Contents
What is a Dataset for Machine Learning (ML)?
What is a Classification Dataset?
Should I use Synthetic Data to Train my Machine Learning and Computer Models?
Where Can I Find Datasets For Machine Learning?
Encord Blog
Best Datasets for Computer Vision [Industry breakdown]



Image and video dataset annotations are crucial for training machine learning (ML) models for computer vision. One of the challenges is finding the best possible, highest-quality datasets to annotate to start training your model.
The good news is, there are dozens of free and open-source image and video-based public datasets for machine learning models you can use.
Whether you use a public dataset depends on your project goals and the problem you are trying to solve. Your project might need proprietary in-house data, or commercial specialist datasets to solve a particular problem.
However, there are numerous use cases where public, open-source datasets that have already been annotated are ideal for training computer vision models.
Organizations in dozens of sectors — insurance, healthcare, smart cities, retail, sports, and many others — are already using public datasets to train ML models and solve image and video-related big data challenges.
In this post, we take a closer look at the best open-source and free datasets for machine learning models across numerous sectors, such as healthcare and insurance, and review the actions you should take once you have found a suitable dataset for your project.
What is a Dataset for Machine Learning (ML)?
Datasets used to train machine learning (ML), artificial intelligence (AI), and other algorithmically-based models can be anything from spreadsheets to a repository of videos. A dataset is simply a way of saying that you have a collection of data, regardless of the format.
In the case of computer vision (CV) and ML models, datasets usually contain thousands of images or videos or both. Training an ML-based model to solve a particular problem means ensuring you’ve picked the right type of images or videos, in the most suitable format, with the highest quality of annotations and labels possible to produce the results you want.
Poor quality data — or thousands of irrelevant images or videos within a dataset — will generate negative project outcomes. ML projects often work on tight deadlines. Using a public dataset saves time, as there are far fewer data cleansing tasks, so it’s a shortcut to having a proof of concept (POC) project up and running.
However, you need to ensure the images or videos contained within any datasets you are going to use are relevant to your project goals. You need to ensure the annotations, labels, and metadata are high quality, with sufficient modalities, and object types.
It’s also important that there is a sufficient range of images or videos to reduce bias and produce the answers you need once this data is fed into an ML model. Datasets should also contain a wide range of images or videos under different conditions, e.g. light, dark, day, night, shadows, etc. Higher quality data produces better ML and CV project outcomes.
What is a Classification Dataset?
A classification dataset is a dataset that’s used to categorize a specific object amongst a range of options. With image classification, the image is the input and the output is a label applied to an object or objects within that image.
Image classification datasets are used to train ML-based or other algorithmically-generated models to identify with a high degree of accuracy the object(s) you are looking for.
For example, if you’re looking for images that identify a specific make and model of a car, you need a dataset with enough images containing that car, alongside hundreds or thousands of images of cars that are not that make or model.
In this scenario, it would be a waste of time to show ML models thousands of images of tractors when you need it to identify a specific type of car. Hence the importance of picking the right dataset for your ML project.
Should I use Synthetic Data to Train my Machine Learning and Computer Models?
ML, AI, and computer vision models are data intensive. Even when you use micro-models to train them, when it comes to solving problems at scale, you need A LOT of data.
But in some use cases, that simply isn’t possible. How many images and videos of things that don’t happen very often or even exist anymore have made their way into datasets? The answer is ‘not many’. Not enough to train an ML-based model accurately, without bias, and dozens of other problems occur when a model doesn’t have enough data to learn from.
In edge cases such as this, ML teams need synthetic data.
For more information, here’s An Introduction to Synthetic Training Data
Synthetic data solves the problems of difficult-to-find datasets, such as pictures of pedestrians' shadows, rare diseases, or car crashes. Synthetic data is manufactured images and videos, useful when edge cases need hundreds of thousands of images or videos, and yet only a few thousand exist in reality.
Computer-generated images (CGI), 3D games engines — such as Unity and Unreal — and Generative adversarial networks (GANs) are ideal solutions for this problem. Of course, the tools used to create these images or videos depend on your budget and how much time you have to create synthetic data. You can also buy custom or ready-made synthetic data that should fill your imaging dataset gaps and help train an ML model more effectively.
Now let’s take a look at the dozens of options we’ve found for sourcing open-source public datasets for machine learning.
Where Can I Find Datasets For Machine Learning?
To make these dataset sources easier to find, we have broken this list down according to sectors:
- Insurance
- Sports
- SAR (Synthetic Aperture Radar)
- Smart cities and autonomous vehicles
- Retailers and manufacturers
- Medical and healthcare
- Open dataset aggregators
Let’s dive in . . .
Insurance Machine Learning Datasets
Car Damage Assessment Dataset
On Kaggle, one of the best places to find high-quality datasets (both balanced and imbalanced), there are dozens of image and video files available to download for free. Kaggle is a data science community with hundreds of resources for professionals in this field, including open-source datasets, making it an open dataset aggregator.
One of these datasets is ideal for car insurance data analysts and data scientists. It’s a folder of 1,500 unique RGB images (224 x 224 pixels) split into a training and validation subset. It contains classifications such as broken headlamps, glass shatter, dumper dent, and all of the most common car damage categories.
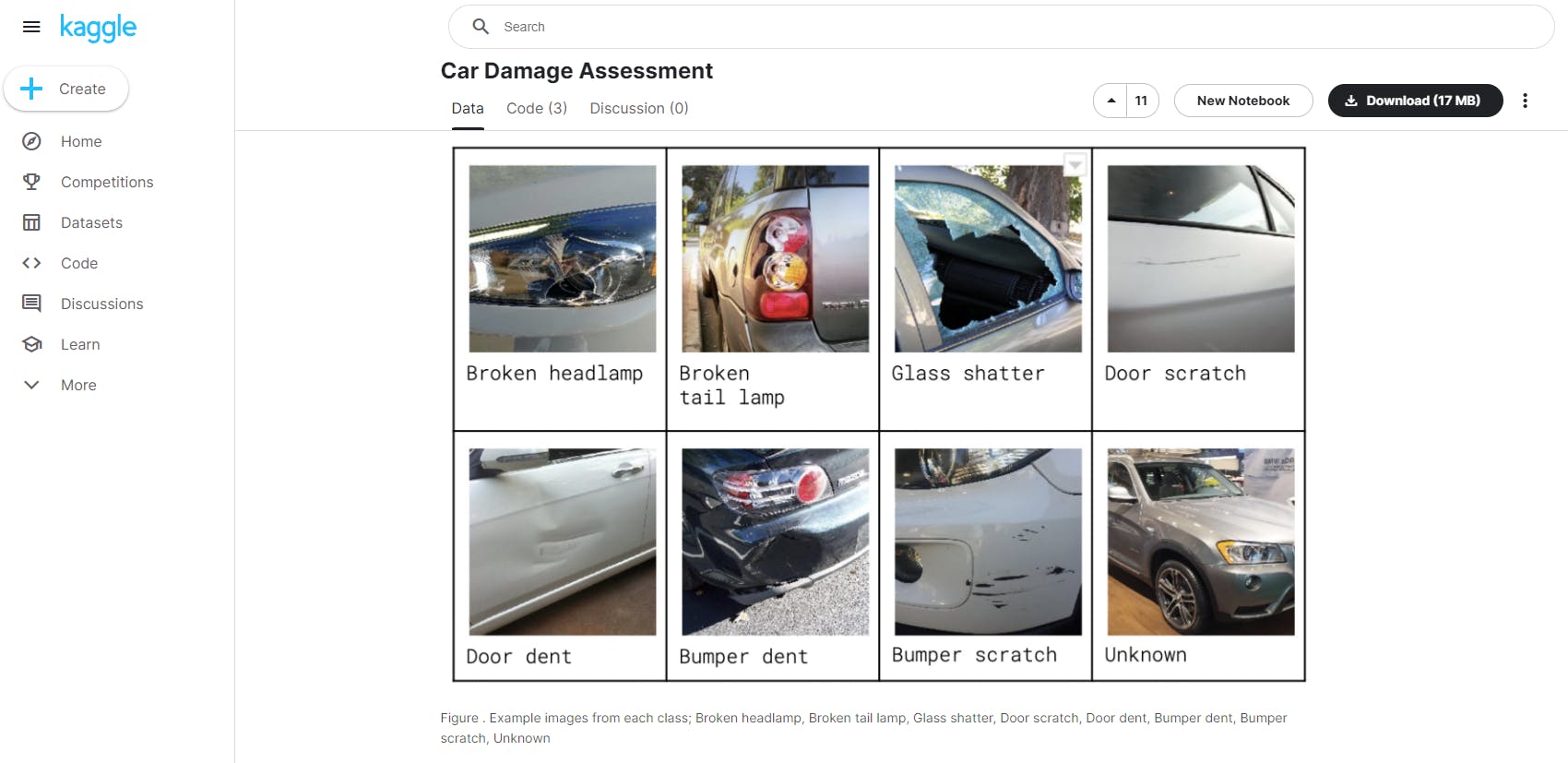
Car Damage Assessment Dataset
Sports Analytics Datasets
KTH (KTH Royal Institute of Technology, Stockholm) Multiview Football Dataset I & II
This dataset contains thousands of images of football players during an Allsvenskan League professional game. It includes one dataset with images with ground truth pose in 2D and the other dataset with ground truth pose in both 2D and 3D. Datasets such as this can help train computer vision models on Human Pose Estimation (HPE) techniques.
It includes around 7,000 images, dozens of annotated joints and players, an orthographic camera matrix for each frame, and images calibrated and synchronized.
The open-source provider of this dataset, the KTH Royal Institute of Technology, says it can’t be used for commercial purposes, only academia and research.
OpenTTGames Dataset
The OpenTTGames Dataset was created for the evaluation of computer vision tasks for the game of table tennis. It is designed to help ML scientists and data ops managers with table tennis projects evaluate the following: “ball detection, semantic segmentation of humans, table and scoreboard and fast in-game events spotting.”
It includes 5 videos between 10 and 25 minutes in length, fully annotated, markup files provided, and 7 short testing/training annotated videos.
SAR (Synthetic Aperture Radar), Overhead, Satellite Datasets
Open-source image datasets are one of the best places for organizations that need overhead satellite images, such as those captured by synthetic aperture radar (SAR). Here are some of the most valuable sources of annotated satellite imagery datasets:
xView
xView is one of the largest publicly available datasets of overhead and satellite imagery. It contains images from complex scenes around the world, annotated using bounding boxes. xView includes over 1 million object instances, 60 classes, and a 0.3 meter resolution.
xView3
xView3 is a dataset that contains approximately 1000 scenes from maritime regions of interest. Each scene consists of two SAR images (VV, VH); and each scene also includes five ancillary images: bathymetry, wind speed, wind direction, wind quality, and land/ice mask.
The xView3 maritime image dataset was sourced from synthetic aperture radar (SAR) imagery from the Copernicus Sentinel-1 mission of the European Space Agency (ESA), taken from two polar-orbiting satellites, with images taken in every weather conditions, every day and night. The resolution is 20 meters, and it’s a useful dataset for detecting ships against sea clutter, while also being useful for identifying near-shore and sea/ocean surface features.
EU Copernicus Constellation
Copernicus is a European Union (EU) funded project, whereby a constellation of satellites are taking thousands of pictures every day, building a vast database of marine, land, and air-based images. Consequently, Copernicus is one of the largest image-based dataset creators in the world, producing 16 terabytes of data per day.
The majority of images Copernicus produces are “made available and accessible to any citizen, and any organization around the world on a free, full, and open basis.”
Smart Cities & Autonomous Vehicles ML Datasets
BDD100K
Berkeley DeepDrive is a diverse and extensive dataset for heterogeneous multitask learning. It contains over 100,000 driving videos collected from 50,000 car journeys. Each is 40-seconds long, 30fps, with over 100 million frames in total.
Videos in this dataset include city streets, residential areas, highways, and every type of weather condition. The dataset includes: “lane detection, object detection, semantic segmentation, instance segmentation, panoptic segmentation, multi-object tracking, segmentation tracking, and more.”
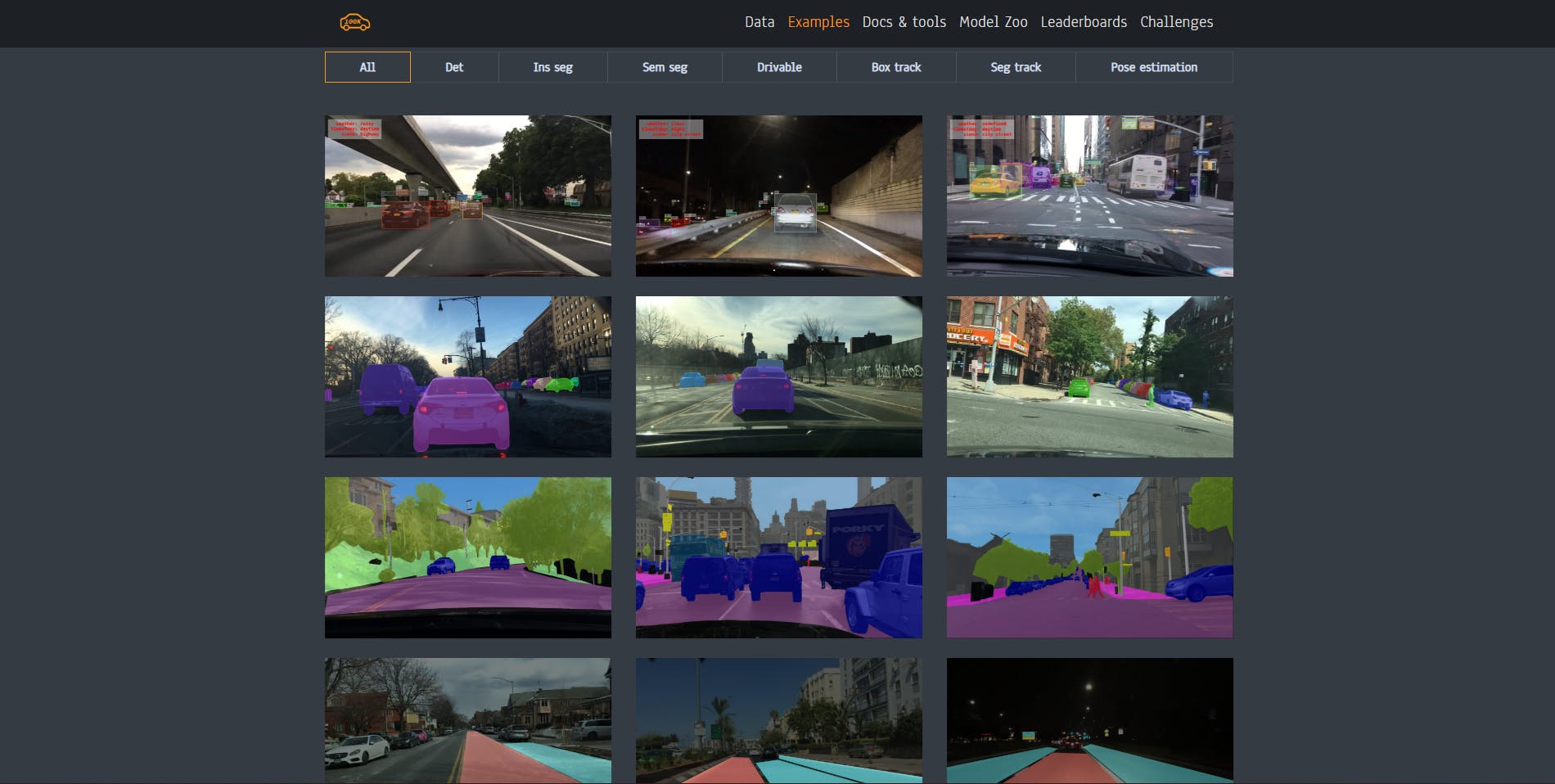
BDD100K Dataset
The KITTI Vision Benchmark Suite
The KITTI benchmark dataset contains a suite of vision tasks built using and for autonomous driving platforms. The full benchmark contains many tasks such as stereo, optical flow, visual odometry, and numerous others. This dataset contains the object detection dataset, including the monocular images and bounding boxes. The dataset contains 7481 training images annotated with 3D bounding boxes. This project was developed by the Karlsruhe Institute of Technology and Toyota Technological Institute in Chicago, with a car driving around a mid-size city equipped with several cameras and sensors.
Datasets for Retailers & Manufacturers
RPC-Dataset Project
The RPC dataset project is a large-scale and fine-grained retail product checkout dataset, one of the most extensive datasets in terms of both product image quantity and product categories. The dataset was created to solve the problem of images aligning with product databases at automated checkouts (ACOs).
The test dataset contains 24,000 images, and there are a further 6,000 validation images, plus 53,739 training dataset images. Within the images are several layers of annotations, labels, and over 300,000 objects.
Zalando Fashion MNIST (on Kaggle)
The Zalando Fashion MNIST dataset of Zalando's clothing images—consists of a training set of 60,000 examples, and a test set of 10,000 annotated and labeled fashion images. Each example is a 28x28 grayscale image, associated with a label from 10 classes.
MNIST databases are popular amongst the AI/ML and computer vision community to validate training datasets. In this case, it’s useful for CV projects that need to use fashion image datasets.
For even more fashion and retail datasets, here’s a list of 12 free retail datasets for computer vision models.
Medical Imaging Datasets
The Cancer Imaging Archive (TCIA)
The Cancer Imaging Archive (TCIA) is a service that de-identifies cancer images (by removing patient data) and makes them available for free download. Hospitals and other medical providers can upload data to this public research project.
With TCIA, healthcare companies and researchers can access thousands of cancer datasets in several ways, including through a portal and an API.
NIH Chest X-Rays (on Kaggle)
The National Institute of Health Chest X-Ray Dataset contains 112,000 chest X-ray images from over 30,000 patients. Natural Language Processing (NLP) was used to annotate text-mine disease classifications from the associated radiological reports, with a 90% accuracy rating.
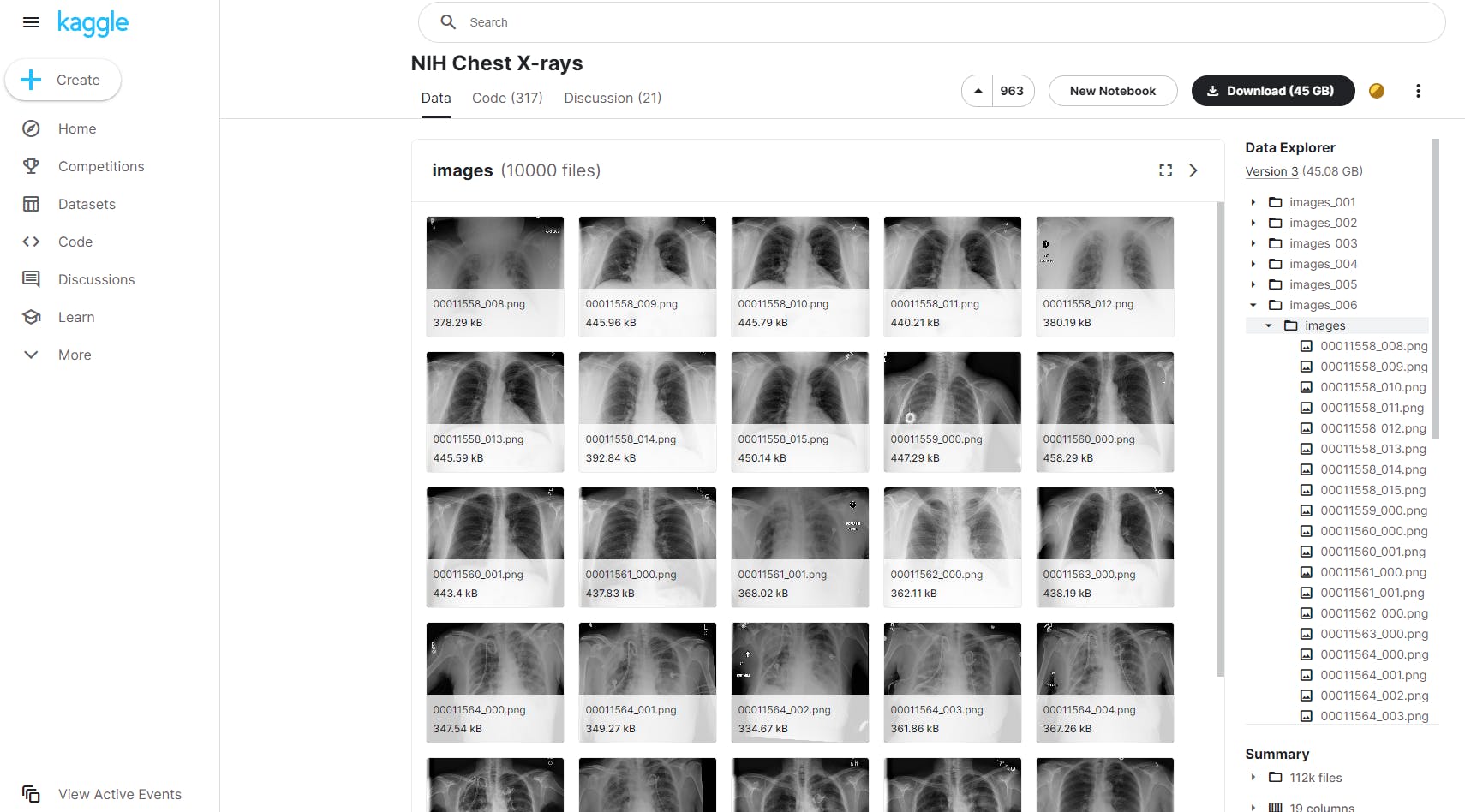
NIH Chest X-Rays Dataset
And finally, here’s a list of popular open dataset aggregators for machine learning models.
{{cta}}
Open Dataset Aggregators
Kaggle
Kaggle is a community of ML practitioners and students, containing thousands of open-source datasets from dozens of sectors and verticals. You will need to drill down to search for an image or video-specific datasets that you can use for your project, depending on your particular project goals. It’s a valuable resource and research tool for the ML and computer vision community.
OpenML
OpenML is an open platform for sharing and finding machine learning, image, and video-based datasets. It’s open and free to use, for anyone and any purpose. Every dataset on the platform is uniformly formatted with rich metadata included, suitable to be uploaded into any tool, and to train any kind of ML, AI, or Computer Vision model.
And there we go, an extensive list of open-source image and video datasets!
Free for anyone and any organization to use, for almost any purpose, including commercial, in most cases. We hope you have found it useful!
Ready to automate and improve the quality of your data annotations?
Sign-up for an Encord Free Trial: The Active Learning Platform for Computer Vision, used by the world’s leading computer vision teams.
AI-assisted labeling, model training & diagnostics, find & fix dataset errors and biases, all in one collaborative active learning platform, to get to production AI faster. Try Encord for Free Today.
Want to stay updated?
Follow us on Twitter and LinkedIn for more content on computer vision, training data, and active learning.
Join our Discord channel to chat and connect.
Data infrastructure for multimodal AI
Click around the platform to see the product in action.
Written by

Frederik Hvilshøj
Explore our products
Index
Manage & curate your data
Understand and manage your visual data, prioritize data for labeling, and initiate active learning pipelines.
Annotate
Supporting your labeling needs
Super charge your data annotation with AI-powered labeling — including automated interpolation, object detection and ML-based quality control.
Active
Find & fix data issues with ease
Monitor, troubleshoot, and evaluate the data and labels impacting model performance.