Active Learning in Machine Learning: Guide & Strategies [2025]

ML Lead at Encord
Active learning is a supervised machine learning approach that aims to optimize annotation using a few small training samples. One of the biggest challenges in building machine learning (ML) models is annotating large datasets. Active learning can help you overcome these challenges.
If you are building ML models, you must ensure that you have large enough volumes of annotated data and that your data contains valuable information from which your machine learning models can learn.
Unfortunately, data annotation can be a costly and time-consuming endeavor, especially when outsourcing this work to large teams of human annotators. Many teams don’t have the time, money, or manpower to label and review each piece of data in these vast datasets.
Fortunately, active learning pipelines and active learning algorithms and platforms can make this task much simpler, faster, and more accurate.
Active learning is a powerful technique that can help overcome these challenges by allowing a machine learning model to selectively query a human annotator for the most informative data points to label in image or video-based datasets. By iteratively selecting the most informative samples to label, active learning can help improve the accuracy of machine learning models while reducing the amount of labeled data required.
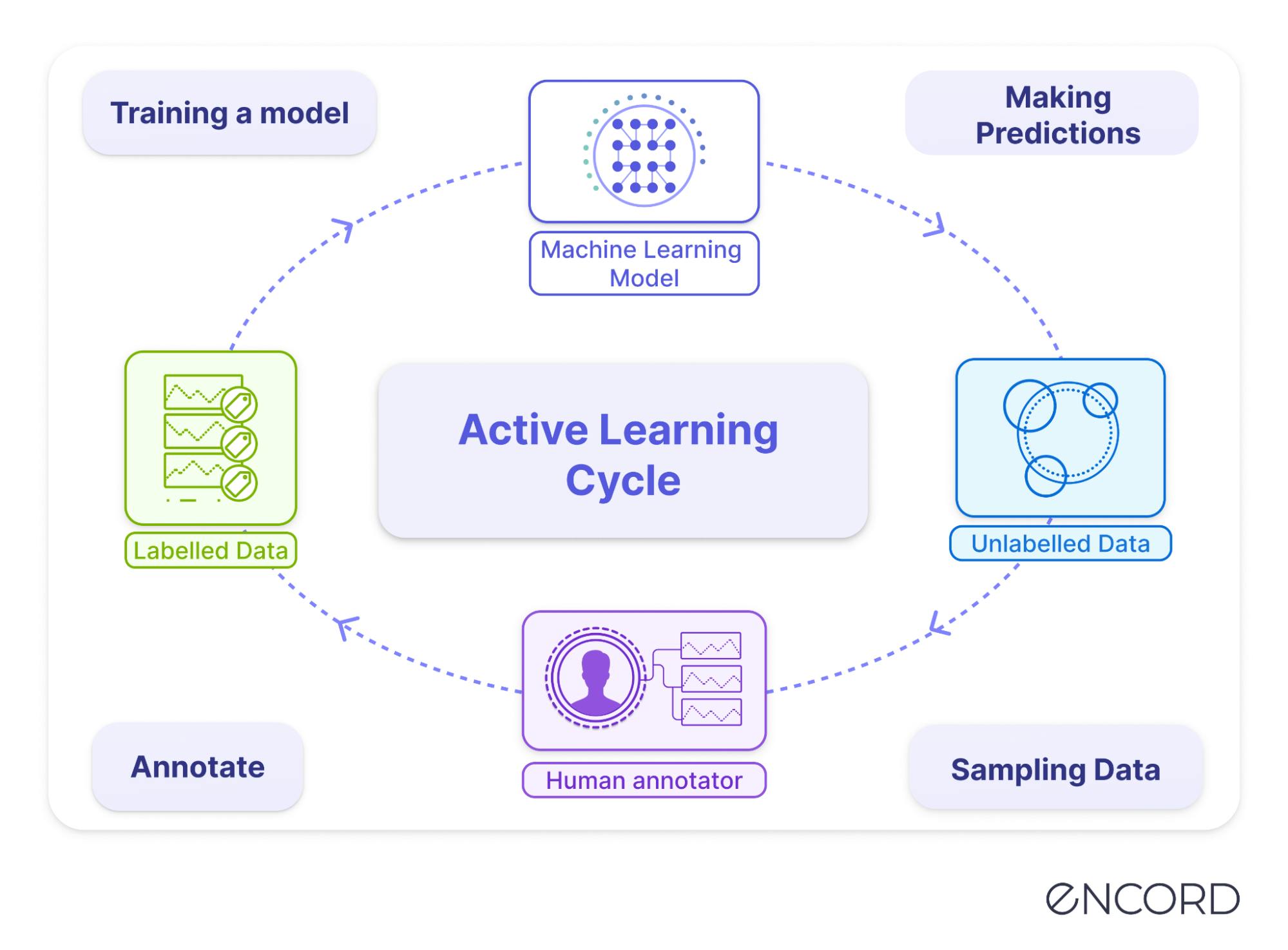
In this comprehensive guide to active learning for machine learning, we will cover
- Active Learning in Machine Learning: What is it?
- Active Learning Machine Learning: How Does it Work?
- Active Learning vs Passive Learning
- Active Learning vs Reinforcement Learning
- Active Learning Query Strategies
- Active Learning in Machine Learning: Examples and Applications
- Tools for Active Learning in Machine Learning

Active Learning in Machine Learning: What is it?
Active learning is an approach that strategically selects data points for labeling to optimize the learning process.
Unlike traditional supervised learning, where a fixed dataset with labeled examples is used for training, active learning algorithms actively query for the most informative data points to label.
The primary objective is to minimize the labeled data required for training while maximizing the model's performance.
In active learning, the algorithm interacts with a human annotator to select data points that are expected to provide the most valuable information for improving the model.
By intelligently choosing which instances to label, active learning algorithms can achieve better learning efficiency and performance than passive learning approaches.
Active learning is particularly beneficial when labeling data is costly, time-consuming, or scarce.
It has applications across various domains, including medical diagnosis, natural language processing, image classification, and more, where obtaining labeled data can be challenging.
Active Learning in Machine Learning: How Does It Work?
Active learning operates through an iterative selection, labeling, and retraining process. Here's how it typically works:
- Initialization: The process begins with a small set of labeled data points, which serve as the starting point for training the model.
- Model Training: A machine learning model is trained using the initial labeled data. This model forms the basis for selecting the most informative, unlabeled data points.
- Query Strategy: A query strategy guides selecting which data points to label next. Various strategies, such as uncertainty sampling, diversity sampling, or query by committee, can be employed based on the nature of the data and the learning task.
- Human Annotation or Human-in-the-Loop: The selected data points are annotated by a human annotator, providing the ground truth labels for these instances.
- Model Update: After labeling, the newly annotated data points are incorporated into the training set, and the model is retrained using this augmented dataset. The updated model now benefits from the additional labeled data.
- Active Learner Loop: Steps 3 through 6 are repeated iteratively. The model continues to select the most informative data points for labeling, incorporating them into the training set and updating itself until a stopping criterion is met or labeling additional data ceases to provide significant improvements.
Through this iterative process, active learning algorithms optimize labeled data, improving learning efficiency and model performance compared to traditional supervised learning methods.
Watch the video below to learn more about how active machine learning works and how it can be integrated into your ML pipelines.
Active Learning Vs. Passive Learning
Passive learning and active learning are two different approaches to machine learning. In passive learning, the model is trained on a pre-defined labeled dataset, and the learning process is complete once the model is trained.
In active learning, the informative data points are selected using query strategies instead of a pre-defined labeled dataset. Then, an annotator labels them before using them to train the model.
By iterating this process of using informative samples, we constantly work on improving the performance of a predictive model.
Here are some key differences between active and passive learning:
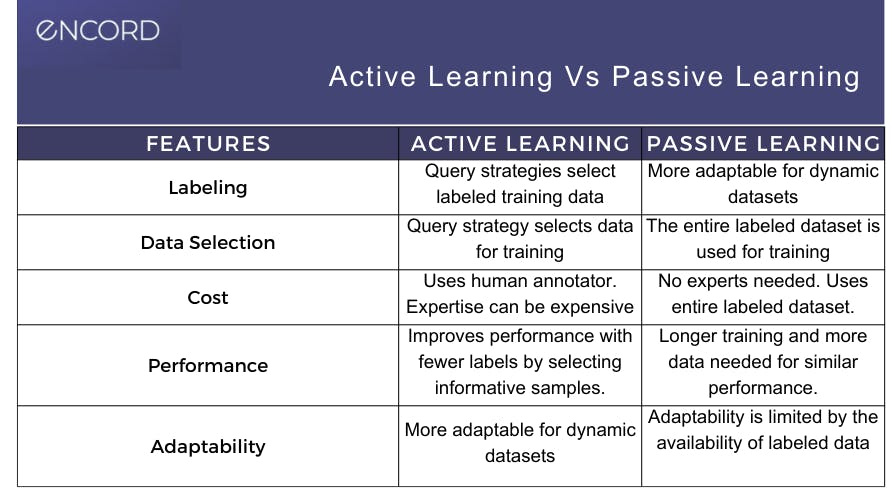
Differences between active and passive learning:
- Labeling: In active learning, a query strategy is used to determine the data to label and annotate, and the labels that need to be applied.
- Data selection: A query strategy is used to select data for training in active learning.
- Cost: Active learning requires human annotators, sometimes experts, depending on the field (e.g., healthcare). Although costs can be controlled with automated, AI-based labeling tools and active learning software.
- Performance: Active learning doesn't need as many labels due to the impact of informative samples. Passive learning needs more data, labels, and time to train a model to achieve the same results.
- Adaptable: Active learning is more adaptable than passive learning, especially with dynamic datasets.
 💡Active learning is a powerful approach for improving the performance of machine learning models by reducing labeling costs and improving accuracy and generalization.
💡Active learning is a powerful approach for improving the performance of machine learning models by reducing labeling costs and improving accuracy and generalization. Active Learning Vs. Reinforcement Learning
Active Learning and Reinforcement Learning are distinct machine learning algorithms but share some conceptual similarities.
As discussed above, active learning is a framework where the learning algorithm can actively choose the data it wants to learn from, aiming to minimize the amount of labeled data required to achieve a desired level of performance.
In contrast, reinforcement learning is a framework where an agent learns by interacting with an environment and receiving feedback in the form of rewards or penalties to learn a policy that maximizes the cumulative reward.
While active learning relies on a fixed training dataset and uses query strategies to select the most informative data points, reinforcement learning does not require a pre-defined dataset; it learns by continuously exploring the environment and updating its internal models based on the feedback received.
Advantages of Active Learning
There are various advantages to using active learning for machine learning tasks, including:
Reduced Labeling Costs
Labeling large datasets is time-consuming and expensive. Active learning helps reduce labeling costs by selecting the most informative samples that require labeling, including techniques such as auto-segmentation.
The most informative samples are those that are expected to reduce the uncertainty of the model the most and thus provide the most significant improvements to the model's performance.
By selecting the most informative samples, active learning can reduce the number of samples that need to be labeled, thereby reducing the labeling costs.
Improved Accuracy
Active learning improves the accuracy of machine learning models by selecting the most informative samples for labeling. Focusing on the most informative samples can help improve the model's performance.
Active learning algorithms are designed to select samples that are expected to reduce the uncertainty of the model the most. Active learning can significantly improve the model's accuracy by focusing on these samples.
Faster Convergence
Active learning helps machine learning models converge faster by selecting the most informative samples. The model can learn quickly and converge faster by focusing on the most relevant samples.
Traditional machine learning models rely on random sampling or sampling based on specific criteria to select samples for training. However, these methods do not necessarily prioritize the most informative samples.
On the other hand, active learning algorithms are designed to identify the most informative samples and prioritize their inclusion in the training set, resulting in faster convergence.
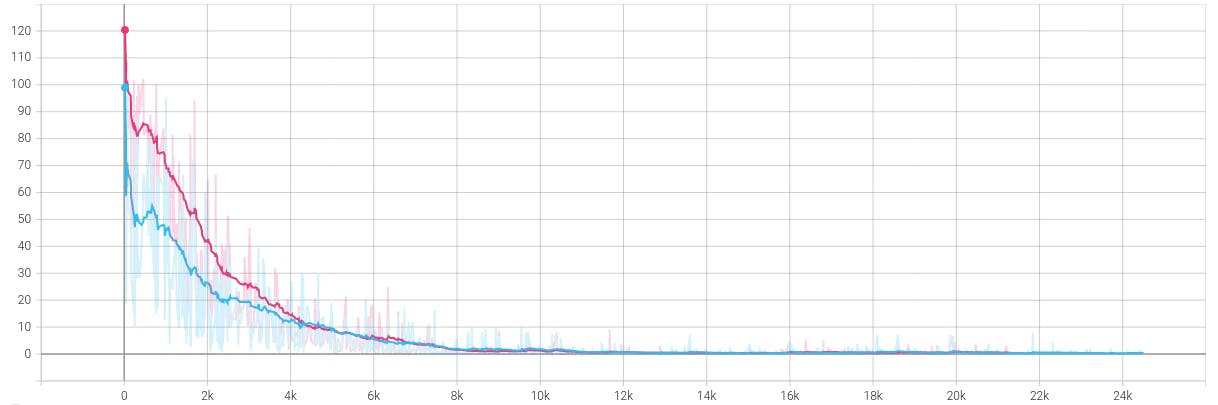
Active learning algorithm (blue) converging faster than the general machine learning algorithm (red)
Improved Generalization
Active learning helps ML models generalize new data better by selecting the most diverse samples for labeling. Active learning Python formulas or deep learning networks improve a model's reinforcement learning capabilities.
The model can learn to recognize patterns and better generalize new data by focusing on diverse samples, including outliers, even when there’s a large amount of data.
Diverse samples cover a broad range of the feature space, ensuring that the model learns to recognize patterns relevant to a wide range of scenarios.
Active learning can help the model generalize to new data by including diverse samples in the training set.
Robustness to Noise
Another way active learning works is to improve the robustness of machine learning models to noise in the data. By selecting the most informative samples, active learning algorithms are trained on the samples that best represent the entire dataset.
Hence, the models trained on these samples will perform well on the best data points and the outliers.
Having discovered the benefits of active learning, we will investigate the query techniques involved and apply them to our existing model.
Active Learning Query Strategies
As we discussed above, active learning improves the efficiency of the training process by selecting the most valuable data points from an unlabeled dataset.
This step of selecting the data points, or query strategy, can be categorized into three methods.
Stream-based Selective Sampling
Stream-based selective sampling is a query strategy used in active learning when the data is generated continuously, such as in online or real-time data analysis.
In this, a model is trained incrementally on a stream of data, and at each step, the model selects the most informative samples for labeling to improve its performance. The model selects the most informative sample using a sampling strategy.
The sampling strategy measures the informativeness of the samples and determines which samples the model should request labels for to improve its performance.
For example, uncertainty sampling selects the samples the model is most uncertain about, while diversity sampling selects the samples most dissimilar to those already seen.
Stream-based sampling is particularly useful in applications where data is continuously generated, like processing real-time video data.
Here, waiting for a batch of data to accumulate may not be feasible before selecting samples for labeling. Instead, the model must continuously adapt to new data and select the most informative samples as they arrive.
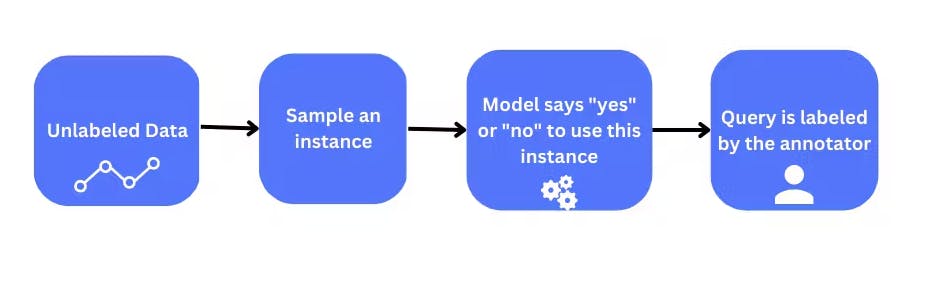
This approach has several advantages and disadvantages, which should be considered before selecting this query strategy.
Advantages of Stream-Based Selective Sampling
- Reduced labeling cost: Stream-based selective sampling reduces the cost of labeling by allowing the algorithm to selectively label only the most informative samples in the data stream. This can be especially useful when the cost of labeling is high and labeling all incoming data is not feasible.
- Adaptability to changing data distribution: This strategy is highly adaptive to changes in the data distribution. As new data constantly arrives in the stream, the model can quickly adapt to changes and adjust its predictions accordingly.
- Improved scalability: Stream-based selective sampling allows for improved scalability since it can handle large amounts of incoming data without storing all the data.
Disadvantages of stream-based selective sampling
- Potential for bias: Stream-based selective sampling can introduce bias into the model if it only labels certain data types. This can lead to a model that is only optimized for certain data types and may not generalize well to new data.
- Difficulty in sample selection: This sampling strategy requires careful selection of which samples to label, as the algorithm only labels a small subset of the incoming data. Selection of the wrong samples to label can result in a less accurate model than a model trained with a randomly selected labeled dataset.
- Dependency on the streaming platform: Stream-based selective sampling depends on the streaming platform and its capabilities. This can limit the approach's applicability to certain data streams or platforms.
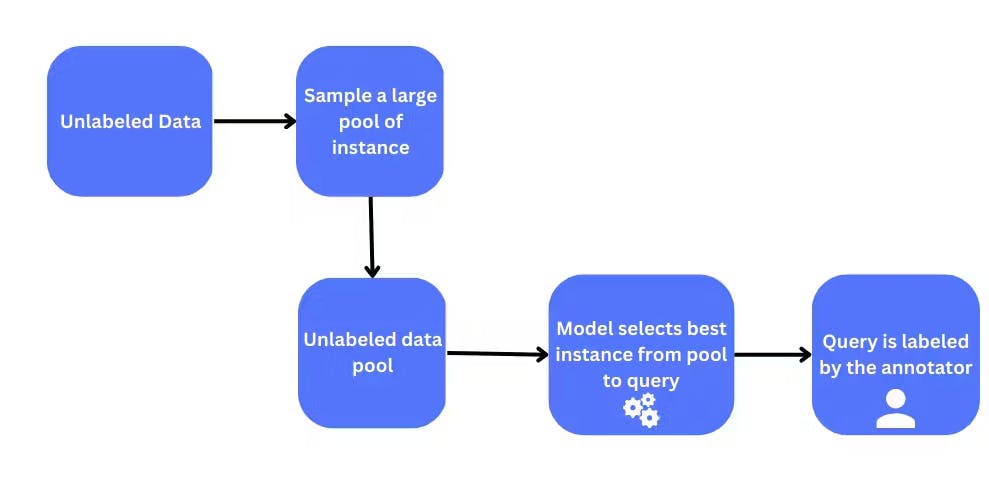
Pool-based Sampling
Pool-based sampling is a popular method used in active learning to select the most informative examples for labeling. This approach creates a pool of unlabeled data, and the model selects the most informative examples from this pool to be labeled by an expert or a human annotator.
The newly labeled examples are then used to retrain the model, which is repeated until the desired level of model performance is achieved. Pool-based sampling can be further categorized into uncertainty sampling, query-by-committee, and density-weighted sampling. We will discuss these in the next section. Let’s look at the advantages and disadvantages of pool-based sampling.
Advantages of pool-based sampling
- Reduced labeling cost: Pool-based sampling reduces the overall labeling cost compared to traditional supervised learning methods since it only requires labeling the most informative sample. This can lead to significant cost savings, especially when dealing with large datasets.
- Efficient use of expert time: Since the expert is only required to label the most informative samples, this strategy allows for efficient use of expert time, saving time and resources.
- Improves model performance: The selected samples are more likely to be informative and representative of the data, so pool-based sampling can improve the model's accuracy.
Disadvantages of pool-based sampling
- Selection of the pool of unlabeled data: The quality of the selected data affects the performance of the model, so careful selection of the pool of unlabeled data is essential. This can be challenging, especially for large and complex datasets.
- Quality of the selection method: The quality of the selection method used to choose the most informative sample can affect the model’s accuracy. The model's accuracy may suffer if the selection method is not appropriate for the data or is poorly designed.
- Not suitable for all data types: Pool-based sampling may not be suitable for all data types, such as unstructured or noisy data. In these cases, other active learning approaches may be more appropriate.
Query Synthesis Methods
Query synthesis methods are a group of active learning strategies that generate new samples for labeling by synthesizing them from the existing labeled data.
The methods are useful when your labeled dataset is small, and the cost of obtaining new labeled samples is high.
One approach to query synthesis is by perturbing the existing labeled data, for example, by adding noise or flipping labels.
Another approach is to generate new samples by interpolating or extrapolating from existing samples in the labeled dataset, and the model is retrained. Generative Adversarial Networks (GANs) and Visual Foundation Models (VFMs) are two popular methods for generating synthetic data samples.
These data samples are adapted to the current model. The annotator labels these synthetic samples added to the training dataset. The model learns from these synthetic samples generated by the GANs.
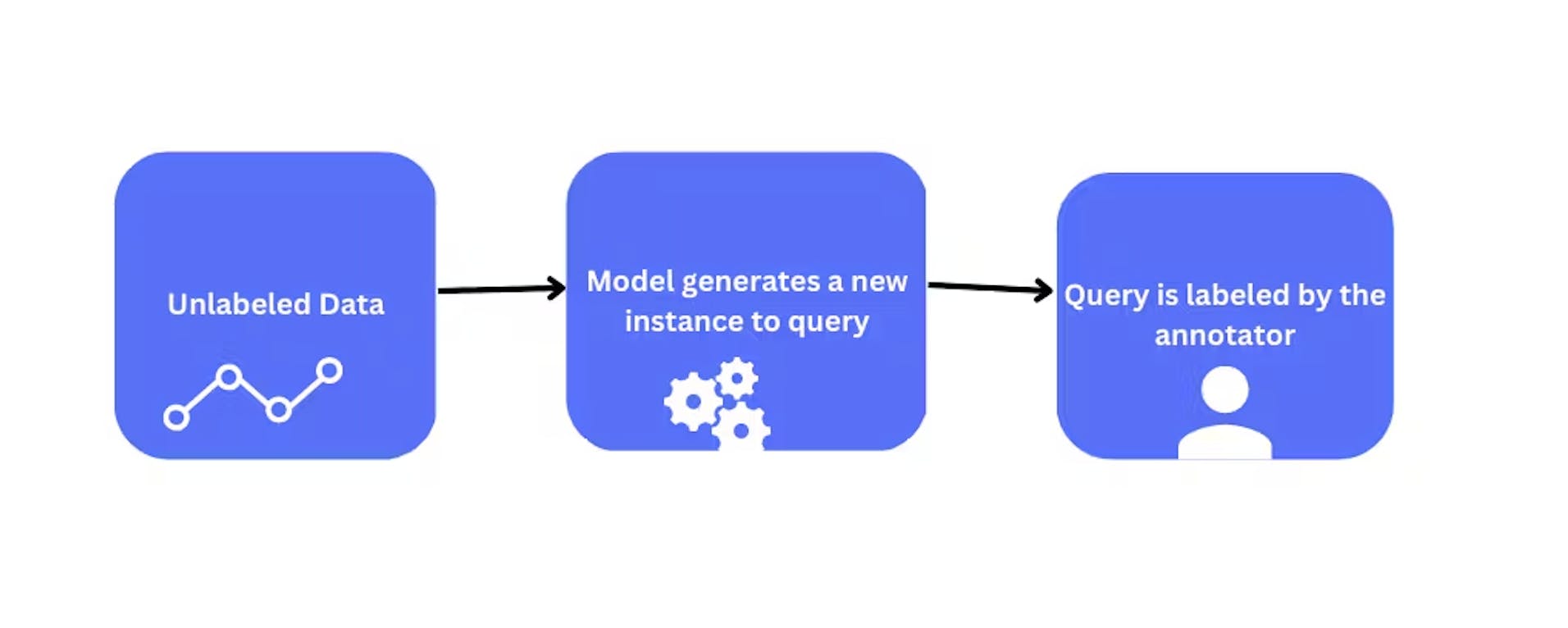
Query synthesis method with unlabeled data
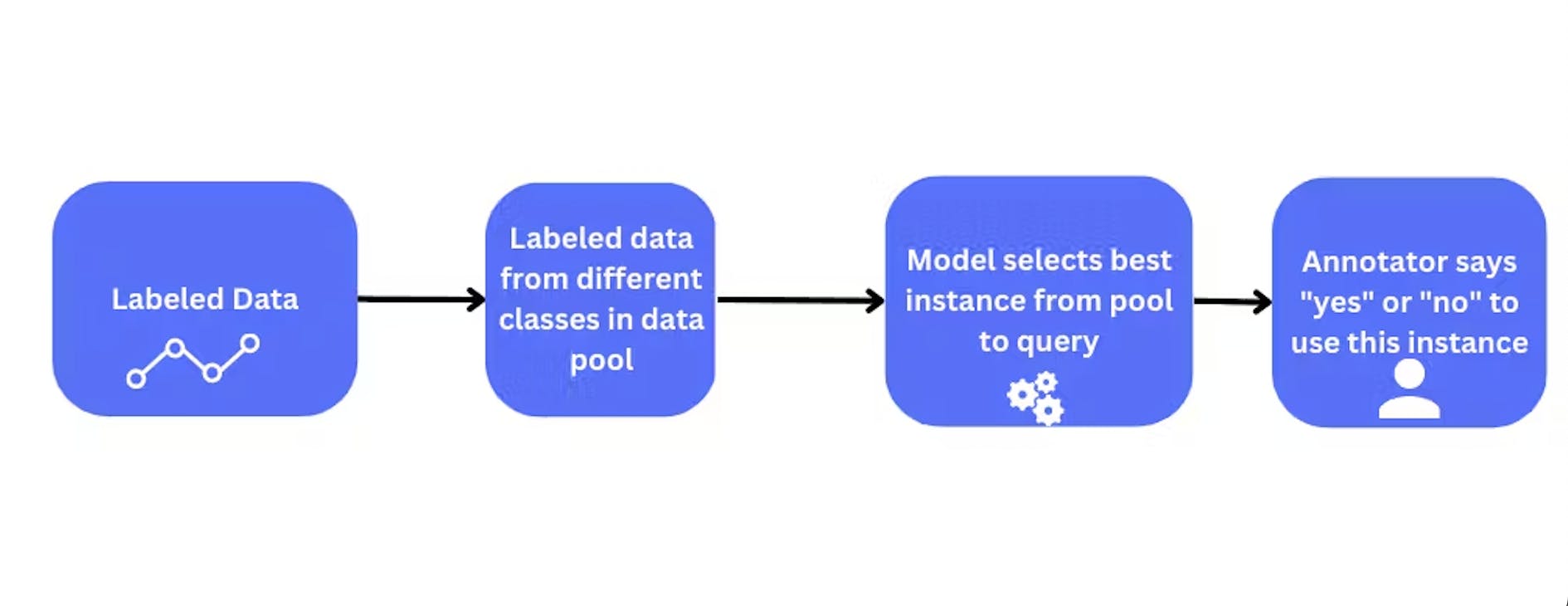
Query synthesis method with labeled data
Advantages of query synthesis
- Increased data diversity: Query synthesis methods can help increase the diversity of the training data, which can improve the model's performance by reducing overfitting and improving generalization.
- Reduced labeling cost: Like the other query strategies discussed above, query synthesis methods also reduce the need for manual labeling and hence lower the overall labeling cost. These methods achieve this by generating new unlabeled samples.
- Improved model performance: The synthetic samples generated using query synthesis methods can be more representative of the data, improving the model’s performance by providing it with more informative and diverse training data.
Disadvantages of query synthesis
- Computational cost: Query synthesis methods can be computationally expensive, especially for complex data types like images or videos. Generating synthetic examples can require significant computational resources, limiting their applicability in practice.
- Limited quality of the synthetic data: The quality of the synthetic data generated using query synthesis methods depends on the selection of the method and the parameters used. Poor selection of the method or parameters can lead to the generation of synthetic examples that are not representative of the data, which can negatively impact the model's performance.
- Overfitting: Generating too many synthetic examples can lead to overfitting, where the model learns to classify the synthetic examples instead of the actual data. This can reduce the model's performance on new, unseen data.
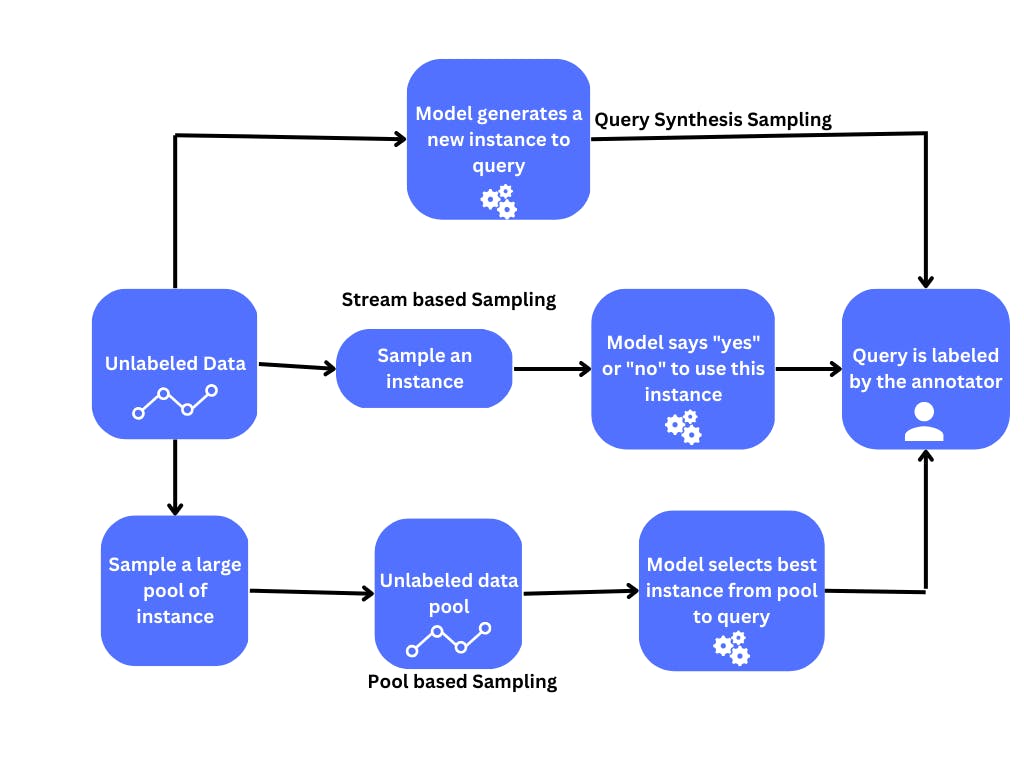
Flow chart showing the three sampling methods
Active learning query strategies typically evaluate the informativeness of the unlabeled samples, which can be generated synthetically or sampled from a given distribution.
These strategies can generally be categorized into different query strategy frameworks, each with a unique process for selecting the most informative sample.
An overview of these query strategy frameworks can help you better understand the active learning process.
By identifying the framework that best fits a particular problem, machine learning researchers and practitioners can make informed decisions about which query strategy to use to maximize the effectiveness of the active learning approach.

Active Learning Informative Measures
Now, let's take a closer look at a series of informative measures you can take, such as uncertainty sampling, query-by-committee, and others.
Uncertainty Sampling
Uncertainty sampling is a query strategy that selects samples expected to reduce the uncertainty of the model the most. The uncertainty of the model is typically measured using a measure of uncertainty, such as entropy or margin-based uncertainty.
Samples with high uncertainty are selected for labeling, as they are expected to provide the most significant improvements to the model's performance.
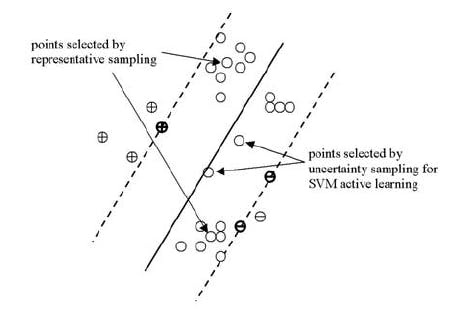
An illustration of representative sampling vs. uncertainty sampling for active learning
Query-by-Committee Sampling
Query-by-commitment is a query strategy that involves training multiple models on different subsets of the labeled dataset and selecting samples based on the disagreement among the models.
This strategy is useful when the model errors on specific samples or classes. By selecting samples on which the committee of models disagrees, the model can learn to recognize sample patterns and improve its performance in those classes.
Diversity-Weighted Methods
Diversity-weighted methods select examples for labeling based on their diversity in the current training set. It involves ranking the pool of unlabeled examples based on a diversity measure, such as the dissimilarity between examples or the uncertainty of the model's predictions.
The most diverse examples are labeled to improve the model's generalization performance by providing informative and representative training data.
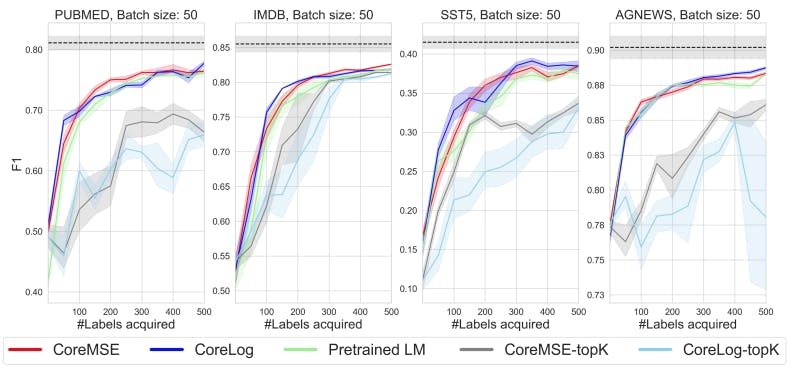
Learning curves of the model training with diversity
The dashed line represents the performance of the backbone classifier trained on the entire dataset.
Expected Model-change-based Sampling
Expected model-change-based sampling is an active learning method that selects examples for labeling based on the expected change in the model's predictions.
This approach selects examples likely to cause the most significant changes in the model's predictions when labeled to improve the model's performance on new, unseen data.
In expected model-change-based sampling, the unlabeled examples are first ranked based on estimating the expected change in the model's predictions when each example is labeled.
This estimation can be based on measures such as expected model output variance, gradient magnitude, or the Euclidean distance between the current and expected model parameters after labeling.
Using this approach, the examples that are expected to cause the most significant changes in the model's predictions are then selected for labeling, with the idea that these examples will provide the most informative training data for the model.
These samples are then added to the training data to update the model.
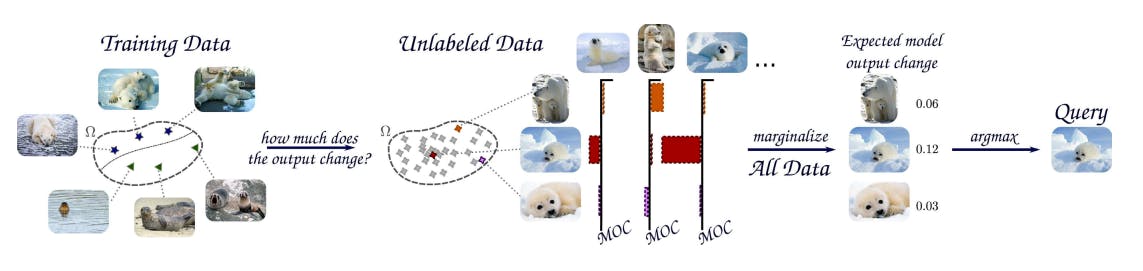
Framework of Active learning with expected model change sampling
Expected Error Reduction
Expected error reduction is an active learning method that selects examples for labeling based on the expected reduction in the model's prediction error.
This approach aims to select examples likely to reduce the model's prediction error the most when labeled to improve the model's performance on new, unseen data.
In expected error reduction, the unlabeled examples are first ranked based on estimating the expected reduction in the model's prediction error when each example is labeled.
This estimation can be based on various measures, such as the distance to the decision boundary, the margin between the predicted labels, or the expected entropy reduction.
The examples expected to reduce the model's prediction error are then selected for labeling, with the idea that these examples will provide the most informative training data for the model.
💡To learn more about these strategies, check out A Practical Guide to Active Learning for Computer Vision Having comprehended the concept of active learning and its implementation on different data types, let us explore its uses. This will aid us in recognizing the importance of including active machine learning in the ML pipeline.
Active Learning in Machine Learning: Examples and Applications
Active learning finds applications across various domains, allowing for more efficient learning processes by strategically selecting which data points to label. Here are some examples of how active learning is applied in specific fields:
Computer Vision
Active learning has numerous applications in computer vision, where it can be used to reduce the amount of labeled data needed to train models for various tasks.
💡 Active learning can play a valuable role in establishing successful data labeling operations, and automated data annotation. Image Classification
In image classification, active learning can be used to select the most informative images for labeling, focusing on challenging or uncertain instances that are likely to improve the model's performance.
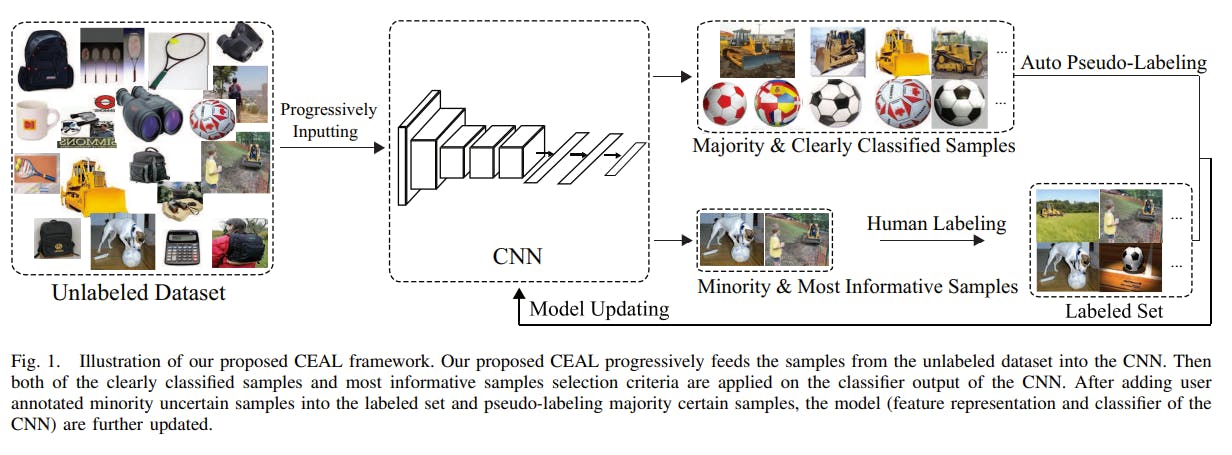
Image classification flowchart
Semantic Segmentation
Semantic segmentation involves assigning a class label to each pixel in an image, delineating different objects or regions. Active learning can help select image regions where the model is uncertain or where labeling would provide the most significant benefit for segmentation accuracy.
For example, we can select images using uncertainty sampling instead of the whole labeled dataset, as proposed in ViewAL.
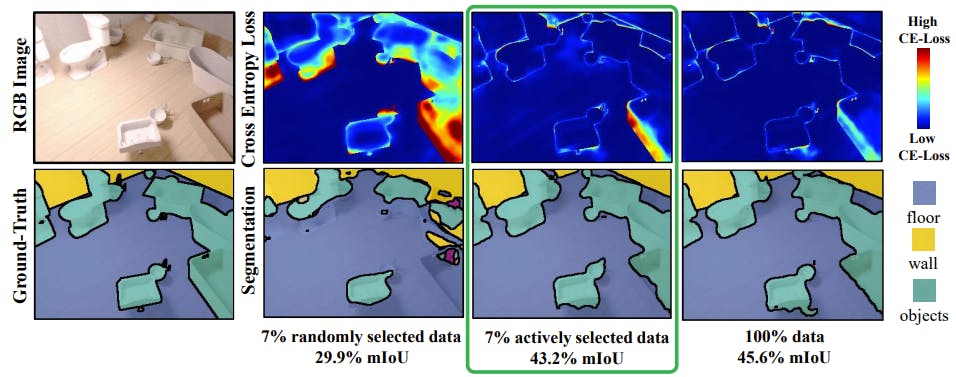
ViewAL achieves 95% of the performance with only 7% of the data of SceneNet-RGBD.
The authors introduce a measure of uncertainty based on inconsistencies in model predictions across different viewpoints, which encourages the model to perform well regardless of the viewpoint of the objects being observed.
They also propose a method for computing uncertainty on a superpixel level, which lowers annotation costs by exploiting localized signals in the segmentation task.
By combining these approaches, the authors can efficiently select highly informative samples for improving the network's performance.
Object Detection
Object detection identifies and localizes multiple objects within an image. Active learning can help prioritize annotating regions with ambiguous or rare objects, leading to better object detection models.
For example, the Multiple Instance Active Object Detection model or MI-AOD uses active learning for object detection. This algorithm selects the most informative images for detector training by observing instance-level uncertainty.
It defines an instance uncertainty learning module, which leverages the discrepancy of two adversarial instance classifiers trained on the labeled set to predict the instance uncertainty of the unlabeled set.
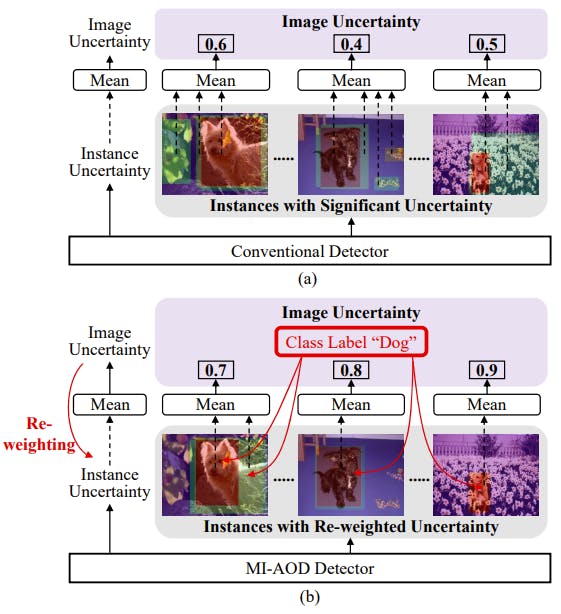
Comparison of conventional methods - active object detection and MI-AOD methods
Natural Language Processing (NLP)
Active learning in NLP involves selecting informative text samples for annotation. Examples include:
- Named Entity Recognition (NER): Identifying entities (e.g., names, dates, locations) in text.
- Sentiment Analysis: Determining sentiment (positive, negative, neutral) from user reviews or social media posts.
- Question Answering: Improving question-answering models by selecting challenging queries.
Active learning workflow for NLP
Audio Processing
Active learning can benefit audio processing tasks such as:
- Speech Recognition: Selecting diverse speech samples to improve transcription accuracy.
- Speaker Identification: Prioritizing challenging speaker profiles for better model generalization.
- Emotion Recognition: Focusing on ambiguous emotional cues for robust emotion classification.
Tools to Use for Active Learning
Here are some of the most popular tools for active learning:
Encord Active
Encord Active provides an intuitive interface for active learning with advanced error analysis features to evaluate model performance.
By running robustness checks, you can identify potential failure modes, ensuring your model remains adaptable and accurate even as data landscapes evolve.
It offers insights into model behavior, making finding and fixing errors easier to improving the debugging process.
Key features
- Data Exploration and Visualization: Explore data through interactive embeddings, precision/recall curves, and other advanced quality metrics.
- Model Evaluation and Failure Mode Detection: Identify labeling mistakes and prioritize high-value data for relabeling.
- Data Types and Labels Supported: Different label types such as bounding boxes, polygon, polyline, bitmask, and key-point labels are supported.
- Performance: Provides off-the-shelf and custom quality metrics to improve performance in your custom computer vision project.
- Integration with Encord Annotate: Seamlessly works with Encord Annotate for data curation, labels, and model evaluation.
Best for
- Teams looking for an integrated and secure commercial-grade enterprise platform encompassing both annotation tooling and workflow management alongside an expansive active learning feature set
- Data science, machine learning, and data operations teams who are seeking to use pre-defined or add custom metrics for parametrizing their data, labels, and models.

Lightly
Lightly is a platform for active learning that integrates seamlessly with popular deep learning libraries and provides tools for visualizing data, selecting samples, and managing annotations. Lightly’s user-friendly interface makes it a great choice for researchers and practitioners alike.
Key features
- Web interface for data curation and visualization
- Supports image, video, and point cloud data for computer vision tasks
- Supports active learning strategies such as uncertainty sampling, core-set, and representation-based approaches
- Integrations with popular annotation tools and platforms
- Python SDK for seamless integration into existing workflows
Best for
- Data scientists and machine learning engineers who want an intuitive, end-to-end solution for active learning, data curation, and annotation tasks
Cleanlab
Cleanlab is a Python library that focuses on label noise detection and correction. While not exclusively an active learning tool, it can be used with active learning pipelines. Cleanlab helps identify mislabeled samples, allowing you to prioritize cleaning noisy labels during the annotation process.
Key features
- Open-source through Cleanlab Opens-source and deployed version, Cleanlab Studio
- Supports images, text, and tabular data for classification tasks
- Scoring and tracking features to monitor data quality over time continuously
- Visual playground with a sandbox implementation
Best for
- Individual researchers and smaller teams looking to solve simple classification tasks and find outliers across different data modalities.
Voxel51
Voxel51 offers a comprehensive platform for active learning across various domains. From computer vision to natural language processing, Voxel51 provides tools for sample selection, model training, and performance evaluation. Its flexibility and scalability make it suitable for both small-scale experiments and large-scale projects.
Key features
- Explore, search, and slice datasets to find samples and labels that meet specific criteria.
- Leverage tight integrations with public datasets or create custom datasets to train models on relevant, high-quality data.
- Optimize model performance by using FiftyOne to identify, visualize, and correct failure modes.
- Automate the process of finding and correcting label errors to curate higher quality datasets efficiently.
Best for
- Data scientists and machine learning engineers working on computer vision projects who seek an efficient and powerful solution for data visualization, curation, and model improvement, with an emphasis on data quality and building streamlined workflows allowing for rapid iteration.
Active Learning Machine Learning: Key Takeaways
- Active learning can drastically reduce the amount of labeled data needed to train high-performing models.
- By selectively labeling the most informative unlabeled examples, active learning makes efficient use of annotation resources.
- The iterative active learning process of selecting, labeling, updating, and repeating builds robust models adaptable to changing data.
- The use cases of active learning models can be broadly found across applications like image classification, NLP, and recommendation systems.
- Incorporating active learning into the ML workflow yields substantial benefits, making it an essential technique for data scientists.
Frequently asked questions
Active learning is a supervised approach to machine learning that uses training data optimization cycles to continiously improve the performance of an ML model. Active learning involves a constant, iterative, quality and metric-focused feedback loop to keep improving machine learning performance and accuracy.
Active learning can be implemented in numerous ways, and there are several key concepts that data science and ML engineering teams need to factor into the process. The components of active learning include a query strategy for data samples and human-in-the-loop (HITL) annotation and QA. There are several different query strategies, such as stream-based selective sampling, pool-based, and query synthesis, and a number of informative measures including uncertainty sampling and query-by committee.
Active learning has numerous use cases and applications in machine learning, including image classification, computer vision, semantic segmentation, object detection, natural language processing (NLP), and even audio processing.
There are a number of ways you can implement active learning in computer vision, and to do this more effectively, it helps to have the right tools. One of the most versatile and robust is Encord Active, with open-source and deployed versions, specially designed for computer vision with support for a broad set of visual modalities
Deep learning uses neural networks to learn from data, while active learning selects the most informative data to label and train the model.
Query-by-Committee and Uncertainty Sampling are examples of active learning models that strategically select data to label and improve model performance.
Active learning algorithms actively select data to label, while passive learning algorithms train on pre-labeled datasets.
Encord Active is a feature designed to analyze model performance by comparing model predictions with ground truth data. It helps identify areas where the model is failing, allowing users to curate better training data, ultimately improving the diversity and performance of the training dataset.
Encord Active is a feature that enables users to bring in model predictions to analyze performance. It helps identify areas where models are excelling or struggling, allowing users to find edge cases and integrate feedback into the annotation workflow for continuous improvement.
Active learning in Encord's annotation platform helps optimize the training of machine learning models by intelligently selecting the most informative data points for annotation. This approach enhances model performance while minimizing the amount of labeled data required.
Encord facilitates the active learning loop by integrating data labeling, management, and model evaluation. By consolidating various tasks into one platform, Encord helps teams efficiently manage their data and improve their model performance through targeted labeling.
Encord's active learning feature enhances the data annotation workflow by automating the selection of the most informative data points for labeling. This results in a more efficient use of resources and helps improve the accuracy of machine learning models over time.
Encord supports active learning by allowing users to iterate on model outputs with domain experts. The platform enables users to review predictions, make adjustments, and incorporate feedback, ensuring that models continuously improve and adapt to new data.
Yes, Encord includes features for evaluating models and identifying failure modes. The platform supports the creation of active learning loops, enabling continuous improvement of models based on annotation results and performance metrics.
Encord is capable of supporting hybrid active learning models, which include both human-in-the-loop and automated processes. This flexibility allows teams to adjust their annotation strategies based on project needs and data requirements.
The Active feature in Encord is designed to evaluate model performance by identifying areas where models may be failing from a data perspective. This allows teams to make informed adjustments and improve overall model accuracy.
Encord provides features that support active learning by allowing users to automate sample selection and feedback collection. This helps in iterating models more efficiently and enhances the overall training process.