Introduction to Vision Transformers (ViT)

In the rapidly evolving landscape of artificial intelligence, a paradigm shift is underway in the field of computer vision.
Vision Transformers, or ViTs, are transformative models that bridge the worlds of image analysis and self-attention-based architectures. These models have shown remarkable promise in various computer vision tasks, inspired by the success of Transformers in natural language processing.
In this article, we will explore Vision Transformers, how they work, and their diverse real-world applications. Whether you are a seasoned AI enthusiast or just beginning in this exciting field, join us on this journey to understand the future of computer vision.
What is a Vision Transformer?
The Vision Transformers, or ViTs for short, combine two influential fields in artificial intelligence: computer vision and natural language processing (NLP). The Transformer model, originally proposed in the paper titled "Attention Is All You Need" by Vaswani et al. in 2017, serves as the foundation for ViTs. Transformers were designed as a neural network architecture that excels in handling sequential data, making them ideal for NLP tasks.
ViTs bring the innovative architecture of Transformers to the world of computer vision.
Vision Transformers vs Convolutional Neural Networks
In computer vision, Convolutional Neural Networks (CNNs) have traditionally been the preferred models for processing and understanding visual data. However, a significant shift has occurred in recent years with the emergence of Vision Transformers (ViTs). These models, inspired by the success of Transformers in natural language processing, have shown remarkable potential in various computer vision tasks.
CNN Dominance
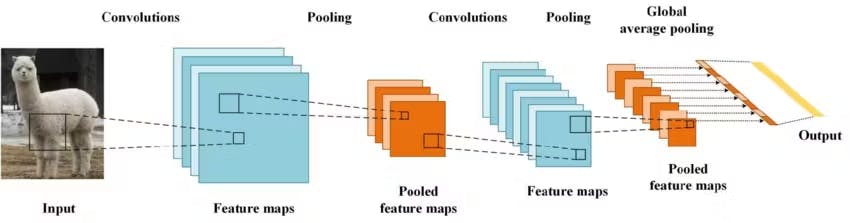
For decades, Convolutional Neural Networks (CNNs) have been the dominant models used in computer vision. Inspired by the human visual system, these networks excel at processing visual data by leveraging convolutional operations and pooling layers. CNNs have achieved impressive resultsin various image-related tasks, earning their status as the go-to models for image classification, object detection, and image segmentation.
Application of Convolutional Neural Network Method in Brain Computer Interface
A convolutional network comprises layers of learnable filters that convolve over the input image. These filters are designed to detect specific features, such as edges, textures, or more complex patterns. Additionally, pooling layers downsample the feature maps, gradually reducing the spatial dimensions while retaining essential information. This hierarchical approach allows CNNs to learn and represent hierarchical features, capturing intricate details as they progress through the network.
Vision Transformer Revolution
While CNNs have been instrumental in computer vision, a paradigm shift has emerged with the introduction of Vision Transformers (ViTs). ViTs leverage the innovative Transformer architecture, originally designed for sequential data, and apply it to image understanding.
CNNs operate directly on pixel-level data, exploiting spatial hierarchies and local patterns. In contrast, ViTs treat images as sequences of patches, borrowing a page from NLP where words are treated as tokens. This fundamental difference in data processing coupled with the power of self-attention, enables ViTs to learn intricate patterns and relationships within images, gives ViTs a unique advantage.
How do Vision Transformers Work?
Transformer Foundation
To gain an understanding of how Vision Transformers operate, it is essential to understand the foundational concepts of the Transformer architecture like self-attention. Self-attention is a mechanism that allows the model to weigh the importance of different elements in a sequence when making predictions, leading to impressive results in various sequence-based tasks.
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Adapting the Transformer for Images
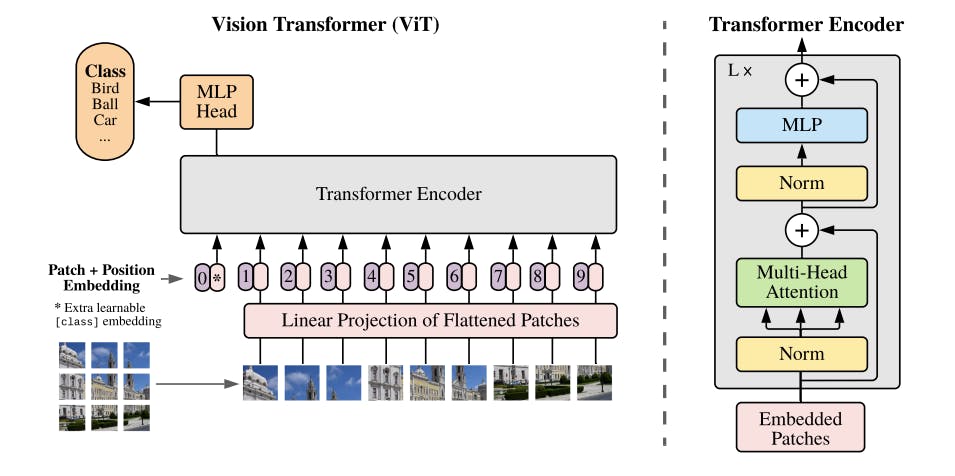
The concept of self-attention has been adapted for processing images with the use of Vision Transformers. Unlike text data, images are inherently two-dimensional, comprising pixels arranged in rows and columns. To address this challenge, ViTs convert images into sequences that can be processed by the Transformer.
- Split an image into patches: The first step in processing an image with a Vision Transformer is to divide it into smaller, fixed-size patches. Each patch represents a local region of the image.
- Flatten the patches: Within each patch, the pixel values are flattened into a single vector. This flattening process allows the model to treat image patches as sequential data.
- Produce lower-dimensional linear embeddings: These flattened patch vectors are then projected into a lower-dimensional space using trainable linear transformations. This step reduces the dimensionality of the data while preserving important features.
- Add positional encodings: To retain information about the spatial arrangement of the patches, positional encodings are added. These encodings help the model understand the relative positions of different patches in the image.
- Feed the sequence into a Transformer encoder: The input to a standard Transformer encoder comprises the sequence of patch embeddings and positional embeddings. This encoder is composed of multiple layers, each containing two critical components: multi-head self-attention mechanisms (MSPs), responsible for calculating attention weights to prioritize input sequence elements during predictions, and multi-layer perceptron (MLP) blocks. Before each block, layer normalization (LN) is applied to appropriately scale and center the data within the layer, ensuring stability and efficiency during training. During the training, an optimizer is also used to adjust the model's hyperparameters in response to the loss computed during each training iteration.
- Classification Token: To enable image classification, a special "classification token" is prepended to the sequence of patch embeddings. This token's state at the output of the Transformer encoder serves as the representation of the entire image.
Inductive Bias and ViT
It's important to note that Vision Transformers exhibit less image-specific inductive bias compared to CNNs. In CNNs, concepts such as locality, two-dimensional neighborhood structure, and translation equivariance are embedded into each layer throughout the model. However, ViTs rely on self-attention layers for global context and only use a two-dimensional neighborhood structure in the initial stages for patch extraction. This means that ViTs rely more on learning spatial relations from scratch, offering a different perspective on image understanding.
Hybrid Architecture
In addition to the use of raw image patches, ViTs also provide the option for a hybrid architecture. With this approach, input sequences can be generated from feature maps extracted by a CNN. This level of flexibility allows practitioners to combine the strengths of CNNs and Transformers in a single model, offering further possibilities for optimizing performance.
Real-World Applications of Vision Transformers
Now that we have a solid understanding of what Vision Transformers are and how they work, let's explore their machine learning applications. These models have proven to be highly adaptable, thereby potentially transforming various computer vision tasks.
Image Classification
A primary application of Vision Transformers is image classification, where ViTs serve as powerful classifiers. They excel in categorizing images into predefined classes by learning intricate patterns and relationships within the image, driven by their self-attention mechanisms.
Object Detection
Object detection is another domain where Vision Transformers are making a significant impact. Detecting objects within an image involves not only classifying them but also precisely localizing their positions. ViTs, with their ability to preserve spatial information, are well-suited for this task. These algorithms can identify objects and provide their coordinates, contributing to advancements in areas like autonomous driving and surveillance.
Image Segmentation
Image segmentation, which involves dividing an image into meaningful segments or regions, benefits greatly from the capabilities of ViTs. These models can discern fine-grained details within an image and accurately delineate object boundaries. This is particularly valuable in medical imaging, where precise segmentation can aid in diagnosing diseases and conditions.
Action Recognition
Vision Transformers are also making strides in action recognition, where the goal is to understand and classify human actions in videos. Their ability to capture temporal dependencies, coupled with their strong image processing capabilities, positions ViTs as contenders in this field. They can recognize complex actions in video sequences, impacting areas such as video surveillance and human-computer interaction.
Multi-Modal Tasks
ViTs are not limited to images alone. They are also applied in multi-modal tasks that involve combining visual and textual information. These models excel in tasks like visual grounding, where they link textual descriptions to corresponding image regions, as well as visual question answering and visual reasoning, where they interpret and respond to questions based on visual content.
Transfer Learning
One of the remarkable features of Vision Transformers is their ability to leverage pre-trained models for transfer learning. By pre-training on large datasets, ViT models learn rich visual representations that can be fine-tuned for specific tasks with relatively small datasets. This transfer learning capability significantly reduces the need for extensive labeled data, making ViTs practical for a wide range of applications.
Vision Transformers: Key Takeaways
- Vision Transformers (ViTs) represent a transformative shift in computer vision, leveraging the power of self-attention from natural language processing to image understanding.
- Unlike traditional Convolutional Neural Networks (CNNs), ViTs process images by splitting them into patches, flattening those patches, and then applying a Transformer architecture to learn complex patterns and relationships.
- ViTs rely on self-attention mechanisms, enabling them to capture long-range dependencies and global context within images, a feature not typically found in CNNs.
- Vision Transformers have applications in various real-world tasks, including image classification tasks, object detection, image segmentation, action recognition, generative modeling, and multi-modal tasks.

Frequently asked questions
A Vision Transformer, or ViT, is a deep learning model architecture that applies the principles of the Transformer architecture, initially designed for natural language processing, to the field of computer vision. ViTs process images by dividing them into smaller patches, treating these patches as sequences, and employing self-attention mechanisms to capture complex visual relationships.
Vision Transformers and Convolutional Neural Networks (CNNs) differ in their approach to processing images. While CNNs operate directly on pixel-level data with convolutional layers, ViTs treat images as sequences of patches, leveraging self-attention for global context and relationships between patches. This unique approach allows ViTs to capture long-range dependencies that CNNs may struggle to capture.
ViTs offer several advantages, including their ability to handle images of varying resolutions, their strong performance in tasks requiring global context, and their effectiveness in transfer learning. They can pre-train on large datasets and then fine-tune for specific tasks with limited labeled data, making them versatile and efficient models for various computer vision tasks.
Vision Transformers have found applications in a wide range of tasks, including image classification, object detection, image segmentation, action recognition, generative modeling, and multi-modal tasks that involve combining visual and textual information. Their flexibility and robust performance make them suitable for diverse industries, from healthcare to entertainment.
While Vision Transformers have shown remarkable performance in various computer vision tasks, they may not entirely replace CNNs. CNNs still excel in tasks where spatial hierarchies and local patterns are crucial, especially in tasks with limited data. ViTs are a valuable addition to the computer vision toolbox, offering a different perspective and capabilities that complement those of CNNs. The choice between them often depends on the specific requirements of a task.
Encord is unique in its ability to render video natively rather than breaking it down into frames. This feature facilitates advanced video processing, allowing users to transform videos into datasets effectively. The platform supports various processing mechanisms to meet specific filtration requirements, ensuring high-quality outputs tailored to user needs.
For teams utilizing fixed cameras, Encord mitigates common data quality issues often encountered with field or human-collected data. The automated nature of data collection from fixed cameras generally results in high-quality raw data, allowing for more efficient annotation processes.
Encord supports video re-identification (re-ID), which is a key reason why many video teams choose our platform. This functionality allows for tracking and identifying subjects across different camera views, enhancing the effectiveness of video analytics.
Encord provides various metrics, such as brightness, to help assess lighting conditions in videos. While we do not offer out-of-the-box models for lighting detection, we enable clients to build their own models tailored to their requirements.
Yes, Encord is designed to support multiple modalities, including audio, computer vision, and text. This versatility allows users to implement a wide range of applications across different domains.