Guide to Image Segmentation in Computer Vision: Best Practices

Product Manager at Encord
In this guide, we will discuss the basics of image segmentation, including different types of segmentation, applications, and various techniques used for image segmentation. We will also cover evaluation metrics and datasets for evaluating image segmentation algorithms.
Image segmentation in computer vision is crucial, where the goal is to divide an image into different meaningful and distinguishable regions or objects. It is a fundamental task in various applications such as object recognition, tracking, and detection, medical imaging, and robotics.
Many techniques are available for image segmentation, ranging from traditional methods to deep learning-based approaches. With the advent of deep learning, the accuracy and efficiency of image segmentation have improved significantly.

What is Image Segmentation?
Image segmentation is the process of dividing an image into multiple meaningful and homogeneous regions or objects based on their inherent characteristics, such as color, texture, shape, or brightness. Image segmentation aims to simplify and/or change the representation of an image into something more meaningful and easier to analyze. Here, each pixel is labeled. All the pixels belonging to the same category have a common label assigned to them. The task of segmentation can further be done in two ways:
- Similarity: As the name suggests, the segments are formed by detecting similarity between image pixels. It is often done by thresholding (see below for more on thresholding). Machine learning algorithms (such as clustering) are based on this type of approach for image segmentation.
- Discontinuity: Here, the segments are formed based on the change of pixel intensity values within the image. This strategy is used by line, point, and edge detection techniques to obtain intermediate segmentation results that may be processed to obtain the final segmented image.
Types of Segmentation
Image segmentation modes are divided into three categories based on the amount and type of information that should be extracted from the image: Instance, semantic, and panoptic. Let’s look at these various modes of image segmentation methods.
Also, to understand the three modes of image segmentation, it would be more convenient to know more about objects and backgrounds.
Objects are the identifiable entities in an image that can be distinguished from each other by assigning unique IDs, while the background refers to parts of the image that cannot be counted, such as the sky, water bodies, and other similar elements. By distinguishing between objects and backgrounds, it becomes easier to understand the different modes of image segmentation and their respective applications.
Here is a quick overview:
| Type | Definition | Characteristics | Applications |
| Instance Segmentation | Detects and segments each object as a separate entity with unique boundaries. | - Identifies individual objects (e.g., cars, people). - Separates overlapping objects. - Does not require class information. | Object tracking, AR/VR, advanced object detection. |
| Semantic Segmentation | Labels each pixel with a class category (e.g., "sky," "road," "car"). | - Assigns dense class labels to every pixel. - Does not distinguish between different instances of the same class. - Background and objects grouped by class. | Road analysis, medical imaging, scene understanding. |
| Panoptic Segmentation | Combines semantic and instance segmentation for detailed labeling. | - Provides pixel-wise labeling by class and instance. - Differentiates objects and their instances. - Offers the most granular, high-quality information. | Autonomous vehicles, robotics, interactive AI systems. |
Instance Segmentation
Instance segmentation is a type of image segmentation that involves detecting and segmenting each object in an image. It is similar to object detection but with the added task of segmenting the object’s boundaries. The algorithm has no idea of the class of the region, but it separates overlapping objects. Instance segmentation is useful in applications where individual objects need to be identified and tracked.

Instance segmentation
Semantic Segmentation
Semantic segmentation is a type of image segmentation that involves labeling each pixel in an image with a corresponding class label with no other information or context taken into consideration. The goal is to assign a label to every pixel in the image, which provides a dense labeling of the image. The algorithm takes an image as input and generates a segmentation map where the pixel value (0,1,...255) of the image is transformed into class labels (0,1,...n). It is useful in applications where identifying the different classes of objects on the road is important.

Semantic segmentation - the human and the dog are classified together as mammals and separated from the rest of the background.
Panoptic Segmentation
Panoptic segmentation is a combination of semantic and instance segmentation. It involves labeling each pixel with a class label and identifying each object instance in the image. This mode of image segmentation provides the maximum amount of high-quality granular information from machine learning algorithms. It is useful in applications where the computer vision model needs to detect and interact with different objects in its environment, like an autonomous robot.

Panoptic segmentation
Each type of segmentation has its unique characteristics and is useful in different applications. In the following section, let’s discuss the various applications of image segmentation.
Image Segmentation Techniques
Traditional Techniques
Traditional image segmentation techniques have been used for decades in computer vision to extract meaningful information from images. These techniques are based on mathematical models and algorithms that identify regions of an image with common characteristics, such as color, texture, or brightness. Traditional image segmentation techniques are usually computationally efficient and relatively simple to implement. They are often used for applications that require fast and accurate segmentation of images, such as object detection, tracking, and recognition. In this section, we will explore some of the most common techniques.
Here is an overview:
| Technique | Definition | Characteristics | Applications |
| Thresholding | Divides image pixels into classes based on intensity relative to a threshold value. | - Simple and efficient. - Binary output (foreground/background). - Effective for high-contrast images. - Global or adaptive. | Document scanning, basic object detection. |
| Region-based Segmentation | Groups pixels into regions based on similarity (e.g., color, texture, intensity). | - Can use "split and merge" or "graph-based" methods. - Requires criteria for similarity. - Handles non-uniform regions. | Medical imaging, scene segmentation, region analysis. |
| Edge-based Segmentation | Detects object boundaries based on intensity changes. | - Focuses on edges. - Common methods: Canny, Sobel, LoG. - May struggle with noisy or smooth regions. | Shape detection, contour extraction, feature recognition. |
| Clustering | Groups pixels with similar features into clusters using algorithms like K-means or mean-shift. | - Handles high-dimensional data. - Adaptable to various similarity metrics. - Limited accuracy in complex scenes. | Color-based segmentation, image simplification, feature extraction. |
Thresholding

Thresholding
Thresholding is one of the simplest image segmentation methods. Here, the pixels are divided into classes based on their histogram intensity which is relative to a fixed value or threshold. This method is suitable for segmenting objects where the difference in pixel values between the two target classes is significant. In low-noise images, the threshold value can be kept constant, but with images with noise, dynamic thresholding performs better. In thresholding-based segmentation, the greyscale image is divided into two segments based on their relationship to the threshold value, producing binary images. Algorithms like contour detection and identification work on these binarized images. The two commonly used thresholding methods are:
Global thresholding is a technique used in image segmentation to divide images into foreground and background regions based on pixel intensity values. A threshold value is chosen to separate the two regions, and pixels with intensity values above the threshold are assigned to the foreground region and those below the threshold to the background region. This method is simple and efficient but may not work well for images with varying illumination or contrast. In those cases, adaptive thresholding techniques may be more appropriate.
Adaptive thresholding is a technique used in image segmentation to divide an image into foreground and background regions by adjusting the threshold value locally based on the image characteristics. The method involves selecting a threshold value for each smaller region or block, based on the statistics of the pixel values within that block. Adaptive thresholding is useful for images with non-uniform illumination or varying contrast and is commonly used in document scanning, image binarization, and image segmentation. The choice of adaptive thresholding technique depends on the specific application requirements and image characteristics.
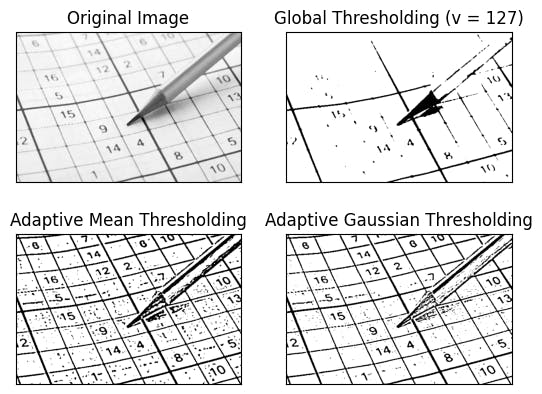
Image showing different thresholding techniques. Source: Author
Region-based Segmentation
Region-based segmentation is a technique used in image processing to divide an image into regions based on similarity criteria, such as color, texture, or intensity. The method involves grouping pixels into regions or clusters based on their similarity and then merging or splitting regions until the desired level of segmentation is achieved. The two commonly used region-based segmentation techniques are:
Split and merge segmentation is a region-based segmentation technique that recursively divides an image into smaller regions until a stopping criterion is met and then merges similar regions to form larger regions. The method involves splitting the image into smaller blocks or regions and then merging adjacent regions that meet certain similarity criteria, such as similar color or texture. Split and merge segmentation is a simple and efficient technique for segmenting images, but it may not work well for complex images with overlapping or irregular regions.
Graph-based segmentation is a technique used in image processing to divide an image into regions based on the edges or boundaries between regions. The method involves representing the image as a graph, where the nodes represent pixels, and the edges represent the similarity between pixels. The graph is then partitioned into regions by minimizing a cost function, such as the normalized cut or minimum spanning tree.
Example of graph-based image segmentation. Source
Edge-based Segmentation
Edge-based segmentation is a technique used in image processing to identify and separate the edges of an image from the background. The method involves detecting the abrupt changes in intensity or color values of the pixels in the image and using them to mark the boundaries of the objects. The two most common edge-based segmentation techniques are:
Canny edge detection is a popular method for edge detection that uses a multi-stage algorithm to detect edges in an image. The method involves smoothing the image using a Gaussian filter, computing the gradient magnitude and direction of the image, applying non-maximum suppression to thin the edges, and using hysteresis thresholding to remove weak edges.
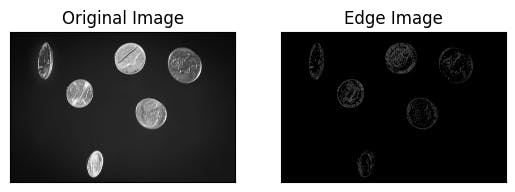
Example of canny edge detection
Sobel edge detection is a method for edge detection that uses a gradient-based approach to detect edges in an image. The method involves computing the gradient magnitude and direction of the image using a Sobel operator, which is a convolution kernel that extracts horizontal and vertical edge information separately.
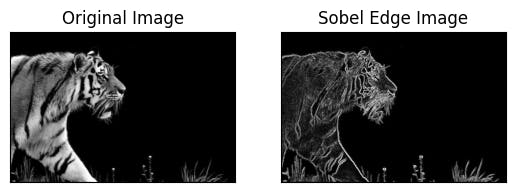
Example of Sobel edge detection.
Laplacian of Gaussian (LoG) edge detection is a method for edge detection that combines Gaussian smoothing with the Laplacian operator. The method involves applying a Gaussian filter to the image to remove noise and then applying the Laplacian operator to highlight the edges. LoG edge detection is a robust and accurate method for edge detection, but it is computationally expensive and may not work well for images with complex edges.

Example of Laplacian of Gaussian edge detection.
Clustering
Clustering is one of the most popular techniques used for image segmentation, as it can group pixels with similar characteristics into clusters or segments. The main idea behind clustering-based segmentation is to group pixels into clusters based on their similarity, where each cluster represents a segment. This can be achieved using various clustering algorithms, such as K means clustering, mean shift clustering, hierarchical clustering, and fuzzy clustering.
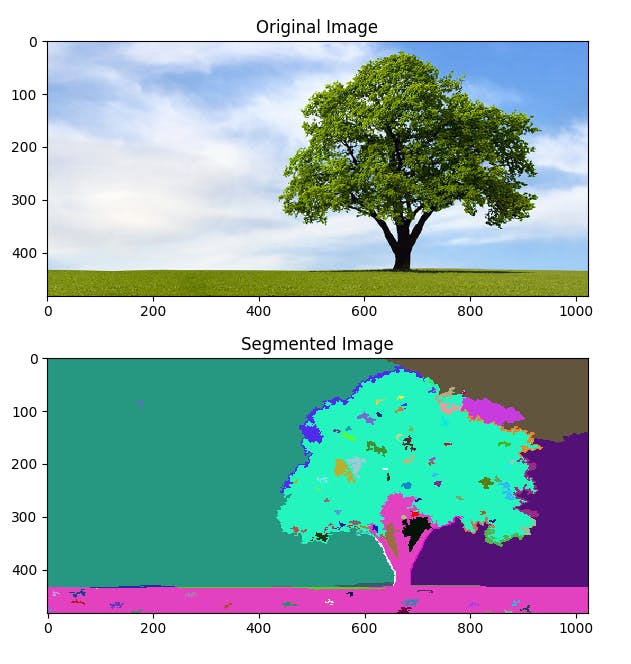
K-means clustering is a widely used clustering algorithm for image segmentation. In this approach, the pixels in an image are treated as data points, and the algorithm partitions these data points into K clusters based on their similarity. The similarity is measured using a distance metric, such as Euclidean distance or Mahalanobis distance. The algorithm starts by randomly selecting K initial centroids, and then iteratively assigns each pixel to the nearest centroid and updates the centroids based on the mean of the assigned pixels. This process continues until the centroids converge to a stable value.

Showing the result of segmenting the image at k=2,4,10. Source
Mean shift clustering is another popular clustering algorithm used for image segmentation. In this approach, each pixel is represented as a point in a high-dimensional space, and the algorithm shifts each point toward the direction of the local density maximum. This process is repeated until convergence, where each pixel is assigned to a cluster based on the nearest local density maximum.
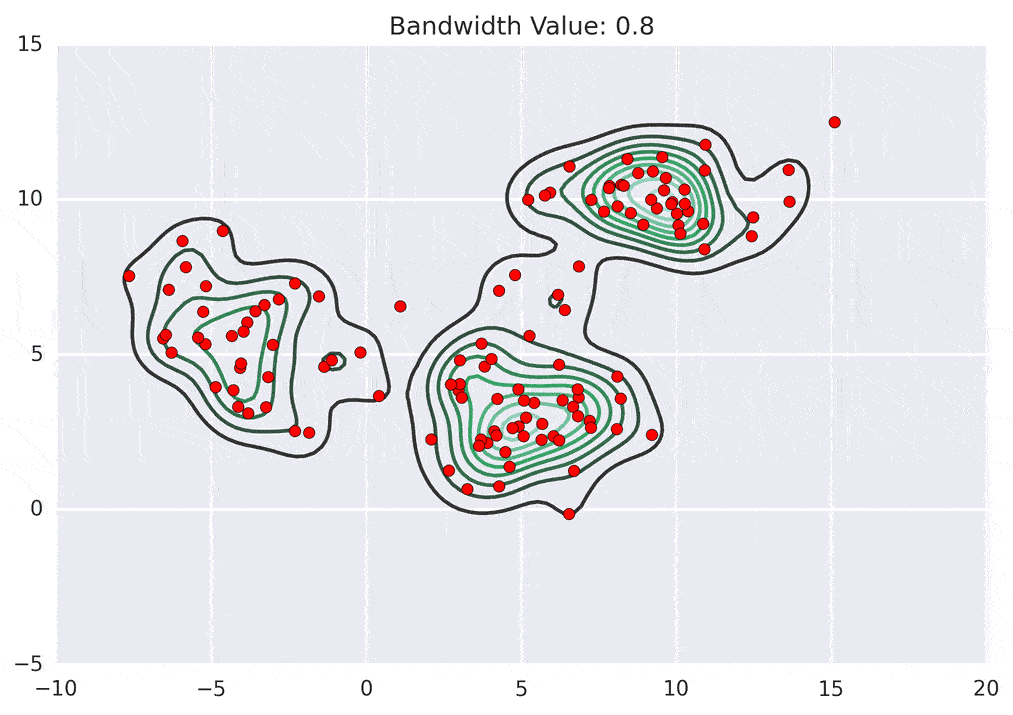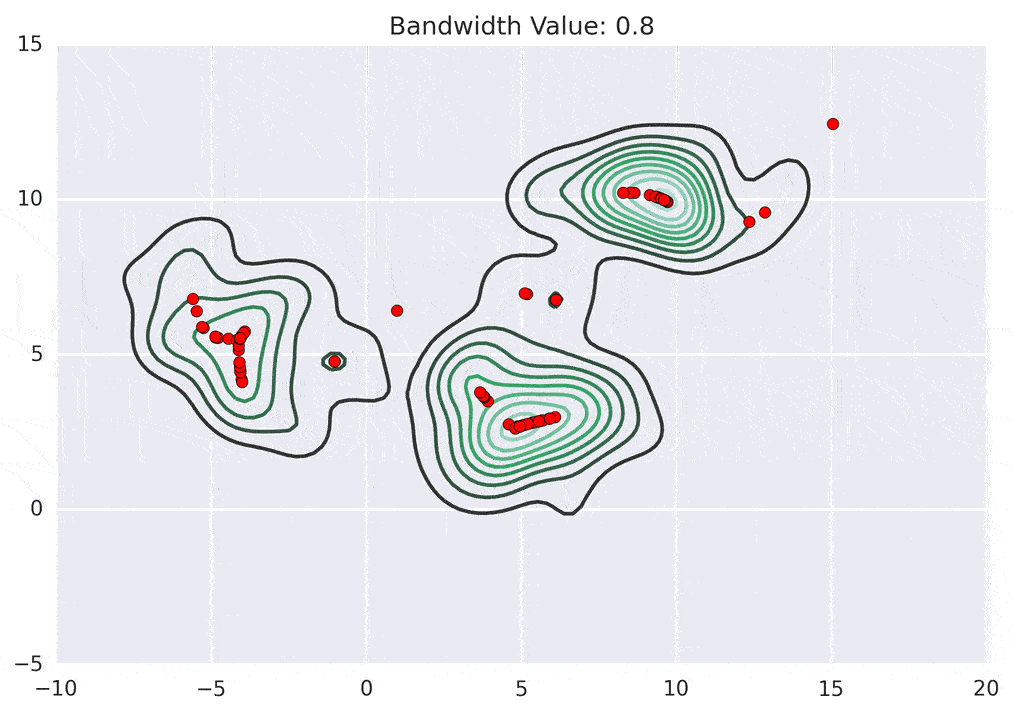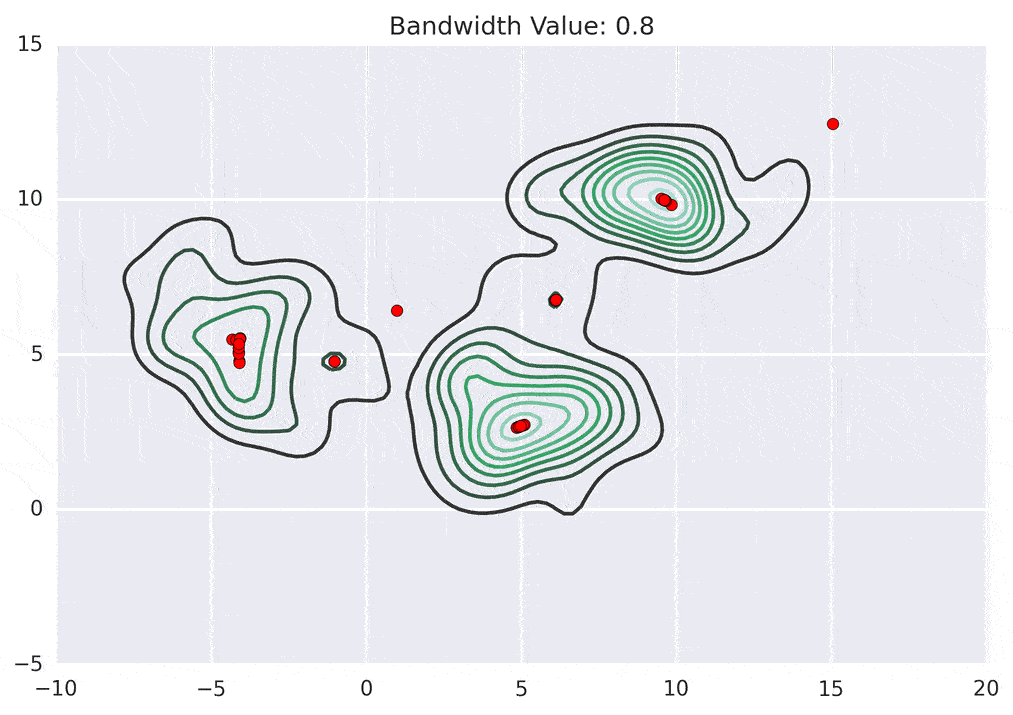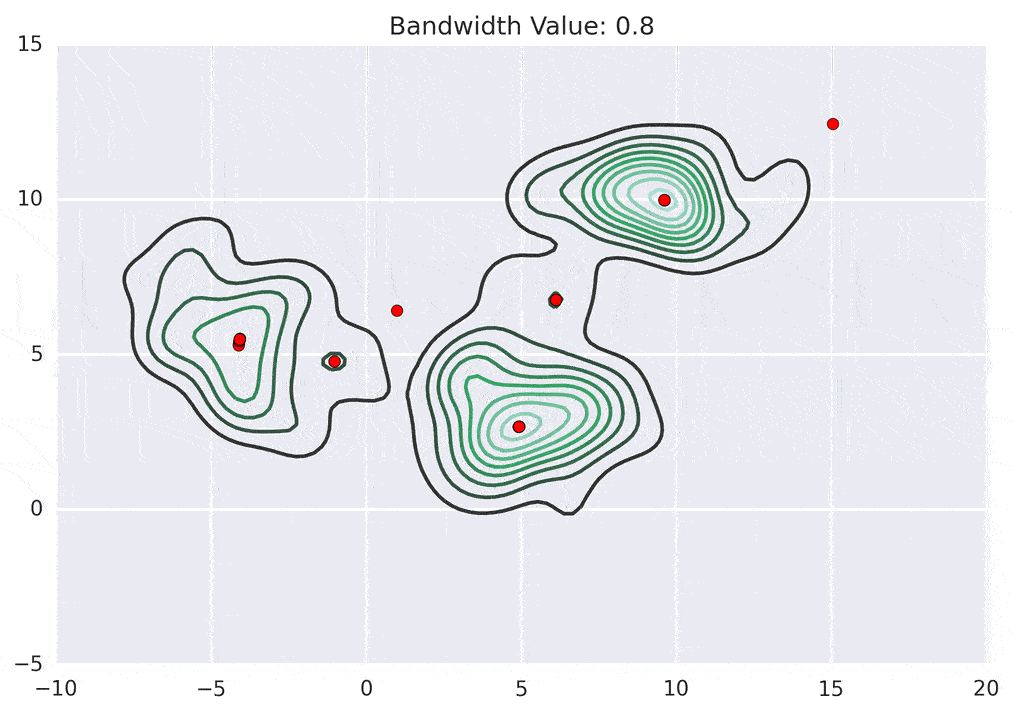
Though these techniques are simple, they are fast and memory efficient. But these techniques are more suitable for simpler segmentation tasks as well. They often require tuning to customize the algorithm as per the use case and also provide limited accuracy on complex scenes.
Deep Learning Techniques
Neural networks also provide solutions for image segmentation by training neural networks to identify which features are important in an image, rather than relying on customized functions like in traditional algorithms. Neural nets that perform the task of segmentation typically use an encoder-decoder structure. The encoder extracts features of an image through narrower and deeper filters. If the encoder is pre-trained on a task like an image or face recognition, it then uses that knowledge to extract features for segmentation (transfer learning). The decoder then over a series of layers inflates the encoder’s output into a segmentation mask resembling the pixel resolution of the input image.
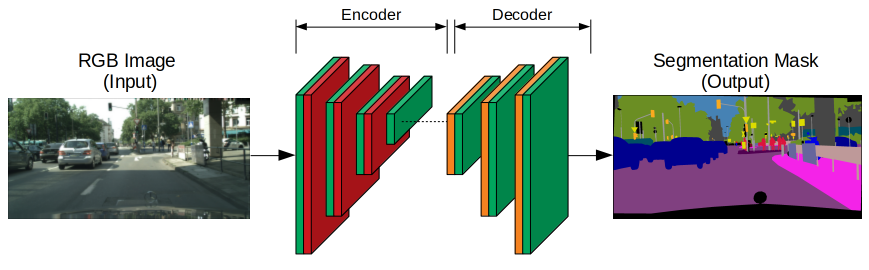
The basic architecture of the neural network model for image segmentation. Source
Many deep learning models are quite adept at performing the task of segmentation reliably. Let’s have a look at a few of them:
| Technique | Definition | Key Features | Applications |
| U-Net | A fully convolutional network designed for precise segmentation tasks, especially in medical imaging. | - Encoder-decoder structure with skip connections. - Combines low-level and high-level features for finer segmentation. - Retains spatial context effectively. | Medical imaging (tumor detection, organ segmentation). |
| SegNet | A deep convolutional network optimized for semantic segmentation tasks. | - Encoder-decoder structure. - Uses max-pooling indices for efficient upsampling. - Reduces computational complexity. | Scene understanding, autonomous driving. |
| DeepLab | A CNN architecture that leverages atrous (dilated) convolution for dense segmentation tasks. | - Incorporates features from all convolutional layers. - Atrous convolution for capturing contextual information. - Efficient computation. | Object detection, road scene analysis. |
U-Net
U-Net is a modified, fully convolutional neural network. It was primarily proposed for medical purposes, i.e., to detect tumors in the lungs and brain. It has the same encoder and decoder. The encoder is used to extract features using a shortcut connection, unlike in fully convolutional networks, which extract features by upsampling. The shortcut connection in the U-Net is designed to tackle the problem of information loss. In the U-Net architecture, the encoders and decoders are designed in such a manner that the network captures finer information and retains more information by concatenating high-level features with low-level ones. This allows the network to yield more accurate results.
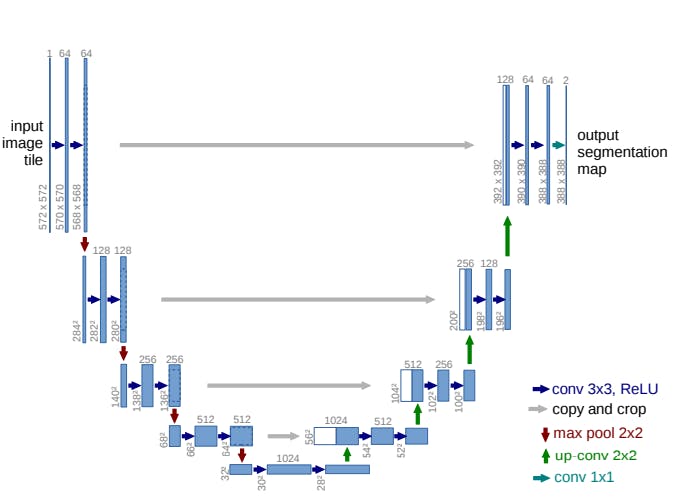
U-Net Architecture. Source
SegNet
SegNet is also a deep fully convolutional network that is designed especially for semantic pixel-wise segmentation. Like U-Net, SegNet’s architecture also consists of encoder and decoder blocks. The SegNet differs from other neural networks in the way it uses its decoder for upsampling the features. The decoder network uses the pooling indices computed in the max-pooling layer which in turn makes the encoder perform non-linear upsampling. This eliminates the need for learning to upsample. SegNet is primarily designed for scene-understanding applications.
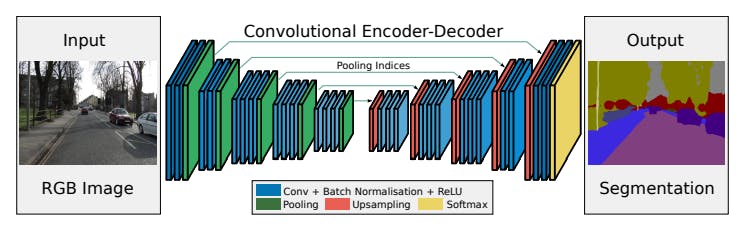
SegNet Architecture. Source
DeepLab
DeepLab is primarily a convolutional neural network (CNN) architecture. Unlike the other two networks, it uses features from every convolutional block and then concatenates them to their deconvolutional block. The neural network uses the features from the last convolutional block and upsamples it like the fully convolutional network (FCN). It uses the atrous convolution or dilated convolution method for upsampling. The advantage of atrous convolution is that the computation cost is reduced while capturing more information.
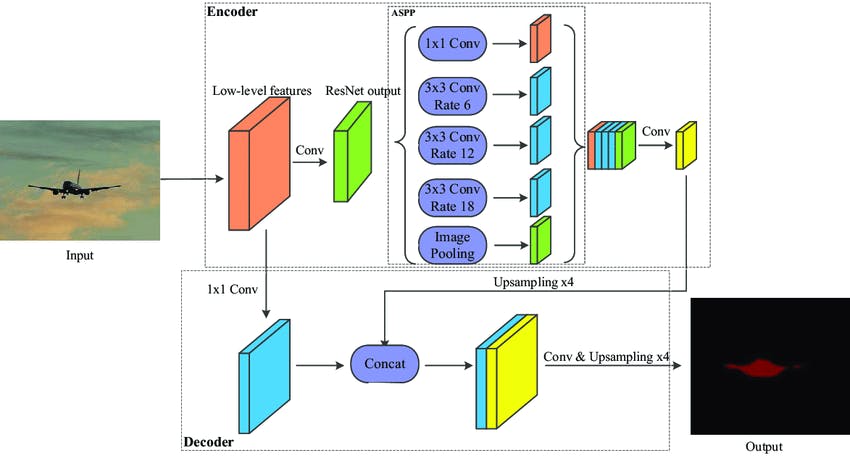
The encoder-Decoder architecture of DeepLab v3. Source
Foundation Model Techniques
Foundation models have also been used for image segmentation, which divides an image into distinct regions or segments. Unlike language models, which are typically based on transformer architectures, foundation models for image segmentation often use convolutional neural networks (CNNs) designed to handle image data.
Segment Anything Model
Segment Anything Model (SAM) is considered the first foundation model for image segmentation. SAM is built on the largest segmentation dataset to date, with over 1 billion segmentation masks. It is trained to return a valid segmentation mask for any prompt, where a prompt can be foreground/background points, a rough box or mask, freeform text, or general information indicating what to segment in an image. Under the hood, an image encoder produces a one-time embedding for the image, while a lightweight encoder converts any prompt into an embedding vector in real time. These two information sources are combined in a lightweight decoder that predicts segmentation masks.
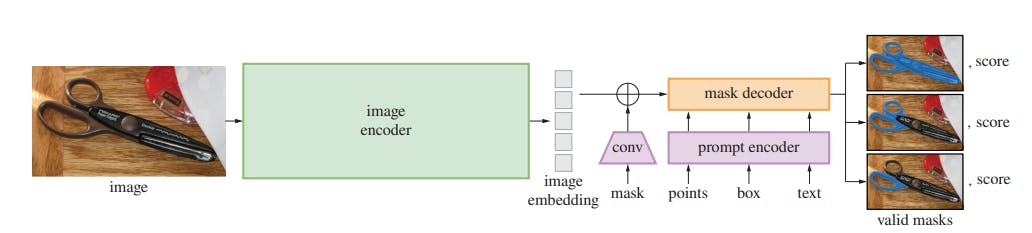
Metrics for Evaluating Image Segmentation Algorithms
Pixel Accuracy
Pixel accuracy is a common evaluation metric used in image segmentation to measure the overall accuracy of the segmentation algorithm. It is defined as the ratio of the number of correctly classified pixels to the total number of pixels in the image.
Pixel accuracy is a straightforward and easy-to-understand metric that provides a quick assessment of the segmentation performance. However, it does not account for the spatial alignment between the ground truth and the predicted segmentation, which can be important in some applications.
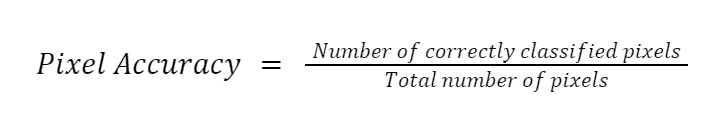
In addition, pixel accuracy can be sensitive to class imbalance, where one class has significantly more pixels than another. This can lead to a biased evaluation of the algorithm's performance.
Dice Coefficient
The dice coefficient measures the similarity between two sets of binary data, in this case, the ground truth segmentation and the predicted segmentation. The dice coefficient is calculated as
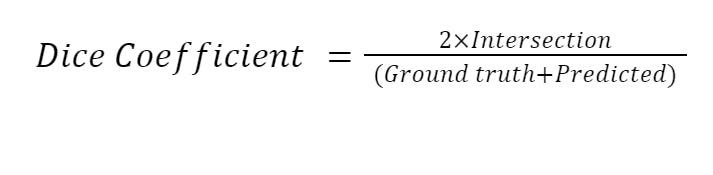
Where intersection is the number of pixels that are correctly classified as positive by both the ground truth and predicted segmentations, and ground truth and predicted are the total number of positive pixels in the respective segmentations.
The Dice coefficient ranges from 0 to 1, with higher values indicating better segmentation performance. A value of 1 indicates a perfect overlap between the ground truth and predicted segmentations.
The Dice coefficient is a popular metric for image segmentation because it is sensitive to small changes in the segmentation and is not affected by class imbalance. However, it does not account for the spatial alignment between the ground truth and predicted segmentation, which can be important in some applications.
Jaccard Index (IOU)
The Jaccard index, also known as the intersection over union (IoU) score, measures the similarity between the ground truth segmentation and the predicted segmentation. It is formulated as
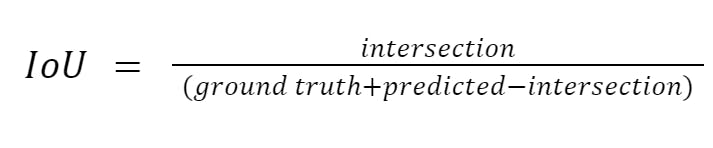
Where intersection is the number of pixels that are correctly classified as positive by both the ground truth and predicted segmentations, and ground truth and predicted are the total number of positive pixels in the respective segmentations.
The IoU score ranges from 0 to 1, with higher values indicating better segmentation performance. A value of 1 indicates a perfect overlap between the ground truth and predicted segmentations.
The Jaccard index takes into account both the true positives and false positives and is not affected by class imbalance. It also accounts for the spatial alignment between the ground truth and predicted segmentations.
Datasets for Evaluating Image Segmentation Algorithms
The evaluation of image segmentation algorithms is a crucial task n computer vision research. To measure the performance of these algorithms, various benchmark datasets have been developed. We will be discussing three popular datasets for evaluating image segmentation algorithms. These datasets provide carefully annotated images with pixel-level annotations, allowing researchers to test and compare the effectiveness of their segmentation algorithms.
Barkley Segmentation Dataset and Benchmark
The Barkley Segmentation Dataset is a standard benchmark for contour detection. This dataset is intended for testing natural edge detection, which takes into account background boundaries in addition to object interior and exterior boundaries as well as object contours. It includes 500 natural images with carefully annotated boundaries collected from multiple users. The dataset is divided into three parts: 200 for training, 100 for validation, and the rest 200 for testing.

Pascal VOC Segmentation Dataset
The Pascal VOC Segmentation Dataset is a popular benchmark dataset for evaluating image segmentation algorithms. It contains images from 20 object categories and provides pixel-level annotations for each image. The dataset is divided into the train, validation, and test sets, with the test set used to evaluate the performance of segmentation algorithms. The Pascal VOC Segmentation Dataset has been used as a benchmark for various computer vision challenges, including the Pascal VOC Challenge and the COCO Challenge.
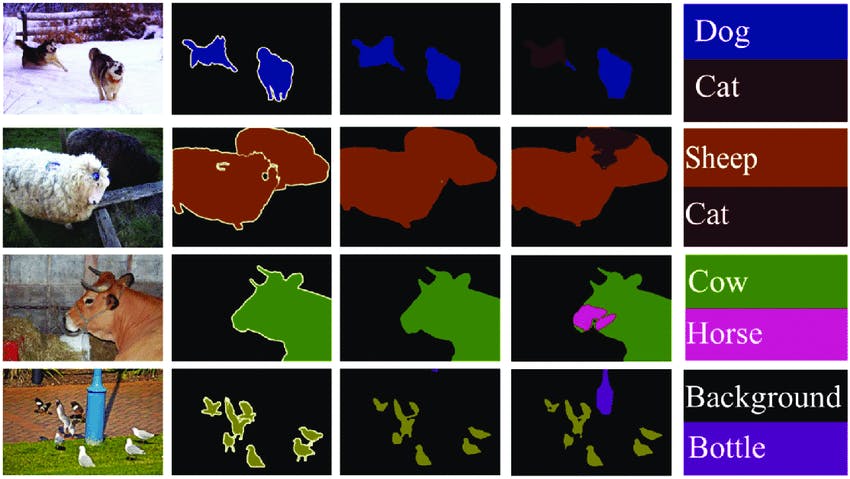
MS COCO Segmentation Dataset
The Microsoft Common Objects in Context (COCO) Segmentation Dataset is another widely used dataset for evaluating image segmentation algorithms. It contains over 330,000 images with object annotations, including segmentations of 80 object categories. The dataset is divided into the train, validation, and test sets, with the test set containing around 5,000 images. The MS COCO Segmentation Dataset is often used as a benchmark for evaluating segmentation algorithms in various computer vision challenges, including the COCO Challenge.

Future Direction of Image Segmentation
Auto-Segmentation with SAM
Auto-segmentation refers to the process of automatically segmenting an image without human intervention. Auto-segmentation with Meta’s Segment Anything Model (SAM) has instantly become popular as it shows remarkable performance in image segmentation tasks. It is a single model that can easily perform both interactive segmentation and automatic segmentation. Since SAM is trained on a diverse, high-quality dataset, it can generalize to new types of objects and images beyond what is observed during training. This ability to generalize means that by and large, practitioners will no longer need to collect their segmentation data and fine-tune a model for their use case.
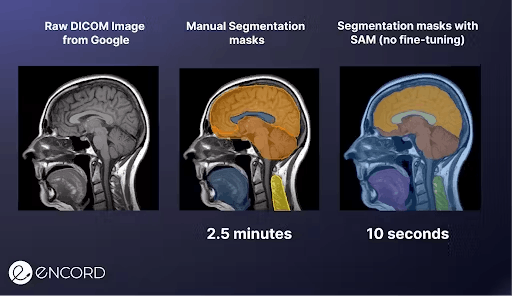
Improvement in segmentation accuracy
Improving segmentation accuracy is one of the main goals of researchers in the field of computer vision. Accurate segmentation is essential for various applications, including medical imaging, object recognition, and autonomous vehicles. While deep learning techniques have led to significant improvements in segmentation accuracy in recent years, there is still much room for improvement. Here are some ways researchers are working to improve segmentation accuracy:
- Incorporating additional data sources: One approach to improving segmentation accuracy is incorporating additional data sources beyond the raw image data. For example, depth information can provide valuable cues for object boundaries and segmentation, particularly in complex scenes with occlusions and clutter.
- Developing new segmentation algorithms: Researchers continuously develop new algorithms for image segmentation that can improve accuracy. For example, some recent approaches use adversarial training or reinforcement learning to refine segmentation results.
- Improving annotation quality: The quality of the ground truth annotations used to train segmentation algorithms is essential to achieving high accuracy. Researchers are working to improve annotation quality through various means, including incorporating expert knowledge and utilizing crowdsourcing platforms.
- Refining evaluation metrics: Evaluation metrics play a crucial role in measuring the accuracy of segmentation algorithms. Researchers are exploring new evaluation metrics beyond the traditional Dice coefficient and Jaccard index, such as the Boundary F1 score, which can better capture the quality of object boundaries.
Integrate Deep Learning with Traditional Techniques
While deep learning techniques have shown remarkable performance in segmentation tasks, traditional techniques such as clustering, thresholding, and morphological operations can still provide useful insights and improve accuracy.
Here are some ways researchers are integrating deep learning with traditional techniques in image segmentation:
- Hybrid models: Researchers are developing hybrid models that combine deep learning with traditional techniques. For example, some approaches use clustering or thresholding to initialize deep learning models or post-process segmentation results.
- Multi-stage approaches: Multi-stage approaches involve using deep learning for initial segmentation and then refining the results using traditional techniques. For example, some approaches use morphological operations to smooth and refine segmentation results.
- Attention-based models: Attention-based models are a type of deep learning model that incorporates traditional techniques for computing attention weights within a feature map. Attention-based models can improve accuracy by focusing on relevant image features and ignoring irrelevant ones.
- Transfer learning: Transfer learning involves pretraining deep learning models on large datasets and then fine-tuning them for specific segmentation tasks. Traditional techniques such as clustering or thresholding can be used to identify relevant features for transfer learning.
Applications of Image Segmentation
Image segmentation has a wide range of applications in various fields, including medical imaging, robotics, autonomous vehicles, and surveillance. Here are some examples of how image segmentation is used in different fields:
- Medical imaging: Image segmentation is widely used in medical imaging for tasks such as tumor detection, organ segmentation, and disease diagnosis. Accurate segmentation is essential for treatment planning and monitoring disease progression.
- Robotics: Image segmentation is used in robotics for object recognition and manipulation. For example, robots can use segmentation to recognize and grasp specific objects, such as tools or parts, in industrial settings.
- Autonomous vehicles: Image segmentation is essential for the development of autonomous vehicles, allowing them to detect and classify objects in their environment, such as other vehicles, pedestrians, and obstacles. Accurate segmentation is crucial for safe and reliable autonomous navigation.
- Surveillance: Image segmentation is used in surveillance for detecting and tracking objects and people in real-time video streams. Segmentation can help to identify and classify objects of interest, such as suspicious behavior or potential threats.
- Agriculture: Image segmentation is used in agriculture for crop monitoring, disease detection, and yield prediction. Accurate segmentation can help farmers make informed decisions about crop management and optimize crop yields.
- Art and design: Image segmentation is used in art and design for tasks such as image manipulation, color correction, and style transfer. Segmentation can help to separate objects or regions of an image and apply different effects or modifications to them.
Image Segmentation: Key Takeaways
Image segmentation is a powerful technique that allows us to identify and separate different objects or regions within an image. It has a wide range of applications in fields such as medical imaging, robotics, and computer vision. In this guide, we covered various image segmentation techniques, including traditional techniques such as thresholding, region-based segmentation, edge-based segmentation, and clustering, as well as deep learning and foundation model techniques. We also discussed different evaluation metrics and datasets used to evaluate segmentation algorithms.
As image segmentation continues to advance, future directions will focus on improving segmentation accuracy, integrating deep learning with traditional techniques, and exploring new applications in various fields. Auto-segmentation with the Segment Anything Model (SAM) is a promising direction that can reduce manual intervention and improve accuracy. Integration of deep learning with traditional techniques can also help to overcome the limitations of individual techniques and improve overall performance. With ongoing research and development, we can expect image segmentation to continue to make significant contributions to various fields and industries.
Further Reading on Image Segmentation
- Comparing Two Object Segmentation Models: Mask-RCNN vs. Personalized-SAM
- Deep Learning Techniques for Medical Image Segmentation: Achievements and Challenges
- Visual Segmentation of “Simple” Objects for Robots
- Best practices in deep learning based segmentation of microscopy image
- Image segmentation: Papers with code
Frequently asked questions
mage segmentation is the process of dividing an image into multiple meaningful and homogeneous regions or objects based on their inherent characteristics, such as color, texture, shape, or brightness. Image segmentation aims to simplify and/or change the representation of an image into something more meaningful and easier to analyze. Here, each pixel is labeled.
Traditional image segmentation techniques are based on mathematical models and algorithms that identify regions of an image with common characteristics, such as color, texture, or brightness. These include: global thresholding, adaptive thresholding, split and merge segmentation, graph-based segmentation, canny edge detection, sobel edge detection and more.
Image segmentation is a crucial task in computer vision, where the goal is to divide an image into different meaningful and distinguishable regions or objects. It is a fundamental task in various applications such as object recognition, tracking, and detection, medical imaging, and robotics.
Encord addresses challenges in two-dimensional segmentation by managing the long tail of rare cases, ensuring that the model is trained effectively without overwhelming users with an excessive number of counter classes. This allows for better handling of complex scenarios, such as distinguishing between cracks and resin ducts in wood.
Yes, Encord is capable of managing both image classification and segmentation tasks. This dual functionality allows you to classify images based on specific conditions like corrosion and then segment the images to identify different objects within them, providing a comprehensive approach to data analysis.
Encord's platform allows users to efficiently partition and extract images from a data lake for various use cases. This capability enables teams to bring images from different field cases into the platform, run tests, and ensure that the data is organized for further analysis and feature development.
When using Encord for annotation projects, users can prioritize object segmentation over human segmentation based on their specific needs. This approach allows for faster delivery of key segments while maintaining acceptable quality for less critical details, such as human features.
Encord supports a variety of data types for segmentation, including depth images and infrared intensity images generated from multiple camera setups. This flexibility allows users to effectively label and segment complex datasets, enhancing their machine learning workflows.
Encord supports various types of images, primarily scanning electron microscope (SEM) images and transmission electron microscope (TEM) images. These images are typically in TIFF or PNG format to avoid compression that can lead to loss of critical information.
Yes, Encord enables users to export labels and annotations, which can include spatial information. This allows for downstream analysis to be conducted externally, using formats like CSV or Excel.