Guide to Reinforcement Learning from Human Feedback (RLHF) for Computer Vision

Product Manager at Encord
Reinforcement Learning (RL) is a machine learning training method that relies on the state of the environment to train intelligent agents. The RL training paradigm induces a form of self-learning where the agent can understand changing environments and modify its output accordingly.
Reinforcement learning from human feedback (RLHF) is an extended form of the conventional RL technique. It adds a human feedback component to the overall architecture. This human-guided training helps fine-tune the model and build applications like InstructGPT. These models converge faster and eventually learn better patterns.
RLHF has several interesting applications across various fields of artificial intelligence, especially Computer Vision (CV). It trains CV models by randomly varying the outputs and comparing evaluation metrics to verify improvements and/or degradations. This technique helps fine-tune models for classification, object detection, segmentation, etc. Before diving into CV further, let’s break down RLHF by starting with RL.
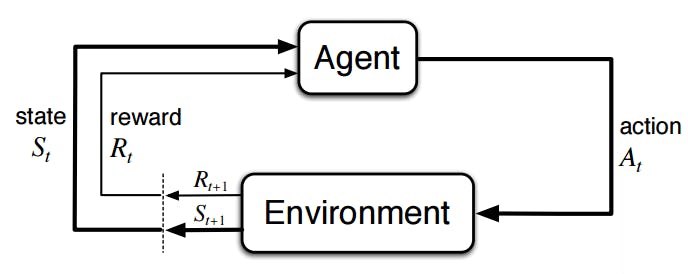
Machine Learning With Reinforcement Learning
Reinforcement learning uses a reward model to guide a machine learning model toward the desired output. The model evaluates its environment and decides upon a set of actions. Based on these actions, it receives positive or negative feedback depending on whether the action was appropriate.
Intention recognition under uncertainties for human-robot interaction
RL was introduced during the 1980s with the popular Q-learning algorithm. This model-free and off-policy algorithm generates its own rules to decide the best course of action. With time RL algorithms have improved upon policy optimization and, in many cases, have gone beyond human intelligence.
Surpassing Humans
Reinforcement learning techniques have created models that have reached and even beat human intelligence. In 1997, IBM’s deep-blue beat the then-world chess champion, Garry Kasparov, and in 2016, Deepmind’s AlphaGo beat the world champion Lee Sedol. Both these programs utilized RL as part of their training process and are prime examples of the algorithm’s capabilities.
Human-In-The-Loop: RLHF
A few significant downsides of RL are that with a static reward function, the overall model only has a limited environment to learn from. If the environment is changed, the performance will be impacted. Moreover, even with a static reward system, the model requires a lot of trial and error before gaining valuable insight and setting itself on the right track. This is time-consuming and computationally expensive.
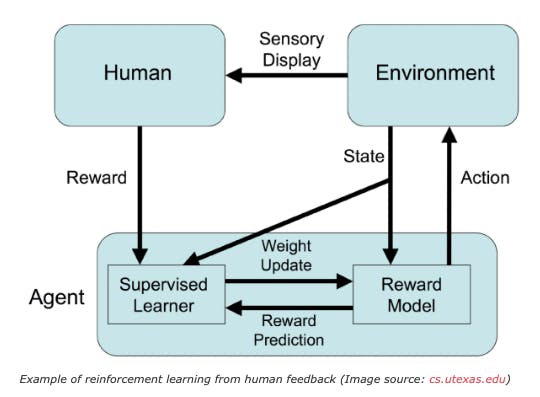
Training an Agent Manually via Evaluative Reinforcement
Reinforcement learning with human feedback solves these issues by introducing a human component in the training loop. With human feedback in the loop, the model learns better training patterns and efficiently adjusts itself to match the desired output.
How RLHF Works
The recent success of large language models (LLMs) demonstrates the capabilities of RLHF. These state-of-the-art natural language models are trained on large corpora from the internet, and the key ingredient has been fine-tuning using RLHF. Let’s break down their training procedures.
Pre-Training
The initial, pre-trained model learns from the text available on the internet. This dataset is considered low-quality since it contains grammatical errors, misinformation, conspiracy theories, etc. A pre-trained LLM is essentially a child that needs more education.
Fine-tuning To Higher-Quality
The next step is to induct high-quality, factually correct, and informative data into the pre-trained model. This includes strong sources like research journals and information hubs like Wikipedia. This supervised learning ensures the model outputs the most desired response.
Fine-tuning With Reward Models and Human Feedback
The final step is creating a human feedback system to enhance the model's output further. A user feedback system judges the language model's output based on human preference. This creates a reward model based on human feedback that further fine-tunes theAI models to output the most desired responses. The reward modellabeling is performed by several humans, which diversifies the learning process.
ChatGPT: An LLM Guided By Human Feedback
By this point, almost everyone is familiar with OpenAI’s ChatGPT. It is a large-scale natural language processing model based on the GPT-3.5 architecture. ChatGPT uses RLHF as part of its constant retraining regime and demonstrates the capabilities of training with human preferences.
When ChatGPT generates a response, it indicates a thumbs up and a thumbs down button. Users can click either of these buttons depending on whether the response was helpful or not. The model constantly learns from this input and adjusts its weights and gradients to output results that are natural and desirable.
Learning from human input, the model can provide human-like, factually accurate responses. Moreover, it can reject answering sensitive topics involving ambiguity or bias.
Training Computer Vision With Reinforcement Learning
Similar to NLP, reinforcement learning can benefit Computer Vision tasks manifold. odern CV problems are addressed using Deep Neural Networks, which are complex architectures designed to capture complicated data patterns.
 💡 Check out our detailed guide on Computer Vision In Machine Learning
💡 Check out our detailed guide on Computer Vision In Machine Learning To tackle CV problems, researchers have experimented with integrating Deep Learning with RL to form Deep Reinforcement Learning (DRL). This new architecture has succeeded in real-world AI use cases, including CV. DRL encompasses several categories, including values-based, policy-gradient, and actor-critic approaches and forming algorithms like Deep Q-learning.
The DRL algorithms help with CV model training for applications like facial expression detection, person identification, object detection, and segmentation. Let’s take a look at how RL integrates into these tasks.
Object Detection
Object detection tasks aim to output bounding boxes for objects within an image on which the model is trained. This particular problem has been continuously improved over the years, particularly with the many variations of the YOLO algorithm.
Other unconventional techniques, like active object localization using deep reinforcement learning, define transformative actions for the bounding box as the feedback loop. The feedback loop moves the bounding box (from the model output) in 8 directions to evaluate whether the model improved performance. The architecture localizes single instances from limited regions (11 to 25) and proves efficient compared to its competitors.

Active Object Localization with Deep Reinforcement Learning
Other strategies further improved this technique by using the agent for extracting regions of interest (ROI). The model worked recursively, finding a smaller ROI within the previous ROI during each iteration.
💡Learn more about object detection and tracking with Tracking Everything Everywhere All at Once Image Segmentation
Image segmentation is similar to object detection, but instead of outputting bounding boxes, the model produces a masked version of the original image that segments it into various objects. The segmentation mask accurately (pixel-by-pixel) makes out and segregates all the different objects.
Conventional segmentation models include Faster R-CNN, Mask-RCNN, and Detectron2. One major downside of these models is that they require significant data for good results. Such large datasets are often unavailable in medical fields, and training remains inadequate.
RL techniques perform well in data-limited scenarios and are an excellent fit for image segmentation tasks. A DRL agent is added to the sequential network that acts as a reward model. The reward model applies transformations to the segmentation map and adjusts the primary model according to the result. Different researchers have demonstrated different methodologies of transformation to work with the feedback loop. Some introduced variations in the image intensity and thresholds to modify the predicted segmentation mask. In contrast, others proposed a multi-agent RL network that uses a relative cross-entropy gain-based reward model for 3D medical images.
These models performed similarly to their state-of-the-art counterparts while being much more efficient.
Fine-Tuning Existing Models With Reinforcement Learning
A key benefit of reward models is that they can enhance existing models' performance without requiring additional training data. Pinto et. el. demonstrate how task rewards can enhance existing CV applications without further annotations.
They train their models in two steps:
- Train the model to imitate the ground truths (Maximum Likelihood Training)
- Further train the model using a reward function
The second step here fine-tunes the model to enhance performance in tasks with the intended usage. They present better results in object detection, panoptic segmentation, and colorization tasks.
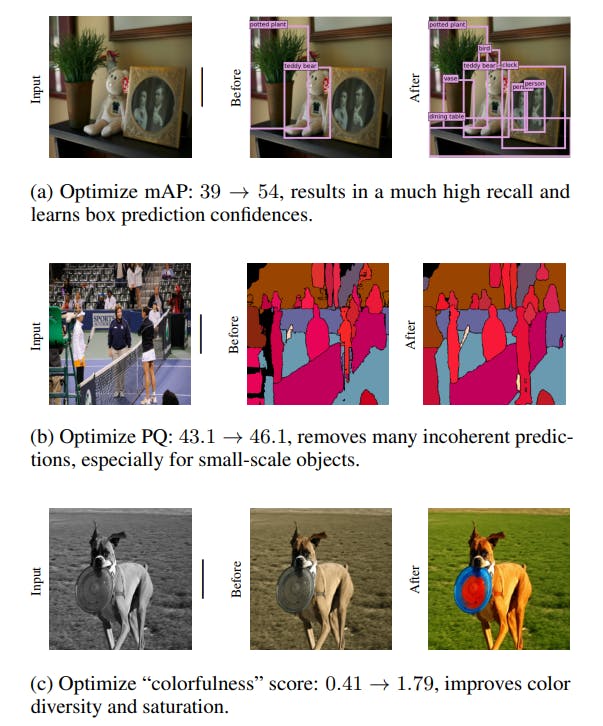
Tuning computer vision models with task rewards
The results set a positive precedent for all the opportunities that can be explored. Computer vision tasks are memory-hogging and computationally expensive. Fine-tuning models with RL can solve resource-related issues while improving results on trivial tasks.
Training Computer Vision With Human Feedback: Segment Anything Model (SAM)
Meta’s latest Segment Anything Model 2 (SAM 2 groundbreaking new foundation model designed for segmenting objects in both images and videos.
The data generation for SAM 2 consisted of 3 stages, one of which included human input to generate precise masks. Masks were generated by users clicking on background or foreground objects and further refined using pixel-precise ‘brush’ and ‘eraser’ tools.
Training Computer Vision With Human Feedback: Google CAPTCHA
Google CAPTCHA is Google’s algorithm to distinguish human internet surfers from robots. CAPTCHA requires users to interact with elements like text and images to determine whether the user is human. These interactions include selecting relevant objects from images, typing the text displayed, and recognizing objects.
Although never officially confirmed by Google, many believe these interactions fed back to Google’s AI algorithms for annotation and training. This feedback-based training is an example of RLHF in CV and is used to fine-tune models to perform better in real-world scenarios.
RLHF: Key Takeaways
- The traditional RL algorithm creates a mathematical reward function that trains the model.
- Reinforcement learning with human feedback enhances the benefits of conventional RL by introducing a human feedback system in the training loop.
- A human reward mechanism allows the model to understand its environment better and converge faster.
- RLHF is widely used in generative AI applications like GPT-4 and similar chatbots and has made its way into several computer vision tasks.
- CV tasks like image detection, segmentation, and colorization are merged with RL for increased efficiency and performance.
- RL can also fine-tune pre-trained models for better performance on niche tasks.
RLHF: Frequently Asked Questions
What is RLHF in Computer Vision?
RLHF uses reinforcement learning and a human feedback mechanism to train computer vision models with additional data or annotation.
How Do You Implement RLHF?
RLHF is implemented by integrating a human reward loop within an existing reinforcement learning algorithm.
What Is the Difference Between RLHF and Other Methods?
Other supervised learning methods rely on large volumes of labeled data for adequate training. RLHF algorithms can adequately adjust them according to human feedback and without any additional data.
What Are The Applications of RLHF?
RLHF has various applications in robotics, computer vision, healthcare, and NLP. Some prominent applications include LLM-based chatbots, training robotic simulations, and self-driving cars.
Frequently asked questions
RLHF uses reinforcement learning and a human feedback mechanism to train computer vision models with additional data or annotation.
RLHF is implemented by integrating a human reward loop within an existing reinforcement learning algorithm.
Other supervised learning methods rely on large volumes of labeled data for adequate training. RLHF algorithms can adequately adjust them according to human feedback and without any additional data.
RLHF has various applications in robotics, computer vision, healthcare, and NLP. Some prominent applications include LLM-based chatbots, training robotic simulations, and self-driving cars.
Encord provides the ability to configure various annotation workflows, including the RHF style workflows discussed in the call. This capability allows teams to tailor their annotation processes according to specific project needs and evolving requirements.
To set up a new project in Encord, three key components are needed: an ontology to define the categories and specifications, a dataset that includes the files to be labeled, and a workflow that outlines the labeling stages, including any review processes.