Instance Segmentation in Computer Vision: A Comprehensive Guide

Accurately distinguishing and understanding individual objects in complex images is a significant challenge in computer vision. Traditional image processing methods often struggle to differentiate between multiple objects of the same class, which leads to inadequate or erroneous interpretations of visual data.
This impacts practitioners working in fields like autonomous driving, healthcare professionals relying on medical imaging, and developers in surveillance and retail analytics. The inability to accurately segment and identify individual objects can lead to critical errors. For example, misidentifying pedestrians or obstacles in autonomous vehicles can result in safety hazards. In medical imaging, failing to precisely differentiate between healthy and diseased tissues can lead to incorrect diagnoses.
Instance segmentation addresses these challenges by not only recognizing objects in an image but also delineating each object instance, regardless of its class. It goes beyond mere detection, providing pixel-level precision in outlining each object that enables a deeper understanding of complex visual scenes.
This guide covers:
- Instance segmentation techniques like single-shot instance segmentation and transformer- and detection-based methods.
- How instance segmentation compares to other types of image segmentation techniques.
- Instance segmentation model architectures like U-Net and Mask R-CNN.
- Practical applications of instance segmentation in fields like medical imaging and autonomous vehicles.
- Challenges of applying instance segmentation and the corresponding solutions.
Let’s get into it!
Types of Image Segmentation
There are three types of image segmentation:
Each type serves a distinct purpose in computer vision, offering varying levels of granularity in the analysis and understanding of visual content.
Instance Segmentation
Instance segmentation involves precisely identifying and delineating individual objects within an image. Unlike other segmentation types, it assigns a unique label to each pixel, providing a detailed understanding of the distinct instances present in the scene.
Semantic Segmentation
Semantic segmentation involves classifying each pixel in an image into predefined categories. The goal is to understand the general context of the scene, assigning labels to regions based on their shared semantic meaning.
Panoptic Segmentation
Panoptic segmentation is a holistic approach that unifies instance and semantic segmentation. It aims to provide a comprehensive understanding of both the individual objects in the scene (instance segmentation) and the scene's overall semantic composition.

Instance Segmentation Techniques
Instance segmentation is a computer vision task that involves identifying and delineating individual objects within an image while assigning a unique label to each pixel. This section will explore techniques employed in instance segmentation, including:
- Single-shot instance segmentation.
- Transformer-based methods.
- Detection-based instance segmentation.
Single-Shot Instance Segmentation
Single-shot instance segmentation methods aim to efficiently detect and segment objects in a single pass through the neural network. These approaches are designed for real-time applications where speed is crucial. A notable example is YOLACT (You Only Look At Coefficients) which performs object detection and segmentation in a single network pass.
Transformer-Based Methods
Transformers excel at capturing long-range dependencies in data, making them suitable for tasks requiring global context understanding. Models like DETR (DEtection TRansformer) and its extensions apply the transformer architecture to this task. They use self-attention mechanisms to capture intricate relationships between pixels and improve segmentation accuracy.
Detection-Based Instance Segmentation
Detection-based instance segmentation methods integrate object detection and segmentation into a unified framework. These methods use the output of an object detector to identify regions of interest, and then a segmentation module to precisely delineate object boundaries. This category includes two-stage methods like Mask R-CNN, which first generate bounding boxes for objects and thn perform segmentation.
Next, we'll delve into the machine learning models underlying these techniques, discussing their architecture and how they contribute to image segmentation.
Understanding Segmentation Models: U-Net and Mask R-CNN
Several models have become prominent in image segmentation due to their effectiveness and precision. U-Net and Mask R-CNN stand out for their unique contributions to the field.
U-Net Architecture
Originally designed for medical image segmentation, the U-Net architecture has become synonymous with success in various image segmentation tasks. Its architecture is unique because it has a symmetric expanding pathway that lets it get accurate location and context information from the contracting pathway. This structure allows U-Net to deliver high accuracy, even with fewer training samples, making it a preferred choice for biomedical image segmentation. U-Net, renowned for its efficacy in biomedical image segmentation, stands out due to its sophisticated architecture, which has been instrumental in advancing medical image computing and computer-assisted intervention. Developed by Olaf Ronneberger, Philipp Fischer, and Thomas Brox, this convolutional network architecture has significantly improved image segmentation, particularly in medical imaging.
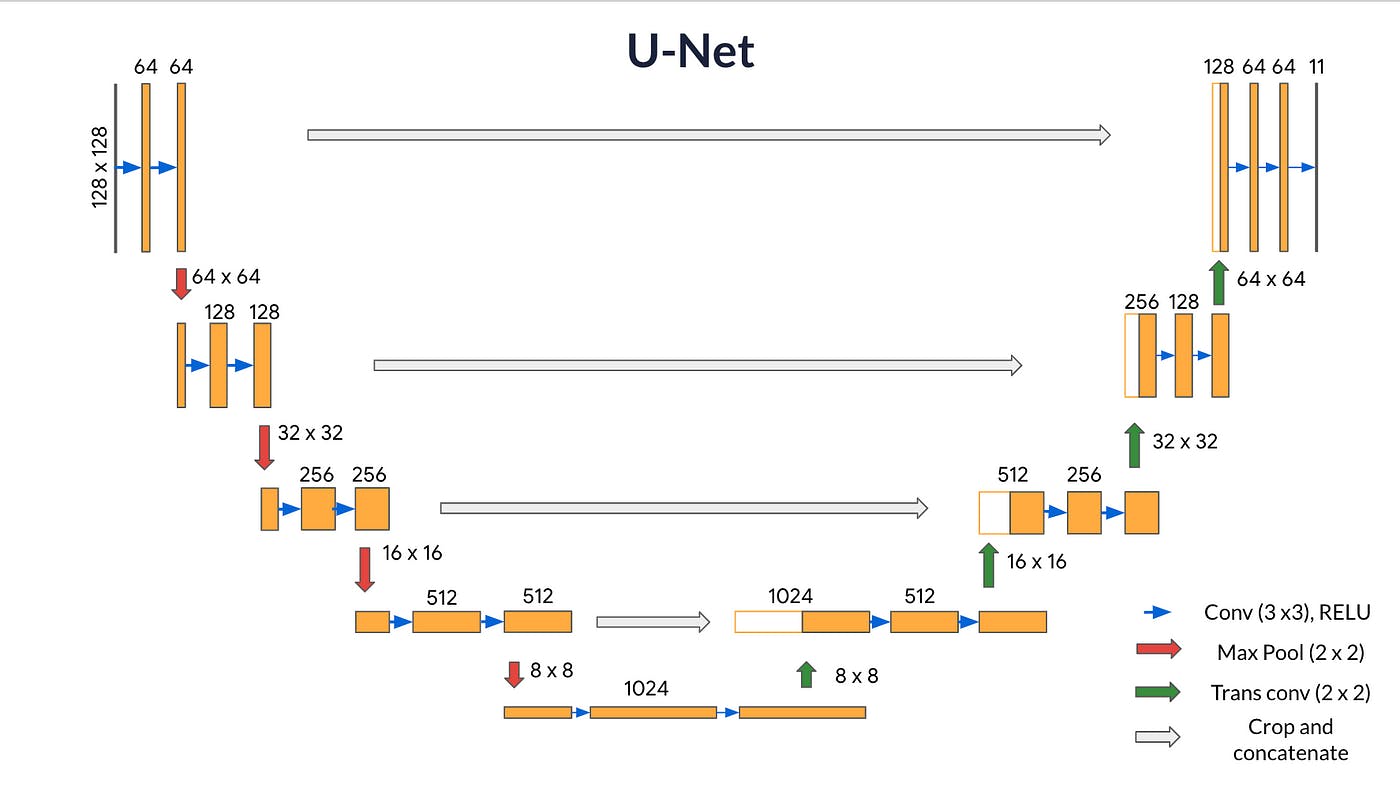
Core components of U-Net architecture
The U-Net architecture comprises a contracting path to capture context and a symmetric expanding path for precise localization. Here's a breakdown of its structure:
- Contracting path: The contracting part of the network follows the typical convolutional network architecture. It consists of repeated application of two 3x3 convolutions, each followed by a rectified linear unit (ReLU) and a 2x2 max pooling operation with stride 2 for downsampling. With each downsampling step, the number of feature channels is doubled.
- Bottleneck: After the contracting path, the network transitions to a bottleneck, where the process is slightly different. Here, the network applies two 3x3 convolutions, each followed by a ReLU. However, it skips the max-pooling step. This area processes the most abstract representations of the input data.
- Expanding Path: The expanding part of the network performs an up-convolution (transposed convolution) and concatenates with the high-resolution features from the contracting path through skip connections. This step is crucial as it allows the network to use information from the image to localize precisely. Similar to the contracting path, this section applies two 3x3 convolutions, each followed by a ReLU after each up-convolution.
- Final Layer: The final layer of the network is a 1x1 convolution used to map each 64-component feature vector to the desired number of classes.
Unique features of U-Net
- Feature Concatenation: Unlike standard fully convolutional networks, U-Net employs feature concatenation (skip connections) between the downsampling and upsampling parts of the network. This technique allows the network to use the feature map from the contracting path and combine it with the output of the transposed convolution. This process helps the network to better localize and use the context.
- Overlap-Tile Strategy: U-Net uses an overlap-tile strategy for seamless segmentation of larger images. This strategy is necessary due to the loss of border pixels in every convolution. U-Net uses a mirroring strategy to predict the pixels in the border region of the image, allowing the network to process images larger than their input size—a common requirement in medical imaging.
- Weighting Loss Function: U-Net modifies the standard cross-entropy loss function with a weighting map, emphasizing the border pixels of the segmented objects. This modification helps the network learn the boundaries of the objects more effectively, leading to more precise segmentation.
With its innovative use of contracting and expanding paths, U-Net's architecture has set a new standard in medical image segmentation. Its ability to train effectively on minimal data and its precise localization and context understanding make it highly suitable for biomedical applications where both the objects' context and accurate localization are critical.
Mask R-CNN Architecture
An extension of the Faster R-CNN, Mask R-CNN, has set new standards for instance segmentation. It builds on its predecessor by adding a branch for predicting segmentation masks on detected objects, operating in parallel with the existing branch for bounding box recognition. This dual functionality allows Mask R-CNN to detect objects and precisely segregate them within the image, making it invaluable for tasks requiring detailed object understanding. The Mask R-CNN framework has revolutionized the field of computer vision, offering improved accuracy and efficiency in tasks like instance segmentation. It builds on the successes of previous models, like Faster R-CNN, by adding a parallel branch for predicting segmentation masks.
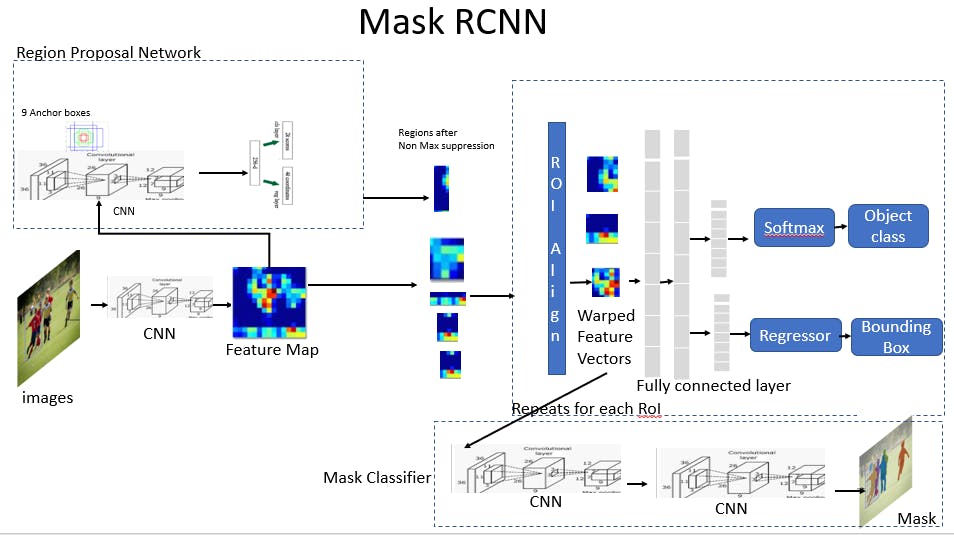
Core components of Mask R-CNN
Here are the core components of Mask R-CNN:
- Backbone: The backbone is the initial feature extraction stage. In Mask R-CNN, this is typically a deep ResNet architecture. The backbone is responsible for processing the input image and generating a rich feature map representing the underlying visual content.
- Region Proposal Network (RPN): The RPN generates potential object regions (proposals) within the feature map. It does this efficiently by scanning the feature map with a set of reference boxes (anchors) and using a lightweight neural network to score each anchor's likelihood of containing an object.
- RoI Align: One of the key innovations in Mask R-CNN is the RoI Align layer, which fixes the misalignment issue caused by the RoI Pooling process used in previous models. It does this by preserving the exact spatial locations of the features, leading to more accurate mask predictions.
- Classification and Bounding Box Regression: Similar to its predecessors, Mask R-CNN uses the features within each proposed region to classify the object and refine its bounding box. It uses a fully connected network to output a class label and bounding box coordinates.
- Mask Prediction: This sets Mask R-CNN apart. In addition to the classification and bounding box outputs, there's a parallel branch for mask prediction. This branch is a small Fully Convolutional Network (FCN) that outputs a binary mask for each RoI.
Unique characteristics and advancements
- Parallel Predictions: Mask R-CNN makes mask predictions parallel with the classification and bounding box regressions, allowing it to be relatively fast and efficient despite the additional output.
- Improved Accuracy: The introduction of RoI Align significantly improves the accuracy of the segmentation masks by eliminating the harsh quantization of RoI Pooling, leading to finer-grained alignments.
- Versatility: Mask R-CNN is versatile and can be used for various tasks, including object detection, instance segmentation, and human pose estimation. It's particularly powerful in scenarios requiring precise segmentation and localization of objects.
- Training and Inference: Mask R-CNN maintains a balance between performance and speed, making it suitable for research and production environments. The model can be trained end-to-end with a multi-task loss.
The Mask R-CNN architecture has been instrumental in pushing the boundaries of what's possible in image-based tasks, particularly in instance segmentation. Its design reflects a deeper understanding of the challenges of these tasks, introducing key innovations that have since become standard in the field.
Practical Applications of Instance Segmentation
Instance segmentation, a nuanced approach within the computer vision domain, has revolutionized several industries by enabling more precise and detailed image analysis. Below, we delve into how this technology is making significant strides in medical imaging and autonomous vehicle systems.
Medical Imaging and Healthcare
In medical imaging, instance segmentation is pivotal in enhancing diagnostic precision. Creating clear boundaries at a granular level for the detailed study of medical images is crucial in identifying and diagnosing various health conditions.
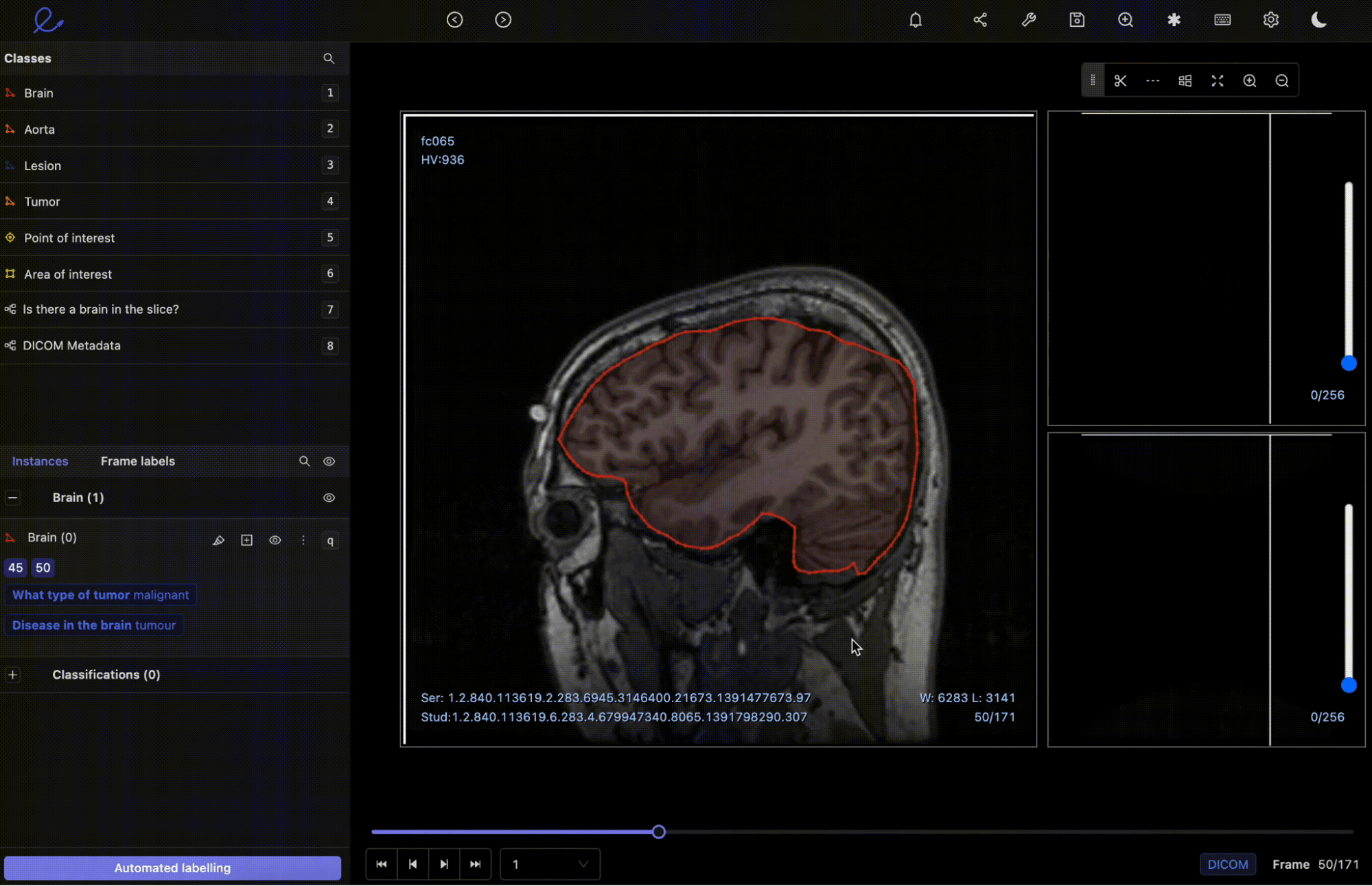
Medical Imaging within Encord Annotate’s DICOM Editor
- Precision in Diagnosis: Instance segmentation facilitates the detailed separation of structures in medical images, which is crucial for accurate diagnoses. For instance, segmenting individual structures can help radiologists precisely locate tumors, fractures, or other anomalies. This precision is vital, especially in complex fields such as oncology, neurology, and various surgical specializations.
- Case Studies: One notable application is in tumor detection and analysis. By employing instance segmentation, medical professionals can identify the presence of a tumor and understand its shape, size, and texture, which are critical factors in deciding the course of treatment. Similarly, in histopathology, instance segmentation helps in the detailed analysis of tissue samples, enabling pathologists to identify abnormal cell structures indicative of conditions such as cancer.
Autonomous Vehicles and Advanced Driving Assistance Systems
The advent of autonomous vehicles has underscored the need for advanced computer vision technologies, with instance segmentation being exceptionally crucial due to its ability to process complex visual environments in real-time.
- Real-time Processing Requirements: For autonomous vehicles, navigating through traffic and varying environmental conditions requires a system capable of real-time analysis. Instance segmentation contributes to this by enabling the vehicle's system to distinguish and identify individual objects on the road, such as other vehicles, pedestrians, and traffic signs. This detailed understanding is crucial for real-time decision-making and manoeuvring.
- Safety Enhancements Through Computer Vision: By providing detailed and precise image analysis, instance segmentation helps increase the safety features of autonomous driving systems. For example, suppose a pedestrian suddenly crosses the road. In that case, the system can accurately segment and identify the pedestrian as a separate entity, triggering an immediate response such as braking or swerving to avoid a collision.
This precision in identifying and reacting to various road elements significantly contributes to the safety and efficiency of autonomous transportation systems.
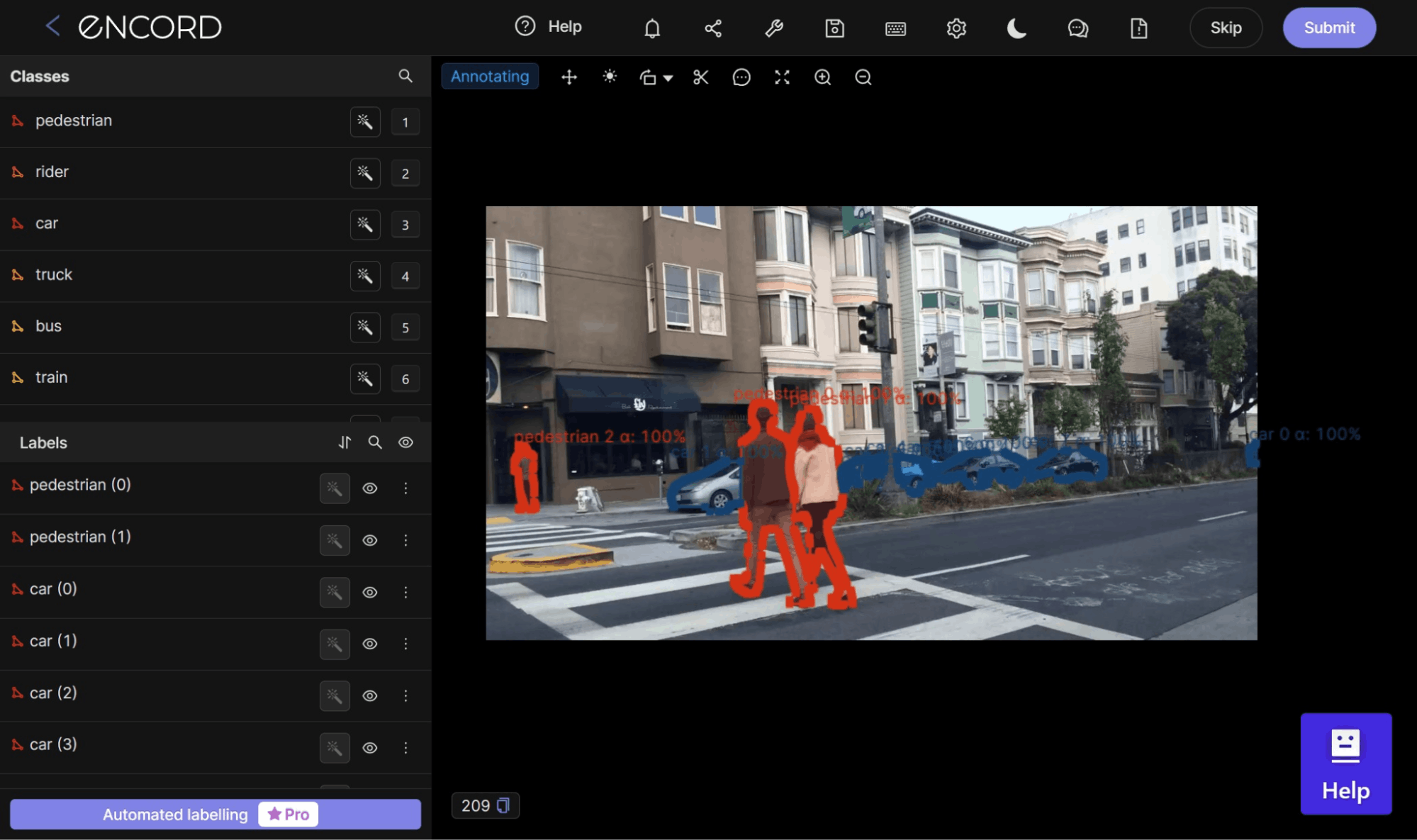
Challenges and Solutions in Instance Segmentation
Instance segmentation, while a powerful tool in computer vision, has its challenges. These obstacles often arise from the intricate nature of the task, which requires high precision in distinguishing and segmenting individual objects within an image, particularly when these objects overlap or are closely intertwined. Below, we explore some of these challenges and the innovative solutions being developed to overcome them.
Handling Overlapping Instances
One of the primary challenges in instance segmentation is managing scenes where objects overlap, making it difficult to discern boundaries. This complexity is compounded when dealing with objects of the same class, as the model must detect each object and provide a unique segmentation mask for each instance.
- The Role of Intersection over Union (IoU): IoU is a critical metric that provides a quantitative measure of the overlap between the predicted segmentation and the ground truth. By optimizing towards a higher IoU, models can improve their accuracy in distinguishing between separate objects, even when closely packed or overlapping.
- Techniques for Accurate Boundary Detection: Several strategies are employed to enhance boundary detection. One approach involves using edge detection algorithms as an auxiliary task to help the model better understand where one object ends and another begins. Additionally, employing more sophisticated loss functions that penalize inaccuracies in boundary prediction can drive the model to be more precise in its segmentation.
Addressing Sparse and Crowded Scenes
The instance segmentation models' quality heavily relies on the training data, which must be meticulously annotated to distinguish between different objects clearly.
- The Importance of Ground Truth in Training Models: For a model to understand the complex task of instance segmentation, it requires a solid foundation of 'ground truth' data. These images have been accurately annotated to indicate the exact boundaries of objects. The model uses this data during training, comparing its predictions against these ground truths to learn and improve.
- Time and Resource Constraints for Dataset Curation: Creating such datasets requires significant time and resources. Solutions to this challenge include using semi-automated annotation tools that leverage AI to speed up the process of employing data augmentation techniques to expand the dataset artificially. Furthermore, there's a growing trend towards collaborative annotation projects and sharing datasets within the research community to alleviate this burden.
The field of instance segmentation will continue to grow by tackling these problems head-on and coming up with new ways to build models and process data. This will make the technology more useful in real-world applications.
Instance Segmentation: Key Takeaways
As we conclude the complete guide to instance segmentation, it's crucial to synthesize the fundamental insights that characterize this intricate niche within the broader landscape of computer vision and deep learning.
- Recap of Core Concepts: At its core, instance segmentation is an advanced technique within image segmentation. It meticulously identifies, segments, and distinguishes between individual objects in an input image, even those within the same class label.
- Instance segmentation across industries: Instance segmentation is a key part of medical imaging. It helps practitioners make accurate diagnoses and plan effective treatments by making it easier to make decisions in real-time through better image analysis. Integrating instance segmentation into various industries underscores its versatility, from navigating self-driving cars through complex environments to optimizing retail operations through advanced computer vision tasks.
Frequently asked questions
Instance segmentation stands out in computer vision due to its intricate capability to identify individual objects within an input image down to the pixel level. Unlike standard object detection, which provides a bounding box for each object, or semantic segmentation, which classifies areas of an image at the pixel level without differentiating between object instances, instance segmentation is unique. It classifies every pixel of an object and differentiates each instance, making it invaluable for complex segmentation tasks that require more than just image classification.
Powered by libraries like TensorFlow and PyTorch, deep learning has revolutionized instance segmentation, particularly through structures like Convolutional Neural Networks (CNNs) and transformers. These models, which often utilize GPUs for accelerated computation, can process vast datasets, learning from the ground truth in annotated images. This results in an improvement in state-of-the-art instance segmentation accuracy. By understanding the feature map of each image, they can create precise segmentation masks, enhancing the boundary detection and classification of individual objects within segmentation tasks.
Instance segmentation, powered by deep learning and machine learning algorithms, finds diverse applications across various sectors. Medical imaging facilitates detailed diagnosis by segmenting individual structures in scans, often leveraging pre-trained models on datasets such as COCO for enhanced accuracy.
For autonomous vehicles, it's crucial for real-time decision-making, allowing the systems to understand their surroundings at the pixel level. Retail can enhance customer experiences through personalized interactions, and in agriculture, for instance, segmentation supports advanced monitoring for precision farming.
The field of instance segmentation is set for exponential growth, driven by advancements in AI, machine learning, and deep learning. We anticipate seeing its integration with augmented reality (AR) and virtual reality (VR), offering immersive experiences. Developing more efficient models, fine-tuning existing ones with techniques such as encoder-decoder architectures, and enhancing real-time processing capabilities are on the horizon. These advancements promise significant improvements in various computer vision tasks, including semantic and instance segmentation methods.
Yes, instance segmentation can be applied to video analysis. It identifies and segments individual objects in each video frame, useful in dynamic environments like video surveillance and autonomous driving.
Common methods include detection-based approaches like Mask R-CNN, single-shot methods such as YOLACT, and transformer-based techniques, each offering different balances of accuracy and speed.
Annotated data is crucial for training instance segmentation models, providing the necessary information for the model to learn how to accurately identify and delineate individual objects within images.
With the group management functionality in Encord, project admins can assign workforce managers who are responsible for onboarding users into groups. This eliminates the need for project admins to individually manage users across multiple projects, as changes to group membership automatically update access to all associated projects.
Encord's annotation platform offers automated tools that simplify the labeling of machine vision data, allowing users to easily apply bounding boxes for object detection or masks for segmentation. This can significantly reduce the time and effort spent on manual labeling, enhancing the overall efficiency of data preparation.
Encord provides advanced segmentation capabilities and a purpose-built solution to manage complex tasks efficiently. This includes flexible review capabilities that allow organizations to optimize task allocation, ensuring that expert resources are used effectively while minimizing unnecessary costs.
Encord supports various annotation techniques, including segmentation and keypoint annotations, which are essential for training advanced machine learning models. Our platform is designed to accommodate a range of annotation needs to meet the specific requirements of different projects.
Encord's SAM tool integrates seamlessly into the platform, allowing for efficient instance segmentation annotations. It leverages advanced capabilities to accelerate the labeling process, making it easier for users to achieve high-quality annotations in a shorter timeframe.
Encord supports various labeling types for segmentation tasks, including segmentation masks. Users can utilize these masks to annotate specific areas in videos and images, providing flexibility in their annotation approach and ensuring high-quality labeled datasets.
Encord offers robust tools for categorization and segmentation, allowing users to accurately label different elements within images. This capability is essential for training AI models in autonomy projects, facilitating better decision-making based on visual data.
Encord includes advanced features for segmentation labeling, such as the brush tool and the ability to overlay multiple segmentation layers. This functionality is crucial for applications like iris segmentation, allowing for precise and complex annotation tasks.
Encord provides various annotation options, including bounding boxes for image regions, classifications for content tags, and text region annotations. This versatility enables users to capture detailed insights and metrics from their media.
Encord supports various types of annotation, including labeling, segmentation, and object tracking. This flexibility allows teams to tailor their annotation strategies to fit the unique requirements of their projects.