An Introduction to Diffusion Models for Machine Learning

Product Manager at Encord
Machine learning and artificial intelligence algorithms are constantly evolving to solve complex problems and enhance our understanding of data. One interesting group of models is diffusion models, which have gained significant attention for their ability to capture and simulate complex processes like data generation and image synthesis.
In this article, we will explore:
- What is diffusion?
- What are diffusion models?
- How do diffusion models work?
- Applications of diffusion models
- Popular diffusion models for image generation

What is Diffusion?
Diffusion is a fundamental natural phenomenon observed in various systems, including physics, chemistry, and biology.
This is readily noticeable in everyday life. Consider the example of spraying perfume. Initially, the perfume molecules are densely concentrated near the point of spraying. As time passes, the molecules disperse.
Diffusion is the process of particles, information, or energy moving from an area of high concentration to an area of lower concentration. This happens because systems tend to reach equilibrium, where concentrations become uniform throughout the system.
In machine learning and data generation, diffusion refers to a specific approach for generating data using a stochastic process similar to a Markov chain. In this context, diffusion models create new data samples by starting with simple, easily generated data and gradually transforming it into more complex and realistic data.
What are Diffusion Models in Machine Learning?
Diffusion models are generative, meaning they generate new data based on the data they are trained on. For example, a diffusion model trained on a collection of human faces can generate new and realistic human faces with various features and expressions, even if those specific faces were not present in the original training dataset.
These models focus on modeling the step-by-step evolution of data distribution from a simple starting point to a more complex distribution. The underlying concept of diffusion models is to transform a simple and easily samplable distribution, typically a Gaussian distribution, into a more complex data distribution of interest through a series of invertible operations.
Once the model learns the transformation process, it can generate new samples by starting from a point in the simple distribution and gradually "diffusing" it to the desired complex data distribution.
Denoising Diffusion Probabilistic Models (DDPMs)
DDPMs are a type of diffusion model used for probabilistic data generation. As mentioned earlier, diffusion models generate data by applying transformations to random noise. DDPMs, in particular, operate by simulating a diffusion process that transforms noisy data into clean data samples.
Training DDPMs entails acquiring knowledge of the diffusion process’s parameters, effectively capturing the relationship between clean and noisy data during each transformation step.
During inference (generation), DDPMs start with noisy data (e.g., noisy images) and iteratively apply the learned transformations in reverse to obtain denoised and realistic data samples.

Diffusion Models: A Comprehensive Survey of Methods and Applications
DDPMs are particularly effective for image-denoising tasks. They can effectively remove noise from corrupted images and produce visually appealing denoised versions. Moreover, DDPMs can also be used for image inpainting and super-resolution, among other applications.
Score-Based Generative Models (SGMs)
Score-Based Generative Models are a class of generative models that use the score function to estimate the likelihood of data samples. The score function, also known as the gradient of the log-likelihood with respect to the data, provides essential information about the local structure of the data distribution.
SGMs use the score function to estimate the data's probability density at any given point. This allows them to effectively model complex and high-dimensional data distributions. Although the score function can be computed analytically for some probability distributions, it is often estimated using automatic differentiation and neural networks.
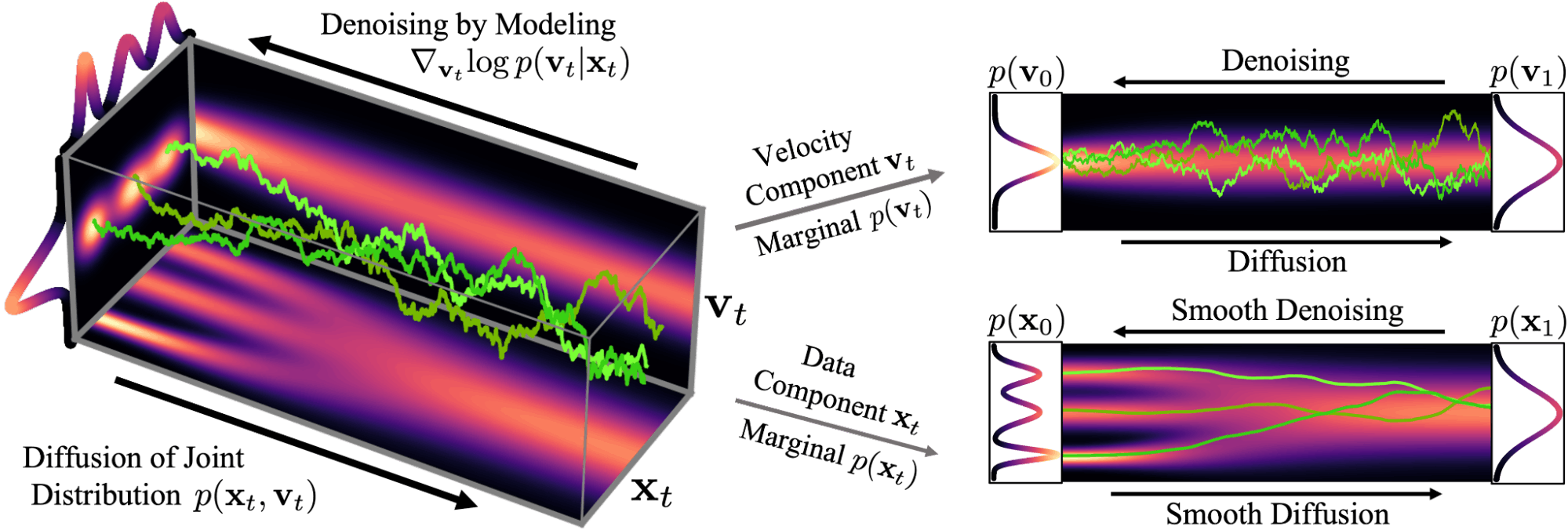
Score-Based Generative Modeling with Critically-Damped Langevin Diffusion
Using the score function, SGMs can generate data samples that resemble the training data distribution. Iteratively updating them toward the log-likelihoods negative gradient achieves this.
Stochastic Differential Equations (Score SDEs)
Stochastic Differential Equations (SDEs) are mathematical equations describing how a system changes over time when subject to deterministic and random forces. In generative modeling, Score SDEs can parameterize the score-based models.
In Score SDEs, the score function is a solution to a stochastic differential equation. The model can learn a data-driven score function that adapts to the data distribution by solving this differential equation.
In essence, Score SDEs use stochastic processes to model the evolution of data samples and guide the generative process toward generating high-quality data samples.

Solving a reverse-time SDE yields a score-based generative model. Score-Based Generative Modeling through Stochastic Differential Equations
Score SDEs and score-based modeling can be combined to create powerful generative models capable of handling complex data distributions and generating diverse and realistic samples.
How do Diffusion Models Work?
Diffusion models are generative models that simulate data generation using the "reverse diffusion" concept.
Let's break down how diffusion models work step-by-step:
Data Preprocessing
The initial step involves preprocessing the data to ensure proper scaling and centering. Typically, standardization is applied to convert the data into a distribution with a mean of zero and a variance of one. This prepares the data for subsequent transformations during the diffusion process, enabling the diffusion models to effectively handle noisy images and generate high-quality samples.
Forward Diffusion
During forward diffusion, the model starts with a sample from a simple distribution, typically a Gaussian distribution, and applies a sequence of invertible transformations to "diffuse" the sample step-by-step until it reaches the desired complex data points distribution.
Each diffusion step introduces more complexity to the data, capturing the intricate patterns and details of the original distribution. This process can be thought of as gradually adding Gaussian noise to the initial sample, generating diverse and realistic samples as the diffusion process unfolds.
Training the Model
Training a diffusion model involves learning the parameters of the invertible transformations and other model components. This process typically involves optimizing a loss function, which evaluates how effectively the model can transform samples from a simple distribution into ones that closely resemble the complex data distribution.
Diffusion models are often called score-based models because they learn by estimating the score function (gradient of the log-likelihood) of the data distribution with respect to the input data points.
The training process can be computationally intensive, but advances in optimization algorithms, and hardware acceleration have made it feasible to train diffusion models on various datasets.
Reverse Diffusion
Once the forward diffusion process generates a sample from the complex data distribution, the reverse diffusion process maps it back to the simple distribution through a sequence of inverse transformations.
Through this reverse diffusion process, diffusion models can generate new data samples by starting from a point in the simple distribution and diffusing it step-by-step to the desired complex data distribution. The generated samples resemble the original data distribution, making diffusion models a powerful tool for image synthesis, data completion, and denoising tasks.
Benefits of Using Diffusion Models
Diffusion models offer advantages over traditional generative models like GANs (Generative Adversarial Networks) and VAEs (Variational Autoencoders). These benefits stem from their unique approach to data generation and reverse diffusion.
Image Quality and Coherence
Diffusion models are adept at generating high-quality images with fine details and realistic textures. When reverse diffusion is used to examine the underlying complexity of the data distribution, diffusion models make images that are more coherent and have fewer artifacts than traditional generative models.
Stable Training
Training diffusion models are generally more stable than training GANs, which are notoriously challenging. GANs require balancing the learning rates of the generator and discriminator networks, and mode collapse can occur when the generator fails to capture all aspects of the data distribution. In contrast, diffusion models use likelihood-based training, which tends to be more stable and avoids mode collapse.
Privacy-Preserving Data Generation
Diffusion models are suitable for applications in which data privacy is a concern. Since the model is based on invertible transformations, it is possible to generate synthetic data samples without exposing the underlying private information of the original data.
Handling Missing Data
Diffusion models can handle missing data during the generation process. Since reverse diffusion can work with incomplete data samples, the model can generate coherent samples even when parts of the input data are missing.
Robustness to Overfitting
Traditional generative models like GANs can be prone to overfitting, in which the model memorizes the training data and fails to generalize well to unseen data. Because they use likelihood-based training and the way reverse diffusion works, diffusion models are better at handling overfitting. This is because they create samples that are more consistent and varied.
Interpretable Latent Space
Diffusion models often have a more interpretable latent space than GANs. The model can capture additional variations and generate diverse samples by introducing a latent variable into the reverse diffusion process.
The reverse diffusion process turns the complicated data distribution into a simple distribution. This lets the latent space show the data's important features, patterns, and latent variables.
This interpretability, coupled with the flexibility of the latent variable, can be valuable for understanding the learned representations, gaining insights into the data, and enabling fine-grained control over image generation.
Scalability to High-Dimensional Data
Diffusion models have demonstrated promising scalability to high-dimensional data, such as images with large resolutions. The step-by-step diffusion process allows the model to efficiently generate complex data distributions without being overwhelmed by the data's high dimensionality.
Applications of Diffusion Models
Diffusion models have shown promise in various applications across domains due to their ability to model complex data distributions and generate high-quality samples. Let’s dive into some notable applications of diffusion models:
Text to Video

Make-A-Video: Text-to-Video Generation without Text-Video Data.
Diffusion models are a promising approach for text-to-video synthesis. The process involves first representing the textual descriptions and video data in a suitable format, such as word embeddings or transformer-based language models for text and video frames in a sequence format.
During the forward diffusion process, the model takes the encoded text representation and gradually generates video frames step-by-step, incorporating the semantics and dynamics of the text. Each diffusion step refines the rendered frames, transforming them from random noise into visually meaningful content that aligns with the text. The reverse diffusion process then maps the generated video frames back to the simple distribution, completing the text-to-video synthesis.
This conditional generation enables diffusion models to create visually compelling videos based on textual prompts. It has potential applications in video captioning, storytelling, and creative content generation. However, challenges remain, including ensuring temporal coherence between frames, handling long-range dependencies in text, and improving scalability for complex video sequences.
Image to Image
Diffusion models offer a powerful approach for image-to-image translation tasks, which involve transforming images from one domain to another while preserving semantic information and visual coherence.
The process involves conditioning the diffusion model on a source image and using reverse diffusion to generate a corresponding target image representing a transformed source version. To achieve this, the source and target images are represented in a suitable format for the model, such as pixel values or embeddings.
During the forward diffusion process, the model gradually transforms the source image, capturing the desired changes or attributes specified by the target domain. This often involves upsampling the source image to match the resolution of the target domain and refining the generated image step-by-step to produce high-quality and coherent results.
The reverse diffusion process then maps the generated target image back to the simple distribution, completing the image-to-image translation. This conditional generation allows diffusion models to excel in tasks like image colorization, style transfer, and image-to-sketch conversion.
Image Search
Diffusion models are powerful content-based image retrieval techniques that can be applied to image search tasks. Using the reverse diffusion process, the first step in using diffusion models for image search is to encode the images in a latent space.
During reverse diffusion, the model maps each image to a point in the simple distribution. This latent representation retains the essential visual information of the image while discarding irrelevant noise and details, making it suitable for efficient and effective similarity searches. When a query image is given for image search, the model encodes the query image into the same latent space using the reverse diffusion process.
The similarity between the query and database images can be measured using standard distance metrics (e.g., Euclidean distance) in the latent space. Images with the most similar latent representations are retrieved, producing relevant and visually similar images to the query.
This application of diffusion models for image search enables accurate and fast content-based retrieval, which is useful in various domains such as ai-generated logo templates, image libraries, image databases, and reverse image search engines.
Diffusion models are one such model that powers the semantic search feature within Encord Active. When you log into Encord → Active → Choose a Project → Use the Natural Language or Image Similarity Search feature. Here is a way to search with image similarity as the query image:
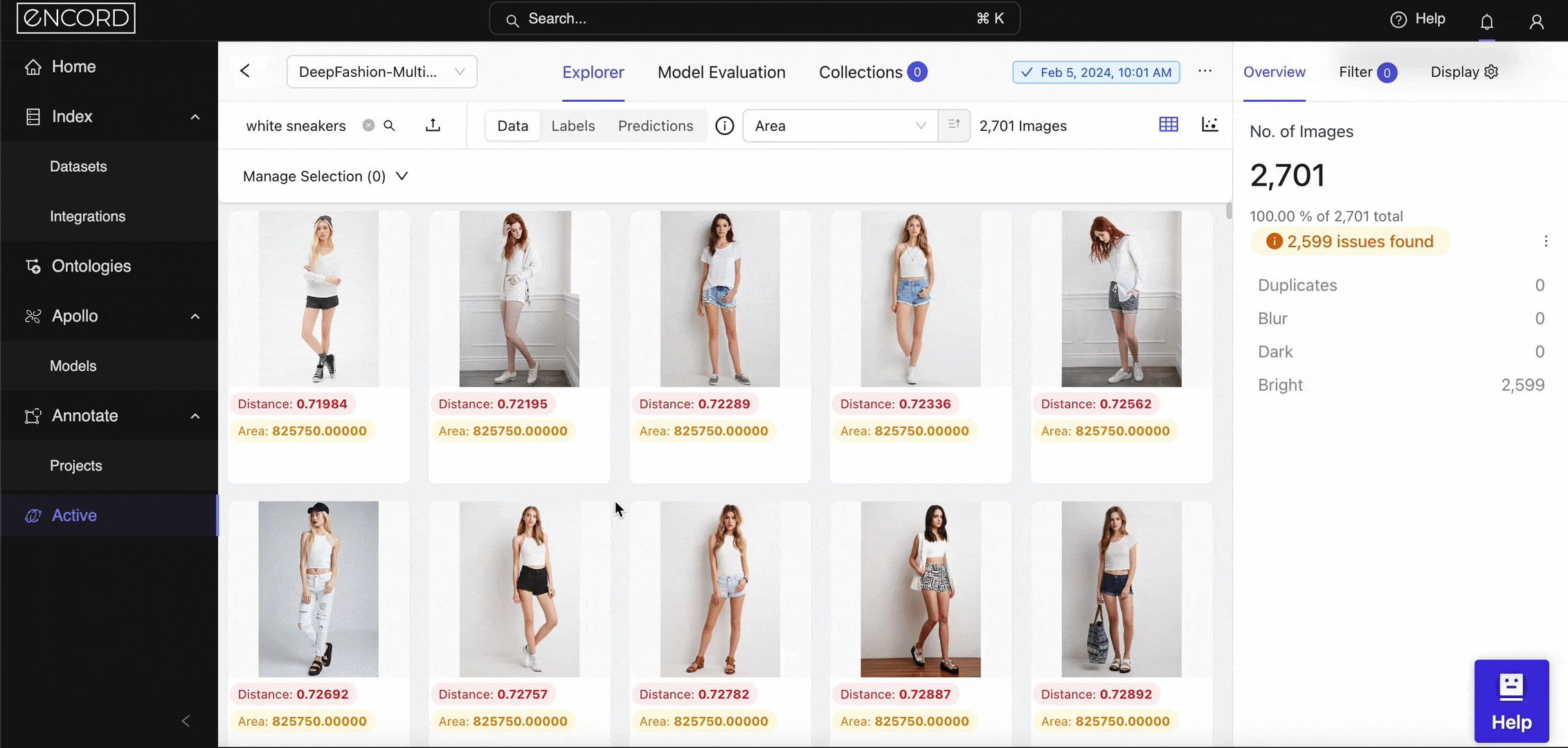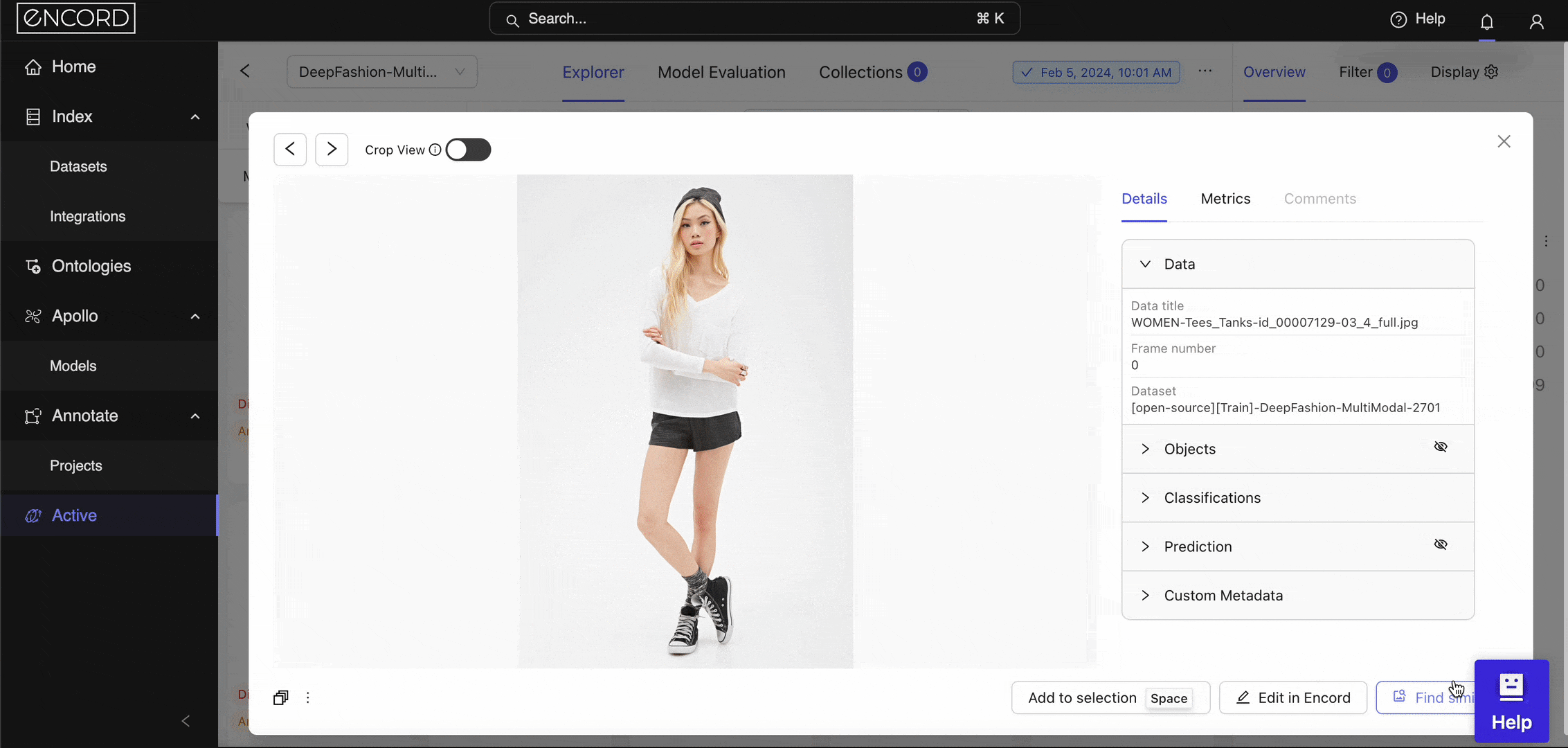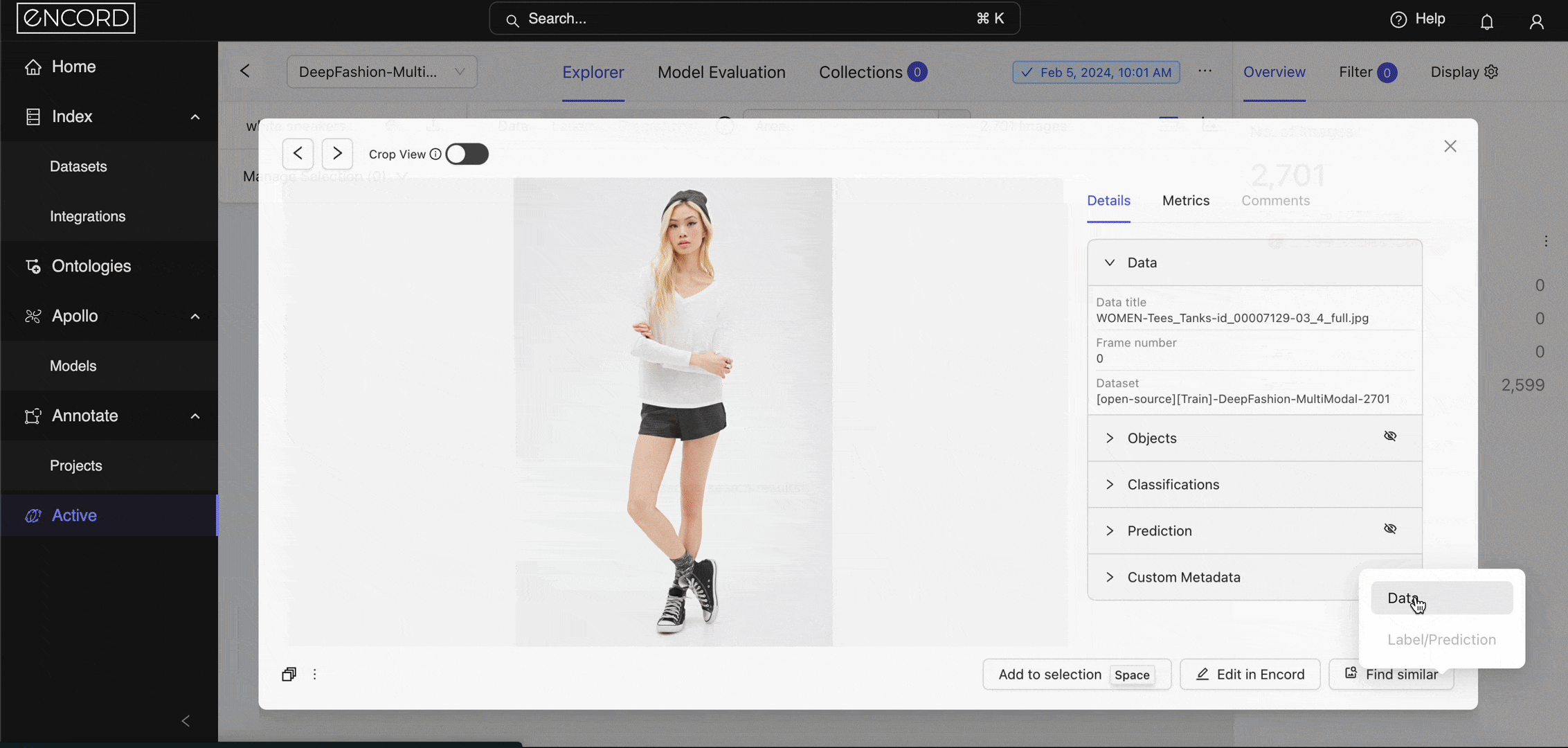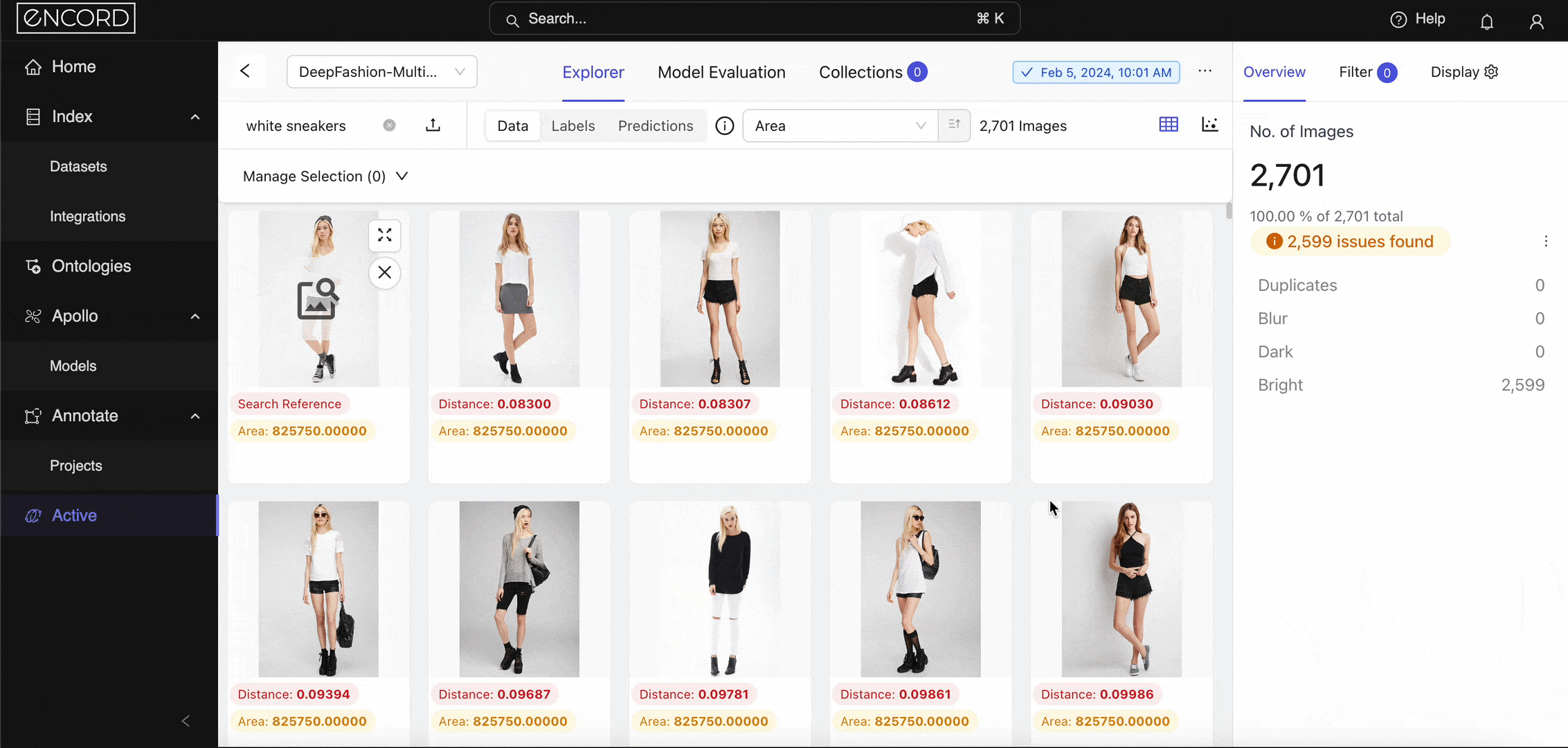
Image Similarity Search within Encord Active.
Reverse Image Search
Diffusion models can be harnessed for reverse image search, also known as content-based image retrieval, to find the source or visually similar images based on a given query image.
To facilitate reverse image search with diffusion models, a database of images needs to be preprocessed by encoding each image into a latent space using the reverse diffusion process. This latent representation captures each image's essential visual characteristics, allowing for efficient and accurate retrieval.
When a query image is provided for reverse image search, the model encodes it into the same latent space using reverse diffusion. By measuring the similarity between the query image's latent representation and the database images' latent representations using distance metrics (e.g., Euclidean distance), the model can identify and retrieve the most visually similar images from the database.
This application of diffusion models for reverse image search facilitates fast and reliable content-based retrieval, making it valuable for various applications, including image recognition, plagiarism detection, and multimedia databases.
Well-known Diffusion Models for Image Generation
Stable Diffusion

High-Resolution Image Synthesis with Latent Diffusion Models
Stable diffusion is a popular approach for image generation that uses diffusion models (DMs) and the efficiency of latent space representation. The method introduces a two-stage training process to enable high-quality image synthesis while overcoming the computational challenges associated directly operating in pixel space.
In the first stage, an autoencoder is trained to compress the image data into a lower-dimensional latent space that maintains perceptual equivalence with the original data. This learned latent space is an efficient and scalable alternative to the pixel space, providing better spatial dimensionality scaling properties.
By training diffusion models in this latent space, known as Latent Diffusion Models (LDMs), Stable Diffusion achieves a near-optimal balance between complexity reduction and detail preservation, significantly boosting visual fidelity.
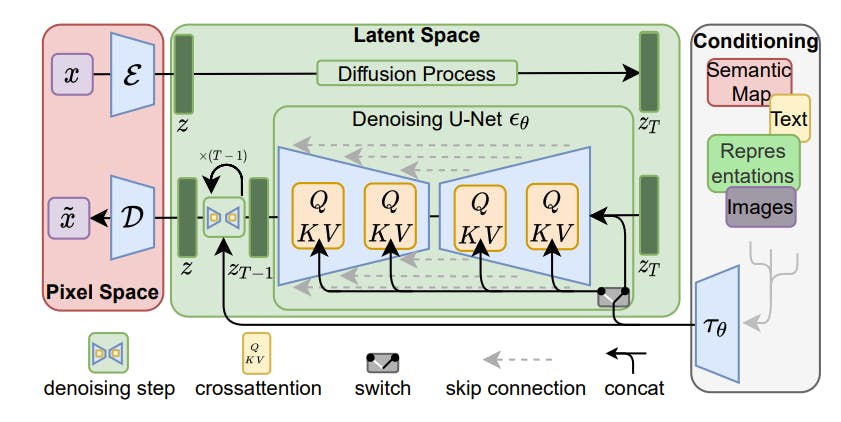
High-Resolution Image Synthesis with Latent Diffusion Models
Stable diffusion introduces cross-attention layers into the model architecture, enabling the diffusion models to become robust and flexible generators for various conditioning inputs, such as text or bounding boxes. This architectural enhancement opens up new possibilities for image synthesis and allows for high-resolution generation in a convolutional manner.
The approach of stable diffusion has demonstrated remarkable success in image inpainting, class-conditional image synthesis, text-to-image synthesis, unconditional image generation, and super-resolution tasks. Moreover, it achieves state-of-the-art results while considerably reducing the computational requirements compared to traditional pixel-based diffusion models.
DALL-E 2

Hierarchical Text-Conditional Image Generation with CLIP Latents
DALL-E 2 utilizes contrastive models like CLIP to learn robust image representations that capture semantics and style. It has a 2-stage model consisting of a prior stage that generates a CLIP image embedding based on a given text caption and a decoder stage.
The model's decoders use diffusion. These models are conditioned on image representations and produce variations of an image that preserve its semantics and style while altering non-essential details.
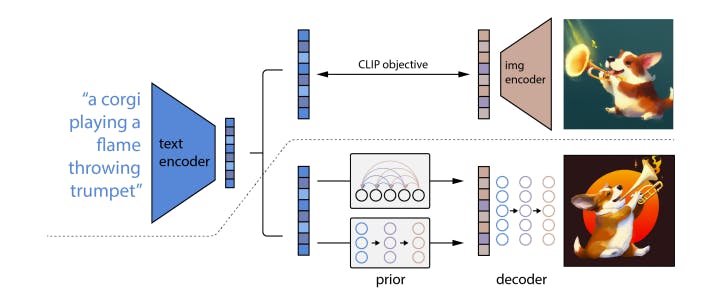
Hierarchical Text-Conditional Image Generation with CLIP Latents
The CLIP joint embedding space allows language-guided image manipulations to happen in a zero-shot way. This allows the diffusion model to create images based on textual descriptions without direct supervision.
Imagen

Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding
Imagen is a text-to-image diffusion model that stands out for its exceptional image generation capabilities. The model is built upon two key components: large pre-trained frozen text encoders and diffusion models.
Leveraging the strength of transformer-based language models, such as T5, Imagen showcases remarkable proficiency in understanding textual descriptions and effectively encoding them for image synthesis.
Imagen uses a new thresholding sampler, which enables the use of very large classifier-free guidance weights. This enhancement further enhances guidance and control over image generation, improving photorealism and image-text alignment.
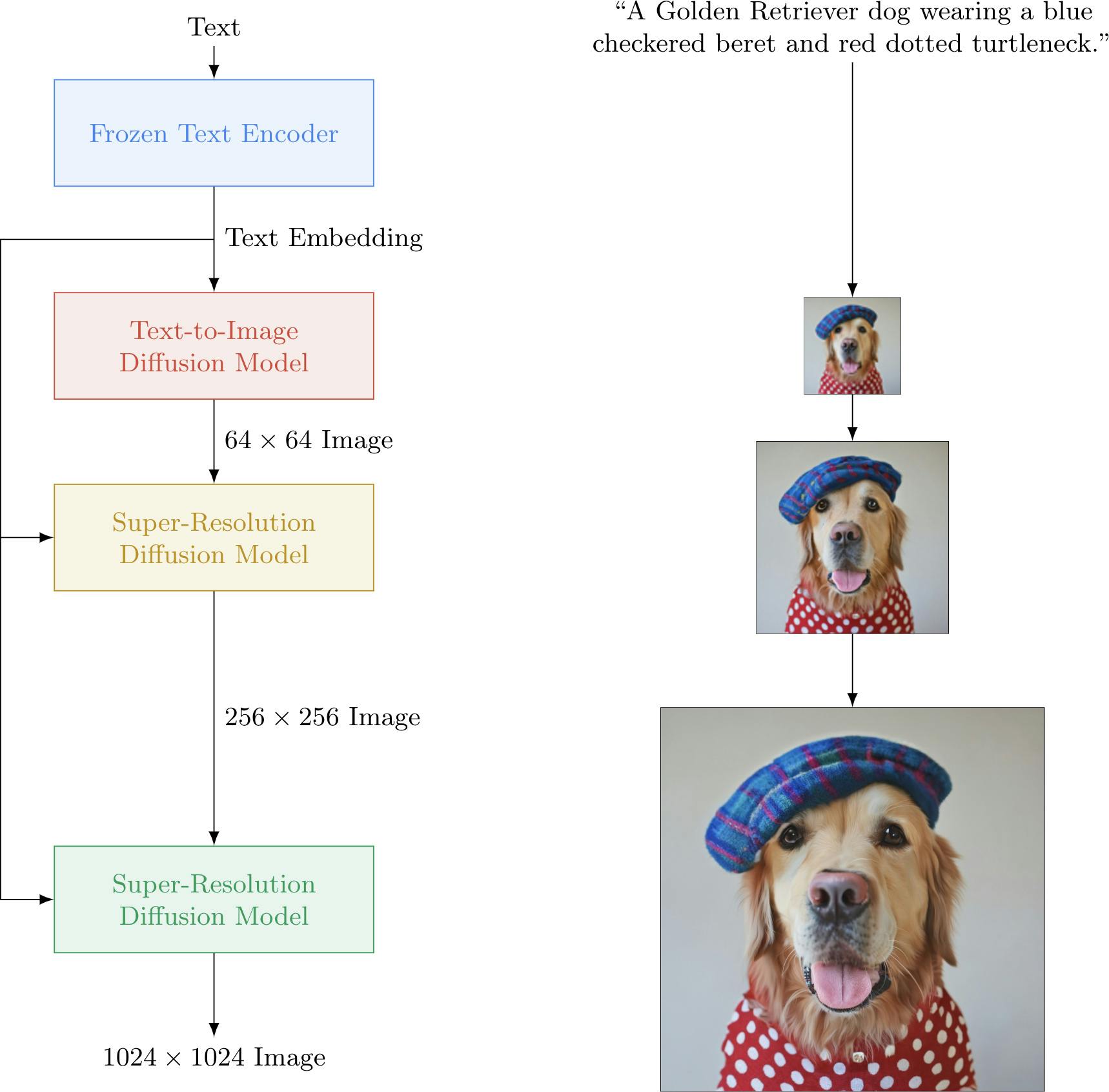
Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding
The researchers introduce a novel, Efficient U-Net architecture to address computational efficiency. This architecture is optimized for better computing and memory efficiency, leading to faster convergence during training.
U-Net: Convolutional Networks for Biomedical Image Segmentation
A significant research finding is the importance of scaling the pre-trained text encoder size for the image generation task. Increasing the size of the language model in Imagen substantially positively impacts both the fidelity of generated samples and the alignment between images and corresponding text descriptions.
This highlights the effectiveness of large language models (LLMs) in encoding meaningful representations of text, which significantly influences the quality of the generated images.
GLIDE
Guided Language to Image Diffusion for Generation and Editing (GLIDE) is another powerful text-conditional image synthesis model by OpenAI. It is a computer vision model based on diffusion models. GLIDE leverages a 3.5 billion-parameter diffusion model with a text encoder to condition natural language descriptions.
The primary goal of GLIDE is to generate high-quality images based on textual prompts while offering editing capabilities to improve model samples for complex prompts.

GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models
In the context of text-to-image synthesis, GLIDE explores two different guidance strategies: CLIP guidance and classifier-free guidance. Through human and automated evaluations, the researchers discovered that classifier-free guidance yields higher-quality images than the alternative. This guidance mechanism allows GLIDE to generate photorealistic samples that closely align with the text descriptions.
One notable application of GLIDE in computer vision is its potential to significantly reduce the effort required to create disinformation or Deepfakes. However, to address ethical concerns and safeguard against potential misuse, the researchers have released a smaller diffusion model and a noisy CLIP model trained on filtered datasets.
Diffusion Models: Key Takeaways
- Diffusion models are generative models that simulate how data is made by using a series of invertible operations to change a simple starting distribution into the desired complex distribution.
- Compared to traditional generative models, diffusion models have better image quality, interpretable latent space, and robustness to overfitting.
- Diffusion models have diverse applications across several domains, such as text-to-video synthesis, image-to-image translation, image search, and reverse image search.
- Diffusion models excel at generating realistic and coherent content based on textual prompts and efficiently handling image transformations and retrievals. Popular models include Stable Diffusion, DALL-E 2, and Imagen.
Frequently asked questions
Diffusion models are generative models used for data synthesis. They generate data by applying a sequence of transformations to random noise, producing realistic samples that resemble the training data distribution.
Diffusion models start with random noise and iteratively transform it using learned parameters. The process is akin to a Markov chain, refining the noise into realistic data samples through a sequential, autoregressive process.
Diffusion models have shown success in tasks like image synthesis, denoising, inpainting, and super-resolution. They are used to generate high-quality images and handle complex data distributions in various machine learning applications.
Training a diffusion model involves learning the parameters of its invertible transformations. This is achieved by optimizing a loss function that measures how well the model can transform noise into samples resembling the target data distribution.
Diffusion models offer benefits such as efficient training, stable convergence, and the ability to handle noisy data effectively. They provide a novel approach to generative modeling and have shown promise in various data generation tasks.