The Full Guide to Embeddings in Machine Learning

Product Manager at Encord
AI embeddings offer the potential to generate superior training data, enhancing data quality and minimizing manual labeling requirements. By converting input data into machine-readable formats, businesses can leverage AI technology to transform workflows, streamline processes, and optimize performance.
Machine learning is a powerful tool that has the potential to transform the way we live and work. However, the success of any machine learning model depends heavily on the quality of the training data that is used to develop it. High-quality training data is often considered to be the most critical factor in achieving accurate and reliable machine learning results.
In this blog, we’ll discuss the importance of high-quality training data in machine learning and how AI embeddings can help improve it. We will cover:
- Importance of high-quality training data
- Creating high-quality training data using AI embeddings
- Case studies demonstrating the use of embeddings
- Best practices for using AI embeddings

Importance of High-Quality Training Data
The importance of high-quality training data in machine learning lies in the fact that it directly impacts the accuracy and reliability of machine learning models. For a model to accurately learn patterns and make predictions, it needs to be trained on large volumes of diverse, accurate, and unbiased data. If the data used for training is low-quality or contains inaccuracies and biases, it will produce less accurate and potentially biased predictions.
The quality of datasets being used to train models applies to every type of AI model, including Foundation Models, such as ChatGPT and Google’s BERT. The Washington Post took a closer look at the vast datasets being used to train some of the world’s most popular and powerful large language models (LLMs). In particular, the article reviewed the content of Google’s C4 dataset, finding that quality and quantity are equally important, especially when training LLMs.
In image recognition tasks, if the training data used to teach the model contains images with inaccurate or incomplete labels, then the model may not be able to recognize or classify similar images in its predictions accurately.
At the same time, if the training data is biased towards certain groups or demographics, then the model may learn and replicate those biases, leading to unfair or discriminatory treatment of certain groups. For instance, Google, too, succumbed to bias traps in a recent incident where its Vision AI model generated racist outcomes.
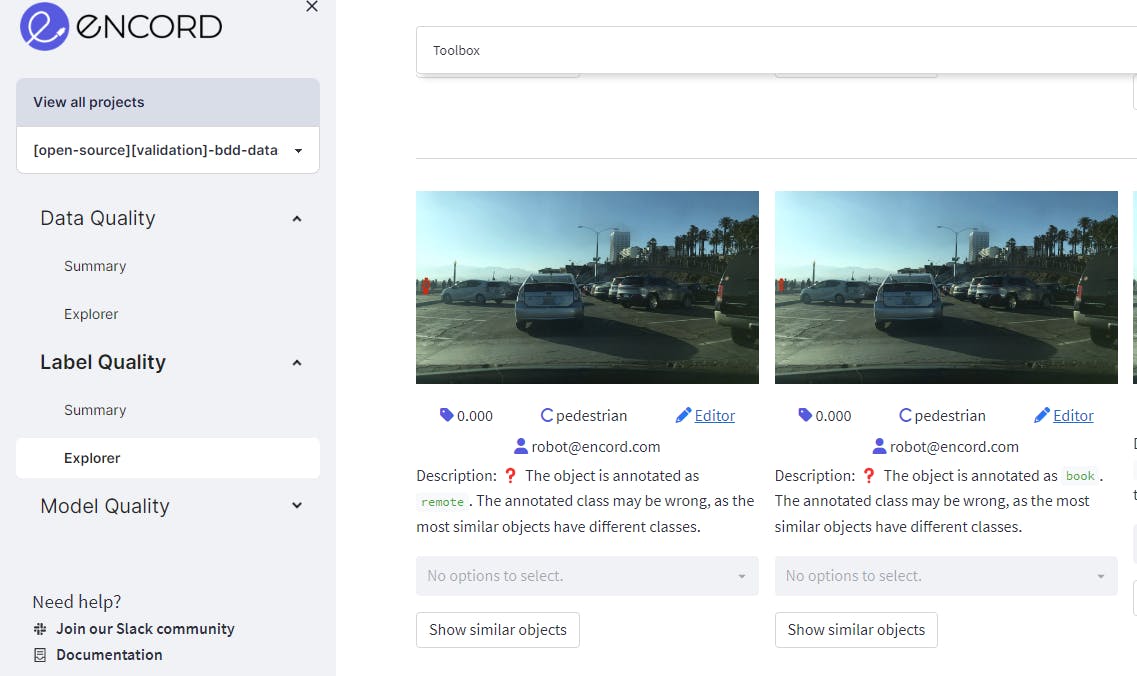
The images in the BDD dataset have a pedestrian labeled as remote and book, which is clearly annotated wrongly.
Hence, using high-quality training data is crucial to ensuring accurate and unbiased machine learning models. This involves selecting appropriate and diverse data sources and ensuring the data is cleaned, preprocessed, and labeled accurately before being used for training.
What is an Embedding in Machine Learning?
In artificial intelligence, an embedding is a mathematical representation of a set of data points in a lower-dimensional space that captures their underlying relationships and patterns. Embeddings are often used to represent complex data types, such as images, text, or audio, in a way that machine learning algorithms can easily process.
Embeddings differ from other machine learning techniques in that they are learned through training a model on a large dataset rather than being explicitly defined by a human expert. This allows the model to learn complex patterns and relationships in the data that may be difficult or impossible for a human to identify.
Once learned, embeddings can be used as features for other machine learning models, such as classifiers or regressors. This allows the model to make predictions or decisions based on the underlying patterns and relationships in the data, rather than just the raw input.
 💡To make things easier, companies like OpenAI also offer services to extract embeddings from your data. Read to find out more.
💡To make things easier, companies like OpenAI also offer services to extract embeddings from your data. Read to find out more. Types of Embeddings
Several types of embeddings can be used in machine learning, including
Image Embeddings
Image embeddings are used to represent images in a lower-dimensional space. These embeddings capture the visual features of an image, such as color and texture, allowing machine learning models to perform image classification, object detection, and other computer vision tasks.
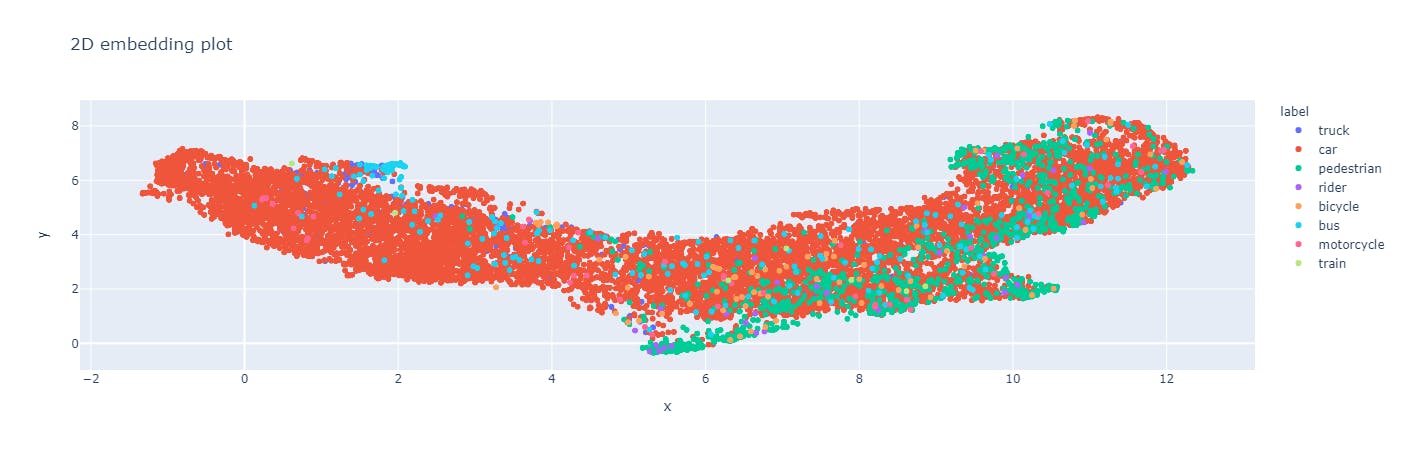
Example of visualization of image embeddings. Here the BDD dataset is visualized in a 2D embedding plot on the Encord platform.
Word Embeddings
Word embeddings are used to represent words as vectors in a low-dimensional space. These embeddings capture the meaning and relationships between words, allowing machine learning models to better understand and process natural language.
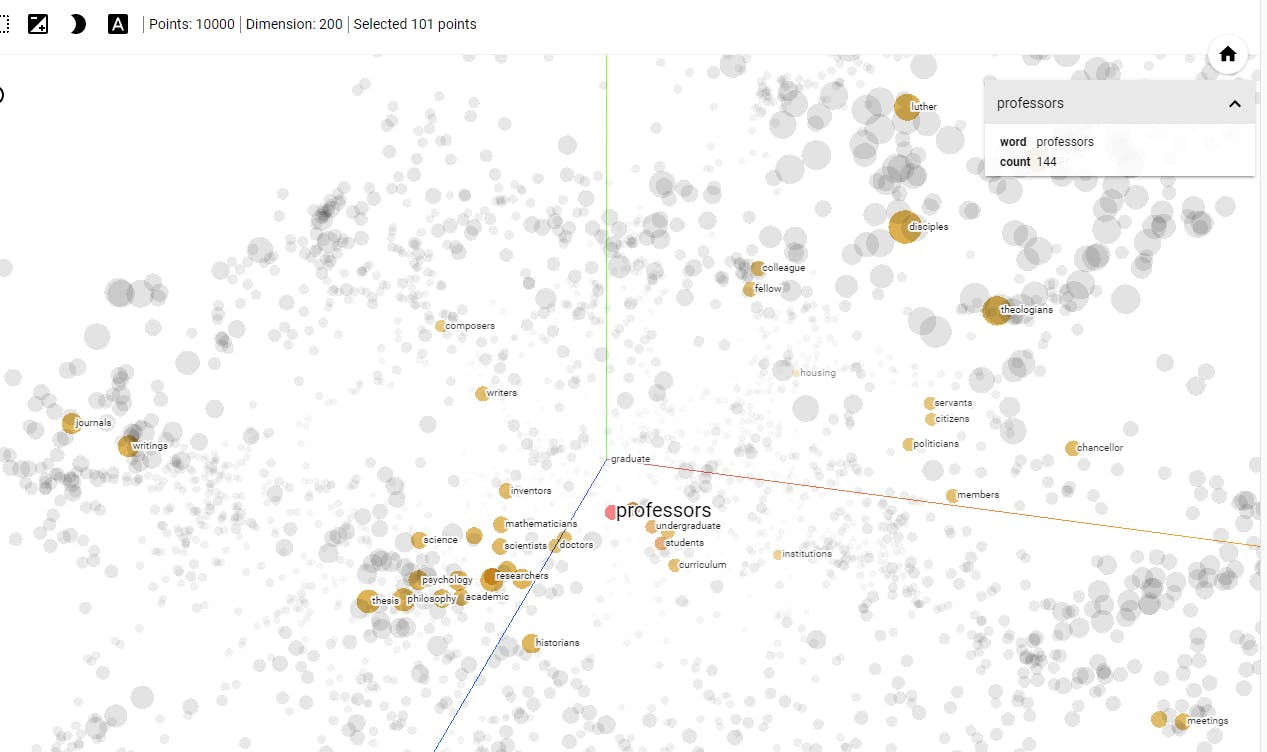
Example of visualization of word embeddings.
Graph Embeddings
Graph embeddings are used to represent graphs, which are networks of interconnected nodes, as vectors in a low-dimensional space. These embeddings capture the relationships between nodes in a graph, allowing machine learning models to perform node classification and link prediction tasks.
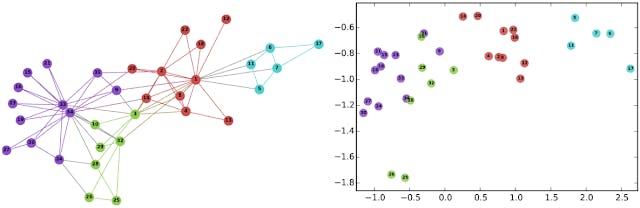
Left: The well-known Karate graph representing a social network. Right: A continuous space embedding of the nodes of the graph using DeepWalk.
By capturing the essence of the data in a lower-dimensional space, embeddings enable efficient computation and discovery of complex patterns and relationships that might not be otherwise apparent. These benefits enable various applications of AI embeddings, as discussed below.
Applications of Embeddings
AI embeddings have numerous applications in data creation and machine learning, including
Improving Data Quality
AI embeddings can help improve data quality by reducing noise, removing outliers, and capturing semantic relationships. This is particularly useful in scenarios where the data needs to be more structured or contain missing values. For example, in natural language processing, word embeddings can represent words with similar meanings closer together, enabling better semantic understanding and enhancing the accuracy of various language-related tasks.
Reducing the Need for Manual Data Labeling
AI embeddings can automatically label data based on its embedding representation. This can save time and resources, especially when dealing with large datasets.
Reducing Computation
Embeddings are useful in reducing computation by representing high-dimensional data in a lower-dimensional space. For example, a 256 x 256 image contains 65,536 pixels in image processing, resulting in many features if directly used. Using a CNN, the image can be transformed into a 1000-dimensional feature vector, consolidating the information. This compression significantly reduces computational requirements, approximately 65 times less, allowing for more efficient image processing and analysis without sacrificing essential details.
Enhancing Natual Language Processing (NLP)
Word embeddings are widely used in NLP applications such as sentiment analysis, language translation, and chatbot development. Mapping words to vector representations makes it easier for machine learning algorithms to understand the relationships between words.
Improving Recommendation Systems
Collaborative filtering, a type of recommendation system uses user and item embeddings to make personalized recommendations. By embedding user and item data in a vector space, the algorithm, can identify similar items and recommend them to users.
Enhancing Image and Video Processing
Image and video embeddings can be used for object detection, recognition, and classification. Mapping images and videos to vector representations makes it easier for machine learning algorithms to identify and classify different objects within them.
Hence, the applications of AI embeddings are diverse and offer many benefits, including improving data quality and reducing the need for manual data labeling. Now, let's delve into how this can be beneficial when utilizing AI embeddings for generating high-quality training data.
Benefits of Embeddings in Data Creation
Here are a few of the benefits of using embeddings in data creation:
Create a Larger and Diverse Dataset
By automatically identifying patterns and relationships within data, embeddings can help to fill in gaps and identify outliers that might be missed by manual labeling. For example, embeddings can help fill in gaps by leveraging the learned patterns and relationships within the data.
AI models can make informed estimations or predictions for missing values by analyzing the surrounding representations, allowing for more complete and reliable data analysis. This can help improve the accuracy of machine learning models by providing more comprehensive and representative data for training.
Reduce Bias
Using AI embeddings in training data can help reduce bias by enabling a more nuanced understanding of the relationships and patterns in the data, allowing for identifying and mitigating potential sources of bias. This can help to ensure that machine learning models are trained on fair and representative data, leading to more accurate and unbiased predictions.
💡Read to find out five more ways to reduce bias in your training data. Improve Model Performance
AI embeddings offer several benefits such as increased efficiency, better generalization, and enhanced performance in various machine learning tasks. They enable efficient computation and discovery of complex patterns, reduce overfitting, and capture the underlying structure of the data to generalize better on new, unseen data.
How to Create High-Quality Training Data Using Embeddings
Data Preparation
The first step is preparing the data for embedding. The data preparation step is crucial for embedding because the input data's quality determines the resulting embeddings' quality.
The first step is to collect the data you want to use for training your model. This can include text data, image data, or graph data. Once you have collected the data, you need to clean and preprocess it to remove any noise or irrelevant information. For example, in text data, data cleaning involves:
- Tokenizing the text into individual words or phrases.
- Removing stop words.
- Correcting spelling errors.
- Removing punctuation marks.
You may need to resize or crop images to a uniform size for image data.
If the data is noisy, unstructured, or contains irrelevant information, the embeddings may not accurately represent the data and may not provide the desired results. Proper data preparation can help improve the quality of embeddings, leading to more accurate and efficient machine learning models.
For example, the pre-processing step of image data preparation involves removing image duplicates and images that have no information like extremely dark or overly bright images.
💡Read the blog on data curation and data curation tools to gain more insight on how to choose the right datasets for your computer vision or machine learning model. Embedding using Machine Learning Techniques
Most machine learning algorithms require numerical data as input. Therefore, you need to convert the data into a numerical format. This can involve creating a bag of words representation for text data, converting images into pixel values, or transforming graph data into a numerical matrix.
Once you have converted the data into a numerical format, you can embed it using machine learning techniques. The embedding process involves mapping the data from a higher-dimensional space to a lower-dimensional space while preserving its semantic meaning. Some of the popular embedding techniques are:

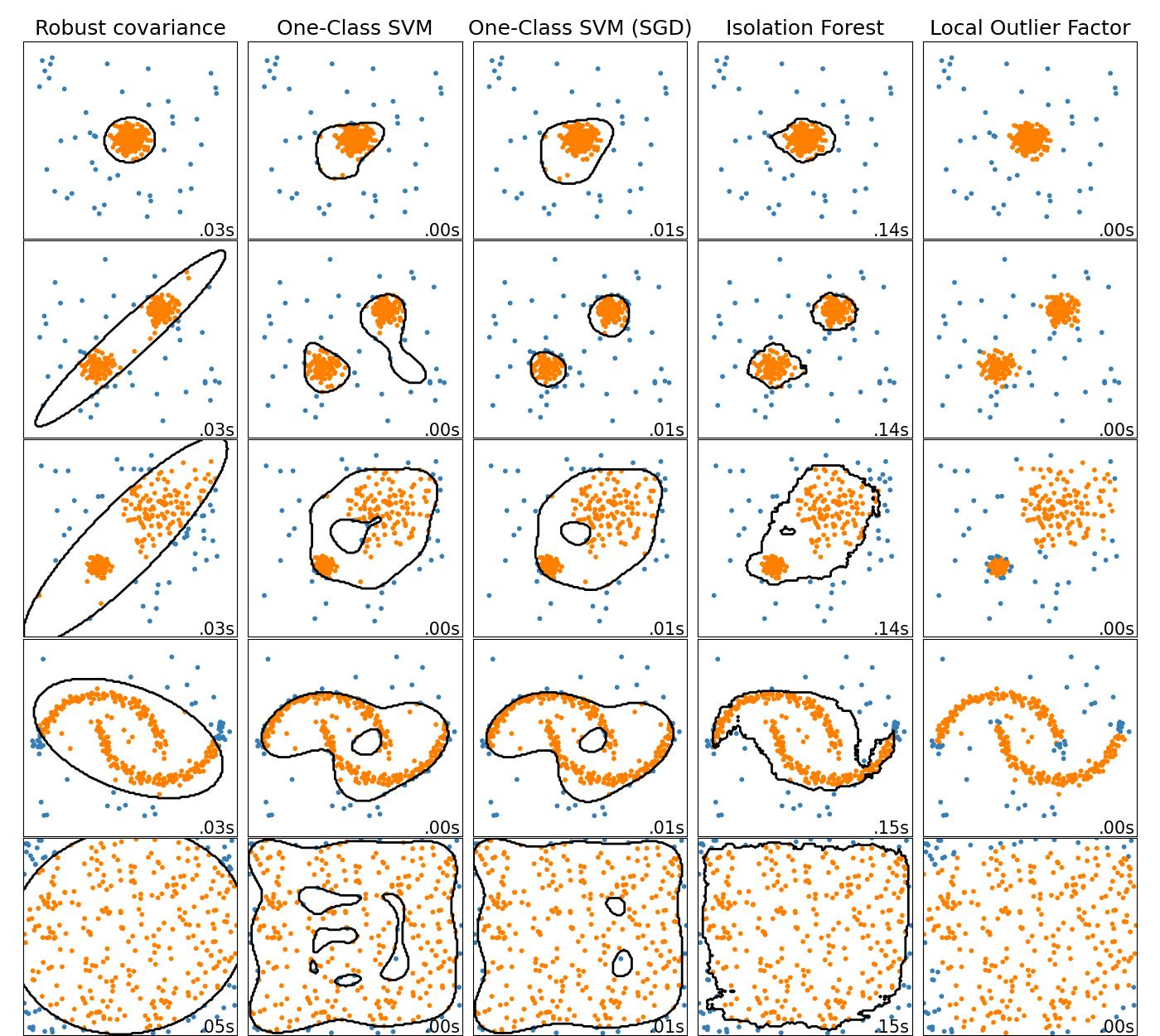
Principal Component Analysis (PCA) & Single Value Decomposition (SVD)
Principal Component Analysis (PCA) is a dimensionality reduction technique that transforms the original data into a set of new, uncorrelated features (called principal components). It captures the most important information in the data while discarding the less important information.
To perform PCA for embedding, the original data is first centered and scaled to have zero mean and unit variance. Next, the covariance matrix of the centered data is calculated. The eigenvectors and eigenvalues of the covariance matrix are then computed, and the eigenvectors are sorted in descending order based on their corresponding eigenvalues. The top k eigenvectors are then selected to form the new feature space, where k is the desired dimensionality of the embedded space.
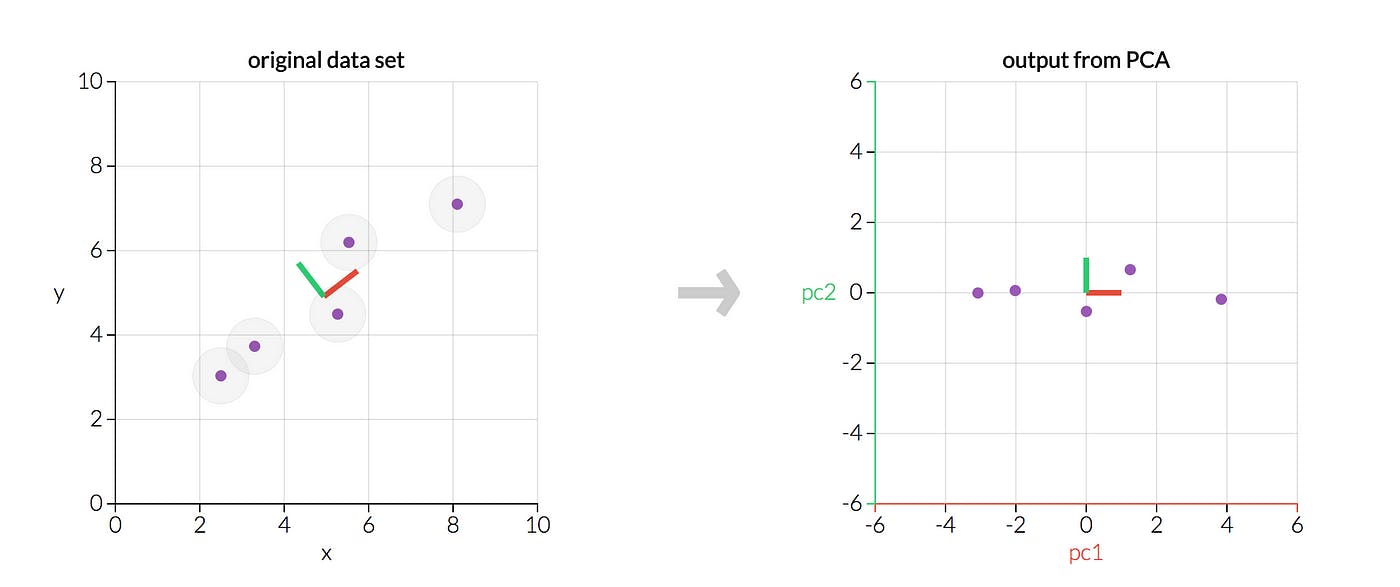
An example where we transform five data points using PCA. The left graph is our original data; the right graph would be our transformed data. The two charts show the same data, but the right graph reflects the original data transformed so that the axes are now the principal components.
Finally, the original data is projected onto the new feature space using the selected eigenvectors to obtain the embedded representation. PCA is a widely used technique for embedding, particularly for image and audio data, and has been used in a variety of applications such as facial recognition and speech recognition.
Singular Value Decomposition (SVD) is used within PCA, so we will only cover this briefly. SVD decomposes a matrix into three matrices: U, Σ, and V. U represents the left singular vectors, S represents the singular values, and V represents the right singular vectors.
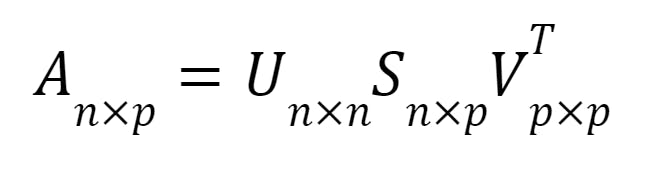
Equation of the SVD theorem.
The singular values and vectors capture the most important information in the original matrix, allowing for dimensionality reduction and embedding creation. Similar to PCA, SVD can be used to create embeddings for various types of data, including text, images, and graphs.
SVD has been used for various machine learning tasks, such as recommendation systems, text classification, and image processing. It is a powerful technique for creating high-quality embeddings that can improve the performance of machine learning models.
Auto-Encoder
Autoencoders are neural network models used for unsupervised learning. They consist of an encoder network that maps the input data to a lower-dimensional representation (encoding) and a decoder network that attempts to reconstruct the original input data from the encoding. An autoencoder aims to learn a compressed and meaningful representation of the input data, effectively capturing the essential features.
Autoencoders consist of an encoder neural network that compresses the input data into a lower-dimensional representation or embedding. The decoder network reconstructs the original data from the embedding. By training an eutoencoder on a dataset, the encoder network learns to extract meaningful features and compress the input data into a compact representation. These embeddings can be used for downstream tasks such as clustering, visualization, or transfer learning.
Word2Vec
Word2Vec is a popular technique for creating word embeddings, which represent words in a high-dimensional vector space. The technique works by training a neural network on a large corpus of text data, to predict the context in which a given word appears. The resulting embeddings capture semantic and syntactic relationships between words, such as similarity and analogy.
Word2Vec is effective in various natural language processing tasks, such as language translation, text classification, and sentiment analysis. It also has applications in recommendation systems and image analysis.
There are two main approaches to implementing Word2Vec: the Continuous Bag-of-Words (CBOW) model and the Skip-gram model. CBOW predicts a target word given its surrounding context, while Skip-gram predicts the context given a target word. Both models have their advantages and disadvantages, and the choice between them depends on the specific application and the characteristics of the data.
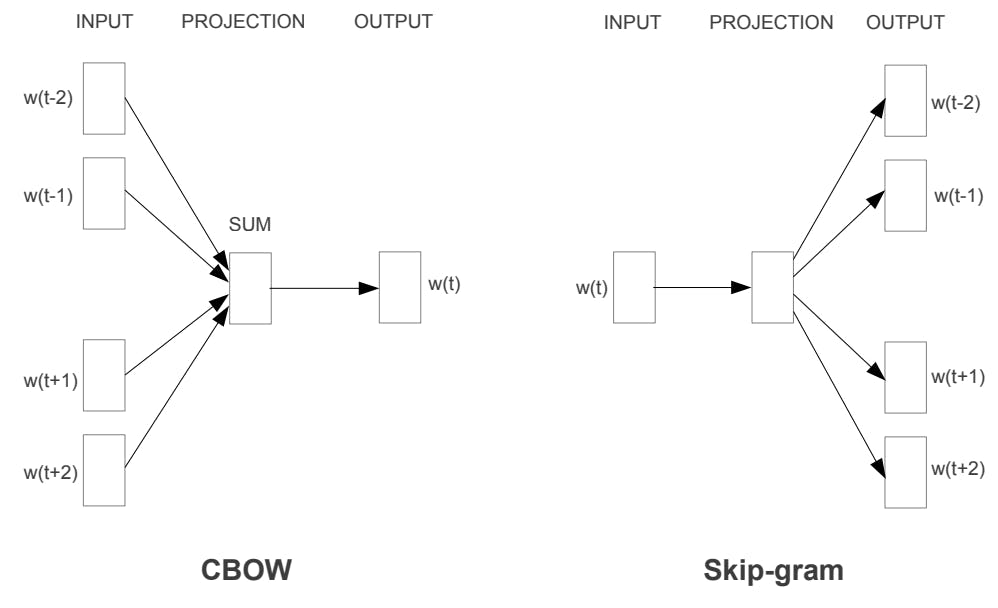
Left: CBOW architecture. Right: Skip-gram architecture. The CBOW architecture predicts the current word based on the context, and the Skip-gram predicts surrounding words given the current word.
GloVe
GloVe, which stands for Global Vectors for Word Representation, is another popular embedding technique that is used to represent words as vectors. Like Word2Vec, GloVe is also a neural network-based approach. However, unlike Word2Vec, which is based on a shallow neural network, GloVe uses a global matrix factorization technique to learn word embeddings.
In GloVe, the co-occurrence matrix of words is constructed by counting the number of times two words appear together in a given context. The rows of the matrix represent the words, and the columns represent the context in which the words appear. The matrix is then factorized into two separate matrices, one for words and the other for contexts. The product of these two matrices produces the final word embeddings.
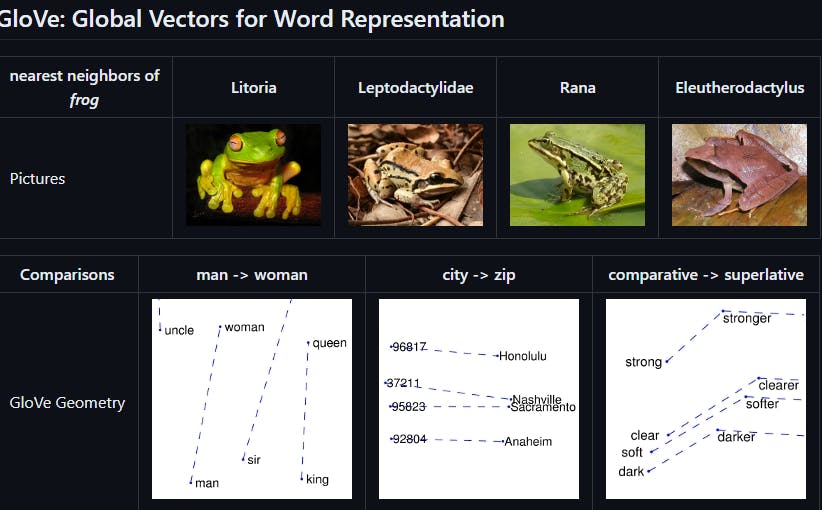
Example of the GloVe embeddings.
GloVe is known to perform well on various NLP tasks such as word analogy, word similarity, and named entity recognition. Additionally, GloVe has also been used for image classification tasks by converting image features into word-like entities and applying GloVe embeddings.
BERT
BERT (Bidirectional Encoder Representations from Transformers) is a popular language model developed by Google that has been used for a variety of natural language processing (NLP) tasks, including embedding. BERT is a deep learning model that uses a transformer architecture to generate word embeddings by taking into account the context of the words. This allows BERT to capture the semantic meaning of words, as well as the relationships between words in a sentence.

BERT is a pre-trained model that has been trained on massive amounts of text data, making it a powerful tool for generating high-quality word embeddings. BERT-based embeddings are highly effective in a range of NLP tasks, including sentiment analysis, text classification, and question-answering. Additionally, BERT allows for fine-tuning specific downstream tasks, which can lead to even more accurate results.
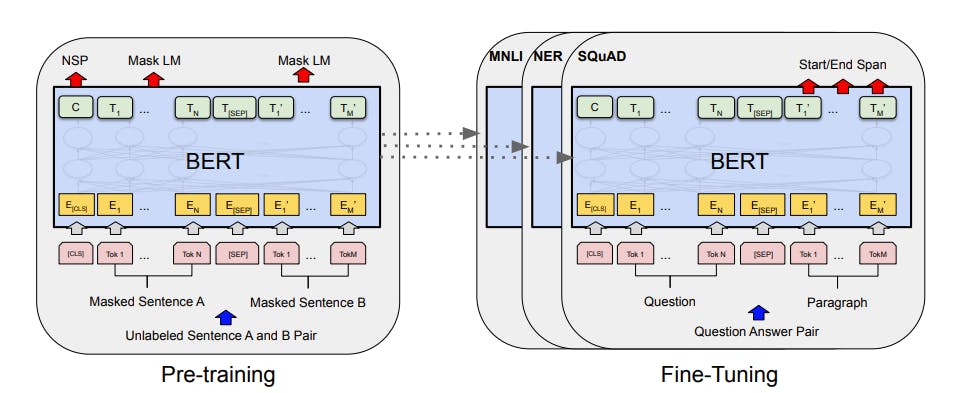
Overall pre-training and fine-tuning procedure for BERT
Overall, BERT is a powerful tool for generating high-quality word embeddings that can be used in a wide range of NLP applications. One downside of BERT is that it can be computationally expensive, requiring significant resources for training and inference. However, pre-trained BERT models can be fine-tuned for specific use cases, reducing the need for expensive training.
t-SNE
t-SNE (t-Distributed Stochastic Neighbor Embedding) is a widely used dimensionality reduction technique for visualizing high-dimensional data. While t-SNE is primarily used for visualization, it can also be used to generate embeddings. The process involves applying t-SNE to reduce the dimensionality of the data and obtaining a lower-dimensional embedding that captures the inherent structure of the original high-dimensional data.
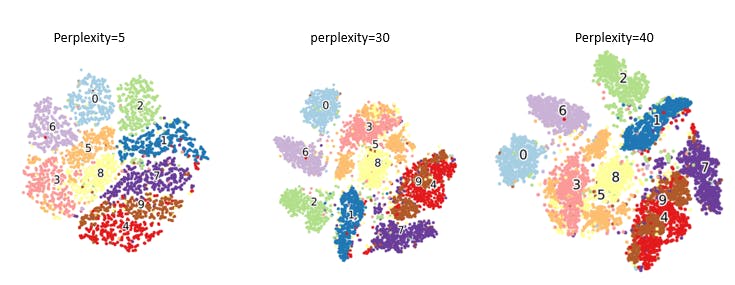
t-SNE works by creating a probability distribution that measures the similarity between data points in high-dimensional space and a corresponding probability distribution in the low-dimensional space. It then minimizes the Kullback-Leibler divergence between these distributions to find an embedding that preserves the pairwise similarities between points.
The resulting embeddings from t-SNE can be used for various purposes such as clustering, anomaly detection, or as input to downstream machine learning algorithms. However, it's important to note that t-SNE is computationally expensive, and the generated embeddings should be interpreted carefully since they emphasize local structure and may not preserve the precise distances between points
UMAP
UMAP (Uniform Manifold Approximation and Projection) is a dimensionality reduction technique commonly used for generating embeddings. Unlike traditional methods like PCA or t-SNE, UMAP focuses on preserving both local and global structure in the data while maintaining computational efficiency.
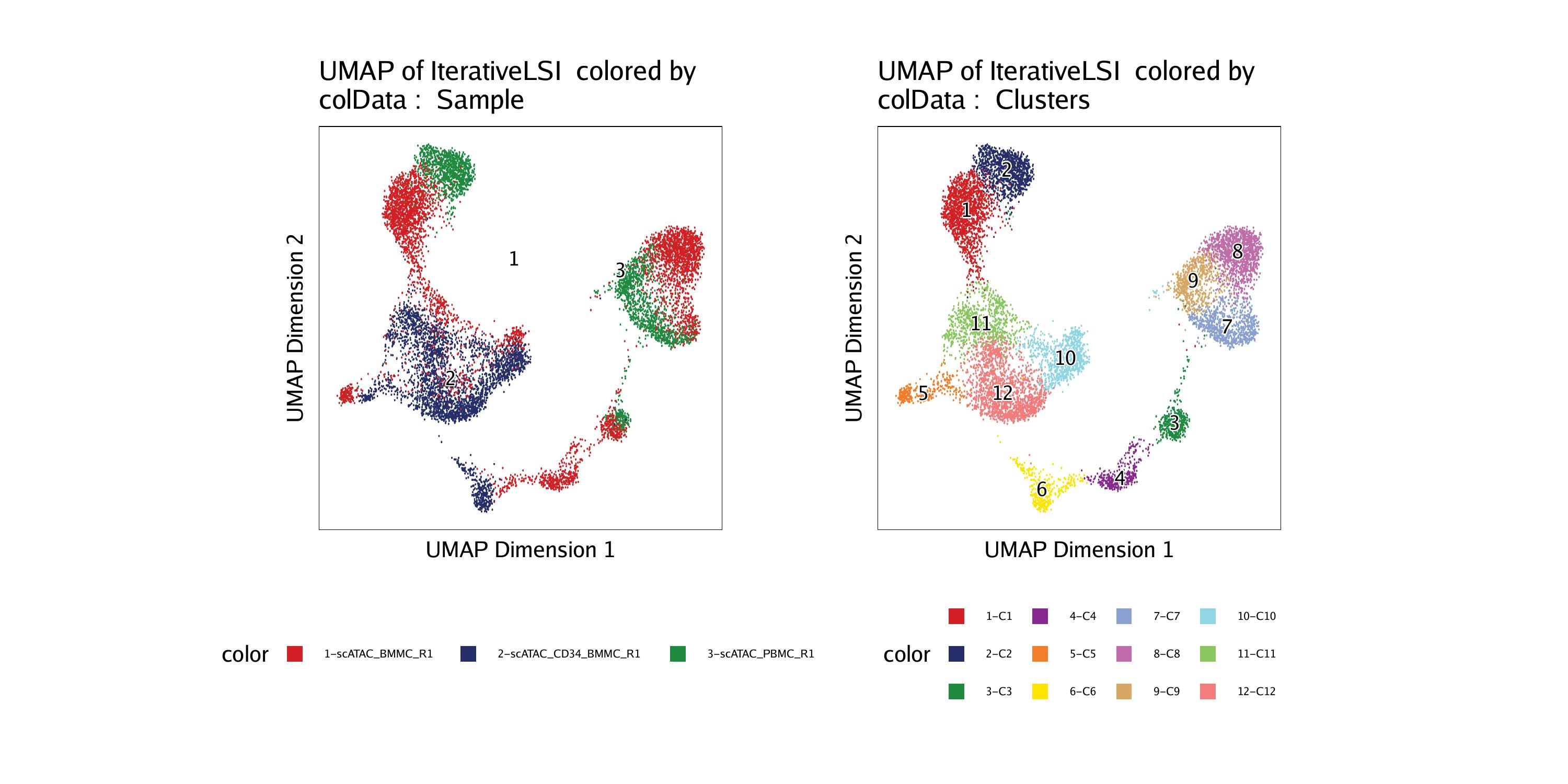
UMAP works by constructing a low-dimensional representation of the data while preserving the neighborhood relationships. It achieves this by modeling the data as a topological structure and approximating the manifold on which the data lies. The algorithm iteratively optimizes a low-dimensional embedding that preserves the pairwise distances between nearby points.
Applying UMAP to a dataset generates embeddings that capture the underlying structure and relationships in the data. These embeddings can be used for various purposes, such as visualization, clustering, or as input to other machine learning algorithms.
UMAP has gained popularity in various domains, including image analysis, genomics, text mining, and recommendation systems, due to its ability to generate high-quality embeddings that preserve both local and global structures while being computationally efficient.
Analyzing and validating embeddings is an important step in quality assurance to ensure that the generated embeddings accurately represent the underlying data.
Analyzing and Validating Embeddings for Quality Assurance
One common method for analyzing embeddings is to visualize them in a lower-dimensional space, such as 2D or 3D, using techniques like t-SNE or PCA. This can help identify clusters or patterns in the data and provide insights into the quality of the embeddings.
There are platforms that create and plot the embeddings of the dataset. These plots are helpful when you want to visualize your dataset in the lower-dimensional space. Visualizing the data in this lower-dimensional space makes it easier to identify any potential issues or biases in the data, which can be addressed to improve the quality of the embeddings. Visualizing embeddings can help evaluate and compare different models by providing an intuitive way to assess the quality and usefulness of the embeddings for specific tasks.
One example is the Encord Active platform, which provides a 2D embedding plot of an image dataset, enabling users to visualize the images within a particular cluster. This simplifies the process of identifying outliers through embeddings. The 2D embedding plot is not only useful in validating the data quality but also the label quality of the dataset.
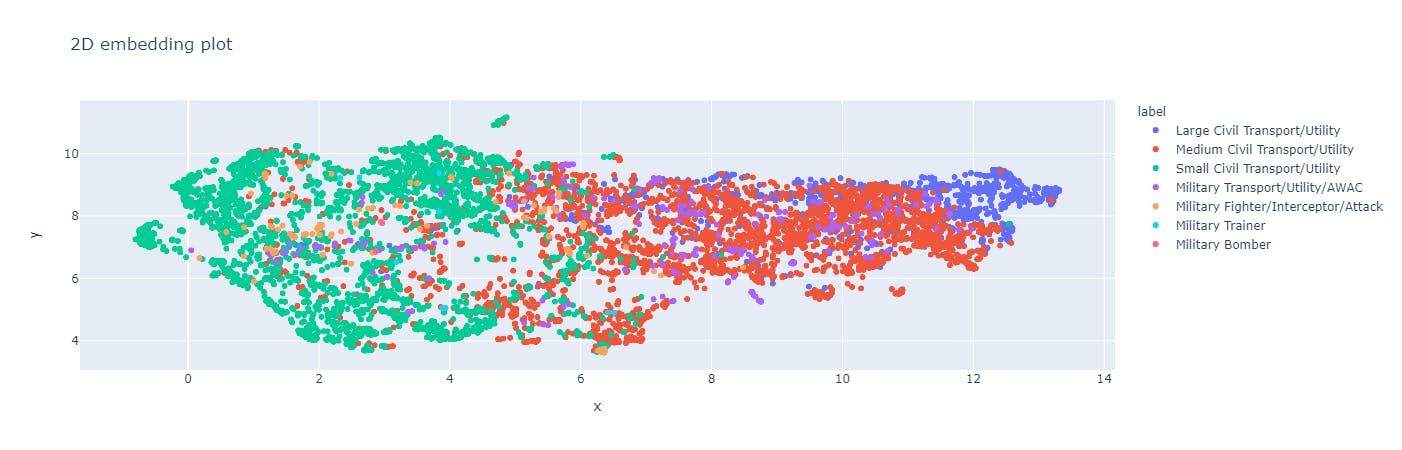
A 2D embedding plot of the Rareplanes dataset
Validation of embeddings involves evaluating their performance on downstream tasks, such as classification or prediction, and comparing it with other methods. This can help determine the effectiveness of the embeddings in real-world scenarios and highlight areas for improvement.
Another aspect of validation is measuring the degree of bias present in the embeddings. This is important because embeddings can reflect biases in the training data, leading to discriminatory or unfair outcomes. Techniques like de-biasing can be used to remove these biases and ensure that the embeddings are fair and unbiased.

Now that we have explored the creation and analysis of embeddings, let's examine a case study to gain a deeper understanding of how embeddings can benefit machine learning models when compared to traditional machine learning algorithms.
Case Study: Embeddings and Object Classification
This case study focuses on the effect of embeddings on object classification algorithms. By visualizing the embeddings of the training dataset, we can explore their impact on the process.
Image classification is a popular application of machine learning, and embeddings are effective for this task. Embedding-based approaches to image classification involve learning a lower-dimensional representation of the image data and using this representation as input to a machine learning model.

Example of dog classification
Analyzing the embeddings can reduce the need for manual feature engineering. Compared to traditional machine learning algorithms, embedding-based approaches enable more efficient computation. Hence, the trained model will often achieve higher accuracy and better generalization to new, unseen data. Let's visualize the embeddings to understand this better.
Visualizing embeddings
Here, we will be using the Encord Active platform to visualize the embedding plot of the Caltech-101 dataset.
The Caltech-101 dataset consists of images of objects categorized into 101 classes. Each image in the dataset has different dimensions, but they are generally of medium resolution, with dimensions ranging from 200 x 200 to 500 x 500 pixels. However, the number of dimensions in the dataset will depend on the number of features used to represent each image. In general, most Caltech-101 image features will have hundreds or thousands of dimensions and it will be helpful to visualize it in lower-dimensional space.

Example of images presented in Caltech101 dataset
Run the following commands in your favorite Python environment with the following commands will download Encord Active:
python3.9 -m venv ea-venv source ea-venv/bin/activate # within venv pip install encord-active
Or you can follow through the following command to install Encord Active using GitHub:
pip install git+https://github.com/encord-team/encord-active
To check if Encord Active has been installed, run:
encord-active --help
Encord Active has many sandbox datasets like the MNIST, BDD100K, TACO dataset, and much more. Caltech101 dataset is one of them. These sandbox datasets are commonly used in computer vision applications for building benchmark models.
Now that you have Encord Active installed, let’s download the Caltech101 dataset by running the command:
encord-active download
The script asks you to choose a project, navigate the options ↓ and ↑ select the Caltech-101 train or test dataset, and hit enter. The dataset has been pre-divided into a training set comprising 60% of the data and a testing set comprising the rest 40% of the data for the convenience of analyzing the dataset.
Easy! Now, you got your data. To visualize the data in the browser, run the command:
cd /path/to/downloaded/project encord-active visualize
The image below shows the webpage that opens in your browser showing the training data and its properties.
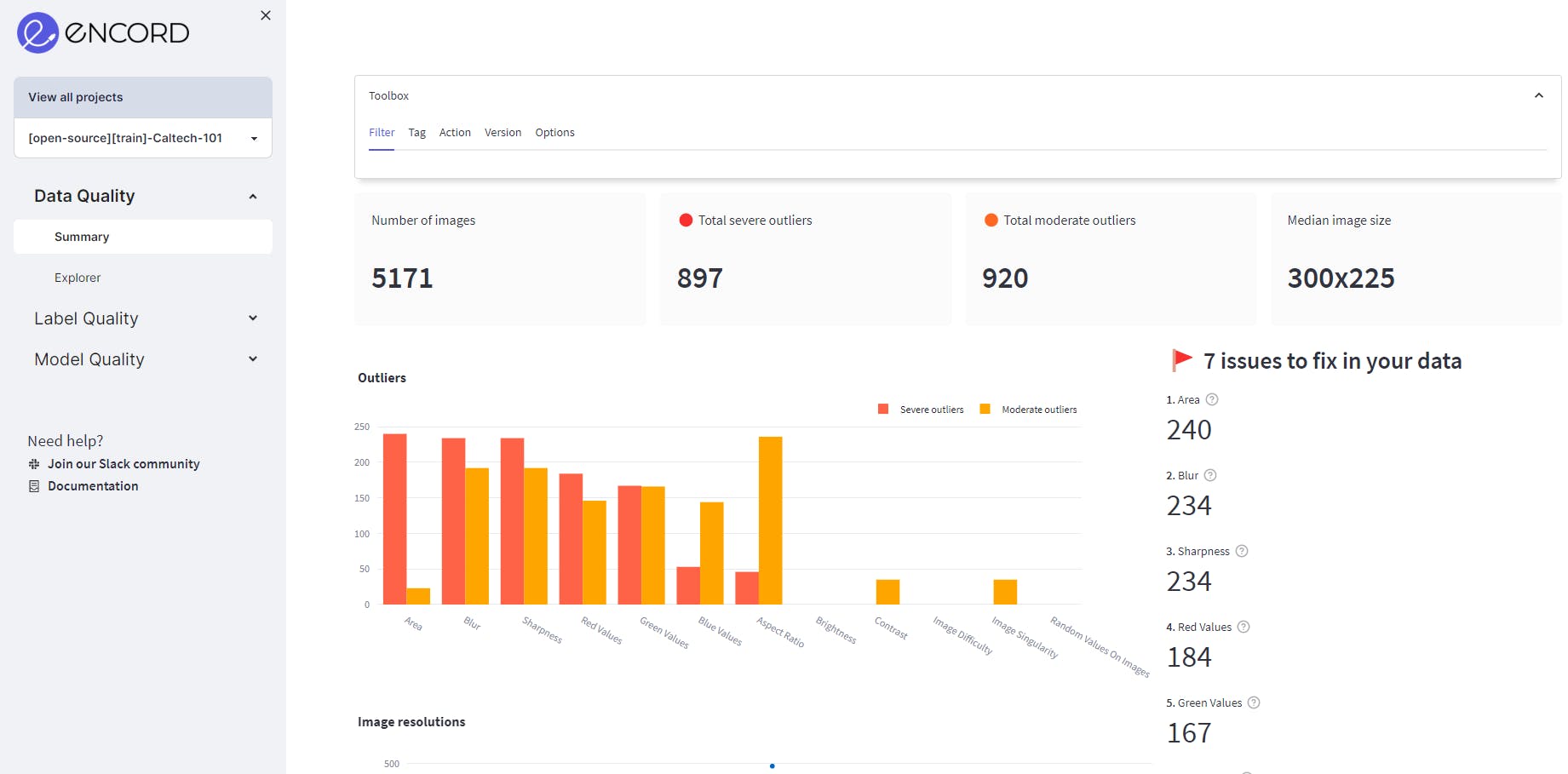
Visualize the data in your browser (data = Caltech-101 training data-60% of Caltech-101 dataset)
The 2D embedding plot can be found in the Explorer pages of the Data Quality and Label Quality sections.
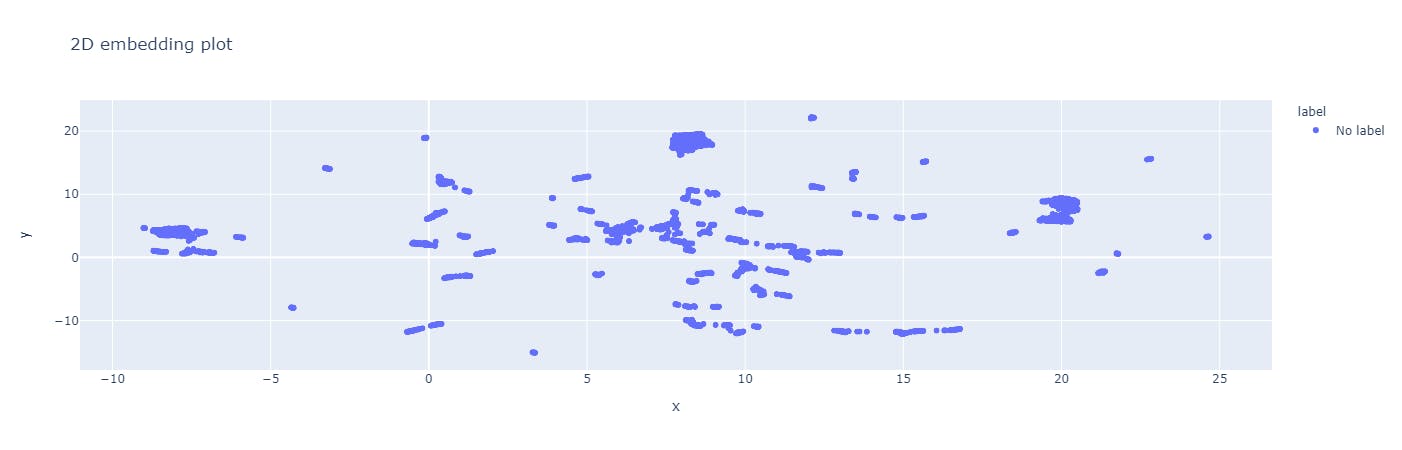
The 2D embedding plot in the Data Quality Explorer page of Encord.
The 2D embedding plot here is a scatter plot with each point representing a data point in the dataset. The position of each point on the plot reflects the relative similarity or dissimilarity of the data points with respect to each other. For example, select the box or the Lasso Select in the upper right corner of the plot. Once you select a region, you can visualize the images only in the selected region.
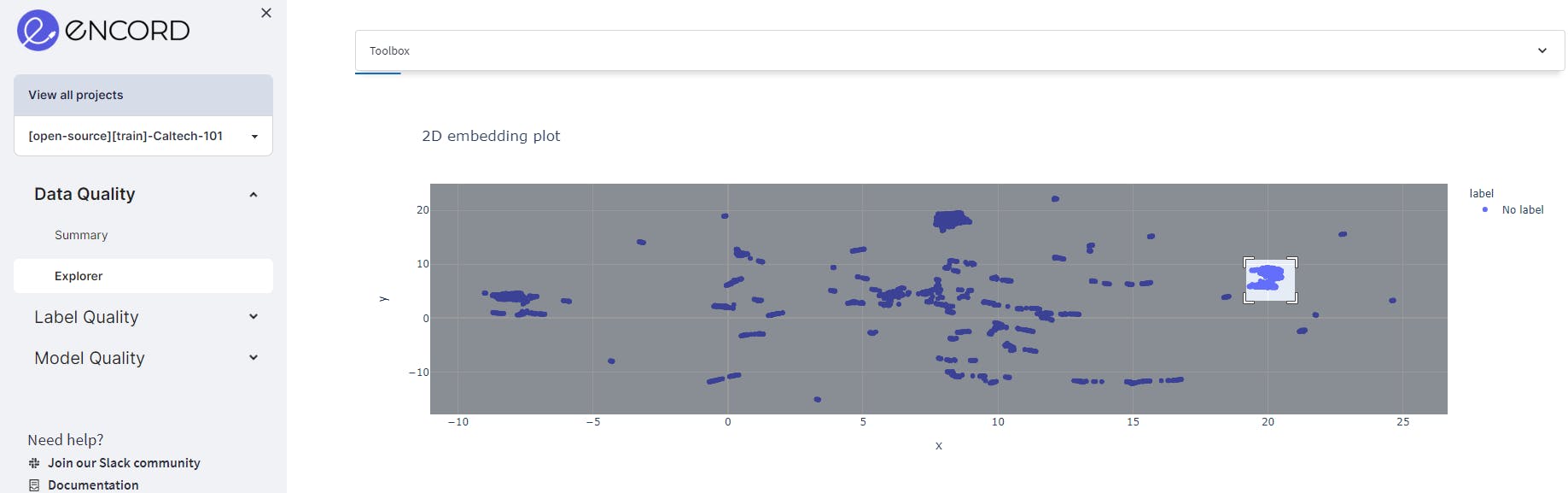
By projecting the data into two dimensions, you can now see clusters of similar data points, outliers, and other patterns that may be useful for data analysis.
For example, we see in the selected cluster, there is one outlier.
The 2D embedding plot in label quality shows the data points of each image and each color represents the class the object belongs to. This helps in finding out the outliers by spotting the unexpected relationships or possible areas of model bias for object labels.
This plot also shows the separability of the dataset. A separable dataset is useful for object recognition because it allows for the use of simpler and more efficient computer vision models that can achieve high accuracy with relatively few parameters.
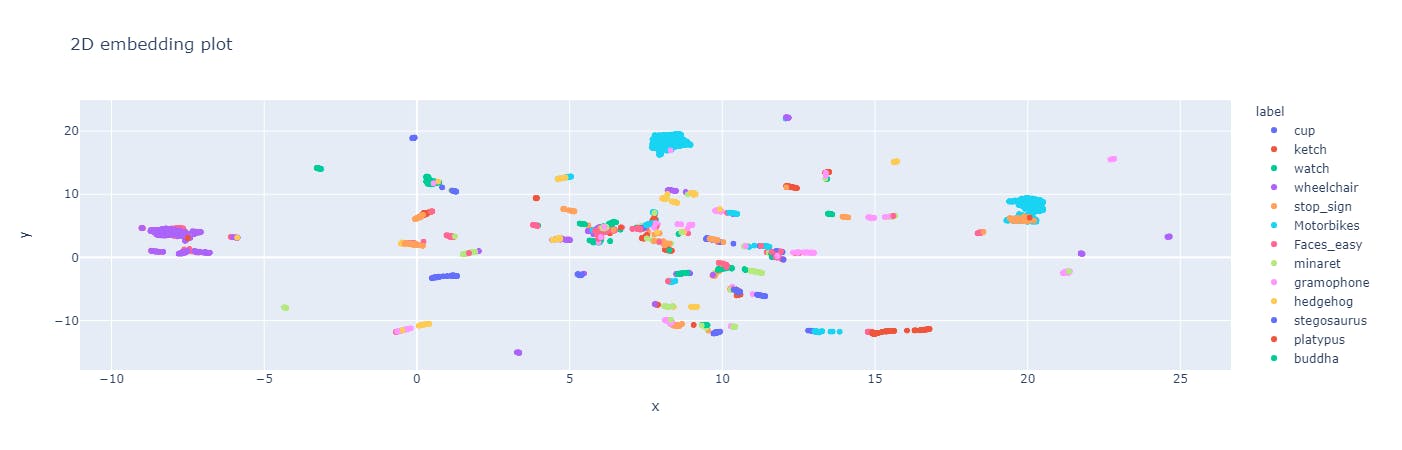
The 2D embedding plot in the Label Quality Explorer page of Encord.
A separable dataset is a useful starting point for object classification, as it allows us to quickly develop and evaluate simple machine learning models before exploring more complex models if needed. It also helps us better understand the data and the features that distinguish the different classes of objects, which can be useful for developing more sophisticated models in the future.
💡Read the detailed analysis of the Caltech101 dataset to understand the dataset better. You can also find out how to visualize and analyze your training data!So far, we have discussed various types of embeddings and how they can be used for analyzing and improving the quality of training data. Now, let's shift our focus to some of the best practices that should be kept in mind while using AI embeddings for creating training data.
Best Practices for Embeddings in Computer Vision & Machine Learning
Here are some of the best practices to sense that the AI embeddings you create for training data are of high quality:
Choosing an Appropriate Embedding Technique
Choosing the appropriate embedding techniques is crucial for using AI embeddings to create high-quality training data.
Different embedding techniques may be more suitable for different data types and tasks. It’s essential to carefully consider the data and the task at hand before selecting an embedding technique. It is also important to remember the computational resources required for the embedding technique and the size of the resulting embeddings.
It’s also important to stay up to date with the latest research and techniques in the field of AI embeddings. This can help ensure that the most effective and efficient embedding techniques are used for creating high-quality training data.
Addressing Data Bias and Ensuring Data Diversity
Using a large and diverse dataset for generating embeddings for the training data is a good way to ensure the embeddings address the bias in the dataset. This helps capture the full range of variation in the data and results in more accurate embeddings.
Validating the Embeddings
Analyzing the embeddings to validate their quality is a crucial step. The embeddings should be evaluated and validated to ensure that they capture the relevant information and can be used effectively for the task at hand. Visualization of the embeddings in a lower-dimensional space can help identify any patterns or clusters in the data and aid in the validation process.
Conclusion
In conclusion, AI embeddings are powerful tools for creating high-quality training data in machine learning. By using embeddings, data scientists can improve data quality, reduce the need for manual data labeling, and enable more efficient computation. Best practices for using AI embeddings include:
- Choosing appropriate techniques.
- Addressing data bias and ensuring diversity.
- Understanding limitations that could impact data quality.
AI embeddings have a promising future in machine learning, and we recommend implementing them in data creation whenever possible.
Future Directions
In the future, we can expect to see more sophisticated embedding techniques and tools, as well as increased use of embeddings in a wide range of applications beyond image and text classification. For example, Meta AI’s new model ImageBIND is a machine learning model that creates a joint embedding space for multiple modalities, such as images, text, and audio. The model is designed to enable the effective integration of multiple modalities and improve performance on a variety of multi-modal machine learning tasks.
💡Read the ImageBIND explainer to understand why it is so exciting! The development of platforms that facilitate the visualization and analysis of embeddings is an exciting area of research. These platforms make it easier to explore the structure and relationships within high-dimensional data and can help identify patterns and outliers that would be difficult to detect otherwise. One example of such a platform is Encord Active, which allows users to visualize their image dataset in a 2D embedding plot and explore images in specific clusters as we saw in the case study above!
Ready to improve the training data of your CV models?
Sign-up for an Encord Free Trial: The Active Learning Platform for Computer Vision, used by the world’s leading computer vision teams.
AI-assisted labeling, model training & diagnostics, find & fix dataset errors and biases, all in one collaborative active learning platform, to get to production AI faster. Try Encord for Free Today.
Want to stay updated?
Follow us on Twitter and LinkedIn for more content on computer vision, training data, and active learning.
Join our Discord channel to chat and connect.
Frequently asked questions
Encord's platform includes capabilities for embeddings extraction that can be utilized in natural language processing applications. This allows users to leverage the power of embeddings to enhance their understanding of data relationships and improve classification tasks, thereby streamlining the overall machine learning pipeline.
Encord supports the integration of custom embeddings, allowing users to import their own embeddings tailored to specific use cases. These custom embeddings can be used alongside Encord's built-in clip embeddings, enabling advanced features like similarity searches and natural language processing to enhance data analysis.
Encord offers robust data exploration features that allow users to analyze and visualize large data sets. By utilizing the embeddings view, users can identify patterns and clusters within the data, which helps in understanding its composition and filtering out unusable images, such as those that are blurry or too dark.
Encord's index features provide a structured approach to data organization and retrieval, enabling users to efficiently manage large datasets. This functionality is particularly beneficial for teams looking to optimize their data usage and improve model training outcomes.
Yes, Encord supports the creation of embeddings for custom datasets. Once the dataset is uploaded and approved, users can generate embeddings that allow for advanced analysis, such as visualizing similar frames and conducting deeper insights into the data.
Encord supports the use of various embedding models, including those from OpenAI and other foundational models. Users can also import embeddings generated externally and utilize them within the platform for enhanced data processing and search capabilities.
Encord is designed to integrate seamlessly with various machine learning solutions, allowing users to manage and implement use cases across different projects. This flexibility is crucial for scaling solutions and adapting to specific project requirements.
Yes, Encord supports the integration of embeddings, allowing users to leverage their own embeddings or utilize Encord's built-in options. This feature enhances the data analysis process, particularly for complex use cases.
Yes, Encord supports the embedding of data sets, enabling users to create and manage embeddings that are essential for machine learning applications. The platform allows for seamless integration with existing tool stacks.
Yes, Encord supports the development of custom embedding models, allowing teams to tailor solutions based on their unique project requirements and data characteristics.