What is Ensemble Learning?

Imagine you are watching a football match. The sports analysts provide you with detailed statistics and expert opinions. At the same time, you also take into account the opinions of fellow enthusiasts who may have witnessed previous matches. This approach helps overcome the limitations of relying solely on one model and increases overall accuracy. Similarly, in ensemble learning, combining multiple models or algorithms can improve prediction accuracy.
In both cases, the power of collective knowledge and multiple viewpoints is harnessed to make more informed and reliable predictions, overcoming the limitations of relying solely on one model. Let us take a deeper dive into what Ensemble Learning actually is.
Ensemble learning is a machine learning technique that improves the performance of machine learning models by combining predictions from multiple models. By leveraging the strengths of diverse algorithms, ensemble methods aim to reduce both bias and variance, resulting in more reliable predictions. It also increases the model’s robustness to errors and uncertainties, especially in critical applications like healthcare or finance.
Ensemble learning techniques like bagging, boosting, and stacking enhance performance and reliability, making them valuable for teams that want to build reliable ML systems.
This article highlights the benefits of ensemble learning for reducing bias and improving predictive model accuracy. It highlights techniques to identify and manage uncertainties, leading to more reliable risk assessments, and provides guidance on applying ensemble learning to predictive modeling tasks.
Here, we will address the following topics:
- Brief overview
- Ensemble learning techniques
- Benefits of ensemble learning
- Challenges and considerations
- Applications of ensemble learning
Types of Ensemble Learning
Ensemble learning differs from deep learning; the latter focuses on complex pattern recognition tasks through hierarchical feature learning. Ensemble techniques, such as bagging, boosting, stacking, and voting, address different aspects of model training to enhance prediction accuracy and robustness.
These techniques aim to reduce bias and variance in individual models, and improve prediction accuracy by learning previous errors, ultimately leading to a consensus prediction that is often more reliable than any single model.
The main challenge is not to obtain highly accurate base models but to obtain base models that make different kinds of errors. If ensembles are used for classification, high accuracies can be achieved if different base models misclassify different training examples, even if the base classifier accuracy is low.
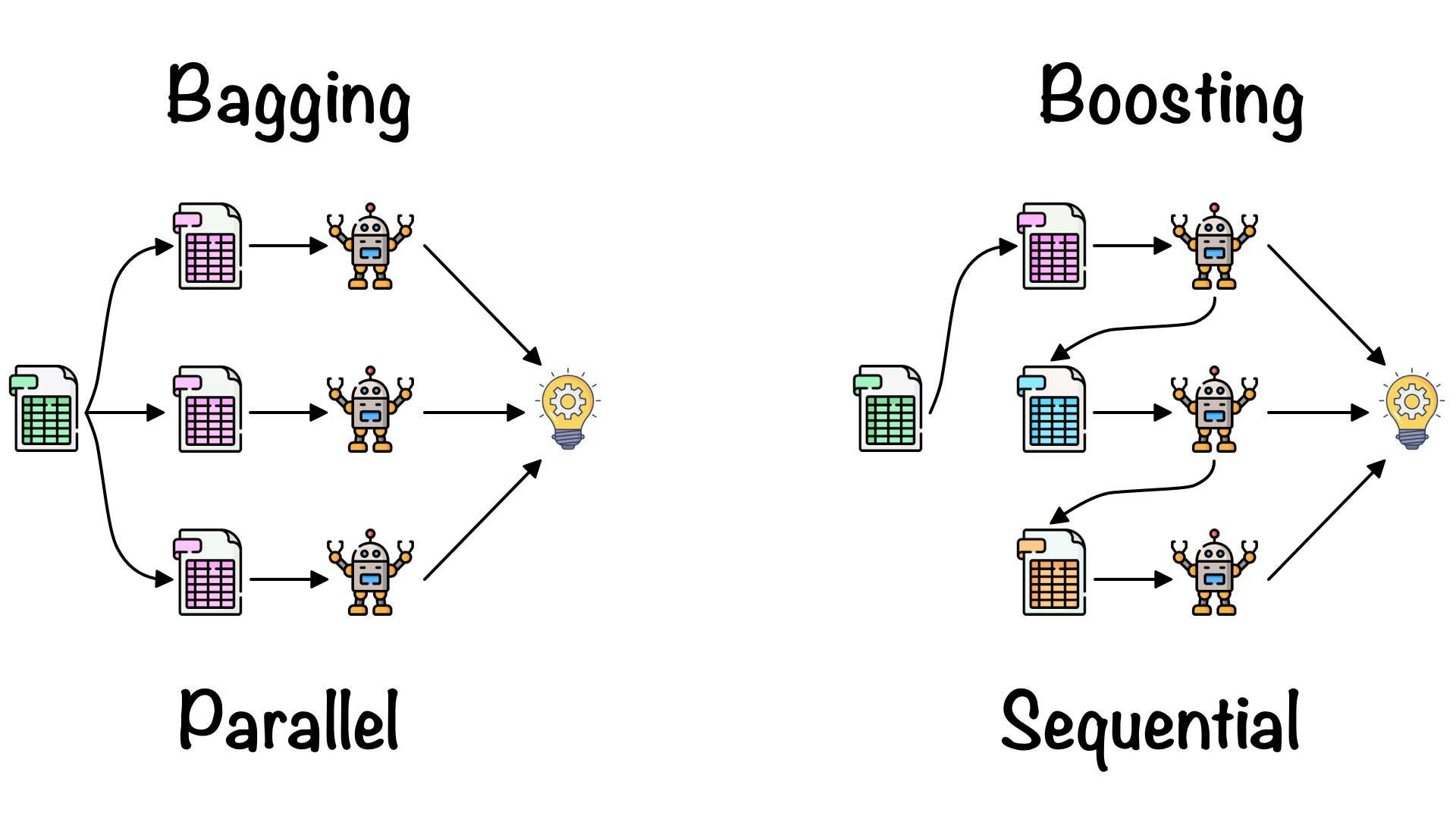
Bagging: Bootstrap Aggregating
Bootstrap aggregation, or bagging, is a technique that improves prediction accuracy by combining predictions from multiple models. It involves creating random subsets of data, training individual models on each subset, and combining their predictions. However, this only happens in regression tasks. For classification tasks, the majority vote is typically used. Bagging applies bootstrap sampling to obtain the data subsets for training the base learners.
Random forest
The Random Forest algorithm is a prime example of bagging. It creates an ensemble of decision trees trained on samples of datasets. Ensemble learning effectively handles complex features and captures nuanced patterns, resulting in more reliable predictions. However, it is also true that the interpretability of ensemble models may be compromised due to the combination of multiple decision trees. Ensemble models can provide more accurate predictions than individual decision trees, but understanding the reasoning behind each prediction becomes challenging. Bagging helps reduce overfitting by generating multiple subsets of the training data and training individual decision trees on each subset. It also helps reduce the impact of outliers or noisy data points by averaging the predictions of multiple decision trees.
Ensemble Learning: Bagging & Boosting | Towards Data Science
Boosting: Iterative Learning
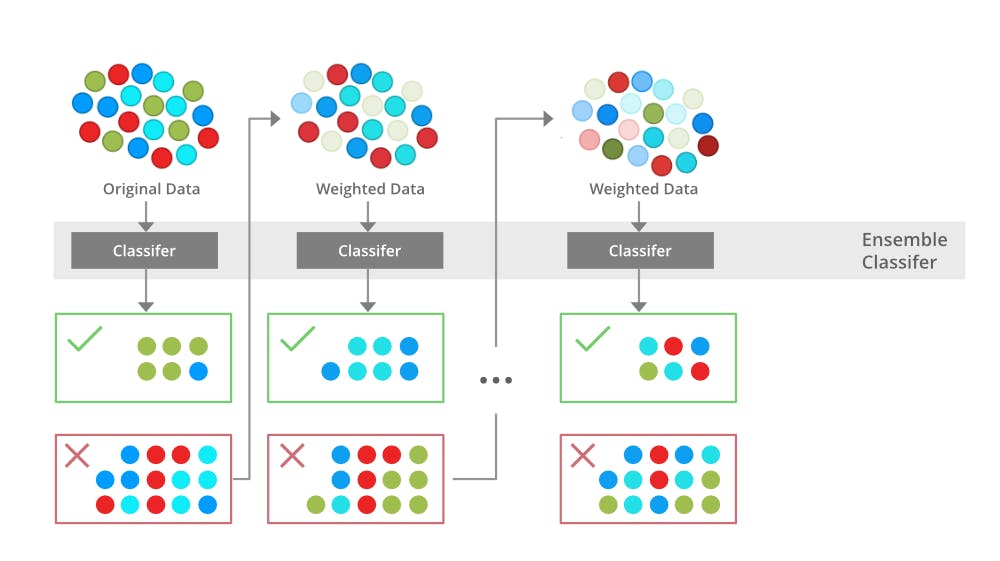
Boosting is a technique in ensemble learning that converts a collection of weak learners into a strong one by focusing on the errors of previous iterations. The process involves incrementally increasing the weight of misclassified data points, so subsequent models focus more on difficult cases. The final model is created by combining these weak learners and prioritizing those that perform better.
Gradient boosting
Gradient Boosting (GB) trains each model to minimize the errors of previous models by training each new model on the remaining errors. This iterative process effectively handles numerical and categorical data and can outperform other machine learning algorithms, making it versatile for various applications.
For example, you can apply Gradient Boosting in healthcare to predict disease likelihood accurately. Iteratively combining weak learners to build a strong learner can improve prediction accuracy, which could be valuable in providing insights for early intervention and personalized treatment plans based on demographic and medical factors such as age, gender, family history, and biomarkers.
One potential challenge of gradient boosting in healthcare is its lack of interpretability. While it excels at accurately predicting disease likelihood, the complex nature of the algorithm makes it difficult to understand and interpret the underlying factors driving those predictions.
This can pose challenges for healthcare professionals who must explain the reasoning behind a particular prediction or treatment recommendation to patients. However, efforts are being made to develop techniques that enhance the interpretability of GB models in healthcare, ensuring transparency and trust in their use for decision-making.
Boosting is an ensemble method that seeks to change the training data to focus attention on examples that previous fit models on the training dataset have gotten wrong.
Boosting in Machine Learning | Boosting and AdaBoost
In the clinical literature, gradient boosting has been successfully used to predict, among other things, cardiovascular events, the development of sepsis, delirium, and hospital readmissions following lumbar laminectomy.

Stacking: Meta-learning
Stacking, or stacked generalization, is a model-ensembling technique that improves predictive performance by combining predictions from multiple models. It involves training a meta-model that uses the output of base-level models to make a final prediction. The meta-model, a linear regression, a neural network, or any other algorithm makes the final prediction.
This technique leverages the collective knowledge of different models to generate more accurate and robust predictions. The meta-model can be trained using ensemble algorithms like linear regression, neural networks, or support vector machines. The final prediction is based on the meta-model's output. Overfitting occurs when a model becomes too closely fitted to the training data and performs poorly on new, unseen data. Stacking helps mitigate overfitting by combining multiple models with different strengths and weaknesses, thereby reducing the risk of relying too heavily on a single model’s biases or idiosyncrasies.
For example, in financial forecasting, stacking combines models like regression, random forest, and gradient boosting to improve stock market predictions. This ensemble approach mitigates the individual biases in the model and allows easy incorporation of new models or the removal of underperforming ones, enhancing prediction performance over time.
Voting
Voting is a popular technique used in ensemble learning, where multiple models are combined to make predictions. Majority voting, or max voting, involves selecting the class label that receives the majority of votes from the individual models. On the other hand, weighted voting assigns different weights to each model's prediction and combines them to make a final decision. Both majority and weighted voting are methods of aggregating predictions from multiple models through a voting mechanism and strongly influence the final decision. Examples of algorithms that use voting in ensemble learning include random forests and gradient boosting (although it’s an additive model “weighted” addition). Random forest uses decision tree models trained on different data subsets. A majority vote determines the final forecast based on individual forecasts.
For instance, in a random forest applied to credit scoring, each decision tree might decide whether an individual is a credit risk. The final credit risk classification is based on the majority vote of all trees in the forest. This process typically improves predictive performance by harnessing the collective decision-making power of multiple models.
The application of either bagging or boosting requires the selection of a base learner algorithm first. For example, if one chooses a classification tree, then boosting and bagging would be a pool of trees with a size equal to the user’s preference.
Benefits of Ensemble Learning
Improved Accuracy and Stability
Ensemble methods combine the strengths of individual models by leveraging their diverse perspectives on the data. Each model may excel in different aspects, such as capturing different patterns or handling specific types of noise. By combining their predictions through voting or weighted averaging, ensemble methods can improve overall accuracy by capturing a more comprehensive understanding of the data. This helps to mitigate the weaknesses and biases that may be present in any single model. Ensemble learning, which improves model accuracy in the classification model while lowering mean absolute error in the regression model, can make a stable model less prone to overfitting. Ensemble methods also have the advantage of handling large datasets efficiently, making them suitable for big data applications. Additionally, ensemble methods provide a way to incorporate diverse perspectives and expertise from multiple models, leading to more robust and reliable predictions.
Robustness
Ensemble learning enhances robustness by considering multiple models' opinions and making consensus-based predictions. This mitigates the impact of outliers or errors in a single model, ensuring more accurate results. Combining diverse models reduces the risk of biases or inaccuracies from individual models, enhancing the overall reliability and performance of the ensemble learning approach. However, combining multiple models can increase the computational complexity compared to using a single model. Furthermore, as ensemble models incorporate different algorithms or variations of the same algorithm, their interpretability may be somewhat compromised.
Reducing Overfitting
Ensemble learning reduces overfitting by using random data subsets for training each model. Bagging introduces randomness and diversity, improving generalization performance. Boosting assigns higher weights to difficult-to-classify instances, focusing on challenging cases and improving accuracy. Iteratively adjusting weights allows boosting to learn from mistakes and build models sequentially, resulting in a strong ensemble capable of handling complex data patterns. Both approaches help improve generalization performance and accuracy in ensemble learning.
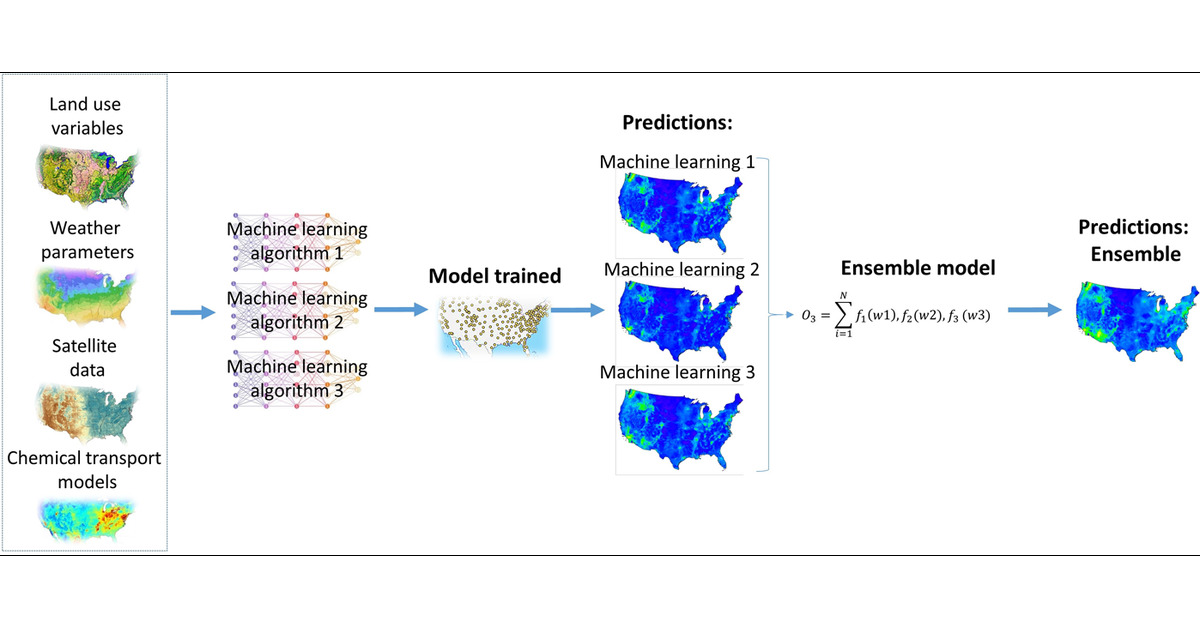
Benefits of using Ensemble Learning on Land Use Data
Challenges and Considerations in Ensemble Learning
Model Selection and Weighting
Selecting the right combination of models to include in the ensemble, determining the optimal weighting of each model's predictions, and managing the computational resources required to train and evaluate multiple models simultaneously. Additionally, ensemble learning may not always improve performance if the individual models are too similar or if the training data has a high degree of noise. The diversity of the models—in terms of algorithms, feature processing, and data perspectives—is vital to covering a broader spectrum of data patterns. Optimal weighting of each model's contribution, often based on performance metrics, is crucial to harnessing their collective predictive power. Therefore, careful consideration and experimentation are necessary to achieve the desired results with ensemble learning.
Computational Complexity
Ensemble learning, involving multiple algorithms and feature sets, requires more computational resources than individual models. While parallel processing offers a solution, orchestrating an ensemble of models across multiple processors can introduce complexity in both implementation and maintenance. Also, more computation might not always lead to better performance, especially if the ensemble is not set up correctly or if the models amplify each other's errors in noisy datasets.
Diversity and Overfitting
Ensemble learning requires diverse models to avoid bias and enhance accuracy. By incorporating different algorithms, feature sets, and training data, ensemble learning captures a wider range of patterns, reducing the risk of overfitting and ensuring the ensemble can handle various scenarios and make accurate predictions in different contexts. Strategies such as cross-validation help in evaluating the ensemble's consistency and reliability, ensuring the ensemble is robust against different data scenarios.
Interpretability
Ensemble learning models prioritize accuracy over interpretability, resulting in highly accurate predictions. However, this trade-off makes the ensemble model more challenging to interpret. Techniques like feature importance analysis and model introspection can help provide insights but may not fully demystify the predictions of complex ensembles. the factors contributing to ensemble models' decision-making, reducing the interpretability challenge.
Real-World Applications of Ensemble Learning
Healthcare
Ensemble learning is utilized in healthcare for disease diagnosis and drug discovery. It combines predictions from multiple machine learning models trained on different features and algorithms, providing more accurate diagnoses. Ensemble methods also improve classification accuracy, especially in complex datasets or when models have complementary strengths and weaknesses. Ensemble classifiers like random forests are used in healthcare to achieve higher performance than individual models, enhancing the accuracy of these tasks.
Agriculture
Ensemble models combine multiple base models to reduce outliers and noise, resulting in more accurate predictions. This is particularly useful in sales forecasting, stock market analysis and weather prediction. In agriculture, ensemble learning can be applied to crop yield prediction. Combining the predictions of multiple models trained on different environmental factors, such as temperature, rainfall, and soil quality, ensemble methods can provide more accurate forecasts of crop yields. Ensemble learning techniques, such as stacking and bagging, improve performance and reliability.
Take a peek at this wonderful article on Encord that shows how to accurately measure carbon content in forests and elevate carbon credits with Treeconomy.
Insurance
Insurance companies can also benefit from ensemble methods in assessing risk and determining premiums. By combining the predictions of multiple models trained on various factors such as demographics, historical data, and market trends, insurance companies can better understand potential risks and make more accurate predictions of claim probabilities. This can help them set appropriate premiums for their customers and ensure a fair and sustainable insurance business.
Remote Sensing
Ensemble learning techniques, like isolation forests and SVM ensembles, detect data anomalies by comparing multiple models' outputs. They increase detection accuracy and reduce false positives, making them useful for identifying fraudulent transactions, network intrusions, or unexpected behavior. These methods can be applied in remote sensing by combining multiple models or algorithms, training on different data subsets, and combining predictions through majority voting or weighted averaging. One practical use of remote sensing can be seen in this article; it’s worth a read. Remote sensing techniques can facilitate the remote management of natural resources and infrastructure by providing timely and accurate data for decision-making processes.
Sports
Ensemble learning in sports involves using multiple predictive models or algorithms to make more accurate predictions and decisions in various aspects of the sports industry. Common ensemble methods include model stacking and weighted averaging, which improve the accuracy and effectiveness of recommendation systems. By combining predictions from different models, such as machine learning algorithms or statistical models, ensemble learning helps sports teams, coaches, and analysts gain a better understanding of player performance, game outcomes, and strategic decision-making. This approach can also be applied to other sports areas, such as injury prediction, talent scouting, and fan engagement strategies.
By the way, you may be surprised to hear that a sports analytics company found that their ML team was unable to iterate and create new features due to a slow internal annotation tool. As a result, the team turned to Encord, which allowed them to annotate quickly and create new ontologies. Read the full story here.
Ensemble models' outcomes can easily be explained using explainable AI algorithms. Hence, ensemble learning is extensively used in applications where an explanation is necessary.
Psuedocode for Implementing Ensemble Learning Models
Pseudocode is a high-level and informal description of a computer program or algorithm that uses a mix of natural language and some programming language-like constructs. It's not tied to any specific programming language syntax. It is used to represent the logic or steps of an algorithm in a readable and understandable format, aiding in planning and designing algorithms before actual coding.
How do you build an ensemble of models? Here's a pseudo-code to show you how:
Algorithm: Ensemble Learning with Majority Voting
Input:
- Training dataset (X_train, y_train)
- Test dataset (X_test)
- List of base models (models[])
Output:
- Ensemble predictions for the test dataset
Procedure Ensemble_Learning:
# Train individual base models
for each model in models:
model.fit(X_train, y_train)
# Make predictions using individual models
for each model in models:
predictions[model] = model.predict(X_test)
# Combine predictions using majority voting
for each instance in X_test:
for each model in models:
combined_predictions[instance][model] = predictions[model][instance]
# Determine the most frequent prediction among models for each instance
ensemble_prediction[instance] = majority_vote(combined_predictions[instance])
return ensemble_prediction
What does it do?
- It takes input of training data, test data, and a list of base models.
- The base models are trained on the training dataset.
- Predictions are made using each individual model on the test dataset.
- For each instance in the test data, the pseudocode uses a function majority_vote() (not explicitly defined here) to perform majority voting and determine the ensemble prediction based on the predictions of the base models.
Here's an illustration with pseudocode on how to implement different ensemble models:

Pseudo Code of Ensemble Learning
Ensemble Learning: Key Takeaways
- Ensemble learning is a powerful technique that combines the predictions of multiple models to improve the accuracy and performance of recommendation systems. It can overcome the limitations of single models by considering the diverse preferences and tastes of different users.
- Ensemble techniques like bagging, boosting, and stacking enhance prediction accuracy and robustness by combining multiple models. Bagging reduces overfitting by averaging predictions from different data subsets. Boosting trains weak models sequentially, giving more weight to misclassified instances. Lastly, stacking combines predictions from multiple models, using another model to make the final prediction. These techniques demonstrate the power of combining multiple models to improve prediction accuracy and robustness.
- Combining multiple models reduces the impact of individual model errors and biases, leading to more reliable and consistent recommendations. Specific ensemble techniques like bagging, boosting, and stacking play a crucial role in achieving better results in ensemble learning.
Frequently asked questions
Recommendation systems combine multiple models by using ensemble learning techniques such as weighted averaging, stacking, or boosting. These techniques allow the system to leverage the strengths of different models and mitigate their individual errors and biases. By aggregating the predictions from multiple models, recommendation systems can provide more reliable and consistent recommendations.
Ensemble learning in recommendation systems can adapt to changing user preferences and item popularity by continuously updating the weights assigned to each model based on their performance. For example, if a particular model consistently provides accurate recommendations for popular items but struggles with niche preferences, its weight can be adjusted accordingly. Additionally, ensemble learning can dynamically adjust the importance of different models based on real-time feedback from users, ensuring that recommendations remain relevant and up-to-date.
For example, if a user's preferences shift over time, the ensemble can give more weight to models that are performing well with the new preferences. Similarly, if certain items become more popular, the ensemble can adjust the weights to give more importance to models that accurately predict the popularity of those items. This dynamic adaptation helps recommendation systems stay up-to-date and provide relevant recommendations to users. By incorporating the concept of continuous learning, the ensemble can effectively respond to evolving user preferences and market trends. This ensures that the recommendations remain accurate and personalized, thereby enhancing the overall user experience. Additionally, the ability to adjust weights allows the ensemble to adapt to changing patterns and make informed predictions, making it a valuable tool for recommendation systems in the ever-changing landscape of online platforms.
Ensemble learning techniques like bagging, boosting, and stacking are used to improve the accuracy, performance, robustness, and personalization of recommendation systems. Bagging involves training multiple models on different data subsets, reducing variance, and improving accuracy. Boosting iteratively trains weak models and gives more weight to misclassified instances, while stacking combines predictions using a meta-model. These techniques help recommendation systems provide more accurate and personalized recommendations, reduce bias and overfitting, and enhance system effectiveness and user satisfaction.
Ensemble learning in recommendation systems can increase computational complexity due to multiple-model training and prediction combining. However, parallel computing and distributed processing have made it efficient, and techniques like model pruning and approximation algorithms can mitigate this burden. For ensemble methods using decision trees (such as Random Forests or Gradient Boosting), pruning techniques like post-pruning (removing nodes from trees) or depth restriction can simplify individual trees, reducing overall model complexity without significant loss of predictive power. Using simpler models or approximations of complex models can significantly reduce computational complexity. For instance, replacing a complex model (like a deep neural network) with a simpler one (like a linear model) or an approximation (like a shallow network) can reduce computational resources.
Ensemble learning techniques in recommendation systems face challenges such as increased complexity in model selection and combination and the potential for poor performance if models are not diverse or have high correlation. To fix these problems, methods like collaborative filtering, content-based filtering, matrix factorization, randomness in training, bagging, and boosting can be used to make different models and improve the performance of the whole ensemble, which will ultimately make the recommendation system work better.
Ensemble learning differs from traditional machine learning techniques by combining multiple models instead of relying on a single model. This approach leverages the collective knowledge and predictions of diverse models to make more accurate and robust predictions. Additionally, ensemble learning can mitigate the limitations of individual models by reducing bias, increasing generalization, and improving overall system performance.
When choosing models for ensemble learning, it is important to select diverse models that have different strengths and weaknesses. This can be achieved by considering models with different algorithms, architectures, or training data. By combining models that complement each other, the ensemble can benefit from a wider range of perspectives and increase the chances of capturing different aspects of the underlying data distribution. Additionally, evaluating individual model performance and selecting high-performing models can also contribute to the success of ensemble learning.
Ensemble learning can be prone to overfitting if the individual models in the ensemble are too similar or if they are trained on the same data. To mitigate this risk, it is important to ensure diversity among the models by using different algorithms, architectures, or training data. Regularization techniques such as bagging and boosting can also help reduce overfitting by introducing randomness or adjusting weights during model combinations.
Encord fosters collaboration through its elite partnership program, providing teams with direct access to leadership and the opportunity to give feedback on product features and roadmaps. This ensures that users' needs are heard and integrated into the platform’s development, enhancing the overall user experience.
Encord enables collaboration by allowing you to define workflows that specify different tasks and roles for collaborators. You can invite team members with specific annotator or reviewer roles and assign them to different stages of the project, ensuring efficient teamwork throughout the annotation process.
Encord is designed to work alongside a variety of third-party solutions, providing flexibility for teams looking to enhance their machine learning tasks. This integration allows users to tap into existing tools while also leveraging Encord's capabilities to bridge gaps in their workflows.
Encord is built to work seamlessly with popular machine learning frameworks, enabling users to import, annotate, and export data easily. This compatibility ensures that teams can leverage their existing tools while benefiting from the enhanced capabilities of the Encord platform.
Encord offers comprehensive onboarding and training support through dedicated solutions teams. They assist in the technical migration, provide training materials, and ensure that new members are equipped with the necessary knowledge to use the platform effectively.
Encord supports teams in expanding the distribution of their machine learning models by providing a framework to continually update models based on new data from diverse environments. This ensures that models remain robust and effective even as conditions change.
Encord enhances collaboration by providing tools that allow team members to share data and metadata easily. This reduces the need for duplicating work and ensures that all team members can access the latest information and resources relevant to their projects.
Yes, Encord includes features that allow users to evaluate model performance, identify areas of class imbalance, and improve training data selection. This helps in enhancing the overall quality and effectiveness of machine learning models.
Yes, Encord can be integrated seamlessly with existing machine learning operations and infrastructure. It supports data ingestion and export, enabling teams to enhance their workflows and optimize their machine learning processes.
Encord encourages collaboration by breaking down silos and connecting various teams and subsidiaries. This approach enhances communication and support for ongoing projects, making it easier for teams to work together effectively.