SegGPT: Segmenting everything in context [Explained]

Product Manager at Encord
Every year, CVPR brings together some of the brightest engineers, researchers, and academics from across the field of computer vision and machine learning.
The last month has felt like inching closer and closer to a GPT-3 moment for computer vision – and a handful of the new CVPR 2023 submissions seem o
Following last month’s announcement of ‘Painter’ (submission here) – the BAAI Vision team published their latest iteration last week with “SegGPT: Segmenting Everything In Context” (in Arxiv here).
In it, the BAAI team – made up of Xinlong Wang, Xiaosong Zhang, Tue Cao, Wen Wang, Chunhua Shen and Tiejun Huang – present another piece of the computer vision challenge puzzle: a generalist model that allows for solving a range of segmentation tasks in images and videos via in-context inference.
In this blog post you will:
- Understand what SegGPT is and why it’s worth keeping an eye on.
- Learn how it fares compared to previous models.
- See what’s inside SegGPT: its network architecture, design, and implementation.
- Learn potential uses of SegGPT for AI-assisted labelling.
Update: Do you want to eliminate manual segmentation? Learn how to use foundation models, like SegGPT and Meta’s Segment Anything Model (SAM), to reduce labeling costs with Encord! Read the product announcement, how to fine-tune SAM or go straight to getting started!
How does SegGPT compare to previous models?
As a foundation model, SegGPT is capable of solving a diverse and large number of segmentation tasks when compared to specialist segmentation models that solve very specific tasks such as foreground, interactive, semantic, instance, and panoptic segmentation. The issue with existing models is that switching to a new mode, or segmenting objects in videos rather than images, requires training a new model. This is not feasible for many segmentation tasks and necessitates expensive annotation efforts.
From the paper and released demo, SegGPT demonstrates strong abilities to segment in and out-of-domain targets, either qualitatively or quantitatively. SegGPT outperforms other generalist models in one-shot and few-shot segmentation with a higher mean Intersection Over Union (mIoU) score when compared to other generalist models like Painter and specialist networks like Volumetric Aggregation with Transformers (VAT).
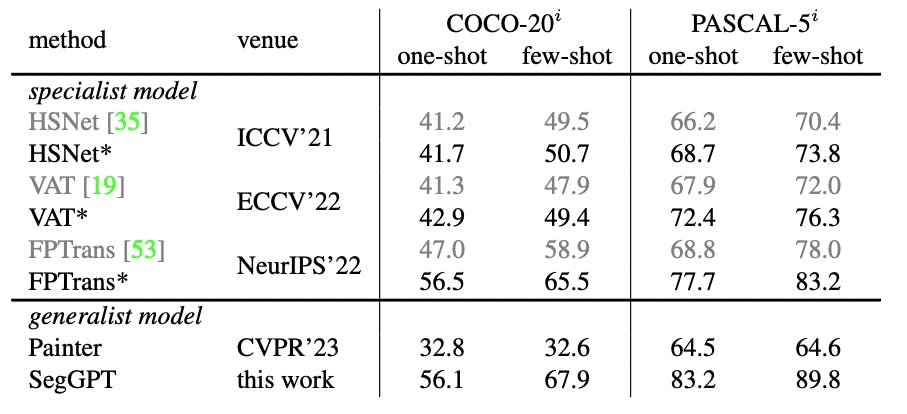
The benchmark datasets the researchers used to train, assess, and compare the performance quantitatively were COCO-20i and PASCAL-5i.
The researchers also tested the model on the FSS-1000, which it had not been trained on. It was also able to out-perform Painter with a higher mIoU on one-shot and few-shot segmentation tasks, and closer performance to specialized networks like Democratic Attention Networks (DAN) and Hypercorrelation Squeeze Networks (HSNet).
SegGPT also provides good in-context video segmentation and outperforms task-specific approaches like AGAME and foundation models like Painter by significant margins on YouTube-VOS 2018, DAVIS 2017, and MOSE datasets.
How does SegGPT work in practice?
SegGPT builds on the Painter framework. Painter is a generalist model that redefines the output of core vision tasks as images and specifies task prompts as also being images. According to the paper, there are two highlights of the Painter framework that make it a working solution for in-context image learning:
- Images speak in images: Output spaces of vision tasks are redefined as images. The images act as a general-purpose interface for perception allowing models to adapt to various image-centric tasks with only a handful of prompts and examples.
- A “generalist painter”: Given an input image, the prediction is to paint the desired but missing output "image".
The SegGPT team took the following approaches to training:
- including part, semantic, instance, panoptic, person, medical image, aerial image, and other data types relevant to a diverse range of segmentation tasks.
- To design a generalizable training scheme that differs from traditional multi-task learning, is flexible on task definition, and can handle out-of-domain tasks.
SegGPT can segment various types of visual data by unifying them into a general format. The model learns to segment by coloring these parts in context, using a random color scheme that forces it to use contextual information rather than relying on specific colors to improve its generalization capability.
This makes the model more flexible and able to handle various segmentation tasks. The training process is similar to using a vanilla ViT model with a simple smooth-ℓ1 loss function.
SegGPT Training Scheme
To improve generalizability, the SegGPT network architecture follows three approaches:
- In-context coloring; using random coloring schemes with mix-and-match so the model learn relationship between masked and not just the colours.
- Context ensembling; using ensembling approaches to improve tightness of the masks.
- In-context tuning; optimizing the learnable image tensors that serve as input context to the model to, again, improve generalizability to different segmentation tasks.
In-Context Coloring
The model uses a random coloring scheme to enable in-context color learning of the input images to avoid the problem of the network solely learning colors without understanding the relationship between segmented objects. This is one of the reasons the network outperforms the Painter network in terms of generalizability and the tightness of bounding boxes.
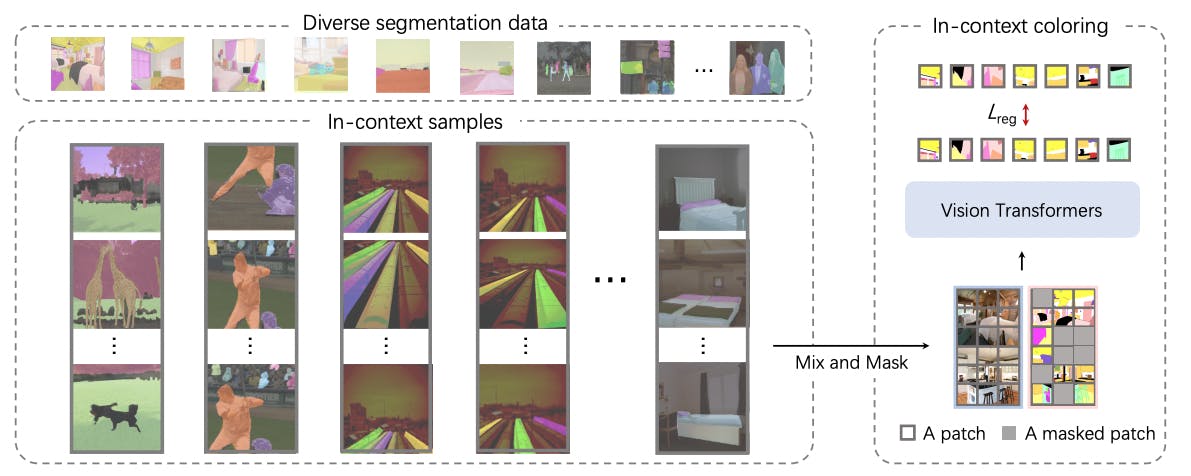
The researchers also employed a "mix-context" training technique, which trains the model using various samples. This entails using the same color mapping to stitch together multiple images. The image is then randomly resized and cropped to create a mixed-context training sample. As a result, the model gains the ability to determine the task by focusing on the image's contextual information rather than just using a limited set of color information.
Context Ensembling
To improve accuracy, the research uses two context ensemble approaches:
- Spatial Ensemble to concatenate multiple examples in a grid and extract semantic information.
- Feature Ensemble to combine examples in the batch dimension and average features of the query image after each attention layer.
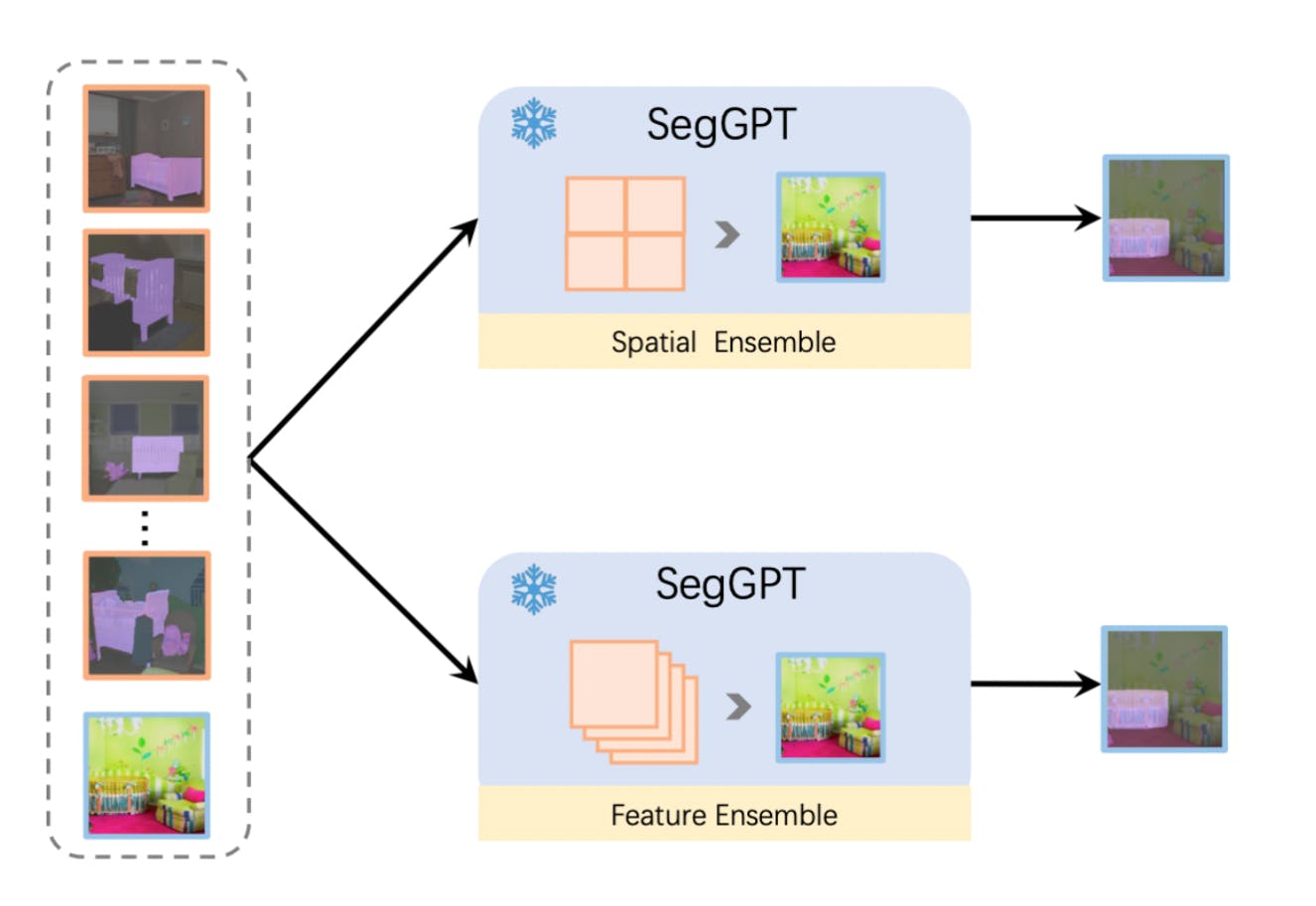
This allows the model to gather information about multiple examples during inference and provide more accurate predictions.
In-Context Tuning
SegGPT can adapt to a unique use case without updating the model parameters. Instead, a learnable image tensor is initialized as the input context and updated during training, while the rest remains the same.
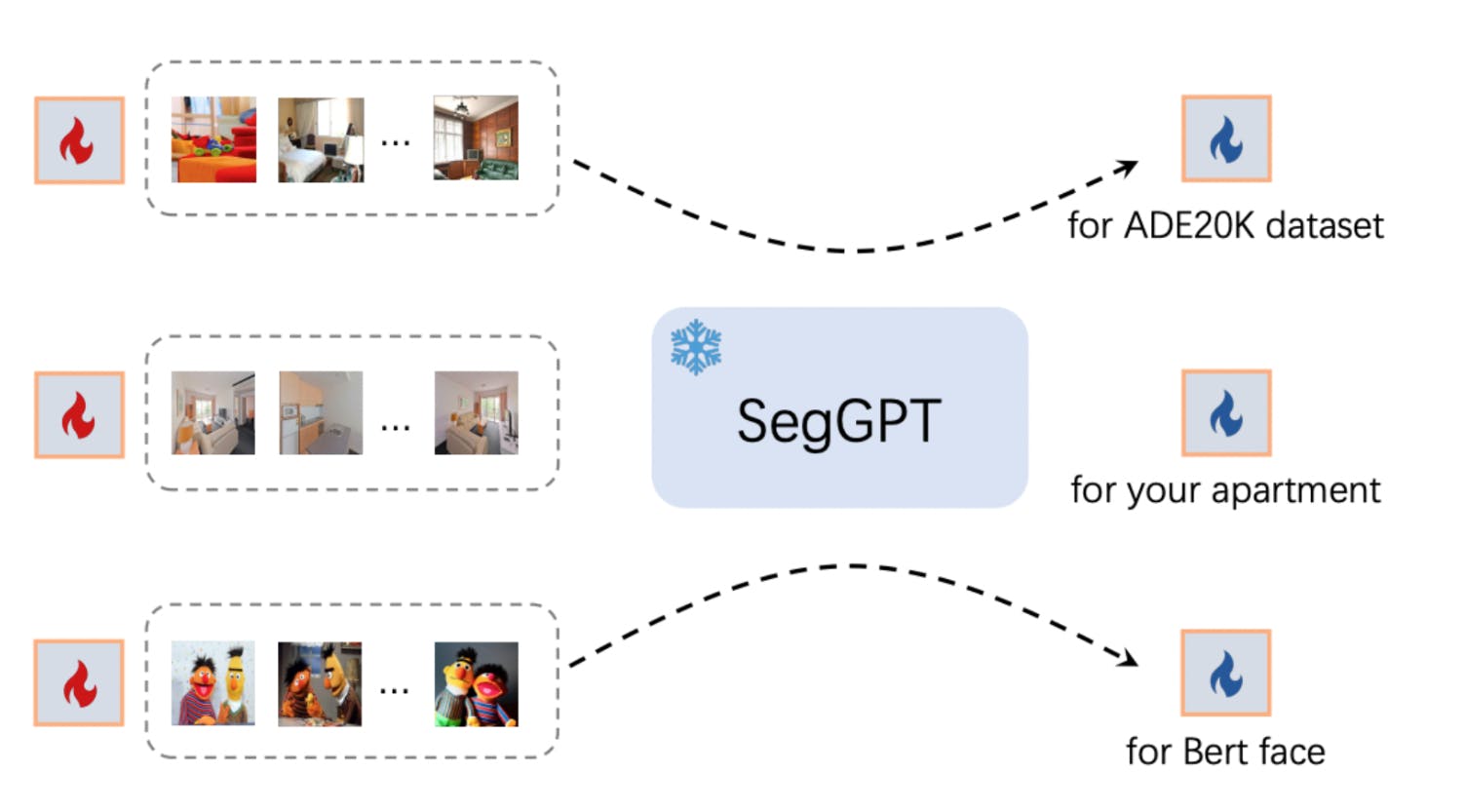
The learned image tensor can be a key for a specific application. This allows for customized prompts for a fixed set of object categories or optimization of a prompt image for a specific scene or character, providing a wide range of applications.
SegGPT Training Parameters
For the training process, the researchers used pre-trained Vision Transformer encoder (ViT-L) with 307M parameters. They also used an AdamW optimizer, a cosine learning rate scheduler with a base learning rate of 1e-4, and a weight decay of 0.05. The batch size is set to 2048, and the model is trained for 9K iterations with a warm-up period of 1.8K. The model uses various data augmentations, such as random resize cropping, color jittering, and random horizontal flipping. The input image size is 448x448.
How can you try out SegGPT?
A SegGPT demo you can try out now is hosted on Hugging Face. The code for SegGPT is open source and in the same repository as the Painter package.
The research team provided a UI with Gradio for running the demo locally. Follow the steps below:
- Clone the project repo: https://github.com/baaivision/Painter/tree/main/SegGPT
- Run python app_gradio.py
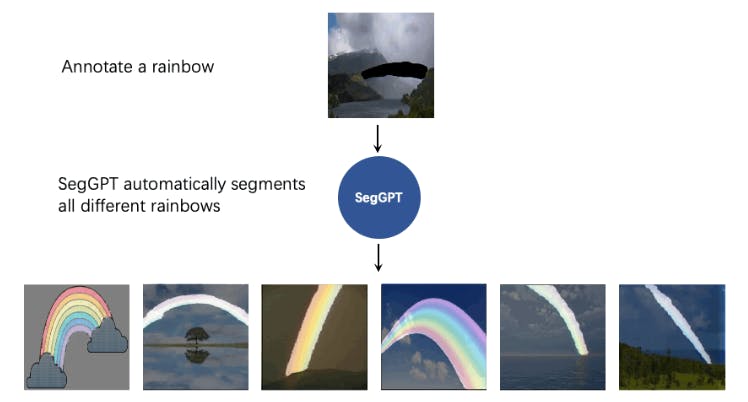
SegGPT performs arbitrary segmentation tasks in images or videos via in-context inference, such as object instance, stuff, part, contour, and text, with only one single model. | Source
What datasets were used to train SegGPT?
The researchers used multiple segmentation datasets, such as part, semantic, instance, panoptic, person, retinal-vessel, and aerial-image. Unlike previous approaches that required manual merging of labels, the training method eliminates the need for additional effort, adjustments to the datasets, or modifying the model architecture.
The dataset BAAI researchers used to train SegGPT includes the following:
- ADE20K, which has a total of 25K images, including 20K training images, 2K validation images, and 3K testing images, provides segmentation labels for 150 semantic categories.
- COCO supports instance segmentation, semantic segmentation, and panoptic segmentation tasks, making it a popular visual perception dataset. It has 80 "things" and 53 "stuff" categories, 118K training images, and 5K validations.
- PASCAL VOC; they used the augmented segmentation version, which provides annotations for 20 categories on 10582 training images.
- Cityscapes: This dataset's primary concerns are the scene and understanding of the street views.
- LIP that focuses on the semantic understanding of people.
- PACO where they processed and used the 41807 training images with part annotations.
- CHASE DB1, DRIVE, HRF, and STARE that all provide annotations for retinal vessel segmentation. They augmented the high-resolution raw images with random cropping.
iSAID and loveDA focus on semantic understanding in aerial images, with 23262 and 2520 training images for 15 and 6 semantic categories respectively.
Can SegGPT be used for AI-assisted labelling?
Like Meta's Segment Anything Model (SAM) and other recent groundbreaking foundation models, like Grounding DINO, you can use SegGPT for AI-assisted image labelling and annotations. The model generalizes well to a lot of tasks and has the potential to reduce the annotation workload on teams.

Beyond that, here are other key benefits:
- Get faster annotations: Given the reported results, when you use SegGPT in conjunction with a good image annotation tool, it's possible to reduce significantly the labeling time required for annotations.
- Get better quality annotations: There will likely be fewer mistakes and higher quality annotations overall if annotators can produce more precise and accurate labels.
- Get consistent annotations: When multiple annotators are working on the same project, they can use the same version of SegGPT to ensure consistency in annotations.
You could also set up SegGPT so that it learns and improves over time as annotators refine and correct its assisted labeling, leading to better performance over time and further streamlining the annotation process.
One thing to be weary of when using SegGPT is the type of tasks (semantic, instance, e.t.c.) you want to use for annotation. SegGPT does not outperform existing specialist methods across all benchmarks, so it’s important to know what tasks it outperforms.
Conclusion
That's all, folks!
The last few weeks have been some of the most exciting weeks in the last decade of computer vision. And yet we're sure we'll look back at them in a few months time and see that -- from Segment-Anything to SegGPT -- we were barely scratching the surface.
At Encord we've been predicting and waiting for this moment for a long time, and have a lot of things in store over the coming weeks 👀
We're the first platform to release the Segment Anything Model in Encord, allowing you to fine-tune the model without writing any code (you can get read more about fine-tuning SAM here). Stay tuned for many firsts (for us and for our customers!) we'll be sharing more about soon.
Frequently asked questions
Encord is designed to make the transition from other annotation tools seamless. Our team provides support in migrating existing pipelines and scripts, ensuring that users can quickly adapt to our platform while maintaining their workflows.