YOLOv9: SOTA Object Detection Model Explained

Discover the cutting-edge advancements in real-time object detection with YOLOv9—the latest evolution in the renowned YOLO series. Whether you're a computer vision enthusiast or a professional seeking the best in object detection, this blog unpacks everything you need to know about YOLOv9's capabilities, improvements, and practical applications.
The YOLO series has revolutionized the world of object detection for long now by introducing groundbreaking concepts in computer vision like processing entire images in a single pass through a convolutional neural network (CNN).
With each iteration, from YOLOv1 to the latest YOLOv9, it has continuously refined and integrated advanced techniques to enhance accuracy, speed, and efficiency, making it the go-to solution for real-time object detection across various domains and scenarios.
Let’s read an overview of YOLOv9 and learn about the new features.
YOLOv9 Overview
YOLOv9 is the latest iteration in the YOLO (You Only Look Once) series of real-time object detection systems. It builds upon previous versions, incorporating advancements in deep learning techniques and architectural design to achieve superior performance in object detection tasks. Developed by combining the Programmable Gradient Information (PGI) concept with the Generalized ELAN (GELAN) architecture, YOLOv9 represents a significant leap forward in terms of accuracy, speed, and efficiency.
Evolution of YOLO
The evolution of the YOLO series of real-time object detectors has been characterized by continuous refinement and integration of advanced algorithms to enhance performance and efficiency.
Initially, YOLO introduced the concept of processing entire images in a single pass through a convolutional neural network (CNN). Subsequent iterations, including YOLOv2 and YOLOv3, introduced improvements in accuracy and speed by incorporating techniques like batch normalization, anchor boxes, and feature pyramid networks (FPN).
These enhancements were further refined in models like YOLOv4 and YOLOv5, which introduced novel techniques such as CSPDarknet and PANet to improve both speed and accuracy. Alongside these advancements, YOLO has also integrated various computing units like CSPNet and ELAN, along with their variants, to enhance computational efficiency.
In addition, improved prediction heads like YOLOv3 head or FCOS head have been utilized for precise object detection. Despite the emergence of alternative real-time object detectors like RT DETR, based on DETR architecture, the YOLO series remains widely adopted due to its versatility and applicability across different domains and scenarios.
The latest iteration, YOLOv9, builds upon the foundation of YOLOv7, leveraging the Generalized ELAN (GELAN) architecture and Programmable Gradient Information (PGI) to further enhance its capabilities, solidifying its position as the top real-time object detector of the new generation.
The evolution of YOLO demonstrates a continuous commitment to innovation and improvement, resulting in state-of-the-art performance in real-time object detection tasks.
YOLOv9 Key Features
| Feature | Details |
| Object Detection in Real-Time | Can swiftly process input images or video streams and accurately detect objects within them without compromising on speed. |
| PGI Integration | Incorporates the Programmable Gradient Information (PGI) concept, which facilitates the generation of reliable gradients through an auxiliary reversible branch. This ensures that deep features retain crucial characteristics necessary for executing target tasks, addressing the issue of information loss during the feedforward process in deep neural networks. |
| GELAN Architecture | Or, Generalized ELAN (GELAN) architecture, which is designed to optimize parameters, computational complexity, accuracy, and inference speed. By allowing users to select appropriate computational blocks for different inference devices, GELAN enhances the flexibility and efficiency of YOLOv9 |
| Improved Performance | Achieves top performance in object detection tasks on benchmark datasets like MS COCO. It surpasses existing real-time object detectors in terms of accuracy, speed, and overall performance, making it a state-of-the-art solution for various applications requiring object detection capabilities. |
| Flexibility and Adaptability | Designed to be adaptable to different scenarios and use cases. Its architecture allows for easy integration into various systems and environments, making it suitable for a wide range of applications, including surveillance, autonomous vehicles, robotics, and more. |
Updates on YOLOv9 Architecture
Integrating Programmable Gradient Information (PGI) and GLEAN (Generative Latent Embeddings for Object Detection) architecture into YOLOv9 can enhance its performance in object detection tasks. Here's how these components can be integrated into the YOLOv9 architecture to enhance performance:
PGI Integration
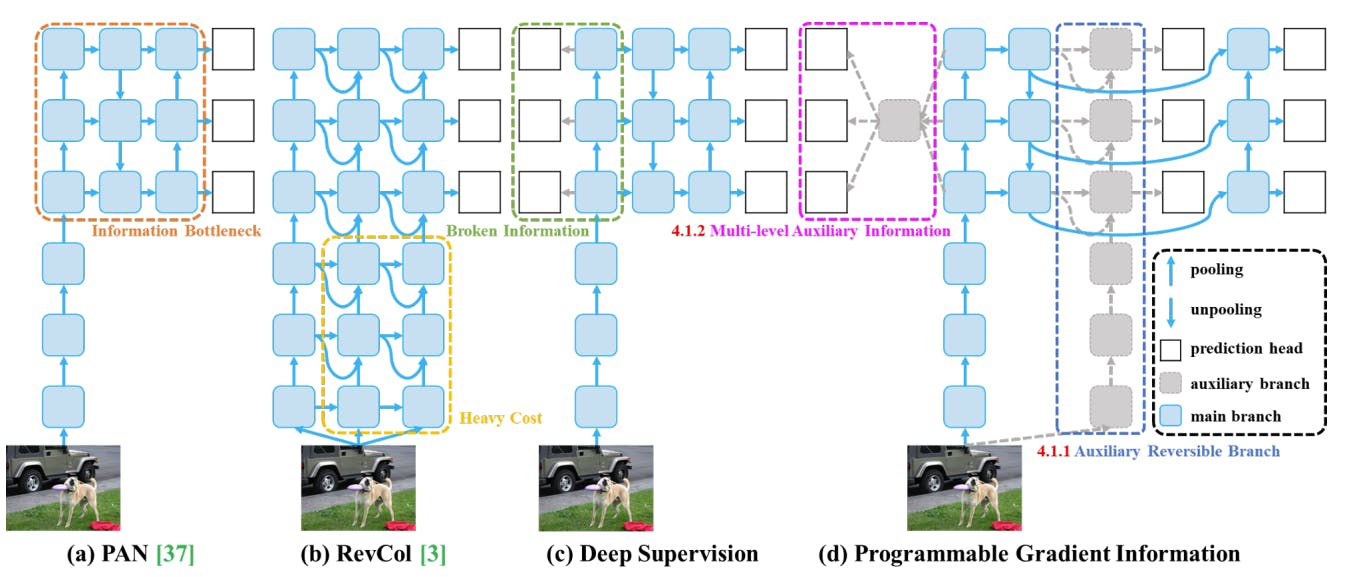
Yolov9: Learning What You Want to Learn Using Programmable Gradient Information
- Main Branch Integration: The main branch of PGI, which represents the primary pathway of the network during inference, can be seamlessly integrated into the YOLOv9 architecture. This integration ensures that the inference process remains efficient without incurring additional computational costs.
- Auxiliary Reversible Branch: YOLOv9, like many deep neural networks, may encounter issues with information bottleneck as the network deepens. The auxiliary reversible branch of PGI can be incorporated to address this problem by providing additional pathways for gradient flow, thereby ensuring more reliable gradients for the loss function.
- Multi-level Auxiliary Information: YOLOv9 typically employs feature pyramids to detect objects of different sizes. By integrating multi-level auxiliary information from PGI, YOLOv9 can effectively handle error accumulation issues associated with deep supervision, especially in architectures with multiple prediction branches. This integration ensures that the model can learn from auxiliary information at multiple levels, leading to improved object detection performance across different scales.
GLEAN Architecture
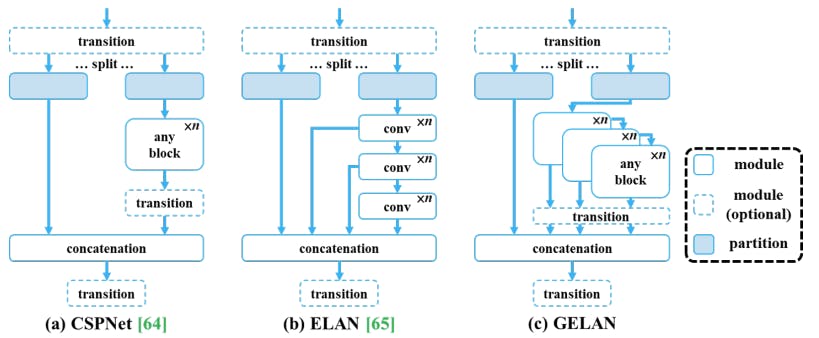
Generalized Efficient Layer Aggregation Network or GELAN is a novel architecture that combines CSPNet and ELAN principles for gradient path planning. It prioritizes lightweight design, fast inference, and accuracy. GELAN extends ELAN's layer aggregation by allowing any computational blocks, ensuring flexibility.
The architecture aims for efficient feature aggregation while maintaining competitive performance in terms of speed and accuracy. GELAN's overall design integrates CSPNet's cross-stage partial connections and ELAN's efficient layer aggregation for effective gradient propagation and feature aggregation.
YOLOv9 Results
The performance of YOLOv9, as verified on the MS COCO dataset for object detection tasks, showcases the effectiveness of the integrated GELAN and PGI components:
Parameter Utilization
YOLOv9 leverages the Generalized ELAN (GELAN) architecture, which exclusively employs conventional convolution operators. Despite this, YOLOv9 achieves superior parameter utilization compared to state-of-the-art methods that rely on depth-wise convolution. This highlights the efficiency and effectiveness of YOLOv9 in optimizing model parameters while maintaining high performance in object detection.
Flexibility and Scalability
The Programmable Gradient Information (PGI) component integrated into YOLOv9 enhances its versatility. PGI allows YOLOv9 to be adaptable across a wide spectrum of models, ranging from light to large-scale architectures. This flexibility enables YOLOv9 to accommodate various computational requirements and model complexities, making it suitable for diverse deployment scenarios.
Information Retention
By utilizing PGI, YOLOv9 ensures handling data loss at every layer ensuring the retention of complete information during the training process. This capability is particularly beneficial for train-from-scratch models, as it enables them to achieve superior results compared to models pre-trained using large datasets. YOLOv9's ability to preserve crucial information throughout training contributes to its high accuracy and robust performance in object detection tasks.
Comparison of YOLOv9 with SOTA Models
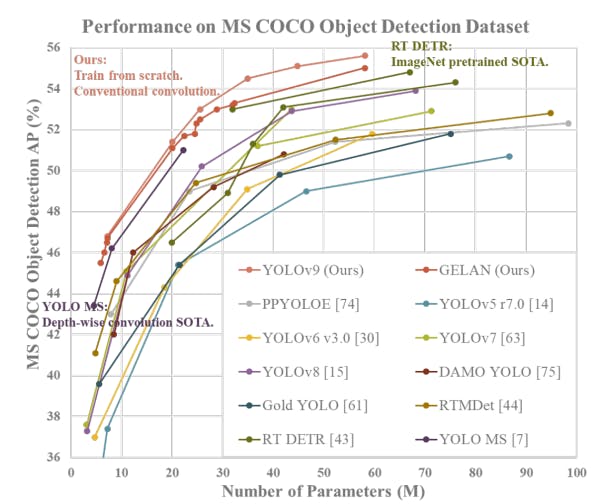
Comparison of YOLOv9 with SOTA Model
The comparison between YOLOv9 and state-of-the-art (SOTA) models reveals significant improvements across various metrics. YOLOv9 outperforms existing methods in parameter utilization, requiring fewer parameters while maintaining or even improving accuracy.
YOLOv9 demonstrates superior computational efficiency compared to both train-from-scratch methods and models based on depth-wise convolution and ImageNet-based pretrained models.
Creating Custom Dataset for YOLOv9 on Encord for Object Detection
With Encord you can either curate and create your custom dataset or use the sandbox datasets already created on Encord Active platform.
Select New Dataset to Upload Data
You can name the dataset and add a description to provide information about the dataset.
Annotate Custom Dataset
Create an annotation project and attach the dataset and the ontology to the project to start annotation with a workflow.

You can choose manual annotation if the dataset is simple, small, and doesn’t require a review process. Automated annotation is also available and is very helpful in speeding up the annotation process.

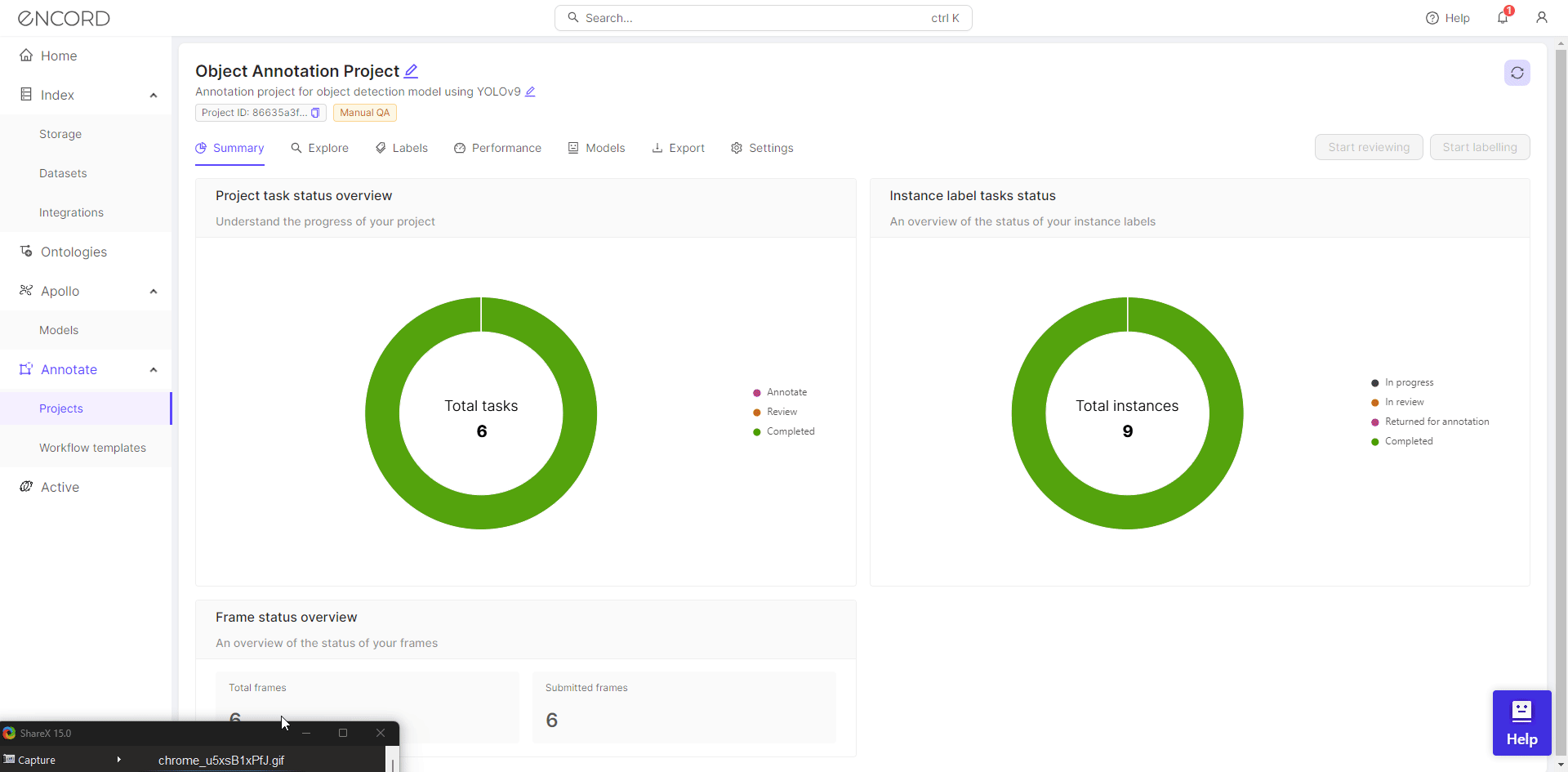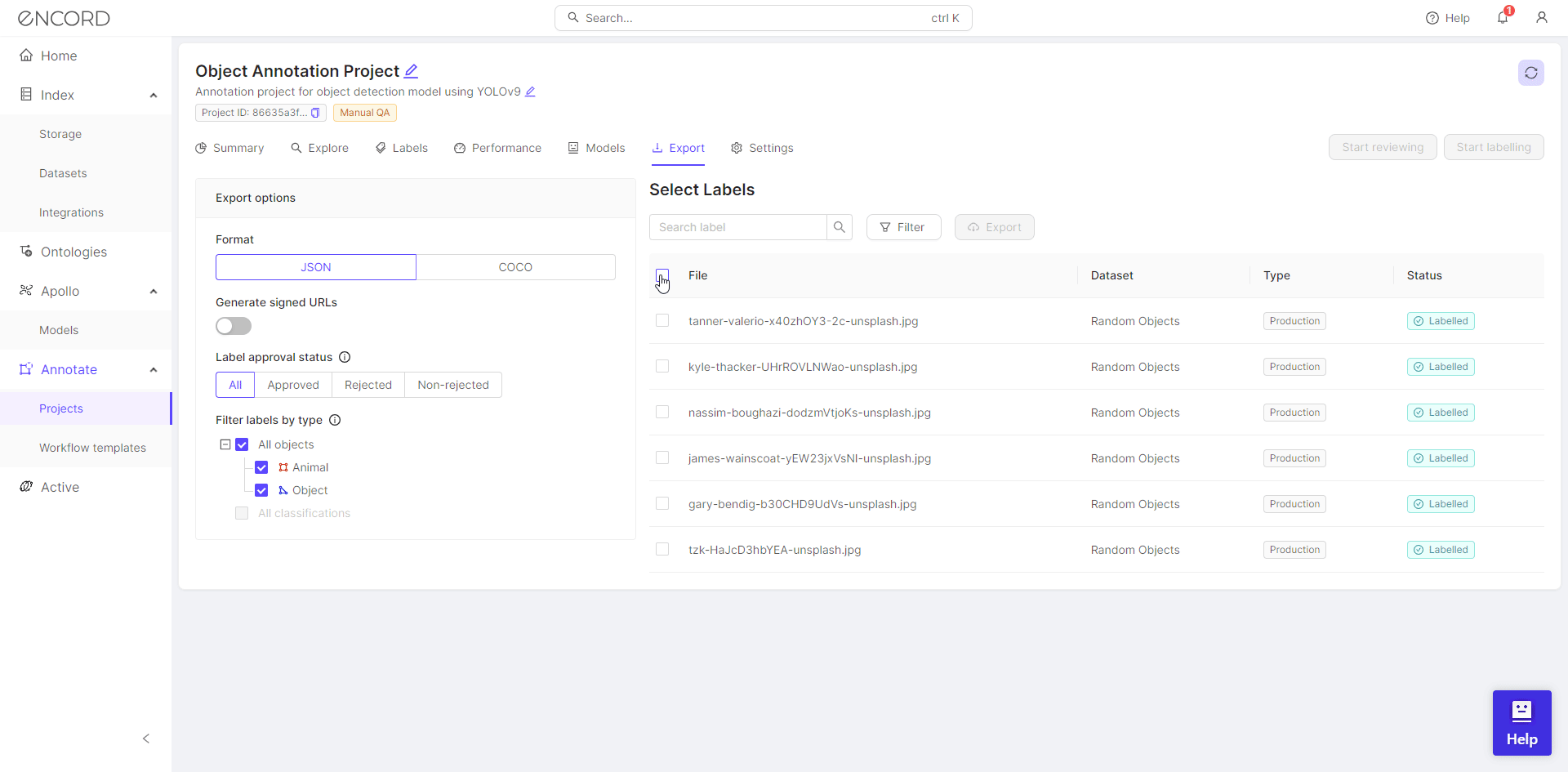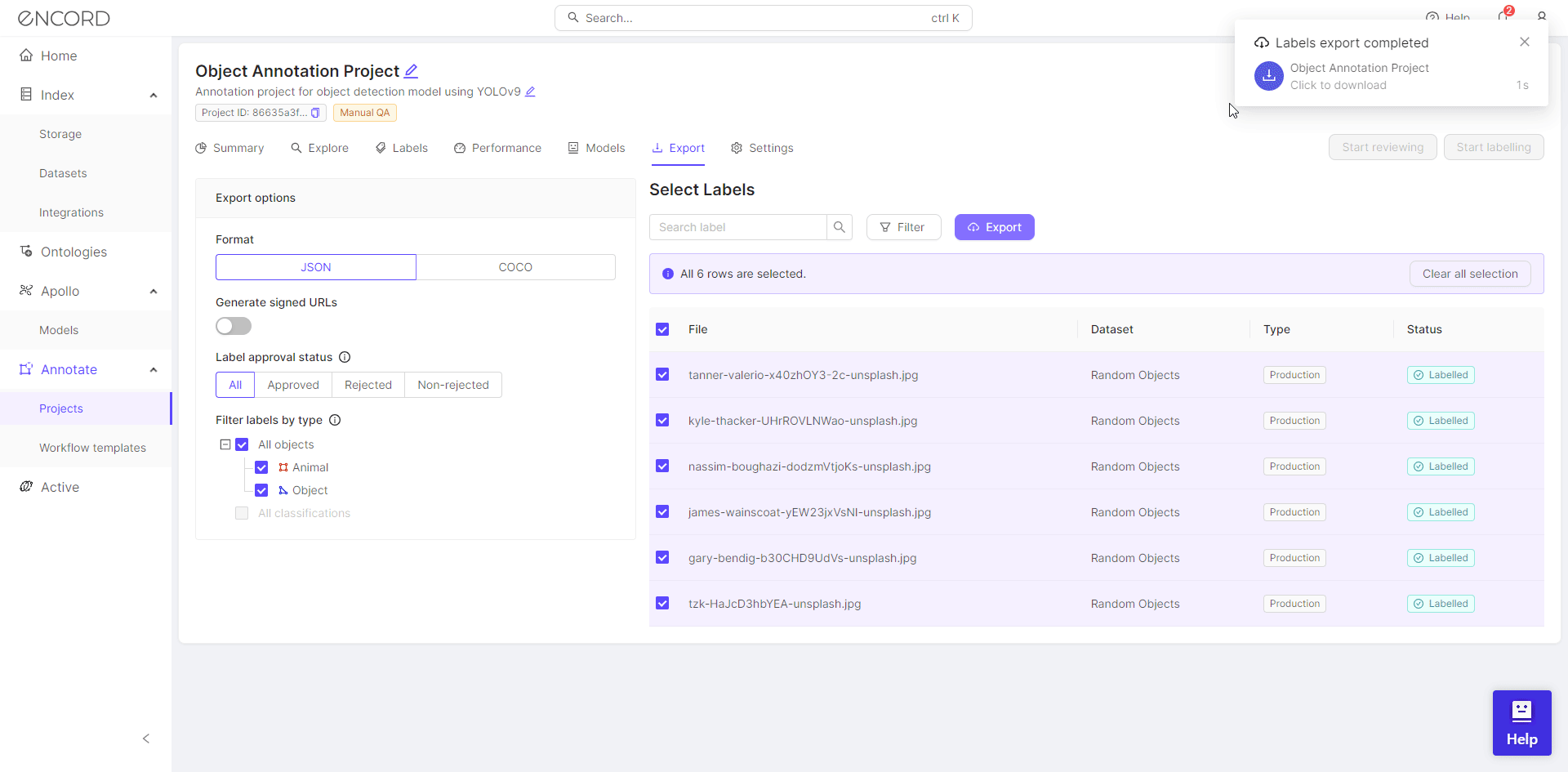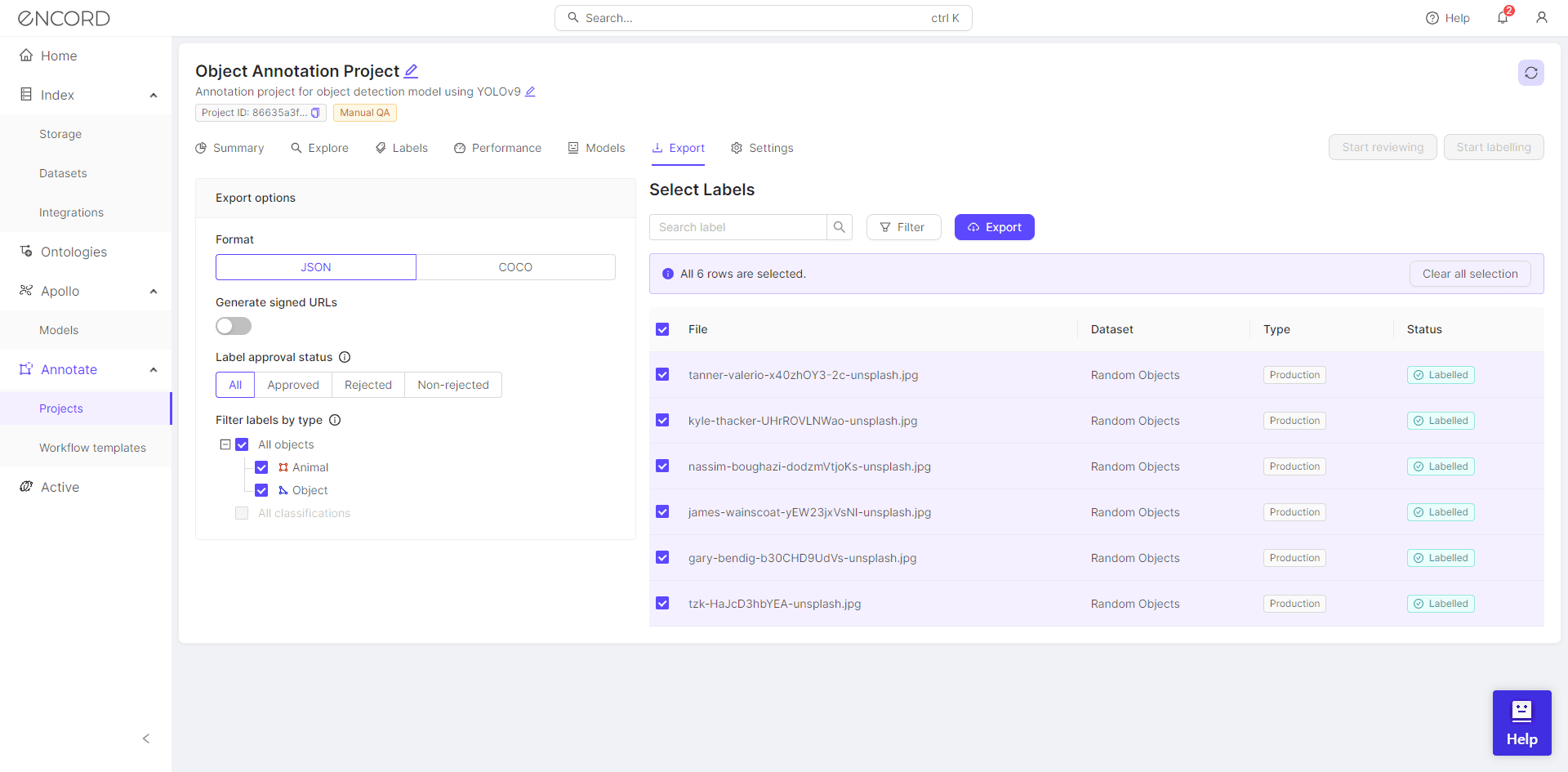
Start Labeling
The summary page shows the progress of the annotation project. The information regarding the annotators and the performance of the annotators can be found under the tabs labels and performance.

Export the Annotation
Once the annotation has been reviewed, export the annotation in the required format.
Object Detection using YOLOv9 on Custom Dataset
You can use the custom dataset curated using Encord Annotate for training an object detection model. For testing YOLOv9, we are going to use an image from one of the sandbox projects on Encord Active.
Copy and run the code below to run YOLOv9 for object detection. The code for using YOLOv9 for panoptic segmentation has also been made available now on the original GitHub repository.
Installing YOLOv9
!git clone https://github.com/WongKinYiu/yolov9.git
Installing YOLOv9 Requirements
!python -m pip install -r yolov9/requirements.txt
Download YOLOv9 Model Weights
The YOLOv9 is available as 4 models which are ordered by parameter count:
- YOLOv9-S
- YOLOv9-M
- YOLOv9-C
- YOLOv9-E
Here we will be using YOLOv9-e. But the same process follows for other models.
from pathlib import Path
weights_dir = Path("/content/weights")
weights_dir.mkdir(exist_ok=True)
!wget 'https://github.com/WongKinYiu/yolov9/releases/download/v0.1/yolov9-e.pt' -O /content/weights/yolov9-e.ptDefine the Model
p_to_add = "/content/yolov9"
import sys
if p_to_add not in sys.path:
sys.path.insert(0, p_to_add)
from models.common import DetectMultiBackend
weights = "/content/weights/yolov9-e.pt"
model = DetectMultiBackend(weights)Download Test Image from Custom Dataset
images_dir = Path("/content/images")
images_dir.mkdir(exist_ok=True)
!wget 'https://storage.googleapis.com/encord-active-sandbox-projects/f2140a72-c644-4c31-be66-3ef80b3718e5/a0241c5f-457d-4979-b951-e75f36d0ff2d.jpeg' -O '/content/images/example_1.jpeg'This is the sample image we will be using for testing YOLOv9 for object detection.

Dataloader
from utils.torch_utils import select_device, smart_inference_mode
from utils.dataloaders import IMG_FORMATS, VID_FORMATS, LoadImages, LoadScreenshots, LoadStreams
from utils.general import (LOGGER, Profile, check_file, check_img_size, check_imshow, check_requirements, colorstr, cv2,
increment_path, non_max_suppression, print_args, scale_boxes, strip_optimizer, xyxy2xywh)
image_size = (640, 640)
img_path = Path("/content/images/example_1.jpeg")
device = select_device("cpu")
vid_stride = 1
stride, names, pt = model.stride, model.names, model.pt
imgsz = check_img_size(image_size, s=stride) # check image size
# Dataloader
bs = 1 # batch_size
dataset = LoadImages(img_path, img_size=image_size, stride=stride, auto=pt, vid_stride=vid_stride)
model.warmup(imgsz=(1 if pt or model.triton else bs, 3, *imgsz)) # warmupRun Prediction
import torch
augment = False
visualize = False
conf_threshold = 0.25
nms_iou_thres = 0.45
max_det = 1000
seen, windows, dt = 0, [], (Profile(), Profile(), Profile())
for path, im, im0s, vid_cap, s in dataset:
with dt[0]:
im = torch.from_numpy(im).to(model.device).float()
im /= 255 # 0 - 255 to 0.0 - 1.0
if len(im.shape) == 3:
im = im[None] # expand for batch dim
# Inference
with dt[1]:
pred = model(im, augment=augment, visualize=visualize)[0]
# NMS
with dt[2]:
filtered_pred = non_max_suppression(pred, conf_threshold, nms_iou_thres, None, False, max_det=max_det)
print(pred, filtered_pred)
break
Generate YOLOv9 Prediction on Custom Data
import matplotlib.pyplot as plt
from matplotlib.patches import Rectangle
from PIL import Image
img = Image.open("/content/images/example_1.jpeg")
fig, ax = plt.subplots()
ax.imshow(img)
ax.axis("off")
for p, c in zip(filtered_pred[0], ["r", "b", "g", "cyan"]):
x, y, w, h, score, cls = p.detach().cpu().numpy().tolist()
ax.add_patch(Rectangle((x, y), w, h, color="r", alpha=0.2))
ax.text(x+w/2, y+h/2, model.names[int(cls)], ha="center", va="center", color=c)
fig.savefig("/content/predictions.jpg")Here is the result!

Training YOLOv9 on Custom Dataset
The YOLOV9 GitHub repository contains the code to train on both single and multiple GPU. You can check it out for more information.
Stay tuned for the training code for YOLOv9 on custom dataset and a comparison analysis of YOLOv8 vs YOLOv8!
YOLOv9 Key Takeaways
- Cutting-edge real-time object detection model.
- Advanced Architectural Design: Incorporates the Generalized ELAN (GELAN) architecture and Programmable Gradient Information (PGI) for enhanced efficiency and accuracy.
- Unparalleled Speed and Efficiency Compared to SOTA: Achieves top performance in object detection tasks with remarkable speed and efficiency.
Frequently asked questions
The latest version of Yolo object detection is YOLOv9. It represents the newest iteration in the YOLO (You Only Look Once) series, incorporating advanced techniques and architectural design for superior real-time object detection.
YOLOv9 utilizes the Generalized ELAN (GELAN) architecture and Programmable Gradient Information (PGI) for enhanced efficiency and accuracy. This innovative architecture optimizes parameters, computational complexity, and inference speed.
Though YOLOv9 shows promising results, it needs to be tested in the real world to claim it as the best YOLO. The last version of YOLO, the YOLOv8 by Ultralytics shows great performance as well.
The key advantage of YOLOv9 over traditional Yolo architectures lies in its advanced features like the Generalized ELAN (GELAN) architecture and Programmable Gradient Information (PGI). These enhancements ensure superior performance, flexibility, and adaptability, making YOLOv9 the top choice for real-time object detection.
YOLOv9 is open sourced and available for implementation on WongKinYiu’s GitHub. This Pytorch implementation has code for training it on single or multiple GPU.
Encord offers a suite of tools designed to optimize the training and evaluation process for machine learning models. With features for model curation, annotation, and evaluation, Encord enables teams to efficiently manage their training data, ensuring high-quality outputs for applications like vehicle part verification.
Yes, Encord's model evaluation dashboard allows users to filter prediction outcomes by specific classes. Users can select particular classes of interest to view detailed performance metrics, including true positives, false positives, and false negatives, ensuring targeted analysis of model performance.
Encord offers robust tools and features designed specifically for deep learning model building and training. Our platform facilitates data curation, annotation, and model evaluation, helping teams streamline their machine learning operations and enhance the efficiency of their data pipelines.
Encord allows users to combine various models in the annotation workflow, integrating machine learning with human oversight. This approach not only speeds up the annotation process but also improves overall quality by leveraging the strengths of different models.
Encord fits into the machine learning pipeline by providing tools for data cleaning, curation, and annotation after data collection. It also offers model evaluation capabilities, ensuring a comprehensive solution from data preparation to model assessment.
Encord includes functionalities for model evaluation that allow users to compare ground truth data against predictions. This feature is essential for assessing model performance and improving machine learning workflows.