Object Detection: Models, Use Cases, Examples

Co-Founder & Co-CEO at Encord
Object detection is a computer vision technique that detects relevant objects within an image or a video frame. Object detection algorithms use complex machine learning and deep learning architectures to analyze image data, and recognize and localize objects of interest. The output of these algorithms includes an object name and a bounding box for location information.
Object detection has various practical applications, including medical imaging, security detection systems, and self-driving cars. This article will discuss object detection, how it works, and some practical applications.
Let’s dive in...

What is Object Detection?
Simply put, object detection is a computer’s ability to identify and localize an object within an image. The intuition here is that, like humans, machines should have knowledge of all entities within their frame of reference. These entities may include people, animals, cars, trees, etc.
However, computer vision has come a long way, and today, we see many advanced machine-learning algorithms for objection recognition and segmentation. Before moving forward, it is important to distinguish what object detection is not.
Object Detection vs. Image Classification
Both image classification and object detection are used to recognize entities within images. However, an image recognition algorithm associates one class from the training data with an entire image or video frame regardless of how much information it contains. For example, a cat classifier model will only output a positive response if a cat is present. Moreover, the classification model does not provide any information about the detected object's location.
Object detection takes the classification algorithm a step further. On top of classifying multiple objects in an image, it returns annotations for bounding boxes corresponding to the location of each entity. The additional perks allow the CV model to be used in several real-world applications.

Object detection vs. Image classification vs. Image segmentation
Object Detection vs. Image Segmentation
Image segmentation is similar to object detection as they perform the same function. Both algorithms detect objects in images and output coordinates for object localization. However, rather than drawing entire boxes around objects, segmentation algorithms generate precise masks that cover objects on a pixel level.
Image segmentation annotations include precise pixel coordinates of instances contained within the image. Due to its precise outcomes, image segmentation is better suited for real-life applications such as vehicle detection. However, due to algorithm complexity, image segmentation models are computationally expensive compared to object detection.

Object Detection in Computer Vision
Object detection can automate cumbersome tasks to improve productivity and efficiency across various industries.
Pros of Object Detection
This computer vision technology has entered several industries and helped automate critical operations.
Most modern object detection models are employed in medical imaging to detect minor abnormalities like tumors that may otherwise go unnoticed. These algorithms are used in everyday applications as well. Some common use cases include person detection with security cameras and face detection for authorized entry/exit. Moreover, modern models are efficient enough to run on mid-tier computers, further expanding their usability.
Cons of Object Detection
While the usefulness of object detection is undeniable, its applications are sensitive to the input images. The detection accuracy depends on image color, contrast, quality, and object shape and orientation.
Object detection models are often troubled by object orientation. Many live objects, such as humans and animals, may be found in different poses. An AI model will not understand all these orientations and lose detection accuracy.
Apart from these examples, object detection is a valuable computer vision component for thousands of real-world use cases and applications.
Deep Learning and Object Detection
Object detection algorithms are quite complex. They require complicated processing, and their datasets contain multi-level information. Such information requires complex algorithms for feature extraction, understanding, and model training.
Deep learning has made modern object detection models, algorithms, and most real-world applications possible. Most modern state-of-the-art models employ deep-learning architecture for their impressive results. Some popular deep-learning architectures for object detection include:
- SSD
- YOLO
- R-CNN
- Fast R-CNN
Before deep learning, object detection was less advanced. Now, we have one- and two-stage object detection algorithms with the influence of deep learning algorithms and models (such as YOLO, SSD, R-CNN, etc.). Making the use cases and applications for object detection much broader and deeper, including countless examples in computer vision.
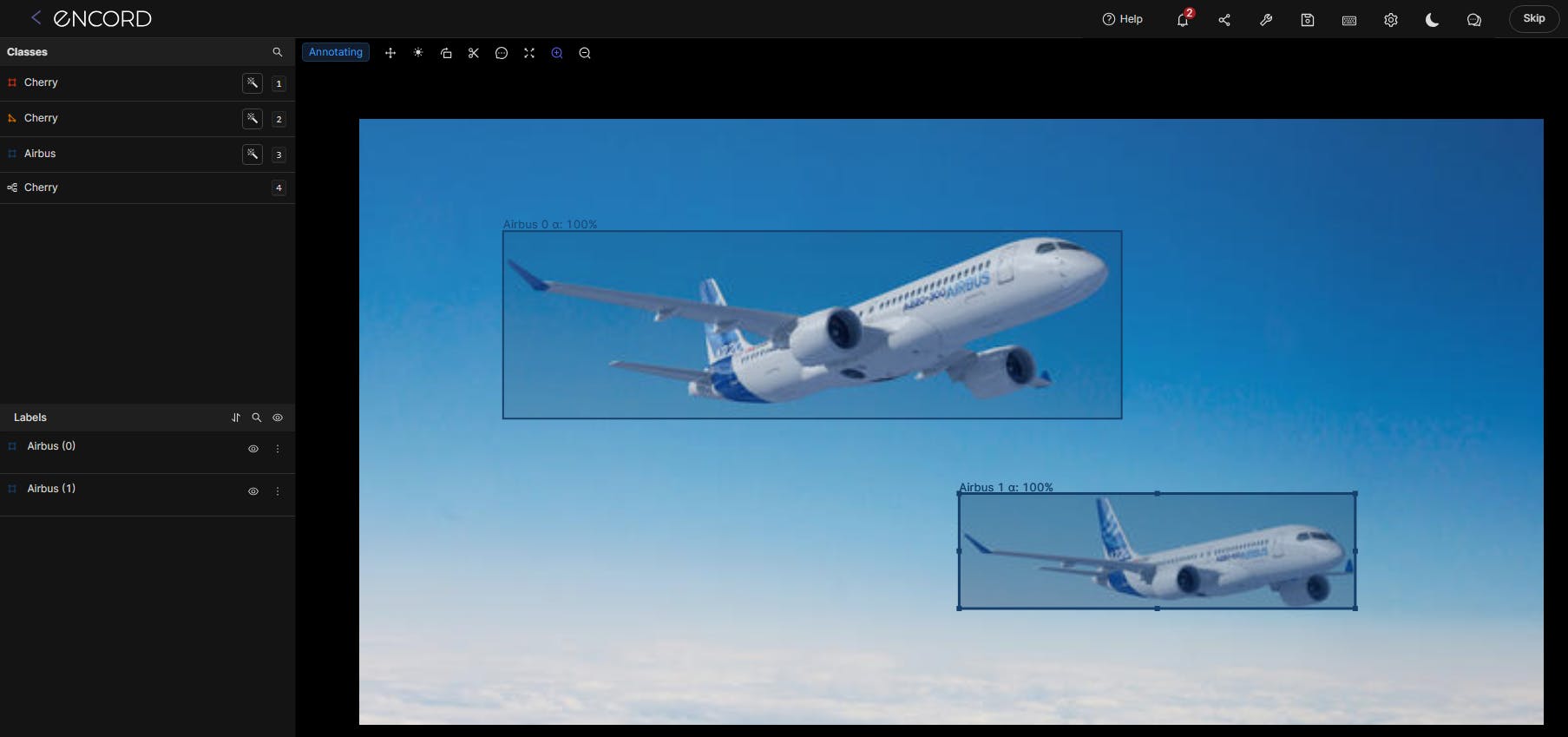
Object detection in action, YOLOv8 used in Encord on the Airbus Aircraft Detection dataset.
Person Detection
Person detection is a key application of object recognition models. It is used with video cameras for real-time video surveillance in homes, public places, and self-driving cars.
This application is further extended to trigger other use cases, e.g., calling the police for unauthorized personnel or stopping a self-driving car from hitting a pedestrian.
Most person detection models are trained to identify people based on front-facing and asymmetric images or video frames.
How Does Object Detection Work?
Traditional computer vision algorithms use image processing techniques for classification and object detection tasks. Open-source Python libraries like OpenCV include implementations for several functions for image transformation and processing. These include image warping, blurring, and advanced implementations like the haar-cascade classifiers.
However, most modern trained models use complex architectures and supervised learning. These utilize dataset annotations and deep learning to achieve high performance and efficiency.
Deep learning object detection works in numerous ways, depending on the algorithms and models deployed (e.g., YOLO, SSD, R-CNN, etc).
In most cases, these models are integrated into other systems and are only one part of the overall process of detecting, labeling, and annotating objects in images or videos. And this includes multi-object tracking for computer vision projects.
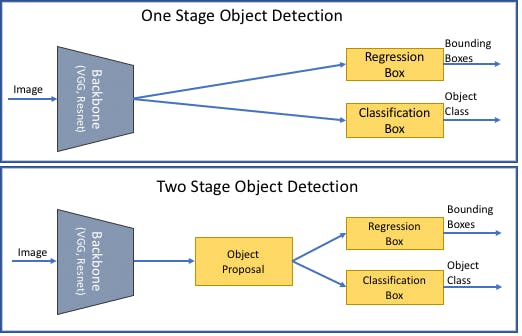
One-stage vs. Two-stage Deep Learning Object Detectors
There are two main approaches to implementing object detection: one-stage object detectors and two-stage object detectors.
Both approaches find the number of objects in an image or video frame and classify those objects or object instances while estimating size and positions using bounding boxes.
A one-stage detector does not include any intermediate processing. It takes an input image and directly outputs the class and bounding boxes. Popular one-stage detectors include YOLO (including v8), RetinaNet, and SSD.
A two-stage detector, conversely, performs two separate tasks. The first step involves a region proposal network that gives us the region of interest (ROI) where an object might be present. A second network then uses this ROI to produce bounding boxes. Popular two-stage detectors include R-CNN, Faster R-CNN, Mask R-CNN, and the latest model, G-RCNN.
Object Detection Use Cases and Applications
Object detection has numerous real-world applications and uses.
It’s an integral part of computer vision (CV), ML, and AI projects and software worldwide in dozens of sectors, including healthcare, robotics, automotive (self-driving cars), retail, eCommerce, art, ecology, agriculture, zoology, travel, satellite imagery, and surveillance.
Some common real-world use cases include:
- Scanning and verifying faces against passports at airports
- Detecting roads, pedestrians, and traffic lights in autonomous vehicles
- Monitoring animals in agricultural farms and zoos
- Ensuring people on the “No Fly” list don’t get through security gates at airports
- Monitoring customers in retail stores
- Detecting branded products mentioned on social media; an AI-based system known as “Visual Listening”
Object detection is even used in art galleries, where visitors can use apps to scan a picture and learn everything about it, from its history to the most recent valuation.
Object Detection Development Milestones
The milestones of object detection were not an overnight success. The field has been undergoing constant innovation for the past 20 years.
The traditional approaches started in 2001 with the Viola-Jones Detector, a pioneering machine-learning algorithm that makes object detection possible. In 2006, the HOG Detector was launched, and then DPM in 2008, introducing bounding box regression.
However, the true evolution was achieved in 2014, when Deep Learning detection started to shape the models that make object detection possible.
Once Deep Learning Detection got involved in 2014, two-stage object detection algorithms and models were developed over the years. These models include RCNN and R-CNN and various iterations on these (Fast, Faster, Mask, and G-RCNN). We cover those in more detail below.
One-stage object detection algorithms, such as YOLO (and subsequent iterations, up to version 8), SSD (in 2016), and RetinaNet, in 2017.
Popular Object Detection Algorithms
YOLO, SSD, and R-CNN are some of the most popular object detection models.
YOLO: You Only Look Once
YOLO (You Only Look Once) is a set of popular computer vision algorithms. It includes several tasks, such as classification, image segmentation, and object detection. YOLO was developed by Joseph Redmon, Ali Farhadi, and Santosh Divvala, aiming to achieve highly-accurate object detection results faster than other models.
YOLO uses one-stage detection models to process images in a single pass and output relevant results. YOLO is part of a family of one-stage object detection models that process images following convolutional neural network (CNN) patterns.
The latest version of YOLO is YOLOv8, developed by Ultralytics. It makes sense to use this model if you prefer YOLO over other object detection models. Its performance (measured in Mean average precision (mAP)), speed (In fps), and accuracy is better, while its computing cost is lower.
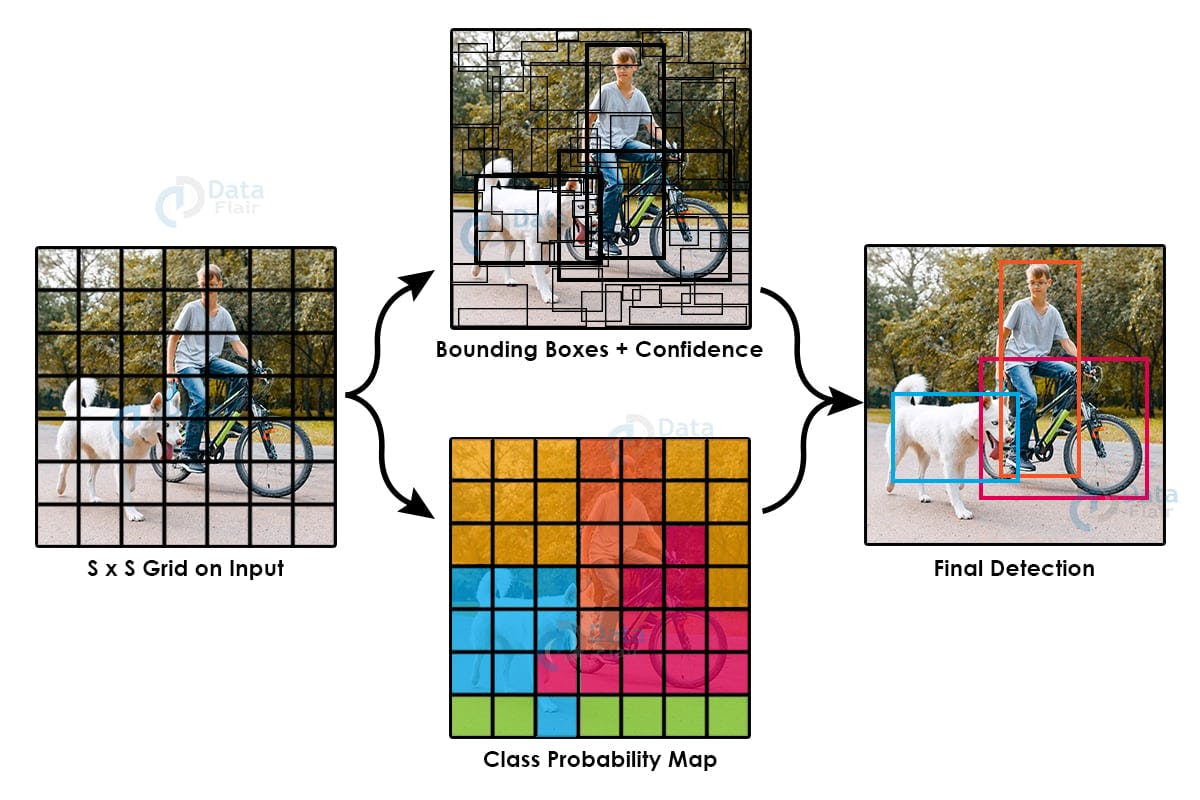
Custom Object Detection with YOLO V5
SSD: Single-shot Detector
Single-shot Detector (SSD) is another one-stage detector model that can identify and predict different classes and objects.
SSD uses a deep neural network (DNN), adapting the output spaces of bounding boxes in images and video frames and then generating scores for object categories in default boxes.
SSD has a high accuracy score, is easy to train, and can integrate with software and platforms that need an object detection feature. It was first developed and released in 2015 by academics and data scientists.
R-CNN: Region-based Convolutional Neural Networks
Region-based convolutional neural networks, or regions/models that use CNN features, known as R-CNNs, are innovative ways to use deep learning models for object detection.
An R-CNN selects several regions from an image, such as an anchor box. A pre-defined class of labels is given to the model first. It uses these to label the categories of objects in the images and other offsets, such as bounding boxes.
R-CNN models can also divide images into almost 2,000 region sections and then apply a convolutional neural network across every region in the image. R-CNN are two-stage models hence they display poor training speeds compared to YOLO, but there are other implementations, such as the fast and faster R-CNN, that improve on the efficiency.
The development of R-CNN models started in 2013, and one application of this approach is to enable object detection in Google Lens.
What’s Next?
As with any technological innovation, advances in object detection for computer vision continue to accelerate based on hardware, software, and algorithmic model developments.
Now, it’s easier for object detection or object recognition uses to be more widespread, mainly due to continuous advancements in AI imaging technology, platforms, software, open-source tools, and elaborate datasets like MS COCO and ImageNet. Computing power keeps increasing, with multi-core processor technology, AI accelerators, Tensor Processing Units (TPUs), and Graphical Processing Units (GPUs) supporting advances in computer vision.
Moreover, the performance improvements in processing units now allow complex models to be deployed on edge devices. For example, it’s easier to incorporate object detection onto mobile devices such as smart security cameras and smartphones.
This means smart devices can come per-built with object detection features, and users no longer need to worry about external processing power. Edge AI is making real-time object detection more affordable as a commercial application.

Object detection, as deployed for facial recognition.
Object Detection With Encord
Encord simplifies and enhances object detection in computer vision projects. Leverage Encord throughout the machine learning pipeline:
- Data Preparation: Encord provides comprehensive annotation tools and data analysis to ensure high-quality data preparation, with automation capabilities for time savings.
- Customize Annotation: Utilize Encord's customizable annotation toolkits to define annotation types, labels, and attributes, adapting to various object detection scenarios.
- Collaborate and Manage Annotators: Simplify annotator management with Encord, assigning tasks, monitoring progress, and ensuring annotation consistency and accuracy through collaborative features.
- Train and Evaluate Models: Effectively train and evaluate object detection models using Encord's properly annotated data, contributing to improved model performance. Analyze model performance within Encord's platform.
- Iterate and Improve: Continuously review and refine annotations using Encord's interactive dashboard, visualizing and analyzing annotated data and model performance to identify areas for enhancement.
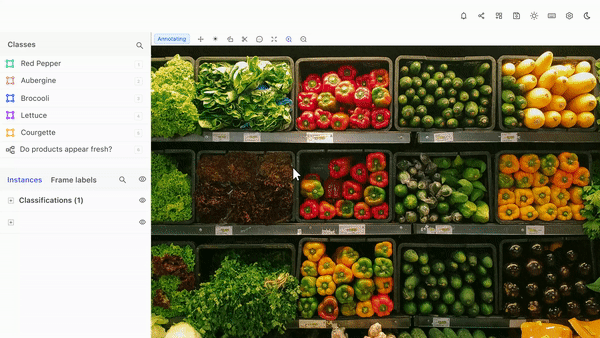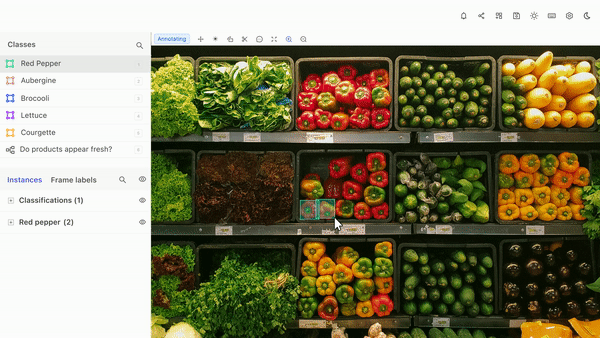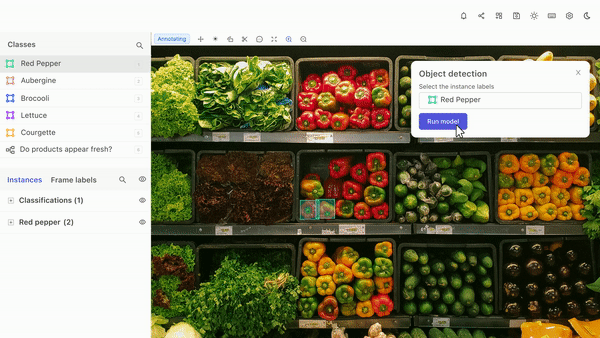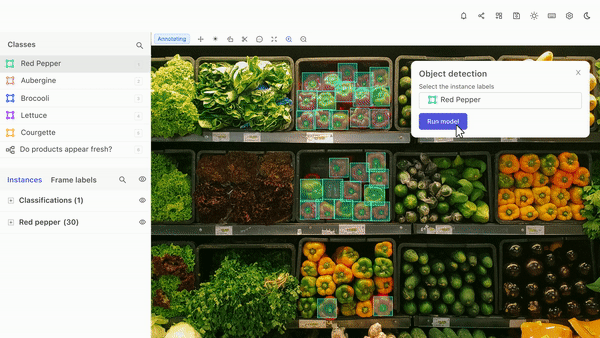
With Encord, the object detection process becomes more efficient and effective, leading to better results in computer vision projects.
Object Detection: Key Takeaways
- Object detection requires complex deep-learning architectures
- Models like R-CNN and YOLO are computationally efficient and present excellent results
- Object detection has various practical use-cases such as video surveillance and autonomous vehicles
- Development in computational hardware such as GPUs and TPUs has made model training easier
- High-performing hardware and efficient architectures have made it possible to deploy object detection on mobile devices for niche applications.
Frequently asked questions
Encord simplifies the process of creating datasets for object detection by allowing users to upload various media files and annotate them effectively. This ensures that crucial objects, such as helmets and vehicles, are accurately labeled for model training and evaluation.
Yes, Encord's annotation platform is equipped to handle segmentation and object detection tasks. This includes features for creating object-oriented bounding boxes, which can enhance the efficiency of training machine learning models by providing precise annotations.
Encord's object detection capabilities focus on identifying persons, vehicles, and safety cones within the operational environment of heavy machinery. This is critical for enhancing safety and operational efficiency in industries such as mining and construction.