Introduction to Semantic Segmentation

Product Manager at Encord
In this article, we delve into the technologies driving this innovation, exploring advanced architectures like U-Net and DeepLab, popular datasets, and real-world applications. Learn how these models enable machines to understand visual data at the pixel level, creating opportunities for automation and efficiency.
The computer vision market is rapidly growing, driven by the demand for automation, autonomous vehicles, and innovation in manufacturing and medicine, studies show.
While the applications are widespread, computer vision algorithms essentially aim to extract vital information from images and videos. One such task is semantic segmentation which provides granular information about various entities in an image. Before moving forward, let’s briefly walk through image segmentation in general.
What is Image Segmentation?
Image segmentation models allow machines to understand visual information from images. These models are trained to produce segmentation masks for the recognition and localization of different entities present in images. These models work similarly to object detection models, but image segmentation identifies objects on a pixel level instead of drawing bounding boxes.
There are three sub-categories for image segmentation tasks
- Instance Segmentation
- Semantic Segmentation
- Panoptic Segmentation

Benchmarking Deep Learning Models for Instance Segmentation
Semantic segmentation classifies all related pixels to a single cluster without regard for independent entities. Instance segmentation identifies ‘discrete’ items such as cars and people but provides no information for continuous items such as the sky or a long grass field. Panoptic segmentation combines these two algorithms to present a unified picture of discrete objects and background entities.
This article will explain semantic segmentation in detail and explore its various implementations and use cases.
Understanding Semantic Segmentation
Semantic segmentation models borrow the concept of image classification models and improve upon them. Instead of labeling entire images, the segmentation model labels each pixel to a pre-defined class. All pixels associated with the same class are grouped together to create a segmentation mask. Working on a granular level, these models can accurately classify objects and draw precise boundaries for localization.
A semantic model takes an input image and passes it through a complex neural network architecture. The output is a colorized feature map of the image, with each pixel color representing a different class label for various objects. These spatial features allow computers to distinguish between the items, separate focus objects from the background, and allow robotic automation of tasks.
Data Collection
Datasets for a segmentation problem consist of pixel values representing masks for different objects and their corresponding class labels. Compared to other machine learning problems, segmentation datasets are usually more extensive and complex.
They consist of tens of different classes and thousands of annotations for each class. The many labels improve diversity within the dataset and help the model learn better . Having diverse data is important for segmentation models since they are sensitive to object shape, color, and orientation.
Popular segmentation datasets include:
- Pascal Visual Object Classes (VOC): The dataset was used as a benchmark in the Pascal VOC challenge until 2012. It contains annotations that include object classes, bounding boxes for detection, and segmentation maps. The last iteration of the data, Pascal VOC 2012, included a total of 11,540 images with annotations for 20 different object classes.
- MS COCO: COCO is a popular computer vision dataset that contains over 330,000 images with annotations for various tasks, including object detection, semantic segmentation, and image captioning. The ground truths comprise 80 object categories and up to 5 written descriptions for each image.
Cityscapes: The Cityscapes dataset specializes in segmenting urban city scenes. It comprises 5,000 finely segmented real-world images and 20,000 coarse annotations with rough polygonal boundaries. The dataset contains 30 class labels captured in diverse conditions, such as different weather conditions across several months.
Moreover, a well-trained segmentation model requires a complex architecture. Let’s take a look at how these models work under the hood.
Deep Learning Implementations of Semantic Segmentation
Most modern, state-of-the-art architectures consist of convolutional neural network (CNN) blocks for image processing. These neural network architectures can extract vital information from spatial features for classifying and segmenting objects. Some popular networks are mentioned below.
Fully Convolutional Network
A fully convolutional network (FCN) was introduced in 2014 and displayed ground-breaking results for semantic image segmentation. It is essentially a modified version of the traditional CNN architecture used for classification tasks. The traditional architectures consist of convolutional layers followed by dense (flattened) layers that output a single label to classify the image.
The FCN architecture starts with the usual CNN modules for information extraction. The first half of the network consists of well-known architecture such as VGG or RESNET. However, the second half replaces the dense layers with 1x1 convolutional blocks. The additional convolution blocks continue to extract image features while maintaining location information.
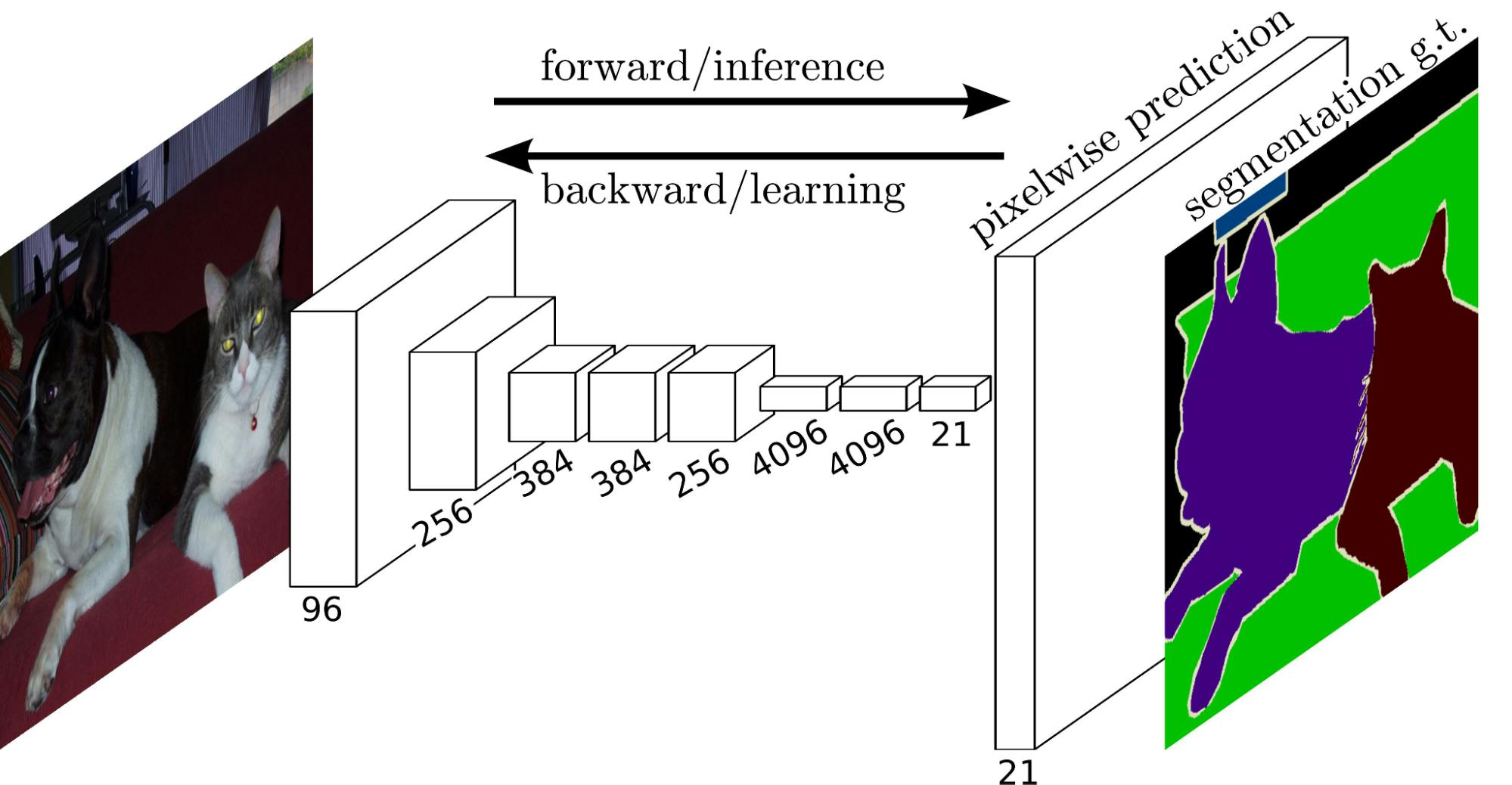
Fully Convolutional Networks for Semantic Segmentation
Upsampling
As the network gets deeper with convolutional layers, the original image is reduced, resulting in the loss of spatial information. The deeper the network gets, the less pixel-level information we have left.
The authors implement a deconvolution layer at the very end to solve this. The deconvolution layer upsamples the feature map to the shape of the original image. The resulting image is a feature map representing various segments in the input image.
Skip-Connections
The architecture still faces one major flaw. The final layer has to upsample by a factor of 32, resulting in a poorly segmented final layer output. The low-resolution problem is solved by connecting the prior max-pooling layers to the final output using skip connections.
Each pooling layer output is independently upsampled to combine with prior features passed on to the last layer. This way, the deconvolution operation is performed in steps, and the final output only requires 8x sampling to represent the image better.
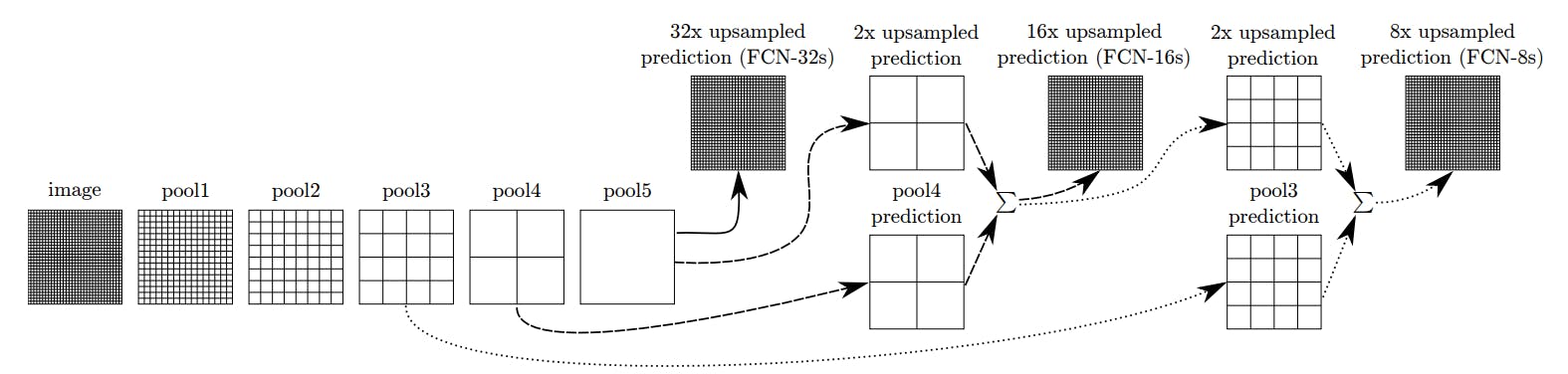
Fully Convolutional Networks for Semantic Segmentation
U-Net
Similarly to FCN, the U-Net architecture is based on the encoder-decoder model. It borrows concepts like the skip connection from FCN and improves upon them for better results.
This popular architecture was introduced in 2015 as a specialized model for medical image segmentation tasks. It won the ISBI cell tracking challenge 2015, beating the sliding window technique with fewer training images and better performance overall.
The U-Net architecture consists of two portions; the encoder (first half) and the decoder (second half). The former consists of stacked convolutional layers that down-sample the input image, extracting vital information, while the latter reconstructs the features using deconvolution.
The two layers serve two different purposes. The encoder extracts information regarding the entities in the image, and the decoder localizes the multiple entities. The architecture also includes skip connections that pass information between corresponding encoder-decoder blocks.
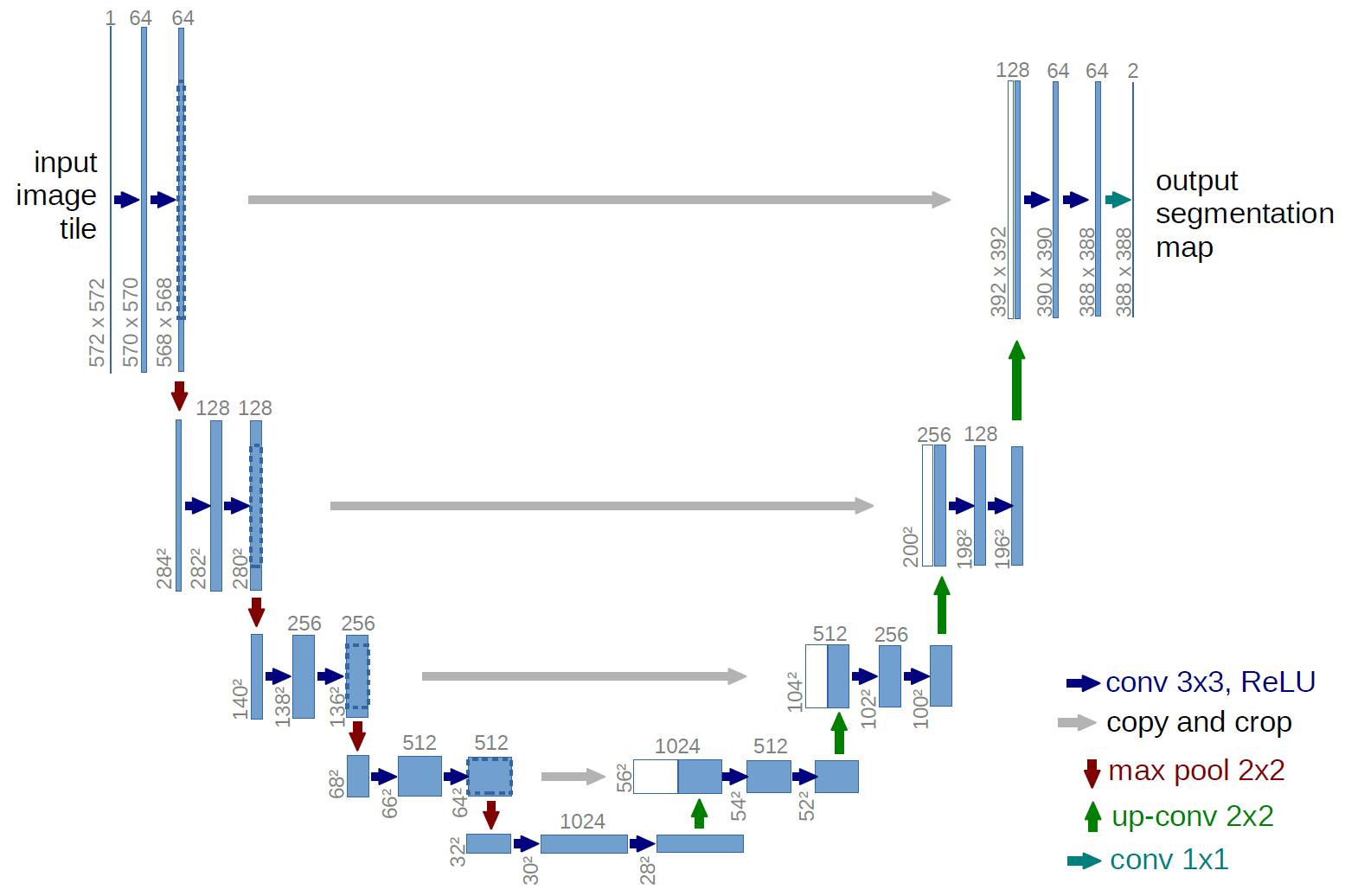
U-Net: Convolutional Networks for Biomedical Image Segmentation
Moreover, the U-Net architecture has seen various overhauls over the past years. The many U-Net variations improve upon the original architecture to improve system efficiency and performance. Some improvements include using popular CNN models like VGG for the descending layer or post-processing techniques for result improvements.
DeepLab
DeepLab is a set of segmentation models inspired by the original FCN architecture but with variations to solve its shortcomings.
An FCN model has stacks of CNN layers that reduce the image dimension significantly. The feature space is reconstructed using deconvolution operations, but the result is not precise due to insufficient information.
DeepLab utilizes Atrous convolution to solve the feature resolution problem. The Atrous convolution kernels extract wider information from images by leaving gaps between subsequent kernel parameters.
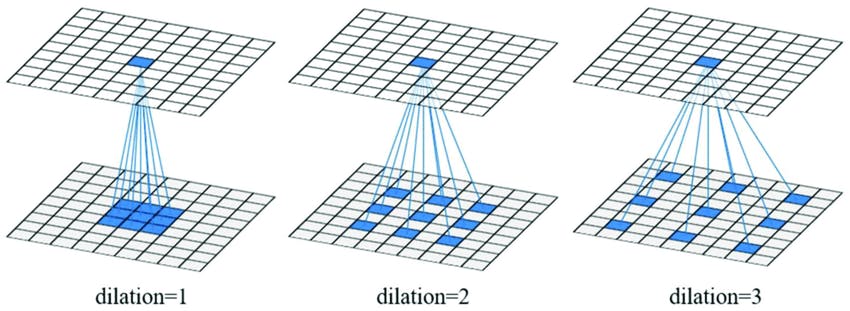
This form of dilated convolution extracts information from a larger field of view without any computational overhead.
Moreover, having a larger field of view maintains the feature space resolution while extracting all the key details.
The feature space passes through bi-linear interpolation and a fully connected conditional random field algorithm (CRF). These layers capture the fine details used for the pixel-wise loss function to make the segmentation mask crisper and more precise.
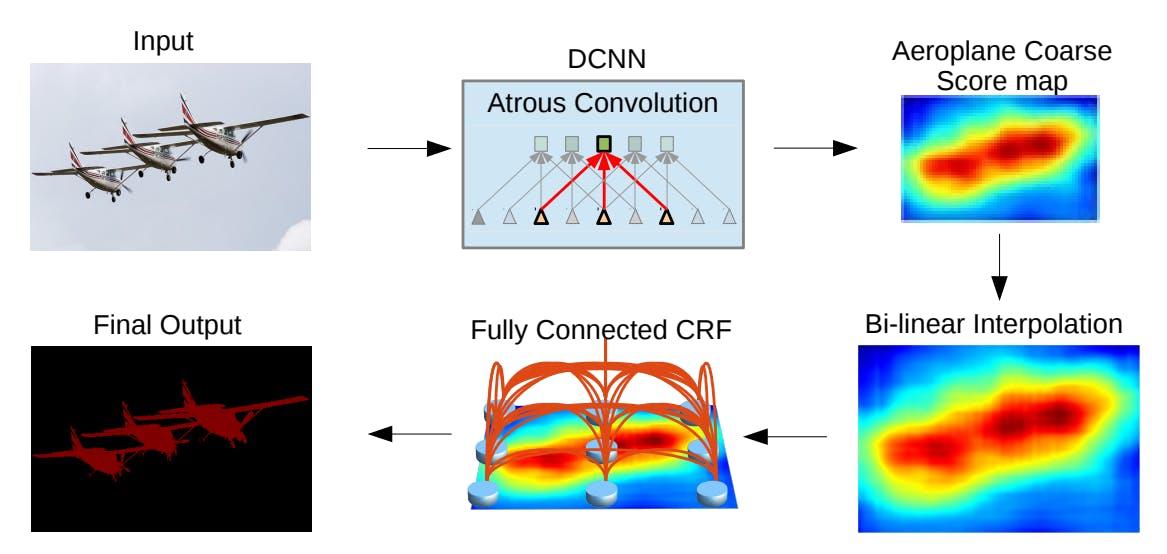
Multi-Scale Object Detection
Another challenge for the dilated convolution technique is capturing objects at different scales. The width of the Atrous convolution kernel defines what scale object it will most likely capture. The solution is to use Atrous Spatial Pyramid Pooling (ASPP). With pyramid pooling, multiple convolution kernels are used with different widths. The results from these variants and fused to capture details from multiple scales.
Pyramid Scene Parsing Network (PSPNet)
PSPNet is a well-known segmentation algorithm introduced in 2017. It uses a pyramid parsing module to capture contextual information from images. The network yields a mean intersection-over-union (mIoU) accuracy of 85.4% on PASCAL VOC 2012 and 80.2% accuracy on the Cityscapes dataset.
The network follows an encoder-decoder architecture. The former consists of dilated convolution blocks and the pyramid pooling layer, while the latter applies upscaling to generate pixel-level predictions. The overall architecture is similar to other segmentation techniques by adding the new pyramid pooling layer.
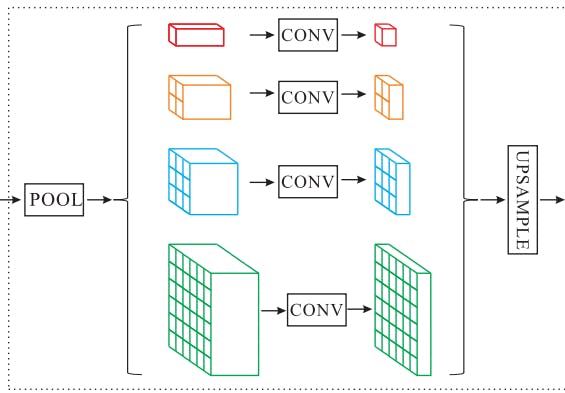
The pyramid module helps the architecture capture global contextual information from the image. The output for the CNN encoders is pooled and various scales and further passed through convolution layers. The convolved features are finally upscaled to the same size and concatenated for decoding. The multi-scale pooling allows the model to gather information from a wide window and aggregate the overall context.
Applications of Semantic Segmentation
Semantic segmentation has various valuable applications across various industries.
Medical Imaging
Many medical procedures involve strict inference of imaging data such as CT scans, X-rays, or MRI scans. Traditionally, a medical expert would analyze these images to decide whether an anomaly is present. Segmentation models can achieve similar results.
Semantic segmentation can draw precise object boundaries between the various elements in a radiology scan. These boundaries are used to detect anomalies such as cancer cells and tumors. These results can further be integrated into automated pipelines for auto-diagnosis, prescriptions, or other medical suggestions.
However, since medicine is a critical field, many users are skeptical of robot practitioners. The delicacy of the domain and lack of ethical guidelines have hindered the adoption of AI into real-time medical systems. Still, many healthcare providers use AI tools for reassurance and a second opinion.
Autonomous Vehicles
Self-driving cars rely on computer vision to understand the world around them and take appropriate actions. Semantic segmentation divides the vision of the car into objects like roads, pedestrians, trees, animals, cars, etc. This knowledge helps the vehicle’s system to engage in driving actions like steering to stay on the road, avoid hitting pedestrians, and braking when another vehicle is detected nearby.
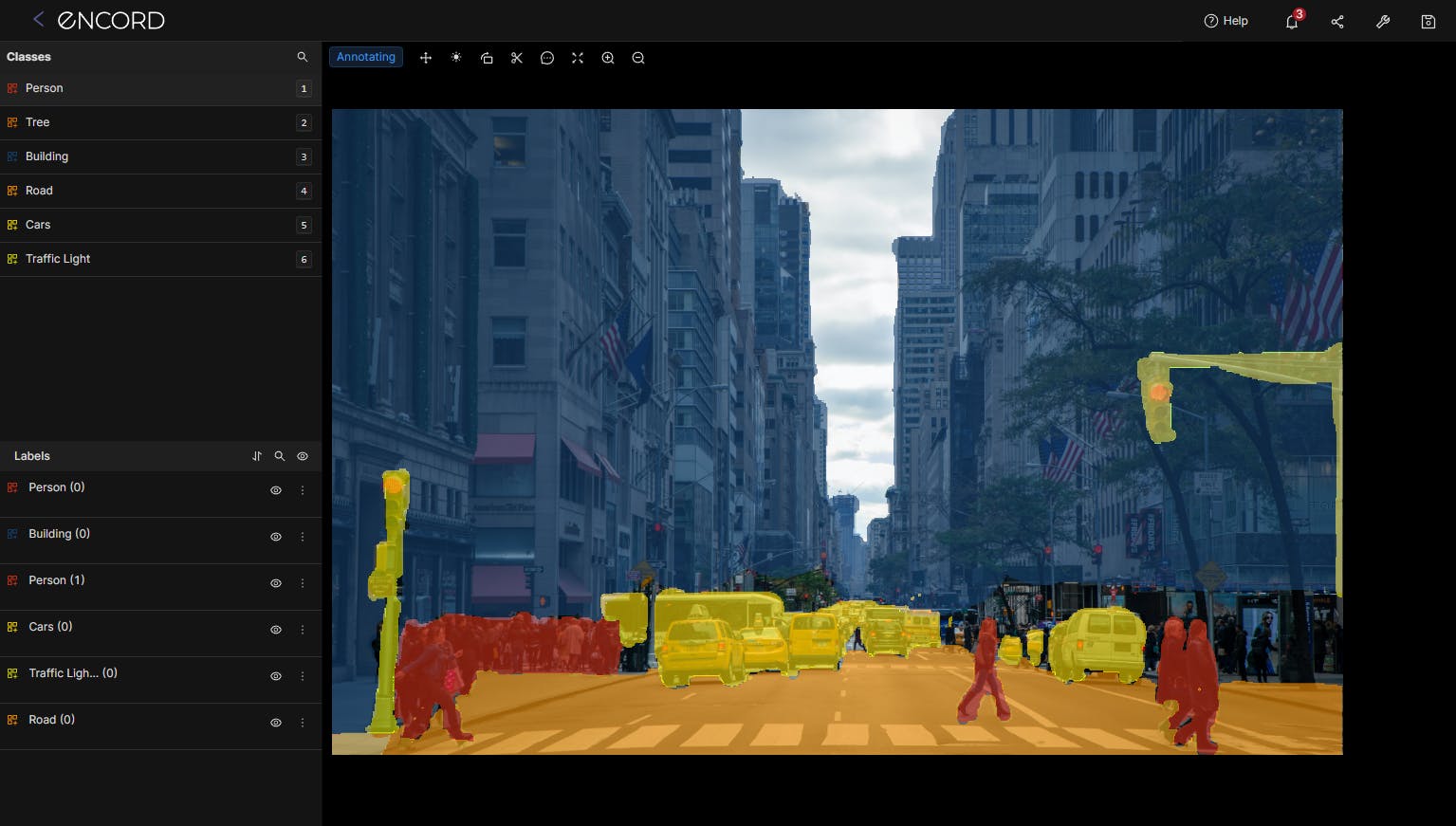
What an Autonomous Vehicle Sees
Agriculture
Segmentation models are used in agriculture to detect bad crops and pests. Vision-based algorithms learn to detect infestations and diseases in crops. Integrating digital twin technology in agriculture complements these advanced segmentation models, providing a comprehensive and dynamic view of agricultural systems to enhance crop management and yield predictions. The automated system is further programmed to alert the farmer to the precise location of the anomaly or trigger pesticides to prevent damage.
Picture Processing
A common application of semantic segmentation is with image processing. Modern smart cameras have features like portrait mode, augmented filters, and facial feature manipulation. All these neat tricks have segmentation models at the core that detect faces, facial features, image background, and foreground to apply all the necessary processing.
Drawbacks of Semantic Segmentation
Despite its various applications, semantic segmentation has drawbacks that limit its applications in real-world scenarios.
Even though it predicts a class label for each pixel, it cannot distinguish between different instances of the same object. For example, if we use an image of a crowd, the model will recognize pixels associated with humans but will not know where a person stands.
This is more troublesome with overlapping objects since the model creates a unified mask without clear instance boundaries. Hence the model cannot be used in certain situations, such as counting the number of objects present. Panoptic segmentation solves this problem by combining semantic and instance segmentation to provide more information regarding the image.
Accelerate Segmentation With Encord
Semantic segmentation plays a vital role in computer vision, but manual annotation is time-consuming. Encord transforms the labeling process, empowering users to efficiently manage and train annotation teams through customizable workflows and robust quality control.
Semantic Segmentation: Key Takeaways
- Image Segmentation recognizes different entities in an image and draws precise boundaries for localization.
- There are three types of segmentation techniques: semantic segmentation, instance Segmentation, and panoptic Segmentation.
- Semantic segmentation predicts a class label for every pixel present in an image, resulting in a detailed segmentation map.
- FCN, DeepLab, and U-Net are popular segmentation architectures that extract information from different variations of CNN and pooling blocks.
- Semantic segmentation is used in everyday tasks such as autonomous vehicles, agriculture, medical imaging, and image manipulation.
- A drawback of semantic segmentation is its inability to distinguish between different occurrences of the same object. Most developers utilize panoptic segmentation to tackle this problem.
Frequently asked questions
Semantic segmentation processes each pixel in an image and associates it with a class label. Pixels of the same class form a segmentation mask for that class. Multiple masks combined together form a semantically segmented image.
The most common metrics to score a semantic segmentation model are Pixel Accuracy, Intersection-over-Union, and Dice Coefficient.
Semantic and pixel-wise segmentation are essentially the same since semantic segmentation processes each pixel to predict a class.
Datasets for semantic segmentation consist of images and their corresponding segmentation masks, which are the ground truth labels. The segmentation mask consists of class label and pixels associated with it.
Encord employs sophisticated AI algorithms that are trained on diverse datasets to provide highly accurate segmentation models. Users can evaluate the performance of different models within the platform to determine which best meets their specific accuracy requirements.
Yes, Encord supports collaborative lesion segmentation labeling, allowing teams to work together effectively on annotation tasks. This feature is part of our comprehensive toolset designed for professionals in regulated fields.
Yes, Encord supports semantic segmentation, allowing users to have labels where each pixel in an image corresponds to a class ID. This functionality is crucial for detailed image analysis and annotation tasks.
Encord currently supports various annotation types including bounding boxes, polygon annotations, and semantic segmentation for images and videos. However, it does not support lidar annotations at this time.