What is Vector Similarity Search?

Vector similarity search is a fundamental technique in machine learning, enabling efficient data retrieval and precise pattern recognition. It plays a pivotal role in recommendation systems, image search, NLP, and other applications, improving user experiences and driving data-driven decision-making.
Vector similarity search, also known as nearest neighbor search, is a method used to find similar vectors or data points in a high-dimensional space. It is commonly used in various domains, such as machine learning, information retrieval, computer vision, and recommendation systems.
The fundamental idea behind vector similarity search is to represent data points as vectors in a multi-dimensional space, where each dimension corresponds to a specific feature or attribute. For example, in a recommendation system, a user’s preferences can be represented as a vector, with each element indicating the user’s preferences for a particular item or category. Similarly, in image search, an image can be represented as a vector of features extracted from the image, such as color histograms or image embeddings.

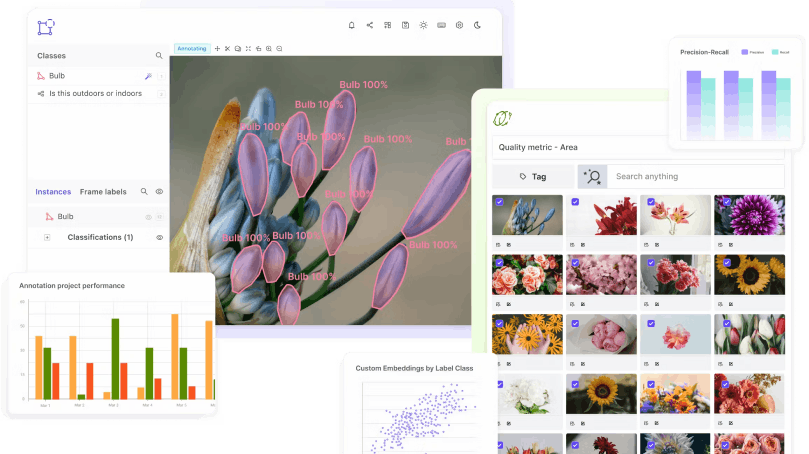
Example of embeddings plot in the BDD dataset using the Encord platform.
In this blog, we’ll discuss the importance of vector similarity search in machine learning and how AI embeddings can help improve it. We will cover the:
- Importance of high-quality training data
- Creating high-quality training data using AI embeddings
- Case studies demonstrating the use of embeddings
- Best practices for using AI embeddings

What Problem is Vector Similarity Search Solving?
Vector similarity search addresses the challenge of efficiently searching for similar items or data points in large datasets, particularly in high-dimensional spaces. Here are some of the problems vector similarity search addresses:
Curse of Dimensionality
In high-dimensional spaces, the sparsity of data increases exponentially, making it difficult to distinguish similar items from dissimilar ones. For example, an image of resolution 512⨯512 pixels contains raw data of 262,144 dimensions. Working directly with the raw data in its high-dimensional form can be computationally expensive and inefficient.
Traditional search methods struggle to handle this curse of dimensionality efficiently. Using embeddings can reduce these dimensions to 1,024, which is significantly lower. This reduction offers advantages such as decreased storage space, faster computations, and elimination of irrelevant information while preserving important features.
Ineffective keyword-based search
Traditional search methods, such as keyword-based search or exact matching, are not suitable for scenarios where similarity is based on multi-dimensional characteristics rather than explicit keywords.
Scalability
Searching through large datasets can be computationally expensive and time-consuming. Vector similarity search algorithms and data structures provide efficient ways to prune the search space, reducing the number of distance computations required and enabling faster retrieval of similar items.
Unstructured or Semi-Structured Data
Vector similarity search is crucial when dealing with unstructured or semi-structured data types, such as images, videos, text documents, or sensor readings. These data types are naturally represented as vectors or feature vectors, and their similarity is better captured using distance metrics.
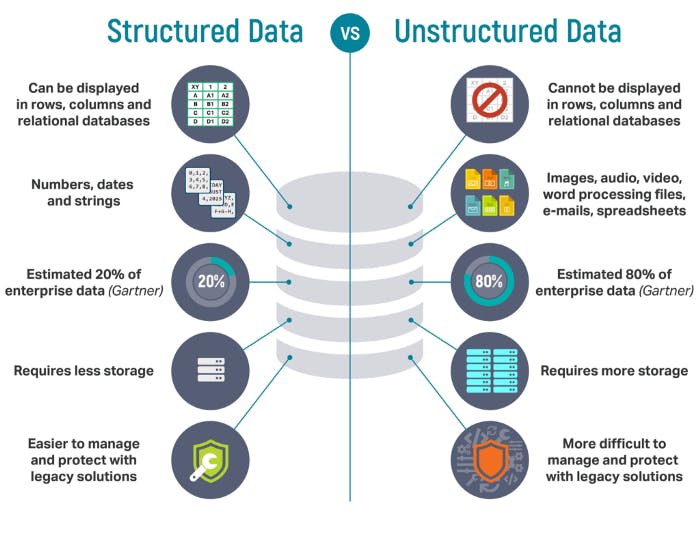
Illustration showing the difference between structured and unstructured data. Source
By addressing these problems, vector similarity search enhances the efficiency and effectiveness of various machine learning and data analysis tasks, contributing to advancements in recommendation systems, content-based search, anomaly detection, and clustering.
How Does Vector Similarity Work?
Vector similarity search involves three key components:
- vector embedding
- similarity score computation
- Nearest neighbor (NN) algorithms
Vector Embeddings
Vector embeddings are lower-dimensional representations of data that capture essential features and patterns, enabling efficient computation and analysis in tasks like similarity searches and machine learning. This is achieved by extracting meaningful features from the data. For example, in natural language processing, word embedding techniques like Word2Vec or GloVe transform words or documents into dense, low-dimensional vectors that capture semantic relationships. In computer vision, image embedding methods such as convolutional neural networks (CNNs) extract visual features from images and represent them as high-dimensional vectors.

Example showing vector embeddings generated using Word2Vec. Source
Similarity Score Computation
Once the data points are represented as vectors, a similarity score is computed to quantify the similarity between two vectors. Common distance metrics used for similarity computation include Euclidean distance, Manhattan distance, and cosine similarity.
Euclidean distance measures the straight-line distance between two points in space, Manhattan distance calculates the sum of the absolute differences between corresponding dimensions, and cosine similarity measures the cosine of the angle between two vectors. The choice of distance metric depends on the characteristics of the data and the application at hand.
NN Algorithms
Nearest neighbor (NN) algorithms are employed to efficiently search for the nearest neighbors of a given query vector. These algorithms trade off a small amount of accuracy for significantly improved search speed. Several ANN algorithms have been developed to handle large-scale similarity tasks:
k-Nearest Neighbors (kNN)
The kNN algorithm searches for the k nearest neighbors of a query vector by comparing distances to all vectors in the dataset. It can be implemented using brute-force search or optimized with data structures like k-d trees or ball trees.
 Naive k-nearest neighbors (kNN) algorithm is computationally expensive, with a complexity of O(n^2), where n is the number of data points. This is because it requires calculating the distances between each pair of data points, resulting in n*(n-1)/2 distance calculations.
Naive k-nearest neighbors (kNN) algorithm is computationally expensive, with a complexity of O(n^2), where n is the number of data points. This is because it requires calculating the distances between each pair of data points, resulting in n*(n-1)/2 distance calculations. 
kNN algorithm. Source
Space Partition Tree and Graph (SPTAG)
SPTAG is an efficient graph-based indexing structure that organizes vectors into a hierarchical structure. It uses graph partitioning techniques to divide the vectors into regions, allowing for a faster nearest-neighbor search.
Hierarchical Navigable Small World (HNSW)
HNSW is a graph-based algorithm that constructs a hierarchical graph by connecting vectors in a way that facilitates efficient search. It uses a combination of randomization and local exploration to build a navigable graph structure.

Illustration of HNSW. Source
Facebook’s similarity search algorithm (Faiss)
Faiss is a library developed by Facebook for efficient similarity search and clustering of dense vectors. It provides various indexing structures, such as inverted indices, product quantization, and IVFADC (Inverted File with Approximate Distance Calculation), which are optimized for different trade-offs between accuracy and speed.
These ANN algorithms leverage the characteristics of the vector space and exploit indexing structures to speed up the search process. They reduce the search space by focusing on regions likely to contain nearest neighbors, allowing for fast retrieval of similar vectors.
Use cases for Vector Similarity Search
Vector similarity search has numerous examples and use cases across various domains. Here are some prominent examples:
Recommendation Systems
Vector similarity search plays a crucial role in recommendation systems. By representing users and items as vectors, similarity search helps find similar users or items, enabling personalized recommendations. For example, in e-commerce, it can be used to recommend products based on user preferences or to find similar users for collaborative filtering.
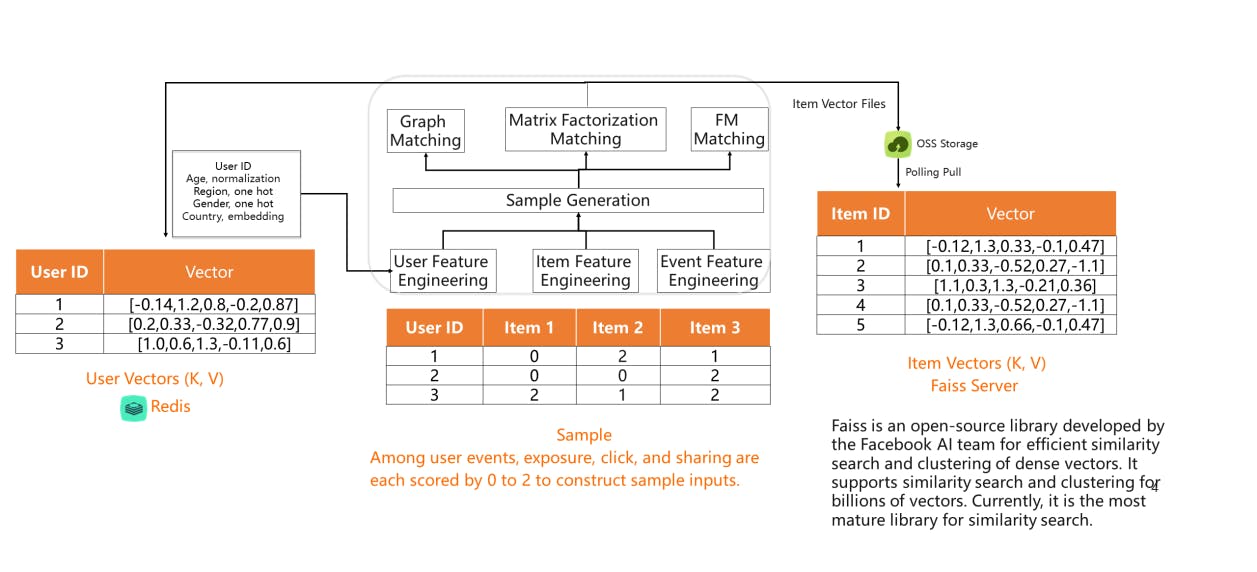
Illustration showing the use of vector similarity search in a recommendation system. Source
Image and Video Search
Vector similarity search is widely used in image and video search applications. By representing images or videos as high-dimensional feature vectors, similarity search helps locate visually similar content. It supports tasks such as reverse image search, content-based recommendation, and video retrieval.
Natural Language Processing (NLP)
In NLP, vector similarity search is employed for tasks like document similarity, semantic search, and word embeddings. Word embedding techniques like Word2Vec or GloVe transform words or documents into vectors, enabling efficient search for similar documents or words based on their semantic meaning.
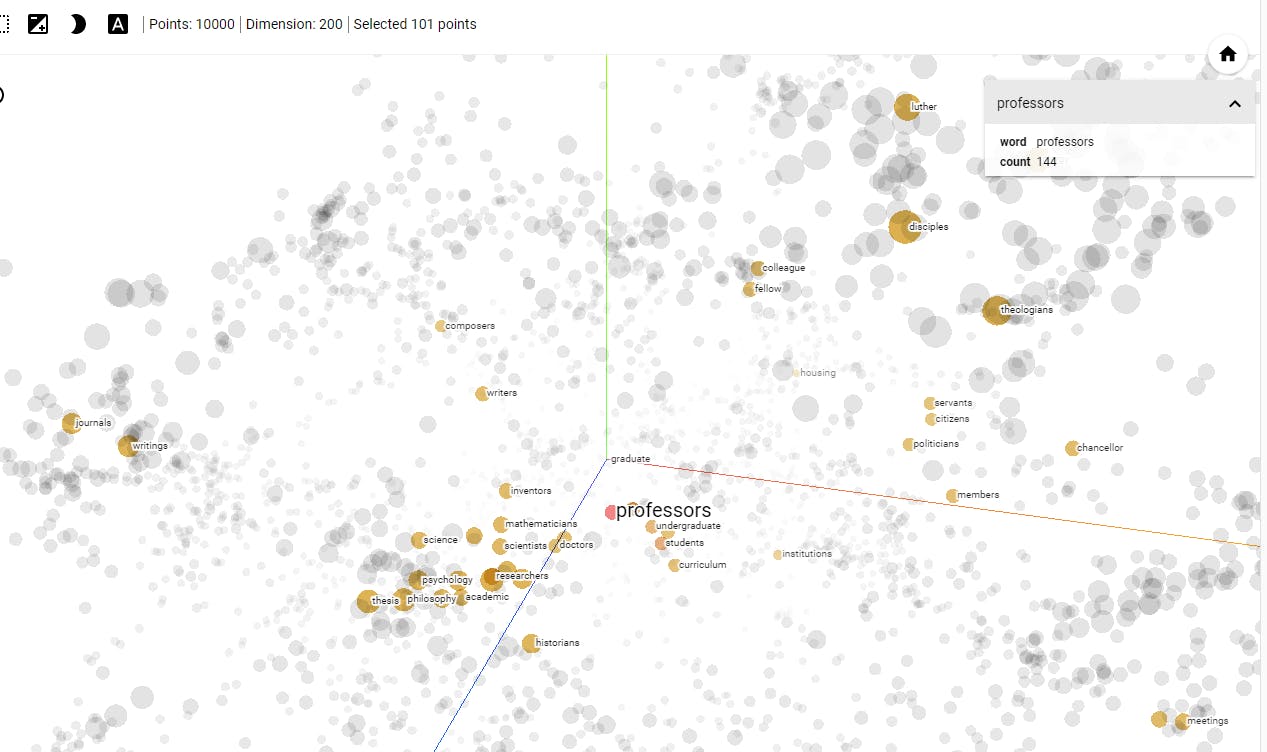
Example of visualization of word embeddings. Source
Anomaly Detection
Vector similarity search is utilized in anomaly detection applications. By comparing the vectors of data points to a normal or expected distribution, similar vectors can be identified. Deviations from the majority can be considered anomalies, aiding in detecting fraudulent transactions, network intrusions, or equipment failures.
Clustering
Clustering algorithms often rely on vector similarity search to group similar data points together. By identifying nearest neighbors or most similar vectors, clustering algorithms can efficiently partition data into meaningful groups. This is beneficial in customer segmentation, image segmentation, or any task that involves grouping similar instances.

Image Segmentation using Encord Annotate.
Read the blog to find out more about image segmentation. Genome Sequencing
In genomics, vector similarity search helps analyze DNA sequences. By representing DNA sequences as vectors and employing similarity search algorithms, researchers can efficiently compare sequences, identify genetic similarities, and discover genetic variations.
Social Network Analysis
Vector similarity search is used in social network analysis to find similar individuals based on their social connections or behavior. By representing individuals as vectors and measuring their similarity, it assists in tasks such as finding influential users, detecting communities, or suggesting potential connections.
Content Filtering and Search
Vector similarity search is employed in content filtering and search applications. By representing documents, articles, or web pages as vectors, similarity search enables efficient retrieval of relevant content based on their similarity to a query vector. This is useful in news recommendations, content filtering, or search engines.
The examples mentioned above highlight the versatility and importance of vector similarity search across different domains. By harnessing the capabilities of high-dimensional vectors and similarity metrics, this approach facilitates efficient information retrieval, pattern recognition, and data exploration. Consider the implementation of a comparison infographic, as it can aid in visualizing the characteristics of vector similarity search algorithms, complementing their applicability across various domains, including content filtering and search. However, it is essential to acknowledge the challenges associated with employing vector similarity search in real-world applications.
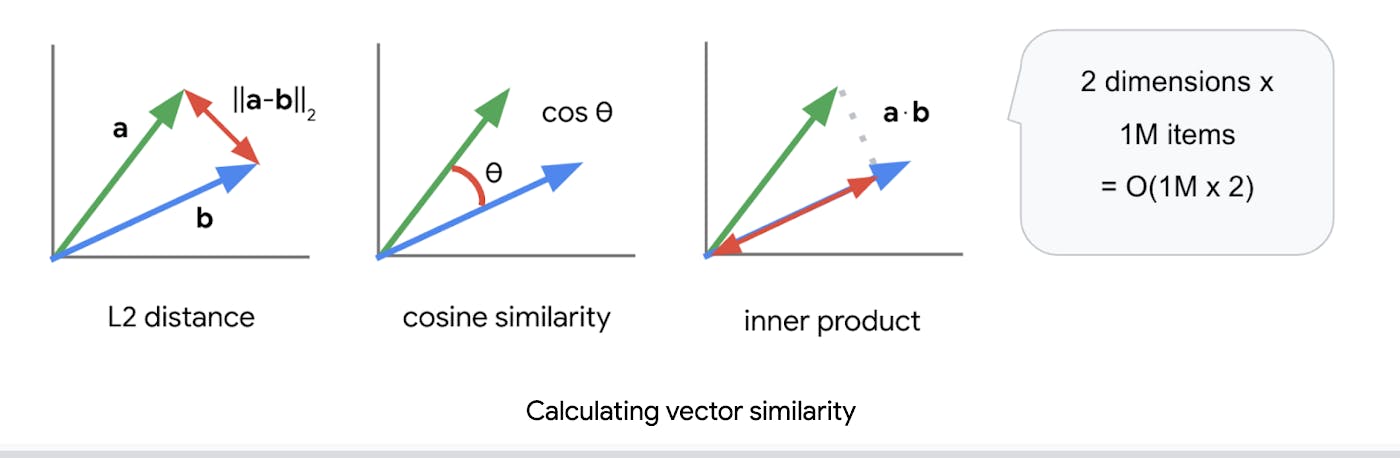
Google's vector similarity search technology. Source
Vector Similarity Search Challenges
While vector similarity search offers significant benefits, it also presents certain challenges in real-world applications. Some of the key challenges include:
High-dimensional Data
As the dimensionality of the data increases, the curse of dimensionality becomes a significant challenge. In high-dimensional spaces, the sparsity of data increases, making it difficult to discern meaningful similarities. This can result in degraded search performance and increased computational complexity.
Scalability
Searching through large-scale datasets can be computationally expensive and time-consuming. As the dataset size grows, the search process becomes more challenging due to the increased number of vectors to compare. Efficient indexing structures and algorithms are necessary to handle the scalability issues associated with vector similarity search.
Choice of Distance Metric
The selection of an appropriate distance metric is crucial in vector similarity search. Different distance metrics may yield varying results depending on the nature of the data and the application domain. Choosing the right metric that captures the desired notion of similarity is a non-trivial task and requires careful consideration.
Indexing and Storage Requirements
Efficient indexing structures are essential to support fast search operations in high-dimensional spaces. Constructing and maintaining these indexes can incur storage overhead and necessitate computational resources. Balancing the trade-off between indexing efficiency and storage requirements is a challenge in vector similarity search.

The trade-off between Accuracy and Efficiency
Many approximate nearest neighbor (ANN) algorithms sacrifice a certain degree of accuracy to achieve faster search performance. Striking the right balance between search accuracy and computational efficiency is crucial and depends on the specific application requirements and constraints.
Data Distribution and Skewness
The distribution and skewness of the data can impact the effectiveness of vector similarity search algorithms. Non-uniform data distributions or imbalanced data can lead to biased search results or suboptimal query performance. Handling data skewness and designing algorithms that are robust to varying data distributions pose challenges.
Interpretability of Results
Vector similarity search primarily focuses on identifying similar vectors based on mathematical similarity measures. While this can be effective for many applications, the interpretability of the results can sometimes be challenging. Understanding why two vectors are considered similar and extracting meaningful insights from the results may require additional post-processing and domain-specific knowledge.

How to Solve Vector Similarity Search Challenges
Here are some approaches you can use to solve the challenges listed above, including handling high-dimensional data, the choice of distance metrics, and indexing and storage requirements.
High-Dimensional Data
Dimensionality Reduction
Apply techniques like Principal Component Analysis (PCA) or t-SNE to reduce the dimensionality of the data while preserving meaningful similarities.
Feature selection: Identify and retain only the most relevant features to reduce the dimensionality and mitigate the curse of dimensionality.
Data preprocessing
Normalize or scale the data to alleviate the impact of varying feature scales on similarity computations. This is especially important in PCA to ensure that the input data is appropriately prepared, outliers and missing values are handled, and the overall quality of the input data is improved.
Choice of Distance Metric
Domain-specific metrics
Design or select distance metrics that align with the specific domain or application requirements to capture the desired notion of similarity more accurately.
Adaptive distance metrics
Explore adaptive or learning-based distance metrics that dynamically adjust the similarity measurement based on the characteristics of the data.
Indexing and Storage Requirements
Trade-off Strategies
Balance the trade-off between indexing efficiency and storage requirements by selecting appropriate indexing structures and compression techniques.
Approximate indexing
Adopt approximate indexing methods that provide trade-offs between storage space, search accuracy, and query efficiency.
Neural Hashing
Neural hashing is a technique that can be employed to tackle the challenges of vector similarity search, particularly in terms of accuracy and speed. It leverages neural networks to generate compact binary codes that represent high-dimensional vectors, enabling efficient and accurate similarity searches.

An example of neural network hashing. Source
Neural Hashing Mechanism
Neural hashing works in three phases:
Training Phase
In the training phase, a neural network model is trained to learn a mapping function that transforms high-dimensional vectors into compact binary codes. This mapping function aims to preserve the similarity relationships between the original vectors.
Binary Code Generation
Once the neural network is trained, it is used to generate binary codes for the vectors in the dataset. Each vector is encoded as a binary code, where each bit represents a specific feature or characteristic of the vector.
Similarity Search
During the similarity search phase, the binary codes are compared instead of the original high-dimensional vectors. This enables efficient search operations, as comparing binary codes is computationally inexpensive compared to comparing high-dimensional vectors.
Neural hashing offers improved efficiency by reducing the dimensionality of data with compact binary codes, enhancing scalability for large-scale datasets. It ensures accurate similarity preservation by capturing underlying similarities through neural networks, facilitating precise similarity searches.
The technique enables compact storage, reducing storage requirements for more efficient data retrieval. With flexibility in trade-offs, users can adjust binary code length to balance search accuracy and computational efficiency. Neural hashing is adaptable to various domains, such as text and images, making it versatile for different applications.

How Vector Similarity Search can be used in Computer Vision
Vector similarity search is crucial in various computer vision applications, enabling efficient object detection, recognition, and retrieval. By representing images as high-dimensional feature vectors, vector similarity search algorithms can locate similar images in large datasets, leading to several practical benefits.
Object Detection
Vector similarity search can aid in object detection by finding similar images that contain objects of interest. For example, a system can use pre-trained deep-learning models to extract feature vectors from images. These vectors can then be indexed using vector similarity search techniques. During runtime, when a new image is provided, its feature vector is compared to the indexed vectors to identify images with similar objects. This can assist in detecting objects in real-time and supporting applications like visual search.
💡Read our guide on object detection and its use cases to find out more. Image Retrieval
Vector similarity search allows for efficient content-based image retrieval. By converting images into high-dimensional feature vectors, images with similar visual content can be identified quickly. This is particularly useful in applications such as reverse image search, where users input an image and retrieve visually similar images from a database. It enables applications like image search engines, product recommendations based on images, and image clustering for organizations.
Image Recognition
Vector similarity search facilitates image recognition tasks by comparing feature vectors of input images with indexed vectors of known images. This aids in tasks like image classification and image similarity ranking.
For example, in image recognition systems, a query image's feature vector is compared to the indexed vectors of known classes or images to identify the most similar class or image. This approach is employed in applications like face recognition, scene recognition, and image categorization.
Image Segmentation
Vector similarity search can assist in image segmentation tasks, where the goal is to partition an image into meaningful regions or objects. Similar regions can be grouped by comparing feature vectors of image patches or superpixels. This aids in identifying boundaries between objects or determining regions with similar visual characteristics, supporting tasks like object segmentation and image annotation.

Vector Similarity Search Summary
Vector similarity search is a vital technique in machine learning used to find similar data points in high-dimensional spaces. It is crucial for recommendation systems, image and video search, NLP, clustering, and more. Challenges include high-dimensional data, scalability, choice of a distance metric, and storage requirements.
Solutions involve dimensionality reduction, indexing structures, adaptive distance metrics, and neural hashing. In computer vision, vector similarity search is used for object detection, image retrieval, recognition, and segmentation. It enables efficient retrieval, faster detection, and accurate recognition. Mastering vector similarity search is essential for enhancing machine learning applications and improving user experiences.
Key Takeaways
- Vector similarity search is essential for numerous machine learning applications, enabling accurate and efficient data analysis.
- Overcoming challenges like high-dimensional data and scalability require techniques such as dimensionality reduction and indexing structures.
- Adaptive distance metrics and approximate nearest-neighbor algorithms can enhance search accuracy and efficiency.
- In computer vision, vector similarity search aids in object detection, image retrieval, recognition, and segmentation, enabling advanced visual understanding and interpretation.
Ready to automate and improve the quality, speed, and accuracy of your computer vision projects?
Sign-up for an Encord Free Trial: The Active Learning Platform for Computer Vision, used by the world’s leading computer vision teams.
AI-assisted labeling, model training & diagnostics, find & fix dataset errors and biases, all in one collaborative active learning platform, to get to production AI faster. Try Encord for Free Today.
Want to stay updated?
- Follow us on Twitter and LinkedIn for more content on computer vision, training data, and active learning.
- Join our Discord channel to chat and connect.
Frequently asked questions
Encord's similarity search feature allows users to find related items in a dataset by identifying duplicates or similar assets. This feature enhances the efficiency of data management by enabling users to group similar annotations and streamline their workflow.
The similarity search feature in Encord enables users to identify the same person entering or leaving a store. This functionality is particularly valuable for retailers aiming to track customer behavior and enhance security measures in their establishments.
Similarity search in Encord enables users to append multiple images to filter and explore relevant cases for specific classes. This feature is essential for identifying edge cases and improving the accuracy of labels through targeted review.
The similarity search feature in Encord allows users to find images similar to a selected sample. This functionality helps teams to adapt models to specific environments by easily identifying and gathering relevant data points for training.
Encord allows users to conduct similarity searches using an embedding-based approach. This feature enables users to find and group images based on visual similarity, such as identifying frames that include hands or other specific features.