How to Automate Data Labeling [Examples + Tutorial]

Product Manager at Encord
TL;DR:This blog dives deep into the critical role of data labeling, the challenges of manual annotation, and how automation is revolutionizing the way we build training datasets. Discover how AI-assisted annotation tools like Encord can transform your workflows, reduce costs, and enhance the accuracy of your models.
What is Automated Data Labelling?
Automated data labeling uses AI-powered software and machine learning algorithms to automatically assign labels or annotations to raw data such as images, videos, text, or audio, to create high-quality training data for machine learning models. This process accelerates labeling, reduces manual effort, and improves consistency and scale compared to fully manual approaches.
If you feed an AI model with junk, it’s bound to return the favor.
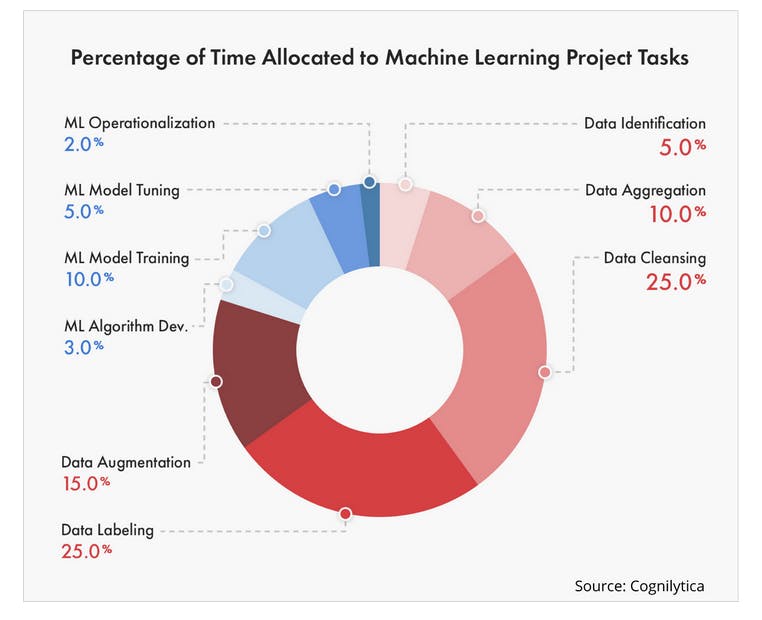
The quality of the data being consumed by an AI algorithm has a direct correlation with its success when it comes to generalizing to new instances; this is the reason data professionals spend 80% of their time during model development, ensuring the data is appropriately prepared, and is representative of the real world.
Data labeling is an essential task in supervised learning, as it enables AI algorithms to create accurate input-to-output mappings and build a comprehensive understanding of their environment. Therefore, efficient data labeling strategies are critical for improving the speed and quality of machine learning model development.
Before exploring how to automate data labeling and chosing the right AI Labeling tool, read our comprehensive guide on 'What is Data Labeling'.
 💡Read the blog to learn how to automate your data labeling process.
💡Read the blog to learn how to automate your data labeling process. What are the benefits of Automated Data Labeling with AI Annotation Tools?
An alternative approach is to use AI annotation tools to automate the labeling process, which can help address the issues associated with manual labeling by:
- Increasing accuracy and efficiency: Speed is just as important as being accurate. Yes, an automatic AI annotation tool can process large amounts of images much faster than a human can, but what makes it so effective is its ability to remain accurate, which ensures labels are precise and reliable.
- Improving productivity and workflow: It’s normal for humans to make mistakes – especially when they are performing the same task for 8 or more hours straight. When you use an AI-assisted labeling tool, the workload is significantly reduced, which means annotating teams can put more focus on ensuring things are labeled correctly the first time around.
- Reduction in labeling costs and resources: Deciding to manually annotate data means paying someone or a group of people to carry out the task; this means each hour that goes by has a cost, which can quickly become extremely high. An AI-assisted labeling tool may take off some of that load by allowing a human annotation team can manually label a percentage of the data and then have an AI tool do the rest.
What are the challenges of Manual Data Labeling?
Manual data labeling presents several operational and quality challenges that can slow down AI development and impact model performance.
- It Is Time-Intensive: Manual labeling requires annotators to review and tag each data point individually, whether images, video frames, text, or audio. For large datasets, this process can consume a significant portion of the overall machine learning lifecycle, sometimes 25% or more of development time.
As datasets scale, labeling quickly becomes a bottleneck, delaying experimentation, iteration, and deployment
- It Introduces Inconsistency and Human Error: Manual annotation depends on human judgment and subjective interpretation. Annotators may vary in expertise, domain understanding, or adherence to guidelines. Over time, this can lead to:
- Labeling inconsistencies
- Annotation drift
- Reduced dataset reliability
- Errors caused by fatigue or ambiguous edge cases
These inconsistencies directly affect model training quality and downstream performance.
- It Is Expensive and Difficult to scale: Large-scale manual labeling requires recruiting, training, and managing annotation teams, alongside implementing quality control processes. As datasets grow in size and complexity, especially in multimodal AI systems, costs increase significantly.
This makes manual labeling difficult to scale efficiently and can limit how quickly organizations can expand AI initiatives.
Because of these limitations, many organizations adopt automated or AI-assisted data labeling to reduce bottlenecks and improve consistency. Automated systems can pre-label large volumes of data, allowing human experts to focus on validation and edge cases rather than repetitive tasks. This hybrid approach improves speed, lowers operational costs, and supports scalable AI development.
Manual data labeling can be a challenging and error-prone process, as it relies on human judgment and subjective interpretation. Labelers may have different levels of expertise, leading to consistency in the labeling process and reduced accuracy. Moreover, manual data labeling can be time-consuming and expensive, especially for large datasets. This can hinder the scalability and efficiency of AI model development.
Integrating automated data labeling into your machine learning projects can be an effective strategy for mitigating the challenges of manual data labeling. By leveraging AI technology to perform data labeling tasks, businesses can reduce the risk of human error, increase the speed and efficiency of model development, and minimize costs associated with manual labeling.
Additionally, automated data labeling can help improve the accuracy and consistency of labeled data, resulting in more reliable and robust AI models.
Let's take a closer look at automated data labeling, including its workings, advantages, and how Encord can assist you in automating your data labeling process.

Using Annotation Tools for Automated Data Labeling
“Automated data annotation is a way to harness the power of AI-assisted tools and software to accelerate and improve the quality of creating and applying labels to images and videos for computer vision models.” – Frederik H. The Full Guide to Data Annotation. Annotation tools can be used for automated data labeling by providing a user interface for creating and managing annotations or labels for a dataset. These tools can help to automate the process of labeling data by providing features such as:
- Auto-labeling: Annotation tools can use pre-built machine learning models or algorithms to generate labels for data automatically.
- Data curation: Annotation tools also assist in data curation by facilitating the organization, filtering, searching, and exporting of large datasets, ensuring data integrity and enhancing the efficiency of downstream tasks.
- Active learning: Annotation tools can use machine learning algorithms to suggest labels for data based on patterns and correlations in the existing labeled data.
- Human-in-the-loop: Annotation tools can provide a user interface for human annotators to review and correct the labels generated by the automation process.
- Quality control: Annotation tools can help to ensure the quality of the labels generated by the automation process by providing tools for validation and verification.
- Data management: Annotation tools can provide tools for managing and organizing large datasets, including tools for filtering, searching, and exporting data.
Organizations can reduce the time and cost required to create high-quality training datasets for machine learning models by using annotation tools for automated data labeling. However, it is important to ensure that the tools used are appropriate for the specific task and that the labeled data is carefully validated and verified to ensure its quality.
AI Annotation Tools
💡Check out our curated list of the 9 Best Image Annotation Tools for Computer Vision to discover what other options are on the market.Encord Annotate
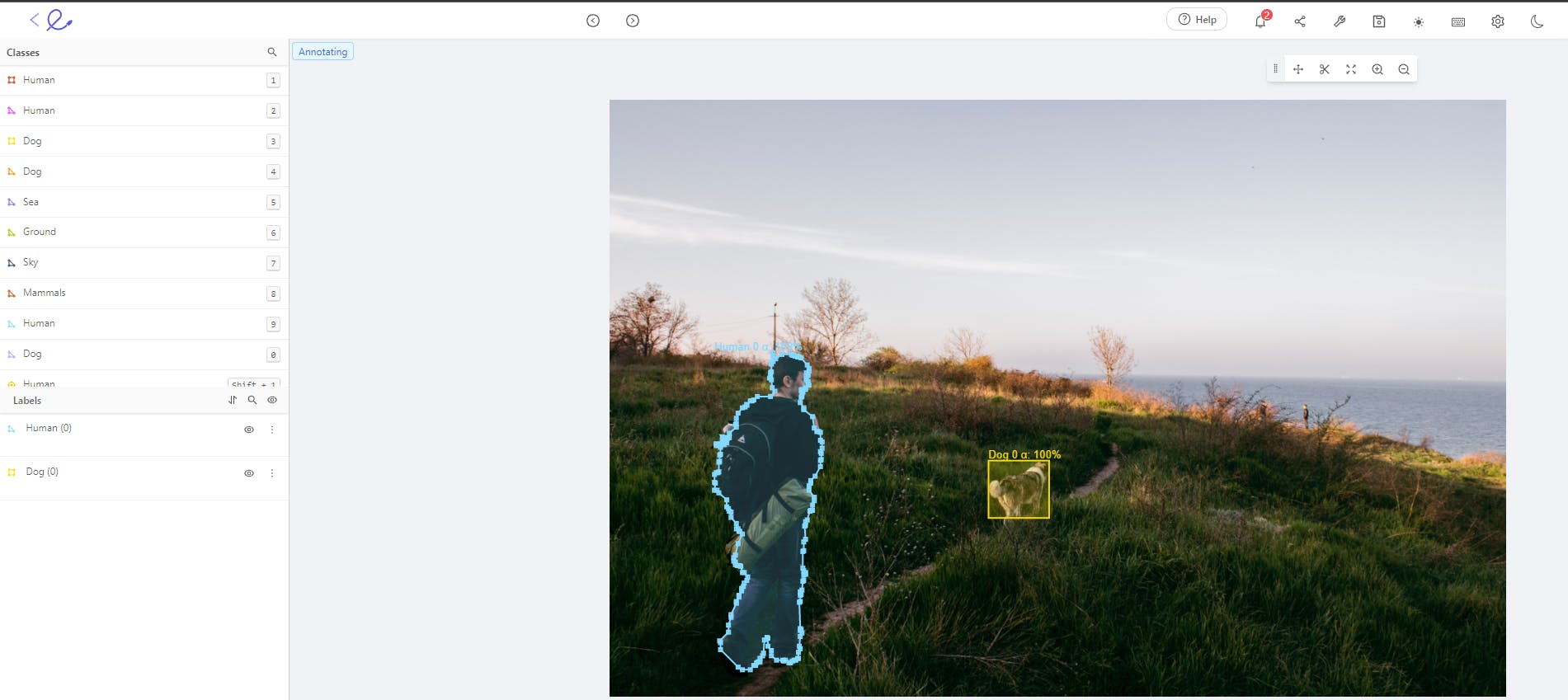
Encord Annotate is an automated annotation platform that performs AI-assisted image annotation, video annotation, and dataset management; part of the Encord product, alongside Encord Index and Encord Active. The key features of Encord Annotate include:
- Support for all annotation types such as bounding boxes, polygons, polylines, image segmentation, and more.
- It incorporates auto-annotation tools such as Meta’s Segment Anything Model and other AI-assisted labeling techniques.
- It has integrated MLOps workflow for computer vision and machine learning teams
- Use-case-centric annotations — from native DICOM & NIfTI annotations for medical imaging to SAR-specific features for geospatial data.
- Easy collaboration, annotator management, and QA workflows — to track annotator performance and increase label quality.
- Robust security functionality — label audit trails, encryption, FDA, CE Compliance, and HIPAA compliance.
How to Automate Data Labeling with Encord
Here is how to automate data labeling using different methods, such as auto-segmentation and interpolation, with Encord and the key steps to take in the platform:
Micro models
Micro-models are models that are designed to be overtrained for a specific task or piece of data, making them effective in automating one aspect of data annotation workflow. They are not meant to be good at solving general problems and are typically used for a specific purpose.
💡Read the blog to find out more about micro-models. The main difference between a traditional model and a micro-model is not in their architecture or parameters but in their application domain, the data science practices used to create them, and their ultimate end-use.
Step 1:

Step 2:
Auto-segmentation
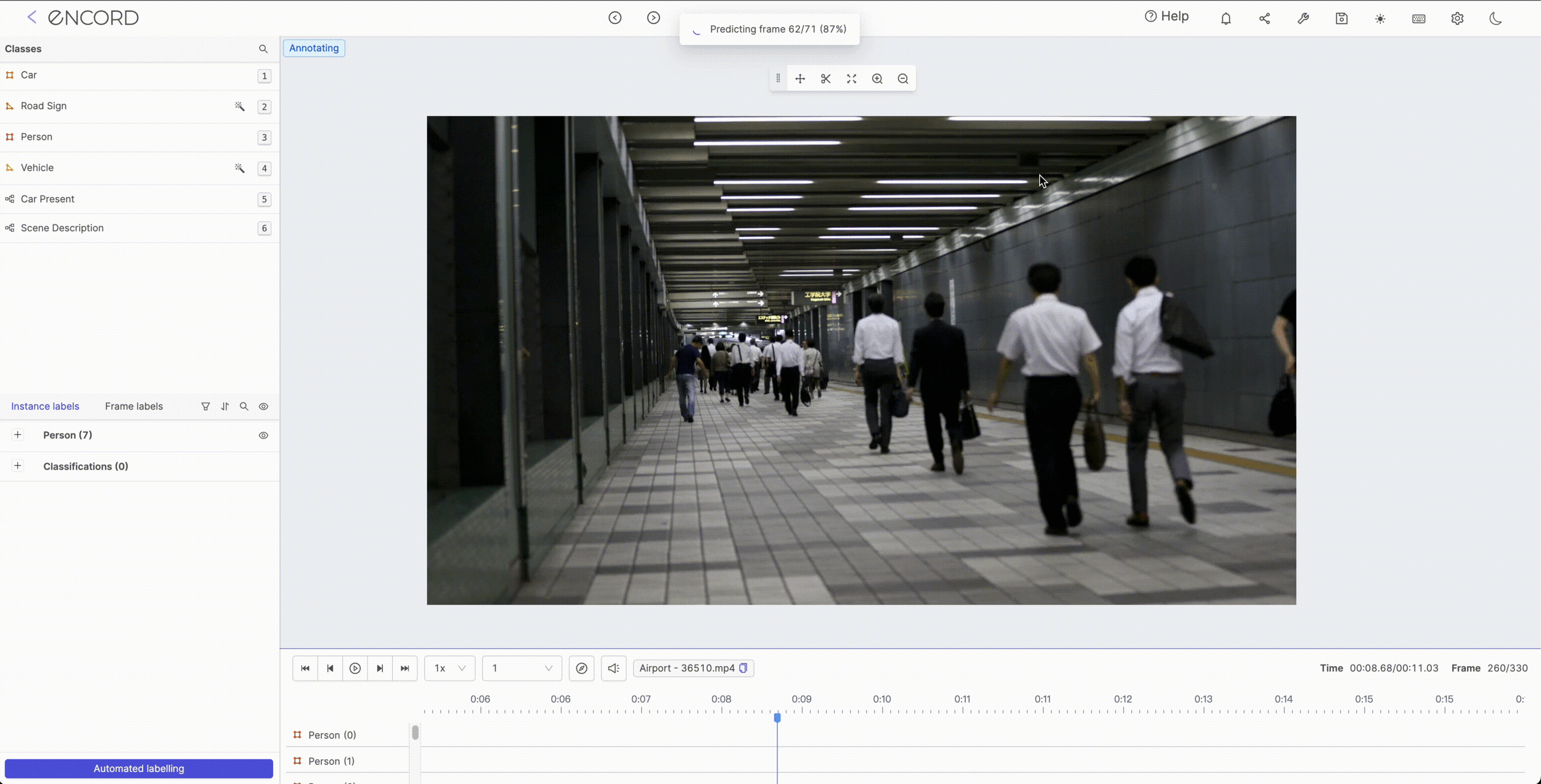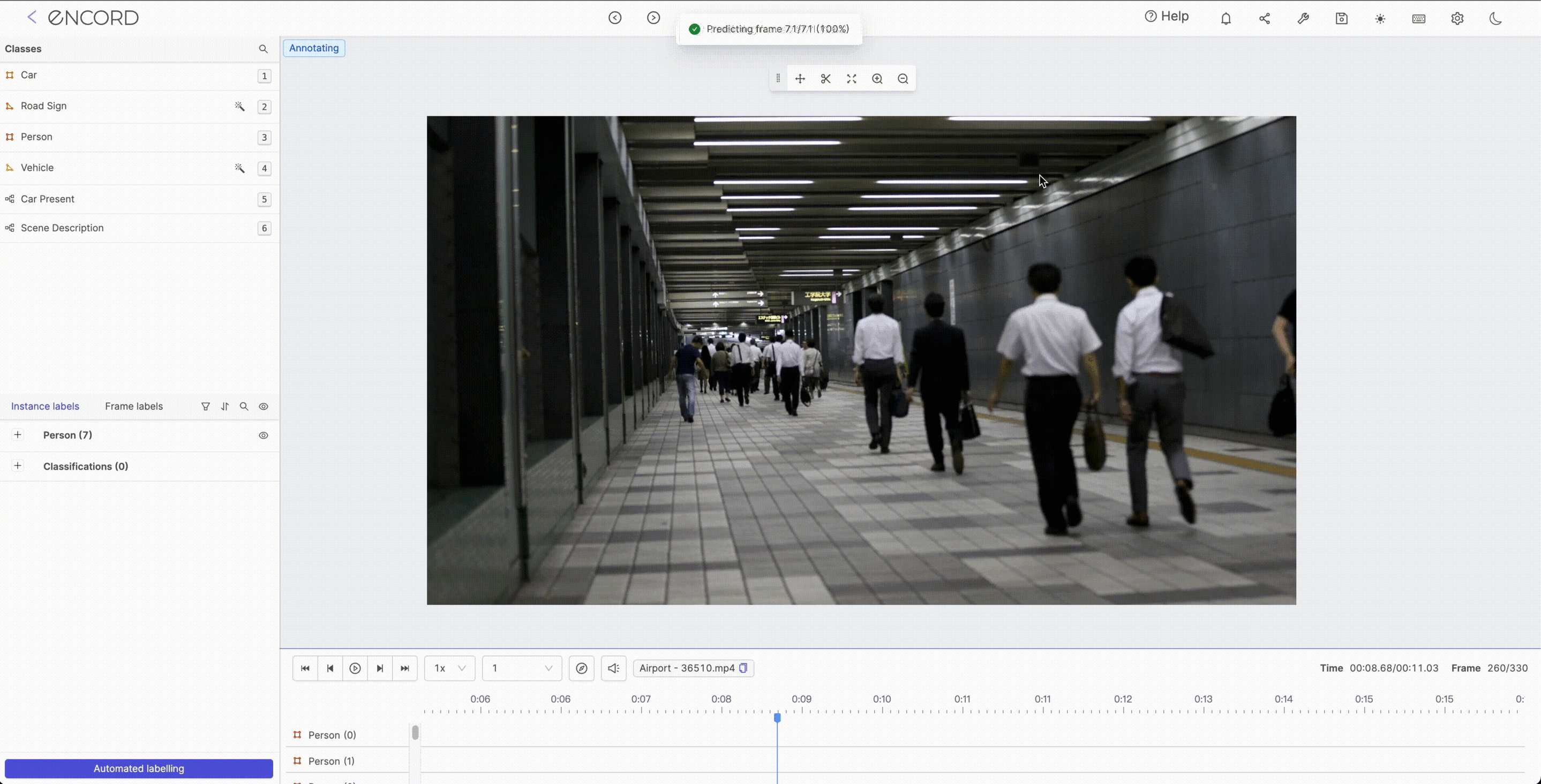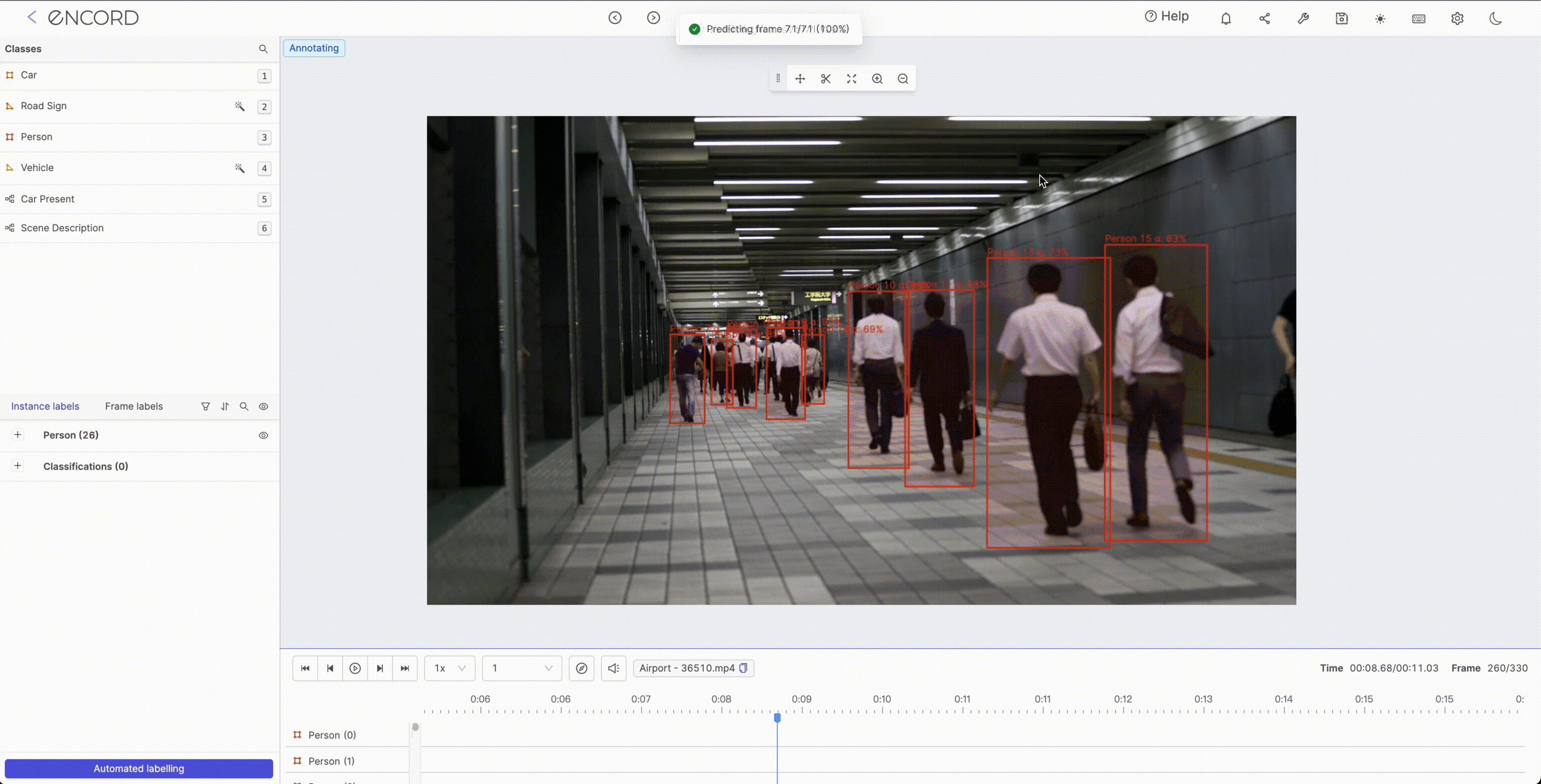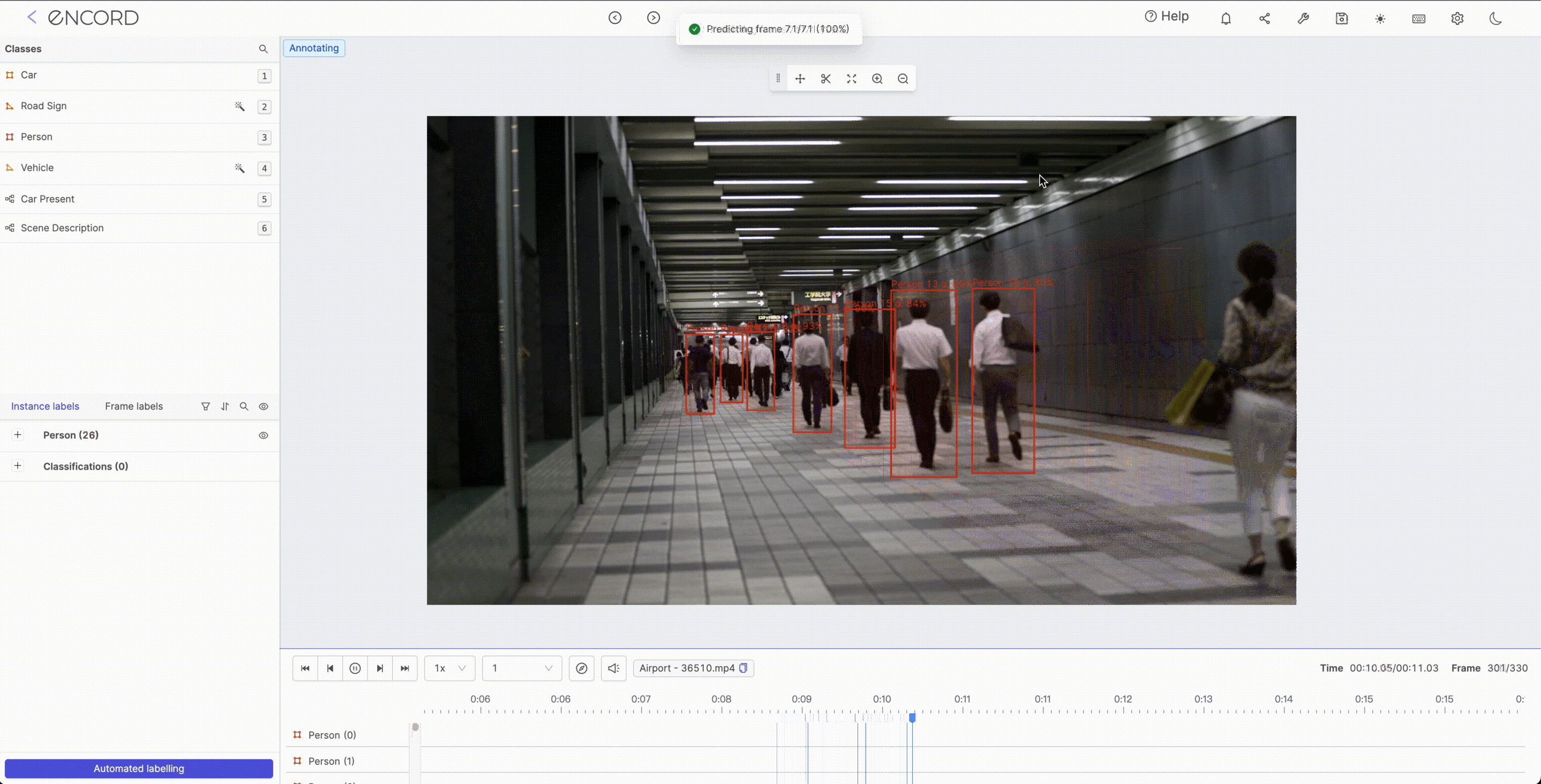
Auto-segmentation is a technique that involves using algorithms or annotation tools to automatically segment an image or video into different regions or objects of interest. This technique is used in various industries, including medical imaging, object detection, and scene segmentation.
For example, in medical imaging, auto-segmentation can be used to identify and segment different anatomical structures in images, such as tumors, organs, and blood vessels. This can help medical professionals to make more accurate diagnoses and treatment plans
Auto-segmentation can potentially speed up the image analysis process and reduce the likelihood of human error. However, it is important to note that the accuracy of auto-segmentation algorithms depends on the input data quality and the segmentation task's complexity. In some cases, manual review and correction may still be necessary to ensure the accuracy of the results.
💡Read the explainer blog on Segment Anything Model 2 to understand how foundation models are used for auto-segmentation. Interpolation
Interpolation is typically used to fill in missing values or smooth the noise in a dataset. It encompasses the process of estimating the value of a function at points that lie between known data points. Several methods can be used for interpolation in ML such as linear interpolation, polynomial interpolation, and spline interpolation. The choice of interpolation method will depend on the data's characteristics and the project's goals.
Step 1:
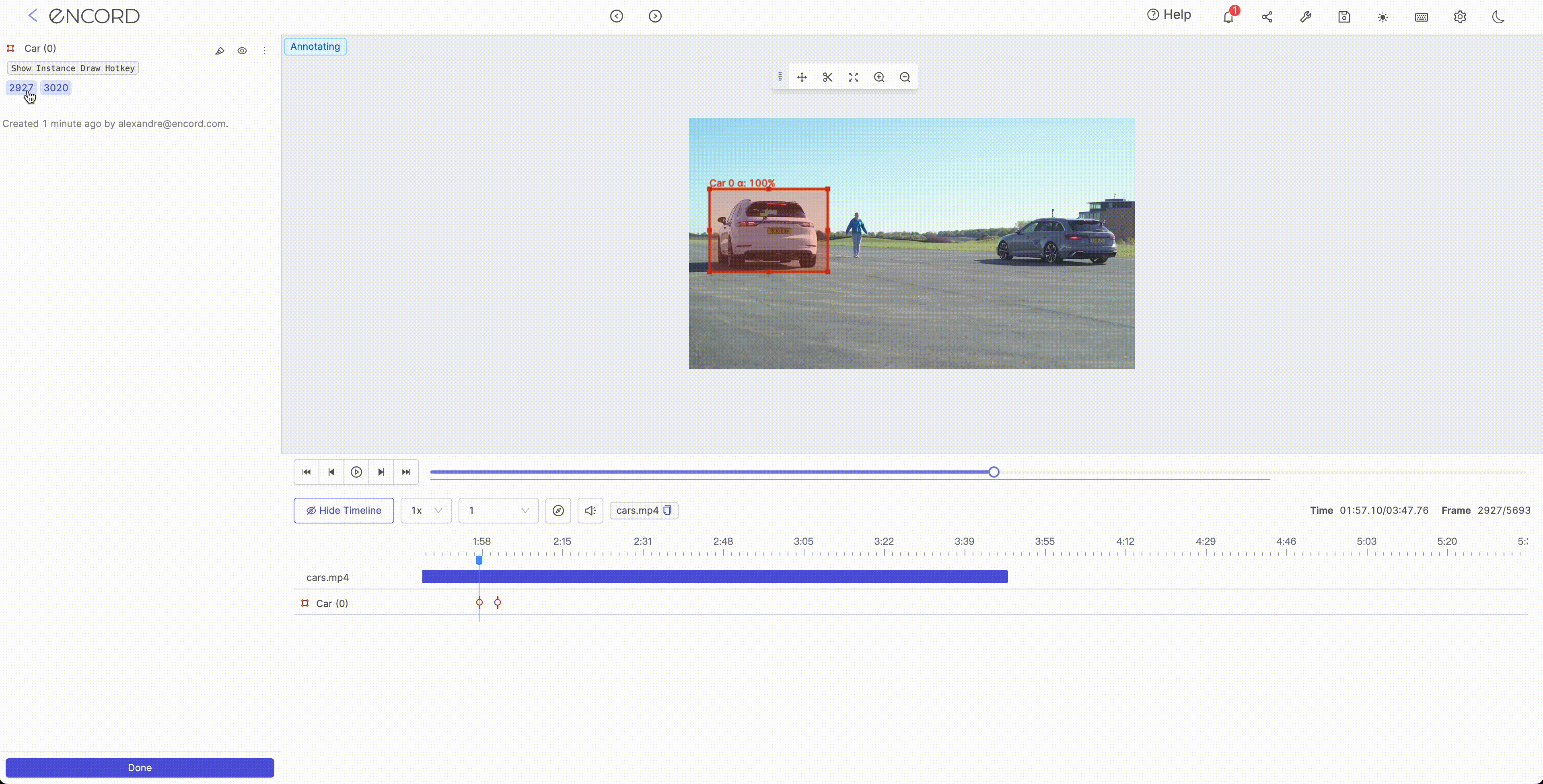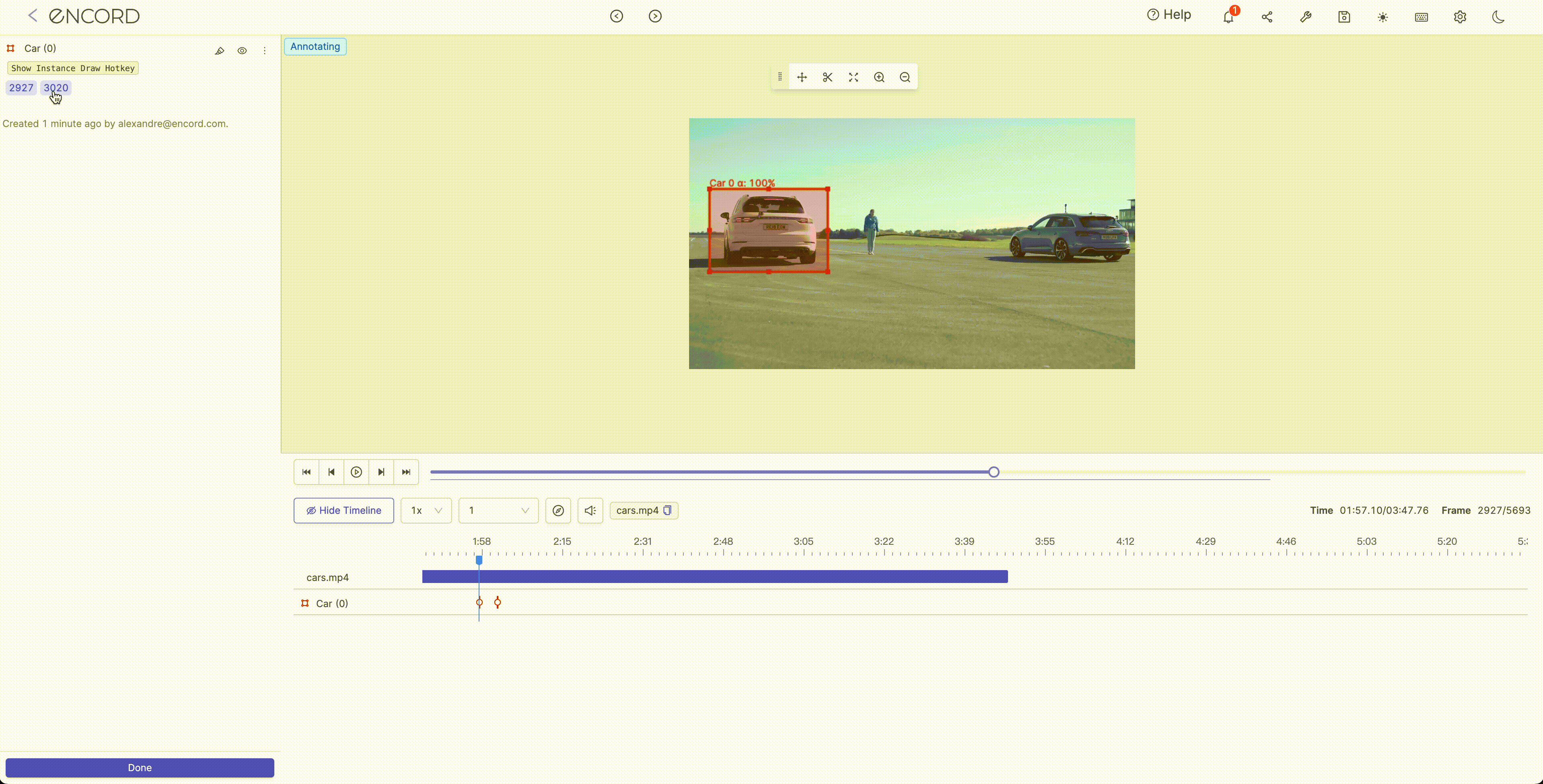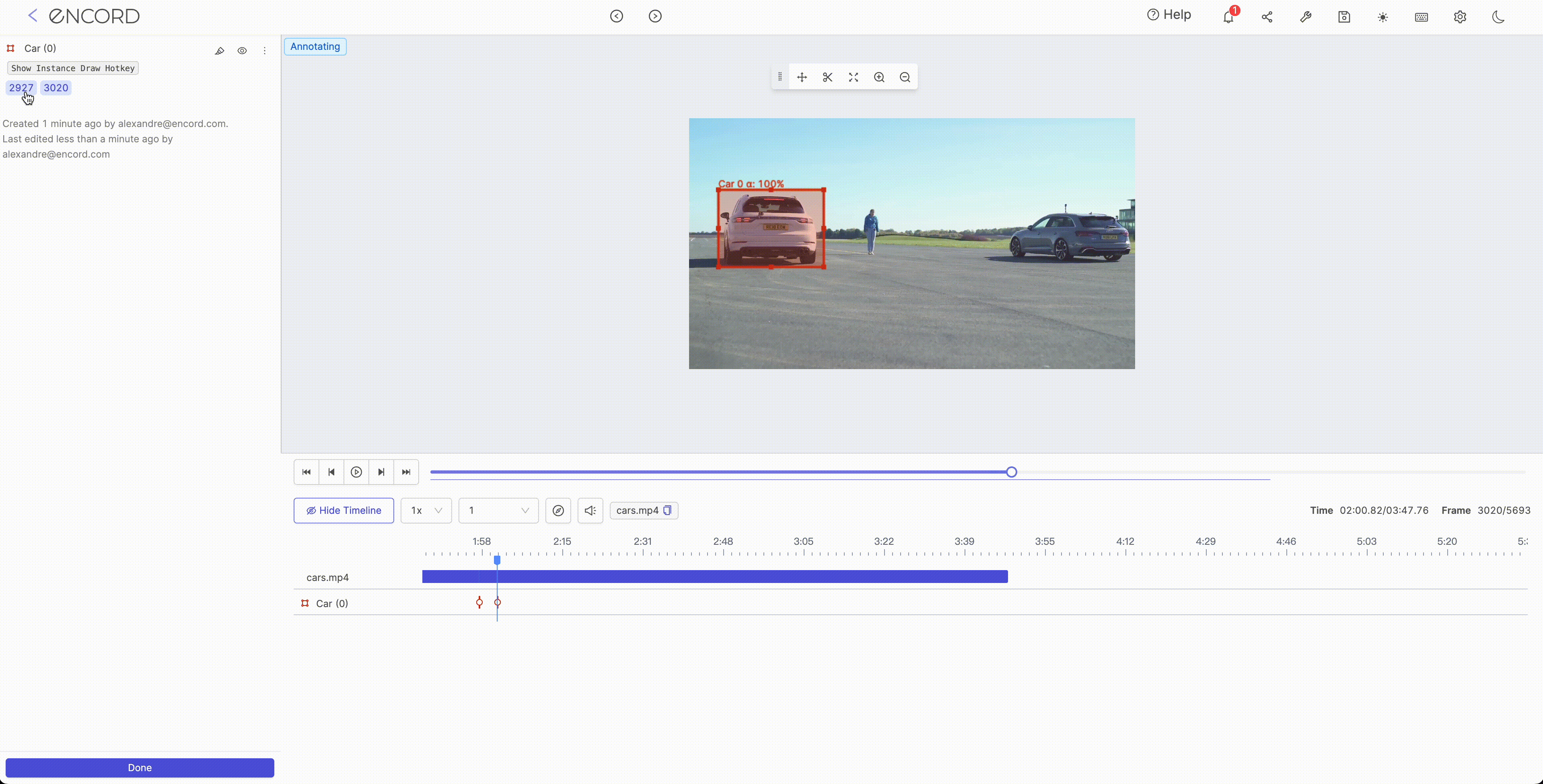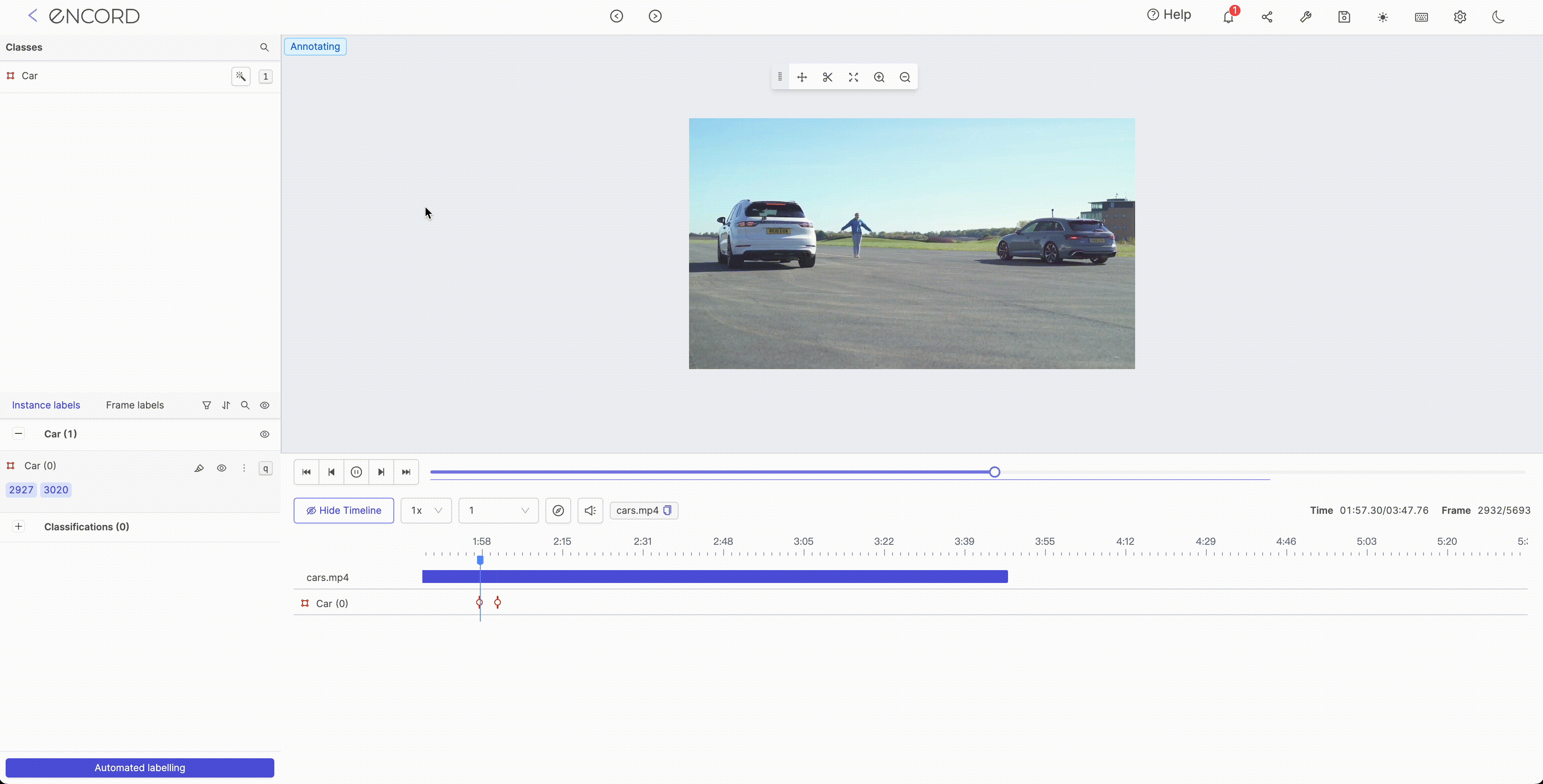
Step 2:
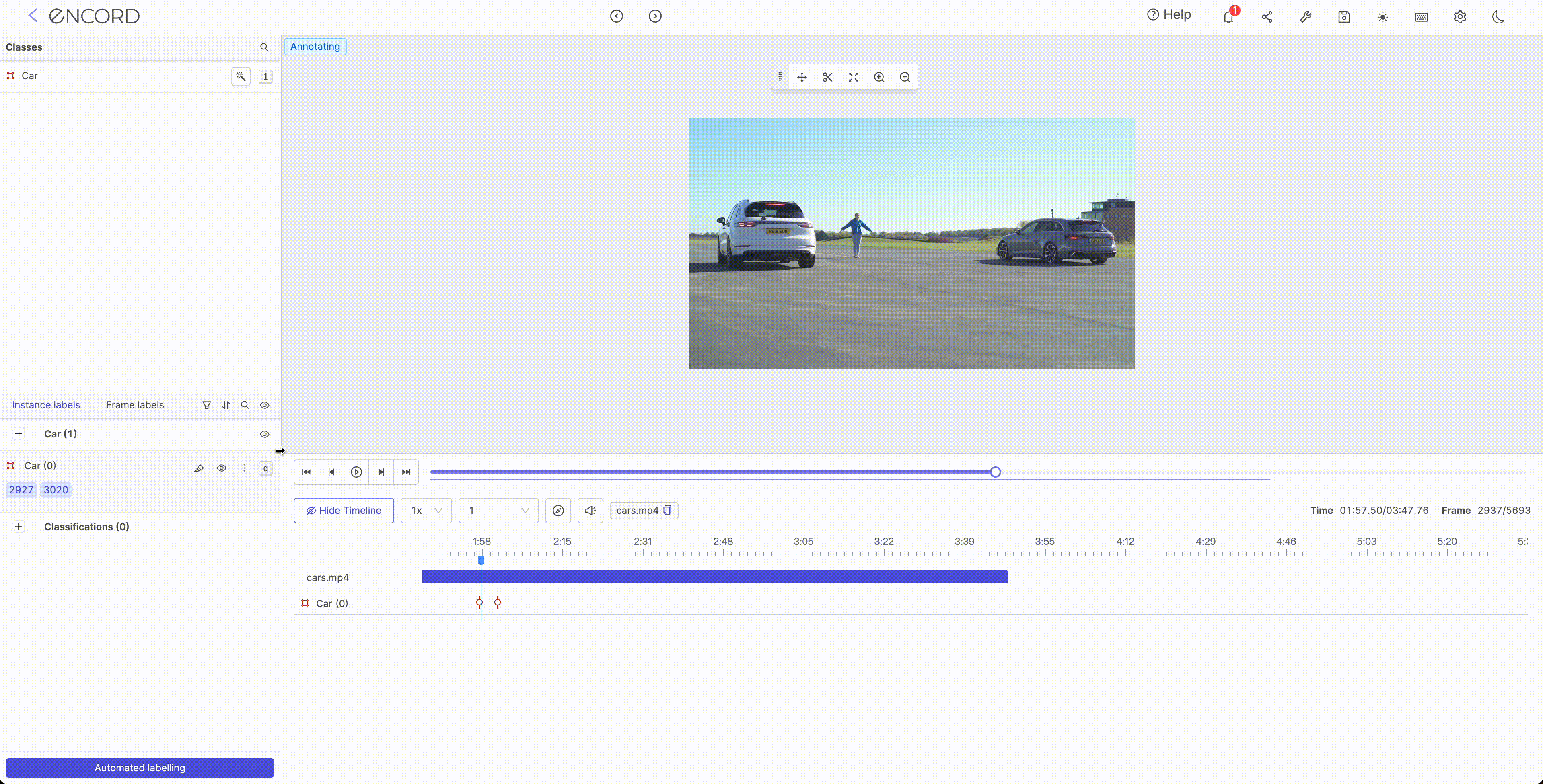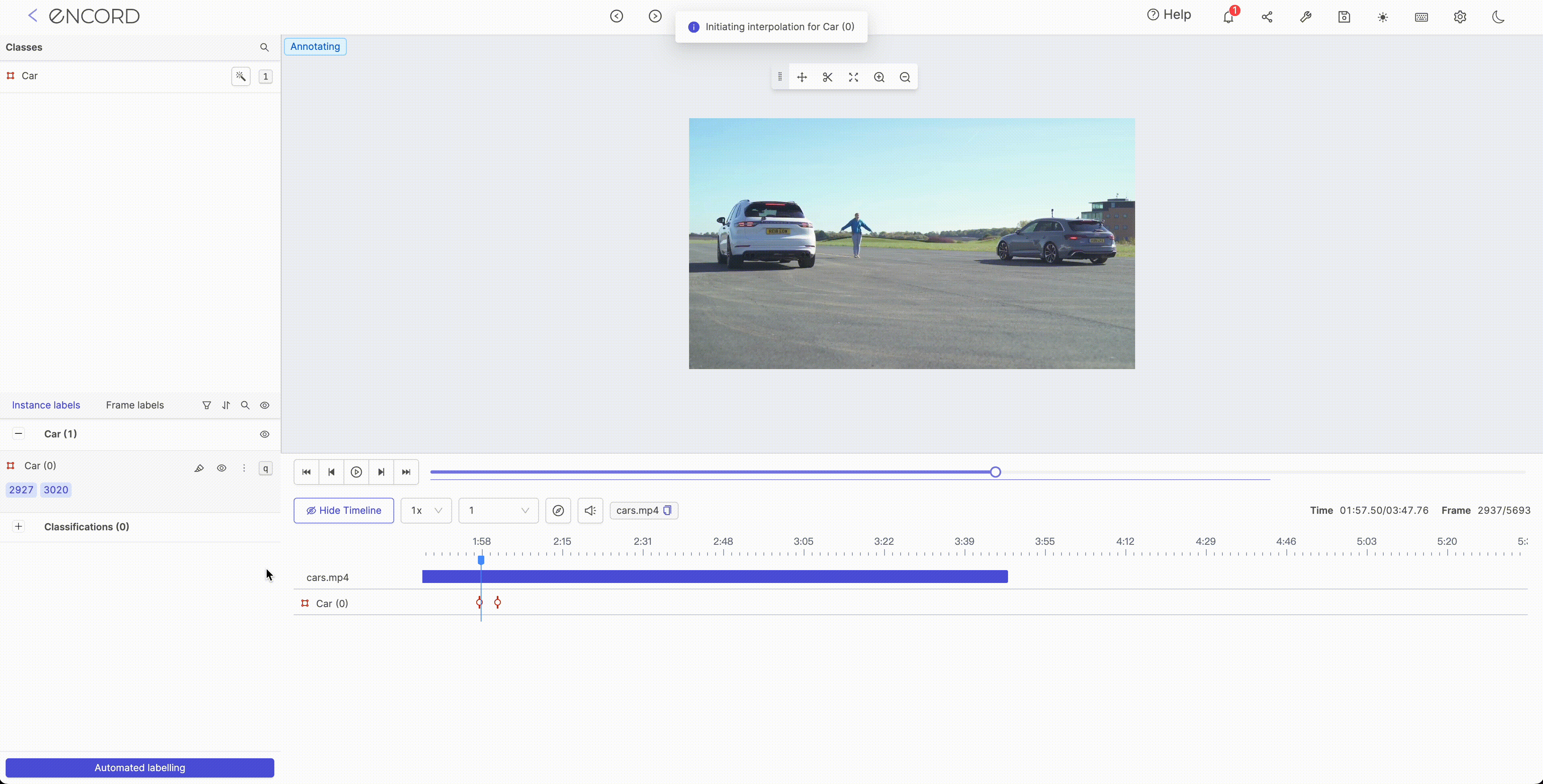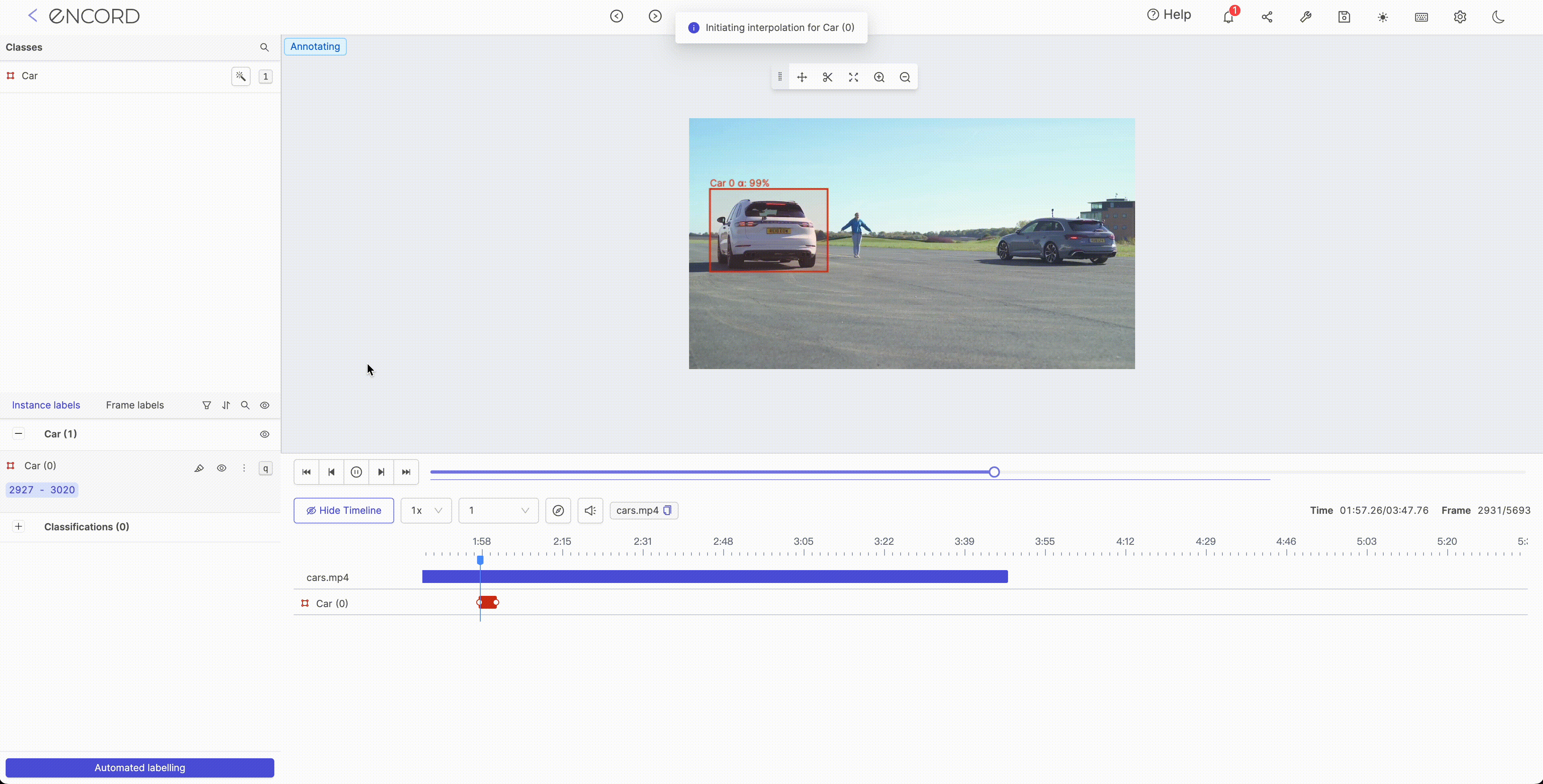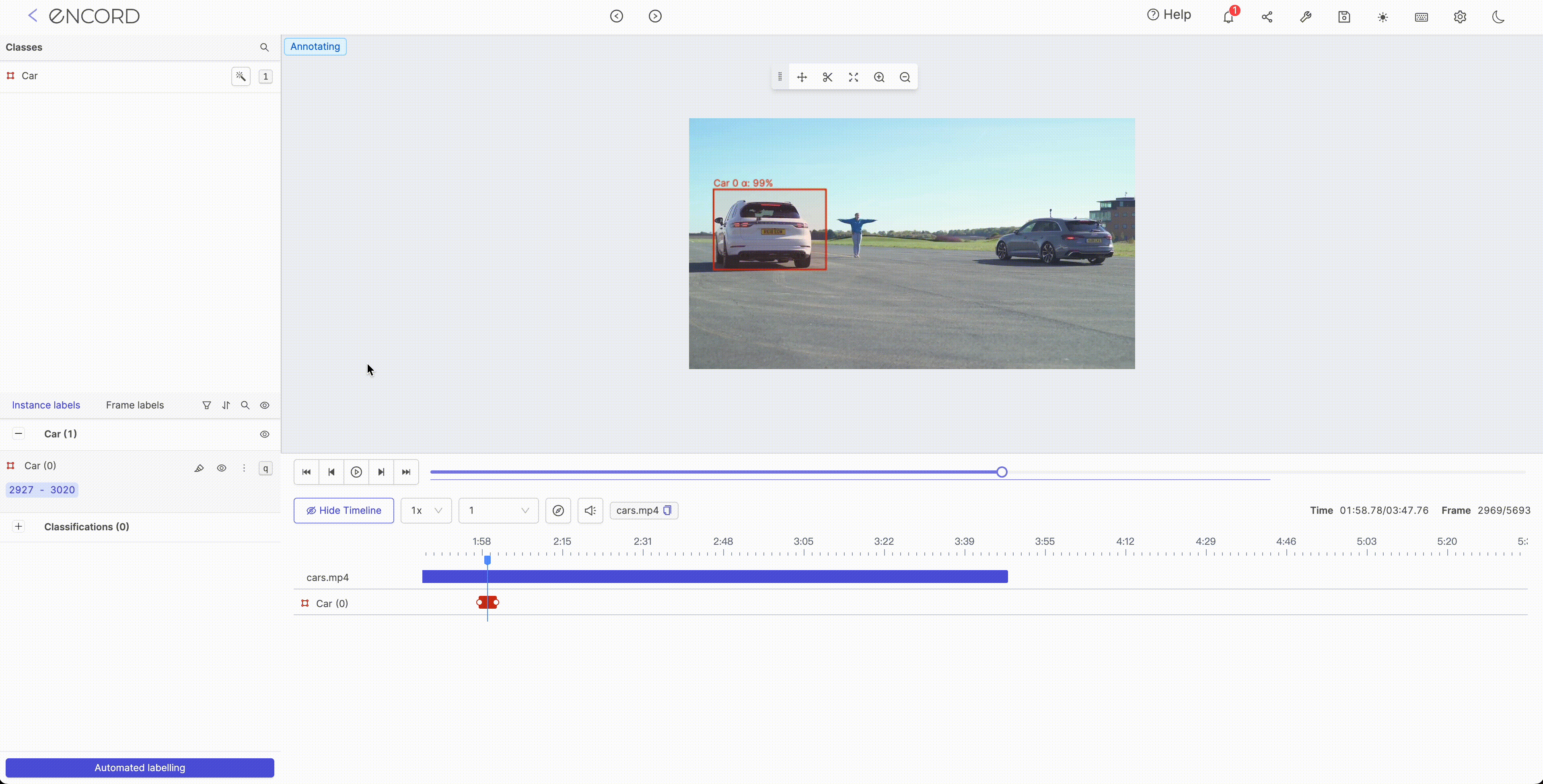
Object Tracking
Object tracking plays a vital role in various applications like security and surveillance, autonomous vehicles, video analysis, and many more. It’s a crucial component of computer vision that enables machines to track and follow objects in motion Using object tracking, you will be able to predict the position and other relevant information of moving objects in a video or image sequence.
Step 1:

Step 2:

💡Check out the Complete Guide to Object Tracking Tutorial to for more insight.Conclusion
Supervised machine learning algorithms depend on labeled data to learn how to generalize to unseen instances. The quality of data provided to the model has a significant impact on its final performance, hence it’s vital the data is accurately labeled and representative of the data available in a real-world scenario; this means AI teams often spend a large portion of their time preparing and labeling their data before it reaches the model training phase.
Manually labeling data is slow, tedious, expensive, and prone to human error. One way to mitigate this issue is with automated data labeling and annotation solutions. Such tools can serve as a cost-effective way to accurately speed up the process, which in turn improves the team’s productivity and workflow.
Ready to accelerate the automation of your data annotation and labeling?
Sign-up for an Encord Free Trial: The Active Learning Platform for Computer Vision, used by the world’s leading computer vision teams.
AI-assisted labeling, model training & diagnostics, find & fix dataset errors and biases, all in one collaborative active learning platform, to get to production AI faster. Try Encord for Free Today.
Want to stay updated?
Follow us on Twitter and LinkedIn for more content on computer vision, training data, and active learning.
Automated Data Labeling FAQs
What are the benefits of automated data labeling?
Automated data labeling helps to increase the accuracy and efficiency of the labeling process in contrast to when it’s performed by humans. It also reduces labeling costs and resources as you are not required to pay labelers to perform the tasks.
How is automated data labeling different than manual labeling?
Manual data labeling is the process of using individual annotators to assign labels to raw data. Opposingly, automated labeling is the same thing but the responsibility is passed on to machines instead of humans to speed up the process and reduce costs.
What is AI data labeling?
AI data labeling refers to a technique that leverages machine learning to provide one or more meaningful labels to raw data (e.g., images, videos, etc.). This is done with the intent of offering a machine learning model with context to learn input-output mappings from the data and make inferences on new, unseen data.
Explore More Data Labeling Resources
Product Demo:
Data Labeling Platforms & Tools:
- Ultimate Guide to Data annotation
- Best data labeling platforms (2025)
- Data Labeling Platforms for Generative AI
- Data Labeling tools with weights and biases integration
- Data Labeling platform trends
- Encord Data Labeling platform
Industry & Use Case
- Data Labeling Platforms for smart cities
- Data Labeling platforms for healthcare AI
- Top Data Labeling platforms for sports AI
- Data Labeling platforms for autonomus vehicle development
- Data Labeling platforms for logistics
- Labeling and analyzing multimodal medical AI data
- Data Labeling platforms for Physical AI
- Best Data Labeling platforms for 3D Lidar
- Best data labeling platforms for Individual AI use cases
Guides & Tutorials
Frequently asked questions
Automated data labeling uses AI-driven tools and algorithms to tag or annotate raw data with meaningful labels. This process accelerates the creation of training datasets for machine learning models by reducing the time and effort required for manual labeling.
Increased accuracy: Reduces human error, ensuring consistent and precise annotations.
Enhanced efficiency: Processes large volumes of data at a faster pace.
Lower costs: Decreases the need for human resources, minimizing operational expenses.
Improved productivity: Frees up human annotators to focus on quality control and complex tasks.
Auto-labeling: Automatically generating labels with algorithms.
Data curation: Organizing and filtering datasets for better management.
Active learning: Suggesting labels based on existing patterns in data.
Human-in-the-loop: Allowing human reviewers to validate and refine machine-generated labels.
Quality control: Ensuring label accuracy through validation mechanisms.
Auto-segmentation uses algorithms to divide images or videos into distinct regions or objects. It is widely applied in industries like medical imaging and object detection, offering faster, more accurate segmentation with reduced manual effort.
Interpolation estimates values for missing or intermediate data points in a dataset, smoothing gaps or noise. It’s used in machine learning to maintain data consistency and fill in incomplete datasets.
Encord includes features that automate various parts of the manual labeling process, enhancing efficiency and reducing the time required for annotation. This includes the use of model integrations to pre-generate captions, allowing users to streamline their workflows and focus on more complex tasks.
Encord streamlines the data labeling process by automating tasks and providing a structured platform to manage annotations. This reduces the reliance on manual processes and spreadsheet allocations, ultimately enhancing collaboration and ensuring that high-quality data is consistently maintained.
Yes, Encord can automate the data labeling process through programmatic integration and visual tooling. This flexibility allows teams to streamline their workflows, reduce manual effort, and focus on higher-level tasks while ensuring that data is accurately labeled and ready for model training.
Encord supports pre-labeling features that allow users to integrate their machine learning models into the annotation process. This functionality helps streamline the labeling workflow by providing initial annotations, which can save time and reduce manual effort during data preparation.
Yes, Encord is designed to support organizations in their journey towards automated labeling. By syncing with existing models, users can leverage Encord's features to transition from manual labeling to more efficient auto labeling processes, ultimately streamlining their operations.
Encord provides automatic label generation capabilities that can significantly expedite the annotation process. Users have found that these models yield high accuracy, allowing teams to focus on evaluating and refining their datasets before deciding on additional labeling tools.
Yes, Encord can support both manual and automated data labeling processes. Our platform is equipped to work with human annotators for intricate labeling tasks while also integrating automated solutions to enhance efficiency and scalability, depending on project demands.
Setting up pre-labeling in Encord involves integrating your model with the platform through an API. Once configured, any new data uploaded to a project can be automatically pre-labeled, enhancing efficiency in the annotation workflow.
No, Encord does not offer auto labeling for clustered data. Instead, users can view similar clusters and manually tag or classify them as needed, providing flexibility in how data is organized for further analysis.
Yes, Encord offers features that complement and enhance internal tools for auto labeling, allowing teams to scale their data annotation efforts efficiently.