The Full Guide to Automated Data Annotation

ML Lead at Encord
Automated data annotation accelerates the labeling of images, videos, and other data types using AI-powered tools, essential for training accurate computer vision and machine learning models. This guide explores the benefits, use cases, and best practices of automated annotation, including how tools like Encord streamline workflows, reduce costs, and improve data quality for scalable AI projects.
Automated data annotation is a way to use AI-assisted tools and software to accelerate and improve the quality of creating and applying labels to images and videos for computer vision models.
According to G2, "The market for AI-based automated data labeling tools is estimated to grow at a compound annual growth rate (CAGR) of over 30% by 2025".
Automated data annotations and labels greatly impact the accuracy, outputs, and results that algorithmic models generate. Therefore, research shows that 80% of major companies will need external assistance to complete the necessary data labeling tasks.
Artificial intelligence (AI), computer vision (CV), and machine learning (ML) models require high-quality and large quantities of annotated data, and the most cost-effective and time-effective way of delivering that is through automation.
Automated data annotation and labeling, normally using AI-based tools and software, makes a project run much smoother and faster. Compared to manual data labeling, automation can take manual, human-produced labels and apply them across vast datasets.
This guide covers everything from the different types of automated data labeling, use cases, best practices, and how to implement automated data annotation more effectively with tools such as Encord.

What is Data Annotation?
Data annotation (or data labeling) is the task of labeling objects for machine learning algorithms in datasets, such as images or videos. As we focus on automation, AI-supported data labeling, and annotation for computer vision (CV) models, we will cover image and video-based use cases in this article.
However, you can use automated data annotation and labeling for any ML project, such as audio and text files for natural language processing (NLP), conversational AI, voice recognition, and transcription.
Data annotation maps the objects in images or videos against what you want to show in a CV model. Annotations and labels describe the objects in a dataset, including contextual information.
Every label and annotation applied to a dataset should be aligned with a project's outcome, goals, and objectives. ML and CV models are widely used in dozens of sectors, with hundreds of use cases, including medical and healthcare, manufacturing, and satellite images for environmental and defense purposes.
Labels are an integral part of the data that an algorithmic model learns. Quality and accuracy are crucial. If you put poor-quality data in, you’ll get inaccurate results.

There are several ways to implement automated data annotation, including supervised, semi-supervised, in-house, and outsourcing.
Now, let’s dive into how annotation, ML, and data ops teams can automate data annotation for computer vision projects.
How to Automate Data Annotation
Manual tasks, including data cleaning, annotation, and labeling, are the most time-consuming part of any computer vision project. According to Cognilytica, preparation absorbs 80% of the time allocated for most CV projects, with annotation and labeling consuming 25%.
Automating data annotation tasks with AI-based tools and software greatly affects the time it takes to get a model production-ready.
AI-supported data labeling is quicker, more efficient, cost-effective, and reduces manual human errors. However, picking the right AI-based tools is essential.
As ML engineers and data ops leaders know, dozens of options are available, such as open-source, low-code and no-code, and active learning annotation solutions, toolkits, and dashboards, including Encord.
There are also several ways you can implement automated data annotation to create the training data you need, such as:
- Supervised learning;
- Unsupervised learning;
- Semi-supervised learning;
- Human-in-the-Loop (HITL);
- Programmatic data labeling.
We compare those in this article in more detail.
Now, let’s consider one of the most important questions many ML and data ops leaders need to review before they start automating data annotation: “Should we build our own tool or buy?”
Build vs. Buy Automated Data Annotation Tools
Building an in-house tool takes 6 to 18 months ⏤ and usually costs anywhere in the 6 to 7-figure range. Even if you outsource the development work, it’s a resource-hungry project.
Plus, you’ve got to factor in things like, “What if we need new features/updates?”, maintenance, and integration with up and downstream tools like those for managing data and evaluating models.
The number of features and tools you’ll need correlates to the volume of data a tool will process, the number of annotators, and how many projects an AI-based tool will handle in the months and years ahead.
On the other hand, buying an out-of-the-box solution means you could be up and running in hours or days rather than 6 to 18 months. In almost every case, it’s simply more time- and cost-effective.
Plus, you can select a tool based on your use case and data annotation and labeling needs rather than any limitations of in-house engineering resources.


Different Types of Automated Data Annotation in Computer Vision
Computer vision uses machine learning models to extract commercial and real-world outputs and insights from image and video-based datasets.
Some of the most common automated data annotation tasks in computer vision include:
- Image annotation;
- Video annotation;
- DICOM and medical image or video annotation.
Let’s explore all three in more detail.
Image Annotation
Image annotation is an integral part of any image-based computer vision model. Especially when taking the data-centric AI approach or using an active learning pipeline to accelerate a model’s iterative learning.
Although not as complex as video annotation, applying labels to images is more complex than many realize.
Image annotation is the manual or AI-assisted process of applying annotations and labels to images in a dataset. You can accelerate this process with the right tools, improving a project's workflow and quality control.
Video Annotation
Video annotation is more complex and nuanced than image annotation and usually needs specific tools to handle native video file formats.
Videos include more layers of data, and with the right video annotation tools, you ensure labels are correctly applied from one frame to the next. Sometimes, an object might be partially obscured or contain occlusions, and an AI-based tool is needed to apply the right labels to those frames.
For more information, check out our guide on the 5 features you need in a video annotation tool.

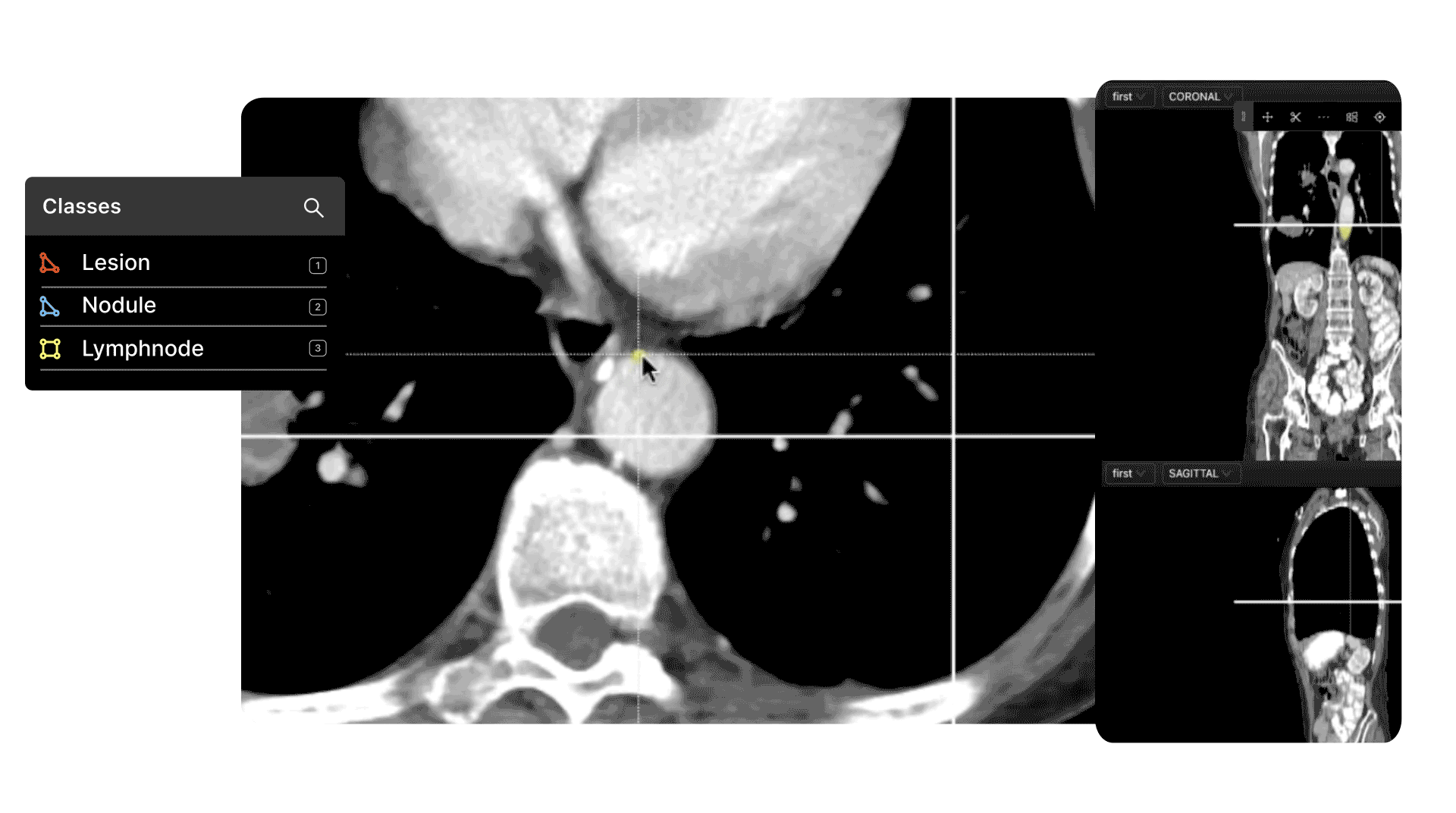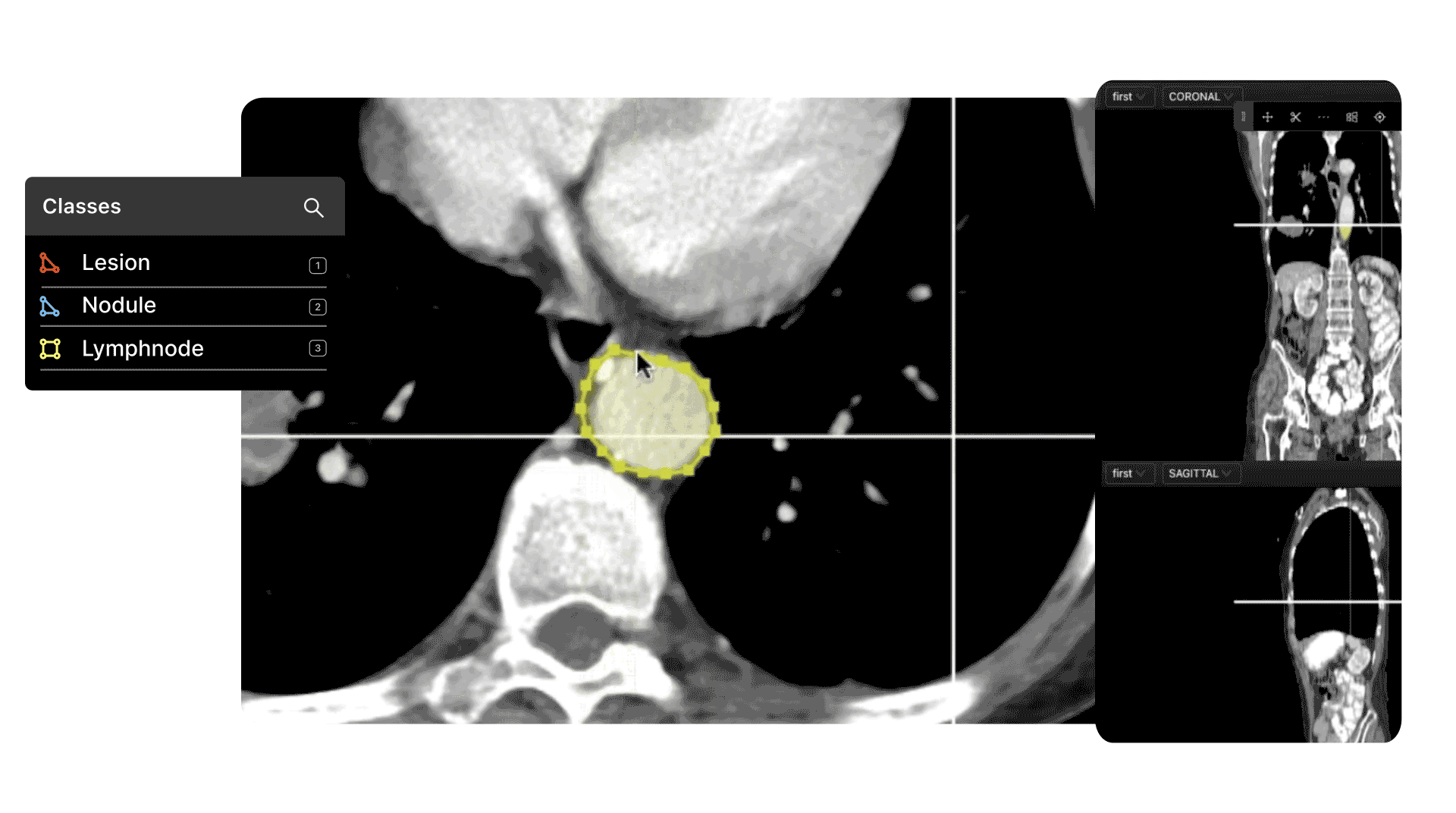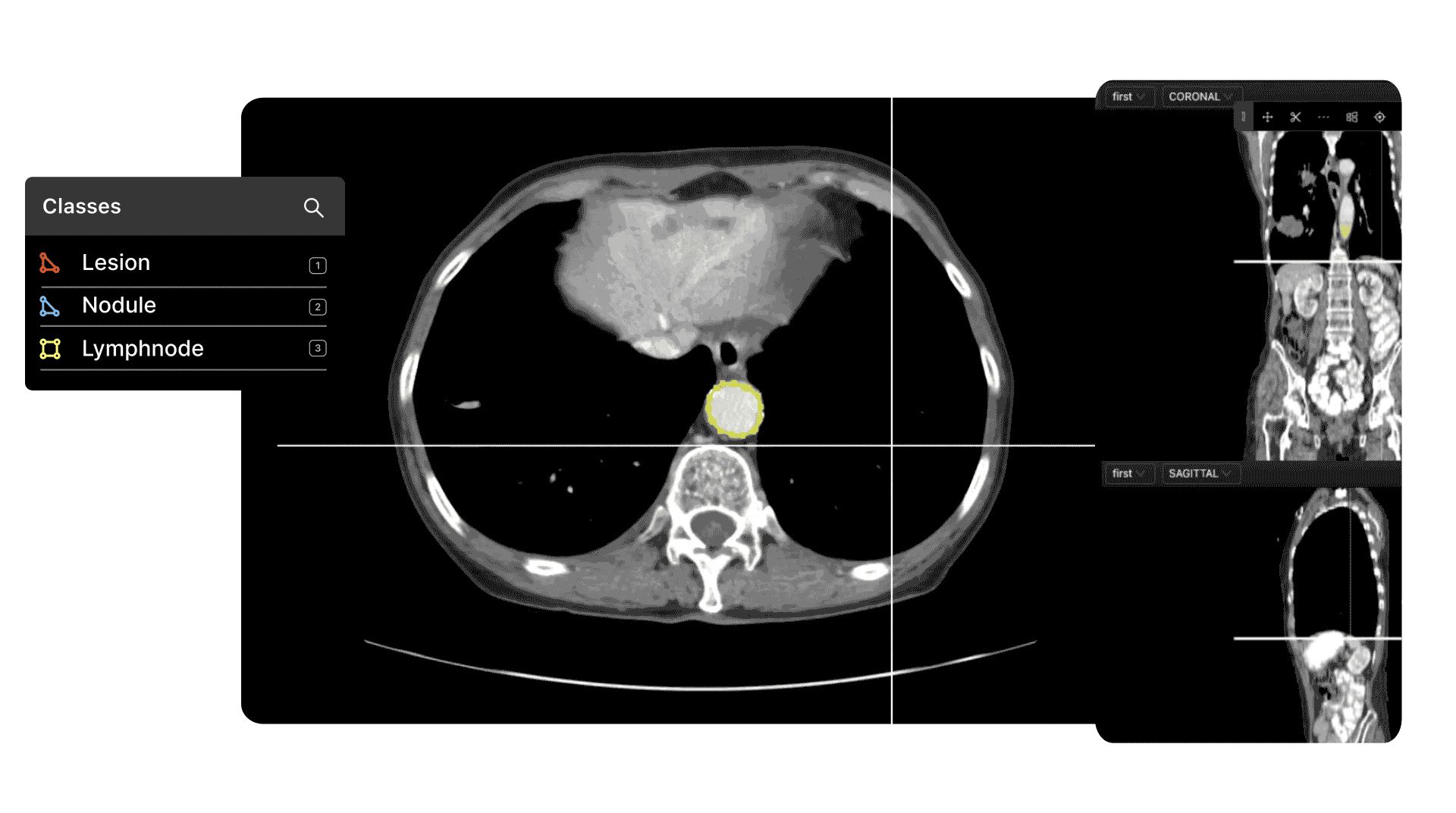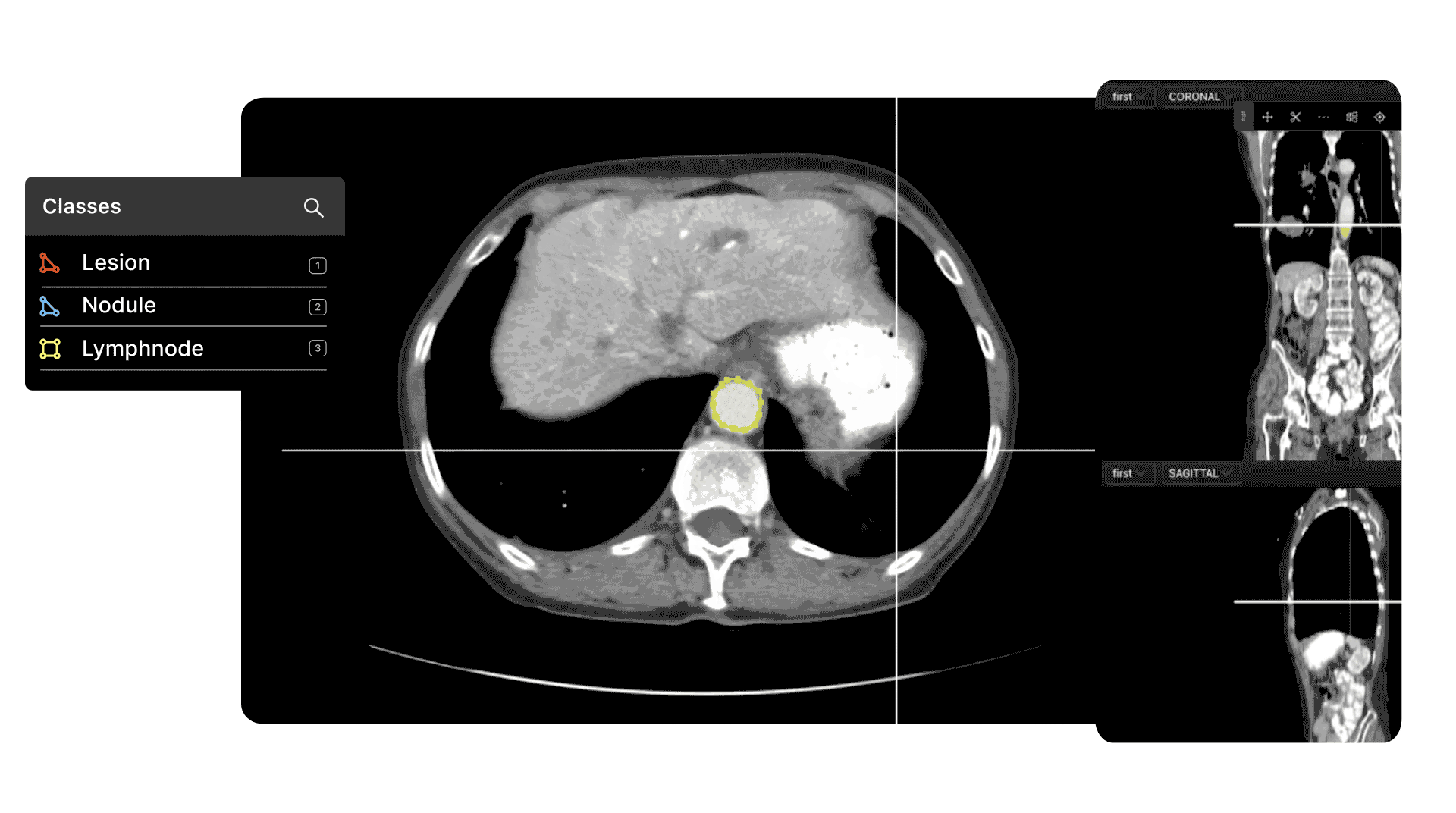
DICOM and Medical Image/Video Annotation
Medical image file formats, such as DICOM and NIfTI, are even more complex and nuanced than images or even videos in many ways.
The most common use cases in healthcare for automated computer vision medical image and video annotation include pathology, cancer detection, ultrasound, microscopy, and numerous others.
The accuracy of an AI-based model depends on the quality of the annotations and labels applied to a dataset. To achieve this, you need human annotators with the right skills and tools to easily handle dozens of medical image file formats.
In most cases, especially at the pre-labeling and quality control stage, you need specialist medical knowledge to ensure the right labels are correctly created and applied. High levels of precision are essential, with most projects having to pass various FDA guidelines.
As for data security, and data compliance, any tool you use needs to adhere to security best practices such as SOC 2 and HIPAA (the Health Insurance Portability and Accountability Act). Project managers need granular access to every stage of the data annotation and labeling process to ensure that annotators do their job well.
With the right tool, one designed with and alongside medical professionals and healthcare data ops teams, all of this is easier to implement and guarantee.
Find out more with our best practice guide for annotating DICOM and NIfTI Files.
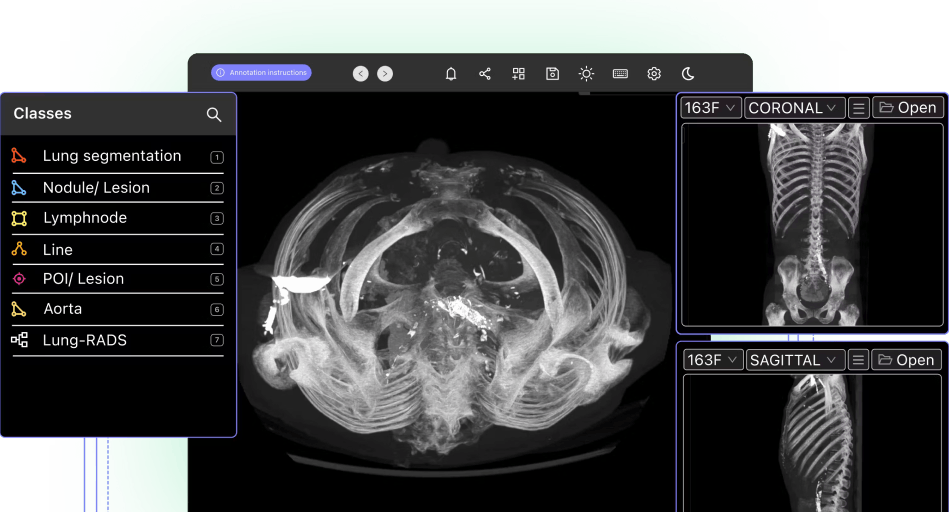

Benefits of Automated Data Annotation
Automated data annotation and labeling for computer vision and other algorithmic-based models include the following:
Cost-effective
Manually annotating and labeling large datasets takes time. Every hour of that work costs money. In-house annotation teams are more expensive.
But outsourcing isn’t cheap either, and then you’ve got to consider issues such as data security, data handling, accuracy, expertise, and workflow processes. All of this has to be factored into the budget for the annotation process.
With automated, AI-supported data annotation, a human annotation team can manually label a percentage of the data and then have an AI tool do the rest.
And then, whichever approach you use for managing the annotation workflow ⏤ unsupervised, supervised, semi-supervised, human-in-the-loop, or programmatic ⏤ annotators and quality assurance (QA) team members can guide the labeling process to improve accuracy and efficiency.
Either way, it’s far more cost-effective than manually annotating and labeling an entire dataset.
Faster annotation turnaround time
Speed is as important as accuracy. The quicker you start training a model, the sooner you can test theories, address bias issues, and improve the AI model.
Automated data labeling and annotation tools will give you an advantage when training an ML model. Ensuring a faster and more accurate annotation turnaround time so that models can go from training to production-ready more easily.
Consistent and objective results
Humans make mistakes. Especially if you’re performing the same task for 8 or more hours. Data cleaning and annotation is time-consuming, and the risk of errors or bias creeping into a dataset and, therefore, into ML models increases over time.
With AI-supported tools, human annotator workloads aren’t as heavy. Annotators can take more time and care to get things right the first time, reducing the number of errors that must be corrected. Applying the most suitable, accurate, and descriptive labels for the project's use case and goals manually will improve the automated process once an AI tool takes over.
Results from data annotation tasks are more consistent and objective with the support of AI-based software, such as active learning pipelines and micro-models.
Increased productivity and scalability
Ultimately, automated annotation tools and software improve the team's productivity and make any computer vision project more scaleable. You can handle larger volumes of data, annotate, and label images and videos more accurately.
Which Label Tasks Can I Automate?
With the right automated labeling tools, you should be able to easily automate most data annotation tasks, such as classifying objects in an image. The following is a list of data labeling tasks that an AI-assisted automation software suite can help you automate for your ML models:
- Bounding boxes: Drawing a box around an object in an image and video and then labeling that object. Automation tools can then detect the same or similar object(s) in other images or frames of videos within a dataset.
- Object detection: Using automation to detect objects or semantic instances of objects in videos and images. Once annotators have created labels and ontologies for objects, an AI-assisted tool can detect those objects accurately throughout a dataset.
- Image segmentation: In a way, this is more detailed than detection. Segmentation can reach the granular, pixel-based level within images and videos. With segmentation, a label or mask is applied to specific objects, instances, or areas of an image or video. Then AI-assisted tools can identify identical collections of pixels and apply the correct labels throughout a dataset.
- Image classification: A way of training a model to identify a set of target classes (e.g., an object in an image) using a smaller subset of labeled images. Classifying images is a process that can also include binary or multi-class classification, where there’s more than one label/tag for an object).
- Human Pose Estimation (HPE): Tracking human movements in images or videos is a computer-intensive task. HPE tracking tools make this easier, providing images or videos of human movement patterns that have been labeled accurately and in enough detail.
- Polygons and polylines: Another way to annotate and label images is by drawing lines around static or moving objects in images and videos. Once enough of these have been applied to a subset of data (automated tools can implement those same labels accurately across an entire dataset.
- Keypoints and primitives: Also known as skeleton templates, these are data-labeling methods to templatize specific shapes, such as 3D cuboids and the human body.
- Multi-Object Tracking (MOT): A way to track multiple objects from frame to frame in videos. With automated labeling software, MOT becomes much easier, providing the right labels are applied by annotation teams, and a QA workflow keeps those labels accurate across a dataset.
- Interpolation: Another way to use data automation to fill in the gaps between keyframes in videos.
- Auto object segmentation and detection, including instance segmentation and semantic segmentation, perform a similar role to interpolation.
Now, look at the features you need in an automated data annotation tool and best practices for AI-assisted data labeling.
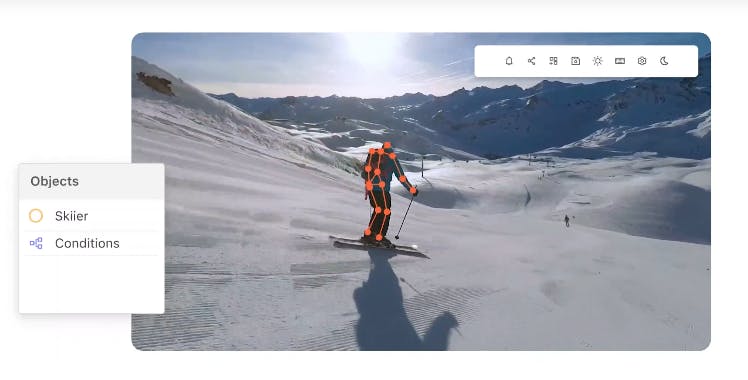
(Source)
What Features Do You Need in an Automated Data Annotation Tool?
Here are 7 features to look for in an automated data annotation tool.
Supports Model or AI-Assisted Labeling
Naturally, if you’ve decided that your project needs an automated tool, you must pick one that supports model or AI-assisted labeling.
Assuming you’ve resolved the “buy vs. build” question and are opting for a customizable SaaS platform rather than open-source, then you’ve got to select the right tool based on the use case, features, reviews, case studies, and pricing.
Make a checklist of what you’re looking for first using a checklist app. That way, data ops and ML teams can provide input and ideas for the AI-assisted labeling features a software solution should have.
Supports Different Types of Data & File Formats
Equally crucial is that the solution you pick can support the various file types and formats you’ll find in the datasets for your project.
For example, you might need to label and annotate 2D and 3D images or more specific file formats, such as DICOM and NIfTI, for healthcare organizations.
Depending on your sector and use case, you might even need a tool to handle Synthetic-Aperture Radar (SAR) images in various modes for computer vision applications.
Ensure every base is covered and that the tool you pick supports images and videos in their native format without any issues (e.g., needing to reduce the length of videos).
Easy-to-Use Tool With a Collaborative Dashboard
Considering the number of people and stakeholders usually involved in computer vision projects, having an easy-to-use labeling tool with a collaborative dashboard is essential.
Especially if you’ve outsourced the annotation workloads. With the right labeling tools, you can keep everyone on the same page in real time while avoiding mission creep.

Data Privacy and Security
DataOps teams must consider data privacy and security when sourcing image or video files for a computer vision project. In particular, whether there are any personally identifiable data markers or metadata within images or videos in datasets. Anything like that should be removed during the data cleaning process.
Afterwards, you must make the right provisions for moving and storing the datasets. Especially if you’re in a sector with more stringent regulatory requirements, such as healthcare. You need to get this right if you’re outsourcing data annotation tasks. Only then can you move forward with the annotation process.
Comprehensive platforms ensure you can maintain audit and security trails to demonstrate data security compliance with the relevant regulatory bodies.
Automated Data Pipelines
When a project involves large volumes of data, an easier way to automate data pipelines is to connect datasets and models using Encord’s Python SDK and API. This way, it’s even easier and faster to train an ML model continuously.
Customizable Quality Control Workflows
Make quality control (QC) or QA workflows customizable and easily managed. Validate labels and annotations being created. Check that the annotation teams are applying them correctly. Reduce errors and bias, and fix bugs in the datasets.
You can automate this process using the right tool to check the AI-assisted labels applied from start to finish.
Training Data and Model Debugging
Every training dataset includes errors, inaccuracies, poorly-labeled images or video frames, and bugs. Pick an automated annotation tool that will help you fix those faster.
Include this in your quality control workflows so annotators can correct mistakes and resubmit reformatted images or videos to the training datasets.

Automated Data Annotation Best Practices
Now let’s take a quick look at some of the most efficient automated data annotation best practices.
Develop Clear Annotation Guidelines
In the same way that ML models can’t train without accurately labeled data, annotation teams need guidelines before they start work. Create these guidelines and standard operating procedure (SOP) documents with the tool they’ll be using in mind.
Align annotation guidelines with the product’s features and functionality and your organization's in-house data best practices and workflows.
Design an Iterative Annotation Workflow
Using the above as your process, incorporate an iterative annotation workflow. So this way, there are clear steps for processing data, fixing errors, and creating the right labels and annotations for the images and videos in a dataset.
Manage Quality Assurance (QA) and Feedback via an Automated Dashboard
In data-centric model training, quality is mission-critical. No project gets this completely right, as MIT research has found that even amongst best-practice benchmark datasets, at least 3.4% of labels are inaccurate.
However, with a collaborative automated dashboard and expert review workflows, you can reduce the impact of common quality control headaches, such as inaccurate, missing, mislabeled images or unbalanced data, resulting in bias or insufficient data for edge cases.
Read Also: 5 ways to improve the quality of your labeled data.
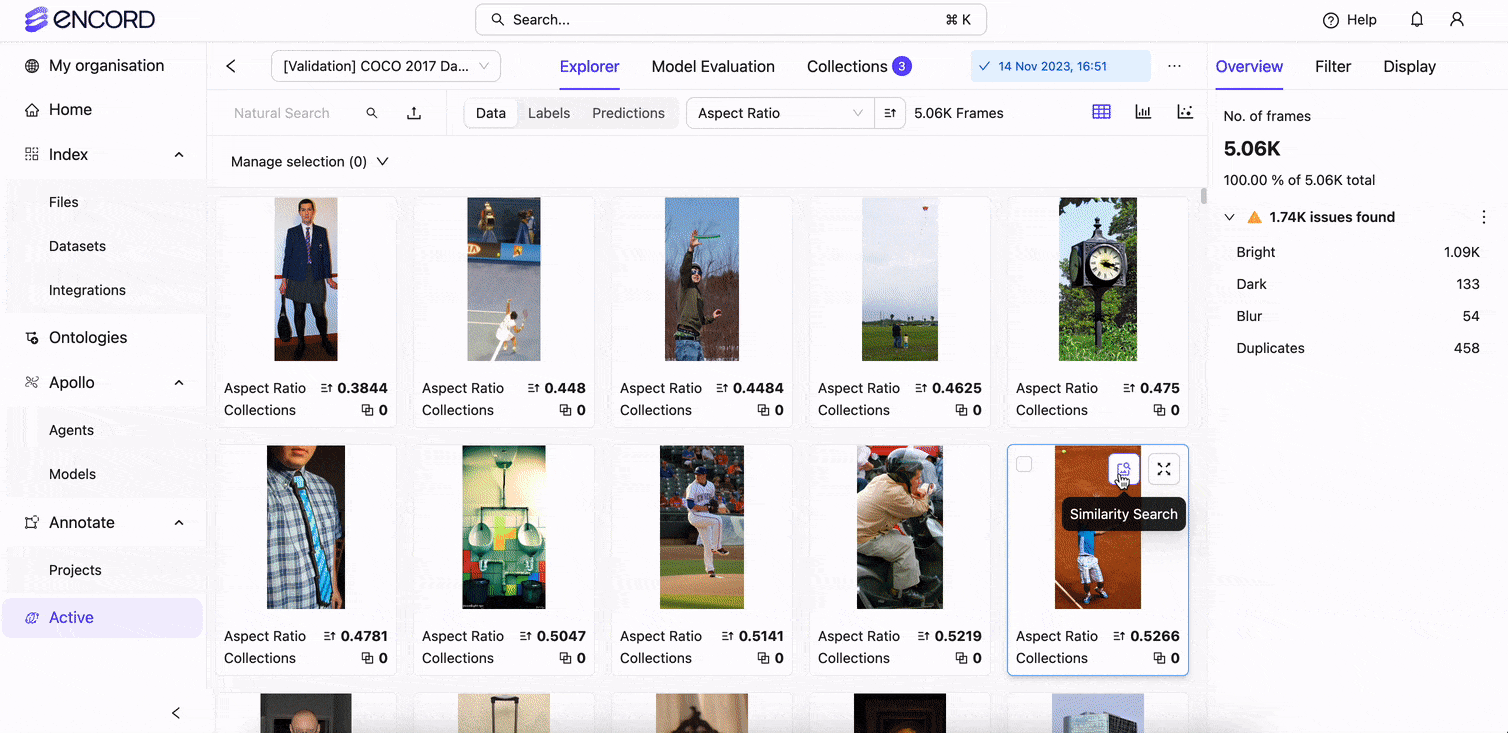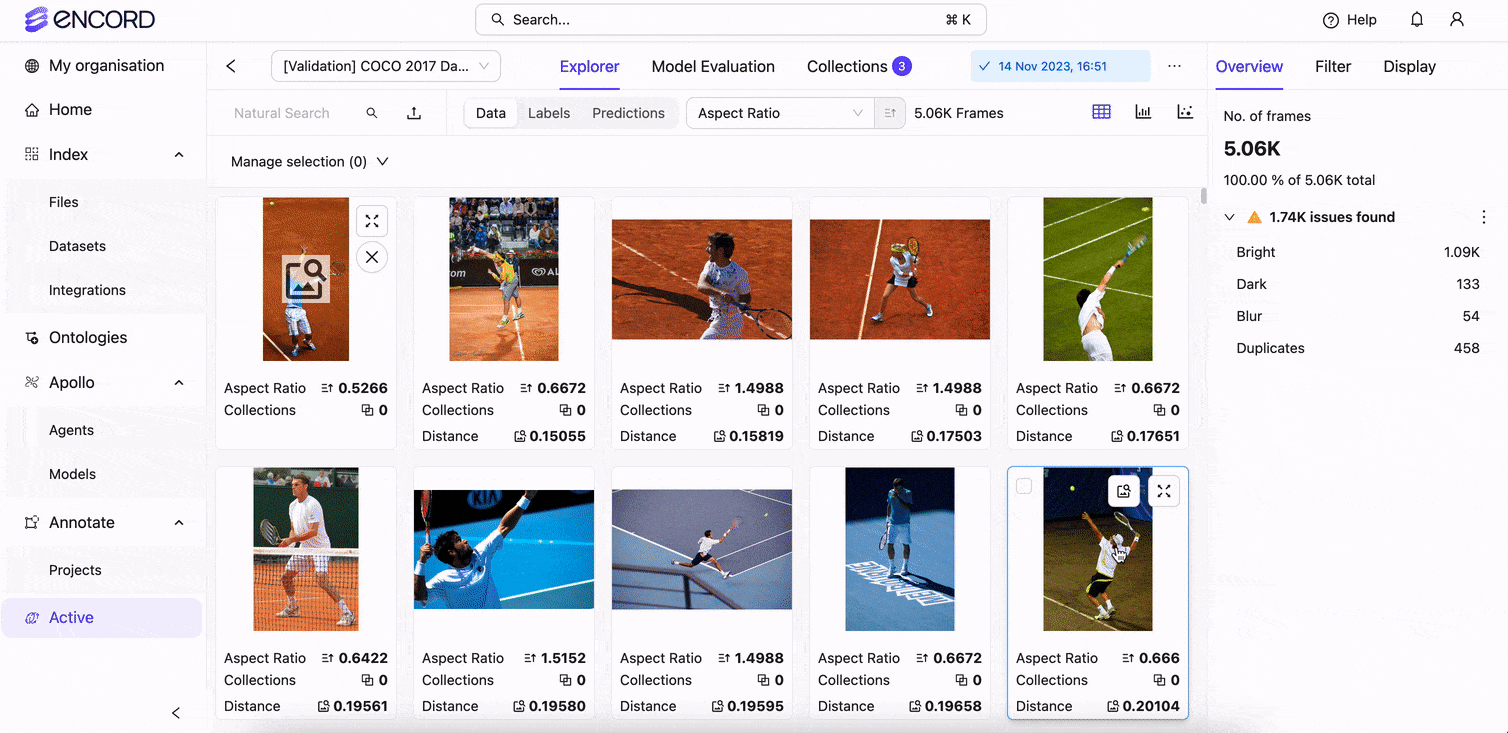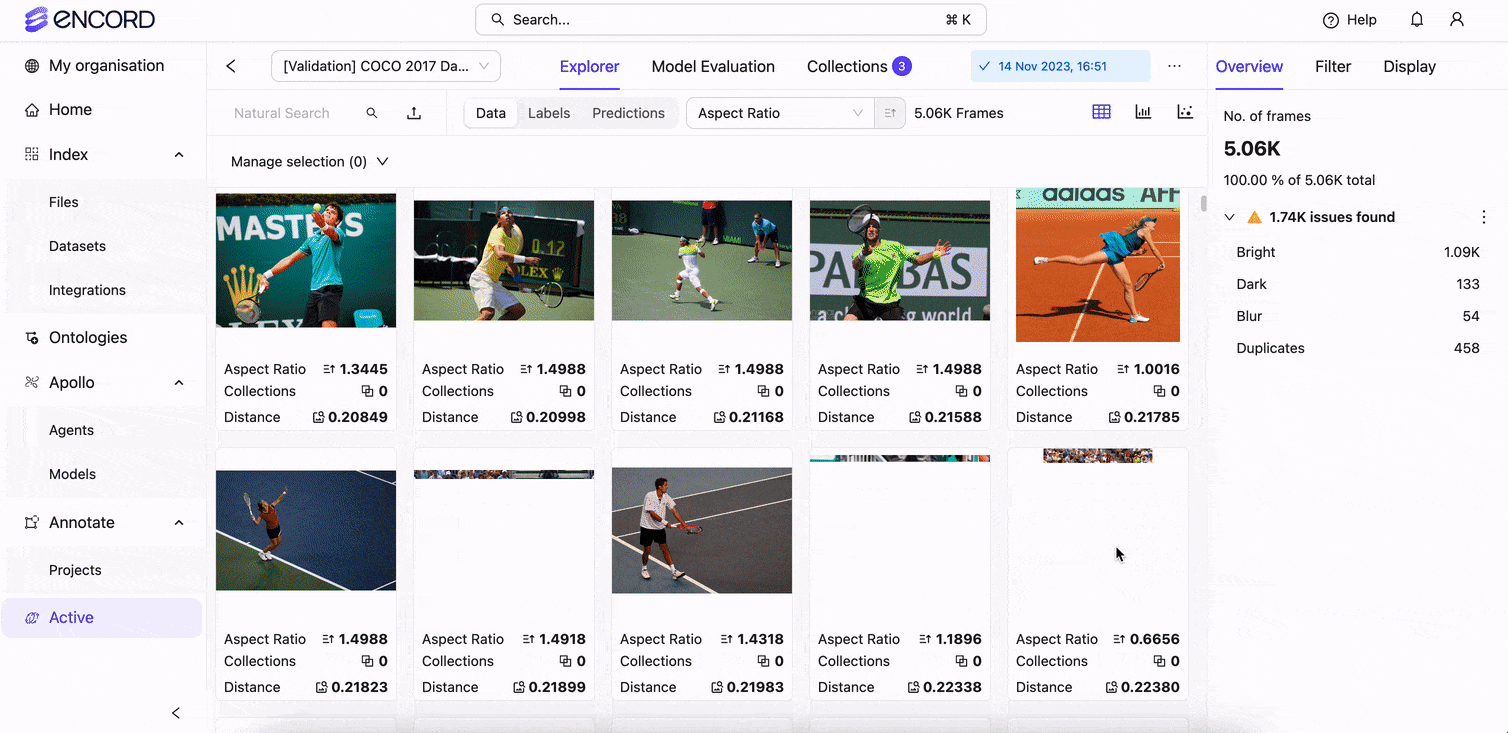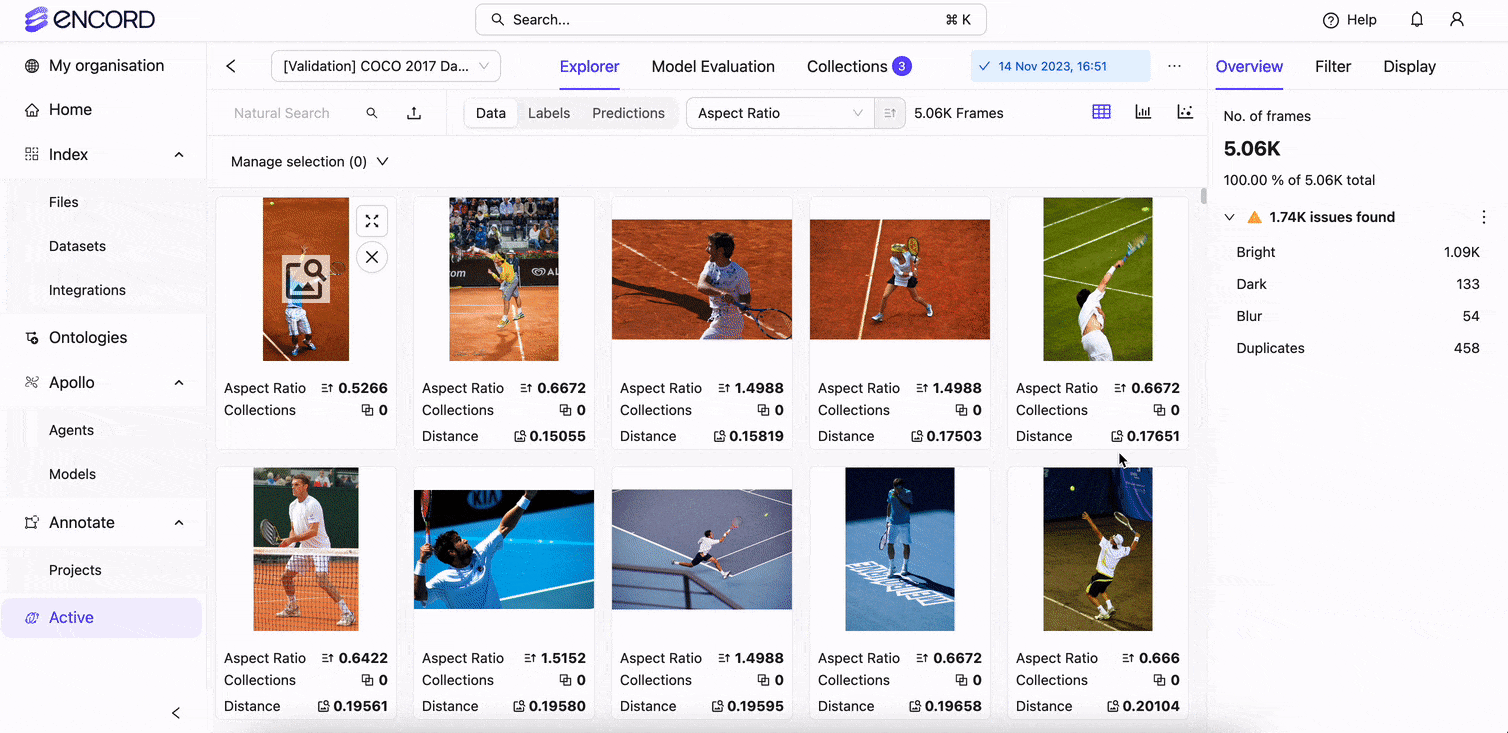
Automated Data Annotation With Encord
With Encord Annotate, Index, and Active, automated tools used by world-leading AI teams, you can accelerate data labeling workflows more effectively, securely, and at scale.
Encord was created to improve the efficiency of automated image and video data labeling for computer vision projects. Our solution also makes managing a team of annotators easier, takes more time, and is cost-effective while reducing errors, bugs, and bias. With Encord, you can achieve production AI faster with ML-assisted labeling, training, and diagnostic tools to improve quality control, fix errors, and reduce dataset bias.
Make data labeling more collaborative, faster, and easier to manage with an interactive dashboard and customizable annotation toolkits. Improve the quality of your computer vision datasets with Encord Index and enhance model performance with Active.
Key Takeaways
AI, ML, and CV models need high-quality and a large volume of accurately labeled and annotated data to train, learn, and go into production.
It takes time to source, clean, and annotate enough data to reach the training stage. Automation, using AI-based tools, accelerates the preparation process.
Automated data labeling and annotation reduce the time involved in one of the most crucial stages of any computer vision project. Automation also improves quality, accuracy, and the application of labels throughout a dataset, saving you time and money.
Ready to accelerate the automation of your data annotation and labeling?

Frequently asked questions
AI and ML models require high-quality, accurately labeled datasets to train effectively. Automation enhances the speed and consistency of annotations, ensuring better model performance while reducing the time and cost associated with manual labeling.
Automated tools can handle various data types, including:
Images (bounding boxes, segmentation, keypoints)
Videos (multi-object tracking, interpolation)
Medical imaging formats like DICOM and NIfTI
Building an in-house tool can be resource-intensive, requiring 6–18 months and significant financial investment. Buying a customizable solution, like Encord, is faster, cost-effective, and allows you to focus on your project goals without worrying about tool development and maintenance.
Automated annotation provides several advantages:
Cost-Effectiveness: Reduces reliance on large manual annotation teams.
Speed: Shortens the time needed to prepare datasets.
Consistency: Ensures objective and uniform labeling.
Scalability: Handles larger datasets more efficiently.
Encord incorporates automation features that can help streamline the annotation process, making it easier and faster for users to generate high-quality labeled datasets. These features can assist in pre-labeling data and managing workflows efficiently, which is particularly beneficial for large-scale projects.
Encord provides a pre-labeling feature that allows users to automate the initial pass of annotations. This capability is particularly beneficial given the increasing volume of data annotation, as it helps streamline the process and enhance overall efficiency before human review and finalization.
Encord enhances efficiency through its streamlined annotation processes and intuitive tools that reduce the laborious nature of data labeling. By automating repetitive tasks and providing robust collaboration features, teams can significantly speed up their workflow and focus on model training.
Encord allows users to seamlessly sync their custom machine learning models with the platform. This integration enables users to utilize their developed models for auto labeling tasks, ensuring that the annotation process is efficient and tailored to their specific data requirements.
Yes, Encord provides an anti-training module that helps identify and block suspicious behavior from annotators producing low-quality data. This feature allows teams to implement probationary measures and retraining flows, automating the process of maintaining annotation quality.
Yes, Encord allows users to automate the filtering process using both simple and complex preset filters. This feature helps in narrowing down the data set based on specific criteria, making it easier to identify items that should be sent for annotation.
Encord's annotation platform utilizes both human and machine learning models in the loop to annotate data across different modalities. It also features intelligent workflows that enhance the annotation process, improving efficiency and accuracy.
Encord allows users to combine human annotations with automated processes, such as speech-to-text, to create a comprehensive dataset. This hybrid approach ensures higher quality data while reducing the reliance on manual annotation.
Yes, Encord is designed to automate various data annotation tasks, significantly reducing the need for writing custom scripts. This feature allows teams to focus on higher-level project work rather than manual data management.
Encord offers an easy-to-use SDK that allows clients to build custom pre-labeling agents. This feature streamlines the data annotation process and enhances productivity by enabling teams to automate parts of their workflows.