Introduction to Balanced and Imbalanced Datasets in Machine Learning

Product Manager at Encord
When it comes to determining model performance, ML engineers need to know if their classification models are predicting accurately. However, because of the accuracy paradox, they should never rely on accuracy alone to evaluate a model’s performance.
The trouble with accuracy is that it’s not necessarily a good metric for determining how well a model will predict outcomes. It’s counterintuitive (hence the paradox), but depending on the data that it encounters during training, a model can become biased towards certain predictions that result in a high percentage of accurate predictions but poor overall performance. A model might report having very accurate predictions, but, in reality, that accuracy might only be a reflection of the way it learned to predict when trained on an imbalanced dataset.
What is Imbalanced Data?
Classification models attempt to categorize data into different buckets. In an imbalanced dataset, one bucket makes up a large portion of the training dataset (the majority class), while the other bucket is underrepresented in the dataset (the minority class). The problem with a model trained on imbalanced data is that the model learns that it can achieve high accuracy by consistently predicting the majority class, even if recognizing the minority class is equal or more important when applying the model to a real-world scenario.

Consider the case of collecting training data for a model predicting medical conditions. Most of the patient data collected, let’s say 95 percent, will likely fall into the healthy bucket, while the sick patients make up a much smaller portion of the data. During training, the classification model learns that it can achieve 95 percent accuracy if it predicts “healthy” for every piece of data it encounters. That’s a huge problem because what doctors really want the model to do is identify those patients suffering from a medical condition.
Why Balancing Your Datasets Matters
Although models trained on imbalanced data often fall victim to the accuracy paradox, good ML teams use other metrics such as precision, recall, and specificity to decompose accuracy. These metrics answer different questions about model performance, such as “Out of all the sick patients, how many were actually predicted sick?” (recall). Imbalanced data can skew the outcomes for each metric, so testing a model’s performance across many metrics is key for determining how well a model actually works.
Imbalanced datasets create challenges for predictive modeling, but they’re actually a common and anticipated problem because the real world is full of imbalanced examples.
Balancing a dataset makes training a model easier because it helps prevent the model from becoming biased towards one class. In other words, the model will no longer favor the majority class just because it contains more data.
We’ll use the following running example throughout the article to explain this and other concepts. In the example, cats are from the majority class, and the dog is from the minority.

Example of an unbalanced dataset
Now, let’s look at some strategies that ML teams can use to balance their data.
Collect More Data
When ML teams take a data-centric approach to AI, they know that the data is the tool that powers the model. In general, the more data you have to train your model on, the better its performance will be. However, selecting the right data, and ensuring its quality, is also essential for improving model performance.
So the first question to ask when you encounter an imbalanced dataset is: Can I get more quality data from the underrepresented class?
ML teams can take two approaches to source more data. They can attempt to obtain more “true” data from real-world examples, or they can manufacture synthetic data, using game engines or generative adversarial networks.
In our running example, the new dataset would look like this:

Undersampling
If you can’t get more data, then it’s time to start implementing strategies designed to even out the classes.
Undersampling is a balancing strategy in which we remove samples from the over-represented class until the minority and majority classes have an equal distribution of data. Although in most cases it’s ill-advised, undersampling has some advantages: it’s relatively simple to implement, and it can improve the model’s run-time and compute costs because it reduces the amount of training data.
However, undersampling must be done carefully since removing samples from the original dataset could result in the loss of useful information. Likewise, if the original dataset doesn’t contain much data to begin with, then undersampling puts you at risk of developing an overfit model.
For instance, if the original dataset contains only 100 samples– 80 from the majority class and 20 from the minority class– and I remove 60 from the majority class to balance the dataset, I’ve just disregarded 60 percent of the data collected. The model now only has 40 data points on which to train. With so little data, the model will likely memorize the data training data and fail to generalize when it encounters never-before-seen data.
With undersampling, the datasets in our running example could look like this, which is obviously not ideal.

Achieving a balanced dataset at the risk of overfitting is a big tradeoff, so ML teams will want to think carefully about the types of problems for which they use undersampling.
Suppose the underrepresented class has a small number of samples. In that case, it’s probably not a good idea to use undersampling because the size of the balanced dataset will increase the risk of overfitting.
However, undersampling can be a good option when the problem which the model is trying to solve is relatively simple. For instance, if the samples in the two classes are easy to distinguish because they don’t have much overlap, then the model doesn’t need as much data to learn to make a prediction because it’s unlikely to confuse one class for another, and it’s less likely to encounter noise in the data.
Undersampling can be a good option when training models to predict simple tabular data problems. However, most computer vision problems are too complicated for undersampling. Think about basic image classification problems. An image of a black cat and a white cat might appear very different to a human. Still, a computer vision model takes in all the information in the image: the background, the percent of the image occupied by a cat, the pixel values, and more. What appears as a simple distinction to the human eye is a much more complicated decision in a model's eyes.
In general, ML teams think twice before throwing away data, so they’ll typically favour other methods of balancing data, such as oversampling.
Oversampling
Oversampling increases the number of samples in the minority class until its makeup is equal to that of the majority class. ML teams make copies of the samples in the underrepresented class so that the model encounters an equal number of samples from each class, decreasing the likelihood of it becoming biased towards the majority class.
Unlike undersampling, oversampling doesn’t involve throwing away data, so it can help ML teams solve the problem of insufficient data without the risk of losing important information. However, because the minority class is still composed of a limited amount of unique data points, the model is susceptible to memorizing data patterns and overfitting.
To mitigate the risk of overfitting, ML teams can augment the data so that the copies of the samples in the minority class vary from the originals. When training a computer vision model on image data, they could compose any number of augmentations like rotating images, changing their brightness, cropping them, increasing their sharpness or blurriness, and more to simulate a more diverse dataset. Even algorithms are designed to help find the best augmentations for a dataset.
With oversampling, the datasets in our running example could look like this:

Weighting Your Loss Function
As an alternative to oversampling, you can adjust your loss-function to account for the uneven class distribution. In a classification model, unweighted loss functions treat all misclassifications as similar errors, but penalty weights instruct the algorithm to treat prediction mistakes differently depending on whether the mistake occurred when predicting for the minority or majority class. Adding penalty weights injects intentional bias into the model, preventing it from prioritizing the majority class.
If an algorithm has a higher weight on the minority class and a reduced weight on the majority class, it will penalize misclassifications from the underrepresented class more than those from the overrepresented class. With penalty weights, ML teams can bias a model towards paying more attention to the minority class during training, thus creating a balance between the classes.
Let’s look at a simple example. Suppose you have six training examples, of which five samples are of cats and one is of a dog. If you were to oversample, you would make a dataset with five different cats and five copies of the dog. When you compute your loss function on this oversampled dataset, cats and dogs would contribute equally to the loss.
With loss-weighting, however, you wouldn’t oversample but simply multiply the loss for each individual sample with its class’s inverse number of samples (INS)
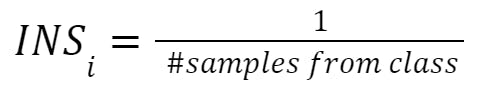
That way, each of the five cat samples would contribute one-fifth to the loss, while the loss of the dog samples wouldn’t be scaled. In turn, the cat and the dog class would contribute equally.
Theoretically, this approach is equivalent to oversampling. The advantage here is that it takes only a few simple lines of code to implement, and it even works for multi-class problems.
Although ML engineers typically use this approach along with data augmentation, the overfitting problem can persist since models can still remember the minority class(es) in many cases. To mitigate this problem, they will likely need to use model regularisation such as dropout or consider adding penalty weights to the model.
Using a Variety of Metrics to Test Model Performance
Every time ML teams retrain their model on an altered dataset; they should check the model’s performance using different metrics.
All of the above techniques require some form of trial and error, so testing the model on never-before-seen datasets is critical to ensuring that retraining the model on a balanced dataset resulted in an acceptable level of performance.
Remember, a model’s performance scores on its training data do not reflect how it will perform “in the wild.” A sufficiently complex model can obtain 100 percent accuracy, perfect precision, and flawless recall of training data because it has learned to memorize the data’s patterns. To be released “in the wild,” a model should perform well on never-before-seen data because its performance indicates what will happen when applied in the real world.

Balancing Datasets Using Encord Active
Encord Active is an open-source active learning toolkit that can help you achieve a balanced dataset. By using its data quality metrics, you can evaluate the distribution of images or individual video frames without considering labels. These metrics show any class imbalance in your dataset, highlighting potential biases or underrepresented classes.
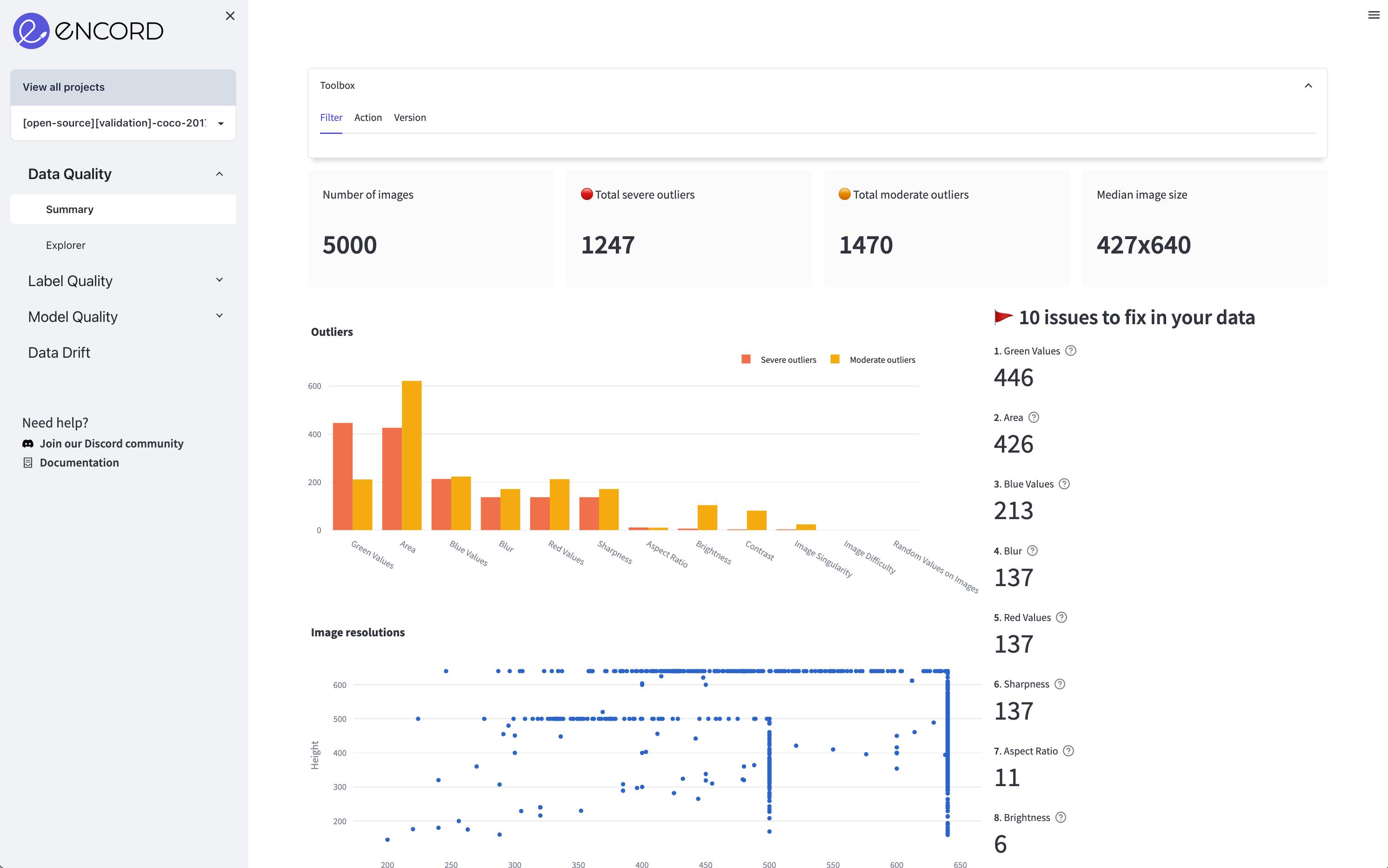
The toolkit's label quality metrics focus on the geometries of objects, such as bounding boxes, polygons, and polylines. This allows you to spot labeling errors or inaccuracies in the annotated data.
Visualizing your labeled data's distribution using Encord Active's tools can help you identify class imbalances or gaps in your dataset. Once you have this information, you can prioritize high-value data for re-labeling, focusing on areas with limited representation or potential model failure modes.
Whether you are beginning to collect data, have labeled samples, or have models in production, Encord Active offers valuable support at all stages of your computer vision journey. Using this toolkit to balance your dataset can improve data quality, address class imbalances, and enhance your model's performance and accuracy.

Frequently asked questions
Classification models attempt to categorize data into different buckets. In an imbalanced dataset, one bucket makes up a large portion of the training dataset (the majority class), while the other bucket is underrepresented in the dataset (the minority class).
Every time ML teams retrain their model on an altered dataset; they should check the model’s performance using different metrics. Testing the model on never-before-seen datasets is critical to ensuring that retraining the model on a balanced dataset resulted in an acceptable level of performance.
ML teams employ various tactics to balance data, including: collect more data, undersampling, oversampling, weighting your loss function
Imbalanced datasets create challenges for predictive modeling, but they’re actually a common and anticipated problem because the real world is full of imbalanced examples.
Encord provides features that assist in data curation, enabling users to balance and integrate various datasets effectively. This ensures that your model training is supported by a well-rounded dataset that includes both common and edge case scenarios, which is essential for achieving high accuracy in high-stakes applications.
Having a strong but lean team is crucial when using Encord, as it allows for focused efforts on significant projects without being overwhelmed by resources. This approach enables teams to prioritize their goals, efficiently manage their time, and achieve better outcomes in machine learning initiatives.
Encord assists users in creating balanced datasets by enabling the selection and curation of both defective and non-defective images. This ensures that the training data maintains an appropriate distribution across various product types, which is crucial for training effective machine learning models.
Encord offers tools that allow users to upload their data and automate the process of obtaining statistics on various object types. This enables users to effectively subsample frames before sending them for annotation, ensuring a balanced representation of classes for training.
Yes, Encord helps address class imbalance by enabling users to curate and sample data effectively, ensuring that they can collect more examples of underrepresented classes, such as packages at doorsteps, which is critical for training accurate machine learning models.
Yes, Encord is designed to efficiently manage large datasets, including those that may consist of several terabytes of data. It offers features that allow users to split datasets into manageable jobs, optimizing the training process for machine learning models.
Yes, Encord is equipped to manage large datasets, facilitating efficient annotation and versioning. Our platform is designed to streamline the annotation process, ensuring that teams can work with extensive data collections without compromising on quality.
Encord allows users to sample a percentage of their dataset, ensuring that the selected samples are well-balanced and relevant to the project. This is particularly useful for large datasets where a complete review may not be feasible.