Zero-Shot Learning (ZSL) Explained

Artificial intelligence (AI) models, especially in computer vision, rely on high-quality labeled data to learn patterns and real-world representations to build robust models. However, obtaining such data is a challenging task in the real world. It requires significant time and effort to curate datasets of high quality, and it is practically impossible to identify and curate data for all classes within a domain.
With novel architectures, optimized training techniques, and robust evaluation mechanisms, practitioners can solve complex business problems and enhance the reliability of AI systems.
Enter Zero-shot learning (ZSL). Zero-shot learning (ZSL) enables machine learning models to recognize objects from classes they have never seen during training. Instead of relying solely on extensive labeled datasets, ZSL leverages auxiliary information like semantic relationships or attributes learned from training data to bridge the gap between known and unknown classes.
With ZSL, the struggle to label extensive datasets is reduced significantly, and ML models no longer need to undergo the time-consuming training process to deal with previously unknown data.
In this post, you will delve into the significance of the zero-shot learning paradigm, explore its architecture, list prominent ZSL models, and discuss popular applications and key challenges.
What is Zero-Shot Learning?
Zero-shot learning is a technique that enables pre-trained models to predict class labels of previously unknown data, i.e., data samples not present in the training data. For instance, a deep learning (DL) model trained to classify lions and tigers can accurately classify a rabbit using zero-shot learning despite not being exposed to rabbits during training. This is achieved by leveraging semantic relationships or attributes (like habitat, skin type, color, etc.) associated with the classes, bridging the gap between known and unknown categories.
Zero-shot learning is particularly valuable in domains such as computer vision (CV) and natural language processing (NLP), where access to labeled datasets is limited. Teams can annotate vast datasets by leveraging zero-shot learning models, requiring minimal effort from specialized experts to label domain-specific data. For example, ZSL can help automate medical image annotation for efficient diagnosis or learn complex DNA patterns from unlabeled medical data.
It is important to differentiate zero-shot learning from one-shot learning and few-shot learning. In one-shot learning, a sample is available for each unseen class. In few-shot learning, a small number of samples are present for each unseen class. The model learns information about these classes from this limited data and uses it to predict labels for unseen samples.
Types of Zero-Shot Learning
There are several zero-shot learning techniques available to address specific challenges. Let’s break down the four most common ZSL methods.
Attribute-based Zero-Shot Learning
Attribute-based ZSL involves training a classification model using specific attributes of labeled data. The attributes refer to the various characteristics in the labeled data, such as its color, shape, size, etc. A ZSL model can infer the label of new classes using these attributes if the new class sufficiently resembles the attribute classes in the training data.
Semantic Embedding-based Zero-Shot Learning
Semantic embeddings are vector representations of attributes in a semantic space, i.e., information related to the meaning of words, n-grams, and phrases in text or shape, color, and size in images. For example, an image or word embedding is a high-dimensional vector where each element represents a particular property. Methods like Word2Vec, GloVe, and BERT are commonly used to generate semantic embeddings for textual data. These models produce high-dimensional vectors where each element can represent a specific linguistic property or context.
Zero-shot learning models can learn these semantic embeddings from labeled data and associate them with specific classes during training. Once trained, these models can project the known and unknown classes onto this embedding space. By measuring the similarity between embeddings using distance measures, the model can infer the category of unknown data.
Some notable semantic embedding-based ZSL methods are Semantic AutoEncoder (SAE), DeViSE, and VGSE.
SAE involves an encoder-decoder framework that classifies unknown objects by optimizing a restricted reconstruction function.
Similarly, DeViSE trains a deep visual semantic embedding model to classify unknown images through text-based semantic information.
VGSE automatically learns semantic embeddings of image patches requiring minimal human-level annotations and uses a class relation module to compute similarities between known and unknown class embeddings for zero-shot learning.
Generalized Zero-Shot Learning (GZSL)
GZSL extends the traditional zero-shot learning technique to emulate human recognition capabilities. Unlike traditional ZSL, which focuses solely on unknown classes, GZSL trains models on known and unknown classes during supervised learning. You train GSZL models by establishing a relationship between known and unknown classes, i.e., transferring knowledge from known classes to unknown classes using their semantic attributes. One technique that complements this approach is domain adaptation.
Domain adaptation is a useful transfer learning technique in this regard. It allows AI practitioners to re-purpose a pre-trained model for a different dataset containing unlabeled data by transferring semantic information.
Researchers Pourpanah, Farhad, et al. have presented a comprehensive review of GZSL methods. They classified GZSL into two categories based on how knowledge is transferred and learned from known to unknown classes:
- Embedding-based methods: Usually based on attention mechanism, autoencoders, graphs, or bidirectional learning. Such methods learn lower-level semantic representations derived from visual features of known classes in the training set and classify unknown samples by measuring their similarity with representations of known classes.
- Generative-based methods: These techniques often include Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs). They learn visual representations from known class features and word embeddings from known and unknown class descriptions to train a conditional generative model for generating training samples. The process ensures the training set includes known and unknown classes, turning zero-shot learning into a supervised-learning problem.
GZSL provides a more holistic and adaptable approach to recognizing and categorizing data across a broader spectrum of classes through these methods.
Multi-Modal Zero-Shot Learning
Multi-modal ZSL combines information from multiple data modalities, such as text, images, videos, and audio, to predict unknown classes. By training a model using images and their associated textual descriptions, for instance, an ML practitioner can extract semantic embeddings and discern valuable associations. The model can extract semantic embeddings and learn valuable associations from this data. With zero-shot capabilities, this model can generalize to similar unseen datasets with accurate predictive performance.
Basic Architecture of Zero-Shot Learning
Let’s consider a ZSL image classification model. Fundamentally, it includes semantic and visual embedding modules and a zero-shot learning component that calculates the similarity between the two embeddings.
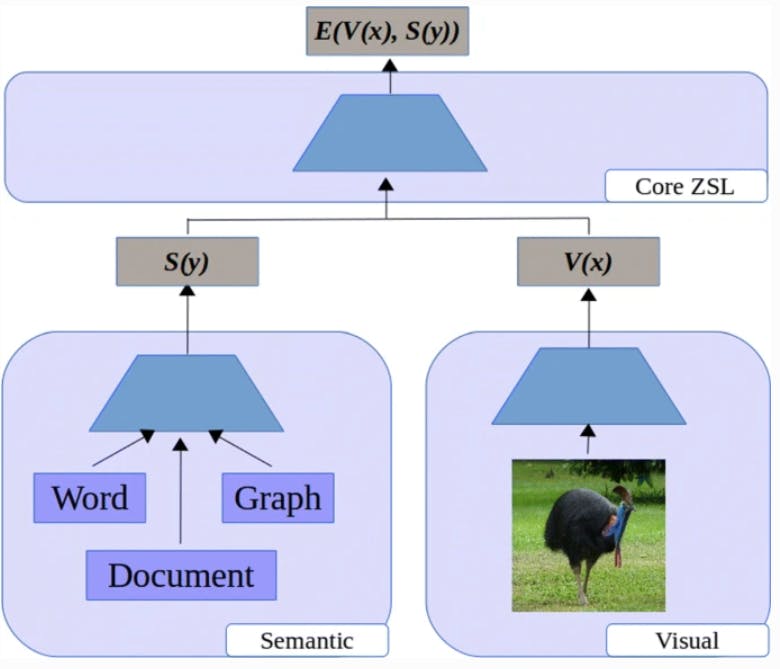
Overview of a Basic Zero-shot Learning Architecture
The semantic embedding module projects textual or attribute-based information, like a document, knowledge graph, or image descriptors, onto a high-dimensional vector space.
Likewise, the visual embedding module converts visual data into embeddings that capture the core properties of an image. Both the semantic and visual embeddings are passed on to the ZSL module to compute their similarity and learn the relationship between them.
How Does Zero-shot Learning Work?
The learning process involves minimizing a regularized loss function with respect to the model’s weights over the training examples. The loss function includes the similarity score derived from the ZSL module. Once trained, a one-vs-rest classifier model can then predict the label of an unknown image by assigning it the class of a textual description with the highest similarity score. For example, if the image embedding is close to a textual embedding that says “a lion,” the model will classify the image as a lion.
The semantic and visual embedding modules are neural networks that project images and text onto an embedding space. The modules can be distinct deep learning models trained on auxiliary information, like ImageNet. The output from these models is fed into the ZSL module and trained separately by minimizing an independent loss function. Alternatively, these modules can be trained in tandem, as illustrated below.
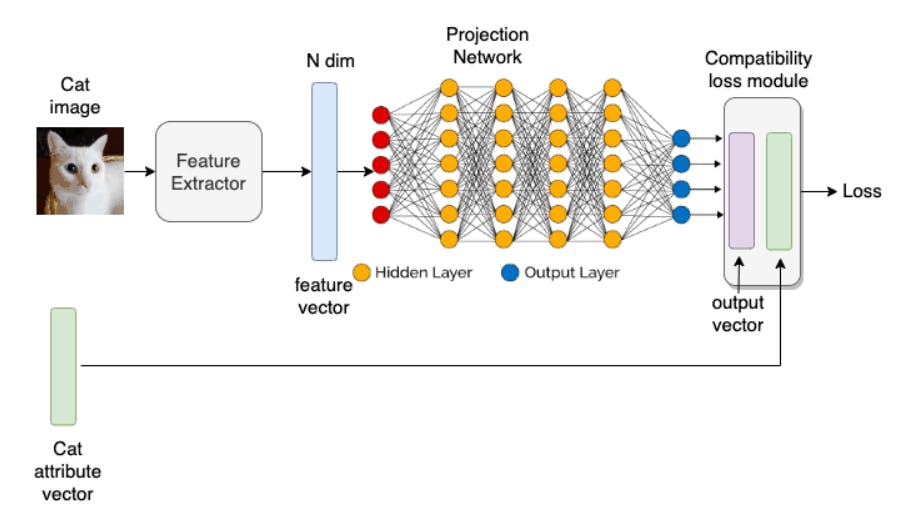
A pre-trained feature extractor transforms the cat’s image in the illustration above into an N-dimensional vector. The vector represents the image’s visual features fed into a neural net. The neural net's output is a lower-dimensional feature vector. The model then compares this lower-dimensional feature vector with the known class attribute vector and uses backpropagation to minimize the loss (difference between both vectors).
In summary, when you get an image of a new, unknown class (not part of training data), you would:
- Extract its features using the feature extractor.
- Project these features into the semantic space using the projection network.
- Find the closest attribute vector in the semantic space to determine the class of the image.
Recent Generative Methods
Traditional zero-shot learning is still limited because the projection function of semantic and visual modules only learns to map known classes onto the embedding space.
It’s not apparent how well the learning algorithm will perform on unknown classes, and the possibility exists that the projection of such data is incorrect. And that’s where GZSL plays a vital role by incorporating known and unknown data as the training set.
However, the learning methods are different from the ones described above. Generative adversarial networks (GANs) and variational autoencoders (VAEs) are prominent techniques in this domain.
A Brief Overview of Generative Adversarial Networks (GANs) in Zero-Shot Learning
GANs consist of a discriminator and a generator network. The objective of a generator is to create fake data points, and the discriminator learns to determine whether the data points are real or fake.
AI practitioners use this concept to treat zero-shot learning as a missing data problem. The illustration below shows a typical GAN architecture for ZSL.
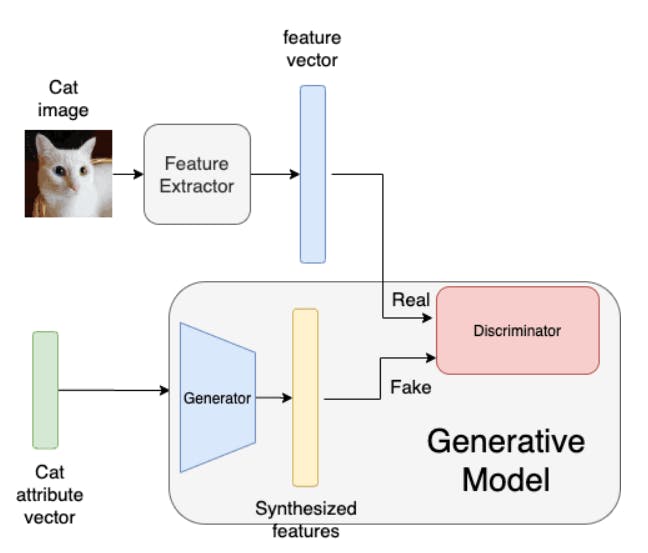
The workings of this architecture are as follows:
- A feature extractor transforms an image into an N-dimensional vector.
- A corresponding attribute vector is used for pre-training a generator network.
- The resulting output of the generator network is a synthesized N-dimensional vector.
- A discriminator then compares the two vectors to see which one is fake.
You can then feed semantic embeddings or attribute vectors of unknown classes to the generator to synthesize fake feature vectors with relevant class labels. Together with actual feature vectors, you can train a neural network to classify known and unknown embedding categories to achieve better model accuracy.
A Brief Overview of Variational Autoencoders (VAEs) in Zero-Shot Learning
VAEs, as the name suggests, consist of encoders that transform a high-dimensional data distribution into a latent distribution, i.e., a compact and low-dimensional representation of data that keeps all its important attributes. You can use the latent distribution to sample random data points. You can then feed these points to a decoder network, which will map them back to the original data space.
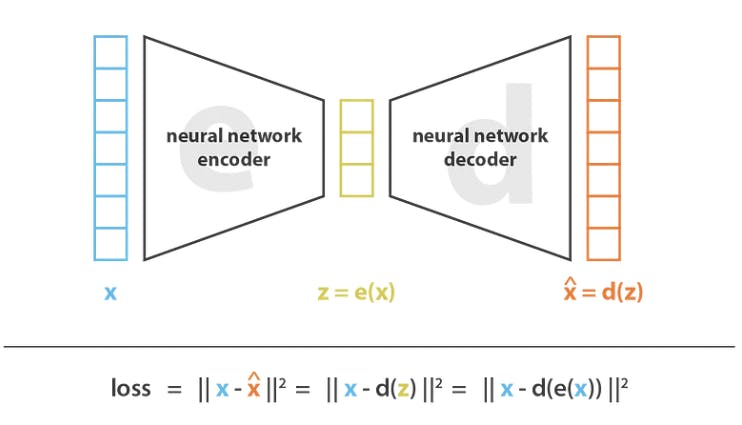
Like GANs, you can use VAEs for multi-modal GZSL. You can train an encoder network to generate a distribution in the latent space using a set of known classes as the training data, with semantic embeddings for each class.
A decoder network can sample a random point from the latent distribution and project it onto the data space. The difference between the reconstructed and actual classes is the learning error in training the decoder.
Once trained, you feed semantic embeddings of unknown classes into the decoder network to generate samples with corresponding labels. You can train a classifier network for the final classification task using the generated and actual data.
Evaluating Zero-Shot Learning (ZSL) models
Practitioners use several evaluation metrics to determine the performance of zero-shot learning models in real-world scenarios. Common methods include:
- Top-K Accuracy: This metric evaluates if the actual class matches the predicted classes with top-k probabilities. For instance, class probabilities can be 0.1, 0.2, and 0.15 for a three-class classification problem. With top-1 accuracy, the model is doing well if the predicted class with the highest probability (0.2) matches the actual class. With top-2 accuracy, the model is doing well if the real class matches either of the predicted classes with top-2 probability scores of 0.2 and 0.15.
- Harmonic Mean: You can compute the harmonic mean—the number of values divided by the reciprocal of their arithmetic mean—off top-1 and top-5 precision values for a more balanced result. It helps evaluate the average model performance by combining top-1 and top-5 precision.
- Area Under the Curve (AUC): AUC measures the area under the receiver operating characteristic (ROC) curve, i.e., a plot that shows the tradeoff between the true positive rate (TPR) or recall against the false positive rate (FPR) of a classifier. You can measure a ZSL model’s overall classification performance based on this metric.
- Mean Average Precision (mAP): The mAP metric is particularly used to measure the accuracy of object detection tasks. It is based on measuring the precision and recall for every given class at various levels of confidence thresholds. The method helps measure performance for tasks that require recognizing multiple objects within a single image. It also allows you to rank average precision scores for different thresholds and see which threshold gives the best results.
Popular Zero-Shot Learning (ZSL) models
The following list mentions some mainstream zero-shot learning models with widespread application in the industry.
Contrastive Language-Image Pre-Training (CLIP)
Introduced by OpenAI in 2021, CLIP uses an encoder-decoder architecture for multimodal zero-shot learning. The illustration below explains how CLIP works.
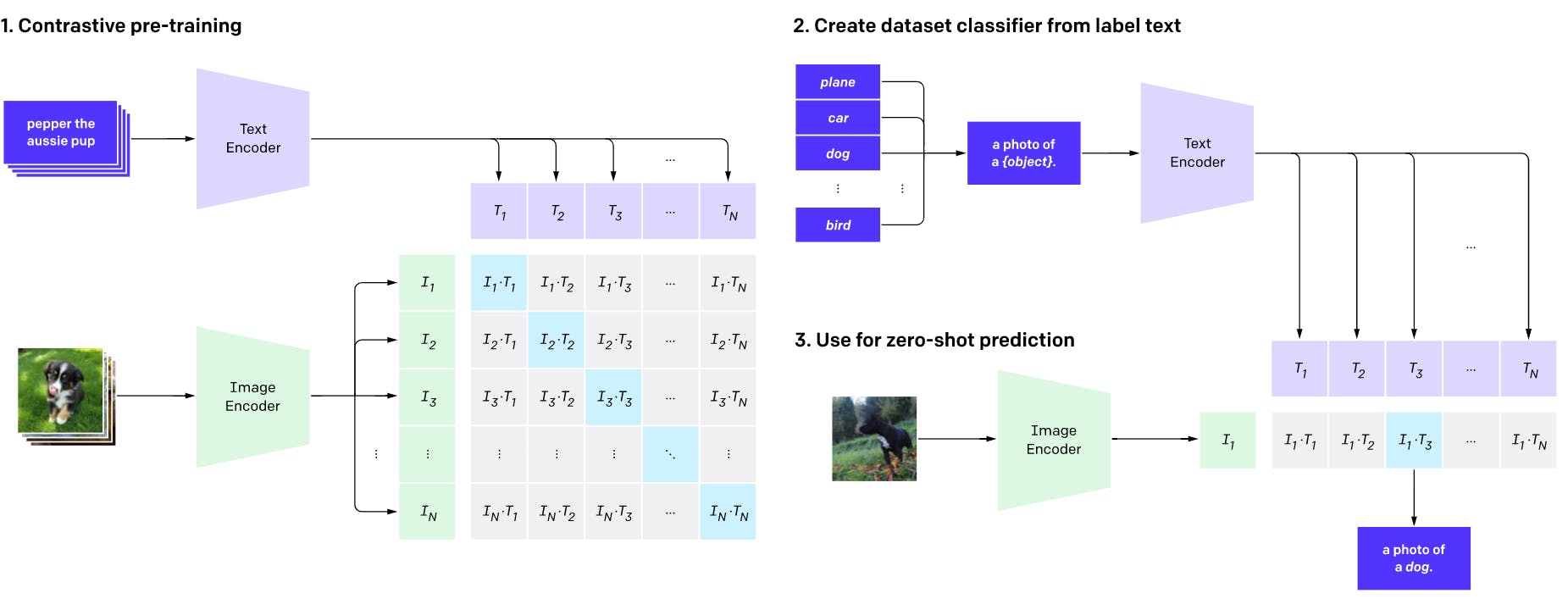
CLIP Architecture Overview
It inputs text snippets into a text encoder and images into an image encoder. It trains the encoders to predict the correct class by matching images with the appropriate text descriptions.
You can use a textual dataset of class labels as captions and feed them to the pre-trained text encoder. They can input an unseen image into the image decoder. The predicted class will belong to the text caption with which the image has the highest pairing score.
Bidirectional Encoder Representations from Transformers (BERT)
BERT is a popular sequence-to-sequence large language model that uses a transformer-based encoder-decoder framework. Unlike traditional sequential models that can read words in a single direction, transformers use the self-attention mechanism to process sentences from both directions, allowing for a richer understanding of the sequence’s context.
During training, the model learns to predict a masked or hidden word in a given sentence. It also learns to identify whether two sentences are connected or distinct. Typically, BERT is used as a pre-trained model to fine-tune it for various downstream NLP tasks, such as question answering and natural language inference.
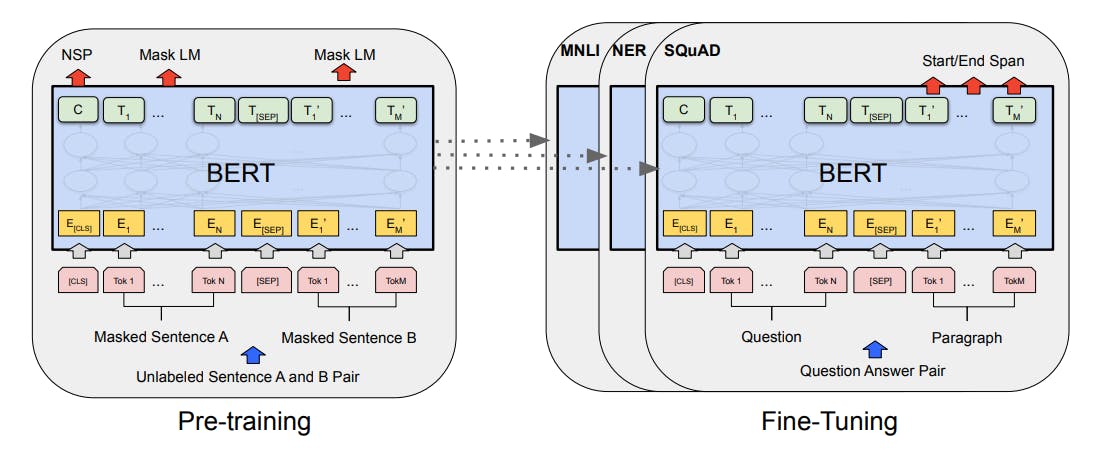
BERT Pre-training and Fine-tuning Architecture
Though BERT was not initially designed with zero-shot capabilities, practitioners have developed various BERT variants capable of performing zero-shot learning. Models like ZeroBERTo, ZS-BERT, and BERT-Sort can perform many NLP tasks on unseen data.
Text-to-Text Transfer Transformer (T5)
T5 is similar to BERT, using a transformer-based encoder-decoder framework. The model converts all language tasks into a text-to-text format, i.e., taking text as input and generating text as output. This approach allows practitioners to apply the same model, parameters, and decoding process to all language tasks. As a result, the model delivers good performance for several NLP tasks, such as summarization, classification, question answering, translation, and ranking.
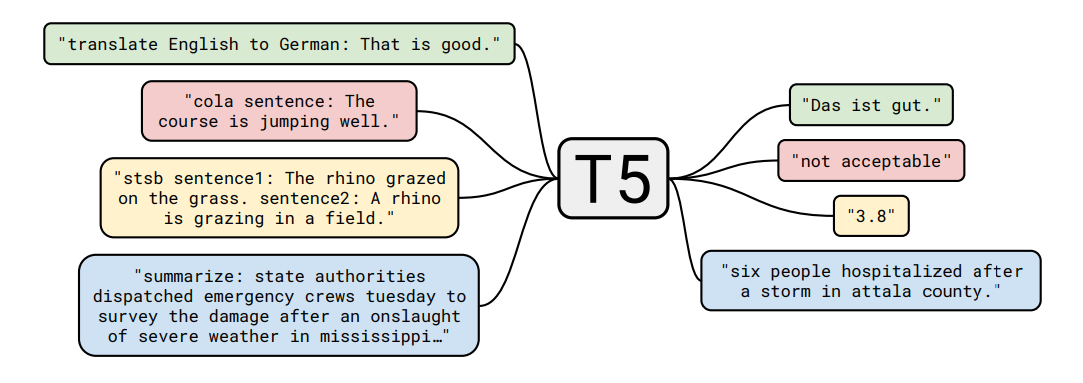
Since T5 can be applied to a wide range of tasks, researchers have adapted it to achieve good performance for zero-shot learning. For instance, RankT5 is a text ranking model that performs well on out-of-domain datasets. Another T5 model variant, Flan T5, generalizes well to unseen tasks.
Challenges of Zero-Shot Learning (ZSL) models
While zero-shot learning offers significant benefits, it still poses several challenges that AI researchers and practitioners need to address. These include:
Hubness
The hubness problem occurs due to the high-dimensional nature of zero-shot learning. ZSL models project data onto a high-dimensional semantic space and classify unseen points using a nearest neighbor (NN) search.
However, the semantic space can often contain “hubs” where particular data points are close to other samples. The diagram below illustrates the issue in two-dimensional space.
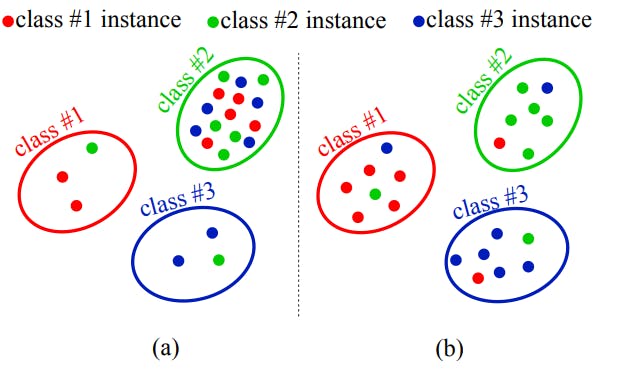
Panel (a) in the diagram shows that data points form a hub around class 2. It means the model will wrongly classify most unseen classes as class 2 since their embeddings are closest to class 2. The problem is more severe in higher dimensions.
Panel (b) shows the situation when there’s no hubness and class predictions have an even distribution.
Semantic Loss
When projecting seen classes onto the semantic space, zero-shot learning models can miss crucial semantic information. They tend to focus on semantics, which only helps them classify seen classes. For instance, a ZSL model trained to classify cars and buses may fail to label a bicycle correctly since it doesn’t consider that cars and buses have four wheels. That’s because the attribute “have four wheels” wasn’t necessary when classifying buses and cars.
Domain Shift
Zero-shot learning models can suffer from domain shift when the training set distribution differs significantly from the test set. For instance, a ZSL model trained to classify wild cats may fail to classify insect species, as the underlying features and attributes can vary drastically.
Bias
Bias occurs when zero-shot learning models only predict classes belonging to the seen data. The models cannot predict anything outside of the seen classes. This inherent bias can hinder the model's ability to genuinely predict or recognize unseen classes.
Applications of Zero-Shot Learning (ZSL)
Zero-shot learning technique applies to several AI tasks, especially computer vision tasks, such as:
- Image Search: Search engines can use ZSL models to find and retrieve relevant images aligned with a user’s search query.
- Image Captioning: ZSL models excel at real-time labeling, helping labelers annotate complex images instantly by reducing the manual effort required for image captioning.
- Semantic Segmentation: Labeling specific image segments is laborious. ZSL models help by identifying relevant segments and assigning them appropriate classes.
- Object Detection: ZSL models can help build effective navigation systems for autonomous cars as they can detect and classify several unseen objects in real-time, ensuring safer and more responsive autonomous operations.
Zero-Shot Learning (ZSL): Key Takeaways
Zero-shot learning is an active research area, as it holds significant promise for the future of AI. Below are some key points to remember about ZSL.
- Classification efficiency: ZSL allows AI experts to instantly identify unseen classes, freeing them from manually labeling datasets.
- Embeddings at the core: Basic ZSL models use semantic and visual embeddings to classify unknown data points.
- Generative advancements: Modern generative methods allow ZSL to overcome issues related to high-dimensional embeddings.
- Hubness problem: The most significant challenge in ZSL is the hubness problem.
- Multi-modal GZSL can help mitigate many issues by using seen and unseen data for training.
Frequently asked questions
Zero-shot means the ability of a machine learning model to classify completely unseen data.
Zero-shot Learning (ZSL) in NLP is a learning technique that allows AI models to classify unseen textual data. For instance, sentiment analysis is one example where ZSL can classify the sentiment of an utterly novel text snippet.
A zero-shot classifier uses semantic embeddings of seen classes and compares them to the embeddings of unseen classes. The predicted label is the one for which the unseen semantic embedding is closest to the seen class embedding according to a similarity measure.
Zero-shot learning involves building a model to classify data without any label. In one-shot learning, only a single label exists for a new class.
A ZSL model for an autonomous car can convert the images of any new object it sees on the road into semantic embeddings. Using an appropriate similarity measure, it can assign the new object a class label closest to the class with a similar embedding.
ZSL models can suffer from bias, unable to predict classes outside the seen class distribution. As such, ZSL models may fail to generalize to novel data with significantly different distributions from the source. The projection of classes onto the semantic space is also problematic due to the high dimensionality of the source data.
Encord streamlines the annotation process by providing an intuitive interface that allows users to efficiently annotate videos and images, reducing the time spent on manual tasks. This helps teams focus on building and training machine learning models more effectively.