
The end-to-end partner
for Physical AI data
Data collection, curation, annotation, and deployment feedback, under one roof. Encord is the only end-to-end data provider for teams building robotics, autonomous systems and embodied AI.
Collect, curate, annotate and deploy
From raw data to production-ready. Build a complete data lifecycle, custom to your needs, with a dedicated team of experts from Encord.
Designed for robotics and autonomy teams

Phase 1: Data collection & QC
Dedicated in-field operators and lab facilities with reconfigurable sets, teleoperation arms and standardised hardware - shaped to your needs.

Phase 2: Curate high-value data
Surface edge cases and trim datasets before they reach production, across images, video, LiDAR, PCD, audio and data from cloud buckets.
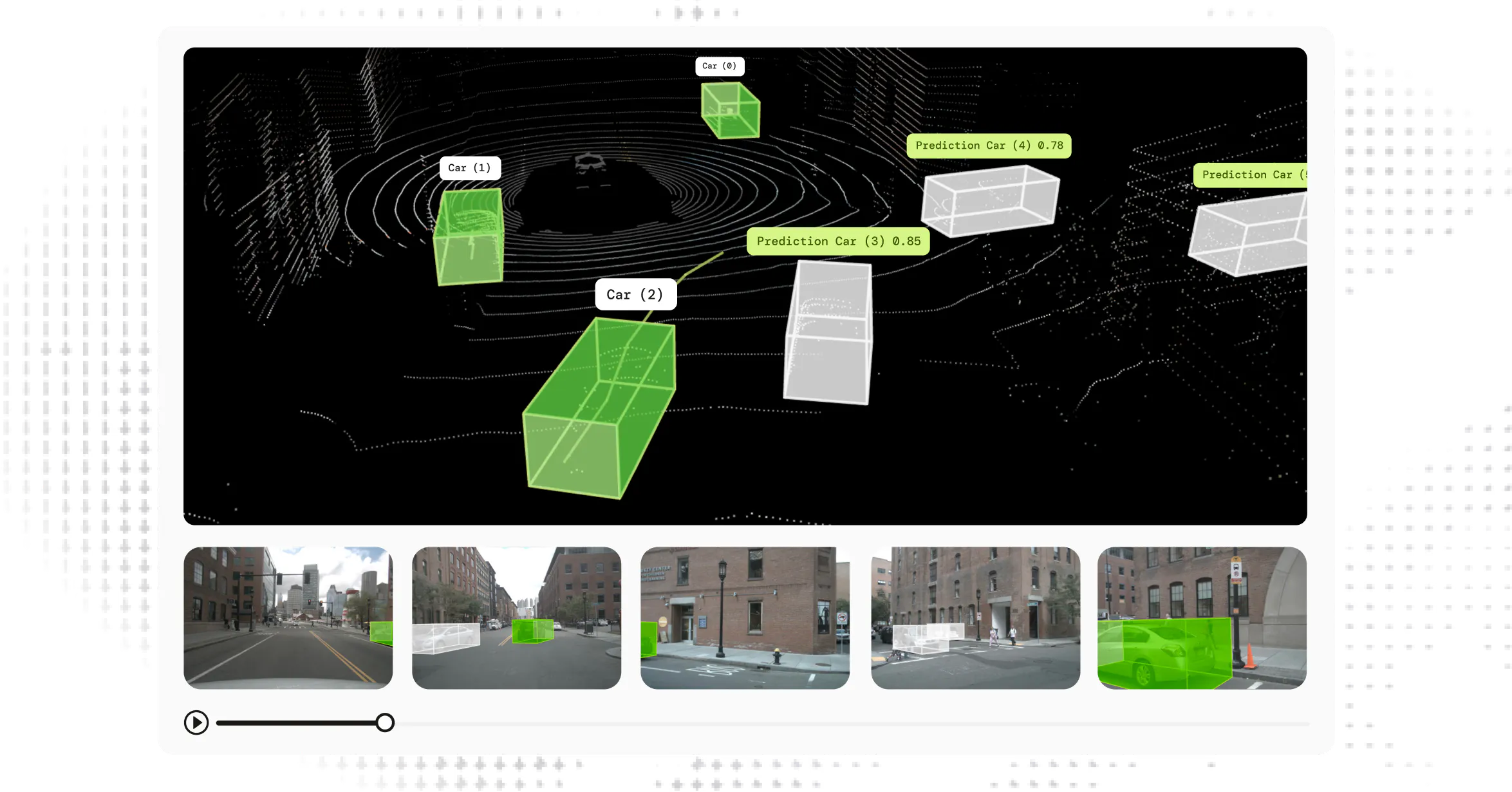
Phase 3: LiDAR & PCD labeling
Visualize and annotate LiDAR scans and 3D point cloud data directly in one platform, with sensor fusion across scenes, on the native sensor formats.

Phase 4: Deployment feedback
Human-in-the-loop supervision captures failure modes through remote teleoperation - feeding them back into your collection & annotation policies.
Tools built for VLMs and VLAs
Granular VLA annotation is slowed down by tools that were only made for basic image classification. Encord is built for working across long video timelines, multiple label tracks, and schemas with complex reasoning.
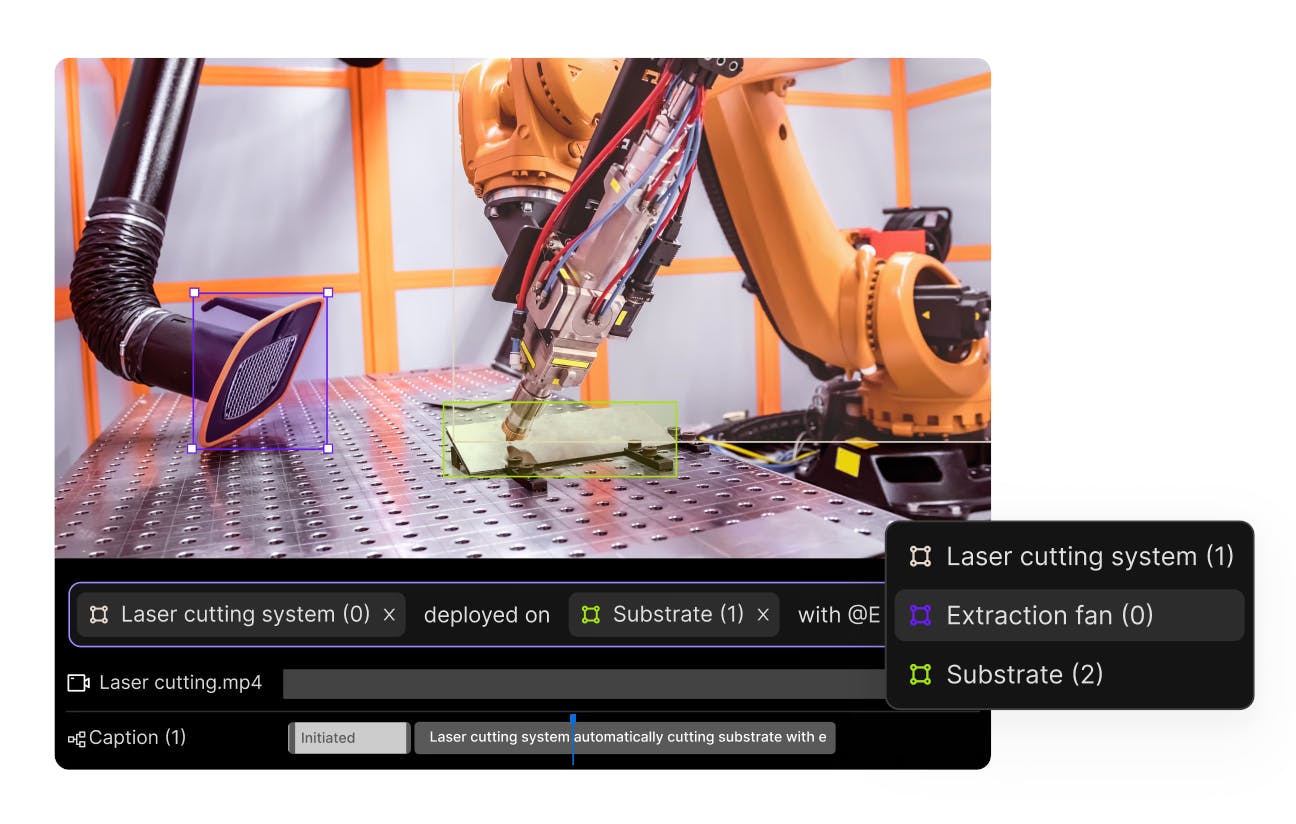
Complex action captioning at scale
Train VLA models on structured observation- action data across diverse embodiments. Close the gap between lab demonstrations and real deployment conditions.
Complex action captioning at scale
Train VLA models on structured observation- action data across diverse embodiments. Close the gap between lab demonstrations and real deployment conditions.
Why Encord?
300+ frontier AI teams use Encord to manage, curate and annotate their data.
“A big reason why we decided to partner with Encord was because of the quality bar we saw in doing POCs with around a dozen companies.”

Devi Parikh
Co-Founder & Co-CEO of Yutori
Built for scale.
Designed for reliable AI.
Designed for reliable AI.
API/SDK-first. Zero data migration. Your data stays in your cloud.
Visit trust center


Frequently asked questions
Multi-camera video, LiDAR, point cloud, time-series, IMU, audio, and sensor-fused data, with native support for MCAP and ROSBAG. Data is treated as time-aligned, calibrated streams, so 2D and 3D annotation happen in a single interface against the formats your sensors produce.
Yes! full-resolution and merged point clouds at scale, including dense scenes with billions of points. Tooling supports 3D bounding boxes, point cloud segmentation, sensor fusion across multi-camera and 3D views, and projection between point cloud and RGB data including fisheye and stereo.
Yes, in-field operators and reconfigurable lab facilities collect trajectory, teleoperation, embodiment-specific, and egocentric data. Collection protocols are designed around your task, environment, and hardware, then piloted at Encord facilities before scaling, including on-site collection at your factory or warehouse.
Yes! the full pipeline, including action captioning with timestamped frames, multi-step subtask annotation, structured observation-action labelling across embodiments, and pre-captioning with VLM models reviewed by humans. Output is structured JSON aligned to your training pipeline.
Multi-stage review with configurable consensus, role-based reviewers, granular feedback on individual frames or points, and full audit trails. Annotators specialise across off-road, construction, warehouse manipulation, agricultural environments, and pedestrian detection, with annotation guidelines built alongside your domain experts before scaling.
Yes! VPC and on-premise deployment is available alongside the standard SaaS option, including AWS VPC peering and air-gapped setups. Your data stays in your own cloud. Encord is SOC 2 Type II, HIPAA, and GDPR certified.
Field failures are captured through remote teleoperation and human review, then fed back into the data pipeline. Collection and annotation policies update automatically based on what's failing, so retraining data reflects where your model is breaking in the real world.
Design your
collection protocol
We start with your task definition, deployment environment, and hardware configuration. From there we design the collection protocol, pilot it at our facilities, and scale.