Top 10 Video Object Tracking Algorithms in 2026

Object tracking has become a fundamental part of the computer vision ecosystem. It powers various modern artificial intelligence applications and is behind several revolutionary technologies, such as self-driving cars, surveillance, and action recognition systems.
Tracking algorithms use a combination of object detection and object tracking to detect and localize entities within a video frame. These algorithms range from basic machine learning to complex deep learning networks. Each of these has different implementations and use cases.
This article will discuss the top 10 most popular video object-tracking algorithms. It will go over video object-tracking algorithms' back-end implementations, advantages, and disadvantages. We will also explore popular computer vision applications for object tracking.
What is Video Object Tracking?
Video object tracking refers to detecting an object within a video frame and tracking its position throughout the video. The concept of object tracking stems from object detection, a popular computer vision (CV) technique used for identifying and localizing different objects in images.
While object detection works on still images (single frames), video object tracking applies this concept to every frame in the video. It analyzes each frame to identify the object in question and draw a bounding box around it. The object is effectively tracked throughout the video by performing this operation on all frames.
![]()
However, complex machine learning and deep learning algorithms apply additional techniques such as region proposal and trajectory prediction for real-time object inference.
Object tracking algorithms have revolutionized several industries. It has enabled businesses to implement analytics and automation in various domains and led to applications like:
- Autonomous Vehicles: Tracking surrounding elements like pedestrians, roads, curbs.
- Automated Surveillance: Tracking people or illegal objects like guns and knives.
- Sports Analytics: Tracking the ball or players to create match strategies.
- Augmented Reality Applications: Tracking all objects in the visual field to superimpose the virtual elements.
- Customer Analysis in Retail: Tracking retail store customers to understand movement patterns and optimize shelf placement.
Over the years, object tracking algorithms have undergone various improvements in-terms of accuracy and performance. Let’s discuss these in detail.
Single-stage Object Detectors Vs. Two-stage Object Detectors
Object detection is a crucial part of tracking algorithms. Hence, it is vital to understand them in detail. There are two main categories of object detectors: Single-stage and two-stage. Both these methodologies have proven to provide exceptional results. However, each offers different benefits, with the former having a lower inference time and the latter having better accuracy.
Single-stage detectors perform faster since they rely on a single network to produce annotations. These models skip intermediate feature extraction steps, such as region proposal. They use the raw input image to identify objects and generate bounding box coordinates. One example of a single-stage detector is You only look once (YOLO). YOLO can generate annotations with a single pass of the image.
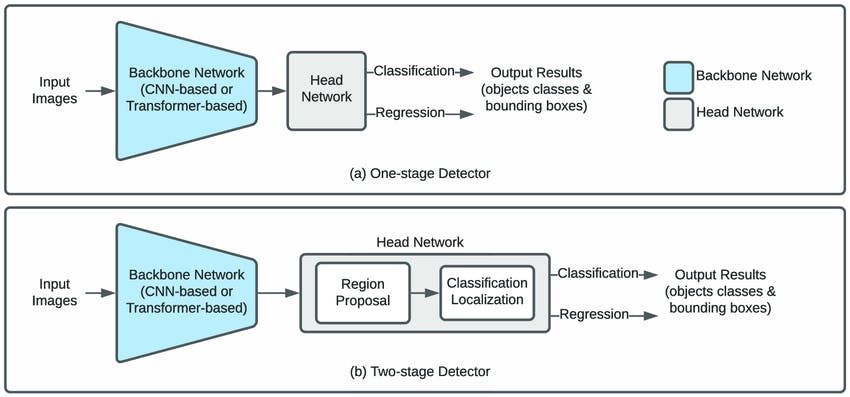
Single Stage Vs. Two-Stage Detection
Two-stage detectors, such as Fast R-CNN, comprise two networks. The first is a region proposal network (RPN) that analyzes the image and extracts potential regions containing the desired objects. The second network is a CNN-based feature extractor that analyzes the proposed regions. The latter identifies the objects present and outputs their bounding box coordinates.
Two-stage object detectors are computationally expensive compared to their single-stage counterparts. However, they produce more accurate results.
Object Tracking Approaches
Object tracking algorithms work on two granularity levels. These include:
Single Object Tracking (SOT)
SOT is used to track the location of a single object throughout the video feed. These detection-free algorithms depend on the user to provide a bounding box around the target object on the first frame. The algorithm learns to track the position and movement of the object present within the box. It localizes the object's shape, posture, and trajectory in every subsequent frame.
Single object tracking is useful when the focus must be kept on a particular entity. Some examples include tracking suspicious activity in surveillance footage or ball-tracking in sports analytics.
Popular SOT algorithms include Particle Filters and Siamese Networks. However, one downside of traditional SOT algorithms is that they are unsuitable for context-aware applications where tracking multiple objects is necessary.
Multiple Object Tracking (MOT)
MOT works on the same concept as SOT. However, multi-object tracking identifies and tracks multiple objects throughout a video instead of a single object. MOT algorithms use extensive training datasets to understand moving objects. Once trained, they can identify and track multiple objects within each frame. Modern deep-learning MOT algorithms, like DeepSORT, can even detect new objects mid-video and create new tracks for them while keeping existing tracks intact.
Multiple-object tracking is useful when various objects must be analyzed simultaneously. For example, in virtual reality (VR) applications, the algorithm must keep track of all objects in the frame to superimpose the virtual elements. However, these algorithms are computationally expensive and require lengthy training time.
Phases of Object Tracking Process
Visual object tracking is a challenging process comprising several phases.
- Target Initialization: The first step is to define all the objects of interest using labels and bounding boxes. The annotations, which include the names and locations of all the objects to be tracked, are specified in the first video frame. The algorithm then learns to identify these objects in all the subsequent images or video sequences.
- Appearance Modelling: An object may undergo visual transformation throughout the video due to varying lighting conditions, motion blur, image noise, or physical augmentations. This phase of the object-tracking process aims to capture these various transformations to improve the model’s robustness. It includes constructing object descriptions and mathematical models to identify objects with different appearances.
- Motion Estimation: Once the object features are defined, motion estimation predicts the object’s position based on the previous frame data. This is achieved by leveraging linear regression techniques or Particle Filters.
- Target Positioning: Motion estimation provides an estimate of the object's position. The next step is to pinpoint the exact coordinates within the predicted region. This is accomplished using a greedy search, i.e., checking every possibility or a maximum posterior estimation that looks at the most likely place using visual clues.
Criteria for Selecting a Video Object Tracking Algorithm
The two primary criteria to evaluate object tracking methods are accuracy and inference time. These help determine the best algorithm for particular use cases. Let’s discuss these criteria in detail.
Accuracy
Tracking algorithms output two main predictions: object identity (label) and location (bounding box coordinates). The accuracy of these models is determined by evaluating both these predictions and analyzing how well it was able to identify and localize the object.
Metrics like Accuracy, Precision, Recall, and F1-score help evaluate the model's ability to classify the found object. While accuracy provides a generic picture, precision, and recall judge the model based on occurrences of false positives and negatives.
Metrics like intersection-over-union (IoU) are used for localization accuracy. IoU calculates how much the predicted bounding box coincides with its ground truth value. A higher value means higher intersection and, hence, higher accuracy.
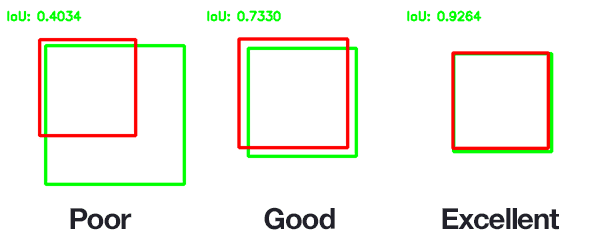
Inference Time
The second judgment criterion is the speed of inference. Inference time determines how quickly the algorithm processes a video frame and predicts the object label and location. It is often measured in frames-per-second (FPS). This refers to the amount of frames the algorithm can process and output every second. A higher FPS value indicates faster inference.
Challenges in Object Tracking
Object tracking techniques carry various benefits for different industries. However, implementing a robust tracking algorithm is quite challenging. Some key challenges include:
- Object Variety: The real world comes with countless objects. Training a generic tracking algorithm would require an extensive dataset containing millions of objects. For this reason, object tracking models are generally domain-specific, with even the vastest models trained on only a few thousand objects.
- Varying Conditions: Besides the object variety, the training data must also cover objects in different conditions. A single object must be captured in different lighting conditions, seasons, times of day, and from different camera angles.
- Varying Image Quality: Images from different lenses produce varying information in terms of color production, saturation, etc. A robust model must incorporate these variations to cover all real-world scenarios.
- Computation Costs: Handling large image or video datasets requires considerable expertise and computational power. Developers need access to top-notch GPUs and data-handling tools, which can be expensive. Training deep-learning-based tracking algorithms can also increase operational costs if you use paid platforms that charge based on data units processed.
- Scalability: Training general-purpose object tracking models requires extensive datasets. The growing data volumes introduce scalability challenges as developers require platforms that can handle increasingly large volumes of data and can increase computation power to train larger complex models.
Top Algorithms for Video Object Tracking
Here is a list of popular object tracking algorithms, ranging from simple mathematical models to complex deep learning architectures.
Kalman Filter
Kalman filters estimate an object’s position and predict its motion in subsequent frames. They maintain an internal representation of the object's state, including its position, velocity, and sometimes acceleration.
The filters use information from the object’s previous state and a mathematical model analyzing the object’s motion to predict a future state. The model accounts for any uncertainty in the object's motion (noise). It incorporates all the discussed factors and estimates the object’s current state to create a future representation.
Advantages
- It is a mathematical model that does not require any training.
- It is computationally efficient.
Disadvantage
- Subpar performance and capabilities compared to modern deep learning algorithms.
- The model works on various assumptions, such as constant object acceleration.
- The algorithm does not perform well in random motion scenarios.
KCF (Kernelized Correlation Filters)
KCF is a mathematical model that understands object features and learns to distinguish them from their background. It starts with the user providing a bounding box around the object in the first frame.
Once feature understanding is complete, it uses correlation filters based on the kernel trick to construct a high-dimensional relationship between the features and the true object. It uses the correlation features in subsequent frames to scan around the object's last known location. The area with the highest correlation is predicted to contain the object.
Advantages
- Fast Computation.
- Low Memory Requirement.
- Competitive Results in general cases.
Disadvantages
- Traditional KCF faces challenges in conditions such as varying object scales or objects touching frame boundaries.
DeepSORT
The Deep Simple Online Realtime Tracking (DeepSORT) algorithm extends the original SORT algorithm. The original SORT algorithm used Kalman filters to predict object motion and the Hungarian algorithm for frame-by-frame data association. However, this algorithm struggles with occlusions and varying camera angles and can lose object tracking in such complex scenarios.
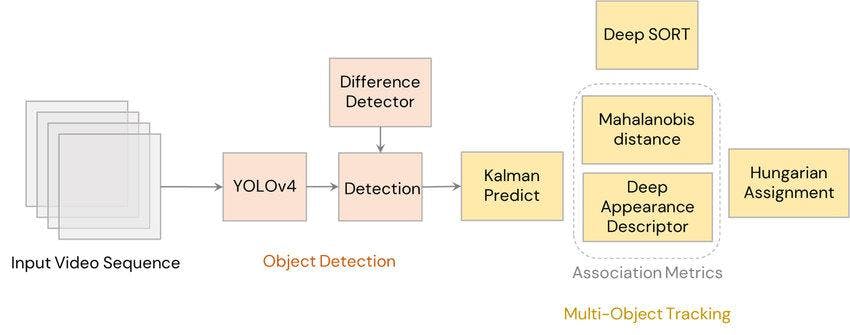
DeepSORT uses an additional convolutional neural network (CNN) as a feature extractor. These are called appearance features as they learn to determine the object identity (appearance) in different scenarios and allow the algorithm to distinguish between moving objects. DeepSORT combines the information from Filtering and CNN to create a deep association metric for accurate detection.
Advantages
- DeepSort’s simple yet efficient implementation provides real-time performance.
- The model is modular. It can support any detection network of the user's choice, such as YOLO or SSD.
- It maintains its detection during occluded environments and can distinguish between different objects in complex scenarios.
Disadvantages
- Offline training of a separate detection network can be challenging and requires an extensive dataset for high accuracy.
FairMOT
The fair multi-object tracking (FairMOT) algorithm uses a pre-trained model like faster R-CNN for detecting objects in the video sequence. It then uses a neural network to extract features from the detected object.
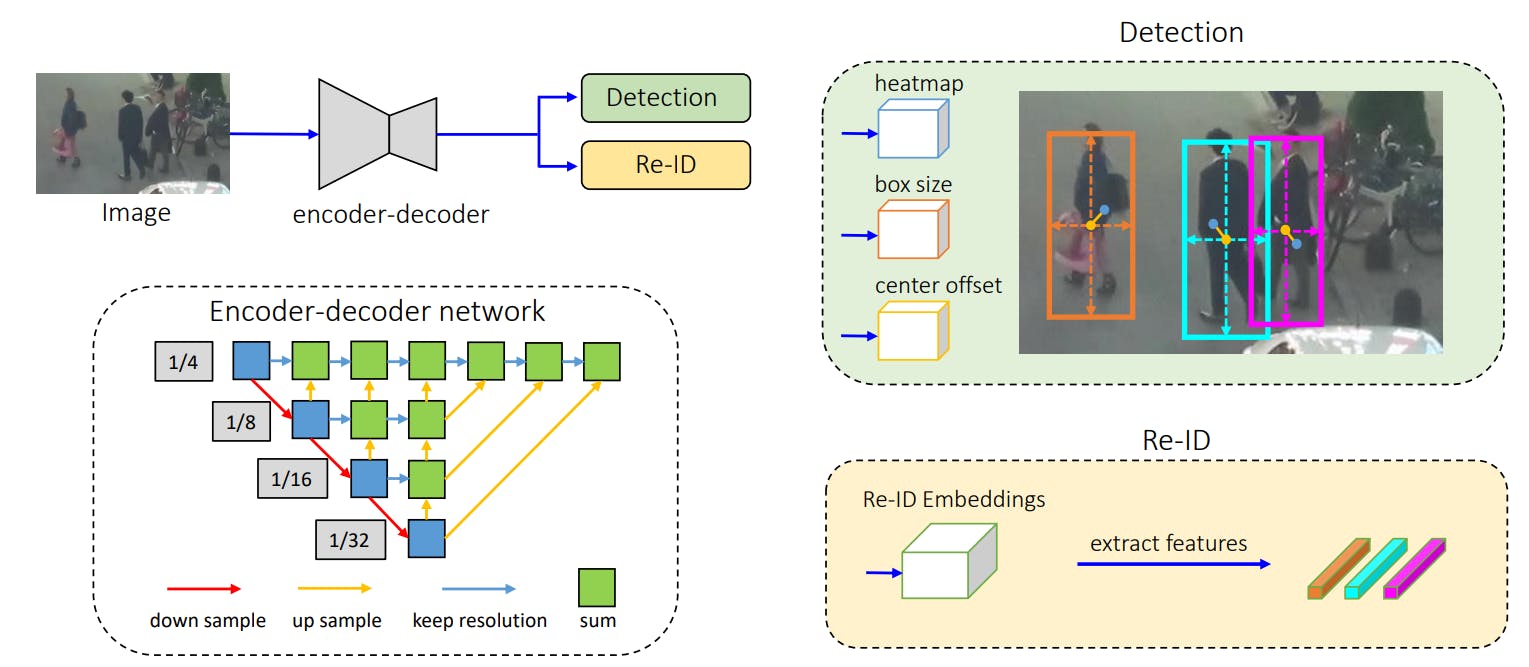
These features are used to track the object across other frames. The branches share the same underlying architecture and receive equal weightage during training.
The FairMOT algorithm treats all classes fairly and provides a balanced performance between the two tasks: detection and tracking.
Advantages
- Provides balanced performance between tracking and detection.
- Improved tracking accuracy due to the re-identification branch (feature extraction branch)
Disadvantage
- Computationally expensive due to the two neural network branches being trained.
MDNet
The multi-domain network (MDNet) is popular for learning across different domains. It consists of two modules. The first is a CNN architecture shared amongst all the video sequences, i.e., it is domain-independent and learns from the entire dataset. This consists of CNN layers and a few flattened, fully connected layers.
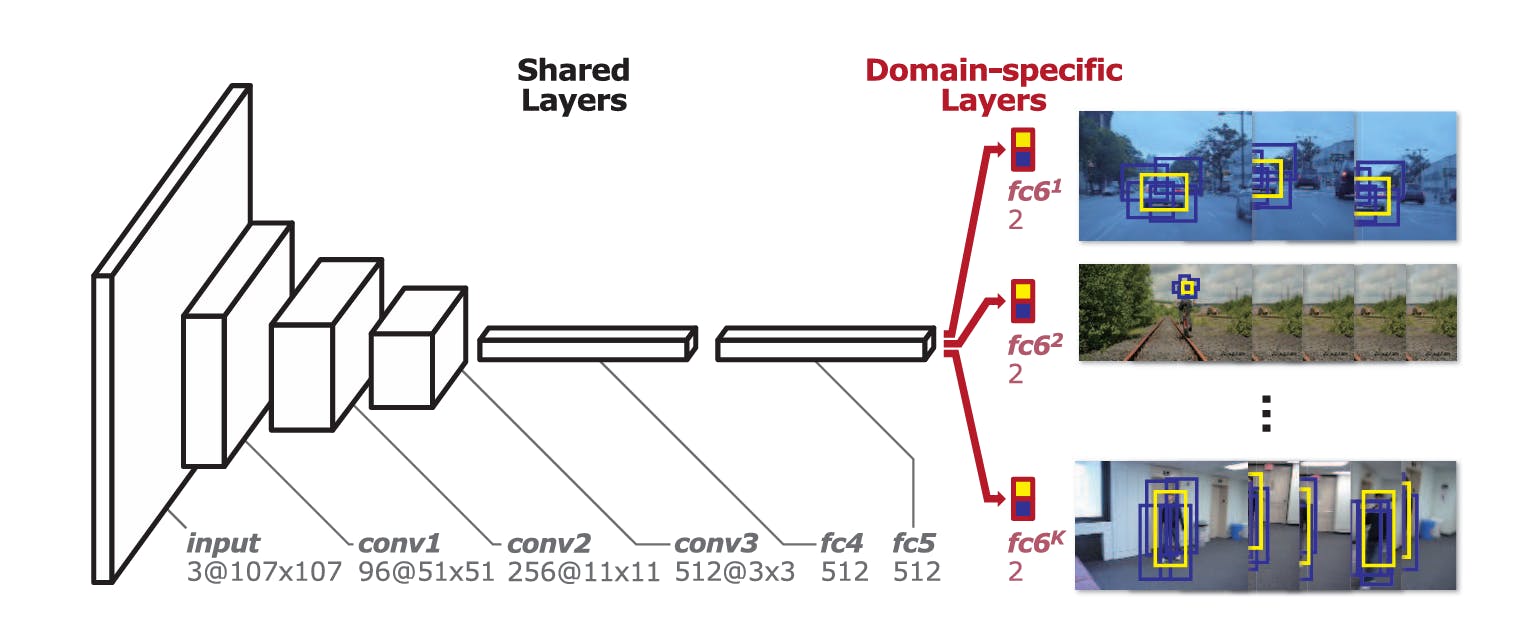
The second part comprises parallel fully connected (FC) layers, each processing domain-specific information. If the data captures information from 5 domains, the second portion will have 5 FC layers. Each of these layers is independently updated during back-propagation depending on the domain of the target image.
Advantages
- Excellent performance across different domains.
- The domain-specific branches can be fine-tuned on the fly if significant domain shifts are detected.
Disadvantages
- If data is imbalanced, the model will display uneven performance across the different domains.
YOLOv8 (You Only Look Once)
YOLOv8 is a single stage-detector that ranks among the most popular object tracking algorithms. The YOLO family of models is based on a CNN architecture that learns to predict object labels and positions with a single pass of the image.

The model v8 follows a similar architecture to its predecessor and consists of various CNN and fully connected layers. It is an anchor-free algorithm, which directly predicts the object’s center rather than an offset from a predefined anchor. Moreover, the algorithm can be used for classification, segmentation, pose estimation, object detection, and tracking.
YOLOv8 extends its detection capabilities by providing a range of trackers. Two popular options amongst these are Bot-SORT and ByteTrack. All the trackers are customizable, and users can fine-tune parameters like confidence threshold and tracking area.
Advantages
- The model covers various use cases, including tracking and segmentation.
- High accuracy and performance.
- Easy Python Interface.
Disadvantages
- Trouble detecting small objects.
- YOLOv8 provides various model sizes, each trading performance for accuracy.
Siamese Neural Networks (SNNs)
Siamese-based tracking algorithms consist of two parallel branches of neural networks. One is a template branch, which contains the template image (including the object bounding box information) and the next frame where the object is to be found. This branch consists of CNNs and pooling layers and extracts features from both images, such as edges, texture, and shape.
![]()
A fully convolutional siamese network for object tracking
The other is the similarity branch that takes the features from the template and search image. It calculates the similarity between the two images using algorithms like contrastive loss. The output of this network is the likelihood of the object being present at different positions in the image.
The Siamese network has had various advancements over the years. The modern architectures include attention mechanisms and RPNs for improved performance.
Advantages
- Multiple advancements, including SiamFC, SiamRPN, etc.
Disadvantages
- Training two parallel networks leads to long training times.
GOTURN (Generic Object Tracking Using Regression Networks)
Generic Object Tracking Using Regression Networks (GOTURN) is a deep learning based offline learning algorithm. The framework accepts two images, a previous frame and a current frame. The previous frame contains the object at its center, and the image is cropped to 2 times the bounding box size. The current frame is cropped in the same location, but the object is off-center as it has supposedly moved from its position.
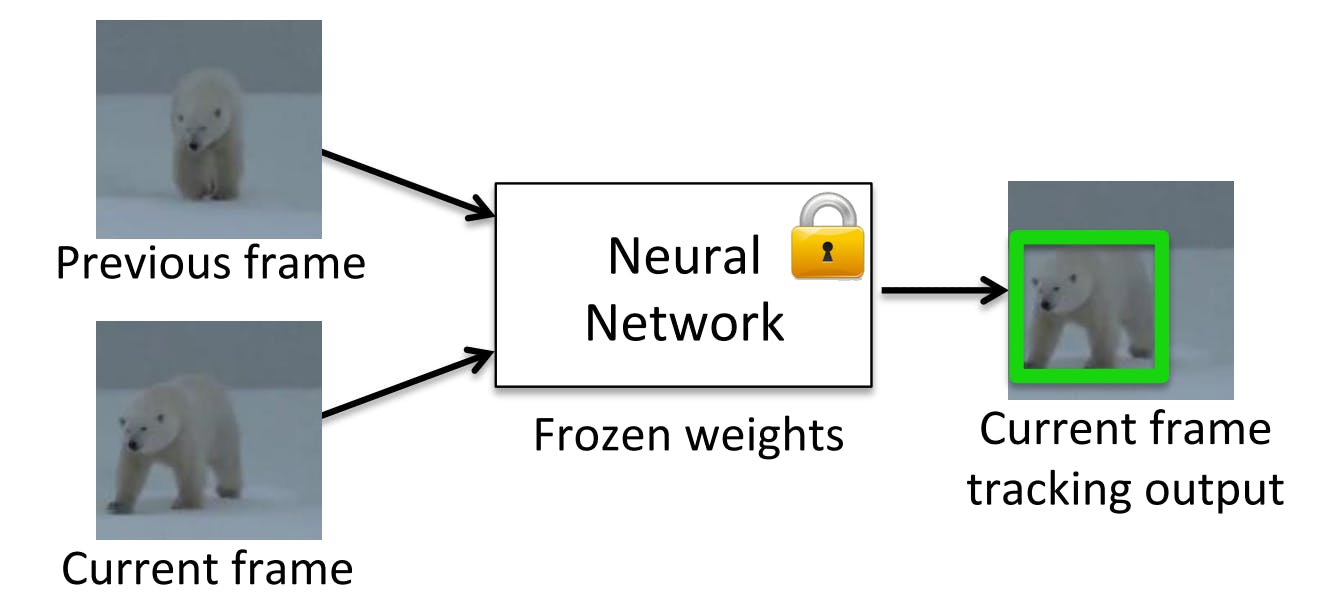
GOTURN High-level Architecture
The internal structure of the model consists of convolutional layers taken from the CaffeNet architecture. Each of the two frames is passed through these layers, and the output is concatenated and processed through a series of fully connected layers. The objective of the network is to learn features from the previous frame and predict the bounding box in the current.
Advantages
- Excellent performance, even on CPU.
Disadvantages
- Troubled in scenarios where only some part of the object is visible.
- Object tracking is highly affected by imbalanced training data.
TLD (Tracking, Learning, and Detection)
TLD is a framework designed for long-term tracking of an unknown object in a video sequence. The three components serve the following purpose:
- Tracker: Predicts the object location in the next frame using information in the current frame. This module uses techniques like mean-shift or correlation filtering.
- Detector: Scans the input frame-by-frame for potential objects using previously learned object appearances.
- Learning: Observes the tracker's and the detector's performance and identifies their errors. It further generates training samples to teach the detector to avoid mistakes in the future.
![]()
Advantages
- Real-time performance.
Disadvantages
- Sensitive to illumination changes.
- Can lose track of the object if it is completely occluded in any frame.
- Can fail if the object appearance changes mid-video.
Median Flow Tracker
The Median Flow Tracker predicts object movement in videos by analyzing feature points across frames. It estimates optical flow, filters out unreliable measurements, and uses the remaining data to update the object's bounding box.
![]()
Internally, it tracks motion in both forward and backward directions and compares the two trajectories.
Advantages
- Works well for predictable motion.
Disadvantage
- Fails in scenarios of abrupt and random motion.
Applications of Video Object Tracking
Video Object Tracking has important use-cases in various industries. These use-cases automate laborious tasks and provide critical analytics. Let's discuss some key applications.
Autonomous Vehicles
Market leaders like Tesla, Waymo, and Baidu are constantly enhancing their AI infrastructure with state-of-the-art algorithms and hardware for improved tracking.
Modern autonomous vehicles use different cameras and robust neural processing engines to track the objects surrounding them. Video object tracking plays a vital role in mapping the car's surroundings. This feature map helps the vehicle distinguish between elements such as trees, roads, pedestrians, etc.
Autonomous Harvesting Robots
Object tracking algorithms also benefit the agriculture industry by allowing autonomous detection and harvesting of ready crops. Agri-based companies like Four Growers use detection and tracking algorithms to identify harvestable tomatoes and provide yield forecasting.
They use the Encord annotation tool and a team of professional annotators to label millions of objects simultaneously. Using AI-assisted tools has allowed them to cut the data processing time by half.
Sports Analytics
Sports analysts use computer vision algorithms to track player and ball movement to build strategies. Video tracking algorithms allow the analysts to understand player weaknesses and generate AI-based analytics.
The tracking algorithms can also be used to fix player postures to improve performance and mitigate injury risks.
Traffic Congestion & Emission Monitoring System
Computer vision is used to track traffic activity on roads and airports. The data is also used to manage traffic density and ensure smooth flow. Companies like Automotus use object tracking models to monitor curb activity and reduce carbon emissions.
Their solution automatically captures the time a car spends on the curb, detects any traffic violations, and analyzes driver behavior.
Vascular Ultrasound Analysis
Object detection has various use cases in the healthcare domain. One of the more prominent applications is Ultrasound analysis for diagnosing and managing vascular diseases like Popliteal Artery Aneurysms (PAAs).
CV algorithms help medical practitioners in detecting anomalous entities in medical imaging. The automated detection allows for further AI analysis, such as classification, and allows the detection of minute irregularities that might otherwise be ignored.
Professional Video Editing
Professional tools like Adobe Premiere Pro use object tracking to aid professional content creators. It allows creators to apply advanced special effects on various elements and save time creating professional video editing.
Customer Analysis in Retail Stores
Tracking algorithms are applied in retail stores via surveillance cameras. They are used to detect and track customer movement throughout the store premises. The tracking data helps the store owner understand hot spots where the customers spend the most time. It also gives insights into customer movement patterns that help optimize product placement on shelves.
Video Object Tracking: Key Takeaways
The computer vision domain has come a long way, and tasks like classification, segmentation, and object tracking have seen significant improvements. ML researchers have developed various algorithms for video object tracking, each of which holds certain benefits over the other. In this article, we discussed some of the most popular architectures. Here are a few takeaways:
- Object Tracking vs. Object Detection: Video object tracking is an extension of object detection and applies the same principles to video sequences.
- Multiple Categories of Object Tracking: Object tracking comprises various sub-categories, such as single object tracking, multiple object tracking, single-stage detection, and two-stage detection.
- Object Tracking Metrics: Object tracking algorithms are primarily judged on their inference time (frames-per-second) and tracking accuracy.
- Popular Frameworks: Popular tracking frameworks include YOLOv8, DeepSORT, GOTURN, and MDNet.
- Applications: Object tracking is used across various domains, including healthcare, autonomous vehicles, customer analysis, and sports analytics.
Frequently asked questions
Object tracking uses machine learning algorithms to identify and locate objects in an image. It then does the same for all frames in a video, subsequently tracking the object.
Object detection is used in self-driving cars, AR/VR applications, and surveillance cameras.
You can use algorithms like YOLO, MDNet, Siamese Network, or GOTURN to track objects in videos.
Choosing a single best algorithm is difficult as each has its benefits and downsides. Simpler algorithms like Kalman filters are computationally light but fail in complex scenarios. Neural Network architectures like YOLO are robust and accurate but require extensive training and powerful hardware.
Encord provides the capability to track objects through time, allowing users to create specific segmentations and ranges directly within the timeline. This feature enhances the accuracy of tracking movements and interactions within a scene, which is essential for applications in fields such as healthcare monitoring and behavioral analysis.
Encord streamlines the data gathering process by providing tools that automate the annotation of images and videos for object detection and tracking. This capability enhances the accuracy of model training and allows organizations to gain deeper insights from their data, ultimately improving decision-making in waste management.
Encord's platform allows users to visualize entire videos, rather than just isolated frames, making it especially useful for teams working with CCTV footage. Features include calculating metrics like diversity, uniqueness, and brightness across the video, helping to identify significant moments and areas of interest.
Encord's SAM II tracking feature allows users to track objects across frames in video annotations while maintaining the instance ID. Additionally, Encord supports bulk tracking, which enables users to annotate individual frames and then apply tracking to all annotations simultaneously, streamlining the workflow.
Encord utilizes deep learning approaches for tracking in video annotations, allowing it to follow the movement of objects across multiple frames. Users have the option to use different methods, including linear interpolation, to ensure that moving objects are accurately tracked and labeled throughout the video.
Encord allows users to efficiently track and annotate objects within CCTV footage by creating bounding boxes and utilizing our SAM feature for quick labeling. The platform supports tracking multiple objects across frames, enabling users to maintain an organized annotation workflow even in complex scenarios.
Encord supports the development of tracking models by offering capabilities to label video data efficiently. Users can utilize proprietary algorithms to curate video segments, ensuring that the most relevant moments are highlighted for analysis and model training.
Encord offers robust tools for pose estimation and key point tracking across videos, facilitating the analysis of time series data. This capability is particularly beneficial for robotics applications where precise tracking and analysis of movements are critical.
Yes, Encord allows users to index motion tracks within video data. Each motion track can be filtered by various attributes, such as character gender, making it simple to search for and analyze specific sequences in the dataset.