What is K-Means Clustering?
K-means clustering is a machine learning algorithm that partitions a dataset into K distinct clusters, with each data point assigned to the cluster whose centroid (center) is closest, aiming to group similar data points together. It iteratively refines cluster assignments and centroids until convergence.
K-means clustering was first introduced by Stuart Lloyd in 1957 to address the problem of pulse-code modulation in telecommunications. The algorithm’s simplicity and effectiveness in partitioning data into clusters have made it popular in various fields.
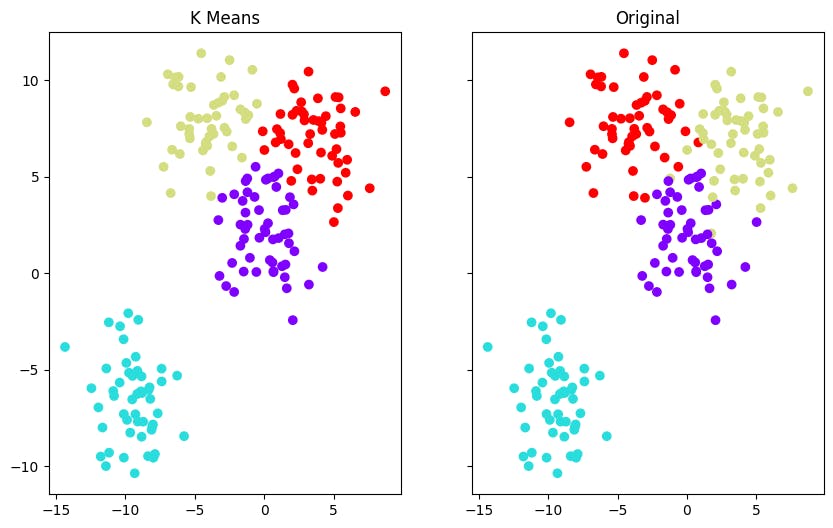
K-means clustering with Python
K-means clustering is a technique that aims to group data points into clusters in such a way that data points within the same cluster are as similar to each other as possible. It does this by minimizing the within-cluster variance, effectively making the points within each cluster as close to each other as possible. The centroid of a cluster and data points are assigned to the cluster whose centroid is closest to them. Interpretation involves understanding that points in the same cluster are more similar to each other than to points in other clusters.
Applications
K-means clustering has multiple applications in various domains, including:
- Image Compression: It's used to reduce the size of image files by grouping similar pixel values together, thereby preserving image quality while reducing storage requirements.
- Customer Segmentation: Businesses use K-means to group customers with similar behaviors, preferences, or purchase histories. This helps in targeted marketing and product recommendations.
- Anomaly Detection: K-means can identify outliers or anomalies by labeling data points that are far from any cluster centroid as anomalies, which is valuable in fraud detection and quality control.
- Text Document Clustering: It can cluster documents by topic or content, making it easier to organize and retrieve information from large text corpora.
- Genomic Data Analysis: In bioinformatics, K-means can group genes with similar expression patterns, aiding in gene function discovery and disease classification.
- Recommendation Systems: By clustering users with similar preferences or behaviors, K-means can enhance recommendation engines.
Significance
K-means clustering is a significant tool in data analysis and machine learning due to its ability to uncover hidden patterns and group data points without the need for labeled data. . K-means clustering is a computationally efficient algorithm that scales well to large datasets, making it an ideal tool for data exploration, preprocessing, and segmentation. This can lead to cost savings and improved decision-making.
Overall, K-means clustering is a powerful tool that enables more informed decision-making and improved performance. Its ability to uncover hidden structures and relationships within data makes it a foundational technique in data analysis and machine learning.
Frequently asked questions
- K-means is a widely used unsupervised ML algorithm that clusters data by iteratively assigning points to groups with similar attributes. It reveals data patterns by recalculating the cluster centroids, aiding in data understanding and segmentation.
- K-nearest neighbors (KNN) is a supervised machine learning algorithm used for classification and regression, relying on the proximity of data points. K-means is an unsupervised algorithm for data clustering, dividing a dataset into groups based on data point similarity. KNN involves prediction, while K-means focuses on pattern discovery and data segmentation.
- No, K-means is not the same as random forest. Random forest is an ensemble learning algorithm that combines multiple decision trees to make predictions, while K-means is a clustering algorithm that aims to group similar data points together based on their distances.