DINOv2: Self-supervised Learning Model Explained

Meta AI's latest breakthrough, DINOv2, is transforming how we approach computer vision tasks. Whether you're exploring cutting-edge research, seeking practical applications in industries like robotics or autonomous vehicles, or curious about how DINOv2 compares to CLIP or OpenCLIP, this article dives deep into everything you need to know.
MetaAI continues to lead the charge in AI research, making groundbreaking advances in both natural language processing (NLP) and computer vision. With their transformative contributions like LLaMA (Large Language Model Meta AI), SAM (Segment Anything Model), and now DINOv2, MetaAI is shaping the future of self-supervised learning.
In April 2023, they released DINOv2, an advanced self-supervised learning technique to train models, enhancing computer vision by accurately identifying individual objects within images and video frames.
The DINOv2 family of models boasts a wide range of applications, including image classification, object detection, and video understanding, among others. Unlike other models like CLIP and OpenCLIP, DINOv2 does not require fine-tuning for specific tasks. It is pretrained to handle many tasks out-of-the-box, simplifying the implementation process.
In this article, you will take an in-depth look at:
- DINOv2, the underlying techniques and datasets.
- How DINOv2 compares to other foundation models.
- How DINOv2 works, including the network design and architecture.
- Potential applications and the frequently asked questions (FAQs) by adopters.

The growth of self-supervision models
In the past decade or two, the most dominant technique for developing models has been supervised learning, which is very data-intensive and requires careful labeling. Acquiring labels from human annotators is very difficult and expensive to achieve at scale, and this slows down the progress of ML in lots of areas, more specifically computer vision.
Over the past few years, many researchers and institutions have focused their efforts on self-supervision models, obtaining the labels through a “semi-automatic” technique that involves observing a labeled dataset and predicting part of the data from that batch based on the features. It leverages both labeled and unlabeled datasets to build the training data or help with other downstream tasks.
One of those “self-supervision” techniques is self-supervised learning (SSL). SSL has gained traction in computer vision for training deep learning models without extensive labeled data. It involves a two-step process of pretraining and fine-tuning, where models learn representations from unlabeled data through auxiliary tasks and adapt to specific tasks using smaller amounts of labeled data.
Self-supervised models have, over the past few years, shown promise in applications such as image classification, object detection, and semantic segmentation, often achieving competitive or state-of-the-art performance. The advantages include a reduced reliance on labeled data, scalability to large datasets, and the potential for transfer learning.
The challenges with SSL remain in designing effective tasks, handling domain shifts, and understanding model interpretability and robustness. Some self-supervised learning (SSL) systems overcome these challenges by using techniques such as self-DIstillation with NO labels (DINO) which uses SSL and knowledge (or model) distillation methods.
Understanding knowledge (model) distillation
Knowledge distillation is the process of training a smaller model to mimic the larger model. In this case, you transfer the knowledge from the larger model (often called the “teacher”) to the smaller model (often called the “student”).
The first step involves training the teacher model with labeled data; it produces an output, so you map the input and output from the teacher model and use the smaller model to copy the output, while being more efficient in terms of model size and computational requirements.
The second step requires you to use a large dataset of unlabeled data to train the student models to perform as well as or better than the teacher models. The idea here is to train the large models with your techniques and distill a set of smaller models. This technique is very good for saving computing costs, and DINOv2 is built with it.
Comparing DINOv2 to DINO
Understanding the first generation DINO
DINOv1 (self-DIstillation with NO labels) is Meta AI’s version of a system for unsupervised pre-training of visual transformers. The idea is that self-supervised learning is well-aided by visual transformers for object detection because the attention maps contain explicit information about the semantic segmentation of an image.
DINO can visualize attention maps without supervision for random, unlabeled images and videos. This can be useful in cases like:
- Image retrieval, where similar images are clustered together.
- Image segmentation and proto-object detection.
- Zero-shot classification using a k-nearest neighbor (kNN) classifier in the feature space (the features are extracted from the Vision Transformers trained by DINO).
What does DINOv2 do better than DINO?

After testing both DINO and DINOv2 out, we have found the latter version to provide more accurate attention maps for objects in ambiguous and unambiguous scenes. According to Meta AI in the blog post explainer for DINOv2:
“DINOv2 is able to take a video and generate a higher-quality segmentation than the original DINO method. DINOv2 allows remarkable properties to emerge, such as a robust understanding of object parts, and robust semantic and low-level understanding of images.”
DINOv2 works better than DINO because of the following reasons:
- A larger curated training dataset.
- Improvements on the training algorithm and implementation.
- A functional distillation pipeline.
Larger curated training dataset
Training more complex architectures for DINOv2 necessitates more data for optimal results. Since accessing more data is not always possible, the team used a publicly available repository of web data and built a pipeline to select useful data.
That entailed removing unnecessary images and balancing the dataset across concepts. Because manual curation was not feasible, they developed a method for curating a set of seed images from multiple public datasets (e.g., imagenet) and expanding it by retrieving similar images from crawled web data. This resulted in a pretraining dataset of 142 million images from a source of 1.2 billion images.
Improvements on the training algorithm and implementation
DINOv2 tackles the challenges of training larger models with more data by improving stability through regularization methods inspired by the similarity search and classification literature and implementing efficient techniques from PyTorch 2 and xFormers. This results in faster, more memory-efficient training with potential for scalability in data, model size, and hardware.
Functional distillation pipeline
In an earlier section, you learned that the process of knowledge distillation involves training the student model using both the original labelled data and the teacher model's output probabilities as soft targets. By leveraging the knowledge learned by the teacher model, such as class relationships, decision boundaries, and model generalization, the student model can achieve similar performance to the teacher model with a smaller footprint.
This makes knowledge distillation particularly useful with DINOV2. The training algorithm for DINOv2 uses self-distillation to compress large models into smaller ones, enabling efficient inference with minimal loss in accuracy for ViT-Small, ViT-Base, and ViT-Large models.
Compared to the state-of-the-art in areas like semi-supervised learning (SSL) and weakly-supervised learning (WSL), DINOv2 models perform very well across tasks such as segmentation, video understanding, fine-grained classification, and so on:
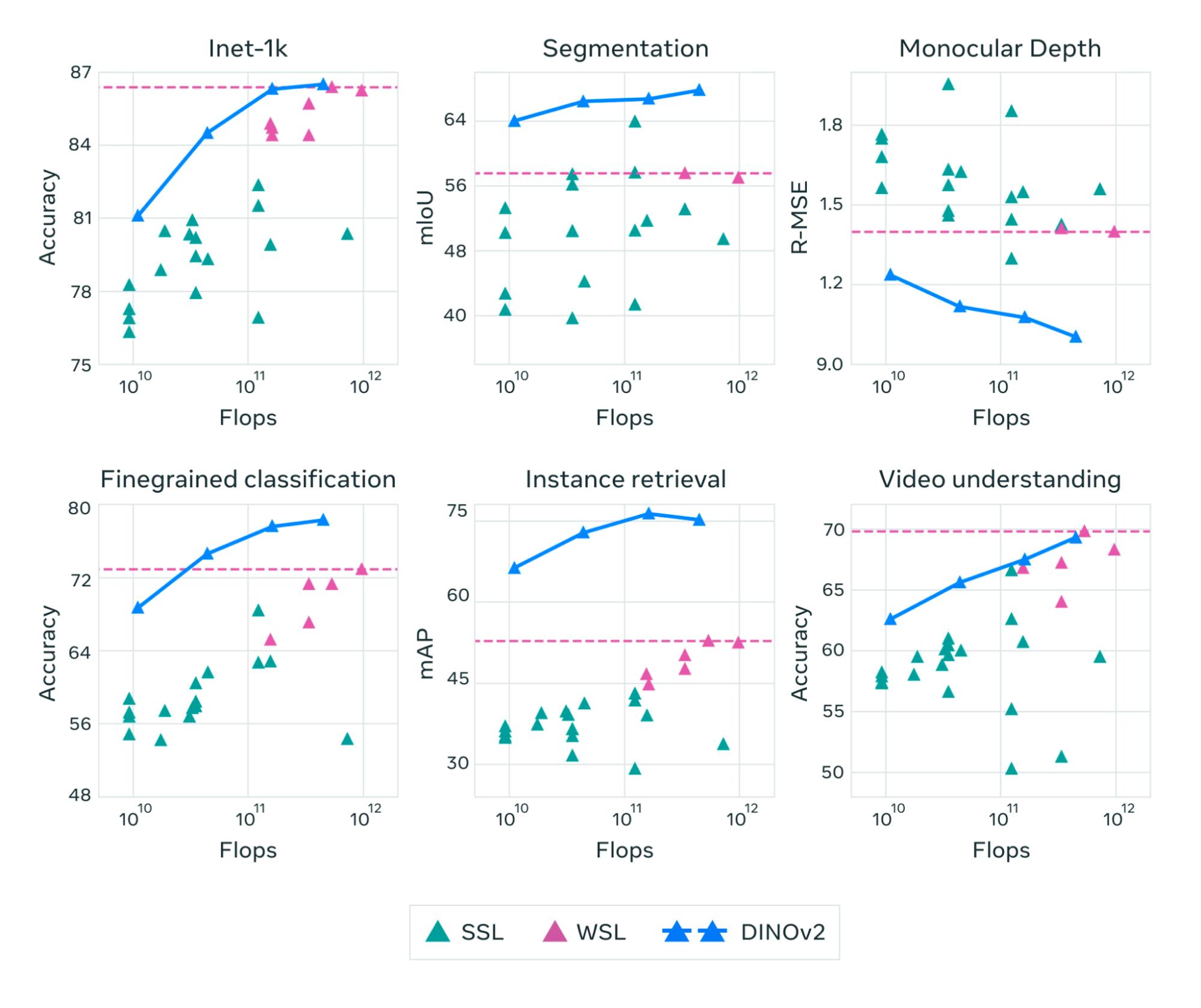
The DINOv2 models seem to be able to achieve general, multipurpose backbones for many types of computer vision tasks and applications. The models generalize well across domains without fine-tuning, unlike other models like CLIP and OpenCLIP.
DinoV2 Dataset
Meta AI researchers curated a large dataset to train DINOv2; they call it LVD-142M which includes 142 million images, largely due to a self-supervised image retrieval pipeline. The model extracts essential features directly from images, rather than relying on text descriptions.
The main components of the data pipeline are:
- The data sources.
- Processing technique.
- Self-supervised image retrieval.
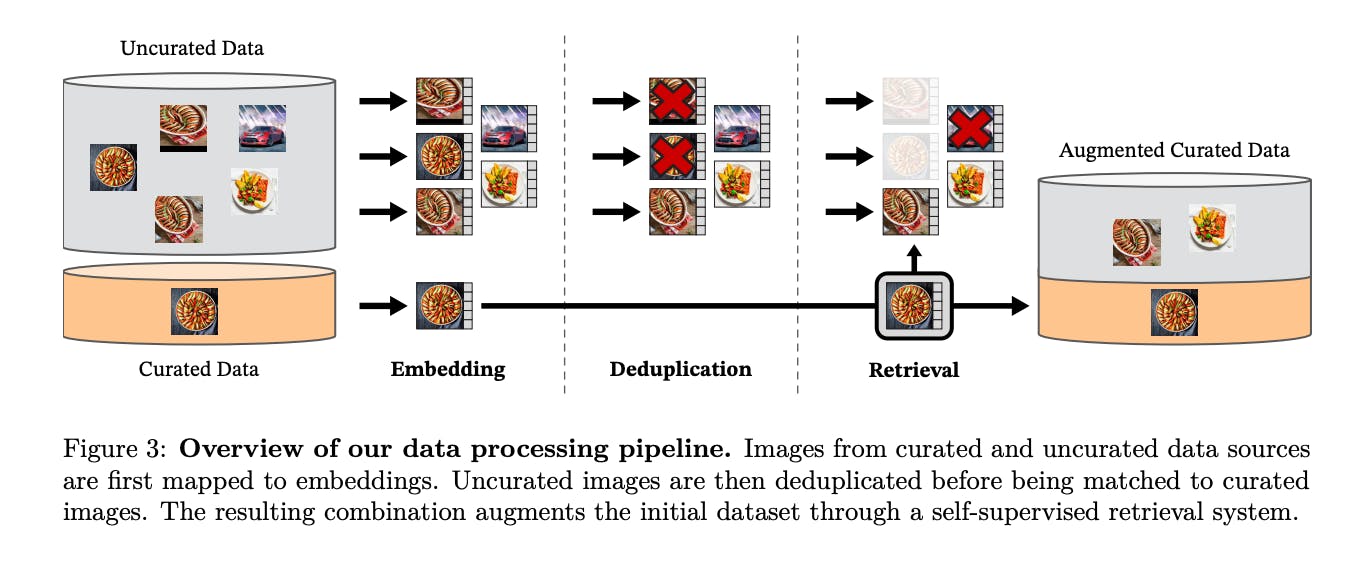
Data sources
The database consists of curated and uncurated datasets of 1.2 billion unique images. According to the researchers, the curated datasets contain ImageNet-22k, the train split of ImageNet-1k, Google Landmarks, and several fine-grained datasets.
Additionally, they sourced the uncurated dataset from a publicly available repository of crawled web data. They filtered the images to remove unsafe or restricted URLs and used post-processing techniques such as PCA hash deduplication, NSFW filtering, and blurring identifiable faces.
Image processing technique (de-duplication)
The researchers took the curated and uncurated datasets and fed them into a feature encoder to produce embeddings. They used the similarities (implemented with Faiss) between the embeddings to find and compare different images, which is helpful for de-duplication and retrieval.
De-duplication is the process of removing images with identical embeddings to reduce redundancy, while image retrieval is the process of retrieving images with identical embeddings.
Self-supervised image retrieval
In this case, a self-supervised image retrieval system uses a ViT-H/16 network pre-trained on ImageNet-22k to compute the image embeddings. They used a distributed compute cluster of nodes with 8 V100-32GB GPUs to compute the embeddings.
Using the embeddings, it finds similar images from the uncurated dataset to the curated datasets using cosine-similarity as a distance measure between the embeddings and k-means clustering of the uncurated data.
It then stores those similar embeddings in a database after processing them. This way, the system trains on batches of data that it curates itself by learning the similarities between curated and uncurated data batches.
DINOv2’s Network Architecture and Design: How it works
DINOv2 builds upon DINO’s network architecture and design and iBOT with several adjustments to “improve both the quality of the features as well as the efficiency of pretraining.” It uses self-supervised learning to extract essential features directly from images, rather than relying on text descriptions. This enables DINOv2 to better understand local information (in the image patches) and provide a multipurpose backbone for various computer vision tasks.
The researchers used the following approaches for DINOv2’s network architecture and design:
Image-level objective
In the initial DINO architecture, there’s a student-teacher network that involves a large network (the teacher) and a smaller network (the student). They crop different parts of the image and feed that to the feature encoder (a ViT) to produce embeddings. They build the student network by training on the embeddings, and they build the teacher network by taking the average of the weights of different student models.
Patch-level objective
The ViT divides the images into 4x4 patches, unrolls the array, and randomly masks some of the input patches the student network trains on. Principal component analysis (PCAs) are computed for patch features extracted by the network.

The iBOT Masked Image Modeling (MIM) loss term DINOv2 adopted improves patch-level tasks (e.g., segmentation).
Untying head weights between both objectives
Based on their learnings from DINO, there’s every likelihood that the model head can overfit the data due to its small size. The models can also underfit at the patch-level with a large ViT network.
Adapating the resolution of the images
According to the researchers, increasing image resolution is important for pixel-level downstream tasks like segmentation or detection, but training at high resolution can be time and memory intensive. So they proposed a “curriculum learning” strategy to train the models in a meaningful order from low to high resolution images. In this case, they increased the resolution of images to 518 x 518 during a brief period at the end of pretraining.
In addition to the approaches we explained above, the researchers also applied parameters such as softmax normalization, KoLeo regularizers (which improve the nearest-neighbor search task), and the L2-norm for normalizing the embeddings.
DINOv2 in Action
Along with segmentation, DINOv2 allows the semantic understanding of object parts in ambiguous and unambiguous images. The model can generalize across domains, including:
- Depth estimation.
- Semantic segmentation.
- Instance retrieval.
Depth estimation
DINOv2 can estimate the depth or distance information of objects in a scene from ambiguous two-dimensional images. At the high level, DINOv2 tries to determine the relative distances of different points or regions in the image, such as the distance from the camera to the objects or the distance between objects in the scene.
This makes the DINOv2 family of models useful for applications in various areas, such as:
- Augmented reality,
- Robotics,
- Autonomous vehicles,
- Medical imaging,
- Human-computer interaction,
- Gaming and entertainment,
- and virtual reality.
Semantic segmentation
DINOv2 can accurately classify and segment different objects or regions within an image, such as buildings, cars, pedestrians, trees, and roads. This fine-grained level of object-level understanding provides a detailed understanding of the visual content in an image and is useful in a wide range of applications, including agriculture, microbiology, video surveillance, and environmental monitoring.
Instance retrieval
DINOv2 also works well in scenarios where fine-grained object or scene understanding is required and where it is necessary to identify and locate specific instances of objects or scenes with high precision. This is the perfect scenario for instance retrieval. The model directly uses frozen features from the SSL technique to find images similar to a given image from a large image database.
It compares the visual features of the query instance with the features of instances in the image database and finds the closest matches based on visual similarity. This has wide applications in areas like image-based search, visual recommendation systems, image retrieval, and video analytics.
Conclusion
DINOv2 from Meta AI is a game changer in computer vision. Its self-supervised learning approach and multipurpose backbone make it a versatile tool that can be easily adopted across various industries. Without fine-tuning and minimal labeled data requirements, DINOv2 paves the way for a more accessible and efficient future in computer vision applications.
In the future, the team aims to incorporate this versatile model as a foundational component into a larger, more intricate AI system capable of interacting with expansive language models.
By leveraging a robust visual backbone that provides detailed image information, these advanced AI systems can analyze and interpret images with greater depth, surpassing the limitations of single-text sentence descriptions commonly found in text-supervised models. DINOv2 eliminates this inherent constraint, opening up new possibilities for enhanced image understanding and reasoning.
DINOv2 Frequently Asked Questions (FAQs)
Is DINOv2 Open-Source? Can I use it for commercial use-cases?
MetaAI released the pre-trained model and project assets on GitHub, but they are not exactly open source. They are rather source-available because they are under the Creative Commons Attribution-NonCommercial 4.0 International Public License. Essentially, that means they are only available for noncommercial use. Find the license file in the repository.
What tasks can DINOv2 be used for?
DINOv2 generalizes to a lot of tasks, including semantic segmentation, depth estimation, instance retrieval, video understanding, and fine-grained classification.
Do I need to fine-tune DINOv2?
Fine-tuning is optional. You can fine-tune the encoder to squeeze out more performance on your task, but the DINOv2 family of models were trained to work out-of-the-box for most tasks, so unless a 2-5% performance improvement is significant for your tasks, then it’s likely not worth the effort.
Does it perform better than other methods?
DINOv2 has a competitive performance on classification tasks with other weakly supervised learning methods like CLIP, OpenCLIP, SWAG, and EVA-CLIP on various pre-trained visual transformer (ViT) architectures. It also compares well against other self-supervised learning methods like DINO, EsViT, iBOT, and Mugs. See the table below for the full comparison with kNN and linear classifiers:
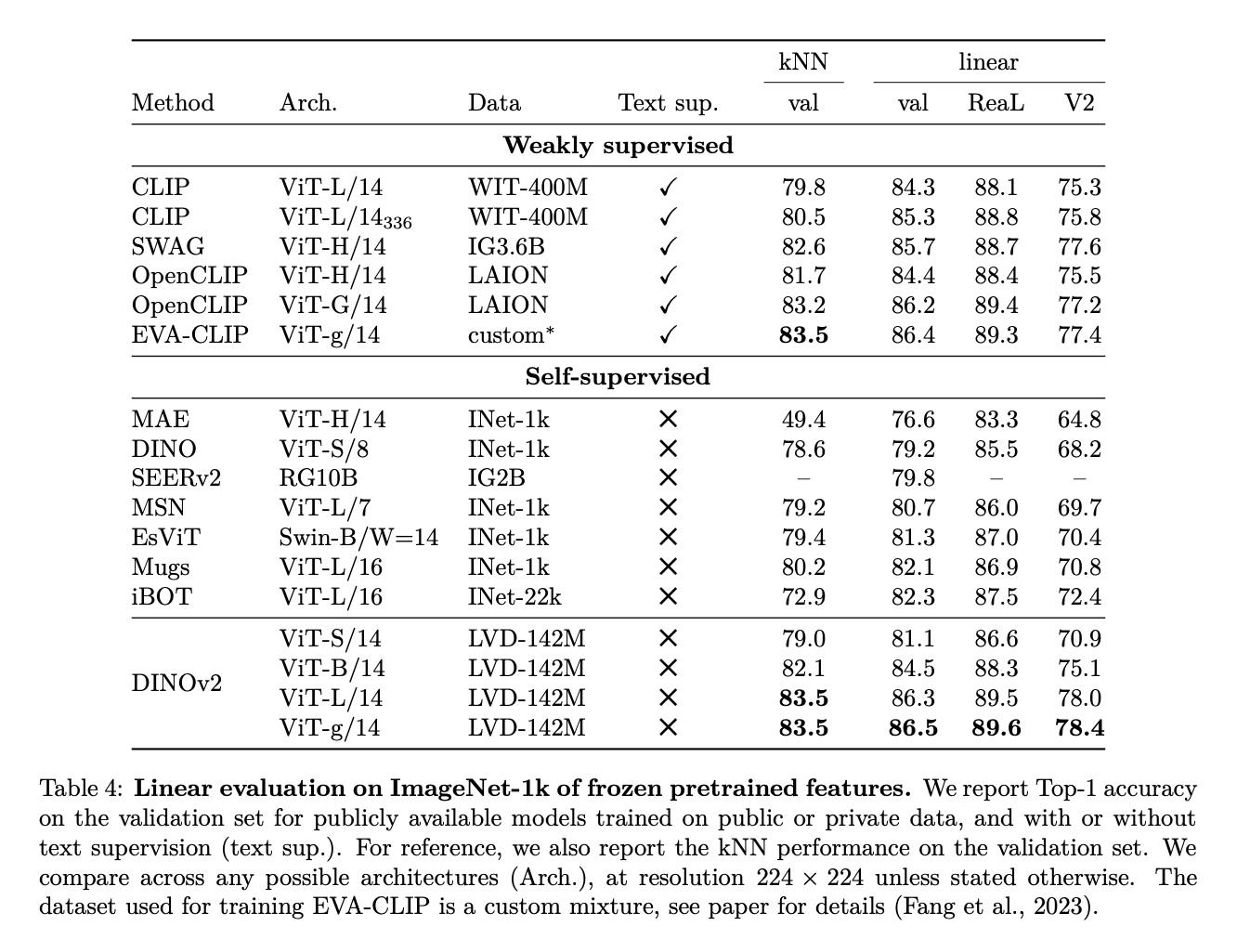
DINOv2's ability to train a large ViT model and distill it into smaller models that outperform OpenCLIP is an impressive feat in the unsupervised learning of visual features. The results speak for themselves, with superior performance on image and pixel benchmarks.
How can DINOv2 and SAM be used together?
SAM is the state-of-the-art for object detection and cannot be directly used for classification. Since it’s great at providing segmentation masks, you can use DINOv2’s ability for fine-grained classification on top of SAM for end-to-end applications.
How can I start using DINOv2?
There’s a demo lab for you to get started using the model on this page. At Encord, we are also working on a tutorial walkthrough with a step-by-step guide so you can implement the DINOv2 family of models on your dataset.
Can I incorporate prompting with the DINOv2 family of models?
For now, no. The DINOv2 are pure image foundation models and were not trained with texts. This is, of course, in contrast to text-image foundation models like CLIP. The authors of the paper argue that using images alone helped DINOv2 models outperform CLIP and other text-image foundation models.
What you might see in the next few months (I dare to say weeks, with the speed of innovation) is that there’d likely be a self-supervised pipeline that captions model outputs, uses them to train and caption more images, and produces a flywheel that iteratively labels and captions images, improving over time.
Will DINOv2 be great for labeling?
Yes, but compared to other solutions, the improvement might be minimal. Looking at the results from the evaluation table, comparisons with other methods like CLIP and OpenCLIP do not show significantly improved performance.
Resources
- Meta AI’s announcement blog post.
- GitHub repository for pre-trained models and other project assets.
- DINOV2 website.
- DINOv2 youtube video.
Frequently asked questions
DINOv2 is not fully open-source but is source-available under the Creative Commons Attribution-NonCommercial 4.0 International Public License. This means you can use it for research and non-commercial purposes but not for commercial applications without explicit permission. The license file is included in the official GitHub repository.
Semantic segmentation, Depth estimation, Instance retrieval, Video understanding, Fine-grained classification
It particularly shines in applications requiring object-level understanding, such as segmentation and depth estimation, where text supervision is less effective.
Unlike CLIP, which uses text-image pairs, DINOv2 relies solely on images, enabling it to outperform text-supervised models in certain vision tasks.
Yes, DINOv2 and SAM can complement each other. SAM excels in generating precise segmentation masks, while DINOv2 can provide fine-grained classification and feature extraction. Together, they can create robust end-to-end solutions for tasks requiring segmentation and classification.
No, DINOv2 is designed purely as an image-based model and does not support text-based tasks or prompting.
Encord offers training sessions for new users, including radiologists who may be transitioning from traditional software like 3D Slicer or ITK Snap. The platform is designed to be intuitive and familiar, making it easier for users to adapt. Our team is available to support training and ensure a smooth onboarding process.
Ground truthing is critical for validating the performance of machine learning models in autonomous driving. Encord's annotation platform ensures that the labeled data accurately reflects real-world scenarios, which is essential for training reliable models for tasks like lane and object detection.
Encord provides a comprehensive solution for data curation and annotation, enabling clients to find interesting moments in their data and annotate them effectively. This includes working with video natively for tasks such as tracking and labeling, which helps clients build better AI models faster.
Encord offers a variety of features for data annotation, including spatial and temporal labeling, as well as active learning capabilities. These tools allow users to efficiently create and manage annotation projects, ensuring that the data meets specific requirements for machine learning models.
Encord allows users to upload data from local devices and facilitates the curation process by enabling users to filter videos based on metadata, such as folder names and file names. This helps in identifying videos that are more likely to contain defects, thus optimizing the annotation workflow.
Encord includes built-in quality control features within its platform, allowing users to review and manage annotations effectively. This ensures that the annotation results meet the desired quality standards, unlike some providers that may deliver results without transparency or quality checks.
Encord is designed to facilitate seamless transitions from other annotation platforms by offering a range of features that enhance model training and evaluation. Our team works closely with clients to ensure a smooth migration, addressing any specific needs related to their previous systems.
Using supervised learning with Encord allows for more accurate image recognition as it utilizes annotated data to train models. This approach is particularly beneficial in industries like nuclear fuel production where identifying defects in images is critical for quality assurance.
Encord provides a robust annotation platform that includes features like indexing and active learning, enabling teams to efficiently manage and annotate their datasets. This is particularly beneficial for organizations looking to leverage machine learning and AI in their projects.
Encord is designed with user-friendliness in mind, making it accessible for non-technical annotators. The platform simplifies the annotation process, allowing users without extensive technical backgrounds to contribute effectively.