5 Ways to Reduce Bias in Computer Vision Datasets

Despite countless innovations in the field of computer vision, the concept of ‘garbage in, garbage out’ is still a key principle for anything within the field of data science. An area where this is particularly pertinent is bias within the datasets being used to train machine learning models.
If your datasets are biased in some way, it will negatively impact the outcomes of your computer vision models, whether it’s using a training dataset or has moved into the production phase.
There are some well known examples of bias within machine learning models. For example, Amazon’s recruitment algorithms were found to contain gender-bias, favoring men over women. A risk assessment sentencing algorithm used by state judges across the US, known as COMPAS (Correctional Offender Management Profiling for Alternative Sanctions), was found to be biased against black defendants when sentenced for violent crimes. Microsoft experimented with a Twitter chatbot called Tay for one day in 2016, with the algorithm producing thousands of Tweets filled with racism, hate speech, anti-semitism, sexism, and misogyny.
What do all of these things have in common, and what does this mean for companies experimenting with using artificial intelligence models on image or video-based datasets?
Algorithms themselves can’t be biased. On the other hand, whether it’s intentional or not, humans are. Personal bias, in favor of one thing, concept or demographic, can unintentionally influence the results an algorithm produces. Not only that, but if a biased dataset is used to train these algorithms, then the outcomes will be skewed towards or against specific results and outcomes.
In this article, we outline the problems caused by biased computer vision datasets and five ways to reduce bias in these datasets.
What Are The Problems Caused By A Biased Computer Vision Dataset?
Bias can enter datasets or computer vision models at almost any juncture. It’s safe to assume there’s bias in almost any dataset, even those that don’t involve people. Image or video-based datasets could be biased toward or against too many or too few examples of specific objects, such as cars, trucks, birds, cats, or dogs. The difficulty is, knowing how to identify the bias and then understanding how to counteract it effectively.
Bias can unintentionally enter datasets at a project's collection, aggregation, model selection, and end-user interpretation phase. This bias could result from human biases and prejudices, from those involved in selecting the datasets, producing the annotations and labels, or from an unintentional simplification of the dataset.
Different types of bias can occur, usually unintentionally, within an image or video-based computer vision dataset. Three of the most common are the following:
Uneven number of sample classes: When there is this kind of bias in the dataset ⏤ especially during the training stage ⏤ the model is exposed to different classes of objects numerous times. Therefore, it’s sensible to assume that the model might give more weight to samples that it has seen more frequently, and underrepresented samples may have poor performance. For example, the aim of a training project might be to show a computer vision model how to identify a certain make and model of car. If you don’t show enough examples of other cars that aren’t that make and model then it won’t perform as well as you want.
Ideally, to reduce this type of bias, we want the model to see the same number of samples of different classes, especially when trying to identify positive and negative results. Even more important, a CV model is exposed to a sufficient range of sample classes when the model training aims to support medical diagnoses.
Selection bias: When the dataset is collected, it may be sampled from a subset of the population, such as a specific ethnic group, or in many cases, datasets unintentionally exclude various ethnic groups. Or datasets have too many men or women in them.
In any scenario along those lines, the dataset won’t fully represent the overall population and will, intentionally or not, come with a selection bias. When the models are trained on this kind of dataset, they have poor generalization performance at the production stage, generating biased results.
Category bias: When annotating a dataset, annotators, and even automated annotation tools can sometimes confuse one label category with another. For example, a dog could be labeled as a fox, or a cat is labeled as a tiger.
In this scenario, a computer vision model will perform below expectations because of the confusion and bias in the category labels.
Any of these can unbalance a dataset, producing unbalanced or biased outcomes. There are other examples, of course, such as the wrong labels being applied depending on the country/region. Such as the use of the word “purse” in America, meaning a woman’s handbag, whereas a purse in the UK is the name for a woman’s wallet.
Algorithmic bias is also possible and this can be caused by a number of factors. For example, a computer vision model being used in the wrong context or environment, such as a model designed for medical imaging datasets being used to identify weather patterns or tidal erosion. Human bias naturally influences and impacts computer vision models too.
Examples of How Bias Can Be Reduced in Computer Vision Datasets
Thankfully, there are numerous ways you can reduce bias in computer vision datasets, such as:
1. Observe the annotation process to measure class imbalances, using a quality control process to limit any potential category or selection bias.
2. Whenever possible, when sourcing datasets, images or videos must come from different sources to cover the widest possible range of objects and/or people, including applicable genders and ethnic groups.
3. Annotation procedure should be well-defined, and consensus should be reached when there are contradictory examples, or fringe/edge cases within the dataset.
With every training and production-ready dataset, the aim should be to collect a large-scale selection of images or videos that are representative of the classes and categories for the problem you are trying to solve and annotate them correctly.
Now, here’s five ways to reduce bias in more detail:
Observe and monitor the class distributions of annotated samples
During the annotation process, we should observe the class distributions within the dataset. If there are underrepresented sample groups within the dataset, we can increase the prioritization of the underrepresented classes in unlabeled samples using an active learning schema. For example, we can find images similar to the minority classes in our dataset, and we can increase their order in the annotation queue.
With Encord Active, you can more easily find similar images or objects in your dataset, and prioritize labeling those images or videos to reduce the overall bias in the data.
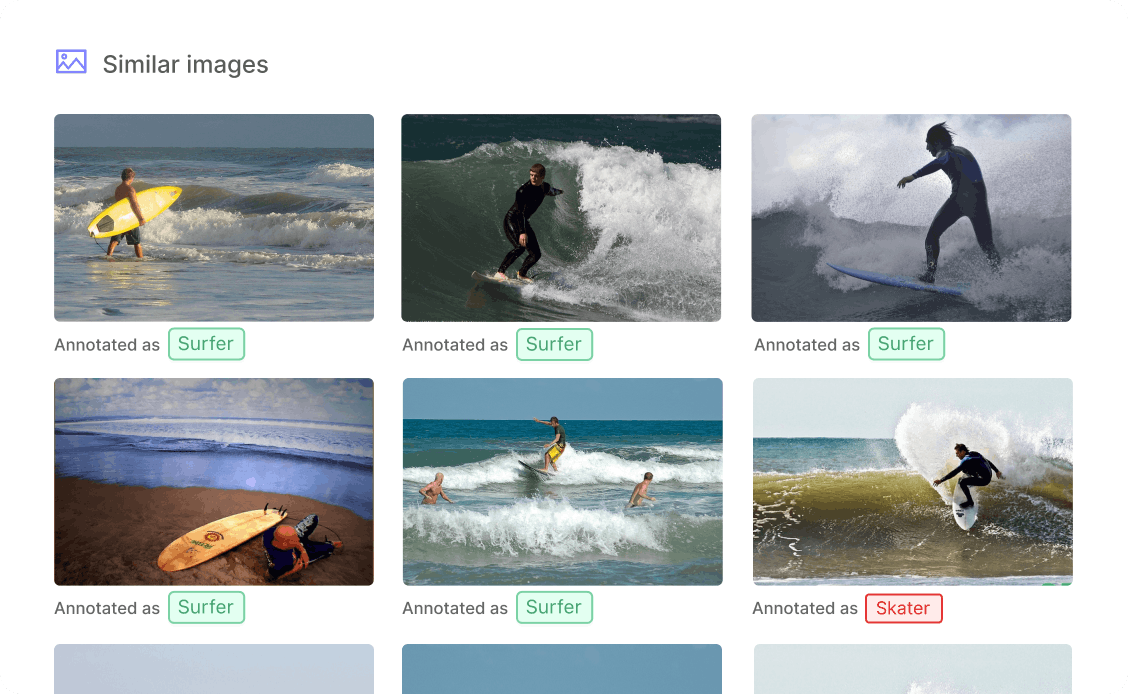
Finding similar images in Encord Active
Ensure the dataset is representative of the population in which the model will work
When collecting and collating any dataset, we should be careful about creating a dataset that accurately represents the population (e.g., a “population” refers to any target group that the model will process during the production stage).
For example, suppose a medical imaging computer vision project is trying to collect chest X-Ray images to detect COVID-19 in patients. In that case, these images should come from different institutions and a wide range of countries. Otherwise, we risk bias in the model when there isn’t a broad enough sample size for a specific group.
Clearly define processes for classifying, labeling, and annotating objects
Before any annotation work starts, a procedure/policy should be prepared.
In this policy, classes and labels should be clearly defined. If there are confusing classes, their differences should be explained in detail, or even sample images from each class should be shared. If there are very close objects of the same type, it should be clearly defined whether they will be labeled separately or whether a single annotation will cover both. If there are occluded objects, will their parts be labeled separately or as a whole? All of this should be defined before any annotations and labels are applied.
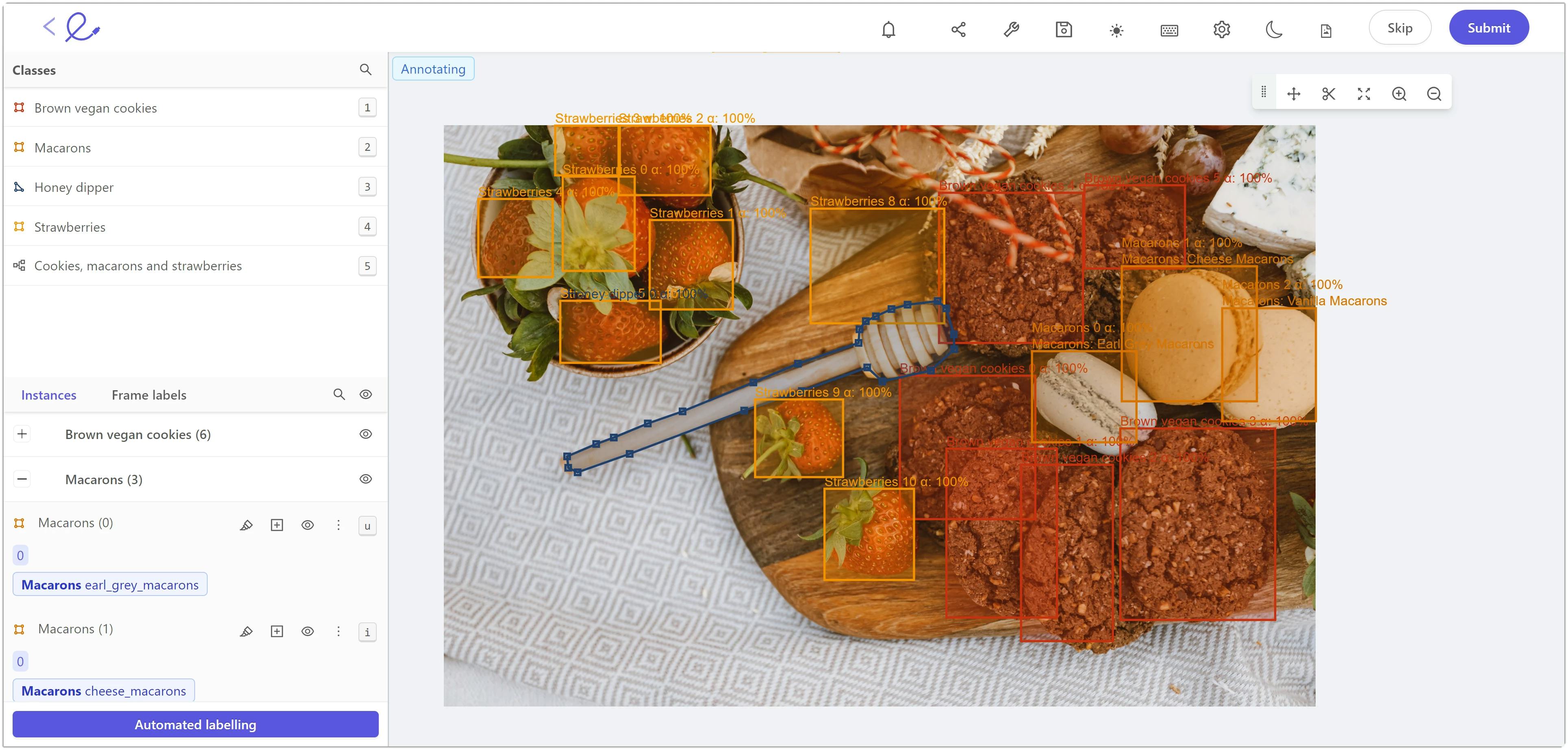
Image annotation within Encord
Establish consensus benchmarks for the quality assurance of labels
When there is a domain-specific task, such as in the healthcare sector, images or videos should be annotated by different experts to avoid bias according to their own experiences. For example, one doctor may be more aligned to classify tumors as malignant due to their own experience and personality, while others may do the opposite. Encord Annotate has tools such as consensus benchmark and quality assurance to reduce the possibility of this type of bias negatively influencing a model.
Check the performance of your model regularly
You must regularly check the performance of your model. By reviewing your model's performance, you can see under which samples/conditions your model fails or performs well. So that you know which samples you should prioritize for the labeling work. Encord Active provides a user interface (UI) so you can easily visualize a model's performance.
With Encord Active, users can define metrics to assess how well their model performs against those metrics and goals.
How Encord Can Help You Address Bias In Your Datasets
Reducing bias in real-world computer vision model training data is integral to producing successful outcomes from production-ready models. One of the best ways to do that is to equip your annotation teams with the best tools, such as Encord.
Encord is an AI-assisted active learning platform for image and video-based computer vision models and datasets. It’s a powerful tool, developed alongside numerous real-world use cases, such as those in the medical and healthcare sector, and dozens of other industries.
With Encord Active, you can also access an open-source customizable toolkit for your data, labels, and models. Everything we have developed will help you reduce bias and improve quality and processes. Therefore, the labels and annotations applied to datasets ensure enhanced outcomes and outputs from computer vision models.
Reduce bias in your computer vision datasets and training models. Encord is a comprehensive AI-assisted platform for collaboratively annotating data, orchestrating active learning pipelines, fixing dataset errors, and diagnosing model errors & biases. Try it for Free Today.
Frequently asked questions
Encord's platform is designed to enhance data curation processes by providing advanced tools for identifying and managing corner case images. This includes leveraging machine learning models that can be fine-tuned to improve recall on specific domains, thereby reducing the challenges associated with extreme corner cases and ensuring more reliable outcomes.
Encord focuses on making the labeling process more efficient by leveraging improved vision models, which reduces the need for extensive fine-tuning and annotation. This approach not only saves money but also increases throughput, allowing teams to focus on enhancing model performance through better data management.
Encord includes a comprehensive model evaluation toolkit designed to help users identify biases and performance issues in their computer vision models. This toolkit enables users to analyze model outputs, understand failure points, and make informed adjustments to improve overall accuracy and reliability.
Encord's platform supports efficient data annotation workflows tailored for stereo camera outputs, enabling users to categorize and label data accurately. This includes enhanced tools for managing large datasets and ensuring high-quality annotations that are crucial for machine learning model training.
Encord provides comprehensive tools for filtering and curating data, allowing users to identify areas of interest for annotation. This includes evaluating video quality, detecting systematic errors, and filtering data based on various metrics and metadata, such as video source and format.
Encord enhances the curation process by enabling users to visualize video data at both the frame and video levels. Users can scrub through frames, select points of interest, and plot metrics to identify significant moments in the footage, aiding in effective data management.
Encord focuses on enhancing data quality with features that allow users to curate datasets by filtering out poor quality images, such as blurry or irrelevant ones. This ensures that only high-quality examples are used for model training, improving overall model performance.
Yes, Encord enables users to oversample specific data types by applying filters based on characteristics like brightness. This feature ensures that models are trained on the most relevant data, improving overall model performance.
Encord allows users to perform on-the-fly pre-processing of satellite imagery, which includes enhancing features and improving contrast directly within the platform, eliminating the need for extensive external processing.
Encord allows users to zoom in and out of files and adjust brightness levels to improve visibility. These tools enable annotators to get the best view of the data, which is crucial for accurate annotations.