Full Guide to Contrastive Learning

Product Manager at Encord
Contrastive learning allows models to extract meaningful representations from unlabeled data.
By leveraging similarity and dissimilarity, contrastive learning enables models to map similar instances close together in a latent space while pushing apart those that are dissimilar.
This approach has proven to be effective across diverse domains, spanning computer vision, natural language processing (NLP), and reinforcement learning.
What is Contrastive Learning?
Contrastive learning is an approach that focuses on extracting meaningful representations by contrasting positive and negative pairs of instances. It leverages the assumption that similar instances should be closer in a learned embedding space while dissimilar instances should be farther apart. By framing learning as a discrimination task, contrastive learning allows models to capture relevant features and similarities in the data.
Supervised Contrastive Learning (SCL)
Supervised contrastive learning (SCL) is a branch that uses labeled data to train models explicitly to differentiate between similar and dissimilar instances. In SCL, the model is trained on pairs of data points and their labels, indicating whether the data points are similar or dissimilar. The objective is to learn a representation space where similar instances are clustered closer together, while dissimilar instances are pushed apart.
The Information Noise Contrastive Estimation (InfoNCE) loss function is a popular method. InfoNCE loss maximizes the agreement between positive samples and minimizes the agreement between negative samples in the learned representation space. By optimizing this objective, the model learns to discriminate between similar and dissimilar instances, leading to improved performance on downstream tasks.
We will discuss the InfoNCe loss and other losses later in the article.
Self-Supervised Contrastive Learning (SSCL)
Self-supervised contrastive learning (SSCL) takes a different approach by learning representations from unlabeled data without relying on explicit labels. SSCL leverages the design of pretext tasks, which create positive and negative pairs from the unlabeled data. These pretext tasks are carefully designed to encourage the model to capture meaningful features and similarities in the data.
One commonly used pretext task in SSCL is the generation of augmented views. This involves creating multiple augmented versions of the same instance and treating them as positive pairs, while instances from different samples are treated as negative pairs. Training the model to differentiate between these pairs, it learns to capture higher-level semantic information and generalize well to downstream tasks.
SSCL has shown impressive results in various domains, including computer vision and natural language processing. In computer vision, SSCL has been successful in tasks such as image classification, object detection, and image generation. SSCL has been applied to tasks like sentence representation learning, text classification, and machine translation in natural language processing.

Supervised Contrastive Learning
How does Contrastive Learning Work?
Contrastive learning has proven a powerful technique, allowing models to leverage large amounts of unlabeled data and improve performance even with limited labeled data. The fundamental idea behind contrastive learning is to encourage similar instances to be mapped closer together in a learned embedding space while pushing dissimilar instances farther apart. By framing learning as a discrimination task, contrastive learning allows models to capture relevant features and similarities in the data.
Now, let's dive into each step of the contrastive learning method to gain a deeper understanding of how it works.
Data Augmentation
Contrastive learning often begins with data augmentation, which involves applying various transformations or perturbations to unlabeled data to create diverse instances or augmented views.
Data augmentation aims to increase the data's variability and expose the model to different perspectives of the same instance. Common data augmentation techniques include cropping, flipping, rotation, random crop, and color transformations. By generating diverse instances, contrastive learning ensures that the model learns to capture relevant information regardless of variations in the input data.

The Full Guide to Data Augmentation in Computer Vision
Encoder Network
The next step in contrastive learning is training an encoder network. The encoder network takes the augmented instances as input and maps them to a latent representation space, where meaningful features and similarities are captured.
The encoder network is typically a deep neural network architecture, such as a convolutional neural network (CNN) for image data or a recurrent neural network (RNN) for sequential data. The network learns to extract and encode high-level representations from the augmented instances, facilitating the discrimination between similar and dissimilar instances in the subsequent steps.
Projection Network
A projection network is employed to refine the learned representations further. The projection network takes the output of the encoder network and projects it onto a lower-dimensional space, often referred to as the projection or embedding space.
This additional projection step helps enhance the discriminative power of the learned representations. By mapping the representations to a lower-dimensional space, the projection network reduces the complexity and redundancy in the data, facilitating better separation between similar and dissimilar instances.
Contrastive Learning
Once the augmented instances are encoded and projected into the embedding space, the contrastive learning objective is applied. The objective is to maximize the agreement between positive pairs (instances from the same sample) and minimize the agreement between negative pairs (instances from different samples).
This encourages the model to pull similar instances closer together while pushing dissimilar instances apart. The similarity between instances is typically measured using a distance metric, such as Euclidean distance or cosine similarity. The model is trained to minimize the distance between positive pairs and maximize the distance between negative pairs in the embedding space.
 💡 To learn more about embeddings, read The Full Guide to Embeddings in Machine Learning.
💡 To learn more about embeddings, read The Full Guide to Embeddings in Machine Learning. Loss Function
Contrastive learning utilizes a variety of loss functions to establish the objectives of the learning process. These loss functions are crucial in guiding the model to capture significant representations and differentiate between similar and dissimilar instances.
The selection of the appropriate loss function depends on the specific task requirements and data characteristics. Each loss function aims to facilitate learning representations that effectively capture meaningful similarities and differences within the data. In a later section, we will detail these loss functions.
Training and Optimization
Once the loss function is defined, the model is trained using a large unlabeled dataset. The training process involves iteratively updating the model's parameters to minimize the loss function.
Optimization algorithms such as stochastic gradient descent (SGD) or its variants are commonly used to fine-tune the model's hyperparameters. The training process typically involves batch-wise updates, where a subset of augmented instances is processed simultaneously.
During training, the model learns to capture the relevant features and similarities in the data. The iterative optimization process gradually refines the learned representations, leading to better discrimination and separation between similar and dissimilar instances.
Evaluation and Generalization
Evaluation and generalization are crucial steps to assess the quality of the learned representations and their effectiveness in practical applications.
Downstream Task Evaluation

Image Classification vs Object Detection vs Image Segmentation
The ultimate measure of success for contrastive learning is its performance on downstream tasks. The learned representations are input features for tasks such as image classification, object detection, sentiment analysis, or language translation.
The model's performance on these tasks is evaluated using appropriate metrics, including accuracy, precision, recall, F1 score, or task-specific evaluation criteria. Higher performance on the downstream tasks indicates better generalization and usefulness of the learned representations.
💡 Read the blog How to Measure Model Performance in Computer Vision: A Comprehensive Guide to understand how to measure the model performance of deep learning models. Transfer Learning
Contrastive learning enables transfer learning, where the presentation of learned representations from one task can be applied to related tasks. Generalization is evaluated by assessing how well the representations transfer to new tasks or datasets. If the learned representations generalize well to unseen data and improve performance on new tasks, it indicates the effectiveness of contrastive learning in capturing meaningful features and similarities.

Is Transfer Learning the final step for enabling AI in Aviation?
Comparison with Baselines
To understand the effectiveness of contrastive learning, comparing the learned representations with baseline models or other state-of-the-art approaches is essential. Comparisons can be made regarding performance metrics, robustness, transfer learning capabilities, or computational efficiency. Such comparisons provide insights into the added value of contrastive learning and its potential advantages over alternative methods.
After understanding how contrastive learning works, let's explore an essential aspect of this learning technique: the choice and role of loss functions.
Loss Functions in Contrastive Learning
In contrastive learning, various loss functions are employed to define the objectives of the learning process. These loss functions guide the model in capturing meaningful representations and discriminating between similar and dissimilar instances. By understanding the different loss functions used in contrastive learning, we can gain insights into how they contribute to the learning process and enhance the model's ability to capture relevant features and similarities within the data.
Contrastive Loss
Contrastive loss is a fundamental loss function in contrastive learning. It aims to maximize the agreement between positive pairs (instances from the same sample) and minimize the agreement between negative pairs (instances from different samples) in the learned embedding space. The goal is to pull similar instances closer together while pushing dissimilar instances apart.
The contrastive loss function is typically defined as a margin-based loss, where the similarity between instances is measured using a distance metric, such as Euclidean distance or cosine similarity. The contrastive loss is computed by penalizing positive samples for being far apart and negative samples for being too close in the embedding space.
One widely used variant of contrastive loss is the InfoNCE loss, which we will discuss in more detail shortly. Contrastive loss has shown effectiveness in various domains, including computer vision and natural language processing, as it encourages the model to learn discriminative representations that capture meaningful similarities and differences.
Triplet Loss
Triplet loss is another popular loss function employed in contrastive learning. It aims to preserve the relative distances between instances in the learned representation space. Triplet loss involves forming triplets of instances: an anchor instance, a positive sample (similar to the anchor), and a negative sample (dissimilar to the anchor). The objective is to ensure that the distance between the anchor and the positive sample is smaller than the distance between the anchor and the negative sample by a specified margin.

FaceNet: A Unified Embedding for Face Recognition and Clustering
The intuition behind triplet loss is to create a "triplet constraint" where the anchor instance is pulled closer to the positive sample while being pushed away from the negative sample. The model can better discriminate between similar and dissimilar instances by learning representations that satisfy the triplet constraint.
Triplet loss has been widely applied in computer vision tasks, such as face recognition and image retrieval, where capturing fine-grained similarities is crucial. However, triplet loss can be sensitive to the selection of triplets, as choosing informative triplets from a large dataset can be challenging and computationally expensive.
N-pair Loss
N-pair loss is an extension of triplet loss that considers multiple positive and negative samples for a given anchor instance. Rather than comparing an anchor instance to a single positive and negative sample, N-pair loss aims to maximize the similarity between the anchor and all positive instances while minimizing the similarity between the anchor and all negative instances.

Improved Deep Metric Learning with Multi-class N-pair Loss Objective
The N-pair loss encourages the model to capture nuanced relationships among multiple instances, providing more robust supervision during learning. By considering multiple instances simultaneously, N-pair loss can capture more complex patterns and improve the discriminative power of the learned representations.
N-pair loss has been successfully employed in various tasks, such as fine-grained image recognition, where capturing subtle differences among similar instances is essential. It alleviates some of the challenges associated with triplet loss by leveraging multiple positive and negative instances, but it can still be computationally demanding when dealing with large datasets.
InfoNCE
Information Noise Contrastive Estimation (InfoNCE) loss is derived from the framework of noise contrastive estimation. It measures the similarity between positive and negative pairs in the learned embedding space. InfoNCE loss maximizes the agreement between positive pairs and minimizes the agreement between negative pairs.
The key idea behind InfoNCE loss is to treat the contrastive learning problem as a binary classifier. Given a positive pair and a set of negative pairs, the model is trained to discriminate between positive and negative instances. The similarity between instances is measured using a probabilistic approach, such as the softmax function.
InfoNCE loss is commonly used in self-supervised contrastive learning, where positive pairs are created from augmented views of the same instance, and negative pairs are formed using instances from different samples. By optimizing InfoNCE loss, the model learns to capture meaningful similarities and differences in the data points, acquiring powerful representations.
💡 InfoNCE was introduced in the paper Representation Learning with Contrastive Predictive Coding by Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Logistic Loss
Logistic loss, also known as logistic regression loss or cross-entropy loss, is a widely used loss function in machine learning. It has been adapted for contrastive learning as a probabilistic loss function. Logistic loss models the likelihood of two instances being similar or dissimilar based on their respective representations in the embedding space.
Logistic loss is commonly employed in contrastive learning to estimate the probability that two instances belong to the same class (similar) or different classes (dissimilar). By maximizing the likelihood of positive pairs being similar and minimizing the likelihood of negative pairs being similar, logistic loss guides the model toward effective discrimination.
The probabilistic nature of logistic loss makes it suitable for modeling complex relationships and capturing fine-grained differences between instances. Logistic loss has been successfully applied in various domains, including image recognition, text classification, and recommendation systems.
These different loss functions provide diverse ways to optimize the contrastive learning objective and encourage the model to learn representations that capture meaningful similarities and differences in the data points. The choice of loss function depends on the specific requirements of the task and the characteristics of the data.
By leveraging these objectives, contrastive learning enables models to learn powerful representations that facilitate better discrimination and generalization in various machine learning applications.
Contrastive Learning: Use Cases
Let's explore some prominent use cases where contrastive learning has proven to be effective:
Semi-Supervised Learning
Semi-supervised learning is a scenario where models are trained using labeled and unlabeled data. Obtaining labeled data can be costly and time-consuming in many real-world situations, while unlabeled data is abundant. Contrastive learning is particularly beneficial in semi-supervised learning as it allows models to leverage unlabeled data to learn meaningful representations.
By training on unlabeled data using contrastive learning, models can capture useful patterns and improve performance when labeled data is limited. Contrastive learning enables the model to learn discriminative representations that capture relevant features and similarities in the data. These learned representations can then enhance performance on downstream tasks, such as image classification, object recognition, speech recognition, and more.
Supervised Learning
Contrastive learning also has applications in traditional supervised learning scenarios with plentiful labeled data. In supervised learning, models are trained on labeled data to predict or classify new instances. However, labeled data may not always capture the full diversity and complexity of real-world instances, leading to challenges in generalization.
By leveraging unlabeled data alongside labeled data, contrastive learning can augment the learning process and improve the discriminative power of the model. The unlabeled data provides additional information and allows the model to capture more robust representations. This improves performance on various supervised learning tasks, such as image classification, sentiment analysis, recommendation systems, and more.
NLP
Contrastive learning has shown promising results in natural language processing (NLP). NLP deals with the processing and understanding human language, and contrastive learning has been applied to enhance various NLP tasks.
Contrastive learning enables models to capture semantic information and contextual relationships by learning representations from large amounts of unlabeled text data. This has been applied to tasks such as sentence similarity, text classification, language modeling, sentiment analysis, machine translation, and more.
For example, in sentence similarity tasks, contrastive learning allows models to learn representations that capture the semantic similarity between pairs of sentences. By leveraging the power of contrastive learning, models can better understand the meaning and context of sentences, facilitating more accurate and meaningful comparisons.
Data Augmentation
Augmentation involves applying various transformations or perturbations to unlabeled data to create diverse instances or augmented views. These augmented views serve as positive pairs during the contrastive learning, allowing the model to learn robust representations that capture relevant features.
Data augmentation techniques used in contrastive learning include cropping, flipping, rotation, color transformations, and more. By generating diverse instances, contrastive learning ensures that the model learns to capture relevant information regardless of variations in the input data.
Data augmentation plays a crucial role in combating data scarcity and addressing the limitations of labeled data. By effectively utilizing unlabeled data through contrastive learning and data augmentation, models can learn more generalized and robust representations, improving performance on various tasks, especially in computer vision domains.
Popular Contrastive Learning Frameworks
In recent years, several contrastive learning frameworks have gained prominence in deep learning due to their effectiveness in learning powerful representations. Let’s explore some popular contrastive learning frameworks that have garnered attention:
SimCLR
Simple Contrastive Learning of Representations (SimCLR) is a self-supervised contrastive learning framework that has garnered widespread recognition for its effectiveness in learning powerful representations. It builds upon the principles of contrastive learning by leveraging a combination of data augmentation, a carefully designed contrastive objective, and a symmetric neural network architecture.

Advancing Self-Supervised and Semi-Supervised Learning with SimCLR
The core idea of SimCLR is to maximize the agreement between augmented views of the same instance while minimizing the agreement between views from different instances. By doing so, SimCLR encourages the model to learn representations that capture meaningful similarities and differences in the data. The framework employs a large-batch training scheme to facilitate efficient and effective contrastive learning.
Additionally, SimCLR incorporates a specific normalization technique called "normalized temperature-scaled cross-entropy" (NT-Xent) loss, which enhances training stability and improves the quality of the learned representations.
SimCLR has demonstrated remarkable performance across various domains, including computer vision, natural language processing, and reinforcement learning. It outperforms prior methods in several benchmark datasets and tasks, showcasing its effectiveness in learning powerful representations without relying on explicit labels.
💡 SimCLR was introduced in the paper A Simple Framework for Contrastive Learning of Visual Representations by the authors from Google Research Ting Chen, Simon Kornblith, Mohammad Norouzi, Geoffrey Hinton. MoCo
Momentum Contrast (MoCo) is another prominent self-supervised contrastive learning framework that has garnered significant attention. It introduces the concept of a dynamic dictionary of negative instances, which helps the model capture meaningful features and similarities in the data. MoCo utilizes a momentum encoder, which gradually updates the representations of negative examples to enhance the model's ability to capture relevant information.
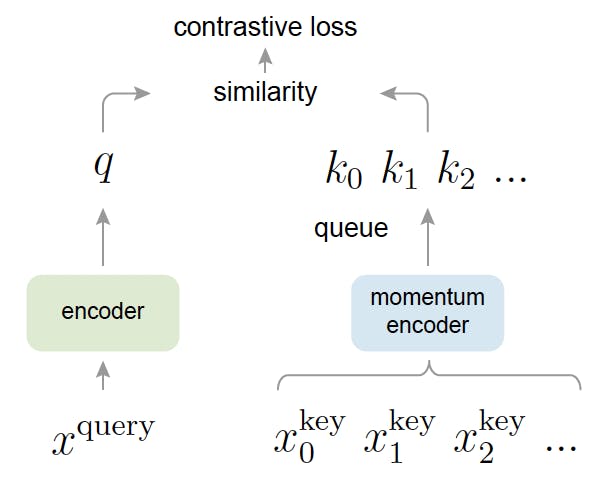
Momentum Contrast for Unsupervised Visual Representation Learning
The framework maximizes agreement between positive pairs while minimizing agreement between negative pairs. By maintaining a dynamic dictionary of negative instances, MoCo provides richer contrasting examples for learning representations. It has shown strong performance in various domains, including computer vision and natural language processing, and has achieved state-of-the-art results in multiple benchmark datasets.
💡 MoCo was introduced in the paper Momentum Contrast for Unsupervised Visual Representation Learning by the authors from Meta Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, Ross Girshick.
BYOL
Bootstrap Your Own Latent (BLOY) is a self-supervised contrastive learning framework that emphasizes the online updating of target network parameters. It employs a pair of online and target networks, with the target network updated through exponential moving averages of the online network's weights. BYOL focuses on learning representations without the need for negative examples.
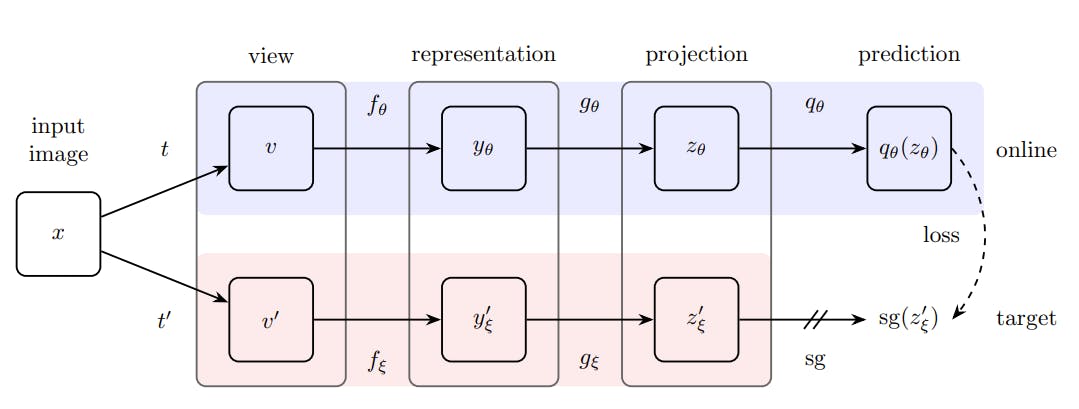
Bootstrap your own latent: A new approach to self-supervised Learning
The framework maximizes agreement between augmented views of the same instance while decoupling the similarity estimation from negative examples. BYOL has demonstrated impressive performance in various domains, including computer vision and natural language processing. It has shown significant gains in representation quality and achieved state-of-the-art results in multiple benchmark datasets.
💡 BYOL was introduced in the paper Bootstrap your own latent: A new approach to self-supervised Learning. SwAV
Swapped Augmentations and Views (SwAV) is a self-supervised contrastive learning framework that introduces clustering-based objectives to learn representations. It leverages multiple augmentations of the same image and multiple views within a mini-batch to encourage the model to assign similar representations to augmented views of the same instance.
Using clustering objectives, SwAV aims to identify clusters of similar representations without the need for explicit class labels. It has shown promising results in various computer vision tasks, including image classification and object detection, and has achieved competitive performance on several benchmark datasets.
💡 SwAV was introduced in the paper Unsupervised Learning of Visual Features by Contrasting Cluster Assignments. Barlow Twins
Barlow Twins is a self-supervised contrastive learning framework that reduces cross-correlation between latent representations. It introduces a decorrelation loss that explicitly encourages the model to produce diverse representations for similar instances, enhancing the overall discriminative power.
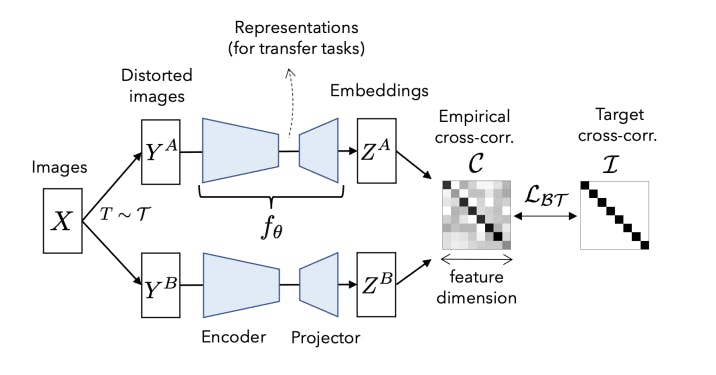
Barlow Twins: Self-Supervised Learning via Redundancy Reduction
Barlow Twins aims to capture more unique and informative features in the learned representations by reducing cross-correlation. The framework has demonstrated impressive performance in various domains, including computer vision and natural language processing, and has achieved state-of-the-art results in multiple benchmark datasets.
💡 Barlow Twins was introduced in the paper Barlow Twins: Self-Supervised Learning via Redundancy Reduction. By leveraging the principles of contrastive learning and incorporating innovative methodologies, these frameworks have paved the way for advancements in various domains, including computer vision, natural language processing, and reinforcement learning.
Contrastive Learning: Key Takeaways
- Contrastive learning is a powerful technique for learning meaningful representations from unlabeled data, leveraging similarity and dissimilarity to map instances in a latent space.
- It encompasses supervised contrastive learning (SSCL) with labeled data and self-supervised contrastive learning (SCL) with pretext tasks for unlabeled data.
- Important components include data augmentation, encoder, and projection networks, capturing relevant features and similarities.
- Common loss functions used in contrastive learning are contrastive loss, triplet loss, N-pair loss, InfoNCE loss, and logistic loss.
- Contrastive learning has diverse applications, such as semi-supervised learning, supervised learning, NLP, and data augmentation, and it improves model performance and generalization.

Frequently asked questions
Contrastive learning is a machine learning technique that aims to learn meaningful representations by contrasting positive and negative pairs of instances. It leverages the assumption that similar instances should be closer together in a learned embedding space, while dissimilar instances should be farther apart.
Contrastive learning differs from traditional supervised learning in that it doesn’t rely on explicit labels for training. Instead, it learns representations by contrasting positive and negative pairs of data points. This makescontrastive learning suitable for scenarios where labeled data is limited or unavailable.
Contrastive learning can be applied to various types of data, including images, text, audio, and other types of structured and unstructured data. As long as there are meaningful similarities and dissimilarities between instances, contrastive learning can be used to learn representations from the data.
Contrastive learning can be beneficial for small datasets because it leverages unlabeled data to enhance representation learning. By learning from a combination of labeled and unlabeled data, contrastive learning can help improve the model's generalization and performance on small datasets.
Yes, contrastive learning can be combined with other learning techniques to further enhance representation learning. For example, contrastive learning can be used in conjunction with transfer learning, where pre-trained representations from one task or domain are fine-tuned on a target task. This combination allows leveraging the benefits of both techniques for improved performance.
Encord offers comprehensive training materials and documentation to support users in navigating the platform effectively. After your initial setup, you will receive access to these resources, and you can also reach out via Slack or email for any specific inquiries.
Encord recognizes the importance of user interface preferences and offers multiple themes, including options for dark mode, to accommodate user comfort during annotation tasks. This flexibility can help reduce eye strain and improve overall user satisfaction.