Visual Foundation Models (VFMs) Explained

ML Lead at Encord
The computer vision (CV) market is soaring, with an expected annual growth rate of 19.5%, according to Yahoo Finance. By 2023, it is predicted to reach a value of $100.4Bn, compared to $16.9Bn in 2022. This growth is largely attributable to the development of Visual Foundation Models (VFMs), which are engineered to understand and process the complexities of visual data.
VFMs excel in various CV tasks, including image generation, object detection, semantic segmentation, text-to-image generation, medical imaging, and more. Their accuracy, speed, and efficiency make them highly useful at enterprise scale.
This guide provides an overview of VFMs and discusses several prominent models available. We’ll list their benefits and applications and highlight prominent fine-tuning techniques for VFMs.

Understanding Visual Foundation Models
Foundation models are general-purpose large-scale artificial intelligence (AI) models that organizations use to build downstream applications, especially in generative AI. For instance, in the natural language processing (NLP) domain, large language models (LLMs) such as BERT, GPT-3, GPT-4, and MPT-30B are foundation models that enable businesses to build chat or language systems that are tailored to specific tasks and can understand human language to enhance customer engagement.
Visual foundation models are foundation models that perform image generation tasks. VFMs usually incorporate components of large language models to enable image generation using text-based input prompts. They require appropriate prompt engineering to achieve high-quality image generation results.
Some notable examples of proprietary and open-source VFMs include Stable Diffusion, Florence, Pix-2-Pix, DALL-E, etc. These models are trained on enormous datasets, allowing them to understand the intricate features, patterns, and representations in visual data. They use various architectures and techniques that focus on processing visual information, making them adaptable to many use cases.
Evolution from CNNs to Transformers
Traditionally, computer vision models have used convolutional neural networks (CNNs) to extract relevant features. CNNs focus on a portion of an image at a time, allowing them to effectively distinguish between objects, edges, and textures at inference time.
In 2017, a research paper titled "Attention is All You Need” transformed the NLP landscape by introducing a new machine learning architecture for building effective language models. This architecture takes a text sequence and generates a text sequence as input-output formats. Its key component is the attention mechanism, which enables the model to focus on the essential portions of a text sequence. Overall, transformers understand longer texts better and provide enhanced speed and accuracy. The transformer architecture has given rise to the foundational LLMs that we know today.
Although the attention mechanism was initially intended for language format, researchers soon saw its potential in computer vision applications. In 2020, a research paper titled “An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale” showed how the transformeralgorithm can transform images into vectorized embeddings and use self-attention to let the model understand the relationship between image segments. The resulting model is called a Vision Transformer (ViT).
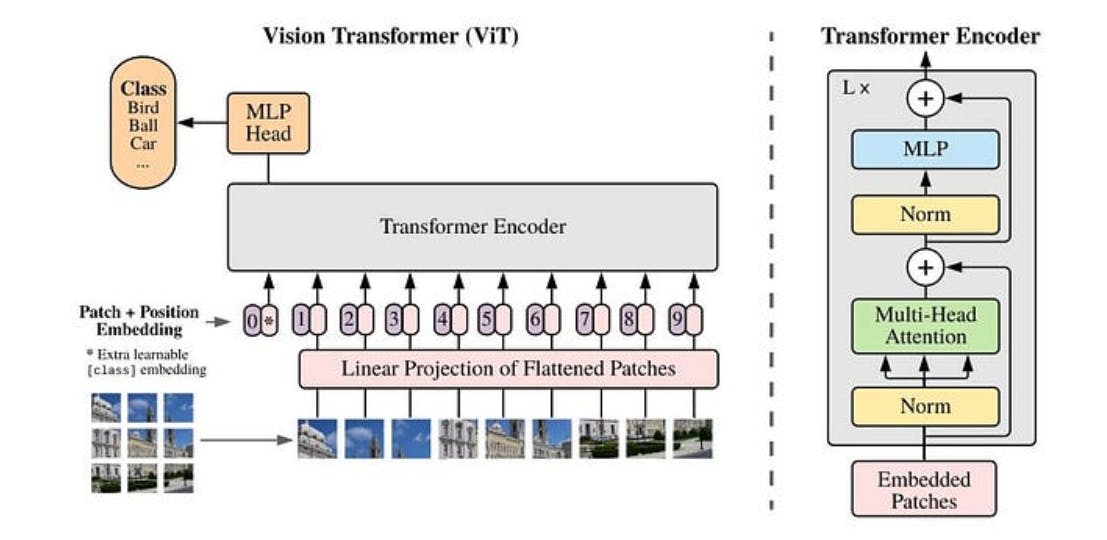
Vision Transformer Architecture
Today, ViTs are used to power many VFMs. Additionally, the growing prevalence of GPUs has made it easier to process visual data and execute large-scale generative AI workloads. Consequently, the development and deployment of different VFMs have become more feasible.
Self-Supervision & Adaptability
Many visual foundation models use self-supervision techniques to learn from unlabeled data. Unlike supervised learning, where all data points must have labels, self-supervision techniques enable model training via unlabeled data points. This allows enterprises to quickly adapt them for specific use cases without incurring high data annotation costs.
Popular Visual Foundation Models
Foundation models are making remarkable progress, leading to the emergence of a variety of VFMs designed to excel in different vision tasks. Let’s explore some of the most prominent VFMs.
DINO (self-DIstillation with NO labels)
DINO is a self-supervised model by Meta AI based on the ViT and teacher-student architecture. It enables users to quickly segment any object from an image, allowing for the extraction of valuable features from an image without the time-consuming fine-tuning and data augmentation process.
SAM (Segment Anything Model)
SAM revolutionizes image and video segmentation by requiring minimal annotations compared to traditional methods. CV practitioners can give a series of prompts to extract different image features. The prompts are in the form of clickables, meaning practitioners can select a specific portion of any image, and SAM will segment it out for quicker annotation.
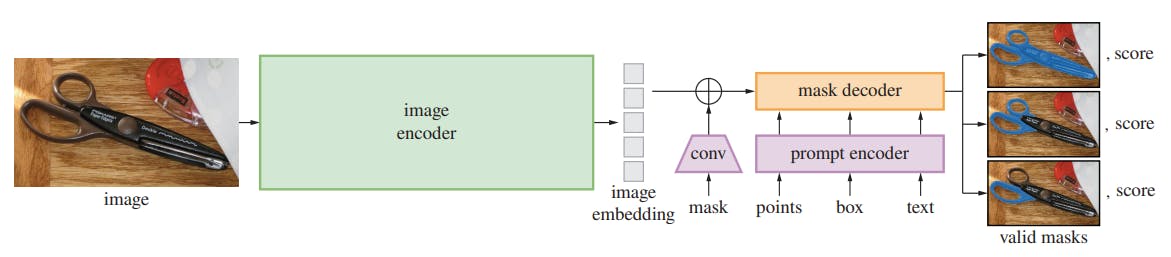
SegGPT
SegGPT is a generalist segmentation model built on top of the Painter framework, which allows the model to adapt to various tasks using minimum examples. The model is useful for all segmentation tasks, such as instance, object, semantic, and panoptic segmentation. During training, the model performs in-context coloring, which uses a random coloring scheme (instead of specific colors) to identify segments by learning their contextual information, resulting in improved model generalizability.
Microsoft's Visual ChatGPT
Microsoft’s Visual ChatGPT expands the capabilities of text-based ChatGPT to include images, enabling it to perform various tasks, including visual question answering (VQA), image editing, and image generation. The system uses a prompt manager that can input both linguistic and visual user queries to the ChatGPT model. Visual ChatGPT can access other VFMs such as BLIP, Stable Diffusion, Pix2Pix, and ControlNet to execute vision tasks. The prompt manager then converts all input visual signals into a language format that ChatGPT can understand. As a result, the ChatGPT model becomes capable of generating both text and image-based responses.
The following diagram illustrates Visual ChatGPT architecture:
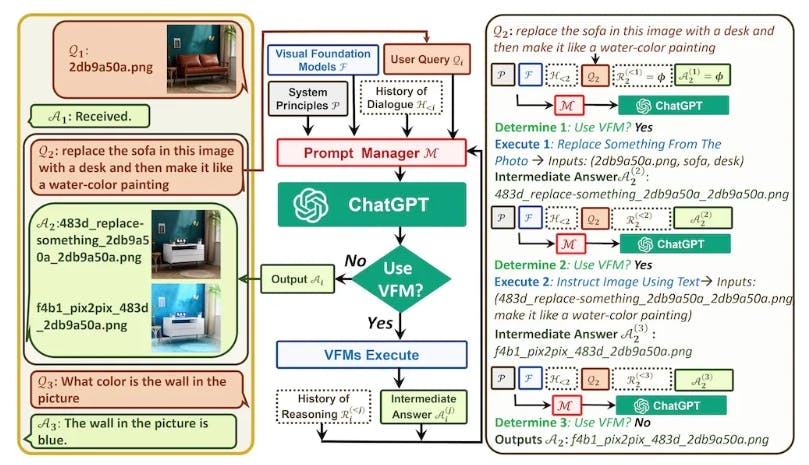
Applications of Visual Foundation Models
VFMs have a range of applications across various industries. Let’s explore some of them below:
- Healthcare Industry: VFMs can improve medical image analysis, assisting in disease detection and diagnosis by detecting issues in X-rays, MRI and CTI scans, and other medical images.
- Cybersecurity Systems: VFMs can provide sophisticated observation, spot irregularities, and identify potential threats in the cybersecurity domain. Early threat detection enables organizations to safeguard their digital assets proactively.
- Automotive Industry: VFMs can help self-driving automobiles improve scene comprehension and pedestrian recognition, ensuring public safety.
- Retail Industry: VFMs can automate stock tracking and shelf replenishment through image-based analysis and improve inventory management.
- Manufacturing Industry:VFMs can improve visual quality control by detecting flaws in real-time, reducing time to repair and cutting down on maintenance costs.
Benefit of Visual Foundation Models
VFMs offer significant economic benefits across industries. These models are refined and pre-trained using enormous datasets, which speed up development, use fewer resources, and improve the quality of AI-powered applications.
By eliminating the need for time-consuming manual feature engineering and annotation, VFMs can shorten product development cycles, allowing organizations to reduce the time to market for their AI applications.
VFMs’ capacity to detect subtle details can improve user experience by enabling precise picture recognition, automatically identifying objects, and making recommendations.
The transfer learning capabilities of VFMs are particularly beneficial for enterprise AI systems. Withtransfer learning, businesses can fine-tune VFMs to suit specific tasks without training the entire model from scratch.
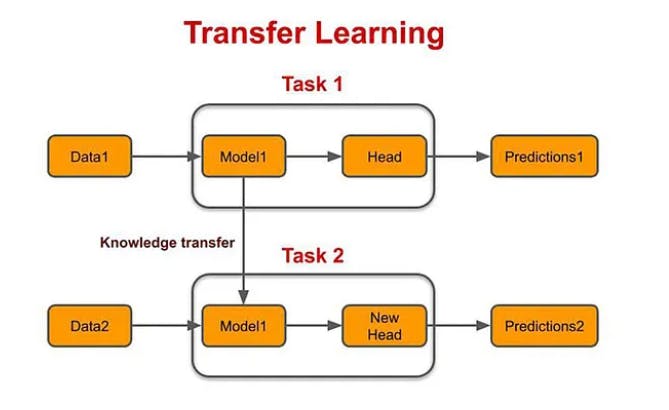
Challenges & Considerations of Visual Foundation Models
VFMs have a robust visual understanding, but they are still relatively new models, and practitioners may experience several challenges when trying to make the models work as intended. Let’s briefly address these challenges below.
Addressing Ethical, Fairness, & Bias-related Concerns in Visual AI
While VFMs are smart models, they can sometimes exhibit bias due to the data they learn from. This becomes a concern if the data contains underrepresented classes. For example, a VFM in a security system may generate alarms only when it sees people of a certain demographic. Such a result may occur due to the training data containing a skewed representation of people. To prevent the model from giving biased results, companies must ensure that their datasets are collected from diverse sources and represent all classes fairly.
Safeguarding Privacy, Compliance, & Data Security
Visual foundation models pose challenges regarding data security, as large training datasets may inadvertently expose confidential information. Protecting data through robust anonymization, encryption, and compliance with regulations like GDPR is crucial.
To prevent legal issues, it is essential to adhere to data regulations, intellectual property rights, and AI regulations. In sectors like healthcare and finance, interpretable AI is vital for understanding complex VFM predictions.
Managing Costs
While VFMs offer high speed and performance, they have a significant training cost based on the size of the data and model. OpenAI’s GPT-3 model, for example, reportedly cost $4.6MM to train. According to another OpenAI report, the cost of training a large AI model is projected to rise from $100MM to $500MM by 2030. These figures indicate the prohibitive costs organizations must bear to create large image models. They must invest heavily in computational resources such as GPUs, servers, and data pipelines, making development a highly challenging process. In addition, there is an inference cost for deployed models that must be taken into account.
Fine-tuning Visual Foundation Models
VFMs are pre-trained models with pre-defined weights, meaning they understand complex visual patterns and features. In other words, businesses do not need to undergo the training process from scratch. Instead, they can use a small amount of additional domain-specific data to quickly tweak the model’s weights and apply it to unique problems.
Steps for Fine-Tuning Visual Models
- Select a Pre-Trained VFMs Model: Choose from popular ones like Visual GPT, Stable Diffusion, DALL-E, and SAM since they provide state-of-the-art performance on vision tasks. Each has strengths that fit different tasks, so your decision should be based on your business requirements.
- Get Your Fine-Tuning Training Data Ready: Resize images, label objects, and ensure data quality. In most cases, only a small amount of labeled data is required since most VFMs apply self-supervision to learn from unlabeled data.
- Keep Top Layers Intact:VFMs are complex deep learning models with several layers. Each layer extracts relevant features from the input data. For fine-tuning, freeze the top layers so that generalizable image features remain intact. Replace the final layers with a custom configuration to learn new features from
Model Fine-Tuning - Tweak It Gradually: Think of it like fine-tuning a musical instrument - unfreeze layers step by step to adapt to the fine details of your task. Use techniques like dropout, weight decay, adjusting learning rate, and batch normalization to prevent over-fitting and maximize performance. Experiment with learning rate schedules, such as step decay, cosine annealing, or one-cycle learning rates, to determine the best strategy for your dataset. Implement early stopping based on validation loss or accuracy and experiment with different hyperparameters such as batch size and optimizer settings.
- Evaluation & Testing: Once training is complete, evaluate the fine-tuned VFMs model on the testing dataset to measure its performance accurately. Use appropriate evaluation metrics for your specific task, such as intersection-over-union (IoU)and average precision. If the results are not satisfactory, repeat the steps again.
Strategies for Handling Imbalanced Datasets & Variability
While using pre-trained VFMs expedites the model development and fine-tuning process, businesses can face data limitations that prevent them from achieving the desired model performance. There are several techniques to overcome data hurdles while fine-tuning VFMs.
- Data Augmentation: Increase class balance through data augmentation, which increases the dataset by manipulating existing images.
- Stratified Sampling: Ensure unbiased evaluation through fair representation of classes in training, validation, and testing data.
- Resampling Techniques: Address class imbalance with over-sampling and under-sampling methods like SMOTE.
- Weighted Loss Functions: Enhance focus on underrepresented classes during training by adjusting loss function weights.
- Ensemble Methods: Improve performance and robustness by combining predictions from multiple models.
- Domain Adaptation: This technique improves target model performance by leveraging the knowledge learned from another related source domain.
Future Trends & Outlook
In the realm of AI and computer vision, VFMs are the future. Here are some exciting trends that we can expect to see in the coming years:
Architectural Advancements: VFMs will improve with more advanced architecture designs and optimization techniques. For instance, a self-correcting module in VFMs could continuously improve the model’s understanding of human intentions by learning from feedback.
Robustness & Interpretability: VFMs will become more interpretable, and humans will be able to learn how a model thinks before making a prediction. This ability will significantly help in identifying biases and shortfalls.
Multimodal Integration: With multimodal integration, VFMs will be able to handle different types of information, such as combining pictures with words, sounds, or information from sensors.
For example, the multimodal conversational model, JARVIS, extends the capabilities of traditional chatbots. Microsoft Research’s JARVIS enhances ChatGPT's capability by combining several other generative AI models, allowing it to simultaneously process several data types, such as text, image, video, and audio. A user can ask JARVIS complex visual questions, such as writing detailed descriptions of highly abstract images.
Synergies with Other AI Domains: The development of VFMs is closely connected to the development of other areas of AI, creating an alliance that amplifies their overall impact. For instance, VFMs that work with NLP systems can enhance applications like picture captioning and visual question answering.
Visual Foundation Models — A Step Towards AGI
Visual foundation models are a promising step towards unlocking artificial general intelligence (AGI). To develop algorithms that can be applied to any real-world task, these models need to be able to process multimodal data, such as text and images. While the NLP domain has showcased AGI-level performance using LLMs, such as OpenAI’s GPT-4, the computer vision domain has yet to achieve similar performance due to the complexity of interpreting visual signals. However, emerging visual foundation models are a promising step in this direction.
Ideally, VFMs can perform various vision-language tasks and generalize accurately to new, unseen environments. Alternatively, a unified platform could merge different visual foundation models to solve different vision tasks. Models like SAM and SegGPT have shown promise in addressing multi-modal tasks. However, to truly achieve AGI, CV and NLP systems must be able to operate globally at scale.
The All-Seeing project has demonstrated a model’s capabilities to recognize and understand everything in this world. The All-Seeing model (ASM) is trained on a massive dataset containing millions of images and language prompts, allowing it to generalize for many language and vision tasks using a unified framework while maintaining high zero-shot performance. Such advancements are a step towards achieving vision-language artificial general intelligence.
Visual Foundation Models: Key Takeaways
Here are some key takeaways:
- Visual foundation models generate images based on language prompts.
- VFMs perform well on many vision tasks without requiring large amounts of labeled training data.
- VFMs apply self-supervision to learn patterns from unlabeled training data.
- Customizing or fine-tuning VFMs for specific tasks improves their accuracy.
- Data limitations in VFMs can be addressed using techniques such as data augmentation, resampling, ensembling, and domain adaptation.
- Metrics like AP, IoU, and PQ help measure how good VFMs are at visual tasks.
- VFMs can achieve better results when combined with other smart systems like NLP, reinforcement learning, and generative models.
- VFMs are moving towards achieving vision-language artificial general intelligence.
Frequently asked questions
VFMs are foundation models that can handle complex visual tasks like image generation. Most VFMs use visual transformers as the primary component in their architectures. Enterprises can use VFMs for several downstream applications by fine-tuning the models for specific tasks.
Think of VFMs as upgraded versions of traditional computer vision models. They are a lot faster and consume less data. VFMs can even work with language formats and adapt to different tasks.
VFMs can assist in medicine to analyze medical images like X-rays and MRI scans, in retail outlets to track different products, and even in art to restore paintings.
Enterprises can use metric measurements like accuracy, IoU, and PQ to evaluate how well VFMs perform.
The goal of VFM is to merge the capabilities of visual models like Stable Diffusion and visual transformers with large language models like ChatGPT to solve various vision-language tasks and achieve better generalizability for unseen environments.
Fundamental components of VFM include: Pre-training on large-scale datasets, self-supervised learning, image embeddings, linguistic understanding (prompt manager), and fine-tuning for downstream tasks.
Encord provides robust data visualization and curation capabilities that allow users to manage and analyze their datasets effectively. This includes multi-view annotation workflows and support for dynamic nested ontologies, which help in organizing complex data structures and enhancing the overall annotation process.
Encord integrates seamlessly with existing data pipelines and DevOps practices, facilitating a smooth workflow from data collection to model training. This integration ensures that teams can leverage their current infrastructure while enhancing their capabilities with Encord's robust platform.
The workflow template builder in Encord allows users to create custom annotation flows by dragging and arranging stages within the UI. This flexibility ensures that unlabeled data is efficiently transformed into labeled data through various stages, including annotation and review.
Encord offers a seamless integration process for back-end developers, allowing for efficient connectivity with existing systems. This includes tools and documentation that support developers in implementing necessary integrations smoothly.
Yes, Encord can integrate with existing visualization tools used by clients. This flexibility allows teams to utilize their current systems while also benefiting from Encord's advanced capabilities for data management and annotation.