Human-in-the-Loop Machine Learning (HITL) Explained

Product Manager at Encord
Human-in-the-Loop (HITL) is a transformative approach in AI development that combines human expertise with machine learning to create smarter, more accurate models. Whether you're training a computer vision system or optimizing machine learning workflows, this guide will show you how HITL improves outcomes, addresses challenges, and accelerates success in real-world applications.
In machine learning and computer vision training, Human-in-the-Loop (HITL) is a concept whereby humans play an interactive and iterative role in a model's development. To create and deploy most machine learning models, humans are needed to curate and annotate the data before it is fed back to the AI. The interaction is key for the model to learn and function successfully.
Human data annotators, data scientists, and data operations teams always play a role. They collect, supply, and annotate the necessary data. However, how the amount of input differs depends on how involved human teams are in the training and development of a computer vision model.
What Is Human in the Loop (HITL)?
Human-in-the-loop (HITL) is an iterative feedback process whereby a human (or team) interacts with an algorithmically-generated system, such as computer vision (CV), machine learning (ML), or artificial intelligence (AI).
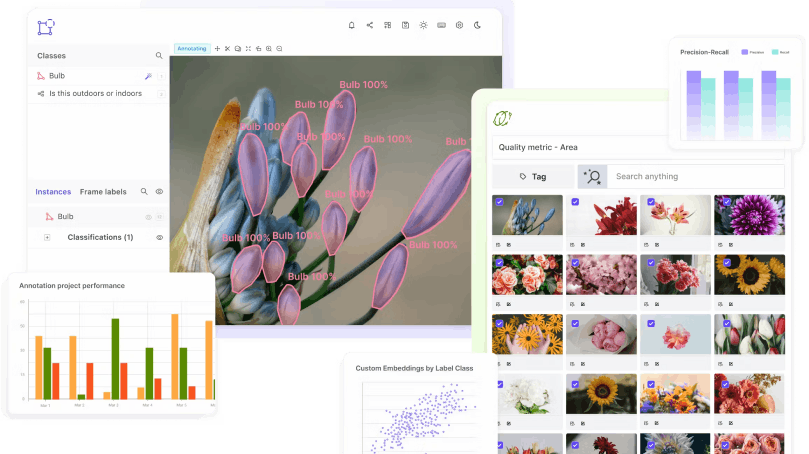

Every time a human provides feedback, a computer vision model updates and adjusts its view of the world. The more collaborative and effective the feedback, the quicker a model updates, producing more accurate results from the datasets provided in the training process.
In the same way, a parent guides a child’s development, explaining that cats go “meow meow” and dogs go “woof woof” until a child understands the difference between a cat and a dog.
 Here's a way to create human-in-the-loop workflows in Encord.
Here's a way to create human-in-the-loop workflows in Encord. How Does Human-in-the-loop Work?
Human-in-the-loop aims to achieve what neither an algorithm nor a human can manage by themselves. Especially when training an algorithm, such as a computer vision model, it’s often helpful for human annotators or data scientists to provide feedback so the models gets a clearer understanding of what it’s being shown.
In most cases, human-in-the-loop processes can be deployed in either supervised or unsupervised learning.
In supervised learning, HITL model development, annotators or data scientists give a computer vision model labeled and annotated datasets.

HITL inputs then allow the model to map new classifications for unlabeled data, filling in the gaps at a far greater volume with higher accuracy than a human team could. Human-in-the-loop improves the accuracy and outputs from this process, ensuring a computer vision model learns faster and more successfully than without human intervention.
In unsupervised learning, a computer vision model is given largely unlabeled datasets, forcing them to learn how to structure and label the images or videos accordingly. HITL inputs are usually more extensive, falling under a deep learning exercise category.
Active Learning vs. Human-In-The-Loop
Active learning and human-in-the-loop are similar in many ways, and both play an important role in training computer vision and other algorithmically-generated models. Yes, they are compatible, and you can use both approaches in the same project.
However, the main difference is that the human-in-the-loop approach is broader, encompassing everything from active learning to labeling datasets and providing continuous feedback to the algorithmic model.
Benefits of Human-in-the-Loop in Machine Learning
Human-in-the-loop (HITL) systems combine automated model predictions with structured human oversight to improve machine learning outcomes. The overall aim of HITL is to strengthen model performance by integrating continuous human feedback directly into the training, testing, tuning, and validation cycle.
With consistent human input, machine learning and computer vision models become progressively smarter. Rather than relying solely on automated predictions, models are refined through human corrections, validations, and contextual judgment. Over time, this iterative feedback loop enables models to produce more accurate, reliable, and confident result, particularly when identifying objects in images or videos, interpreting complex data, or generating responses.
Improved Model Accuracy: Human reviewers correct misclassifications and validate outputs, ensuring higher-quality training data. This continuous feedback reduces errors and improves prediction accuracy across iterations.
Faster and More Efficient Training Cycles: By focusing human input on uncertain or high-impact data points, HITL accelerates model refinement. Instead of retraining blindly, teams can prioritize areas where the model needs the most improvement
Better Handling of Edge Cases: AI systems often struggle with rare, ambiguous, or complex examples. Human oversight helps identify and correct these edge cases, improving robustness and real-world reliability.
Reduced Bias in AI Systems: Human evaluators can detect biased outputs or imbalanced datasets, helping mitigate fairness issues and improving model generalization across diverse scenarios.
Stronger Model Validation and Reliability: Because humans are involved in training, testing, and validation, HITL creates more trustworthy AI systems. Models are not only trained more effectively but also continuously tuned to meet project requirements and performance standards
Over time, this structured collaboration between humans and machines leads to smarter models, better outcomes, and more reliable AI systems.
Drawbacks and Limitations of Human-in-the-Loop
Although human-in-the-loop (HITL) systems offer significant benefits, they also introduce operational and scalability trade-offs that teams must carefully manage.
Speed Constraints: Human review adds latency to AI pipelines. While automated systems process data at scale, human annotators can’t match that speed. As a result, HITL workflows may slow down validation cycles and extend project timelines compared to fully automated approaches..
Human Error Risks: While human oversight improves quality, annotators are not infallible. Fatigue, subjective interpretation, or simple mistakes can introduce errors that affect model performance. If unnoticed, incorrect feedback may propagate through training cycles and degrade outputs.
Cost Considerations: HITL systems require skilled annotators, reviewers, or domain experts. Recruiting, training, managing, and quality-controlling these teams increases operational costs. As datasets grow, especially in complex or multimodal projects, these costs can scale quickly too.
Scalability Limitations: As datasets grow, maintaining consistent human oversight becomes harder. Without strategies like active learning or AI-assisted pre-labeling, HITL workflows can become resource-intensive and difficult to scale.
Workflow and Infrastructure Complexity: Integrating humans into AI development pipelines requires structured collaboration systems, version control, audit trails, and performance tracking. Managing these workflows adds operational complexity beyond purely automated systems.
Examples of Human-in-the-Loop AI Training
One example is in the medical field, with healthcare-based image and video datasets. A 2018 Stanford study found that AI models performed better with human-in-the-loop inputs and feedback compared to when an AI model worked unsupervised or when human data scientists worked on the same datasets without automated AI-based support.
Humans and machines work better and produce better outcomes together. The medical sector is only one of many examples whereby human-in-the-loop ML models are used.
When undergoing quality control and assurance checks for critical vehicle or airplane components, an automated, AI-based system is useful; however, for peace of mind, having human oversight is essential.
Human-in-the-loop inputs are valuable whenever datasets are rare and a model is being fed. Such as a dataset containing a rare language or artifacts. ML models may not have enough data to draw from; human inputs are invaluable for training algorithmically-generated models.
A Human-in-the-Loop Platform for Computer Vision Models
With the right tools and platform, you can get a computer vision model to production faster.
Encord is one such platform, a collaborative, active learning suite of solutions for computer vision that can also be used for human-in-the-loop (HITL) processes.
With AI-assisted labeling, model training, and diagnostics, you can use Encord to provide the perfect ready-to-use platform for a HITL team, making accelerating computer vision model training and development easier. Collaborative active learning is at the core of what makes human-in-the-loop (HITL) processes so effective when training computer vision models. This is why it’s smart to have the right platform at your disposal to make this whole process smoother and more effective.
We also have Encord Active, an open-source computer vision toolkit, and an Annotator Training Module that will help teams when implementing human-in-the-loop iterative training processes.
At Encord, our active learning platform for computer vision is used by a wide range of sectors - including healthcare, manufacturing, utilities, and smart cities - to annotate human pose estimation videos and accelerate their computer vision model development.
Encord is a comprehensive AI-assisted platform for collaboratively annotating data, orchestrating active learning pipelines, fixing dataset errors, and diagnosing model errors & biases. Try it for free today.

Frequently Asked Questions:
Q1. How do you measure the success of HITL workflows?
HITL success can be measured using:
- Improved model accuracy over successive training iterations
- Reduction in task-specific error rates
- Higher consistency in labeled datasets
- Faster convergence during training
- Time and cost savings compared to fully manual workflows
Organizations often track validation accuracy, inter-annotator agreement, correction rates, and model performance uplift before and after human review cycles to quantify impact.
Q2. How does Encord support HITL workflows for annotating prompts and responses?
Encord provides a structured platform for implementing human-in-the-loop processes across multimodal datasets, including prompts and responses for large language models. Teams can annotate, review, and evaluate generated outputs for helpfulness, truthfulness, and relevance.
This enables systematic feedback loops that support LLM fine-tuning, prompt optimization, and reinforcement learning workflows, ensuring higher quality AI outputs.
Q3. What tools are essential for implementing HITL in a project?
Key tools required for HITL implementation include:
- Annotation platforms for labeling, reviewing, and correcting datasets
- Active learning systems to identify high-uncertainty samples requiring human intervention
- Collaboration workflows to manage reviewer assignments, approvals, and quality checks
- Evaluation frameworks to measure performance improvements over time
Together, these tools ensure effective coordination between human expertise and machine automation.
Q4. How does Encord integrate with human-in-the-loop reinforcement learning?
Encord supports human-in-the-loop reinforcement learning by enabling structured ranking, scoring, and comparison of model outputs. Human reviewers can evaluate multiple generated responses, provide preference signals, and score outputs based on quality criteria.
This structured feedback can then be incorporated into reinforcement learning pipelines, helping improve alignment, reliability, and model performance over time.
Explore More Human-in-the-loop Resources:
Product Demo:
See how to ensure efficiency & quality in data annotation with the Encord platform
Learning Guides:
Frequently asked questions
Human-in-the-loop (HITL) is an iterative feedback process whereby a human (or team) interacts with an algorithmically-generated model. Providing ongoing feedback improves a model's predictive output ability, accuracy, and training outcomes.
Human-in-the-loop data annotation is the process of employing human annotators to label datasets. Naturally, this is widespread, with numerous AI-based tools helping to automate and accelerate the process.
However, HITL annotation takes human inputs to the next level, usually in the form of quality control or assurance feedback loops before and after datasets are fed into a computer vision model.
Human-in-the-loop optimization is simply another name for the process whereby human teams and data specialists provide continuous feedback to optimize and improve the outcomes and outputs from computer vision and other ML/AI-based models.
Almost any AI project can benefit from human-in-the-loop workflows, including computer vision, sentiment analysis, NLP, deep learning, machine learning, and numerous others. HITL teams are usually integral to either the data annotation part of the process or play more of a role in training an algorithmic model.
Yes, HITL can be implemented post-deployment to continuously improve model performance. For example, human feedback can refine predictions or outputs when the model encounters new, unexpected data in real-world scenarios.
Annotation: Platforms for labeling and reviewing datasets.
Active learning: Algorithms that identify where human intervention is needed.
Collaboration: Workflow management systems to streamline human and machine interactions.
HITL supports ethical AI by involving humans in decision-making, ensuring that models are trained and used responsibly. This approach helps identify potential ethical concerns, such as discriminatory behavior, before a model is deployed.
Improved model accuracy over iterations.
Reduction in error rates for specific tasks.
Time and cost savings compared to fully manual annotation or development.
Corrective feedback on errors or misclassifications.
Label refinement or additional context for ambiguous data.
Identification of edge cases not handled by the model.
Encord provides a robust platform that enables teams to incorporate human-in-the-loop processes by facilitating the annotation of prompts and responses. This capability helps in evaluating the helpfulness and truthfulness of AI-generated content, allowing for fine-tuning of large language models (LLMs) and optimization of system prompts.
Encord provides a robust platform designed for human in the loop annotation, allowing teams to efficiently manage real-time use cases and ensure high-quality outputs. Our human in the loop system integrates seamlessly into existing workflows, supporting various annotation tasks while addressing the specific needs of your projects.
Human-in-the-loop annotation with Encord is designed for refining already deployed models rather than starting the annotation process. This method allows teams to continuously improve model performance by analyzing incoming data against expected distributions, which is vital for long-term success in medical AI deployments.
Encord provides tools that facilitate human in the loop workflows, allowing teams to effectively manage and validate data annotation efforts. By leveraging our capabilities, users can enhance their annotation processes and ensure high-quality outputs while reducing the workload on human labelers.
Encord supports the implementation of active learning and human-in-the-loop workflows, providing tools that facilitate continuous model improvement by incorporating human feedback into the training process. This approach helps in refining data annotations and improving overall model accuracy.
The human in the loop feature is crucial for maintaining high-quality annotations, especially when dealing with complex datasets. Encord facilitates the integration of human feedback into workflows, which helps refine and improve the accuracy of model outputs.
The human in the loop interface in Encord features a queue displaying each workflow stage defined for the project. Users can view proposed labels and products, make adjustments to annotations, and tighten edges as needed within the annotation interface.
Encord supports human-in-the-loop reinforcement learning by providing frameworks for ranking and scoring model outputs. This integration allows users to enhance their learning processes by incorporating human feedback into the training cycle.
Encord supports human-in-the-loop annotation by providing tools that enable collaboration between automated systems and human annotators. This approach ensures high-quality labeled data while maintaining efficiency in the annotation process.
Encord facilitates human-in-the-loop workflows by allowing programmatic annotation of data, followed by human review of edge cases. This approach ensures high-quality annotations by combining automated processes with human oversight.