Self-supervised Learning Explained

ML Lead at Encord
Self-supervised learning (SSL) is an AI-based method of training algorithmic models on raw, unlabeled data. Using various methods and learning techniques, self-supervised models create labels and annotations during the pre-training stage, aiming to iteratively achieve an accurate ground truth so a model can go into production.
If you struggle with finding the time and resources to annotate and label datasets for machine learning projects, SSL might be a good option. It's not unsupervised, and it doesn't require a time-consuming data labeling process.
In this self-supervised learning explainer from Encord, we’re going to cover:
- What is self-supervised learning?
- How it differs from supervised and unsupervised learning?
- Benefits and limitations of self-supervised learning;
- How does self-supervised learning work?
- Use cases, and in particular, why do computer vision projects need self-supervised learning?
Let’s dive in...

What is Self-Supervised Learning?
Self-Supervised Learning (SSL) is a machine learning (ML) training format and a range of methods that encourage a model to train from unlabeled data.
Instead of a model relying on large volumes of labeled and annotated data (in the case of supervised learning), it generates labels for the data based on the unstructured inputs.
In computer vision (CV), you could train an ML model using greyscale images, or half an image, so that it will accurately predict the other half or what colors go where.
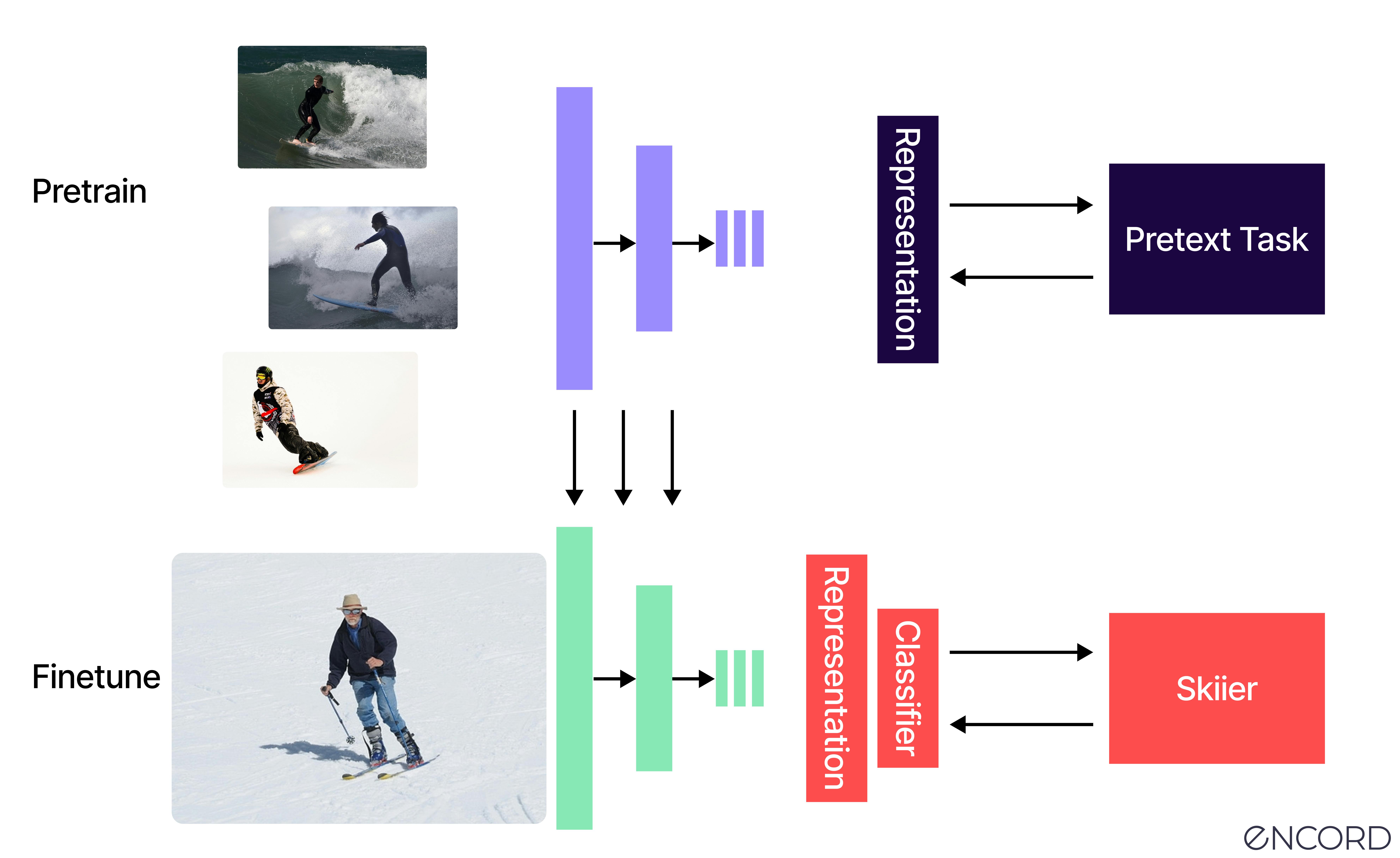
Self-supervised learning is particularly useful in computer vision and natural language processing (NLP), where the amount of labeled data required to train models can be prohibitively large. Training models on less data using a self-supervised approach is more cost and time-effective, as you don’t need to annotate and label as much data.
If you’re annotating enough data for a model to learn and it’s producing accurate results through an iterative process to come to the ground truth, you can achieve a production-ready model more quickly.
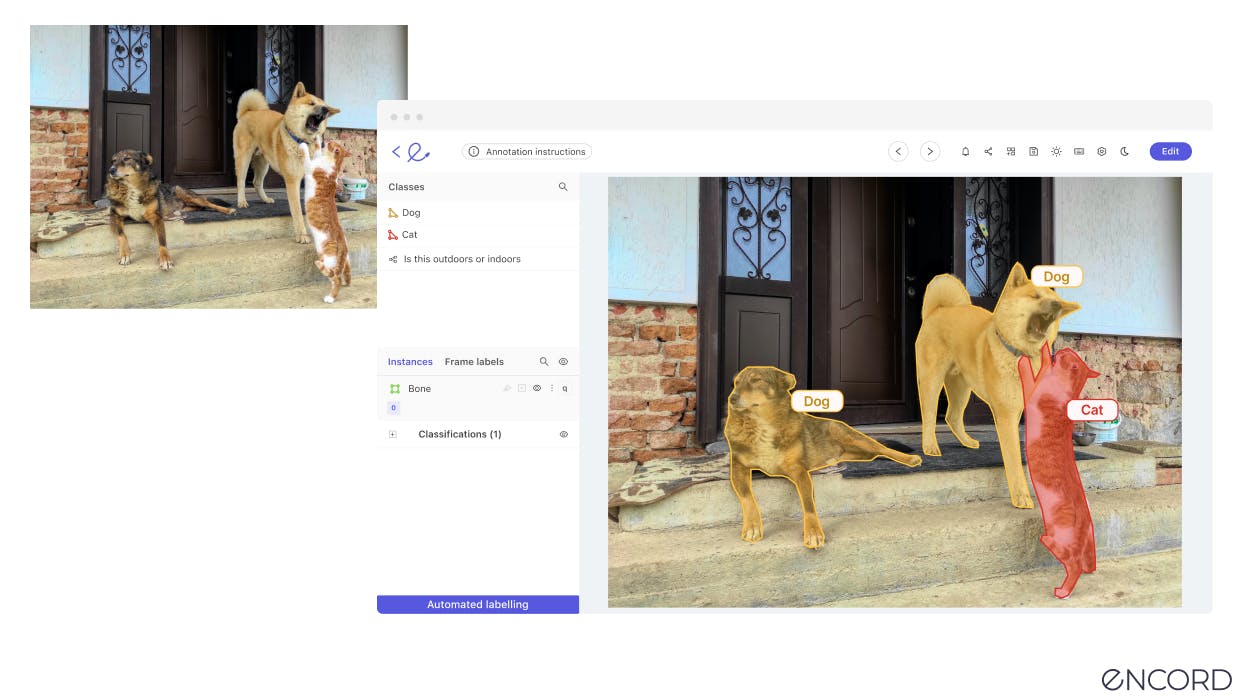
Comparing Self-Supervised Learning With Supervised Learning & Unsupervised Learning
Before we go in-depth into self-supervised learning, it’s useful to compare it with the two main alternatives: supervised and unsupervised learning.
Supervised Learning requires training an artificial intelligence (AI), machine learning (ML), computer vision (CV), or another algorithmically-generated model on high-quality labeled and annotated data. This labeled data is fed into the model in a supervised fashion, whereby human ML engineers are training it through an iterative feedback loop.
Unsupervised Learning involves training a model on unlabeled data, where the model attempts to find patterns and relationships in the data without being given explicit feedback in the form of labels.
Self-Supervised Learning is an ML-based training format and a range of methods that encourage a model to train from unlabeled data. Foundation models and visual foundation models (VFMs) are usually trained this way, not reliant on labeled data.

Unsupervised learning is focused on grouping, clustering, and dimensionality reduction. In many ways, this makes SSL a subset of unsupervised learning. However, there are differences in the outputs of the two formats.
Self-supervised learning, on the other hand, performs segmentation, classification, and regression tasks, similar to supervised learning.
There are other approaches, too, such as semi-supervised learning, which sits between supervised and unsupervised learning. However, we will leave semi-supervised learning as the topic for another article on model training and learning methods.

Now let’s look at why computer vision needs self-supervised learning, the benefits of SSL, how it works, and use cases.
Why do Computer Vision Models Need Self-Supervised Learning?
Computer vision models need self-supervised learning because they often require large amounts of labeled data to train effectively. Sourcing, annotating, and labeling this data can be difficult and expensive to obtain.
Especially in highly-specialized sectors, such as healthcare, where medical professionals are needed to annotate and label data accurately.
Self-supervised learning can provide an alternative to labeling large amounts of data - a costly and time-consuming task, even when you’re using automated data labeling systems. Instead, this allows the models to learn from the data itself and improve their accuracy without the need for vast amounts of labels and annotations.
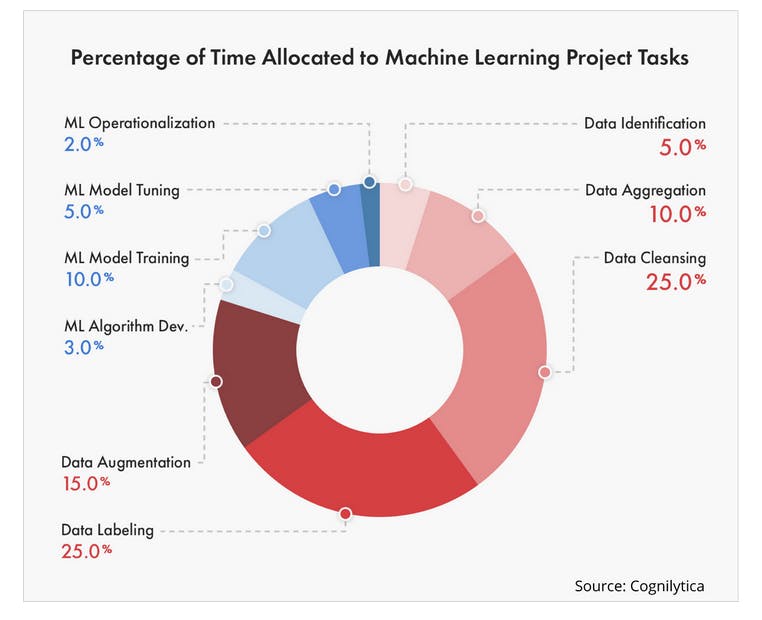
Computer vision and other algorithmically-generated models also perform better when each category of labeled data has an equal number of samples. Otherwise, bias creeps into the model’s performance.
Unfortunately, if a category of images or videos is hard to obtain (unless you invest in synthetic data creation or data augmentation), it can prove difficult to source enough data to improve performance.
Self-supervised learning reduces or eliminates the need to label and annotate data for computer vision models. While simultaneously reducing the need for augmentation and synthetic image or video creation in the case of computer vision.
Benefits of Self-Supervised Learning
Self-supervised learning has numerous benefits for computer vision and other ML and AI-based projects, use cases, and models.
- More scalable: Self-supervised learning is more scaleable and manageable for larger datasets because this approach doesn’t need high-quality labeled data. Even if classes of objects in images or videos aren’t as frequent as other objects, it won’t affect the outcomes because SSL can cope with vast amounts of unstructured data.
- Improved model outcomes: Self-supervised learning can lead to better feature representations of the data, enhancing the performance of computer vision models. Not only that, but an SSL approach enhances a model’s ability to learn without the structure created by labeled data.
- Enhanced AI capabilities: Self-supervised learning was introduced to train Natural Language Processing (NLP) models. Now it’s used for foundation models, such as generative adversarial networks (GANs), variational auto-encoders (VAEs), transformer-based large language models (LLMs), neural networks, multimodal models, and numerous others.
In computer vision, image classification, video frame prediction, and other tasks are performed more effectively using a self-supervised approach to learning.
Limitations of Self-Supervised Learning
At the same time, we need to acknowledge that there are some limitations to self-supervised learning, such as:
- Massive computational power needed: Self-supervised learning requires significant computational power to train models on large datasets. Computing power that’s usually on the same scale as neural networks or small foundation models. Especially since a model is taking raw data and labeling it without human input.
- Low accuracy: It’s only natural to expect that self-supervised learning won’t produce results as accurate as supervised or other approaches. Without a model being given human inputs in the form of labels, annotations, and ground truth training data, the initial accuracy score is going to be low. However, there are ways around that, as we will explore next.
How Does Self-supervised Learning Work?
On a basic level, self-supervised learning is an algorithm paradigm used to train AI-based models. It works when models are provided vast amounts of raw, almost entirely, or completely unlabeled data and then generate the labels themselves.
However, that’s simplifying it somewhat, as several frameworks of SSL can be applied when training a model this way. Let’s look at seven of the most popular, including contrastive and non-contrastive learning.
Contrastive Learning
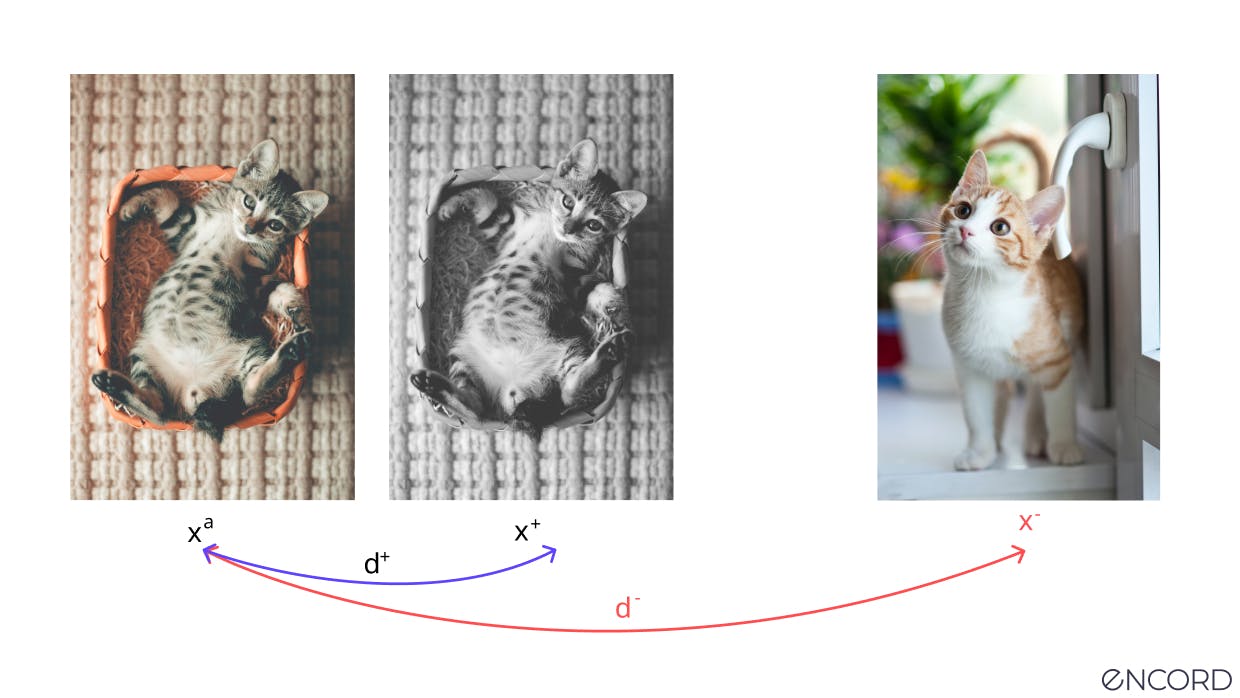
Contrastive learning SSL involves training a model to differentiate between two contrasting data points or inputs. These contrastive points, known as “anchors,” are provided in positive and negative formats.
A positive sample is a data input that belongs to the same distribution as the anchor. In contrast, a negative sample is in a different distribution to the anchor.
A positive sample is a data input that belongs to the same distribution as the anchor. Whereas a negative sample is in a different distribution to the anchor.
Non-Contrastive Learning (NC-SSL)
On the other hand, Non-contrastive self-supervised learning (NC-SSL) involves training a model only using non-contrasting pairs, also known as positive sample pairs. Rather than a positive and negative sample, as is the case with contrastive learning.

Contrastive Predictive Coding (CPC)
Contrastive Predictive Coding (CPC) was first introduced to the world by three AI engineers at Deep Mind, Google, and here’s the paper they released in 2019.
CPC is a popular approach to self-supervised learning in natural language processing, computer vision, and deep learning.
CPC can be used for computer vision, too, using it to combine predictive coding with probabilistic contrastive loss. The aim is to train a model to understand the representations between different parts of the data. At the same time, CPC makes it easier to discard low-level noise within a dataset.
Instance Discrimination Methods
Instance discrimination methods apply contrastive learning (e.g., CPC, Contrastive, and NC-SSL) to whole instances of data, such as an image or series of images in a dataset.
Images should be picked at random. Using this approach, one image is flipped in some way (rotated, made greyscale, etc.), serving as the positive anchor pair, and a completely different one is the negative sample. The aim is to ensure that the model still understands that even though an image has been flipped that it’s looking at the same thing.
Using instance discrimination SSL, a model should be trained to interpret a greyscale image of a horse as part of a positive anchor-pair as different from a black-and-white image of a cow.
Energy-based Model (EBM SSL)
With an energy-based model (EBM), it’s a question of computing the compatibility between two inputs using a mathematical model. Low energy outputs indicate high compatibility. Whereas high energy outputs indicate, there’s a low level of compatibility.
In computer vision, using EBM SSL, showing a model two images of a car should generate low energy outputs. In contrast, comparing a car with a plane should produce high-energy outputs.
Contrasting Cluster Assignments
Contrasting cluster assignments is another way of implementing self-supervised learning. A more innovative way of doing this was published in a 2020 paper, introducing an ML concept known as SwAV (Swapping Assignments between multiple Views).
Traditional contrasting cluster assignments involve offline learning. Models need to alternate between cluster assignment and training steps so that an ML or CV model learns to understand different image views.
Whereas using the SwAV SSL learning approach can be done online, making it easier to scale to vast amounts of data while benefiting from contrastive methods.
Joint Embedding Architecture
Another learning technique for self-supervised models is joint embedding architecture.
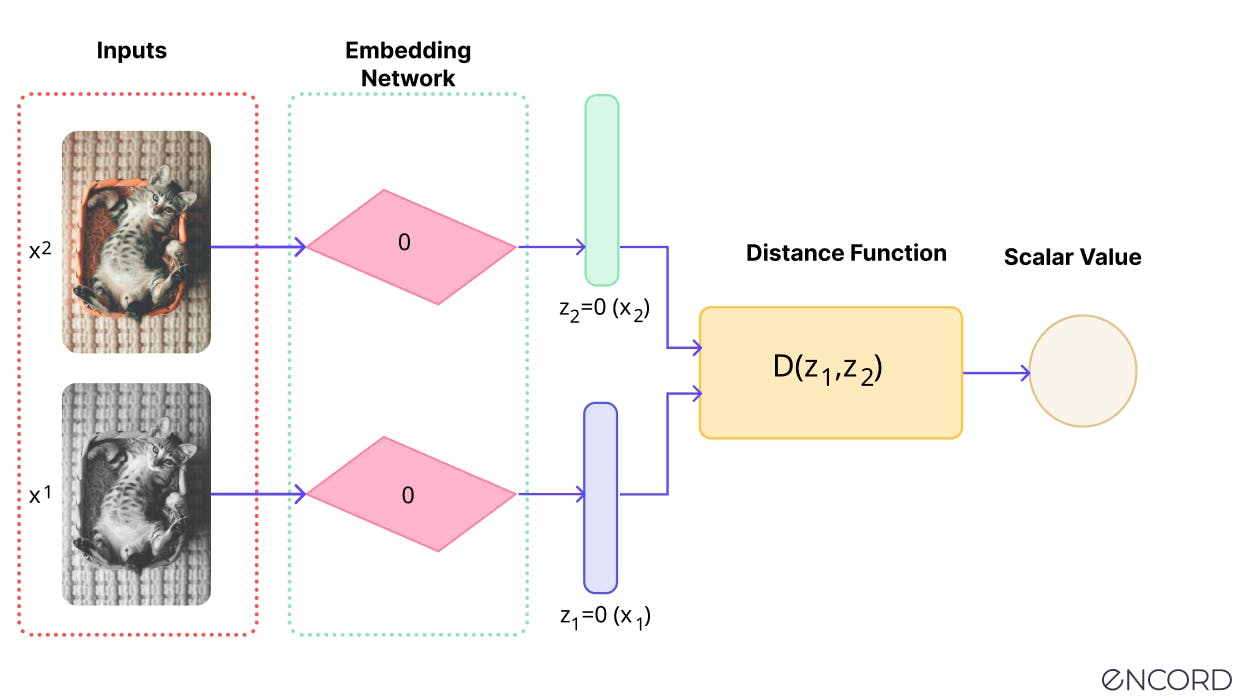
Joint embedding architecture involves a two-branch network identical in construction, where two inputs are given to each branch to compute separate embed vectors.
When the “distance” between the two source inputs is small (e.g., a model being shown two very similar but slightly different images of a bird in flight). Neural network parameters in the latent space can then be tuned to make sure the space between the inputs shrinks
Use Cases of Self-Supervised Learning for Computer Vision
Now let’s take a quick look at four of many real-world applications of self-supervised learning in computer vision.
Healthcare & Medical Imaging Computer Vision
One of the many applications of self-supervised learning in a real-world use case is in the healthcare sector. Medical imaging and annotation is a specialized field. Accuracy is crucial, especially with a computer vision model being used to detect life-threatening or life-limiting illnesses.
In computer vision, DICOM, NIfTI files, X-Rays, MRI, and CT scans are the raw materials that are used to train algorithmic models.
It’s difficult in the medical sector to obtain accurately labeled proprietary data at scale, partly because of data privacy and healthcare laws (e.g., HIPPA) and also because multiple doctors are usually needed to annotate this data. Professional medical time is precious and expensive. Few have spare hours in which to annotate large volumes of images or videos in a dataset.
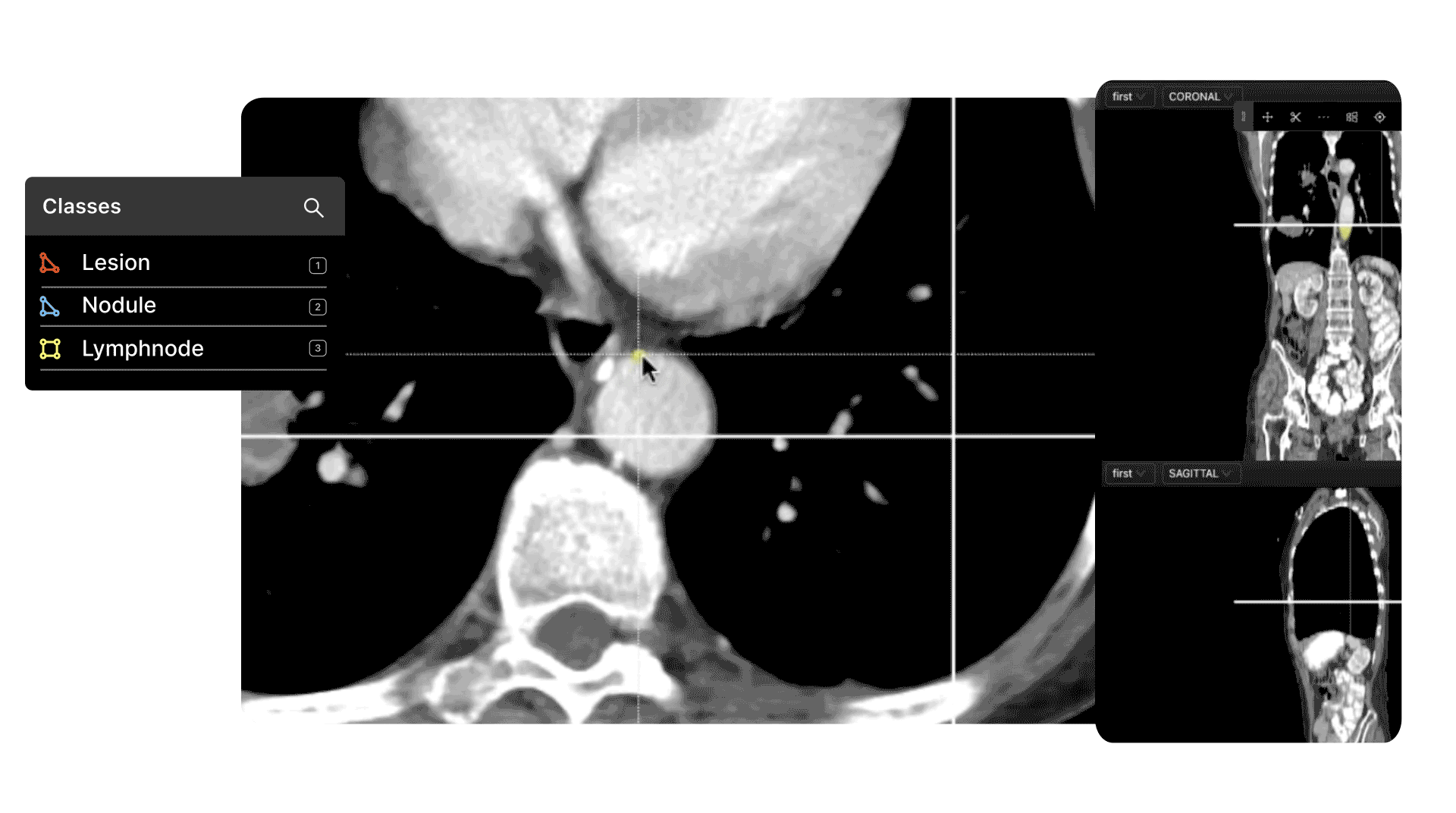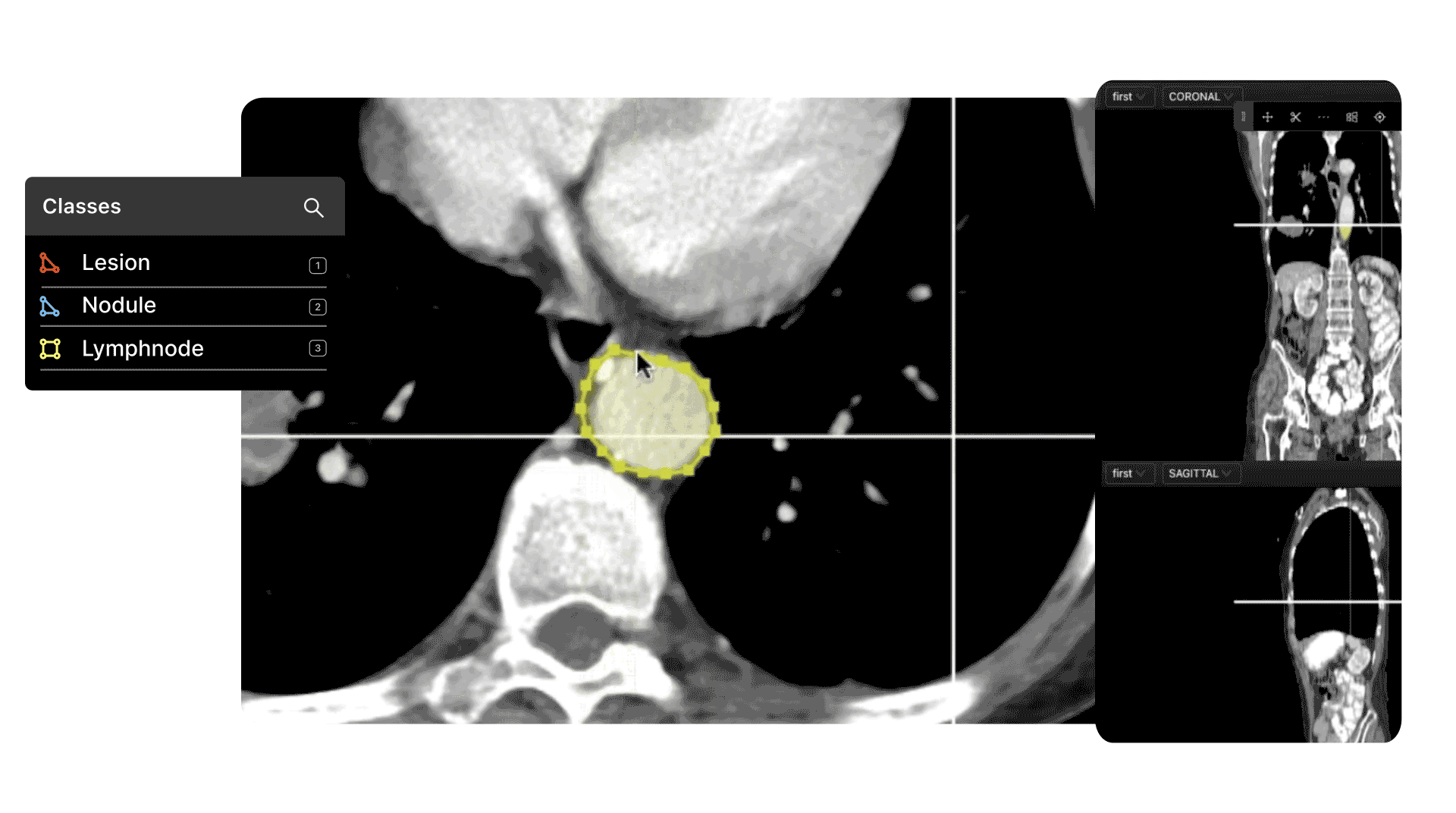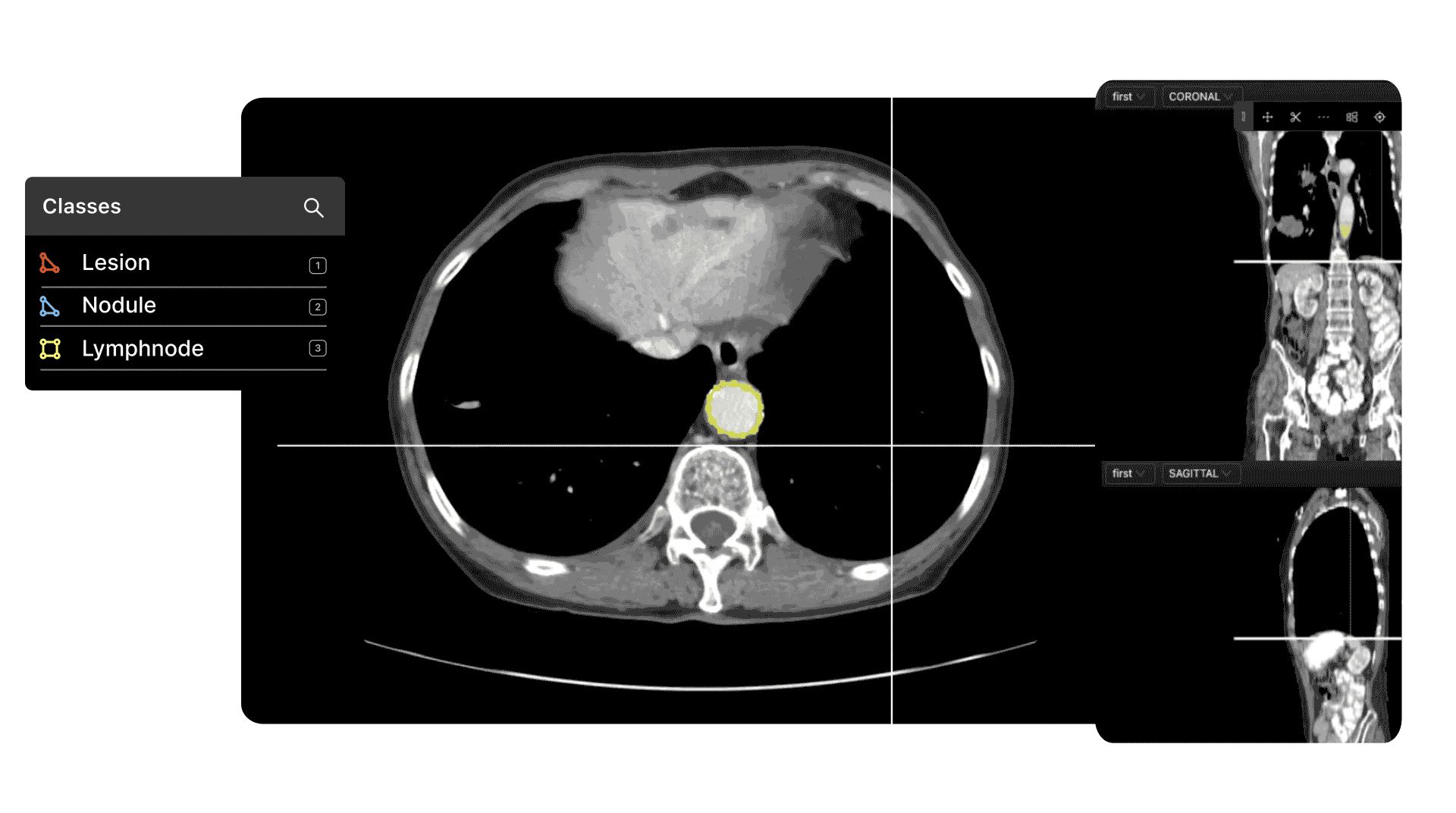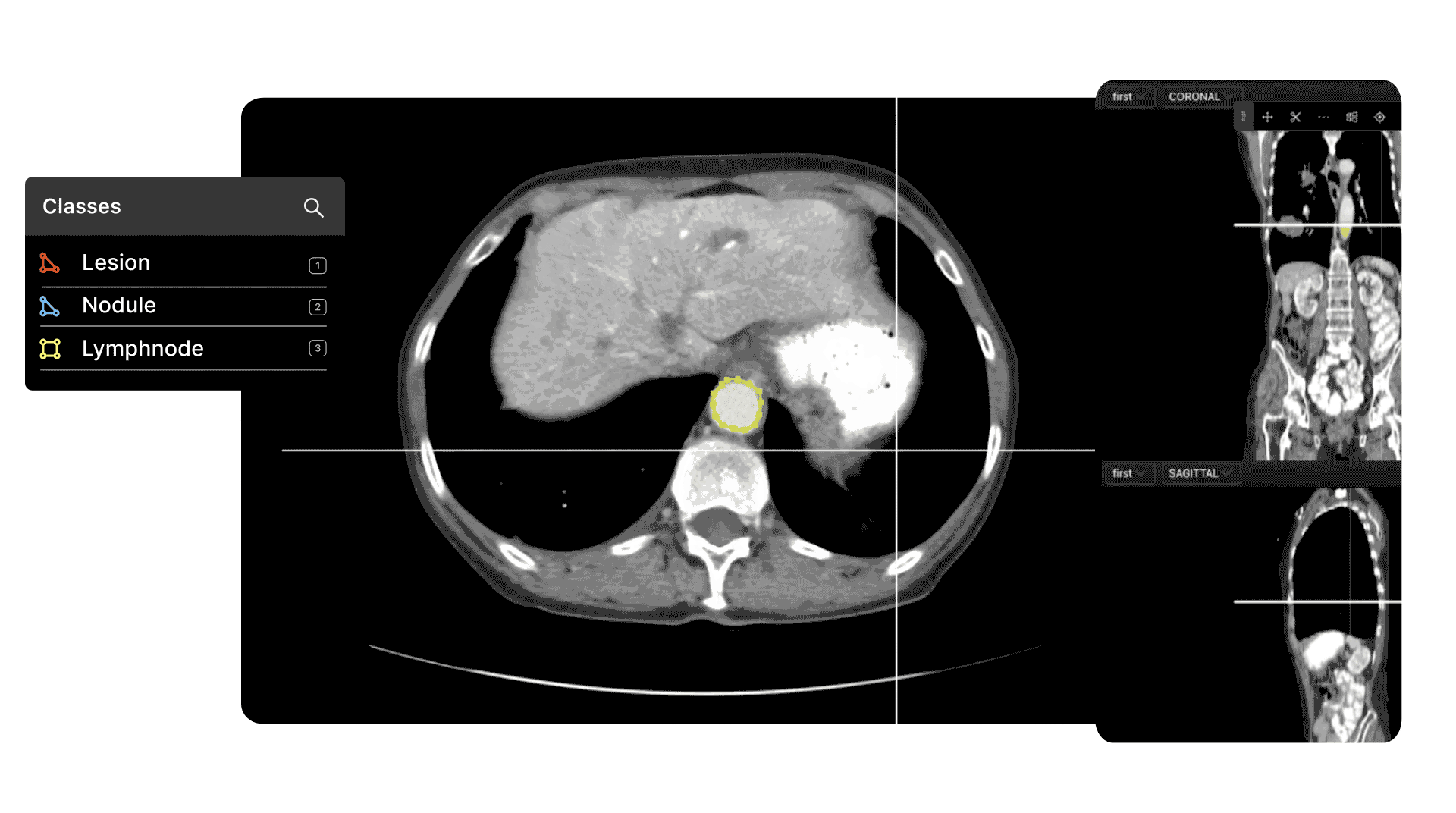
At the same time, computer vision is extremely useful in the healthcare sector, with numerous real-world applications and use cases.
One solution to the challenges noted above is to apply self-supervised learning methodologies to medical imaging datasets. Here’s an example: self-supervised learning for cancer detection.
Encord has developed our medical imaging annotation suite in close collaboration with medical professionals and healthcare data scientists, giving you a powerful automated image annotation suite with precise, 3D annotation built-in, fully auditable images and unparalleled efficiency.

3D Rotation From 2D Images
Another real-world application of self-supervised computer vision learning is in the training of robotic machines in factories to orient 3D objects correctly. Autonomous and semi-autonomous robots must know how to do this, and one way to train them is to use images and videos using a self-supervised computer vision model.
Video Motion Prediction From Semantically Linked Frames In Sequence
Videos are a sequence of semantically linked frames in a sequence. It’s easier to achieve higher accuracy with a self-supervised learning model because objects usually continue from one frame to the next, at least over a series of frames.
Various parameters can be applied in the pre-training stage, such as the fluidity of movement of specific objects and the application of gravity, distance, speed, and time.

Robotics: Autonomy Using Self-Supervised Learning Mechanisms
Robots can’t have every potential situation they might encounter uploaded into their hardware and software. There are simply too many factors to consider.
A certain amount of autonomy is essential, especially if a robot is functioning too far from a control center, such as NASA’s Space Center Houston communicating with the Mars rovers.
Even in a terrestrial setting, robots without the ability to make real-time, sometimes instant decisions are, at best, ineffective and, at worse, dangerous. Hence the advantage of applying self-supervised learning techniques to ensure a robot can make autonomous decisions.
How to implement self-supervised learning more effectively with Encord
With Encord and Encord Active, automated tools used by world-leading AI teams, you can accelerate data labeling workflows more effectively, securely, and at scale.
Even with applications of self-supervised learning in computer vision, you need a collaborative dashboard and suite of tools to make it more cost and time-effective to train a model. Once a model generates labels, the best way to improve accuracy is through an iterative human feedback loop and quality assurance (QA) process. You can do all of this with Encord.
Encord Active is an open-source active learning platform of automated tools for computer vision: in other words, it's a test suite for your labels, data, and models.
Key Takeaways
Self-supervised learning is a useful way to train a CV, AI, ML, or another algorithmic model on vast amounts of raw, unlabeled data. This saves engineers, data scientists, and data ops teams a considerable amount of time, money, and resources.
On the flip side, be prepared to use one of several approaches, as we’ve outlined in this article (e.g., contrastive, non-contrastive, CPC, EBL, etc.) during the pre-training stage so that an SSL-based model can produce more accurate results.
Otherwise, you risk lower levels of accuracy and more time involved in the training process without the support of data labeling and annotations that are helpful to train models.
Frequently asked questions
Unlike traditional annotation providers that often rely solely on human labor, Encord integrates data management capabilities with advanced pre-labeling techniques. This end-to-end solution not only improves data handling but also enhances collaboration between automated processes and human oversight to achieve superior annotation quality.
Encord recognizes the challenges associated with purely supervised learning, such as variability and high costs. By facilitating a blend of supervised, weakly supervised, and self-supervised approaches, Encord aims to enhance the efficiency and effectiveness of AI model training.
Encord ensures the accuracy of labeled data through a structured testing process that allows users to validate the tool with sample data. This includes verifying that the annotations align with user expectations and refining the labeling flow based on real-time feedback.
Encord emphasizes customization by allowing users to tailor their annotation processes to fit specific project needs. This includes defining unique labeling schemas and adjusting workflows to accommodate various use cases, especially in the context of generative AI.
Yes, Encord can effectively manage self-labeling datasets by allowing users to automate the assignment of values to data points based on predefined ground truth. This capability simplifies the data preparation process, enabling faster model training and deployment.
Encord prioritizes data security by allowing users to manage their compute and storage environments. This means that external annotators can work on projects without transferring sensitive data, ensuring control and privacy throughout the annotation process.
Encord enables users to generate ground truth labels for model training directly within the platform. The annotation training module ensures that external annotators meet the required standards before being released into a production environment.
Yes, Encord enables users to build their own machine learning models and iterate on them over time. This capability allows for continuous improvement of the annotation process as users refine their models based on the data they collect.
Yes, Encord allows users to incorporate custom metadata, such as location or camera type, into the annotation process. This feature enhances the sorting and filtering capabilities, making it easier to manage and analyze large datasets.
Encord provides control over data handling, which is crucial for teams dealing with proprietary information. This level of control helps protect sensitive data while facilitating efficient annotation processes.