Convolutional Neural Network (CNN)
Encord Computer Vision Glossary
In the realm of deep learning, Convolutional Neural Networks (CNNs) have revolutionized the field of visual analysis. With their ability to extract intricate patterns and features from images, CNNs have become indispensable for tasks like image classification, object detection, and facial recognition. This article provides a comprehensive overview of CNNs, exploring their architecture, training process, applications, and advantages. From understanding the convolutional layers to grasping the power of pooling and fully connected layers, delve into the world of CNNs and discover how they have transformed visual analysis in the era of artificial intelligence.

Convolutional Neural Networks
Convolutional Neural Networks (CNNs) are a class of deep learning models specifically designed for processing visual data. They mimic the hierarchical organization of the human visual system, making them highly effective in understanding and interpreting images. CNNs excel in tasks such as image classification, object detection, and segmentation.
Convolutional Neural Networks Architecture
The architecture of convolutional neural networks (CNNs) consists of several layers that work together to extract and learn meaningful features from images. This unique design allows CNNs to excel in tasks such as image classification, object detection, and semantic segmentation. Let's explore the key components of the CNN architecture:
Convolutional Layers
The core of a CNN is the convolutional layer. It applies a set of learnable filters to the input image, convolving them across the image spatially. Each filter learns to detect specific patterns or features, such as edges, corners, or textures. The output of this layer is a set of feature maps, where each map represents the activation of a particular filter.
Activation Functions
Activation functions, such as Rectified Linear Units (ReLU), are typically applied after the convolutional layers. They introduce non-linearity to the network, enabling CNNs to learn complex relationships between features. ReLU, for example, sets negative values to zero and keeps positive values intact, enhancing the network's ability to model non-linear transformations.
Pooling Layers
Pooling layers downsample the feature maps, reducing the spatial dimensions of the data. Max pooling is a commonly used technique, where the maximum value within a region is selected and retained while discarding the rest. Pooling helps in reducing computational complexity, improving translation invariance, and capturing the most salient features.
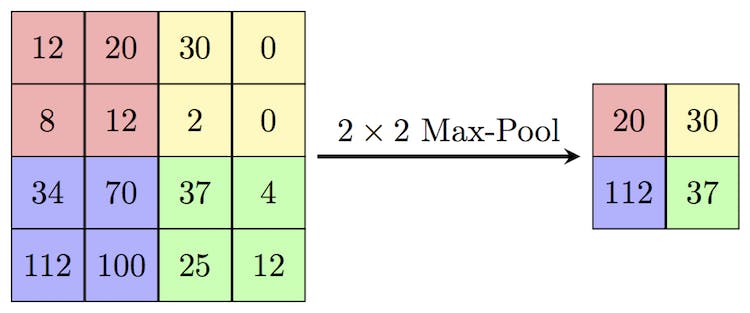
Fully Connected Layers
Fully connected layers, also known as dense layers, are responsible for making final predictions based on the extracted features. These layers connect every neuron from the previous layer to every neuron in the current layer. They integrate information from the feature maps and learn high-level representations, enabling classification or regression tasks.
Dropout
Dropout is a regularization technique often used in CNNs to prevent overfitting. During training, randomly selected neurons in the network are temporarily dropped out, meaning their outputs are set to zero. This forces the network to rely on the remaining neurons and prevents co-adaptation of neurons, enhancing generalization.
Softmax Layer
In classification tasks, a softmax layer is typically used at the end of the CNN architecture. It normalizes the outputs of the last fully connected layer, assigning probabilities to each class. The class with the highest probability is considered the predicted label.
The architecture of CNNs typically follows a sequential pattern, starting with alternating convolutional and pooling layers, followed by fully connected layers. The number of layers, their sizes, and the arrangement can vary based on the complexity of the task and available computational resources.
Training Convolutional Neural Networks
Training CNNs involves two key steps: forward propagation and backpropagation. In forward propagation, input data passes through the network, and intermediate features are computed. Backpropagation then adjusts the network's weights based on the computed error, optimizing its ability to make accurate predictions. This iterative process, driven by large datasets and powerful GPUs, allows CNNs to learn intricate patterns and generalize to unseen data.
Applications of Convolutional Neural Networks
CNNs have revolutionized various domains of visual analysis. In image classification, they can accurately categorize images into predefined classes. Object detection enables CNNs to identify and locate multiple objects within an image. Additionally, CNNs play a vital role in facial recognition, medical image analysis, autonomous vehicles, and more.
Advantages of Convolutional Neural Networks
CNNs offer several advantages over traditional computer vision techniques. They automatically learn features from raw data, eliminating the need for manual feature engineering. The convolutional layers capture spatial hierarchies, enabling effective feature extraction. CNNs are also highly adaptable, capable of handling diverse input sizes and various image characteristics. Moreover, their ability to generalize from large datasets empowers CNNs to achieve impressive performance in visual analysis tasks.

Conclusion
Convolutional Neural Networks (CNNs) have transformed visual analysis with their ability to extract intricate patterns and features from images. From image classification to object detection and facial recognition, CNNs have become the go-to tool for understanding and interpreting visual data. By mimicking the human visual system and leveraging deep learning techniques, CNNs offer unprecedented accuracy and efficiency in analyzing complex images. As CNNs continue to evolve and be integrated into various domains, their impact on computer vision and artificial intelligence will only grow stronger, opening new doors for innovation and advancements in the field.