Image Embeddings to Improve Model Performance

We rely on our senses to perceive and communicate. We view the world through our eyes, hear using our ears, and speak using our mouths. But how do algorithms achieve such incredible feats without these sensory experiences?
The secret lies in embeddings! Embeddings enable computers to understand and analyze data through numerical representations.
An embedding model transforms the complexity of visual data into a condensed, numerical representation - the embedding vector. These embedding vectors hold the essence of images, capturing their unique features, patterns, and semantics. Machine learning models gain insight into images by leveraging image embeddings. This paves the way for enhanced image classification, similarity comparison, and image search capabilities.
 💡 Want to learn more about embeddings in machine learning? Read The Full Guide to Embeddings in Machine Learning.
💡 Want to learn more about embeddings in machine learning? Read The Full Guide to Embeddings in Machine Learning. What are Image Embeddings?
To extract information from images, researchers use image embeddings to capture the essence of an image. Image embeddings are a numerical representation of images encoded into a lower-dimensional vector representation. Image embeddings condense the complexity of visual data into a compact form. This makes it easier for machine learning models to process the semantic and visual features of visual data.
These embedding representations are typically in the form of fixed-length vectors, which are generated using deep learning models, such as Convolutional Neural Networks (CNNs) like ResNet.
Images are created by combining pixels, with each pixel containing unique information. For machine learning models to understand the image, each pixel needs to be represented as an image embedding.

How to Create Image Embeddings
There are various processes of generating image embeddings, used to capture the essence of an image. These processes enable tasks like image classification, similarity comparison, and image search.
Convolutional Neural Networks
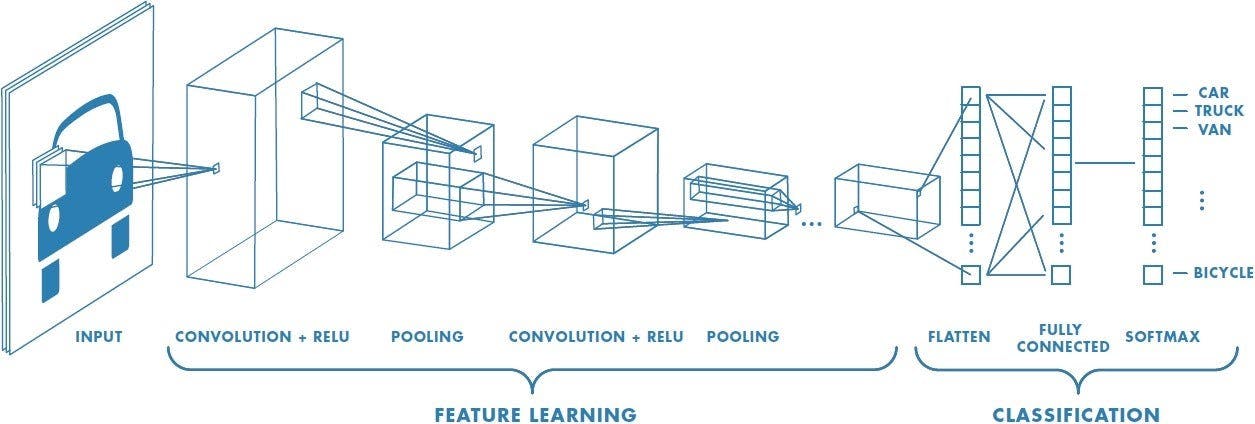
A Comprehensive Guide to Convolutional Neural Networks
Convolutional Neural Networks are a fundamental network architecture in deep learning. The core elements of CNNs include convolutional layers, pooling layers, and fully connected layers. CNNs can serve as both standalone models and as components that enhance the capabilities of other models. As a standalone model, CNNs are specifically tailored to process and analyze grid-like data directly. They can also be used as feature extractors or pre-trained models to aid other models.
CNNs excel at pattern recognition and object identification within visual data by applying convolutional filters to extract low-level features. These low-level features within an image will be combined to identify high-level features within the visual data.
💡 To learn more about CNNs, read our Convolutional Neural Networks Overview. Unsupervised Machine Learning
Unsupervised learning is a machine learning technique in which algorithms learn patterns from unlabeled data. This can be applied to image embeddings to further optimise representation by identifying clusters or latent factors within the embeddings without annotations.
Clustering is a popular unsupervised learning method in which you group similar images together using algorithms. Dimensionality reduction is another technique that involves transforming data from a high-dimensional space into a low-dimensional space. To accomplish this, you could use techniques like Principal Component Analysis (PCA) to transform the embeddings into lower-dimensional spaces and identify unique underlying relationships between images.
Pre-trained Networks and Transfer Learning
Pre-trained networks are CNN models trained on large networks such as ImageNet. These pre-trained models already possess the knowledge base of different representations of images and can be used to create new image embeddings.
Machine learning engineers do not need to build a model from scratch. They can use pre-trained models to solve their task or can fine-tune them for a specific job. An example of where to use pre-trained networks is in tasks such as image classification.
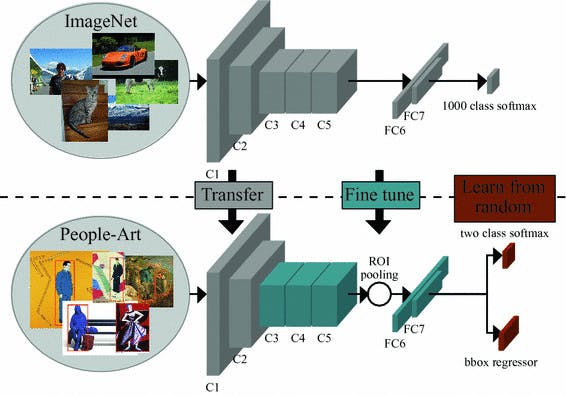
Detecting People in Artwork with CNNs
Transfer learning is a machine learning method where the application of knowledge obtained from a model used in one task can be reused as a foundation point for another task. It can lead to better generalisation, faster convergence, and improved performance on the new task.
You can use both methods to improve image embedding for specific and new tasks.
Benefits of Image Embeddings
Image embeddings offer several benefits in the world of computer vision.
Numerical Representation
Image embeddings offer a compact numerical representation of images that helps machine learning models better understand and learn from the data. Compacting the data into numerical representation saves storage space, reduces memory requirements, and facilitates efficient processing and analysis of the image.
Semantic Information
Image embeddings provide semantic information by capturing low-level visual features, such as edges, and textures, and higher-level semantic information, such as objects. They encode an image's meaningful features, allowing models to interpret the image's content easily. Semantic information is crucial for image classification and object detection tasks.
💡 To learn more about Object Detection, read Object Detection: Models, Use Cases, Examples. Transfer Learning
When using a pre-trained model to generate image embeddings, the weights from the pre-trained models will be transferred, and the embeddings can use that as a starting point with new tasks. Learned image embedding representations have shown higher model performance, even if it comes across unseen or unknown data.
Improved Performance
As image embeddings reduce the dimensionality of the image data, the lower-dimensional vector representations also reduce the visual features' complexity. Therefore, the model will require less memory requirements, improving its performance in processing data and faster training, all while still being able to contain the essential information necessary for the task at hand.

Tools Required for Image Embedding
This section will discuss the essential tools required for creating image embeddings, enabling you to extract powerful representations from images for various computer vision tasks.
Deep Learning Frameworks
Deep learning frameworks offer building blocks for designing, training, and validating deep neural networks. They provide powerful tools and libraries for different tasks, including computer vision, natural language processing, language models, and more. The most popular deep learning frameworks are:
- TensorFlow - provides comprehensive support for building and training deep learning models and computing image embeddings. It offers high-level APIs like Keras so that you can easily build and train your model. This provides flexibility and control over tasks.
- PyTorch is another popular deep learning framework that is well recognized for its easy-to-understand syntax. It provides a seamless integration with Python, containing various tools and libraries to build, train, and deploy machine learning models.
- Keras is a high-level deep learning framework that runs on top of backend engines such as TensorFlow. Keras Core, which will be available in Fall 2023, will also support PyTorch and Jax. Keras provides a variety of pre-trained models to improve your model's performance with feature extraction, transfer learning, and fine-tuning.
Image Embeddings to Improve Model Performance
There are several methods, techniques and metrics in computer vision and image embeddings to improve your model's performance.
Similarity
Similarity is used on image embeddings to plot points onto a dimensional space, in which these points explore similar images based on how close they are in the pixel region. You can use various similarity metrics to measure the distance between points. These metrics include:
- Euclidean distance - the length of a line segment between two points. A smaller Euclidean distance indicates more significant similarity between the image embeddings.

- Cosine similarity - focuses on the angle between vectors rather than the distance between their ends. The angle between the vectors and a value between -1 and 1 will be calculated to indicate the similarities between the embeddings. One (1) represents that the embeddings are identical, and -1 represents otherwise.
- K Nearest Neighbours - used for both regression, classification tasks, and to make predictions on the test set based on the training dataset's characteristics (labeled data). Depending on the chosen distance metric, the distance between the test set and the training dataset assumes that similar characteristics or attributes of the data points exist within proximity.
Other similarity metrics include Hamming distance and Dot product.
Principal Component Analysis
As mentioned above, you can use Principal Component Analysis (PCA) to create image embeddings and improve model performance. PCA is used to reduce the dimensionality of large datasets. This is done by transforming a large set of variables into smaller ones while preserving the most essential variations and patterns.
Principal Component Analysis (PCA) Explained Visually with Zero Math
There are several ways that PCA is used to improve model performance:
- Feature Vectors are the numerical representations that capture the visual and semantic characteristics of images. Feature vectors are concatenated representations that contain meaningful information about images in a lower-dimensional space using PCA and other features such as textual descriptions or metadata.
- Noise Reduction is a major challenge in images as they contain many pixels, making them more susceptible to noise variations. PCA can filter out noise and reduce irrelevant information while retaining the vital information. This increases the model's robustness against noise and improves its ability to generalize to unseen data.
- Interpretability reduces the number of variables and enables a linear transformation from the original embeddings in the large dataset to a new, reduced dataset. This allows improved interpretability of visual and semantic characteristics, identify relationships, and uncover significant features and patterns within the image data.

Hyperparameter Tuning
Hyperparameters are the parameters that define the architecture of a model . You tweak the hyperparameters to create the ideal model architecture for optimal performance. You ideally select hyperparameters that have a significant impact on the model's performance. For example:
- Learning Rate is a hyperparameter that controls the value to change the model’s weights in response to the estimated error each time they are updated. This influences the speed and convergence of the training process. You should aim to find the optimal balance for training the model with image embeddings.
- Batch Size refers to the number of samples used in each training iteration. For example, a large batch size can have faster training but require more GPU memory. A smaller batch size can have better generalization but slower convergence. Batch size greatly affects the model's training speed, generalization, memory consumption, and overall performance.
- Optimization algorithms are used to find the best solution to a problem. For example, algorithms such as Adam and Stochastic Gradient Descent (SGD) have different properties, meaning they have different behaviors. You should experiment with varying algorithms of optimization and hyperparameter tuning to find the optimal performance when training image embeddings. Choosing the correct optimization algorithm and fine-tuning it will impact the speed and quality of the model's convergence.
Other techniques for hyperparameter tuning in image embeddings include regularisation techniques, activation functions, early stopping, and grid/random search.
Transfer Learning
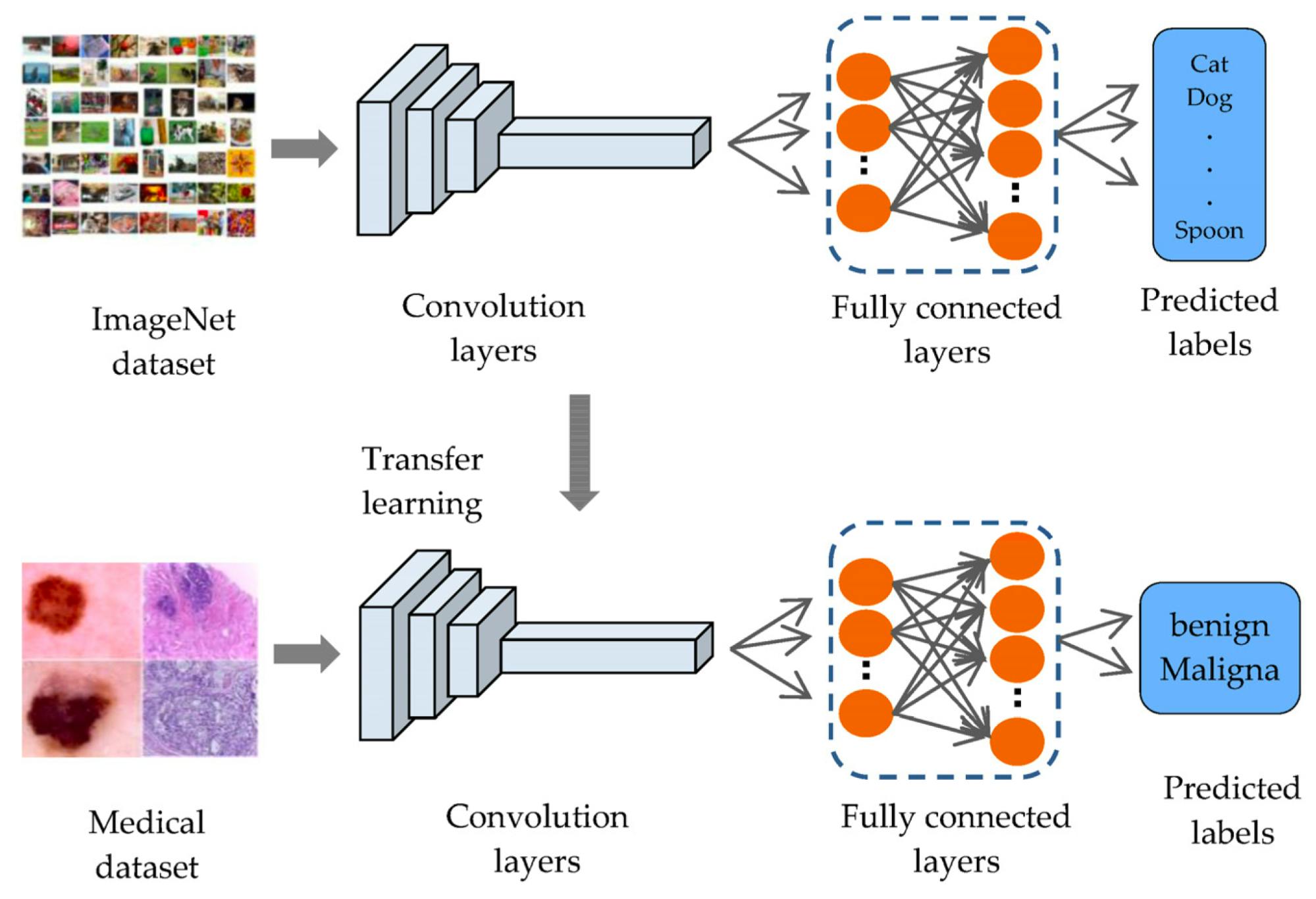
Incorporating a Novel Dual Transfer Learning Approach for Medical Images
Taking the knowledge from one task and applying it to another can help your model generalize better, produce faster convergence, and enhance overall performance. Below are different methods of how transfer learning can do this:
- Feature Extraction - uses pre-trained models that have been trained on large datasets and allows you to utilize the weights on visual representation. Pre-trained models act as a fixed feature extractor in which your model can capture visual insights of other image datasets or unseen data to improve model performance.
- Reduction in Training Time - transfer learning is an excellent way to improve your machine learning workflow, as building a model from scratch can be time-consuming and computationally expensive. Transfer learning of optimally trained models built using large datasets saves you from investing in more GPU, time, and employees. Training a new model with a pre-trained model with weights means that the new model requires fewer iterations and less data to achieve an optimal performance.
- Generalization - the ability of your model to adapt to new or unseen data. Pre-trained models have been developed using diverse datasets, allowing them to generalize better to a wide range of data. Using pre-trained models will enable you to adapt the robustness from the model to yours so it performs well on unseen and new images.
- Fine Tuning - transfer learning of pre-trained models allows you to fine-tune the model to a specific task. Updating the weights of a pre-trained model using a smaller dataset specific to a particular task will allow the model to adapt and learn new features regarding the task quickly.
Large Datasets
Using large image datasets can vastly improve your model's performance. Large image datasets provide a diverse range of images that allow the model to analyze and identify patterns, object variations, colors, and textures.
Overfitting is a problem that many data scientists and machine learning engineers face when working with machine learning models. Large datasets overcome the challenge of overfitting as they have more diverse data to generalise better and capture features and patterns.
The model becomes more stable with a larger dataset, encountering fewer outliers and noise. It can leverage patterns and features from a diverse range of images rather than solely focusing on individual instances in a smaller dataset.
When working with larger datasets, you can effectively reap the benefits of model performance when you implement transfer learning. Larger datasets allow pre-trained models to identify better and capture visual features, which they can transfer to other image-related tasks.
Image Embeddings: Key Takeaways
- Image embeddings compress images into lower-dimensional vector representations, providing a numerical representation of the image content.
- You can generate image embeddings through different methods, such as CNNs, unsupervised learning, pre-trained networks, and transfer learning.
- Image embeddings used in computer vision provide machine learning models with numerical representation, semantic information, improved performance, and transfer learning capabilities.
- Various techniques can improve model performance using image embeddings, such as similarity, PCA, hyperparameter tuning, transfer learning, and the use of larger datasets.
Frequently asked questions
Image embeddings are compressed numerical representations that capture visual and semantic features. Deep learning techniques like CNNs generate them to encode image content in lower dimensions. By processing images, CNNs extract features and patterns, outputting vector representations that encapsulate these characteristics for better understanding by machine learning models.
Image embeddings offer machine learning models enhanced data comprehension through numerical representation, capturing both low-level and high-level features. They facilitate better interpretation of image content. For large-scale projects, using pre-trained models to generate image embeddings significantly reduces time and resource requirements compared to building a model from scratch. Dimensionality reduction, semantic information, and transfer learning enhance model performance.
Data cleaning and preprocessing are vital in machine learning training. Quality data, outlier removal, and data standardization can enhance image embedding robustness. Additionally, techniques like transfer learning, data augmentation, regularization, ensembles, and large datasets further improve the robustness of image embeddings. These steps ensure a solid foundation for practical model training.
Encord provides several speed enhancements for annotating dense images, including the integration of the Sam model for auto-segmentation, which allows annotators to quickly draw boxes and have segmentation performed automatically. Additionally, Encord offers the ability to rapidly copy annotations from similar projects, reducing the number of clicks and improving overall annotation speed.
Encord provides customizable solutions for image storage that cater to the specific needs of teams working with large datasets. By allowing the creation of custom storage types, Encord ensures that users can efficiently manage image data while minimizing inefficiencies associated with traditional storage methods.
Encord's indexing function allows users to focus on specific cameras, sites, or timeframes within videos to refine their annotation process. By identifying areas of data that contribute to model failure modes, users can reallocate resources to those critical points, enhancing overall model performance.
Encord enhances the interpretability of large image databases by allowing users to create custom fields and metrics, making it easier to stratify and manage images effectively. This functionality helps in identifying and correcting values, moving items, and maintaining organization within the dataset.
Encord employs a robust system that combines both quantitative and qualitative metrics to curate datasets. This includes evaluating image quality across different devices and ensuring a balanced representation of various categories, which is essential for effective machine learning model training.
To ensure proper processing of image files in Encord, it's crucial to provide clear context about the data types and expected outputs. Sharing examples of the image formats and any specific requirements helps the Encord team guide you on the necessary preprocessing steps and adjustments.
Encord allows users to prioritize images for annotation by integrating with existing models to leverage embeddings. This enables users to select images that are most likely to benefit the model training process based on specific criteria, streamlining the annotation workflow.
Encord is designed to handle large image and video data sets efficiently, addressing common performance challenges such as slow retrieval times and scattered systems. This allows teams to manage their data pipelines more effectively and focus on improving model accuracy.
Yes, Encord is designed to manage large datasets, including millions of unlabeled images. Its active learning features help identify which data needs annotation, making it easier for teams to scale their operations without compromising on quality or performance.
Yes, Encord can enhance model accuracy in construction design reviews by integrating advanced pre-labeling techniques and multiple models in the annotation process. This ensures that the final outputs are more reliable and aligned with user expectations.