Encord Active
Seamlessly test your models and deploy into production with confidence
Evaluate and validate your models against your data to surface, curate, and prioritize the most valuable data for training and fine-tuning to supercharge model performance.
Why Encord?
Join thousands of ML practitioners deploying production-ready AI applications using best-in-class data curation, labeling, and model evaluation tools with Encord.

67% increase in edge-case class performance.

60% increase in labeling speed simplifying data pipelines.

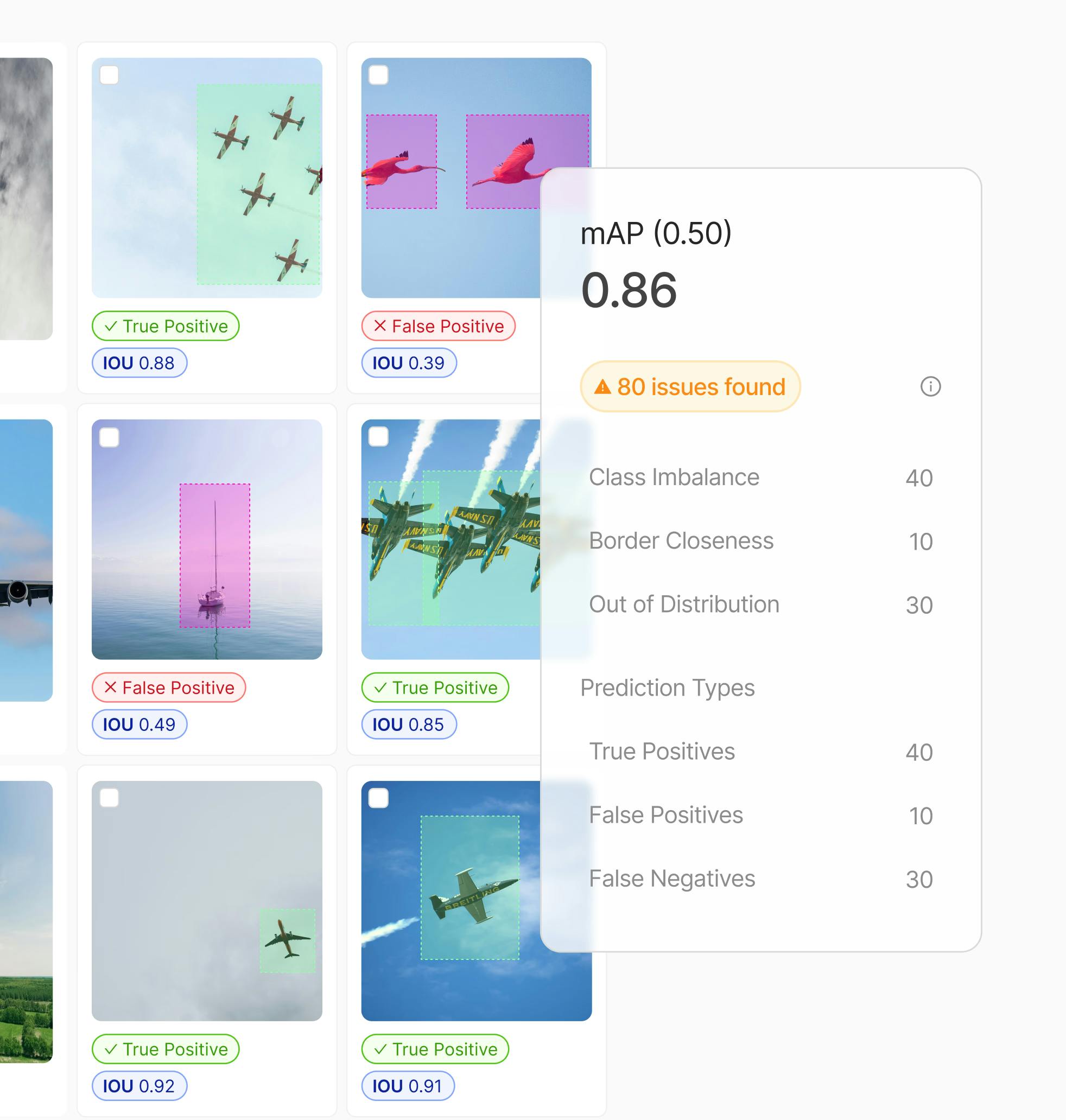
20% increase in mAP leveraging data curation.
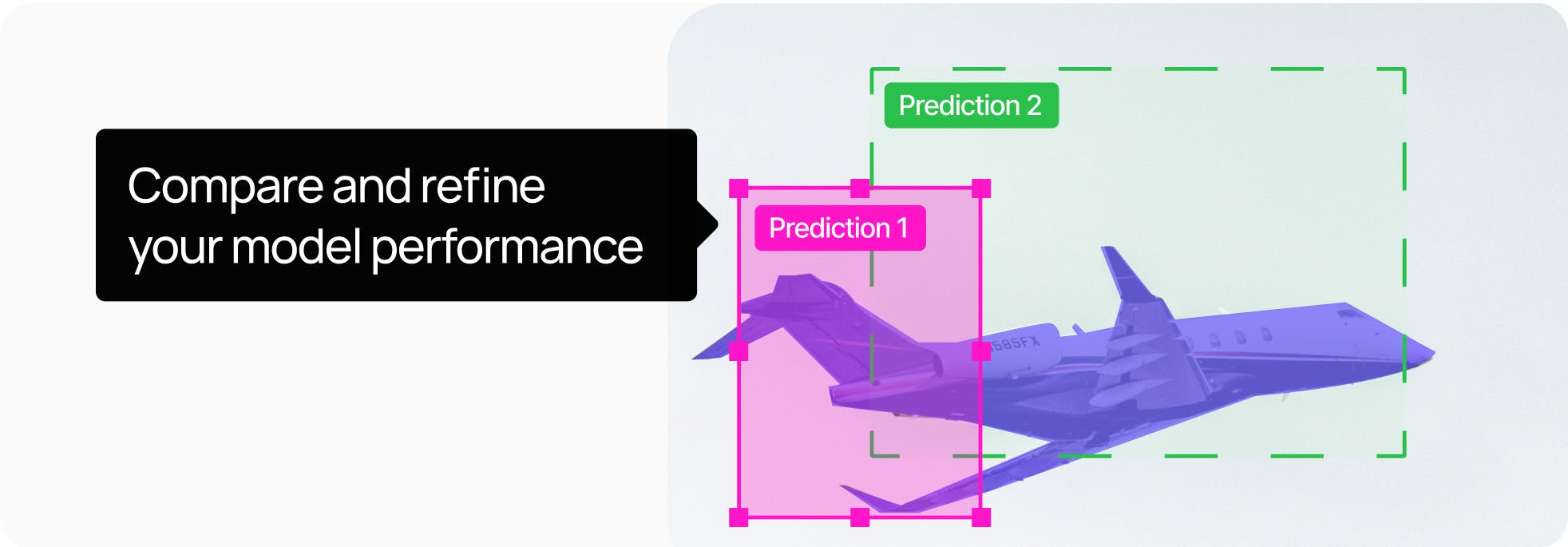
Run robustness checks on your models to deploy high-quality production AI faster
Accelerate your AI development lifecycle with Encord Active, from data curation to deployment, with its cutting-edge model evaluation and active learning capabilities.

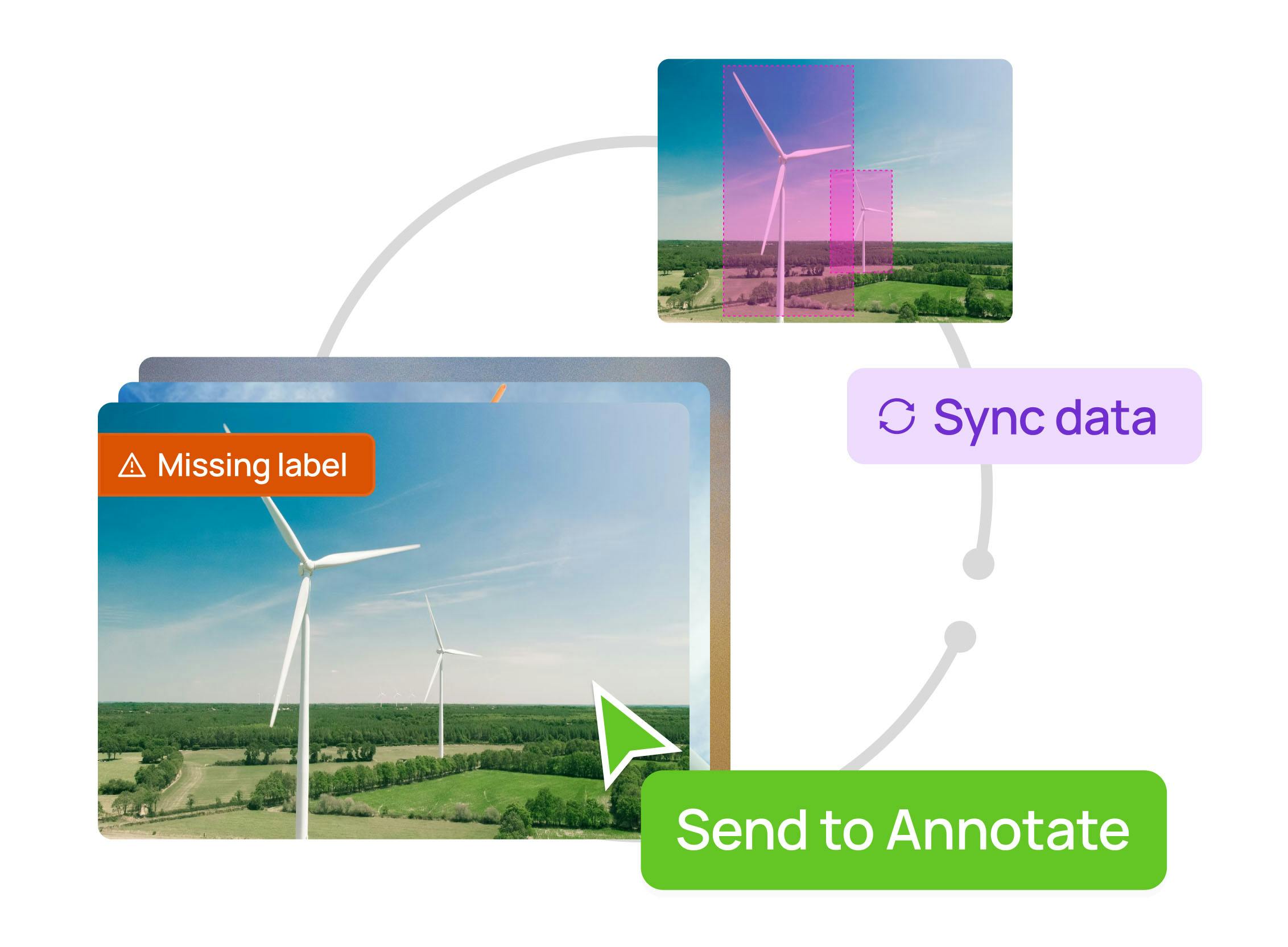
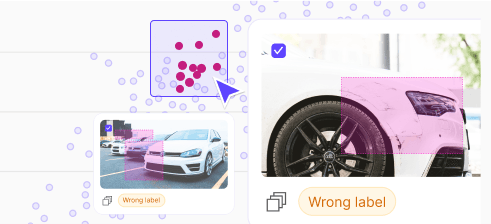
Avoid costly mistakes in your training data
Protect the integrity of your training data with Encord Active's advanced label validation features to enhance its accuracy and reliability.


G2 reviews
Trusted by our customers
Still not sure? Read about what the customers think about our product.
“Pure gold, easily paying for itself through”
Getting Encord to just work with our pipeline was a walk in the park, and for the one odd time when we had to contact support, their team has been amazing and extremely friendly. The annotation tool itself is pure gold, easily paying for itself through increased productivity!
Andrei I, G2 reviewer
“Easy and quick to use to annotate”
Very robust annotation interface, easy to use, and quick to annotate lots of frames/visuals. I explored many, many annotation tools and I enjoy using Encord by far the most.
David F, G2 reviewer
“Easy to use training data platform for model validation”
Encord’s solution provides us with a comprehensive suite of tools to manage annotation workflows and teams that we use to validate the performance of our models and generate new data for training. Focusing our efforts on just annotation data for model failure cases has led to a large reduction in overall error rates.
Mike V, G2 reviewer

"Encord’s robust support system has been remarkable. Whenever questions or issues come up, they are always supportive and helpful. This ensures that our workflows remain uninterrupted."

"It’s always about balancing speed and quality. A lot of platforms prioritize speed over quality or quality over speed. Encord speeds up annotation while still allowing for strong quality control."

“Diving deep into the performance on a class-by-class basis allowed us to tackle some of the worst-performing classes and improve their performance based on insights from analysis of the datasets and models in Encord Active.”
Explore other Encord products

Annotate
Supporting your labeling needs
Super charge your data annotation with AI-powered labeling — including automated interpolation, object detection and ML-based quality control.
Index
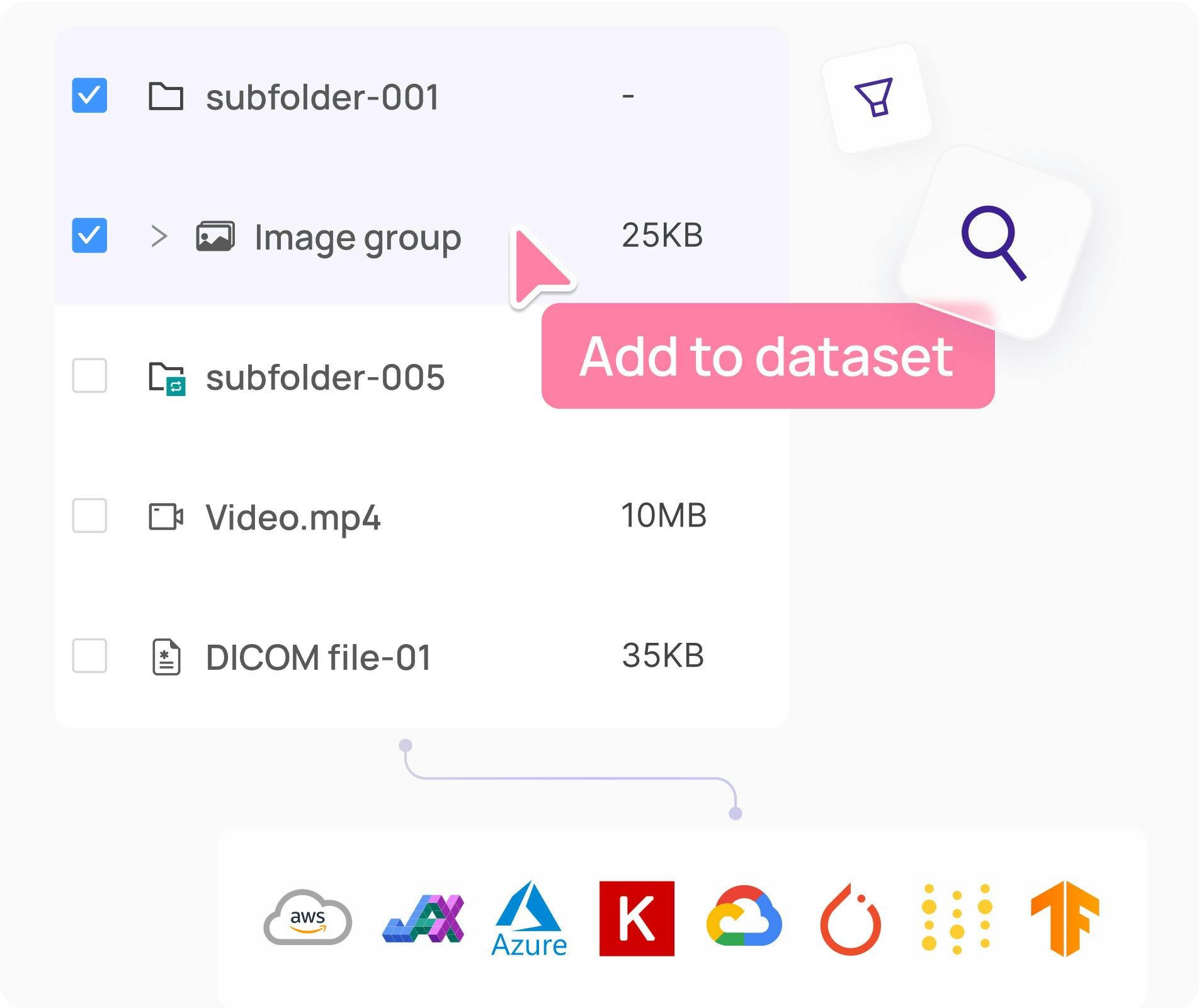
Manage & curate your data
Understand and manage your visual data, prioritize data for labeling, and initiate active learning pipelines.


Take control of your ML pipeline with Encord
Level-up your model development with the Encord Data Engine. Turn unstructured data into production-ready AI in a fraction of the time without compromising quality.