YOLO World Zero-shot Object Detection Model Explained

Object Detection with YOLO Series
The YOLO series of detectors initially introduced by Joseph Redmon have revolutionized zero-shot object detection with their real-time performance and straightforward architecture. These detectors operate by dividing the input image into a grid and predicting bounding boxes and class probabilities for each grid cell.
Despite their efficiency, traditional YOLO detectors are trained on datasets with fixed categories, limiting their ability to detect objects beyond these predefined classes without retraining on custom datasets.
Object Detection with Other Vision Language Models
Recently, with the introduction of vision foundation models, there has been a surge in research exploring the integration of vision and LLM to enhance object detection capabilities. Models like CLIP (Contrastive Language-Image Pre-training) and F-VLM (Fine-grained Vision-Language Model) have demonstrated the potential of vision-language modeling in various computer vision tasks, including object detection.
Grounding DINO
Grounding DINO is a method aimed at improving open-set object detection in computer vision. Open-set object detection is a task where models are required to identify and localize objects within images, including those from classes not seen during training, also known as "unknown" or "unseen" object classes.
To tackle this challenge, Grounding DINO combines DINO, a self-supervised learning algorithm, with grounded pre-training, which incorporates both visual and textual information. This hybrid approach enhances the model's capability to detect and recognize previously unseen objects in real-world scenarios by leveraging textual descriptions in addition to visual features.
CLIP
CLIP is a neural network trained on a diverse range of images and natural language supervision sourced abundantly from the internet. Unlike traditional models, CLIP can perform various classification tasks instructed in natural language without direct optimization for specific benchmarks. This approach, similar to zero-shot capabilities seen in GPT-2 and GPT-3, enhances the model's robustness and performance, closing the robustness gap by up to 75%. CLIP achieves comparable performance to ResNet-50 on ImageNet zero-shot, without using any of the original labeled examples.
F-VLM
F-VLM is a simplified open-vocabulary object detection method that leverages Frozen Vision and Language Models (VLM). It eliminates the need for complex multi-stage training pipelines involving knowledge distillation or specialized pretraining for detection.
F-VLM demonstrates that a frozen VLM can retain locality-sensitive features crucial for detection and serves as a strong region classifier. The method fine-tunes only the detector head and combines detector and VLM outputs during inference.
F-VLM exhibits scaling behavior and achieves a significant improvement of +6.5 mask AP over the previous state-of-the-art on novel categories of the LVIS open-vocabulary detection benchmark.
Open Vocabulary Object Detection in Real-time
YOLO-World addresses limitations of traditional object detection methods by enabling open-vocabulary detection beyond fixed categories, offering adaptability to new tasks, reducing computational burden, and simplifying deployment on edge devices.
Real-Time Performance
YOLO-World retains the real-time performance characteristic of the YOLO architecture. This is crucial for applications where timely detection of objects is required, such as in autonomous vehicles or surveillance systems.
Open-Vocabulary Capability
YOLO-World has the capability to detect objects beyond the fixed categories which the YOLO series is trained. This open-vocabulary approach allows YOLO-World to identify a broader range of objects making it highly adaptable to diverse real-world scenarios.
YOLO-World also presents the "prompt-then-detect" approach, which eliminates the necessity for real-time text encoding. Instead, users can generate prompts, which are subsequently encoded into an offline vocabulary.
Integration of Vision-Language Modeling
YOLO-World integrates vision-language modeling techniques to enhance its object detection capabilities. By leveraging pre-trained models like CLIP, YOLO-World gains access to semantic information embedded in textual descriptions, which significantly improves its ability to understand and detect objects in images.
Efficiency and Practicality
Despite its advanced capabilities, YOLO-World remains highly efficient and practical for real-world applications. Its streamlined architecture and efficient implementation ensure that object detection can be performed in real-time without sacrificing accuracy or computational resources. This makes YOLO-World suitable for deployment in a wide range of applications, from robotics to image understanding systems.
Open-vocabulary Instance Segmentation Feature
In addition to its remarkable object detection capabilities, the pre-trained YOLO-World model also excels in open-vocabulary instance segmentation, demonstrating strong zero-shot performance on large-scale datasets.
The open-vocabulary instance segmentation feature of YOLO-World enables it to delineate and segment individual objects within images, regardless of whether they belong to predefined categories or not. By using its comprehensive understanding of visual and textual information, YOLO-World can accurately identify and segment objects based on their contextual descriptions, providing valuable insights into the composition and layout of scenes captured in images.
YOLO-World achieves 35.4 Average Precision (AP) on the LVIS dataset while maintaining a high inference speed of 52.0 frames per second (FPS). This underscores the model's ability to accurately segment instances across a wide range of object categories, even without specific prior training on those categories.
YOLO-World Framework
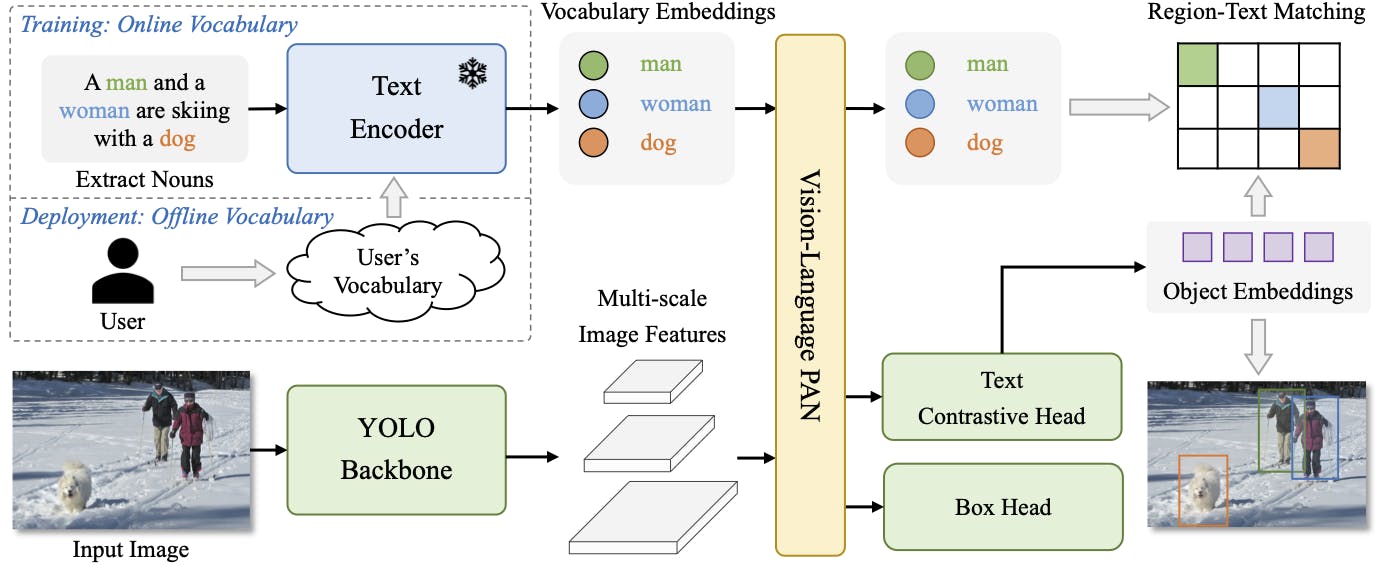
YOLO-World: Real-Time Open-Vocabulary Object Detection
Frozen CLIP-based Text Encoder
Frozen CLIP-based Text Encoder, plays a fundamental role in processing textual descriptions associated with objects in images. This text encoder is based on the CLIP (Contrastive Language-Image Pre-training) model, which has been pre-trained on large-scale datasets to understand the relationship between images and corresponding textual descriptions.
By leveraging the semantic embeddings generated by the CLIP text encoder, YOLO-World gets access to contextual information about objects, enhancing its ability to interpret visual content accurately.
Re-parameterizable Vision-Language Path Aggregation Network
The vision-language path aggregation network (RepVL-PAN) serves as the bridge between visual and linguistic information, facilitating the fusion of features extracted from images and textual embeddings derived from the CLIP text encoder. By incorporating cross-modality fusion techniques, RepVL-PAN enhances both the visual and semantic representations of objects.
Region-Text Contrastive Loss
Region-text contrastive loss involves constructing pairs of regions and their associated textual descriptions, and then calculating the loss using cross-entropy between the predicted object-text similarity and the assigned text indices.
YOLO-World incorporates region-text contrastive loss alongside other loss functions such as IoU loss and distributed focal loss for bounding box regression, ensuring comprehensive training and improved performance.
This loss function helps YOLO-World learn to accurately associate objects with their corresponding textual descriptions, enhancing the model's object detection capabilities.
YOLO-World Performance
Zero-Shot Evaluation on LVIS
The YOLO-World model was tested in a zero-shot setting on the Large Vocabulary Instance Segmentation (LVIS) dataset. Despite not being trained in LVIS categories, it performed well, particularly in rare categories. This suggests that the model is effective at generalizing its learned knowledge to new categories. However, it’s important to note that these results are based on internal evaluations and actual performance may vary.
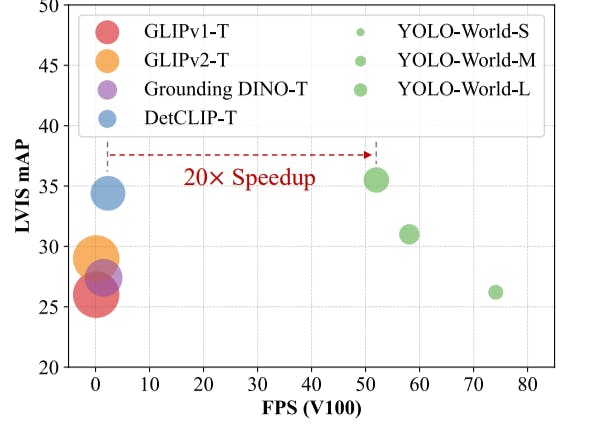
YOLO-World: Real-Time Open-Vocabulary Object Detection
Speed and Accuracy
YOLO-World addresses the limitation of speed in zero-shot object detection models that rely on transformer architectures by applying a faster CNN based YOLO framework. On the challenging LVIS dataset, YOLO-World achieves an impressive 35.4 Average Precision (AP) while maintaining a high inference speed of 52.0 frames per second (FPS) on the V100 platform. This performance surpasses many state-of-the-art methods, highlighting the efficacy of the approach in efficiently detecting a wide range of objects in a zero-shot manner.
After fine-tuning, YOLO-World demonstrates remarkable performance across various downstream tasks, including object detection and open-vocabulary instance segmentation, underscoring its versatility and robustness for real-world applications.
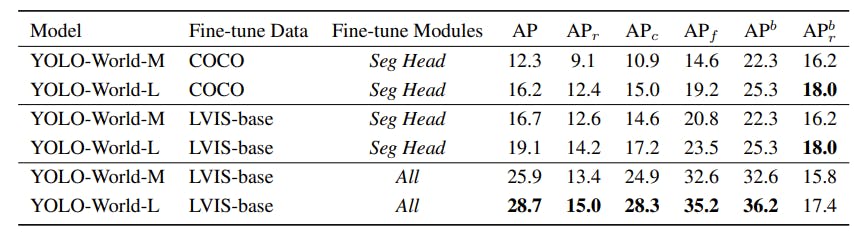
YOLO-World: Real-Time Open-Vocabulary Object Detection
Visualization
In visualizations, YOLO-World’s performance is evaluated across three settings:
- Zero-shot Inference on LVIS: YOLO-World-L detects numerous objects effectively, showcasing its robust transfer capabilities.
- Inference with User's Vocabulary: YOLO-World-L displays fine-grained detection and classification abilities, distinguishing between sub-categories and even detecting parts of objects.
- Referring Object Detection: YOLO-World accurately locates regions or objects based on descriptive noun phrases, showcasing its referring or grounding capability.

YOLO-World: Real-Time Open-Vocabulary Object Detection
Performance Evaluation of YOLO World, GLIP, Grounding DINO
In comparing performance on LVIS object detection, YOLO-World demonstrates superiority over recent state-of-the-art methods such as GLIP, GLIPv2, and Grounding DINO in a zero-shot manner.
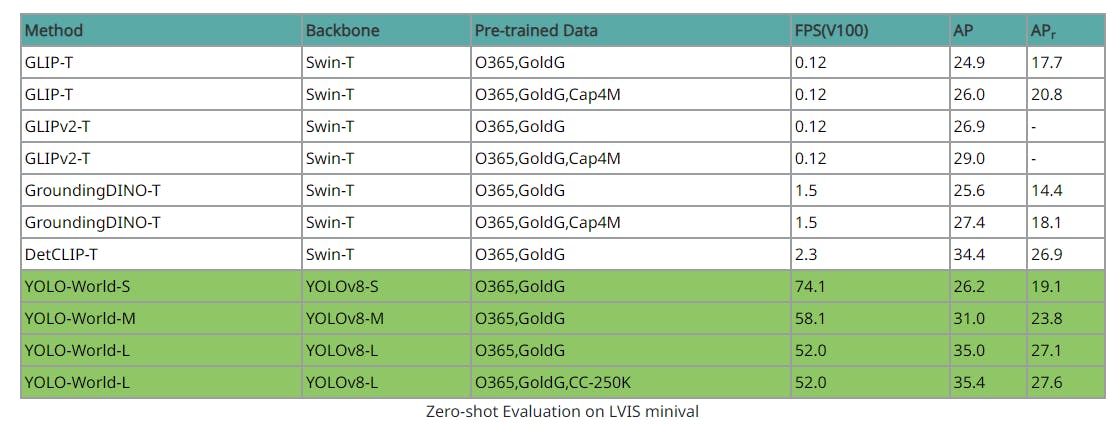
Performance Comparison: GLIP, GLIPv2, and Grounding DINO in a Zero-shot Manner
YOLO-World outperforms these methods in terms of both zero-shot performance and inference speed, particularly when considering lighter backbones like Swin-T. Even when compared to models like GLIP, GLIPv2, and Grounding DINO, which utilize additional data sources such as Cap4M, YOLO-World pre-trained on O365 & GolG achieves better performance despite having fewer model parameters.
GPU Optimization
By efficiently utilizing GPU resources and memory, YOLO-World achieves remarkable speed and accuracy on a single NVIDIA V100 GPU. Leveraging parallel processing capabilities, optimized memory usage, and GPU-accelerated libraries, YOLO-World ensures high-performance execution for both training and inference.
YOLO-World Highlights
- Open-vocabulary detection capability, surpassing fixed category limitations.
- Efficient adaptation to new tasks without heavy computation burdens.
- Simplified deployment, making it practical for real-world applications and edge devices.
- Incorporation of the innovative RepVL-PAN for enhanced performance in object detection.
- Strong zero-shot performance, achieving significant improvements in accuracy and speed on challenging datasets like LVIS.
- Easy adaptation to downstream tasks such as instance segmentation and referring object detection.
- Pre-trained weights and codes made open-source for broader practical use cases.
YOLO-World: What’s Next
With open-vocabulary object detection, YOLO-World has shown improvement in performance against traditional methods. Moving forward, there are different areas for further research:
- Efficiency Enhancements: Efforts can be directed towards improving the efficiency of YOLO-World, particularly in terms of inference speed and resource utilization. This involves optimizing model architectures, leveraging hardware acceleration, and exploring novel algorithms for faster computation.
- Fine-grained Object Detection: YOLO-World could undergo refinement to enhance its capability in detecting fine-grained objects and distinguishing between subtle object categories. This involves exploring advanced feature representation techniques and incorporating higher-resolution image inputs.
- Semantic Understanding: Future developments could focus on enhancing YOLO-World's semantic understanding capabilities, enabling it to grasp contextual information and relationships between objects within a scene. This involves integrating advanced natural language processing (NLP) techniques and multi-modal fusion strategies.
Frequently asked questions
You can either use an object detection dataset like Object365, COCO, GQA, Flickr30k, or CC3M. You can also curate and annotate your own training data as per your use case.
Advancements in GPU architecture, particularly increased computational power and optimized parallel processing, support the real-time performance of YOLO-World by enabling efficient model inference.
YOLO-World can be accessed through open-source repositories on platforms like GitHub, and HuggingFace where pre-trained models, code, api, and documentation are available for download and usage on Colab or on your local system.
YOLO-World differs from previous YOLO models by introducing open-vocabulary detection capabilities through vision-language modeling, pre-training on large-scale datasets, and the RepVL-PAN architecture.
Unlike previous YOLO models, YOLO-World integrates pre-training on large-scale datasets, a frozen CLIP-based text encoder, and the RepVL-PAN architecture to achieve enhanced object detection in real-time.
YOLO-World achieves enhanced object detection at real-time speed through efficient model architecture, GPU optimization, and leveraging pre-trained weights from large-scale datasets for faster inference.
Encord supports object detection through the use of bounding boxes for surgical tools within videos. The platform enables users to classify frames for phase recognition, ensuring that the detection of tools is both accurate and efficient. This functionality is crucial for projects involving complex surgical procedures where precise identification of tools is necessary.
Yes, Encord can assist in training models for custom object detection. Our platform allows users to efficiently annotate and curate datasets for unique objects, like the custom 'handle' objects mentioned, even when data availability is limited. This facilitates scaling training efforts and improving model performance for specific use cases.
Yes, Encord allows users to filter data across different classes, offering the ability to focus on specific labels, such as identifying all frames containing a particular object. This feature enhances data curation and aids in the identification of underperforming classes for targeted improvement.
By providing a robust annotation platform that supports various data types and efficient curation processes, Encord allows users to build high-quality training datasets. This leads to improved performance in object detection models, as they are trained on well-annotated and relevant data.
Encord provides a robust platform for annotating videos, allowing users to create bounding boxes around different objects. This feature is designed to enhance the accuracy and efficiency of object detection tasks, making it ideal for teams looking to streamline their annotation workflows.
Yes, Encord is well-equipped to manage object detection tasks, including drawing bounding boxes and ensuring accurate transcriptions are captured. This functionality is crucial for teams focusing on precise document annotation.
Yes, Encord supports the annotation of both static and moving objects. Users can utilize tools to reliably annotate dynamic objects in the lidar scenes, ensuring comprehensive data coverage and accuracy.