The Full Guide to Training Datasets for Machine Learning

Co-Founder & Co-CEO at Encord
In this article, we’ll explore why training data matters, how tools like Encord are transforming data annotation, and how you can accelerate your AI projects with cutting-edge automation. Read on to learn how to turn raw data into actionable insights and scalable AI solutions.
Training data is the initial training dataset used to teach a machine learning or computer vision algorithm or model to process information.
Algorithmic models, such as computer vision and AI models (artificial intelligence), use labeled images or videos, the raw data, to learn from and understand the information they’re being shown.
These models continue to refine their performance ⏤ , improving their decision-making and confidence ⏤ as they encounter new data and build upon what they learned from the previous data.
High-quality training data is the foundation of successful machine learning because the quality of the training data has a profound impact on any model’s development, performance, and accuracy. Training data is as crucial to the success of a production-ready model as the algorithms themselves because the quality and volume of the labeled training data directly influence the accuracy with which the model learns to identify the outcome it was designed to detect.
Training data guides the model: it’s the textbook and raw material from which the model gains its foundational knowledge. It shows the model patterns and tells it what to look for. After data scientists train the model, it should be able to identify patterns in never-before-seen datasets based on the patterns it learned from the training data.
Machine learning and AI-based models are the students. In this scenario, the teachers are human data scientists, data ops teams, and annotators. They’re turning the raw data into labeled data using data labeling tools. Like human students, machines perform better when they have well-curated and relevant examples to practice with and learn from.
If a computer vision model is trained on unreliable or irrelevant data, well-designed models can become functionally useless. As the old artificial intelligence adage goes: “garbage in, garbage out”.
Labeling is only one part of preparing training data. Curation, deciding what's worth labeling in the first place, happens before and around it. See our guide to Data Curation for how the two fit together.
How do we use a training dataset to train computer vision models?
Unsupervised Machine Learning Models
Unsupervised learning is when annotation and data science teams feed data into a model without providing it specific instructions or feedback on its progress. The training data is raw, meaning there are no annotations or identifying labels within the images and videos provided. So, the computer vision model trains without human guidance and discovers patterns independently. Unsupervised models can cluster and identify patterns in data, but they can’t perform tasks with a desired outcome. For instance, a data scientist can’t feed unsupervised model images of animals and expect the model to group them by species: the model might identify a different pattern and group them by color instead.

Unsupervised machine learning diagram (Source)
Supervised Machine Learning Models
Machine learning engineers build supervised learning models when the desired outcomes are predetermined, such as identifying a tumor or changes in weather patterns. In supervised learning, a human provides the model with labeled data and then supervises the machine learning process, providing feedback on the model’s performance.
Human-in-the-loop (HITL) is the process of humans continuing to work with the machine and help improve its performance. The first step is to curate and label the training data. One of the best ways to achieve this is by using data labeling tools, active learning pipelines, and AI-assisted tools to turn the raw material into a labeled dataset.

HTIL process (Source)
Labeling data allows the data science and ops team to structure the data in a way that makes it readable to the model. Within the training data, specialists identify a target ⏤ outcome that a machine learning model is designed to predict ⏤ , and they annotate objects in images and videos by giving them labels.
By labeling data, humans can point out important features in the images and videos (or any type of data) and ensure that the model focuses on those features rather than drawing incorrect conclusions about the data. Applying well-chosen labels is critical for guiding the model’s learning. For instance, if humans want a computer vision model to learn to identify different types of birds, then every bird that appears in the image training data needs to be labeled appropriately with a descriptive label.
After data scientists begin training the model to predict the desired outcomes by feeding it the labeled data, the “humans-in-the-loop” check its outputs to determine whether the model is working successfully and accurately. Active learning pipelines take a similar, albeit more automated, approach. In the same way that teachers help students prepare for an exam, the annotators and data scientists make corrections and feed the data back to the model so that it can learn from any inaccuracies.
By constantly validating the model’s predictions, humans can ensure that its learning moves in the correct direction. The model improves its performance through this continuous loop of feedback and practice.
Once the machine has been sufficiently trained, data scientists will test the model’s performance at returning real-world predictions by feeding it never-before-seen “test data.” Test data is unlabelled because data scientists don’t use it to tune the model: they use it to confirm that the model is working accurately. If the model fails to produce the right outputs from the test data, then data scientists know it needs more training before predicting the desired outcome.
What makes a good machine learning training dataset?
Because machine learning is an interactive process, it’s vital that the training data is applicable and appropriately labeled for the use case.
The curated data must be relevant to the problem the model is trying to solve. For instance, if a computer vision model is trying to identify bicycles, then the data must contain images of bicycles and, ideally, various types of bicycles. The cleanliness of the data also impacts the performance of a model. The model will make incorrect predictions if trained on corrupt or broken data or datasets with duplicate images. Lastly, as already discussed, the quality of the annotations has a tremendous effect on the quality of the training data. It’s one of the reasons labeling images is so time-consuming, and annotation teams are more effective when they have access to the right tools, such as Encord.
Encord specializes in creating high-quality training data for downstream computer vision models with various powerful AI-backed tools. When organizations train their models on high-quality data, they increase the performance of their models in solving real-world business problems.
Our platform has flexible ontology and easy-to-use annotation tools, so computer vision companies can create high-quality training data customized for their models without spending time and money building these tools in-house.
What’s the best way to create an image or video-based dataset for machine learning?
Creating, evaluating, and managing training data depends on having the right tools.
Encord’s computer vision-first toolkit lets customers label any computer vision modality in one platform. We offer fast and intuitive collaboration tools to enrich your data so that you can build cutting-edge AI applications. Our platform automatically classifies objects, detects segments, and tracks objects in images and videos.
Computer vision models must learn to distinguish between different aspects of pictures and videos, which requires them to process labeled data. The types of annotations they need to learn to vary depending on the task they’re performing.
Let’s take a look at some common annotation tools for computer vision tasks.
Image Classification: For single-label classification, each image in a dataset has one label, and the model outputs a single prediction for each image it encounters. In multi-label classification, each image has multiple labels which are not mutually exclusive.
Bounding boxes: When performing object detection, computer vision models detect an object and its location, and the object’s shape doesn’t need to be detailed to achieve this outcome, which makes bounding boxes the ideal tool for this task. With a bounding box, the target object in the image is contained within a small rectangular box accompanied by a descriptive label.

Bounding box annotation in Encord platform
Polygons/Segments: When performing image segmentation, computer vision models use algorithms to separate objects in the image from both their backgrounds and other objects. Mapping labels to pixel elements belonging to the same image helps the model break down the digital images into subgroups called segments. The shape of these segments matters, so annotators need a tool that doesn’t restrict them to rectangles. With polygons, an annotator can create tight-knit outlines around the target object by plotting points on the image vertices.

Polygon annotation of brain in Encord platform
Encord’s platform provides annotation tools for a variety of computer vision tasks, and our tools are embedded in the platform, so users don’t have to jump through any hoops before accessing model-assisted labeling.
Because the platform supports various data formats, including images, videos, SAR, satellite, thermal imaging, and DICOM images (X-Ray, CT, MRI, etc.), it works for a wide range of computer vision applications.
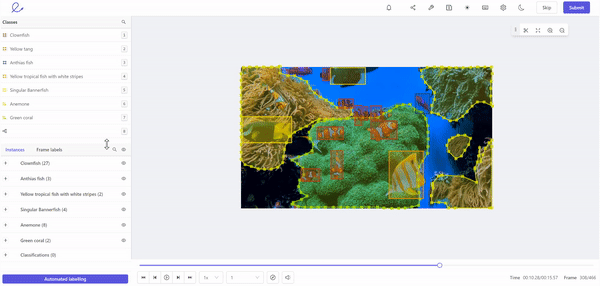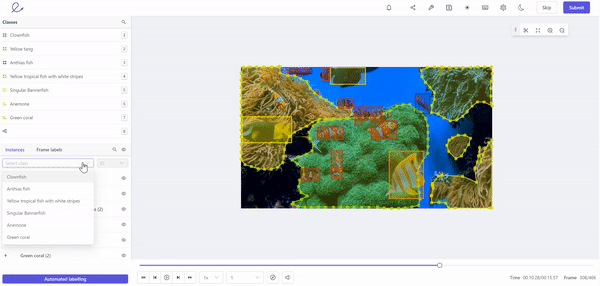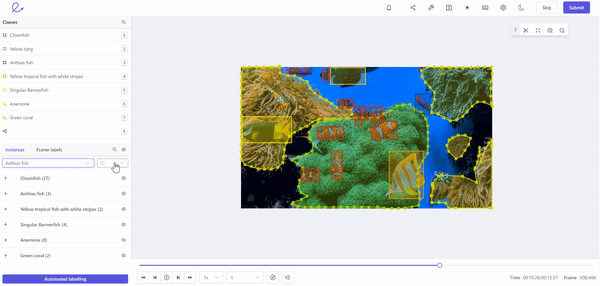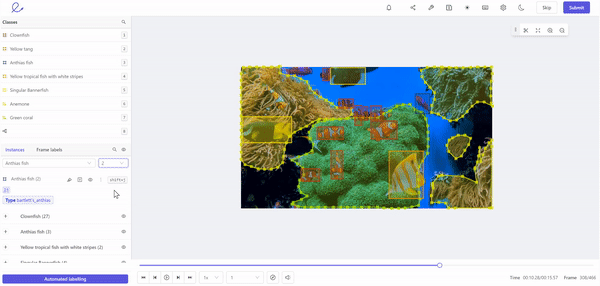
Labeling training data for machine learning in Encord
How to create better training datasets for your machine learning and computer vision models
While there’s no shortage of data in the world, most of it is unlabelled and thus can’t actually be used in supervised machine learning models. Computer vision models, such as those designed for medical imaging or self-driving cars, need to be incredibly confident in their predictions, so they need to train on vast amounts of data. Acquiring large quantities of labeled data remains a serious obstacle to the advancement of AI.
Because every incorrect label has a negative impact on a model’s performance, data annotators play a vital role in the process of creating high-quality training data. Hence the importance of quality assurance in the data labeling process workflow.
Ideally, data annotators should be subject-matter experts in the domain for which the model is answering questions. In this scenario, the data annotators ⏤ , because of their domain expertise, ⏤ understand the connection between the data and the problem the machine is trying to solve, so their labels are more informative and accurate.
Data labeling is a time-consuming and tedious process. For perspective, one hour of video data can take humans up to 800 hours to annotate. That creates a problem for industry experts who have other demands on their time. Should a doctor spend hundreds of hours labeling scans of tumors to teach a machine how to identify them? Or should a doctor prioritize doctor-human interaction and spend those hours providing care to the patients whose scans clearly showed malignancies?
Data labeling can be outsourced, but doing so means losing the input of subject-matter experts, which could result in low-quality training data if the labeling requires any industry-specific knowledge. Another issue with outsourcing is that data labeling jobs are often in developing economies, and that scenario isn’t viable for any domain in which data security and privacy are important. When outsourcing isn’t possible, teams often build internal tools and use their in-house workforces to label their data manually, which leads to cumbersome data infrastructure and annotation tools that are expensive to maintain and challenging to scale.
The current practice of manually labeled training data isn’t sufficient or sustainable. Using a unique technology called micro-models, Encord solves this problem and makes computer vision practical by reducing the burden of manual annotation and label review. Our platform automates data labeling, increasing its efficiency without sacrificing quality.

Using micro-models to automate data labeling for machine learning
Encord uses an innovative technology solution called micro-models to build its automation features. Micro-models allow for quick annotation in a “semi-supervised fashion”. In semi-supervised learning, data scientists feed machines a small amount of labeled data in combination with a large amount of unlabelled data during training.
The micro-model methodology comes from the idea that a model can produce strong results when trained on a small set of purposefully selected and well-labeled data. Micro-models don’t differ from traditional models in terms of their architecture or parameters, but they have different domains of applications and use cases.
A knee-jerk reaction from many data scientists might be that this goes against “good” data science because a micro-model is an overfit model. In an overfit model, the algorithm can’t separate the “signal” (the true underlying pattern data scientists wish to learn from the data) from the “noise” (irrelevant information or randomness in a dataset). An overfit model unintentionally memorizes the noise instead of finding the signal, meaning that it usually makes poor predictions when it encounters unseen data.
Overfitting a production model is problematic because if a production model doesn't train on a lot of data that resembles real-world scenarios, then it won’t be able to generalize. For instance, if data scientists train a computer vision model on images of sedans alone, then the model might not be able to identify a truck as a vehicle.
However, Encord’s micro-models are purposefully overfitted. They are annotation-specific models intentionally designed to look at one piece of data, identify one thing, and overtrain that specific task. They wouldn’t perform well on general problems, but we didn’t design them to apply to real-world production use cases. We designed them only for the specific purpose of automating data annotation. Micro-models can solve many different problems, but those problems must relate to the training data layer of model development.
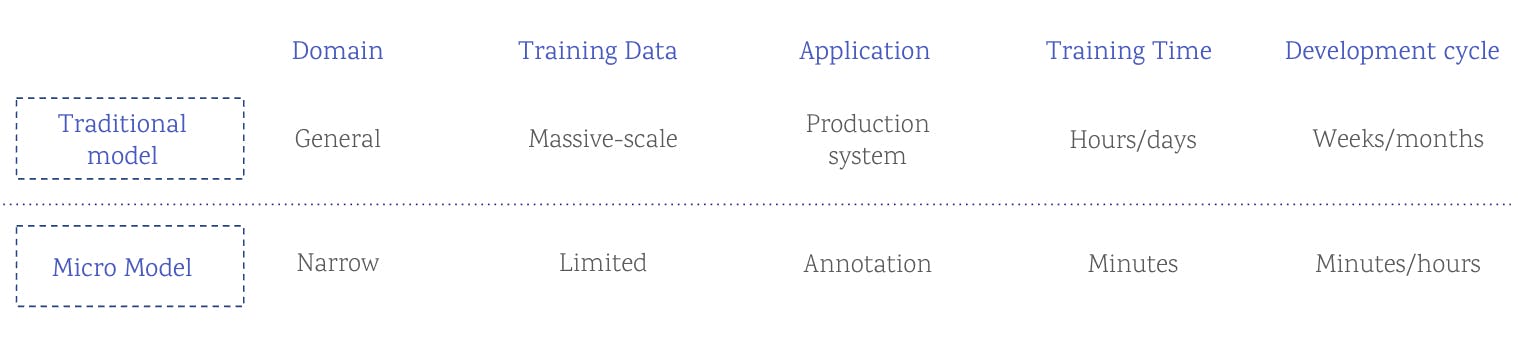
Comparing traditional and micro models for creating machine learning training data
Because micro-models don’t take much time to build, require huge datasets, or need weeks to train, the humans in the loop can start training the micro-models after annotating only a handful of examples. Micro-models then automate the annotation process. The model begins training itself on a small set of labels and removes the human from much of the validation process. The human reviews a few examples, providing light-touch supervision, but mostly the model validates itself each time it retrains, getting better and better results.
With automated data labeling, the number of labels that require human annotation decreases over time because the system gets more intelligent each time the model runs.
When automating a comprehensive annotation process, Encord strings together multiple micro-models. It breaks each labeling task into a separate micro-model and then combines these models. For instance, to classify both airplanes and clouds in a dataset, a human would train one micro-model to identify planes, create and train another to identify clouds, and then chain them together to label both clouds and planes in the training data.
Production models need massive amounts of labeled data, and the reliance on human annotation has limited their ability to go into production and “run in the wild.”
Micro-models can change that.
With micro-models, users can quickly create training data to feed into downstream computer vision models.
Using Encord’s micro-models and AI-assisted labeling tools, clinicians increased annotation output speeds, completing the task 6.4x faster than when manual labeling. In fact, only three percent of the datasets required manual labeling from clinicians.
Encord’s technology not only saved the clinicians a lot of valuable time but also provided King’s College with access to training data much more quickly than had the institution relied on a manual annotation process. This increased efficiency allowed King’s College to move the AI into production faster, cutting model development time from one year to two months.
Encord is a comprehensive AI-assisted platform for collaboratively annotating data, orchestrating active learning pipelines, fixing dataset errors, and diagnosing model errors & biases. Try it for free today.
Frequently asked questions
High-quality training data is critical for the accuracy, performance, and development of machine learning models. Poor-quality or irrelevant training data can lead to unreliable models, as the adage goes: “garbage in, garbage out.”
Supervised Learning: Models are trained with labeled data and guided by humans to achieve specific outcomes, such as identifying objects or predicting trends.
Unsupervised Learning: Models learn from unlabeled data without human intervention. They discover patterns independently but cannot predict specific outcomes.
Human-in-the-loop refers to the process of involving human annotators and data scientists in the training process. They curate, label, and validate data to guide the model’s learning, ensuring accuracy and relevance.
Micro-models are intentionally overfit models designed for specific annotation tasks. They automate the data labeling process by training on small, well-labeled datasets, reducing the need for extensive human intervention and accelerating the annotation process.
Test data is unlabeled data used to evaluate a model's performance on real-world scenarios. It ensures the model can generalize and make accurate predictions beyond the training dataset.
Data labeling is crucial in enhancing forecasting models for self-driving vehicles, and Encord simplifies this process. By providing a user-friendly interface for annotating data, Encord enables teams to identify and label critical behaviors, such as actors' intentions, which improves the accuracy of models and ultimately leads to safer autonomous driving decisions.
Encord addresses challenges in production data annotation by providing tools that streamline the process where models escalate uncertain predictions to human annotators. This human-in-the-loop component is essential as the outputs are used for real-time delivery to customers and can also be leveraged for future model training.
Encord supports machine learning model development by offering robust data annotation tools that facilitate the collection and preparation of labeled datasets. Our platform is designed to improve the efficiency of the annotation process, enabling teams to focus on building and refining their models.
Encord's platform is designed to streamline the data annotation process, enabling teams to annotate data quickly and efficiently. This is achieved through advanced tools that facilitate collaboration and improve workflow management, ultimately helping teams build better models faster.
Encord offers advanced automatic annotation solutions designed to streamline the annotation process, particularly for clients dealing with large-scale data. These solutions minimize manual effort while maintaining high accuracy, allowing users to focus on higher-level tasks.
In Encord's platform, data labeling is an integral part of the training process, but the platform is designed to minimize the amount of data needed for effective training. Users can focus on labeling key images, which allows for quicker model optimization and deployment.
Encord aims to reduce costs in data annotation by offering efficient tools and workflows that streamline the annotation process. Through automation and optimized resource management, teams can achieve higher output at lower costs, ultimately improving project economics.
Encord offers robust labeling tooling that streamlines the labeling and enrichment process. Users can isolate specific text and graphical elements, making it easier to manage complex datasets and ensuring accurate annotations for machine learning models.
Encord's platform supports the annotation of a variety of data types, including text, numbers, images, and even tabular data. This flexibility allows organizations to tailor their annotation efforts based on the specific needs of their AI projects.
Encord ensures high-quality data by combining automated pre-labeling with manual adjustments and rigorous tracking of the labeling process. This approach helps users collect clean, well-enriched datasets ready for model training.