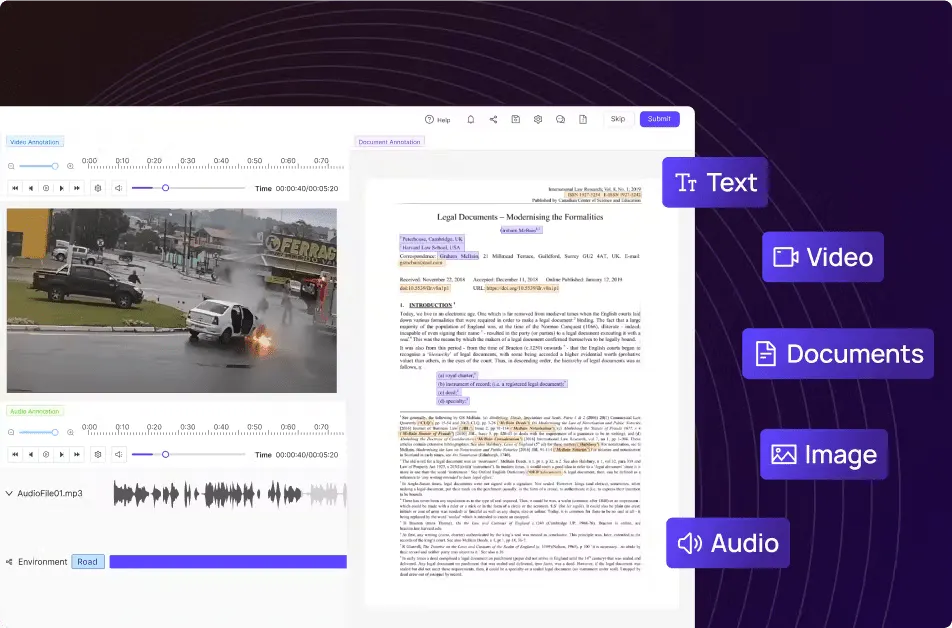
Analyze and annotate multimodal data in one view
Customize the label editor layout to suit any data labeling workflow.
Curate, search and organize large document and text datasets
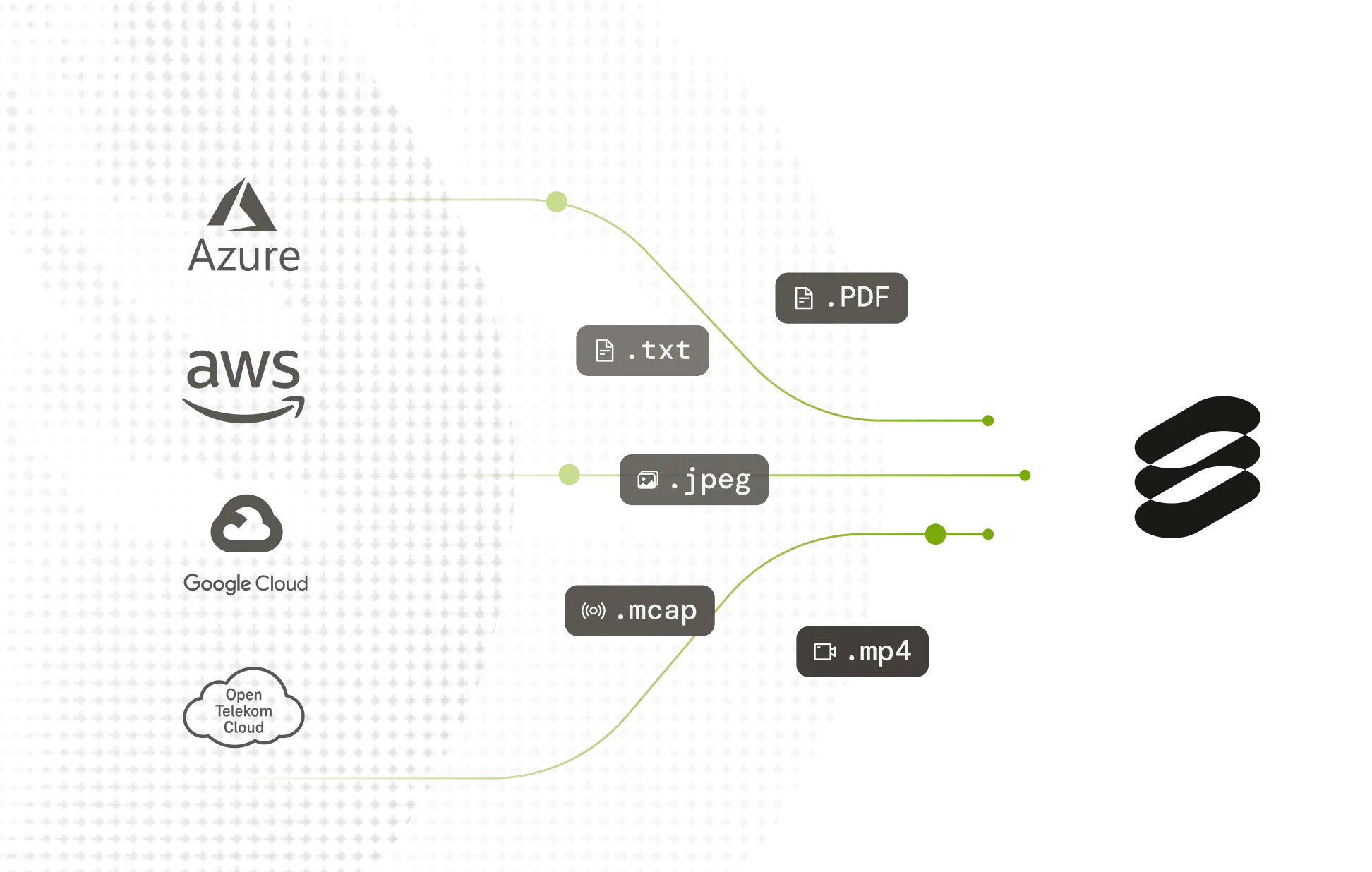
Upload millions of documents in minutes
Seamlessly unify documents across multiple fragmented data sources, teams and projects to one platform, alongside other multimodal datasets.
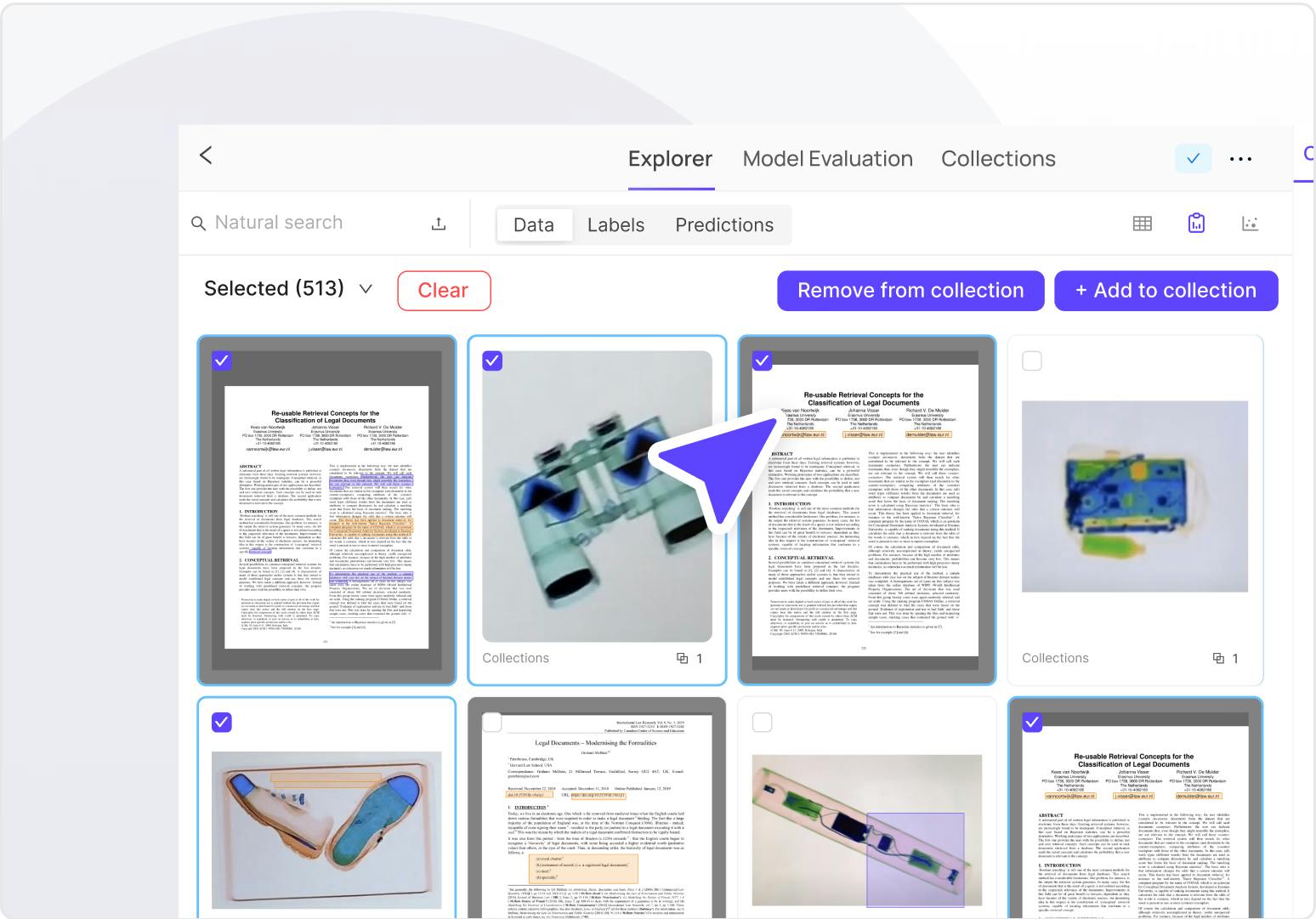
Explore large document and text datasets in seconds
Flexibly understand and curate petabytes of documents with ease using granular filtering by metadata and data attributes as well as embeddings based and natural language search capabilities.
You're in good company
Encord is used by 300+ frontier AI teams to deploy production-ready AI models.
Enterprise-grade.
Built for scale.
Designed for reliable AI.
Built for scale.
Designed for reliable AI.
API/SDK-first. Zero data migration. Your data stays in your cloud.
Visit trust centre



Get the data right
300+ of the best AI teams in the world use Encord. Join them.