Mastering Supervised Learning: A Comprehensive Guide

Product Manager at Encord
Artificial Intelligence (AI) has witnessed remarkable advancements in recent years, revolutionizing industries and reshaping how we interact with technology. At the core of these developments lies supervised learning, a fundamental concept in machine learning.
In this comprehensive guide, we will delve deep into the world of supervised learning, exploring its significance, processes, and various facets like its significance, training a model on labeled data, the relationship between input features and output labels, generalizing knowledge, and making accurate predictions.
By the end of this article, you'll have a firm grasp of what supervised learning is and how it can be applied to solve real-world problems.
Definition and Brief Explanation of Supervised Learning
Supervised Learning is a type of machine learning where algorithms learn from labeled data to make predictions. In simpler terms, it's like teaching a machine to recognize patterns or relationships in data based on the examples you provide. These examples, also known as training data, consist of input features and their corresponding target labels. The objective is to build a model to learn from this training data to make accurate predictions or classifications on new, unseen data.
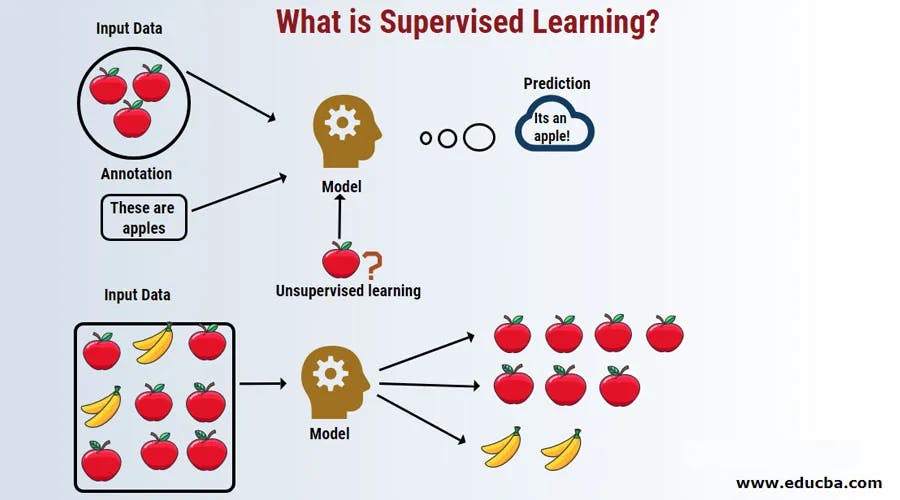
In machine learning, four main learning paradigms are commonly recognized: supervised, self-supervised, unsupervised, and reinforcement learning. As opposed to supervised learning, unsupervised learning deals with unlabeled data within a dataset; self-supervised learning is where the model learns from the data without explicit supervision or labeling; and in reinforcement learning, an agent learns to make decisions by interacting with an environment and receiving feedback in the form of rewards or punishments.
Importance and Relevance of Supervised Learning in AI
Supervised learning is the foundation of many AI applications that impact our daily lives, from spam email detection to recommendation systems on streaming platforms. From medical diagnosis to autonomous driving, supervised learning plays a pivotal role. Its ability to learn from historical data and make predictions makes it versatile for progress in AI.
As AI continues to evolve, supervised learning remains an indispensable part. It powers applications in natural language processing, computer vision, and speech recognition, making it vital for developing intelligent systems. Understanding how supervised learning works is essential for anyone interested in AI and machine learning.
Overview
This article can prove to be a beginner’s guide to supervised learning, and here we will take a structured approach to understanding supervised learning:
- What is Supervised Learning: We'll start by breaking down the basic concept of supervised learning and examining the critical components involved.
- Types of Supervised Learning Algorithms: We will explore the different supervised learning algorithms and their characteristics, including classification and regression. You’ll learn examples of popular algorithms within each category.
- Data Preparation for Supervised Learning: Labeled data is the lifeblood of supervised learning, and we'll discuss the essential steps involved in preparing and cleaning data. We will also explain feature engineering, a crucial aspect of data preparation.
- Model Evaluation and Validation: Once a model is trained, it must be evaluated and validated to ensure its accuracy and reliability. We'll delve into various evaluation metrics and techniques used in this phase.
- Challenges and Future Directions: We'll discuss some of the difficulties in supervised learning and glimpse into the future, considering emerging trends and areas of research.
- Key Takeaways: Finally, we’ll quickly go through the main ingredients of the whole recipe for supervised learning.
Now, let's embark on our journey to understand supervised learning.
What is Supervised Learning?
Supervised learning is a type of machine learning where an algorithm learns from labeled datasets to make predictions or decisions. It involves training a model on a dataset that contains input features and corresponding output labels, allowing the model to learn the relationship between the inputs and outputs.
Basic Concept
Supervised Learning operates under the assumption that there is a relationship or pattern hidden within the data that the model can learn and then apply to new, unseen data. In this context, "supervised" refers to providing guidance or supervision to the algorithm. Think of it as a teacher guiding a student through a textbook. The teacher knows the correct answers (the target labels), and the student learns by comparing their answers (predictions) to the teacher's.
Main Components: Input Features and Target Labels
To understand supervised learning fully, it's crucial to grasp the main components and processes involved. In supervised learning, labeled data is used to train a model, where each data point is associated with a corresponding target or output value.
The model learns from this labeled data to make predictions or classify new, unseen data accurately. Additionally, supervised learning requires the selection of an appropriate algorithm and the evaluation of the model's performance using metrics such as accuracy or precision. It's crucial to grasp the two main components:
- input features
- target labels.
Input Features: These are the variables or attributes that describe the data. For instance, in a spam email detection system, the input features might include the sender's email address, subject line, and the content of the email. The algorithm uses these features to make predictions.
Target Labels: Target labels are the values we want the algorithm to predict or classify. In the case of spam email detection, the target labels would be binary: “spam” (1) or “not spam” (0). These labels are provided as part of the training data.
 ⚡Learn more: The Full Guide to Training Datasets for Machine Learning.
⚡Learn more: The Full Guide to Training Datasets for Machine Learning. Training a Supervised Learning Model
Training a supervised learning model involves iteratively adjusting its parameters to minimize the difference between its predictions and the target values in the labeled data. This process is commonly known as optimization. During training, the model learns the underlying patterns and relationships in the data, allowing it to generalize and make accurate predictions on unseen data. However, it is important to note that the performance of a supervised learning model depends on the quality and representativeness of the labeled data used for training.
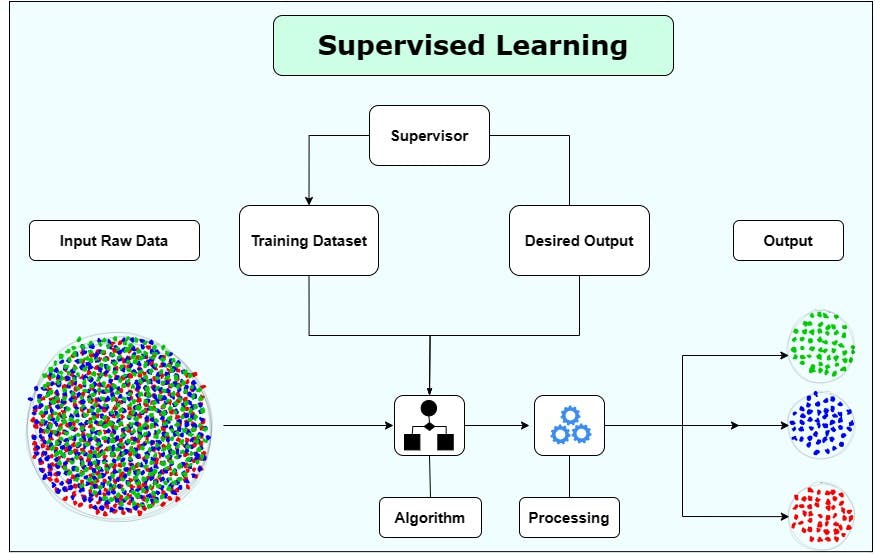
Training a supervised learning model involves several key steps:
- Data Collection: The first step is to gather labeled data, which typically consists of input features and their corresponding target labels. This data should be representative of the problem you want to solve.
- Data curation: The process of cleaning and organizing the collected data to ensure its quality and reliability. This step involves removing any outliers or inconsistencies, handling missing values, and transforming the data into a suitable format for training the model.
- Data Splitting: The collected data is usually divided into two subsets: the training dataset and the test data. Train the model with the training dataset, while the test data is reserved for evaluating its performance.
- Model Selection: Depending on the problem at hand, you choose an appropriate supervised learning algorithm. For example, if you're working on a classification task, you might opt for algorithms like logistic regression, support vector machines, or decision trees.
Training the Model: This step involves feeding the training data into the chosen algorithm, allowing the model to learn the patterns and relationships in the data. The training iteratively adjusts its parameters to minimize prediction errors with its learning techniques.
- Model Evaluation: After training, you evaluate the model's performance using the test set. Standard evaluation metrics include accuracy, precision, recall, and F1-score.
- Fine-tuning: If the model's performance is unsatisfactory, you may need to fine-tune its hyperparameters or consider more advanced algorithms. This step is crucial for improving the model's accuracy.
- Deployment: Once you're satisfied with the model's performance, you can deploy it to make predictions on new, unseen data in real-world applications.
Now that we've covered the fundamentals of supervised learning, let's explore the different types of supervised learning algorithms.

Types of Supervised Learning Algorithms
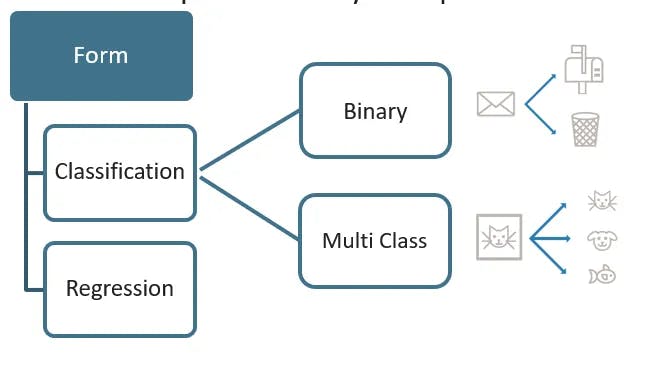
Types of supervised learning Algorithms include linear regression, logistic regression, decision trees, random forests, support vector machines, and neural networks. Each algorithm has its strengths and weaknesses, and the choice of algorithm depends on the specific problem and data at hand. It is also important to consider factors such as interpretability, computational efficiency, and scalability when selecting a supervised learning algorithm. Additionally, ensemble methods such as bagging and boosting can combine multiple models to improve prediction accuracy. Supervised learning can be categorized into two main types:
- Classification
- Regression
Each type has its own characteristics and is suited to specific use cases.
Supervised Learning Algorithms
Classification
Classification is a type of supervised learning where the goal is to assign data points to predefined categories or classes. In classification tasks, the target labels are discrete and represent different classes or groups. Naive Bayes is a classification algorithm commonly used in supervised learning. It is particularly useful for solving classification problems, spam email detection, and sentiment analysis, where it learns the probability of different classes based on the input features.
Here are some key points about classification:
- Binary Classification: In binary classification, there are only two possible classes, such as spam or not spam, fraud or not fraud, and so on.
- Multiclass Classification: Multiclass classification involves more than two classes. For example, classifying emails as spam, promotional, social, and primary.
- Examples of Classification Algorithms: Popular classification algorithms include logistic regression, support vector machines, decision trees, random forests, and neural networks.
- Use Cases: Classification is used in various applications, including sentiment analysis, image recognition, fraud detection, document categorization, and disease diagnosis.
Regression
Regression, on the other hand, is a type of supervised learning where the goal is to predict continuous values or numerical quantities. In regression tasks, the target labels are real numbers, and the model learns to map input features to a continuous output.
Here are some key points about regression:
- Examples of Regression Algorithms: Common regression algorithms include linear regression, polynomial regression, ridge regression, and support vector regression.
- Use Cases: Regression is applied in scenarios like stock price prediction, real estate price estimation, and weather forecasting, where the goal is to make numerical predictions.
Examples of Popular Algorithms Within Each Category
- Logistic Regression (Classification): Despite its name, logistic regression is used for binary classification. It models the probability of a data point belonging to one of the two classes, making it a fundamental algorithm in classification tasks.
- Decision Trees (Classification and Regression): Decision trees can be used for both classification and regression tasks. They break down a data set into smaller subsets based on input features and create a tree-like structure to make predictions.
- Linear Regression (Regression): Linear regression model is a simple yet powerful algorithm for regression tasks. It assumes a linear relationship between the input features and the target variable and tries to fit a straight line to the data.
- Random Forests (Classification and Regression): Random forests are an ensemble method that combines multiple decision trees to improve accuracy. They can be used for classification and regression problems and are known for their robustness.
Some data scientists use the K-Nearest Neighbors (KNN) and K-Means algorithms for data classification and regression. These algorithms enable applications like spam email detection and sales forecasting. KNN is typically associated with unsupervised learning but can also be used in supervised learning. Another algorithm that is used for both regression and classification problems is Support Vector Machines (SVM). SVM aims to create the best line or decision boundary to segregate n-dimensional space into classes.
Now that we've explored the types of supervised learning algorithms, let's move on to another stage of the workflow—data preparation.
Data Preprocessing for Supervised Learning
Data preprocessing is an essential step in supervised learning. It involves cleaning and transforming raw data into a format suitable for training a model. Common techniques used in data preprocessing include handling missing values, encoding categorical variables, and scaling numerical features. Additionally, you can perform feature selection or extraction to reduce the dimensionality of the dataset and likely improve model performance.

Data Preprocessing in Machine Learning
Data Cleaning
Data cleaning is a crucial part of data preprocessing. It involves removing or correcting any errors, inconsistencies, or outliers in the dataset. Data cleaning techniques include removing duplicate entries, correcting typos or spelling errors, and handling noisy or irrelevant data.
- Missing Data in datasets is a common issue that can be addressed through techniques like deleting missing rows, imputing values, or using advanced imputation methods, but the most appropriate method depends on the dataset and research objectives.
- Noisy Data containing errors or inconsistencies from measurement, data entry, or transmission can be addressed through techniques like smoothing, filtering, outlier detection, and removal methods.
{{grey_callout_start}}
Data cleaning is also known as data cleansing or data preprocessing. Learn more about data cleaning and preprocessing through our detailed guide.
{{grey_callout_end}}
Data Transformation
Data transformation is another technique commonly used to address noisy data. This involves converting the data into a different form or scale, such as logarithmic or exponential transformations, to make it more suitable for analysis. Another approach is to impute missing values using statistical methods, which can help fill in gaps in the data and reduce the impact of missing information on the analysis.
- Normalization standardizes the data range, allowing fair comparisons (considering the different units of variables) and reducing outliers, making it more robust and reliable for analysis when dealing with variables with different units or scales.
- Attribute Selection is a crucial step in selecting the most relevant and informative attributes from a dataset, reducing dimensionality, improving efficiency, avoiding overfitting, and enhancing interpretability.
- Discretization converts continuous variables into discrete categories or intervals, simplifying the analysis process and making results easier to interpret.
- Concept Hierarchy Generation sorts data into hierarchical structures based on connections and similarities. This helps us understand both discrete and continuous variables better. They also make it easier to interpret data and make decisions.
Data Reduction
Data reduction is a crucial technique in data analysis, reducing dataset complexity by transforming variables, simplifying the analysis process, improving computational efficiency, and removing redundant or irrelevant variables.
- Data Cube Aggregation summarizes data across multiple dimensions, providing a higher-level view for analysis. This technique aids in quick and efficient decision-making by analyzing large volumes of data.
- Attribute Subset Selection reduces data size, allowing you to focus on key factors contributing to patterns and insights, resulting in more accurate and efficient analysis results. Four methods are used to determine the most relevant attributes for analysis by evaluating their significance and contribution to the overall pattern. They are:
undefinedundefinedundefinedundefined - Numerosity Reduction reduces the data size without losing essential information, improving computational efficiency and speeding up analysis processes, particularly for large datasets.
- Dimensionality Reduction reduces variables while retaining relevant information. It's especially useful for high-dimensional data, eliminating noise and redundancy for better analysis.
Introduction to the Concept of Feature Engineering and Its Impact on Model Performance
Feature engineering is both an art and a science in machine learning. It involves creating new features from the existing ones or transforming features to better represent the underlying patterns in the data. Effective feature engineering can significantly boost a model's performance, while poor feature engineering can hinder it.
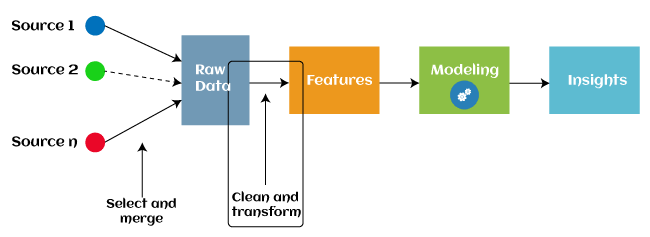
Feature Engineering for Machine Learning
Here are some examples of feature engineering:
- Feature Scaling: As mentioned earlier, feature scaling can be considered a form of feature engineering. It ensures that all features have a similar scale and can contribute equally to the model's predictions.
- Feature Extraction: In some cases, you may want to reduce the dimensionality of your data. Feature extraction techniques like Principal Component Analysis (PCA) can help identify the most critical features while reducing noise (irrelevant features).
- Text Data Transformation: When working with text data, techniques like TF-IDF (Term Frequency-Inverse Document Frequency) and word embeddings (e.g., Word2Vec) can convert text into numerical representations that machine learning models can process.
Feature engineering is a creative process that requires a deep understanding of the data and the problem. It involves experimentation and iteration to find the most informative features for your model. With our data prepared and our model trained, the next critical step is evaluating and validating the supervised learning model.
Model Evaluation and Validation
Model evaluation and validation help you assess the performance of your model and ensure that it generalizes well to unseen data. Proper evaluation and validation help you identify any issues with your model, such as underfitting or overfitting, and make the necessary adjustments to improve its performance.
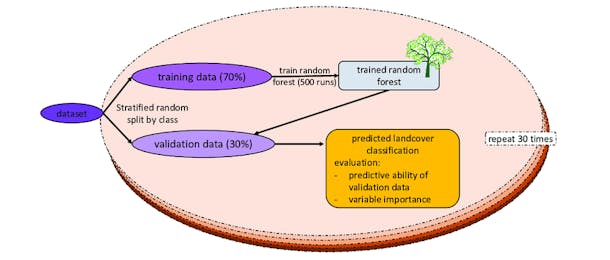
Model Validation and Evaluation
The Importance of Evaluating and Validating Supervised Learning Models
Evaluating and validating supervised learning models is crucial to ensure they perform as expected in real-world scenarios. Without proper evaluation, a model might not generalize effectively to unseen data, leading to inaccurate predictions and potentially costly errors.
Here's why model evaluation and validation are essential:
- Generalization Assessment: The goal of supervised learning is to create models that can make accurate predictions on new, unseen data. Model evaluation helps assess how well a model generalizes beyond the training data.
- Comparison of Models: In many cases, you might experiment with multiple algorithms or variations of a model. Model evaluation provides a basis for comparing these models and selecting the best-performing one.
- Tuning Hyperparameters: Model evaluation guides the fine-tuning of hyperparameters. By analyzing a model's performance on validation data, you can adjust hyperparameters to improve performance.
Overview of Common Evaluation Metrics
There are several evaluation metrics used in supervised learning, each suited to different types of problems. Here are some of the most common evaluation metrics:
- Accuracy: Accuracy measures the proportion of correctly classified instances out of all instances in the test set. It's a suitable metric for balanced datasets but can be misleading when dealing with imbalanced data.
- Precision: Precision measures the ratio of true positive predictions to the total positive predictions. It is particularly useful when the cost of false positives is high.
- Recall: Recall (or sensitivity) measures the ratio of true positives to all actual positives. It is essential when it's crucial to identify all positive instances, even if it means having some false positives.
- F1-Score: The F1-score is the harmonic mean of precision and recall. It provides a balanced measure of a model's performance, especially when dealing with imbalanced datasets.
- Confusion Matrix: A confusion matrix is a table that summarizes the model's predictions and actual class labels. It provides a more detailed view of a model's performance, showing true positives, true negatives, false positives, and false negatives.
Model Evaluation Techniques
To evaluate and validate supervised learning models effectively, you can employ various techniques:
- Cross-Validation: Cross-validation involves splitting the data into multiple subsets and training and testing the model on different subsets. This helps assess how well the model generalizes to other data partitions.
- Learning Curves: Learning curves visualize how a model's performance changes as the size of the training data increases. They can reveal whether the model is underfitting or overfitting.
- ROC Curves and AUC: Receiver Operating Characteristic (ROC) curves show the trade-off between true positive rate and false positive rate at different classification thresholds. The Area Under the Curve (AUC) quantifies the overall performance of a binary classification model.
- Validation Sets: Besides the training and test sets, a validation set is often used to fine-tune models and avoid overfitting. The validation set helps make decisions about hyperparameters and model selection.
By diligently applying these evaluation techniques and metrics, you can ensure that your supervised learning model is robust, accurate, and ready for deployment in real-world scenarios.
Through predictive analytics and predictive modeling, supervised learning empowers teams to make data-driven decisions by learning from historical data.

Challenges and Future Directions
While supervised learning has achieved remarkable success in various domains, it has its challenges. Some of the key challenges in supervised learning include:
- Data Quality: The quality of the training data heavily influences model performance. Noisy, biased, or incomplete data can lead to inaccurate predictions.
- Overfitting: Overfitting occurs when a model learns to memorize the training data rather than generalize from it. Techniques like regularization and cross-validation can mitigate this issue.
- Imbalanced Data: Imbalanced datasets can lead to biased models that perform poorly for underrepresented classes. Resampling techniques and specialized algorithms can address this challenge.
- Curse of Dimensionality: As the dimensionality of the feature space increases, the amount of data required for effective modeling also increases. Dimensionality reduction techniques can help manage this issue.
- Interpretability: Deep learning models, such as neural networks, are often considered "black boxes" due to their complexity. Ensuring model interpretability is an ongoing challenge.
Looking ahead, the field of supervised learning continues to evolve. Some promising directions include:
- Transfer Learning: Transfer learning allows models trained on one task to be adapted for use on another, reducing the need for massive amounts of labeled data.
- Pre-Trained Models: These allow practitioners to leverage the knowledge and feature representations learned from vast, general datasets, making it easier and more efficient to develop specialized models for specific tasks.
- AutoML: Automated Machine Learning (AutoML) tools are becoming more accessible, allowing individuals and organizations to build and deploy models with minimal manual intervention.
- Responsible AI: Responsible AI ensures ethical, fair, and accountable AI systems, considering societal impacts, mitigating harm, and promoting transparency and explainability for clear decision-making.
undefinedundefinedundefinedundefined
Bias in Machine Learning refers to systematic errors introduced by algorithms or training data that lead to unfair or disproportionate predictions for specific groups or individuals. Learn how to mitigate model bias in Machine Learning.
Supervised Learning: Key Takeaways
- Supervised learning is a foundational concept in data science, where data scientists leverage various techniques, including Naive Bayes, to build predictive models.
- It plays a pivotal role in various AI applications, including spam email detection, recommendation systems, medical diagnosis, and autonomous driving, making it essential to develop intelligent systems.
- The structured approach to understanding supervised learning includes input features, target labels, data preparation, model training, evaluation, and deployment.
- There are two main types of supervised learning algorithms: classification (for assigning data points to predefined categories) and regression (for predicting continuous values).
- Data scientists select appropriate algorithms, such as K-Nearest Neighbors (KNN), to classify or regress data points, enabling applications like spam email detection or sales forecasting.
- Common techniques for data preparation include data cleaning, feature scaling, feature engineering, one-hot encoding, and handling imbalanced data.
- Model evaluation and validation are crucial for assessing performance, generalization, and fine-tuning hyperparameters in supervised learning, despite challenges like data quality and interpretability.

Frequently asked questions
Supervised learning is a machine learning method that uses labeled training data to make predictions or decisions. It involves a dataset with input features and output labels, while unsupervised learning or reinforcement learning focuses on patterns or decisions based on rewards and punishments.
Some real-world supervised learning applications include spam email detection, credit scoring, image recognition, and speech recognition. These applications have a significant impact on various industries by improving the efficiency and accuracy of decision-making processes. For example, in the healthcare industry, supervised learning algorithms can assist in diagnosing diseases based on medical images or predicting patient outcomes.
The key steps in training a supervised learning model include data collection, data curation, data preprocessing, feature selection or extraction, model training and evaluation, model deployment, model monitoring, management, and retraining.
Supervised learning faces challenges like overfitting and underfitting, which can be addressed through regularization and cross-validation. High-quality training data, feature selection, and engineering are also crucial. Incomplete data can lead to inaccurate predictions, and class imbalances can affect performance. Techniques like oversampling, undersampling, and ensemble methods can help. The choice of an appropriate evaluation metric is essential for accurate performance assessment.
Deep learning algorithms like CNNs and RNNs are gaining popularity in supervised learning due to their ability to learn hierarchical representations from raw data. In the future, researchers may combine supervised learning with reinforcement learning and unsupervised learning to make models that are more flexible and can learn from labeled and unlabeled data. This could lead to new insights and better performance in challenging domains.
Encord's platform can facilitate the integration of machine learning components within behavior planning systems by providing streamlined data annotation and management tools. This allows for easier scaling of models with data, ensuring that behavior planners can make informed decisions based on accurately labeled datasets.
Encord provides robust features for managing training data pipelines, including data curation and data engineering tools. These capabilities help streamline the process of preparing datasets for machine learning models, ensuring that the data is clean, well-organized, and ready for use in developing AI applications.
Encord is designed to seamlessly fit into your machine learning pipelines, allowing for efficient data ingestion, labeling, and export processes. By automating these workflows, Encord helps optimize your data handling and model training efforts, ensuring that you can focus on developing robust AI solutions.
Encord facilitates continuous learning by allowing users to refine models based on newly labeled data. This approach helps improve annotation speed over time, particularly for specialized datasets like satellite imagery, ensuring models become more effective as they learn from ongoing inputs.
Encord offers integrated tools for tracking and managing machine learning experiments, such as MLflow for trial and error analysis. This allows teams to monitor their data pipelines and training processes, facilitating continuous improvement of their machine learning models.
Yes, Encord is tailored to assist in the development of products like auto refereeing systems. It addresses challenges in data annotation and curation, which are crucial for training accurate machine learning models in sports analytics, such as those used in tennis matches.
Encord helps alleviate the time constraints faced by machine learning engineers by enabling efficient outsourcing of labeling tasks to external experts. This allows internal teams to focus on more strategic tasks while ensuring that data quality remains high.
Encord supports dataset curation through its intuitive annotation tools that simplify the process of labeling data. This capability is essential for preparing high-quality datasets that can be used for training machine learning models effectively.
Encord enhances communication through centralized project management tools that ensure everyone is aligned on terminology and tagging standards. This reduces confusion and helps maintain a consistent approach across different teams.
Encord offers tools that help users construct and manage complex data training pipelines. This allows teams to focus on the critical steps in their workflows, enhancing the overall efficiency of their machine learning models.