How To Mitigate Bias in Machine Learning Models

Product Manager at Encord
Machine learning has revolutionized many industries by automating decision-making processes and improving efficiency. In recent years, data science, machine learning, and artificial intelligence have become increasingly prevalent in various applications, transforming industries and everyday life. As these technologies become more integrated into the real world, one of the significant challenges in responsibly deploying machine learning models is mitigating bias.
To ensure that AI systems are fair, reliable, and equitable, addressing bias is crucial. In this article, you will learn about:
- Types of bias
- Impacts of bias
- Evaluating bias in ML models
- Mitigating bias in ML models
- Mitigating bias with Encord Active
- Key takeaways

Types of Bias
Bias in machine learning refers to systematic errors introduced by algorithms or training data that lead to unfair or disproportionate predictions for specific groups or individuals. Such biases can arise due to historical imbalances in the training data, algorithm design, or data collection process. If left unchecked, biased AI models can perpetuate societal inequalities and cause real-world harm. Biases can be further categorized into explicit and implicit bias:
- Explicit bias refers to conscious prejudice held by individuals or groups based on stereotypes or beliefs about specific racial or ethnic groups. For example, an AI-powered customer support chatbot may be programmed with bias towards promoting products from manufacturers that offer higher commissions or incentives to the company.
- Implicit bias is a type of prejudice that people hold or express unintentionally and outside of their conscious control. These biases can have an unconscious impact on perceptions, assessments, and choices because they are often deeply ingrained in societal norms. The collection of data, the creation of algorithms, and the training of models can all unintentionally reflect unconscious bias.
For simplicity, we can categorize data bias into three buckets: data bias, algorithm bias, and user interaction bias. These categories are not mutually exclusive and are often intertwined.
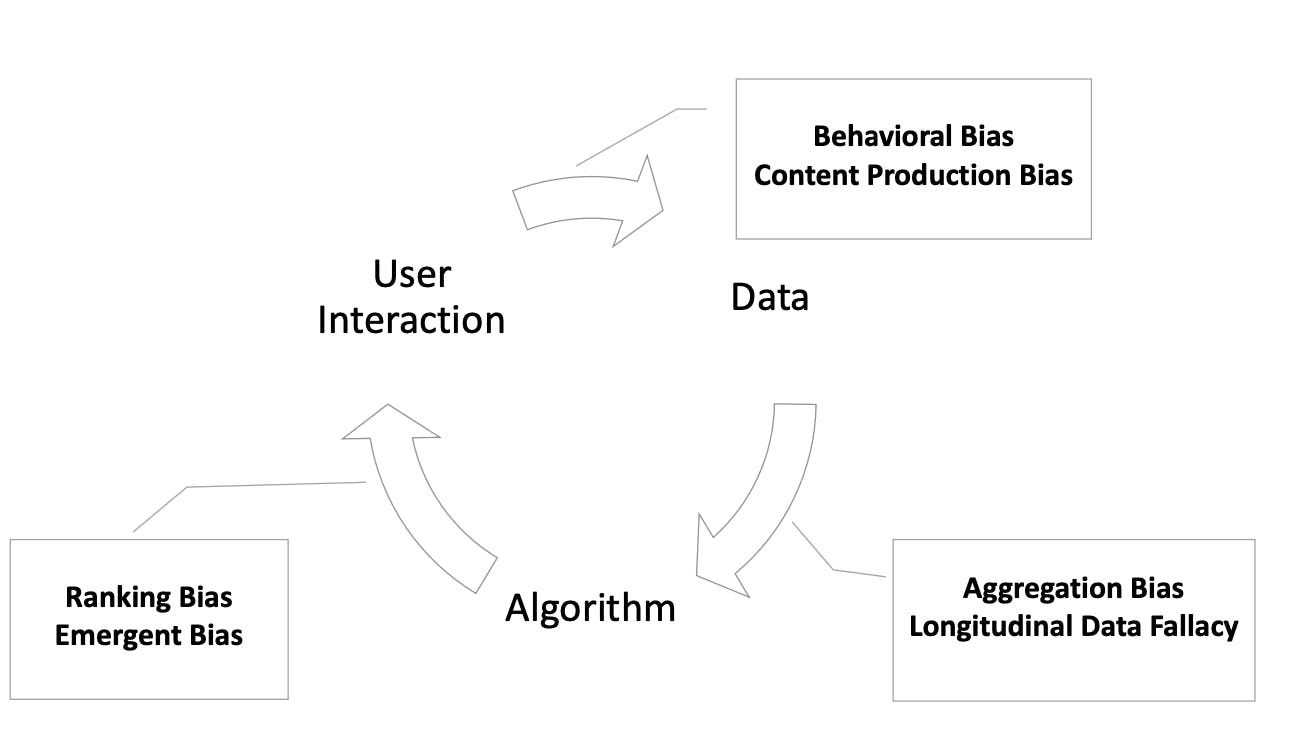
A Survey on Bias and Fairness in Machine Learning
Bias in Data
When biased data is used to train ML algorithms, the outcomes of these models are likely to be biased as well. Let’s look at the types of biases in data:
- Measurement bias occurs when the methods used to record data systematically deviate from the true values, resulting in consistent overestimation or underestimation. This distortion can arise due to equipment calibration errors, human subjectivity, or flawed procedures. Minor measurement biases can be managed with statistical adjustments, but significant biases can compromise data accuracy and skew outcomes, requiring cautious validation and re-calibration procedures.
- Omitted variable bias arises when pertinent variables that impact the relationship between the variables of interest are left out from the analysis. This can lead to spurious correlations or masked causations, misdirecting interpretations and decisions. Including relevant variables is vital to avoid inaccurate conclusions and to capture the delicate interactions that influence outcomes accurately.
- Aggregation bias occurs when data is combined at a higher level than necessary, masking underlying variations and patterns within subgroups. This can hide important insights and lead to inaccurate conclusions. Avoiding aggregation bias involves striking a balance between granularity and clarity, ensuring that insights drawn from aggregated data reflect the diversity of underlying elements.
- Sampling bias occurs when proper randomization is not used for data collection. Sampling bias can help optimize data collection and model training by focusing on relevant subsets, but may introduce inaccuracies in representing the entire population.
- Linking bias occurs when connections between variables are assumed without solid evidence or due to preconceived notions. This can lead to misguided conclusions. It's important to establish causal relationships through rigorous analysis and empirical evidence to ensure the reliability and validity of research findings.
- Labeling bias occurs when the data used to train and improve the model performance is labeled with incorrect or biased labels. Human annotators may inadvertently introduce their own biases when labeling data, which can be absorbed by the model during training. Corporate machine learning training courses are vital for ensuring high-quality, unbiased data, leading to more accurate and reliable machine learning models. Investing in such training empowers employees to enhance the overall effectiveness of machine learning initiatives.
Bias in Algorithms
Bias in algorithms reveals the subtle influences of our society that sneak into technology. Algorithms are not inherently impartial; they can unknowingly carry biases from the data they learn from. It's important to recognize and address this bias to ensure that our digital tools are fair and inclusive. Let’s look at the types of biases in algorithms:
- Algorithmic bias emerges from the design and decision-making process of the machine learning algorithm itself. Biased algorithms may favor certain groups or make unfair decisions, even if the training data is unbiased.
- User interaction bias can be introduced into the model through user interactions or feedback. If users exhibit biased behavior or provide biased feedback, the AI system might unintentionally learn and reinforce those biases in its responses.
- Popularity bias occurs when the AI favors popular options and disregards potentially superior alternatives that are less well-known.
- Emergent bias happens when the AI learns new biases while working and makes unfair decisions based on those biases, even if the data it processes is not inherently biased.
- Evaluation bias arises when we use biased criteria to measure the performance of AI. This can result in unfair outcomes and lead us to miss actual issues.
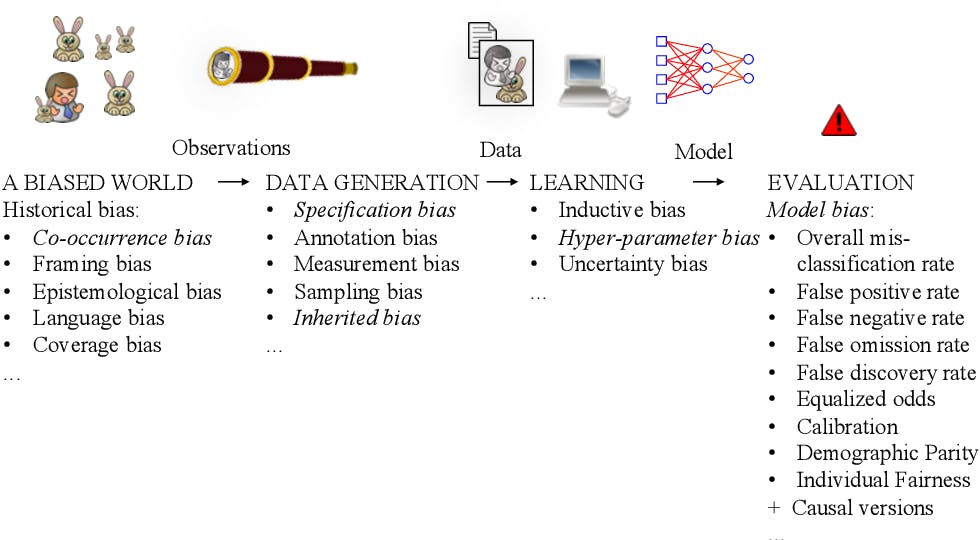
Bias in Machine Learning - What is it Good for?
Bias in User Interaction
User biases can be introduced into the model through user interactions or feedback. If users exhibit biased behavior or provide biased feedback, the AI system might unintentionally learn and reinforce those biases in its responses.
- Historical bias is inherited from past embedded social or cultural inequalities. When historical data contains biases, AI models can perpetuate and even amplify these biases in their predictions.
- Population bias occurs when the AI prioritizes one group over others due to the data it has learned from. This can result in inaccurate predictions for underrepresented groups.
- Social bias can arise from cultural attitudes and prejudices in data, leading the AI to make biased predictions that reflect unfair societal views.
- Temporal bias occurs when the AI makes predictions that are only true for a certain time. Without considering changes over time, the results will be outdated.
Impacts of Bias
The impact of bias in machine learning can be far-reaching, affecting various domains:
Healthcare
Training AI systems for healthcare with biased data can lead to misdiagnosis or unequal access to medical resources for different demographic groups. These biases in AI models can disproportionately affect minority communities, leading to inequitable healthcare outcomes. If the training data mostly represents specific demographic groups, the model may struggle to accurately diagnose or treat conditions in underrepresented populations.

Criminal Justice
Bias in predictive algorithms used in criminal justice systems for risk assessment can perpetuate racial disparities and lead to biased sentencing. For example, biased recidivism prediction models may unfairly label certain individuals as high-risk, resulting in harsher treatment or longer sentences.
Employment and Hiring
Biases in AI-powered hiring systems can perpetuate discriminatory hiring practices, hindering opportunities for minorities and reinforcing workforce inequalities.
Finance
Bias in AI-powered financial applications can result in discriminatory lending practices. AI models that use biased data to determine creditworthiness may deny loans or offer less favorable terms based on irrelevant features.
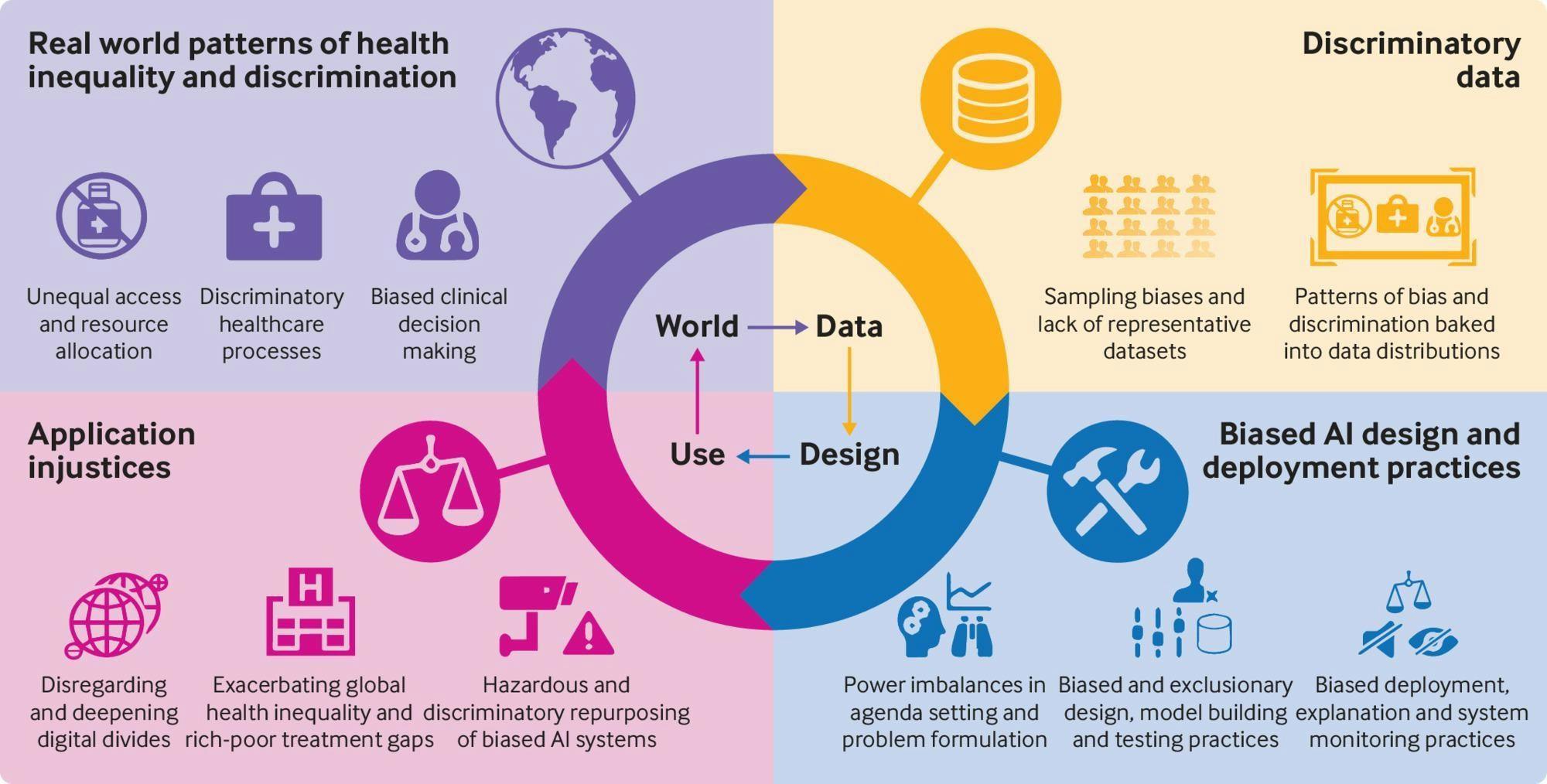
Impact of Bias in Different Applications
Evaluating Bias in ML Models
Evaluating and quantifying bias in machine learning models is essential for effectively addressing this issue. There are several metrics and methodologies used to assess bias, including:
Disparate Impact Analysis
This technique examines the disparate impact of an AI model's decisions on different demographic groups. It measures the difference in model outcome for various groups and highlights potential biases.
Disparate Impact Analysis is a vital tool for assessing the fairness of AI models. It helps detect potential discriminatory effects based on protected attributes like race or gender. By comparing model performance across different demographic groups, it reveals if certain groups are unfairly favored or disadvantaged. Addressing bias issues through data modification, algorithm adjustments, or decision-making improvements is essential for creating equitable results.
Fairness Metrics
Several fairness metrics have been proposed to quantify bias in machine learning models. Examples include Equal Opportunity Difference, Disparate Misclassification Rate, and Treatment Equality. These metrics help assess how fairly the model treats different groups.
Post-hoc Analysis
Post-hoc analysis involves examining an AI system’s decisions after deployment to identify instances of bias and understand its impact on users and society.
One application of post-hoc analysis is in sentiment analysis for customer reviews. This allows companies to assess how well their model performs in classifying reviews as positive, negative, or neutral. This analysis is instrumental in natural language processing tasks like text classification using techniques such as RNN or BERT.
Mitigating Bias in ML Models
To reduce bias in machine learning models, technical, ethical, and organizational efforts must be combined. There are several strategies to mitigate bias, including:
Diverse and Representative Data Collection
It is essential to have diverse and representative training data to combat data bias. Data collection processes should be carefully designed to ensure a fair representation of all relevant data points. This may involve oversampling underrepresented groups or using advanced techniques to generate synthetic data. This technique helps improve model accuracy and reduce bias towards the majority class.
Bias-Aware Algorithms
To foster fairness in machine learning systems, developers can utilize fairness-aware algorithms that explicitly incorporate fairness constraints during model training. Techniques such as adversarial training, reweighing, and re-sampling can be employed to reduce algorithmic bias and ensure more equitable outcomes.
Explainable AI and Model Interpretability
Enhancing the interpretability of AI models can aid in identifying and addressing bias more effectively. By understanding the model's decision-making process, potential biases can be identified and appropriate corrective measures can be taken.
Pre-processing and Post-processing
Pre-processing techniques involve modifying the training data to reduce bias, while post-processing methods adjust model outputs to ensure fairness. These techniques can help balance predictions across different groups.
Regular Auditing and Monitoring
Regularly auditing and monitoring AI models can detect bias and ensure ongoing fairness. Feedback loops with users can also help identify and address potential user biases.
Mitigating Bias with Encord Active
Encord Active offers features to help reduce bias in datasets, allowing you to identify and address any potential biases in your data workflow. By leveraging the data points metadata filters, you can filter the dataset based on attributes like Object Class and Annotator.
These capabilities enable you to concentrate on specific classes or annotations created by particular annotators on your team. This helps ensure that the dataset is representative and balanced across various categories. You can identify and mitigate any inadvertent skew in the dataset by paying attention to potential biases related to annotators or object classes.
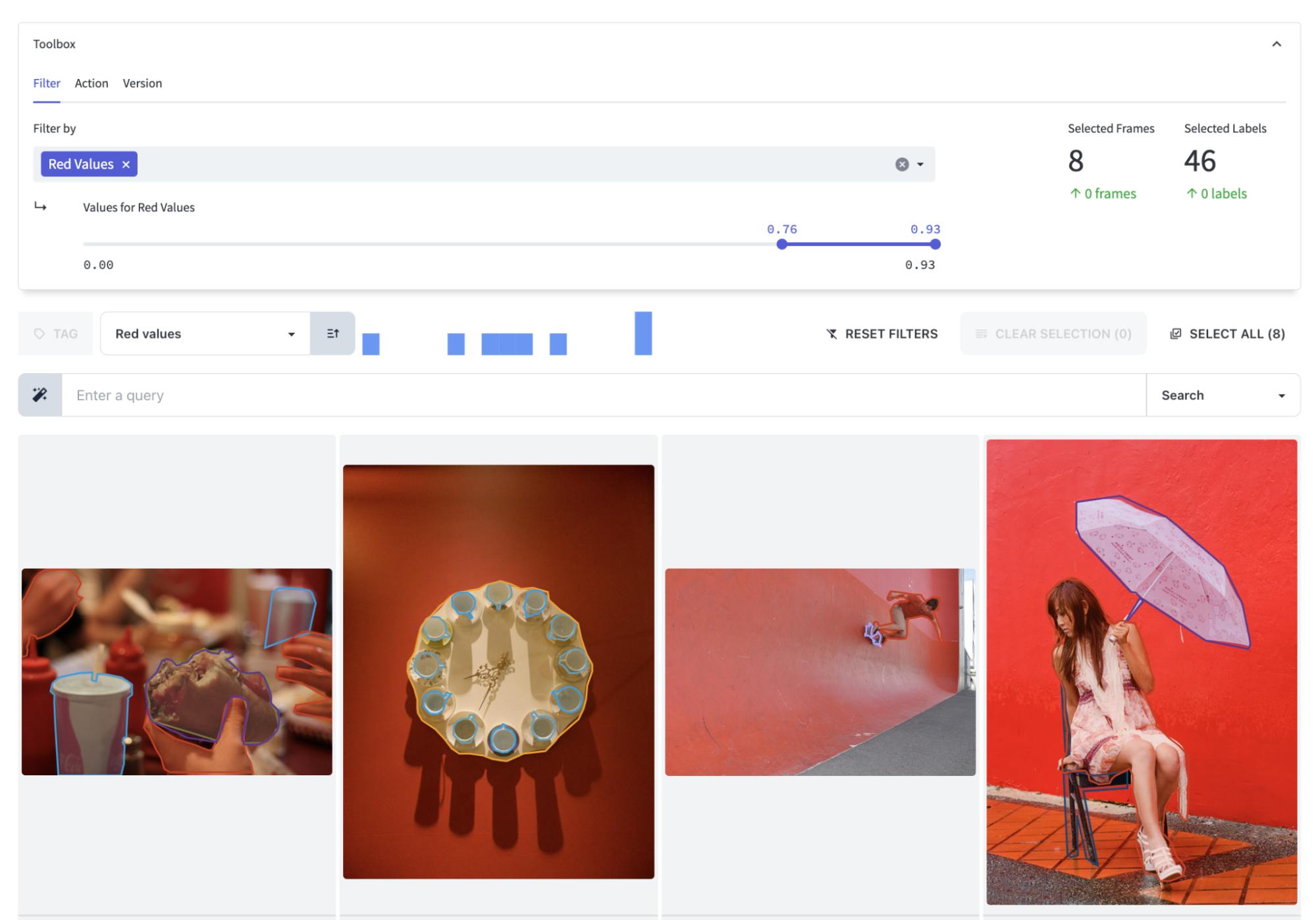
Encord Active's user-defined tag filters are crucial for reducing bias. These filters allow you to apply custom tags to categorize data based on specific attributes, preferences, or characteristics.
By leveraging these user-defined tags for filtering, data can be organized and assessed with respect to critical factors that influence model performance or decision-making processes. For example, if there are sensitive attributes like race or gender that need to be considered in the dataset, corresponding tags can be assigned to filter the data appropriately, ensuring fair representation and equitable outcomes.
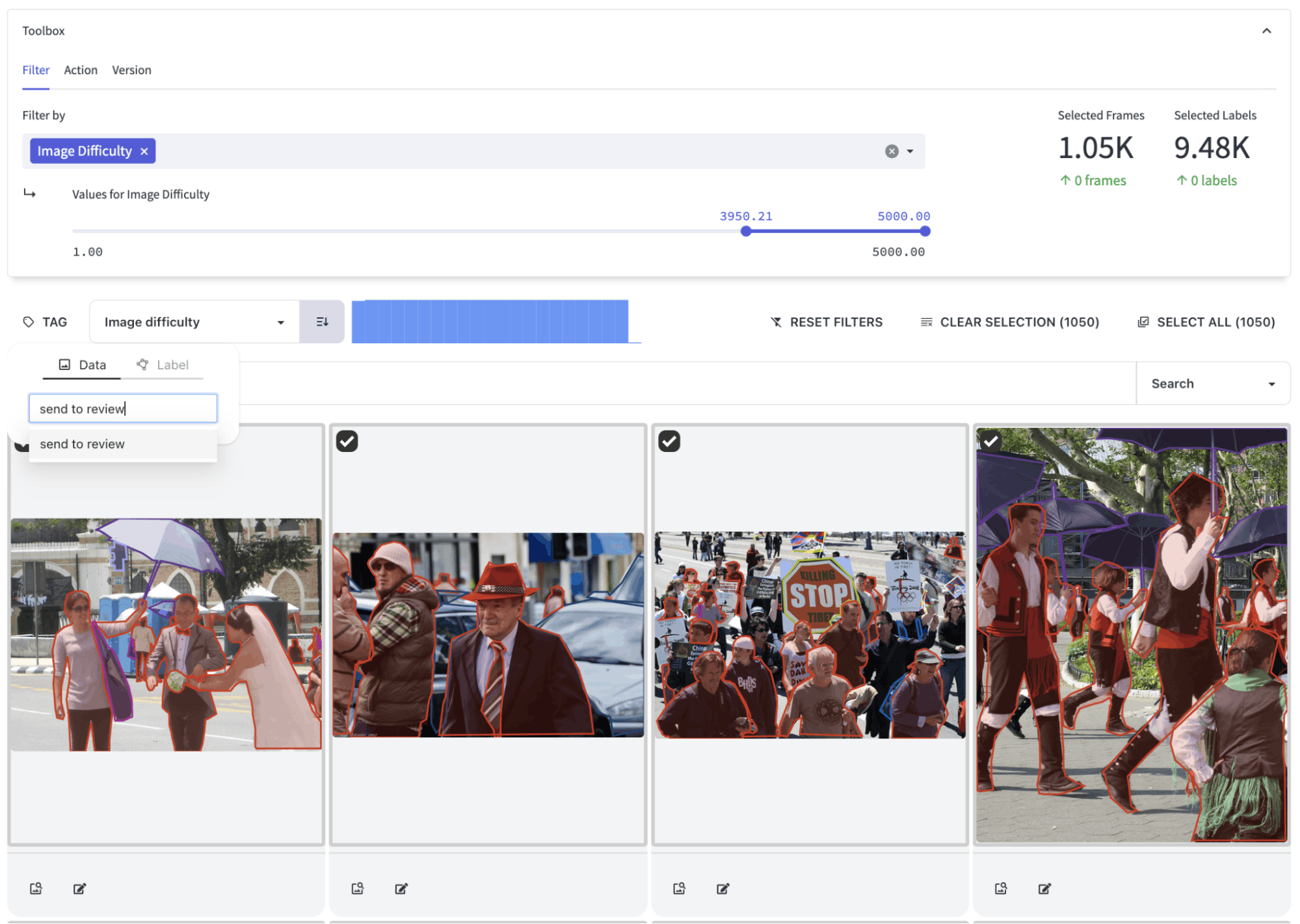
Combined with these filtering capabilities, Encord Active's ability to find outliers based on pre-defined and custom metrics also aids in bias reduction. Outliers, or data points that deviate significantly from the norm, can indicate potential biases in the dataset.
By identifying and labeling outliers for specific metrics, you can gain insights into potential sources of bias and take corrective measures. This process ensures that your dataset is more balanced, reliable, and representative of the real-world scenarios it aims to address. Ultimately, this can lead to more robust and fair machine learning models and decision-making processes.
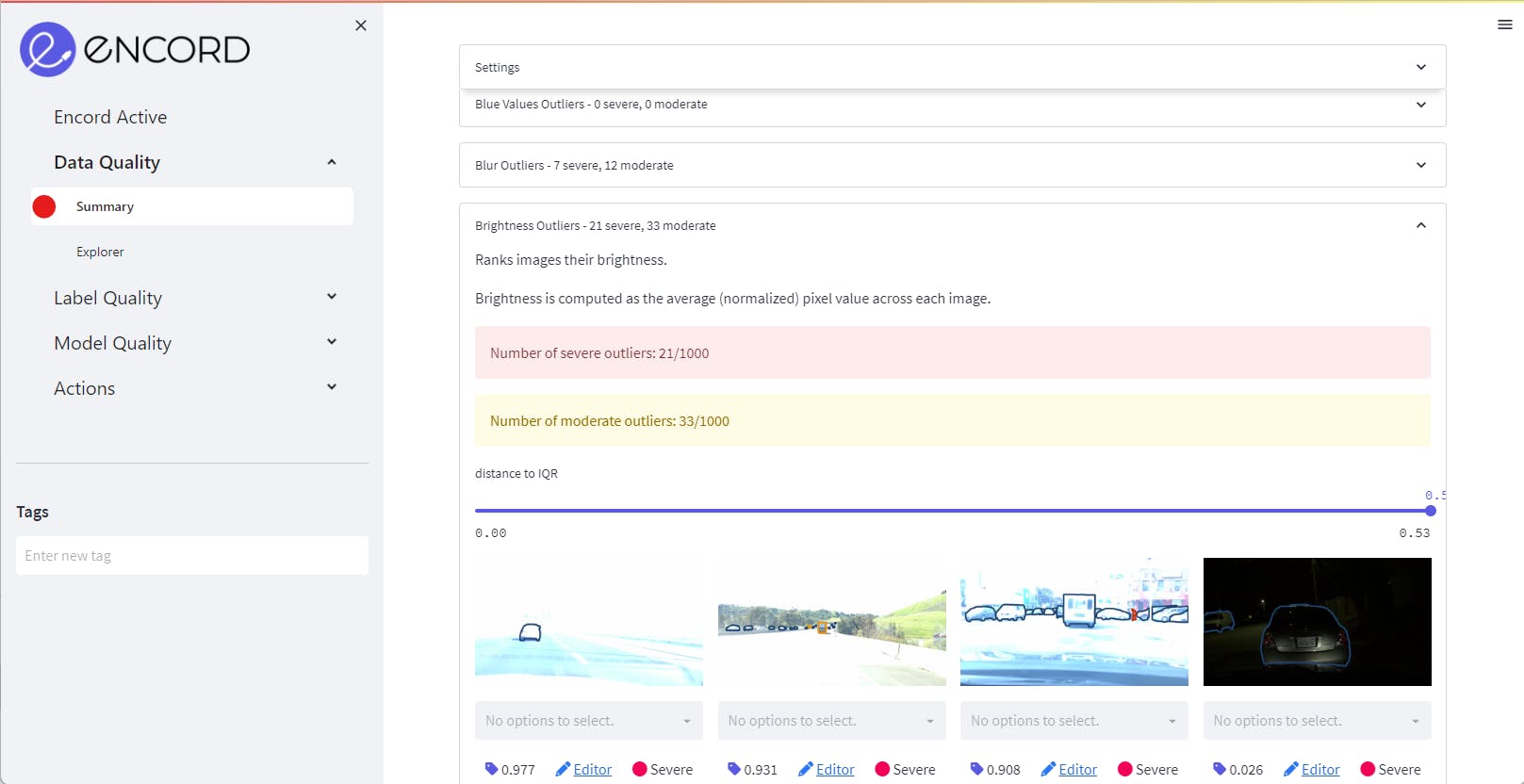
The Summary Tab of each Quality Metrics shows the outliers. Clicking on each outlier gives deeper insight into moderate and severe outliers.
Bias in ML Models: Key Takeaways
- Bias in machine learning is a major challenge that requires attention and efforts from the AI community.
- Identifying sources of bias and evaluating its impact are essential steps toward creating fair and ethical AI systems.
- Effective mitigation strategies can help reduce bias and promote fairness in machine learning models.
- Encord Active and its quality metrics can be used to mitigate bias.
- Reducing bias in machine learning is an ongoing journey that requires a commitment to ethical considerations and fairness.
- The collaboration among data scientists, developers, organizations, and policymakers is crucial in ensuring that AI technologies benefit society without perpetuating biases or discrimination.
Frequently asked questions
Bias in machine learning refers to systematic errors introduced by algorithms or training data that lead to unfair predictions or decisions for specific groups or individuals. These biases can arise from historical imbalances in data, algorithm design, or data collection processes.
Bias in machine learning can have significant impacts across various domains. For example, biased healthcare AI models may lead to misdiagnosis or unequal access to medical resources. In criminal justice, biased predictive algorithms can perpetuate racial disparities and unfair sentencing.
Bias can be evaluated using methods like Disparate Impact Analysis, which measures the differences in model outcomes for different demographic groups. Fairness metrics, such as Equal Opportunity Difference and Disparate Misclassification Rate, also help assess bias in machine learning models.
Mitigating bias requires a combination of technical and ethical efforts. Strategies include collecting diverse and representative data, using bias-aware algorithms, enhancing model interpretability, applying pre-processing and post-processing techniques, and regularly auditing and monitoring AI models.
Encord Active offers features like user-defined tag filters and outlier identification to reduce bias in datasets. These capabilities enable users to filter data based on specific attributes and metrics, ensuring fair representation and balanced outcomes.
Reducing bias in machine learning requires continuous commitment to ethical considerations and fairness. Collaboration among data scientists, developers, organizations, and policymakers is essential to ensure that AI technologies benefit society without perpetuating biases or discrimination.
Encord's platform includes tools for automatic fairness evaluation, which help assess the performance of AI models across different demographic characteristics. This feature is crucial for ensuring that models are equitable and do not favor specific groups, addressing concerns related to biases in AI.
Encord enhances the efficiency of machine learning workflows by providing tools for streamlined data management, annotation, and model evaluation. This comprehensive platform helps teams reduce the time spent on manual tasks, allowing for quicker iteration and deployment of machine learning models.
Encord offers capabilities that facilitate the curation of data by enabling teams to identify and prioritize the most relevant scenarios for annotation. This helps optimize the data pipeline, ensuring that the most useful data is annotated first, ultimately improving model performance.
Encord is designed to manage and curate data effectively for machine learning projects. It provides tools for annotating and organizing data, which is essential for training models and ensuring high-quality outputs in various applications, including quality control in manufacturing.
During model evaluation, Encord provides tools that can identify biases in data, such as facial recognition biases. This is essential for ensuring that AI models are trained fairly and effectively, minimizing any unintended consequences from biased training data.
Yes, Encord is designed to help teams stabilize their existing machine learning pipelines, ensuring that current projects are reliable and efficient before moving on to new initiatives.