Claude 3 | AI Model Suite: Introducing Opus, Sonnet, and Haiku

Joining the tech race of building AI chatbots with OpenAI’s ChatGPT, Google’s Gemini 1.5, or Le Chat of Mistral AI, Anthropic has introduced Claude. Claude is an AI assistant that helps manage organizations' tasks no matter the scale. The Claude 3 model family shows better performance than other SOTA models.
Claude 3 sets new benchmarks across reasoning, math, coding, multi-lingual understanding, and vision quality. Leveraging unsupervised learning and Constitutional AI, trained on AWS and GCP hardware with PyTorch, JAX, and Triton frameworks.
Claude 3’s AI Model Suite
Each large language model within the Claude 3 family is tailored to offer different combinations of capabilities, speed, and cost-effectiveness.
Claude 3 Opus
It is the most capable offering, achieving state-of-the-art results on benchmark evaluations across various domains such as reasoning, math, and coding. It sets new standards in performance and is suitable for applications requiring high levels of intelligence and processing power.
Claude 3 Sonnet
It provides a balance between skills and speed, offering strong performance in cognitive tasks while being more efficient in terms of processing time compared to Opus.
Claude 3 Haiku
It is the fastest and least expensive model in the family, suitable for applications where speed and cost-effectiveness are prioritized over absolute performance.
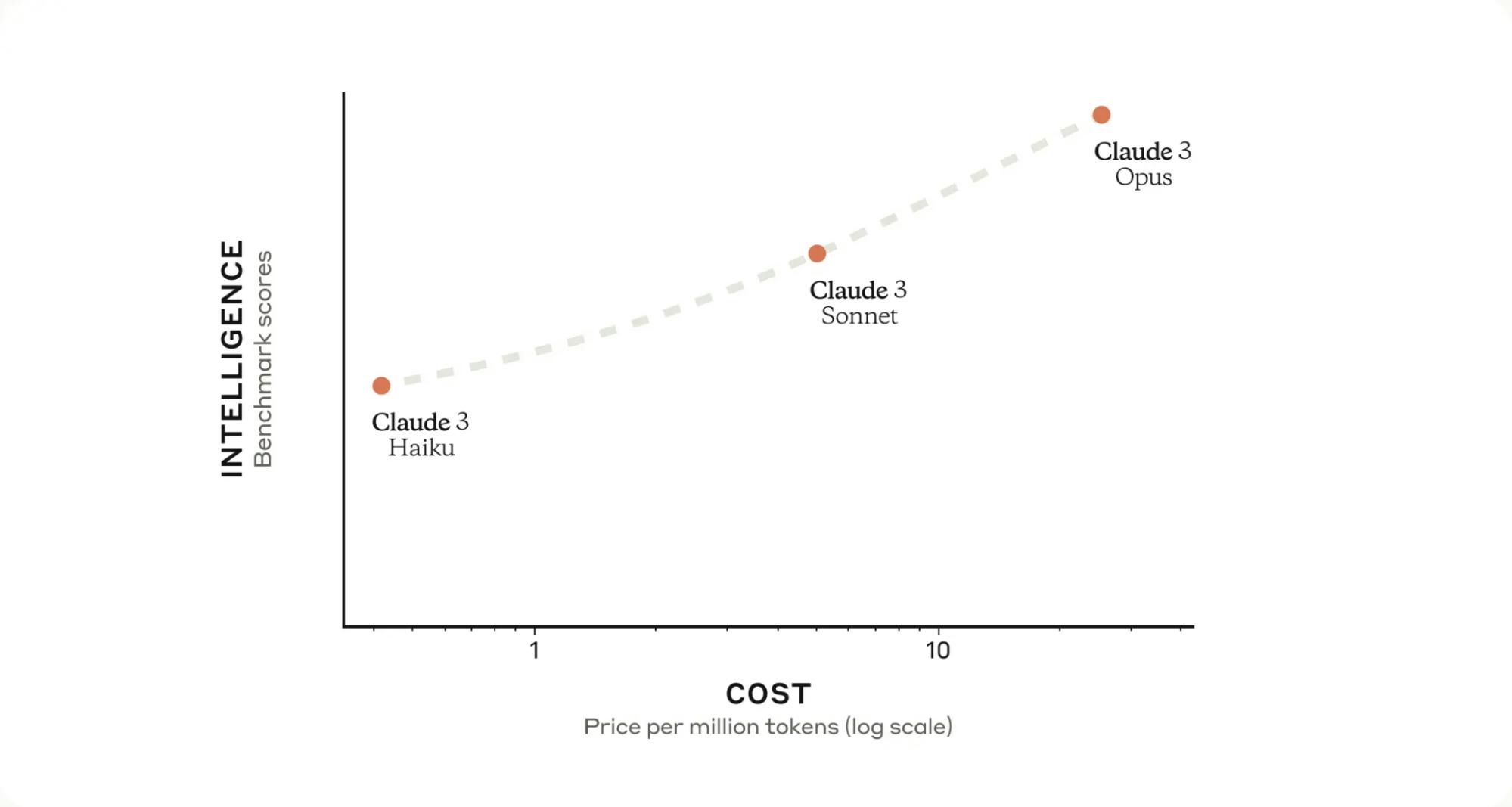
Intelligence Benchmark Scores Vs. Cost Comparison of Claude 3 Model Family
All models in the Claude 3 family come with vision capabilities for processing image data and exhibit improved fluency in non-English languages, making them versatile for a global audience.
Model Training Data and Process
The Claude 3 models are trained using a blend of publicly available internet data as of August 2023, along with public data from data labeling services and synthetic data generated internally. The training process involves several data cleaning and filtering methods, including deduplication and classification. The models are not trained on any user-submitted prompt or output data.

Anthropic follows industry practices when obtaining data from public web pages, respecting robots.txt instructions and other signals indicating whether crawling is permitted. The crawling system operates transparently, allowing website operators to identify Anthropic visits and signal their preferences.
The training of Claude 3 models emphasizes being helpful, harmless, and honest. Techniques include pretraining on diverse data sets for language capabilities and incorporating human feedback to elicit desirable responses.
Constitutional AI, including principles from sources like the UN Declaration of Human Rights, ensures alignment with human values. A principle promoting respect for disability rights is integrated into Claude's constitution. Human feedback data, including publicly available sources, is used for finetuning.
Performance Benchmark: Claude 3, GPT-4, GPT-3.5, Gemini Ultra, and Gemini Pro
Claude 3, particularly the Opus model, surpasses other state-of-the-art models in various evaluation benchmarks for AI tools. It excels in domains such as undergraduate and graduate-level expert knowledge (MMLU, GPQA), basic mathematics (GSM8K), and more. Opus demonstrates near-human levels of comprehension and fluency, positioning itself at the forefront of general intelligence.
Compared to other models like OpenAI’s GPT-4, GPT-3.5, Gemini Ultra, and Gemini Pro, Claude 3 models showcase enhanced capabilities in diverse areas. These include analysis and forecasting, nuanced content creation, code generation, and multilingual conversation proficiency in languages such as Spanish, Japanese, and French.
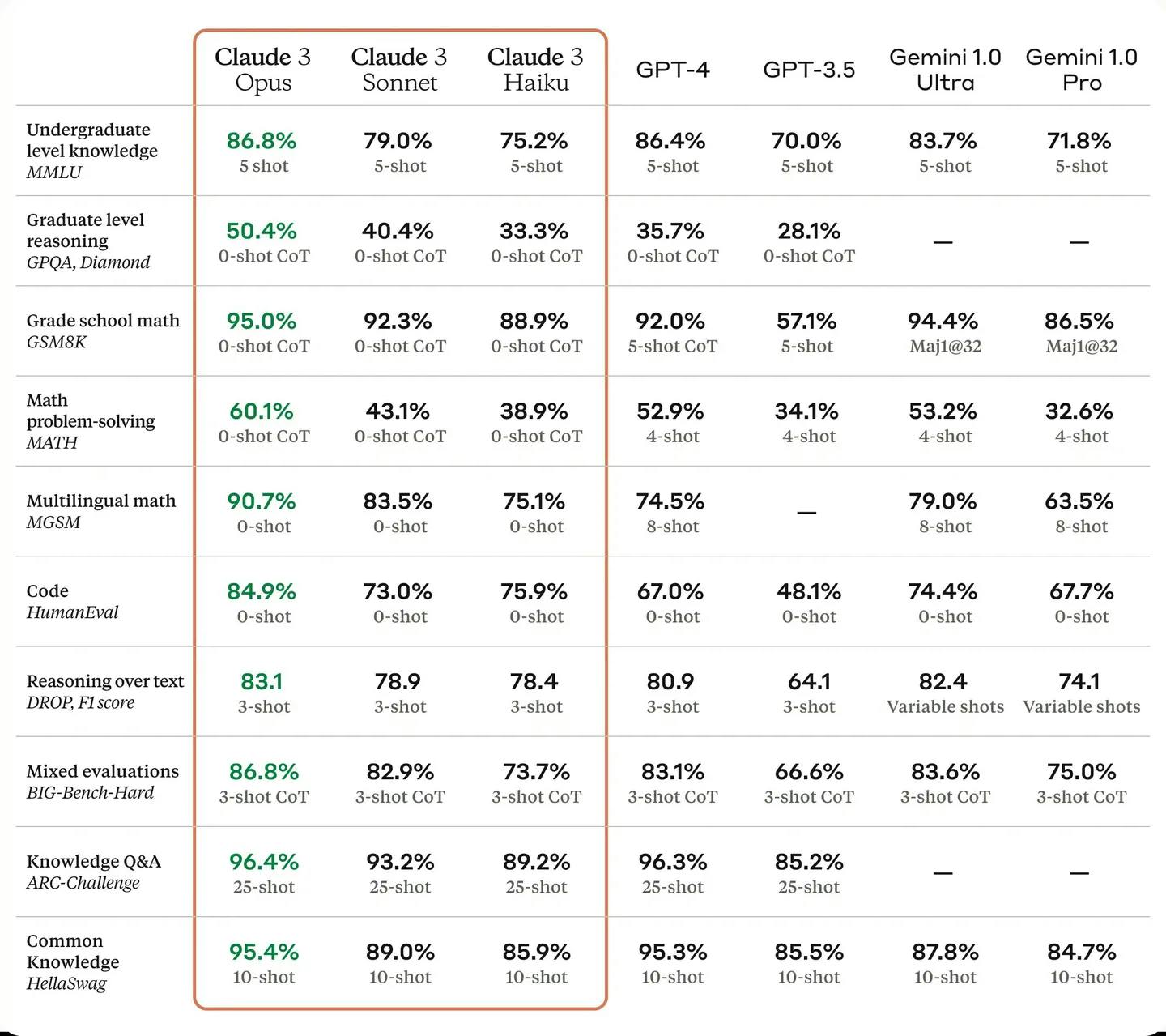
Performance Benchmark Scores of Claude 3 Model Family: Opus, Sonnet, Haiku
Claude 3 Capabilities
Vision Capabilities: Photos, Charts, Graphs and Technical Diagrams
The Claude 3 models are equipped to process and interpret visual information along with text inputs. The vision capabilities are particularly showcased in tasks like the AI2D science diagram benchmark and visual question answering. They excel in parsing scientific diagrams and achieving high accuracy rates in both zero-shot and few-shot settings.
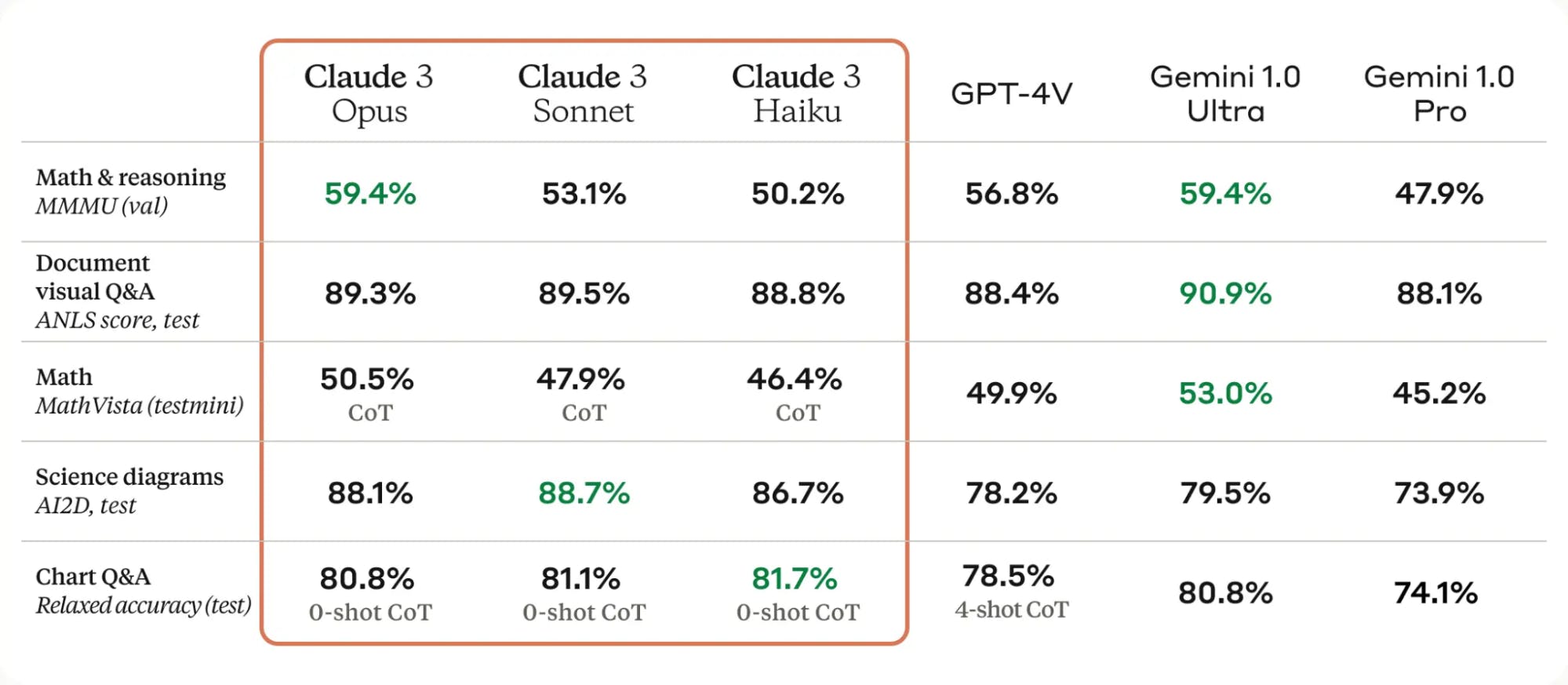
Evaluation Results on Multimodal Tasks
Trained on diverse visual data, Claude 3 models effectively interpret and analyze various visual content, enhancing their overall problem-solving capabilities for applications in fields like image understanding and multimodal reasoning.
Near Instant Model Results
Claude 3 models deliver near-instant results, ideal for live customer chats, auto-completions, and data extraction tasks. Haiku is the fastest and most cost-effective, processing dense research papers in under three seconds. Sonnet is twice as fast as previous versions, suitable for rapid tasks like knowledge retrieval. Opus matches previous speeds but with higher intelligence levels.
Multimodal
Claude 3 shows impressive multimodal capabilities, adept at processing diverse types of data. Claude 3 excels in visual question answering, demonstrating its capacity to understand and respond to queries based on images. It showcases strong quantitative reasoning skills by analyzing and deriving insights from visual data, enhancing its overall versatility across various tasks.
Multilingual Understanding
Claude 3 showcases robust multilingual capabilities, important for global accessibility. Evaluations highlight Claude 3 Opus's state-of-the-art performance in the Multilingual Math MGSM benchmark, achieving over 90% accuracy in a zero-shot setting. Human feedback shows significant improvement in Claude 3 Sonnet, indicating enhanced multilingual reasoning capabilities compared to previous versions.
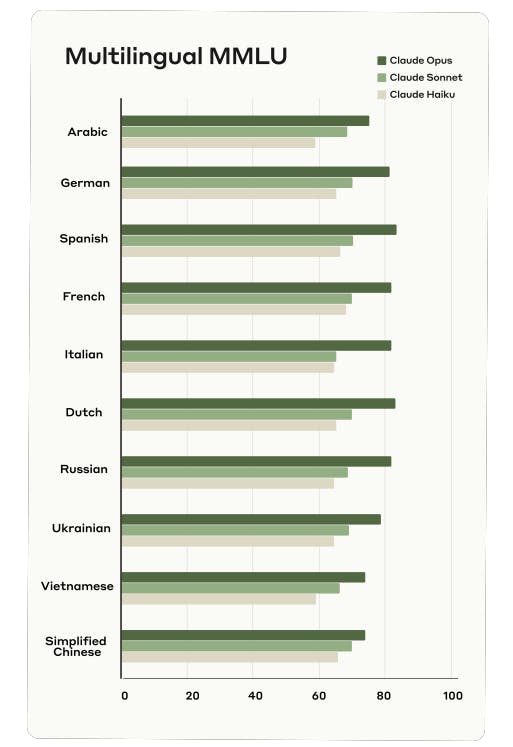
The Claude 3 Model Family: Multilingual Capabilities
Factual Accuracy
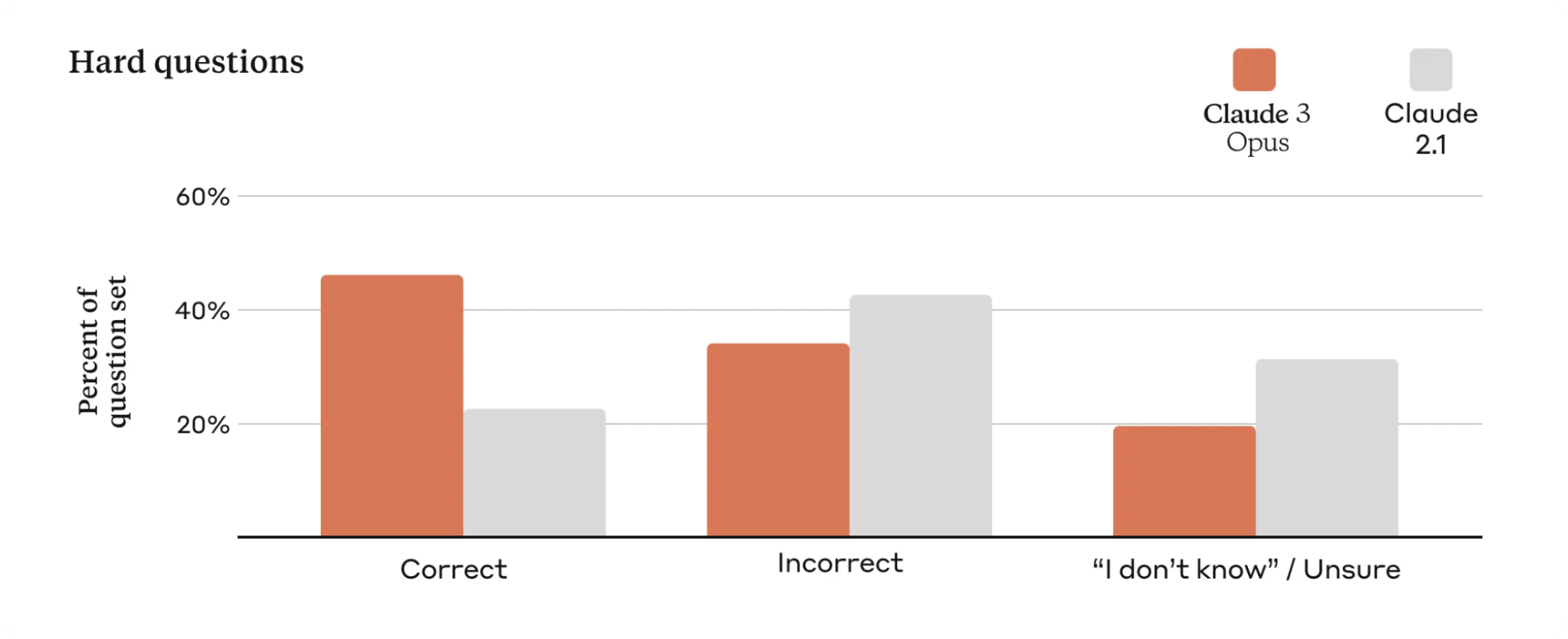
Claude 3 prioritizes factual accuracy through rigorous evaluations, including 100Q Hard and Multi-factual datasets. Tracking correctness, incorrect, and unsure responses, Claude 3 Opus significantly improves accuracy over previous versions.
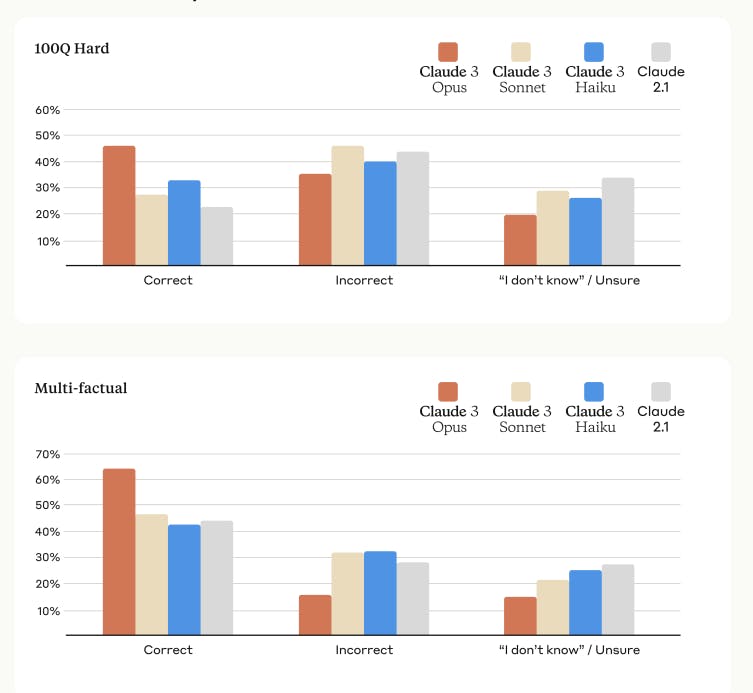
Factual Accuracy of Claude 3 Models Vs Claude 2.1
Reasoning and Mathematical Problem Solving
Claude 3 exhibits remarkable reasoning and mathematical problem-solving abilities, surpassing previous models in various benchmarks. In evaluations such as GPQA and MATH, Claude 3 Opus achieves significant improvements, although falling slightly short of expert-level accuracy. Leveraging techniques like chain-of-thought reasoning and majority voting further enhances performance, with Opus demonstrating impressive scores in both reasoning and mathematical problem-solving tasks, showcasing its advanced capabilities in these domains.
Near-human Comprehension
Claude 3 Sonnet outperforms its predecessors, Claude 2 and Claude Instant, in various core tasks, as assessed through direct comparisons by human raters. It excels in writing, coding, long document Q&A, non-English conversation, and instruction following.
Domain experts across finance, law, medicine, STEM, and philosophy prefer Sonnet in 60-80% of cases. Human feedback, although noisy, provides insights into user preferences that industry benchmarks may overlook. Using Elo scores, Sonnet shows a significant improvement of roughly 50-200 points over Claude 2 models in various subject areas.
Claude models exhibit high proficiency in open-ended conversation, coding tasks, and text-related operations like searching, writing, and summarizing. They also interpret visual input for enhanced productivity and maintain a helpful, conversational tone, described as steerable, adaptive, and engaging by users.
Claude's prediction mechanism constructs responses sequentially based on the input and past conversation, unable to edit previous responses or access external information beyond its context window, achieving near-human comprehension in various tasks.
Contextual Understanding and Fewer Refusals
Unlike previous versions, Claude 3 models are less likely to refuse to answer prompts that are within their capabilities and ethical boundaries. This improvement indicates a more refined understanding of context and a reduction in unnecessary refusals, enhancing their overall performance and usability.
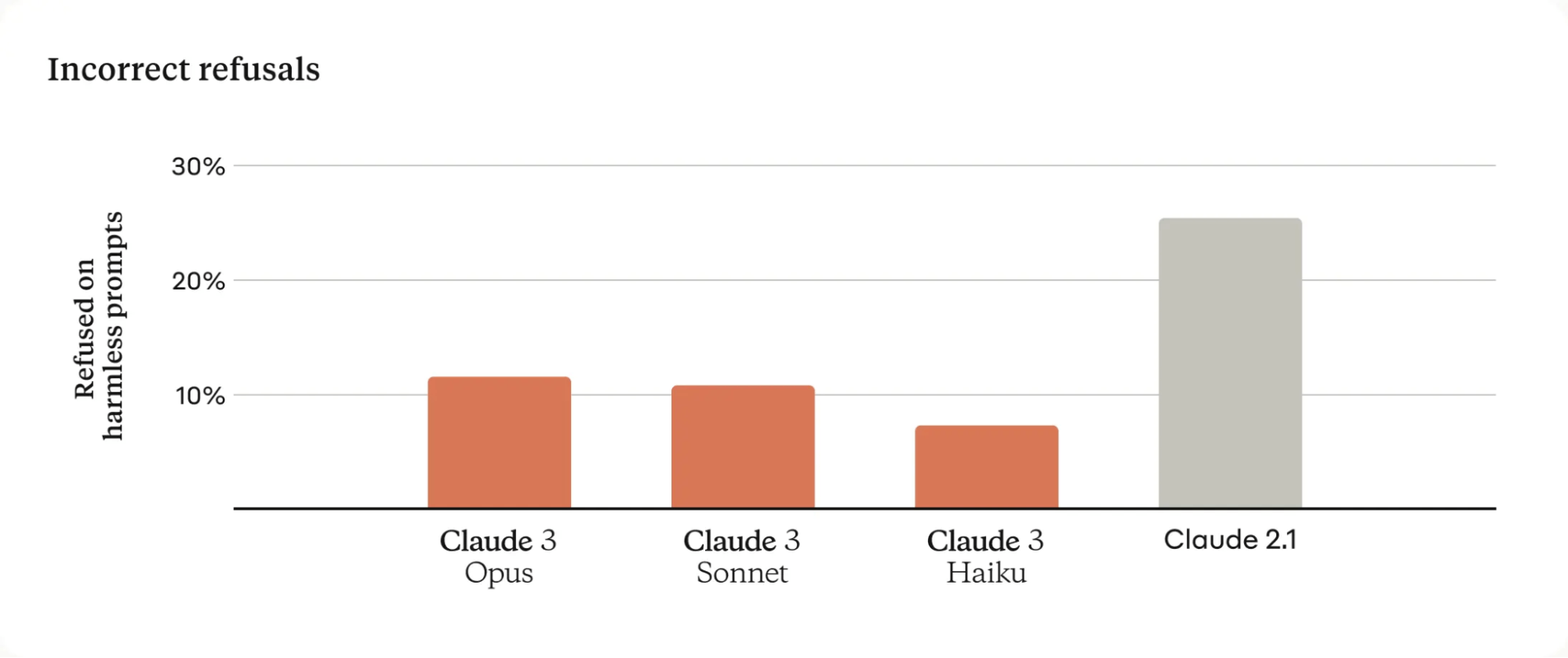
Comparison of Incorrect Refusals: Claude 3 Model Family Vs. Claude 2.1
Information Recall from Long Context
Claude 3's capability for information recall from long contexts is impressive, expanding from 100K to 200K tokens and supporting contexts up to 1M tokens. Despite challenges in reliable recall within long contexts, Claude 3 models, particularly Claude Opus, exhibit significant improvements in accurately retrieving specific information. In evaluations like Needle In A Haystack (NIAH), Claude Opus consistently achieves over 99% recall in documents of up to 200K tokens, highlighting its enhanced performance in information retrieval tasks.
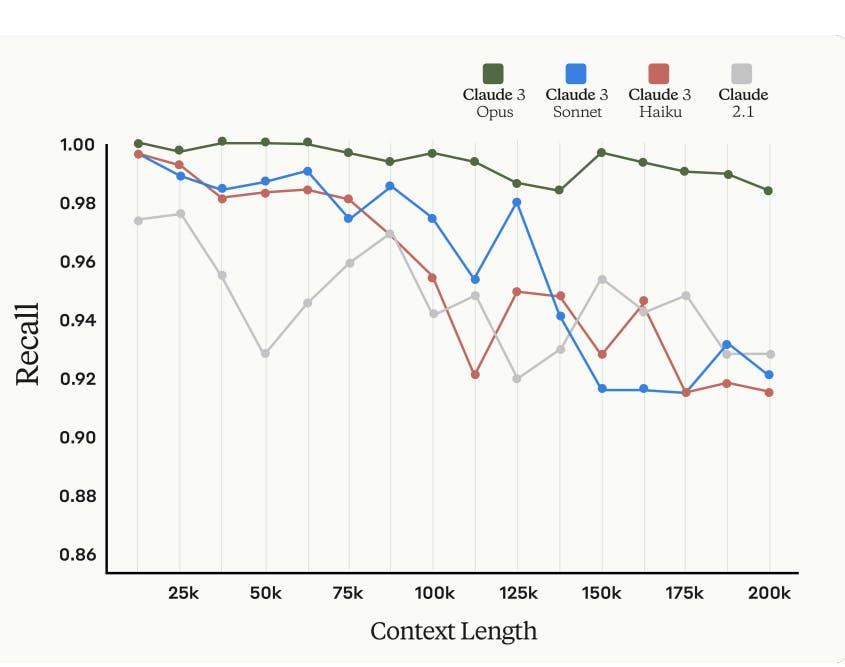
Information Recall: Claude 3 Model Family (Opus, Sonnet, Haiku) Vs. Claude 2
Improved Accuracy
Improved accuracy in Claude 3 models is important for businesses relying on them to serve customers at scale. Evaluation involves a large set of complex, factual questions targeting known weaknesses in previous models.
Accuracy Comparison: Claude 3 Model Family (Opus, Sonnet, Haiku) Vs. Claude 2
Claude 3 Opus demonstrates a twofold improvement in accuracy, reducing incorrect answers and admitting uncertainty when necessary. The upcoming features like citations will enhance trustworthiness by enabling precise verification of answers from reference material.
Model Details
Claude 3: Model Availability
Opus and Sonnet are currently available for use in the Anthropic API, enabling developers to sign up and start using these models immediately. Haiku will be available soon. Sonnet powers the free experience on claude.ai, while Opus is available for Claude Pro subscribers. Sonnet is available through Amazon Bedrock, with Opus and Haiku coming soon to both Amazon Bedrock and Google Cloud's Vertex AI Model Garden in a private preview.
Model Costs
Claude 3 Opus
Claude 3 Opus stands out as the most intelligent model, offering unparalleled performance on complex tasks. It excels in handling open-ended prompts and navigating sight-unseen scenarios with remarkable fluency and human-like understanding, showcasing the outer limits of generative AI. However, this high intelligence comes at a higher cost of $15 per million input tokens and $75 per million output tokens. The context window for Opus is 200K tokens, and it is suitable for tasks such as task automation, research and development, and advanced strategic analysis.
Claude 3 Sonnet
Claude 3 Sonnet, on the other hand, strikes a balance between intelligence and speed, making it ideal for enterprise workloads. It offers strong performance at a lower cost compared to its peers, with rates of $3 per million input tokens and $15 per million output tokens. Sonnet's context window is also 200K tokens, and it is suitable for data processing, sales tasks, and time-saving operations like code generation.
Claude 3 Haiku
Claude 3 Haiku is the fastest and most compact model, designed for near-instant responsiveness. It excels in handling simple queries and requests with unmatched speed and affordability, costing $0.25 per million input tokens and $1.25 per million output tokens. Haiku's context window is also 200K tokens, and it is suitable for tasks like customer interactions, content moderation, and cost-saving operations.
Responsible Design
Risk Mitigation
Dedicated teams continuously track and mitigate various risks, including misinformation, harmful content, and potential misuse in areas such as biological information, election integrity, and autonomous replication.
Bias Reduction
Ongoing efforts focus on reducing biases in model outputs, with Claude 3 demonstrating decreased biases compared to previous models, as measured by the Bias Benchmark for Question Answering (BBQ).
Model Neutrality
Advanced methods such as Constitutional AI enhance model transparency and neutrality, guaranteeing that results are not biased toward any one political position.
Responsible Scaling Policy
Claude 3 models are classified at AI Safety Level 2 (ASL-2) under the Responsible Scaling Policy, with rigorous evaluations affirming minimal potential for catastrophic risks at present. Future models will be closely monitored to assess their proximity to ASL-3.
Claude 3: What’s Next
Here is what to expect from the new models of Anthropic’s Claude:
Feature Updates for Enterprise Use Case
- Tool Use or Function Calling: Development is underway to enable Claude 3 to utilize functions, allowing for more advanced task automation and data processing.
- REPL or Interactive Coding: Claude 3 will soon support an interactive coding environment, providing users with the ability to engage in real-time code execution and debugging.
- Advanced Agentic Capabilities: Explorations are ongoing to equip Claude 3 with more advanced agentic capabilities, facilitating seamless interaction with users and autonomous execution of complex tasks.
- Large-scale Deployments: Optimization efforts are being made to ensure Claude 3 is suitable for large-scale deployments, enabling it to handle high volumes of requests while maintaining performance and reliability in enterprise settings.
- Safety Guardrails with Feature Advancements: In line with feature updates, Claude 3 is also working on its safety protocols to mitigate risks and promote responsible usage. At the same time, the focus remains on leveraging these advancements to foster positive societal outcomes, allowing users to achieve their goals ethically and efficiently while upholding principles of fairness, transparency, and accountability in artificial intelligence.
Frequently asked questions
Claude 3 is available for use, with models like Opus and Sonnet accessible through the Claude.ai platform and Anthropic API. Haiku will be available soon.
Claude 3 finds application across various sectors, including customer service, research, sales, content moderation, and data processing, among others. Its capabilities span from answering complex queries to facilitating task automation and forecasting.
Claude 3 addresses ethical concerns and biases by continuously improving safety guardrails, implementing feature enhancements, and striving for fairness, transparency, and accountability in AI usage. It undergoes rigorous evaluation and bias reduction efforts to ensure responsible deployment.
Currently, a free version of Claude 3, powered by Sonnet, is available on claude.ai for users to experience its capabilities. Opus is accessible for Claude Pro subscribers. Haiku will also be included in the offering soon.
Claude 3 has been implemented across industries for various tasks, including research review, coding, customer support, product recommendations, and more. Notable industries leveraging its capabilities in evaluation include finance, law, medicine, STEM, and philosophy, among others, with promising outcomes.
Claude 3 demonstrates near-human comprehension and fluency, achieving outstanding performance on complex tasks across multiple benchmarks. It excels in tasks such as undergraduate and graduate level expert knowledge, mathematics, reasoning, coding, and more, surpassing its predecessors and setting new standards in AI.
Claude 3's near-human capabilities are empowered by breakthrough technologies such as multimodal capabilities, enhanced contextual understanding, and advanced reasoning abilities. It leverages large context windows, improved language understanding, and innovative training methodologies to achieve remarkable fluency and intelligence.
Encord requires individual user setup for team members. This ensures that each user has the necessary permissions and access tailored to their roles within the project, which is particularly important for larger teams participating in pilot programs.