Stable Diffusion 3: Multimodal Diffusion Transformer Model Explained

Stable Diffusion 3 is the latest version of the Stable Diffusion models. Stable Diffusion is built for text-to-image generation, leveraging a latent diffusion model trained on 512x512 images from a subset of the LAION-5B database. Supported by a generous compute donation from Stability AI and backing from LAION, this model combines a latent diffusion approach with a frozen CLIP ViT-L/14 text encoder for conditioning on text prompts.
Exploring Stable Diffusion 3: Text-to-Image Model
One of the notable features of SD3 is its architecture, which includes a Multimodal Diffusion Transformer (MMDiT). This architecture utilizes separate sets of weights for image and language representations, leading to improved text understanding and spelling capabilities compared to previous versions of SD3.
The core architecture of Stable Diffusion 3 is based on a diffusion transformer architecture combined with flow matching techniques. This combination allows for the efficient and effective generation of high-quality images conditioned on textual input.
Stable Diffusion 3 models vary in size, ranging from 800 million to 8 billion parameters, to cater to different needs for scalability and quality in generating images from text prompts.

The goal of Stable Diffusion 3 is to align with the core values of the development team, including democratizing access to AI technologies. By offering open-source models of varying sizes and capabilities, Stable Diffusion 3 aims to provide users with a range of options to meet their creative needs, whether they require faster processing times or higher image quality.
Let’s dive into the two core concepts of Stable Diffusion 3:
Diffusion Transformer (DiT)
Diffusion Transformers or DiTs are a class of diffusion models that utilize transformer architecture for the generation of images. Unlike traditional approaches that rely on the U-Net backbone, DiTs operate on latent patches, offering improved scalability and performance.

Images were generated using Diffusion Transformer
Through an analysis of scalability using metrics such as Gflops (floating point operations per second), it has been observed that diffusion transformers (DiTs) with higher Gflops, achieved through increased transformer depth/width or a higher number of input tokens, consistently exhibit lower Frechet Inception Distance (FID). This implies improved performance in terms of image quality.
While transformers have gained popularity in fields like natural language processing (NLP) and computer vision tasks, their use in image-level generative models has been limited. This tendency is reflected in the general preference for convolutional U-Net architecture in diffusion models. But U-Net's inductive bias doesn’t necessarily make it the best choice for diffusion models, prompting researchers to explore alternative architectures such as transformers.
Inspired by Vision Transformers, DiTs ensure scalability, efficiency, and high-quality sample generation, making them a good option for generative modeling.
Flow Matching: A Model Training Technique
The core concept of Flow Matching (FM) redefines Continuous Normalizing Flows (CNFs) by focusing on regressing vector fields of fixed conditional probability paths, eliminating the need for simulations.
FM is versatile and can accommodate various types of Gaussian probability paths, including traditional diffusion paths used in diffusion models. It provides a robust and stable alternative for training diffusion models, which are commonly used in generative modeling tasks.
Empirical evaluations on ImageNet, a widely used dataset for image classification tasks, demonstrate that FM consistently outperforms traditional diffusion-based methods in terms of both likelihood (how probable the generated samples are) and sample quality. Moreover, FM enables fast and reliable sample generation using existing numerical Ordinary Differential Equation (ODE) solvers.
Stable Diffusion 3 Architecture
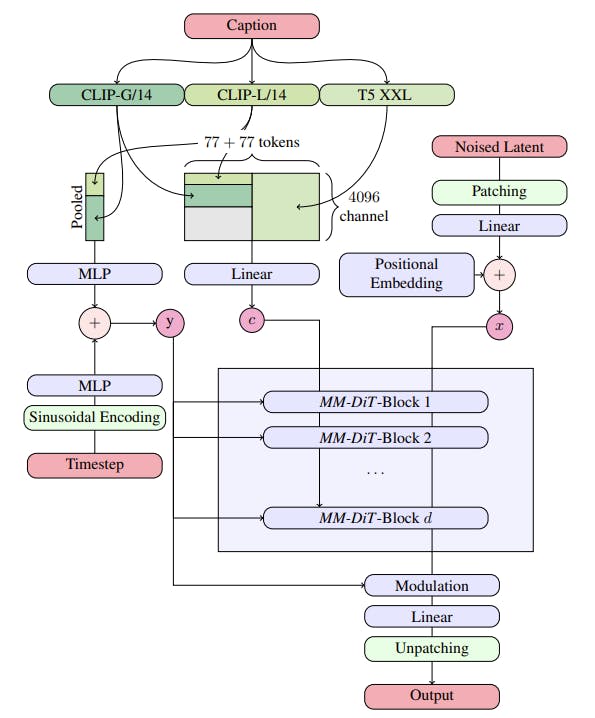
Overview of Stable Diffusion 3’s architecture
The architecture of Stable Diffusion 3 incorporates both text and image modalities, leveraging pretrained models to derive suitable representations for each. Here's a breakdown of the key components and mechanisms involved:
General Setup
SD3 follows the framework of Latent Diffusion Models (LDM) for training text-to-image models in the latent space of a pretrained autoencoder. Text conditioning is encoded using pretrained, frozen text models, similar to previous approaches.
Multi-Modal Diffusion Transformer (MMDiT)
SD3's architecture builds upon the DiT (Diffusion Transformer) architecture, which focuses on class conditional image generation. In SD3, embeddings of the timestep and text conditioning are used as inputs to the modulation mechanism, enabling conditional generation. To address the coarse-grained nature of pooled text representations, SD3 incorporates information from the sequence representation of text inputs.
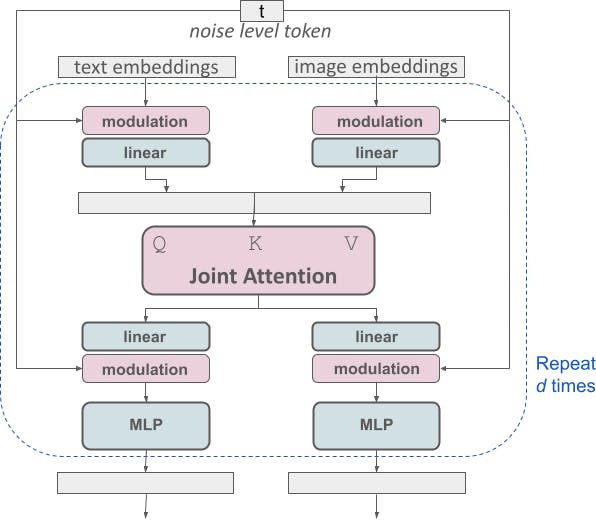
Scaling Rectified Flow Transformers for High-Resolution Image Synthesis
Sequence Construction
SD3 constructs a sequence comprising embeddings of both text and image inputs. This sequence includes positional encodings and flattened patches of the latent pixel representation. After embedding and concatenating the patch encoding and text encoding to a common dimensionality, SD3 applies a sequence of modulated attention and Multi-Layer Perceptrons (MLPs).
Weights of Each Modality
Given the conceptual differences between text and image embeddings, SD3 employs separate sets of weights for each modality. While using two independent transformers for each modality, SD3 combines the sequences of both modalities for the attention operation, enabling both representations to work in their respective spaces while considering each other.
Experiments on SD3 to Improve Performance
Improving Rectified Flows by Reweighting
Stable Diffusion 3 adopts a Rectified Flow (RF) formulation, connecting data and noise on a linear trajectory during training. This approach results in straighter inference paths, enabling sampling with fewer steps.
SD3 introduces a trajectory sampling schedule, assigning more weight to the middle parts of the trajectory to tackle more challenging prediction tasks. Comparative tests against 60 other diffusion trajectories, including LDM, EDM, and ADM, across multiple datasets, metrics, and sampler settings, demonstrate the consistent performance improvement of the re-weighted RF variant.
Scaling Rectified Flow Transformer Models
A scaling study is conducted for text-to-image synthesis using the reweighted Rectified Flow formulation and MMDiT backbone. Models ranging from 15 blocks with 450M parameters to 38 blocks with 8B parameters exhibit a smooth decrease in validation loss with increasing model size and training steps.
Evaluation using automatic image-alignment metrics (GenEval) and human preference scores (ELO) demonstrates a strong correlation between these metrics and validation loss, suggesting the latter as a robust predictor of overall model performance. The scaling trend shows no signs of saturation, indicating potential for further performance improvement in the future.
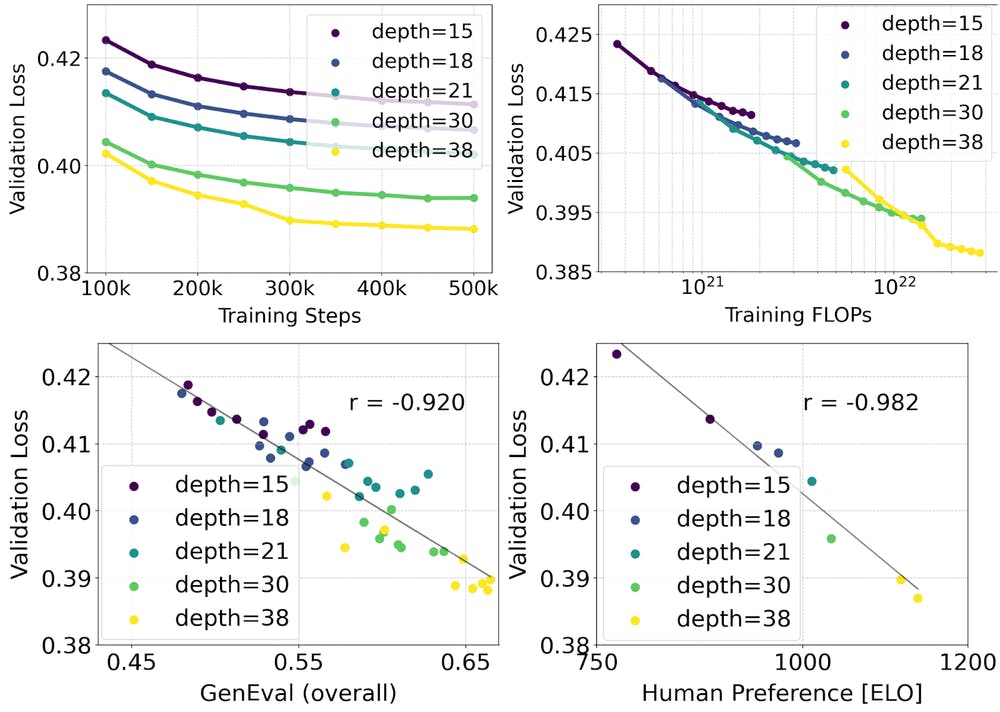
Scaling Rectified Flow Transformers for High-Resolution Image Synthesis
Flexible Text Encoders
Stable Diffusion 3 optimizes memory usage by removing the memory-intensive 4.7B parameter T5 text encoder for inference, resulting in significantly reduced memory requirements with minimal performance loss. The removal of the text encoder does not impact visual aesthetics, with a win rate of 50%, but slightly reduces text adherence with a win rate of 46%. However, it is recommended to include T5 for full power in generating written text, as typography generation experiences larger performance drops without it, with a win rate of 38%.

Scaling Rectified Flow Transformers for High-Resolution Image Synthesis.
Capabilities of Stable Diffusion 3 (SD3)
Though we know very little about the capabilities of stable diffusion 3, here is what we can interpret based on the sample results shared:
Multi-Subject Prompt Handling
In text-to-image generation, multi-subject prompts include detailed descriptions of scenes, compositions, or scenarios involving more than one object, person, or concept. These prompts provide rich and complex information for the model to generate corresponding images that accurately represent the described scene or scenario. Handling multi-subject prompts effectively requires the text-to-image model to understand and interpret the relationships between different subjects mentioned in the prompt to generate coherent and realistic images.
Prompt
A painting of an astronaut riding a pig wearing a tutu holding a pink umbrella, on the ground next to the pig is a robin bird wearing a top hat, and in the corner are the words "stable diffusion"
SD3 Output

Text Rendering
SD3 works well in accurately rendering text within generated images, ensuring that textual elements such as fonts, styles, and sizes are represented properly. This capability enhances the integration of text-based descriptions into the generated imagery, contributing to a seamless and cohesive visual narrative.
Prompt
Graffiti on the wall with the text "When SD3?"
SD3 Output

Fine Detail Representation
SD3 delivers superior image quality compared to previous models. This improvement ensures that the generated images are more detailed, realistic, and visually appealing.
Prompt
Studio photograph closeup of a chameleon over a black background
SD3 Output

Prompt Adherence
SD3 demonstrates strong adherence to provided prompts, ensuring that the generated images accurately reflect the details and specifications outlined in the input text. This enhances the creation of desired visual content with minimal deviation from the intended concept or scene.
Prompt
Night photo of a sports car with the text "SD3" on the side, the car is on a race track at high speed, a huge road sign with the text "faster"
SD3 Output

Photorealism
SD3 excels in producing images with high fidelity and photorealism, surpassing previous iterations in capturing fine details and textures. Its generated images closely resemble real-world photographs or hand-drawn artwork, imbuing them with a sense of authenticity.
Prompt
Fisheye lens photo where waves hit a lighthouse in Scotland, black waves.
SD3 Output

Performance of Stable Diffusion 3
Based on comprehensive evaluations comparing Stable Diffusion 3 with various open and closed-source text-to-image generation models, including SDXL, SDXL Turbo, Stable Cascade, Playground v2.5, Pixart-α, DALL·E 3, Midjourney v6, and Ideogram v1, SD3 emerges as a standout performer across multiple criteria.
Human evaluators assessed output images from each model based on prompt following, typography quality, and visual aesthetics. In all these areas, Stable Diffusion 3 either matches or surpasses current state-of-the-art text-to-image generation systems.
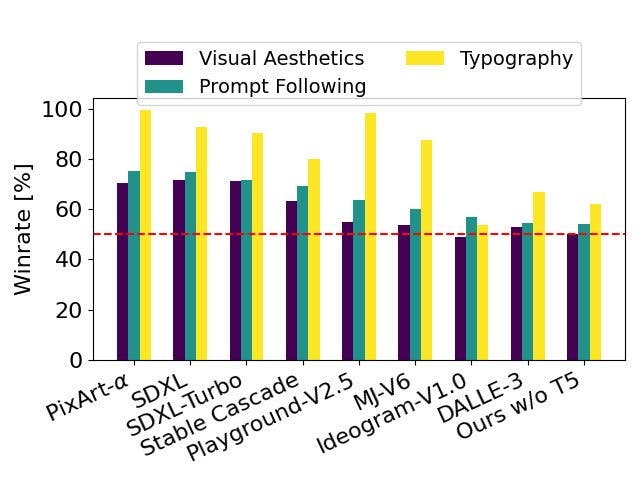
Comparison of baseline SD3 against other SOTA text-to-image generation models
Even in early, unoptimized inference tests on consumer hardware, the largest SD3 model with 8B parameters demonstrates impressive performance, states Stability AI. It fits within the 24GB VRAM of an RTX 4090 and generates a 1024x1024 resolution image in just 34 seconds using 50 sampling steps.
Stability AI also states that the initial release of Stable Diffusion 3 will offer multiple variations, ranging from 800 million to 8 billion parameter models, to ensure accessibility and eliminate hardware barriers for users.
Comparative Performance Analysis: Stable Diffusion 3, Dalle-3, and Midjourney
Here are the few experiments we carried out to compare the three popular text-to-image generation models based on the results shared by Stability AI.
Text Generation Prompt
Epic anime artwork of a wizard atop a mountain at night casting a cosmic spell into the dark sky that says "Stable Diffusion 3" made out of colorful energy
Text Generation Output - Stable Diffusion 3 (SD 3)

Text Generation Output - Dalle-3

Text Generation Output - Midjourney

Multi-Subject Prompt
Resting on the kitchen table is an embroidered cloth with the text 'good night' and an embroidered baby tiger. Next to the cloth, there is a lit candle. The lighting is dim and dramatic.
Multi-Subject Text Prompt Output - Stable Diffusion 3 (SD 3)

Multi-Subject Prompt Output - Dalle-3

Multi-Subject Prompt Output - Midjourney

Text Stylization Prompt
Photo of a 90's desktop computer on a work desk, on the computer screen it says "welcome". On the wall in the background we see beautiful graffiti with the text "SD3" very large on the wall.
Text Stylization Prompt Output - Stable Diffusion 3

Dalle-3

Midjourney

SD3: Responsible AI Practices
As Stable Diffusion plans on releasing the model weights and training procedure as open source shortly, it commits to safe and responsible AI practices at every stage. From the model's initial training to its testing, evaluation, and eventual release, SD3 aims to prevent its misuse by bad actors.
To uphold these standards, SD3 has implemented various safeguards in preparation for the early preview of Stable Diffusion 3. These measures include continuous collaboration with researchers, experts, and the community to innovate further with integrity. Through this ongoing collaboration, SD3 aims to ensure that its generative AI remains open, safe, and universally accessible.
Potential Drawbacks
The Stable Diffusion 3 models have made significant advancements, but they still could have some limitations. The paper doesn’t mention any limitations of the models. But here are some possible limitations that are common in text-to-image generation models:
Fidelity and Realism
Generated images may lack fidelity and realism compared to real-world photographs or hand-drawn artwork. Fine details and textures may not be accurately represented, resulting in images that appear artificial or "uncanny."
For example, the image below lacks fine details like the shadow underneath the bus suggesting light coming from behind it, and the shadow of a building on the street indicating light coming from the left of the image.

Ambiguity
Text descriptions can sometimes be ambiguous or subjective, leading to varied interpretations by the model. This ambiguity can result in generated images that may not fully capture the intended scene or elements described in the text.
Contextual Understanding
Text-to-image models may struggle with understanding contextual nuances and cultural references, leading to inaccuracies or misinterpretations in the generated images. For example, understanding metaphors or abstract concepts described in the text may pose challenges for the model.
Resource Intensiveness
Training and running text-to-image generation models can be computationally intensive and require significant computational resources, including high-performance GPUs or TPUs. This limitation can impact the scalability and accessibility of these models for widespread use.
TripoSR: 3D Object Generation from Single
Along with their SOTA text-to-image generation model, Stability AI also released TripoSR, a fast 3D object reconstruction model.

TripoSR: Fast 3D Object Reconstruction from a Single Image
TripoSR generates high-quality 3D models from a single image in under a second, making it incredibly fast and practical for various applications. Unlike other models, TripoSR operates efficiently even without a GPU, ensuring accessibility for a wide range of users. The model weights and source code are available for download under the MIT license, allowing for commercial, personal, and research use.
Inspired by the Large Reconstruction Model For Single Image to 3D (LRM), TripoSR caters to the needs of professionals in entertainment, gaming, industrial design, and architecture. It offers responsive outputs for visualizing detailed 3D objects, creating detailed models in a fraction of the time of other models.
Tested on an Nvidia A100, TripoSR generates draft-quality 3D outputs (textured meshes) in around 0.5 seconds, outperforming other open image-to-3D models like OpenLRM.
Stable Diffusion 3: Key Highlights
- Multimodal Diffusion Transformer Architecture: SD3's innovative architecture incorporates separate sets of weights for image and language representations, resulting in improved text understanding and spelling capabilities compared to previous versions.
- Superior Performance: In comparative evaluations, SD3 has demonstrated superior performance when compared to state-of-the-art text-to-image generation systems such as DALL·E 3, Midjourney v6, and Ideogram v1. Human preference evaluations have highlighted advancements in typography and prompt adherence, setting a new standard in this field.
- Scalability and Flexibility: SD3 offers models of varying sizes, ranging from 800 million to 8 billion parameters, to cater to different needs for scalability and image quality. This flexibility ensures that users can select models that best suit their creative requirements.
- Open-Source Models: SD3 offers different choices and improvements in creating images from text. This openness fosters collaboration and innovation within the AI community while promoting transparency and accessibility in AI technologies.
Frequently asked questions
Yes, Stable Diffusion 3 will be made open-sourced anytime soon.
Stable Diffusion 3 enhances the handling of complex artistic styles and genres by refining its contextual understanding and visual coherence. It achieves this by integrating the multimodal diffusion transformer architecture and flow matching training methodologies, resulting in more accurate and contextually relevant image generation.
Stable Diffusion 3 operates by leveraging a latent diffusion approach combined with a Multimodal Diffusion Transformer architecture. This architecture allows the model to generate high-quality images from textual descriptions by encoding text prompts and synthesizing corresponding images with advanced algorithms and techniques.
Stable Diffusion 3 prioritizes user privacy and data security through robust encryption protocols and strict adherence to data protection regulations. When processing sensitive or proprietary input prompts, the model ensures that user data remains confidential and is not shared or accessed without proper authorization.
Stable Diffusion 3 addresses safety concerns through continuous monitoring and refinement of its algorithms and training data. It implements safeguards to prevent the generation of inappropriate or harmful content, collaborating with experts and researchers to develop responsible AI practices and mitigate potential misuse by bad actors.
Encord focuses on stability by providing robust connections to blob storage and ensuring reliable access to images and data. This is crucial for users who need to maintain consistent data flow in their projects.