Llama 2: Meta AI's Latest Open Source Large Language Model

Meta AI and Microsoft have joined forces to introduce Llama 2, the next generation of Meta’s open-source large language model.
The best part? Llama 2 is available for free, both for research and commercial use.
LLaMA: Large Language Model Meta AI
Large Language Model Meta AI (LLaMA 1) is the first version of the state-of-the-art foundational large language model that was released by Meta in February this year. It is an impressive collection of foundational models, comprised of models with parameter sixes ranging from 7 billion to 65 billion.
LLaMA 1 stands out due to its extensive training on trillion of tokens, showcasing that state-of-the-art models can be attained solely though publicly available datasets and without the need for proprietary or inaccessible data.
Notably, the LLaMA-13B model outperformed ChatGPT, which has a significantly larger parameter size of 175 billion, across most benchmarkdatasets. This accomplishment highlights LLaMA’s efficiency in delivering top-tier performance with significantly fewer parameters.
The largest model of the collection, LLaMA-65B, holds its own amongst other leading models in the field of natural language processing (NLP) like Chinchilla-70B and PaLM-540B.
LLaMA stands out due to its strong emphasis on openness and accessibility. Meta AI, the creators of LLaMA, have demonstrated their dedication to advancing the field of AI through collaborative efforts by releasing all their models to the research community. This is notably in contrast to OpenAI's GPT-3 or GPT-4.
 💡 Read the published paper LLaMA: Open and Efficient Foundation Language Models.
💡 Read the published paper LLaMA: Open and Efficient Foundation Language Models. Llama 2
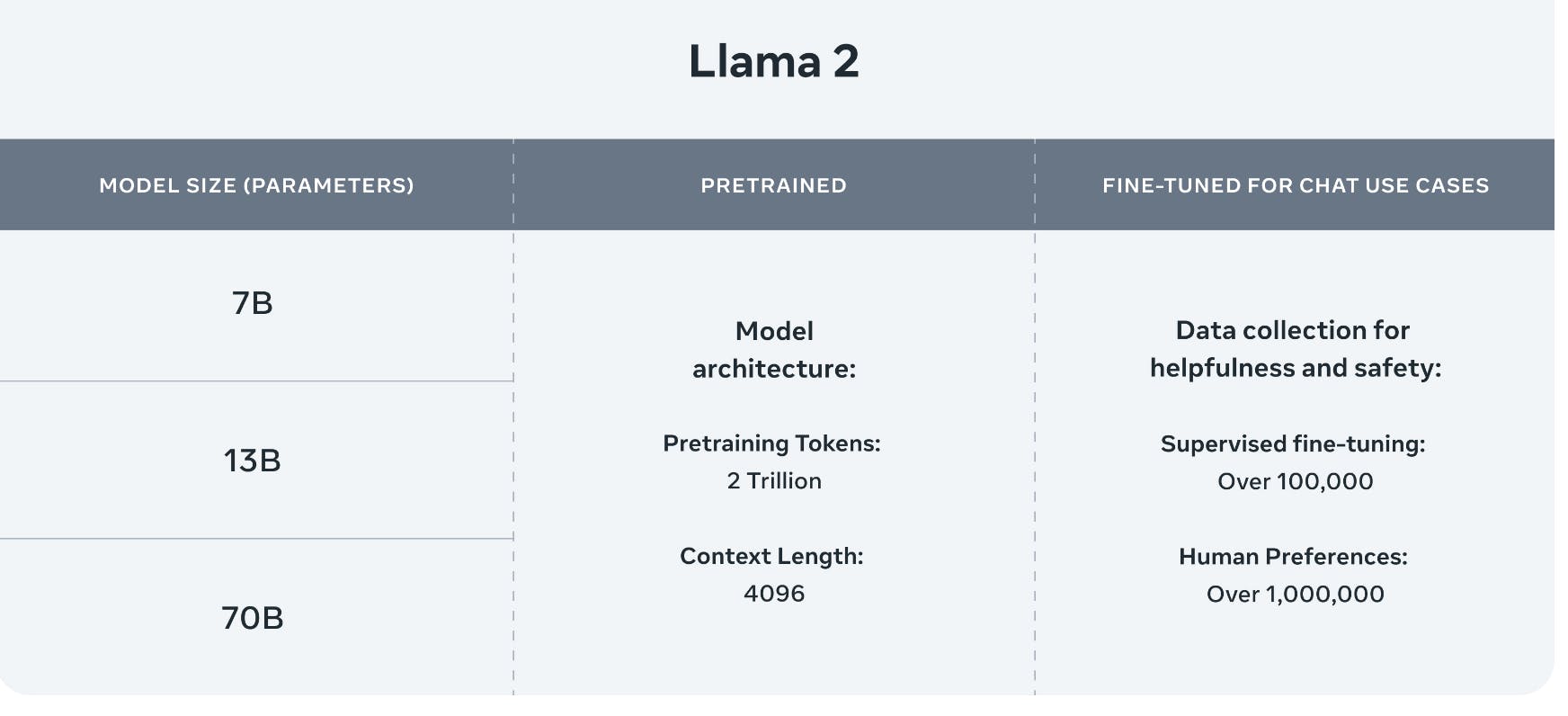
Llama 2 is an updated collection of pre-trained and fine-tuned large language models (LLMs) introduced by Meta researchers. It encompasses models ranging from 7 billion to 70 billion parameters, each designed to deliver exceptional performance across various language processing tasks.
Building upon its predecssor, LLaMA, LLaMA 2 brings several enhancements. The pretraining corpus size has been expanded by 40%, allowing the model to learn from a more extensive and diverse set of publicly available data. Additionally, the context length of Llama 2 has been doubled, enabling the model to consider a more extensive context when generating responses, leading to improved output quality and accuracy.
Llama 2: Open Foundation and Fine-Tuned Chat Models
One notable addition to Llama 2 is the adoption of grouped-query attention, which is expected to enhance attention and focus during language processing tasks.
Llama 2-Chat is a version of Llama 2 that has been fine-tuned for dialogue-related applications. Through the fine-tuning process, the model has been optimized to deliver superior performance, ensuring it generates more contextually relevant responses during conversations.
Llama 2 was pretrained using openly accessible online data sources. For the fine-tuned version, Llama 2-Chat, leveraged publicly available instruction datasets and used more than 1 million human annotations.
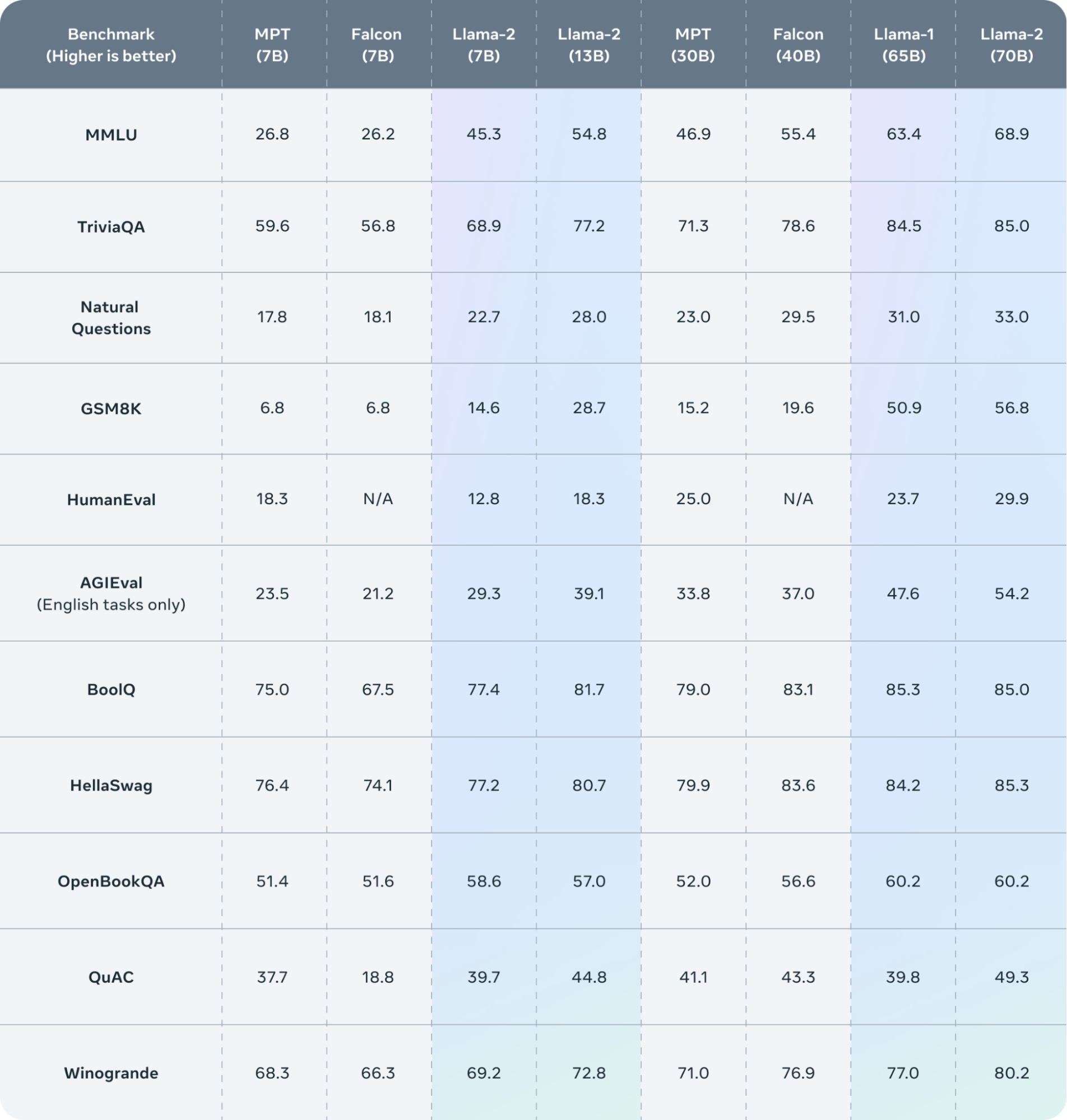
💡 Read the paper Llama 2: Open Foundation and Fine-Tuned Chat Models for more information on technical specifications. Across a range of external benchmarks, including reasoning, coding, proficiency, and knowledge tests, Llama 2 outshines other open-source language models.
Llama 2: Open Foundation and Fine-Tuned Chat Models
Meta researchers have released variants of Llama 2 and Llama 2-Chat with different parameter sizes, including 7 billion, 13 billion, and 70 billion. These variations cater to various computational requirements and application scenarios, allowing researchers and developers to choose the best-suited model for their specific tasks. This allows startups to access Llama 2 models to create their own machine learning products, including various generative AI applications or AI chatbots like Google’s Bard and OpenAI’s ChatGPT.
💡You can download the model here. Focus on Responsibility
Meta's dedication to responsibility is evident in its open-source approach and emphasis on transparency. While recoginizing the profound societal advancements facilitated by AI, Meta remains aware of the associated risks. Their commitment to building responsibly is evident through several key initiatives undertaken during the development and release of Llama 2.
Red-Teaming Exercises
To ensure safety, Meta exposes fine-tuned models to red-teaming exercises. Through internal and external efforts, the models undergo thorough testing with adversarial prompts. This iterative process allows them to continuously enhance safety and address potential vulnerabilities, leading to the release of updated fine-tuned models based on these efforts.
Transparency Schematic
Meta promotes transparency by providing detailed insights into their fine-tuning and evaluation methods. Meta openly discloses known challenges and shortcomings, offering valuable information to the AI community. Their transparency schematic, found within the research paper, provides a roadmap of mitigations implemented and future explorations.
Responsible Use Guide
Meta acknowledges the importance of guiding developers in responsible AI deployment. To achieve this, they have developed a comprehensive Responsible User Guide. This resource equips developers with best practices for responsible development and safety evaluations, ensuring the ethical and appropriate use of Llama 2.
Acceptable Use Policy
Meta implemented an acceptable use policy to prevent misuse and safeguard against inappropriate usage. By explicitly defining certain prohibited use cases, Meta is actively promoting fairness and responsible AI application.
Reinforcement Learning from Human Feedback
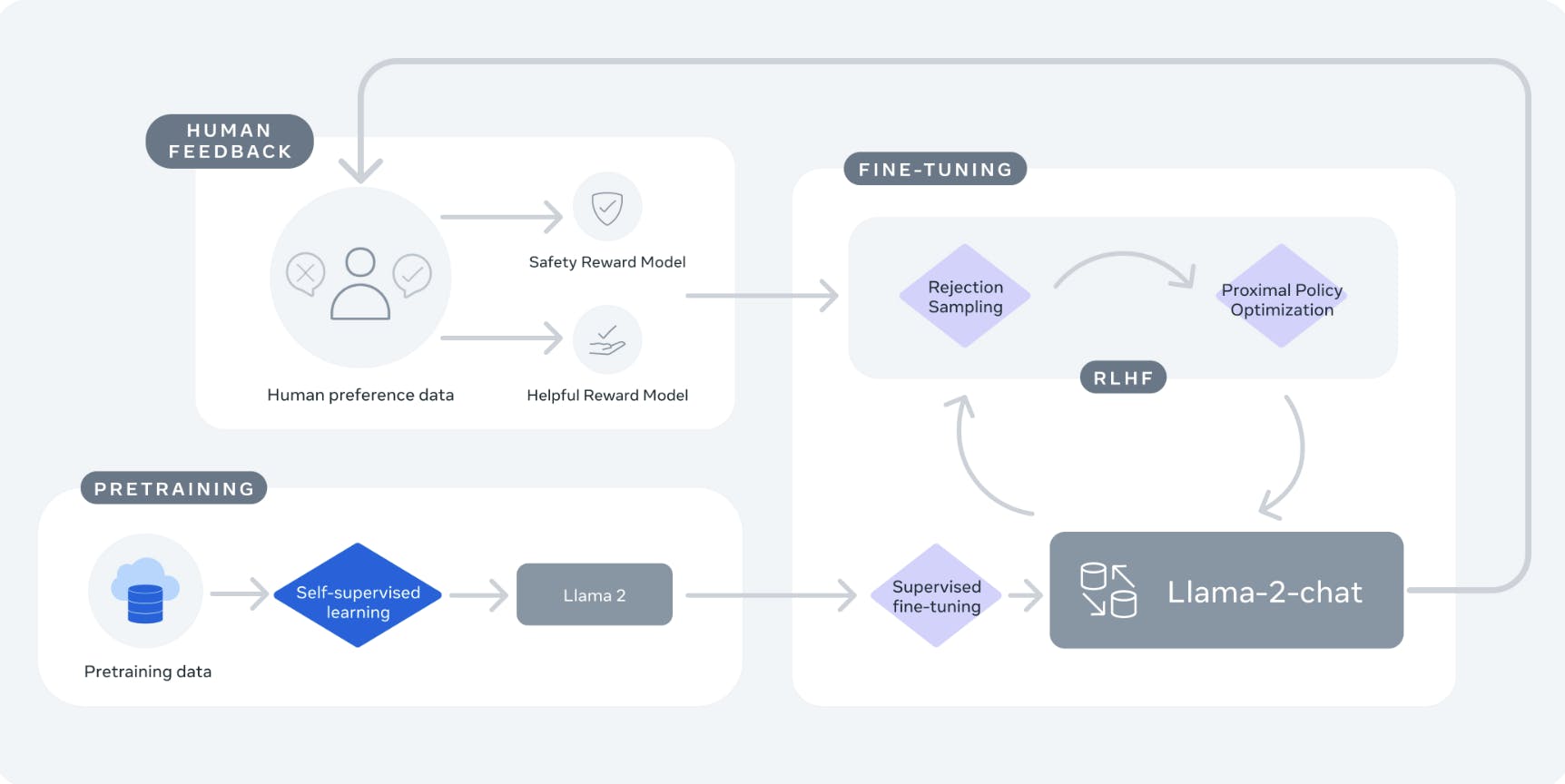
Meta uses Reinforcement Learning from Human Feedback (RLHF) for Llama-2-chat to prioritize safety and helpfulness. This training technique used in Artificial Intelligence models improves model performance through interactions with human evaluators.
💡 Read the blog The Complete Guide to RLHF for Computer Vision for more information. A study of 180 samples revealed that the annotation platform choice affects downstream AI model performance. Model outputs were competitive with human annotations, suggesting prioritizing performance-based annotations for RLHF could enhance efficiency.
Meta AI’s other recent releases
Meta has achieved remarkable success with a series of open source tool releases in recent months.
I-JEPA
I-JEPA (Image-based Joint-Embedding Predictive Architecture) is a self-supervised learning approach for image representations. It efficiently learns semantic features without relying on hand-crafter data augmentations.

Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture
Compared to pixel-reconstruction methods, I-JEPA excels in ImageNet-1K linear probing and low-level vision tasks such as object counting and depth prediction. With excellent scalability and efficiency, it outperforms previous pretraining approaches, making it a versatile and powerful tool for learning meaningful image representations.
💡Read the blog Meta AI’s I-JEPA, Image-based Joint-Embedding Predictive Architecture, Explained for more information. DINO v2
DINOv2 is a self-supervised learning method designed to acquire visual representations from images without the need for labeled data. Unlike transitional supervised learning approaches, DINOv2 overcomes the reliance on vast amounts of labeled data during training.

DINOv2: Learning Robust Visual Features without Supervision
The DINOv2 workflow consists of two main stages: pre-training and fine-tuning. In the pretraining phase, the DINO model gains valuable visual insights by processing a vast collection of unlabeled images. Subsequently, during the fine-tuning stage, the pre-trained DINO model gets customized and adapted to handle specific tasks, such as image classification or object detection, using a dataset tailored to that task.
💡Read the blog DINOv2: Self-supervised Learning Model Explained for more information. Segment Anything Model (SAM)
Segment Anything Model (SAM) revolutionizes image segmentation by adopting foundation models which are typically used in natural language processing (NLP).

SAM introduces prompt engineering, a novel approach that addresses diverse segmentation challenges. This empowers users to select objects for segmentation interactively, employing bounding boxes, key points, grids or text prompts.
When faced with uncertainty regarding the object to be segmented, SAM exhibits the capability to generate multiple valid masks, enhancing the flexibility of the segmentation process. SAM has great potential to reduce labeling costs, providing a much-awaited solution for AI-assisted labeling, and improving labeling speedby orders of magnitude.
💡Read the blog Meta AI's New Breakthrough: Segment Anything Model (SAM) Explained for more information. ImageBind
ImageBIND introduces an approach to learn a unified embedding space encompassing six diverse modalities: tex, image/video, audio, depth, thermal, and IMU. This technique enhances AI model’s ability to process and analyze data more comprehensively, incorporating information from various modalities, thus leading to a more humanistic understanding of the information at hand.

ImageBind: One Embedding Space To Bind Them All
To generate fixed-dimensional embeddings, the ImageBIND architecture employs separate encoders for each modality, coupled with linear projection heads tailored to individual modalities. The architecture primarily comprises three key components:
- Modality-specific encoders
- Cross-modal attention module
- Joint embedding space
Although the framework’s precise specifications have not been made public, the research paper offers insights into the suggested architecture.
💡Read the blog ImageBind MultiJoint Embedding Model from Meta Explained for more information. Conclusion
The introduction of Llama 2 represents a significant milestone. As an open-sourcelarge language model, Llama 2 offers boundless opportunities for research and commercial use, fueling innovation across various domains.