Med-PaLM: Google Research’s Medical LLM | Explained

Google has been actively researching the potential applications of artificial intelligence in healthcare, aiming to detect diseases early and expand access to care. As part of this research, Google built Med-PALM, the first AI system to obtain a pass mark on US Medical License Exam (USMLE) questions.
At their annual health event, The Check Up, Google introduced their latest model, Med-PaLM 2, a large language model (LLM) designed for the medical domain that provides answers to medical questions.
Med-PaLM 2 is able to score 85% on medical exam questions, an 18% improvement from the original Med-PaLM’s performance.
What is Med-PaLM?
Med-PaLM is a large-scale generalist biomedical AI system that operates as a multimodal generative model, designed to handle various types of biomedical data, including clinical language, medical imaging, and genomics, all with the same set of model weights.
The primary objective of Med-PaLM is to tackle a wide range of biomedical tasks by effectively encoding, integrating, and interpreting multimodal data. Med-PaLM leverages recent advances in language and multimodal foundation models, allowing for rapid adaptation to different downstream tasks and settings using in-context learning or few-shot fine-tuning.
The development of Med-PaLM stems from the understanding that medicine is inherently multimodal, spanning text, imaging, genomics, and more. Unlike traditional AI models in biomedicine, which are often unimodal and specialized to execute specific tasks, Med-PaLM harnesses the capabilities of pretrained models and builds upon recent advancements in language and multimodal AI.
The foundation of Med-PaLM is derived from three pretrained models:
- Pathways Language Model (PaLM) is a densely-connected, decoder-only, Transformer-based large language model, trained using the Pathways system. PaLM was trained on an extensive corpus of 780 billion tokens, encompassing webpages, Wikipedia articles, source code, social media conversations, news articles, and books.
- Vision Transformer (ViT) is an extension of the Transformer architecture designed to process visual data. Two ViT models with different parameter sizes are incorporated into Med-PaLM, each pretrained on a vast classification dataset consisting of approximately 4 billion images.
- PaLM-E is a multimodal language model that can process sequences of multimodal inputs, combining text, vision, and sensor signals. This model was built on pretrained PaLM and ViT models, and was initially intended for embodied robotics applications. PaLM-E demonstrated strong performance on various vision-language benchmarks.
The integration of these pretrained models is accomplished through fine-tuning and aligning PaLM-E to the biomedical domain using the MultiMedBench dataset. MultiMedBench plays a pivotal role in the development and evaluation of Med-PaLM.
Med-PaLM is trained with a mixture of different tasks simultaneously, leveraging instruction tuning to prompt the model for various tasks using task-specific instructions, context information, and questions. For certain tasks, a "one-shot exemplar" is introduced to enhance instruction-following capabilities. During training, image tokens are interweaved with text tokens to create multimodal context input for the model.

The resulting Med-PaLM model (with 12 billion, 84 billion, and 562 billion parameter variants) achieves remarkable performance on a wide range of tasks within the MultiMedBench benchmark, often surpassing state-of-the-art specialist models by a significant margin. Notably, Med-PaLM exhibits emergent capabilities such as zero-shot generalization to novel medical concepts and tasks, and demonstrates promising potential for downstream data-scarce biomedical applications.
In addition to its performance, Med-PaLM has garnered attention for its ability to process inputs with multiple images during inference, allowing it to handle complex and real-world medical scenarios effectively.
In addition to releasing a multimodal generative model, Google and DeepMind took the initiative to curate datasets and benchmarks for the development of biomedical AI systems. Moreover, they made these valuable resources openly accessible to the research community.
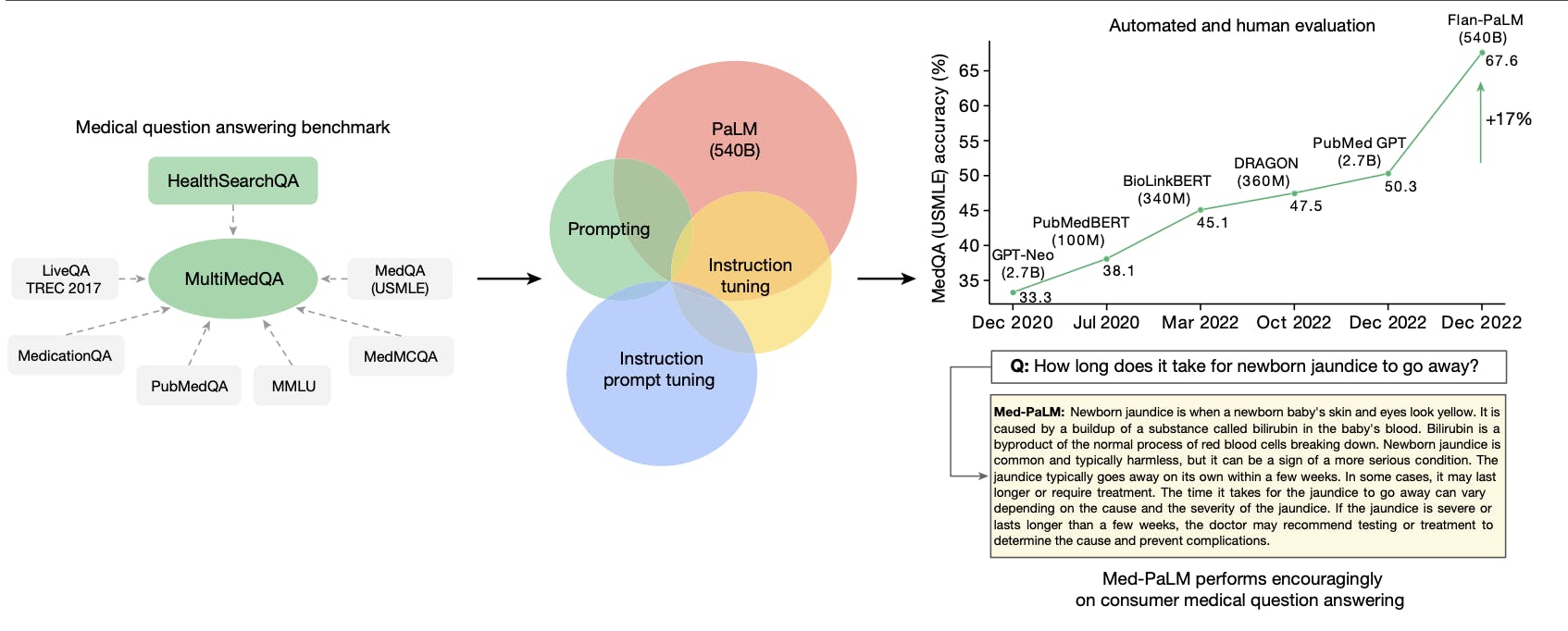
MultiMedBench
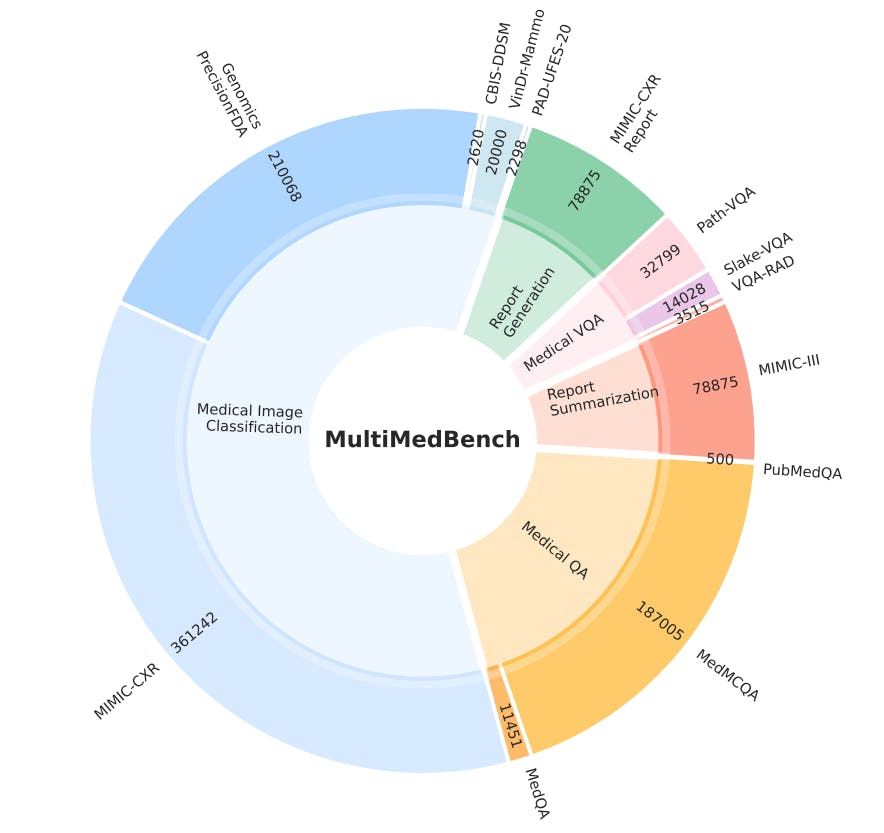
MultiMedBench is a multimodal biomedical benchmark that serves as a comprehensive and diverse evaluation dataset for medical AI applications. Developed as an essential component for training and evaluating generalist biomedical AI systems, MultiMedBench encompasses a wide array of tasks, spanning various data modalities, including clinical language, medical imaging, and genomics.
The benchmark comprises 14 challenging tasks, including medical question answering, image interpretation, radiology report generation, and genomic variant calling. These tasks represent real-world medical complexities and demand multimodal data processing and reasoning capabilities.
Towards Generalist Biomedical AI
MultiMedBench standardizes the evaluation, comparison, and advancement of AI models in the biomedical domain. It fosters collaboration and transparency through open-source access, encouraging reproducibility and knowledge sharing in AI research for medicine. This benchmark represents a significant step forward in developing versatile AI systems with potential applications ranging from scientific discovery to improved healthcare delivery.
MultiMedQA
MultiMedQA is a comprehensive collection of multiple-choice medical question-answering datasets, used for training and evaluating Med-PaLM. MultiMedQA is comprised of the following datasets: MedQA, MedMCQA, and PubMedQA.
These question-answering tasks are language-only and do not involve the interpretation of additional modalities such as medical imaging or genomics. The training set consists of 10,178 questions from MedQA and 182,822 quotations from MedMCQA. The test set contains 1,273 questions from MedQA, 4,183 questions from MedMCQA, and 500 questions from PubMedQA.
HealthSearchQA
HealthSearchQA is a curated free-response dataset comprised of 3,375 commonly searched consumer medical questions. The dataset was carefully assembled using medical conditions and their associated symptoms — publicly-available commonly searched questions related to medical conditions were retrieved from search engine results pages and compiled to form the HealthSearchQA dataset.
This dataset is designed as an open benchmark for consumer medical question answering, aiming to reflect real-world concerns and inquiries that consumers often have about their health. The questions in HealthSearchQA cover a wide range of topics, including queries about medical conditions, symptoms, and possible implications.

Towards Expert-Level Medical Question Answering with Large Language Models
Each question in HealthSearchQA is presented in a free-text format, devoid of predefined answer options, making it an open-domain setting. The dataset is curated to assess the clinical knowledge and question-answering capabilities of large language models in the context of consumer-oriented medical questions.
Med-PaLM: Results
SOTA vs. Med-PaLM
Med-PaLM consistently performs near or exceeds state-of-the-art (SOTA) models on all tasks within the MultiMedBench benchmark, showcasing its effectiveness in handling diverse biomedical data modalities.
In order to assess Med-PaLM’s performance, two baseline models were considered: (i) prior SOTA specialist models for each of the MultiMedBench tasks and (ii) a baseline generalist model without any biomedical domain finetuning. The findings show that across the three model sizes, Med-PaLM achieved its best performance on five out of twelve tasks, surpassing previous state-of-the-art (SOTA) results. For the remaining tasks, Med-PaLM remained highly competitive with the prior SOTA models.
Towards Generalist Biomedical AI
These results were achieved using a generalist model with the same set of model weights, without any task-specific architecture customization or optimization.
Ablations
Google researchers conducted ablation studies to investigate the impact of scale and task joint training on the performance and capabilities of Med-PaLM. The aim was to understand the significance of different factors in achieving superior results and potential for positive task transfer.
The first ablation study focused on assessing the importance of scale in generalist multimodal biomedical models. The findings revealed that larger models, with higher-level language capabilities, are particularly beneficial for tasks that require complex reasoning, such as medical (visual) question answering. This highlights the advantages of larger-scale models in handling diverse biomedical tasks effectively.
The second ablation study investigated the evidence of positive task transfer resulting from joint training a single generalist model to solve various biomedical tasks. To evaluate this, a Med-PaLM variant was trained without including the MIMIC-CXR classification tasks in the task mixture. This variant was then compared to the Med-PaLM variant trained on the complete MultiMedBench mixture in the chest X-ray report generation task. The results demonstrated that joint training across modalities and tasks leads to positive task transfer.
Human Evaluation Results
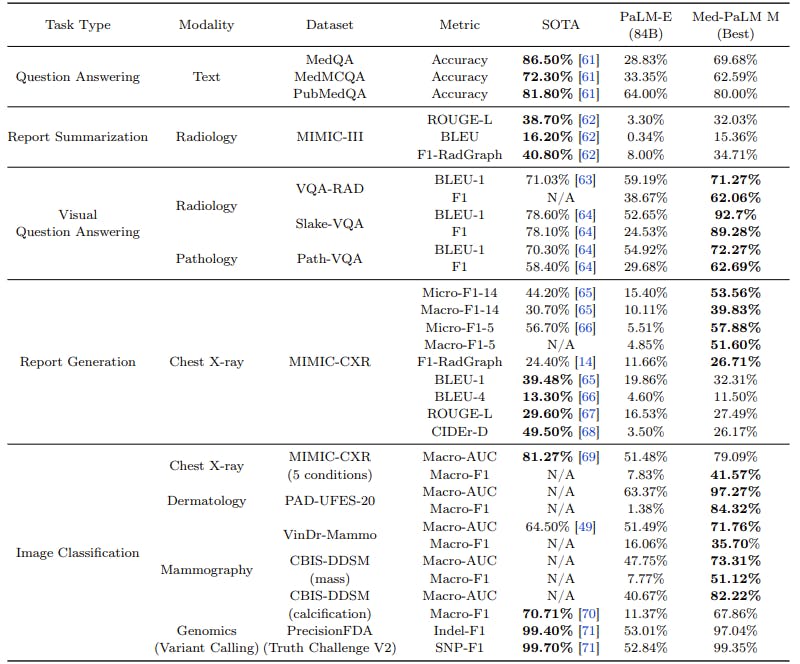
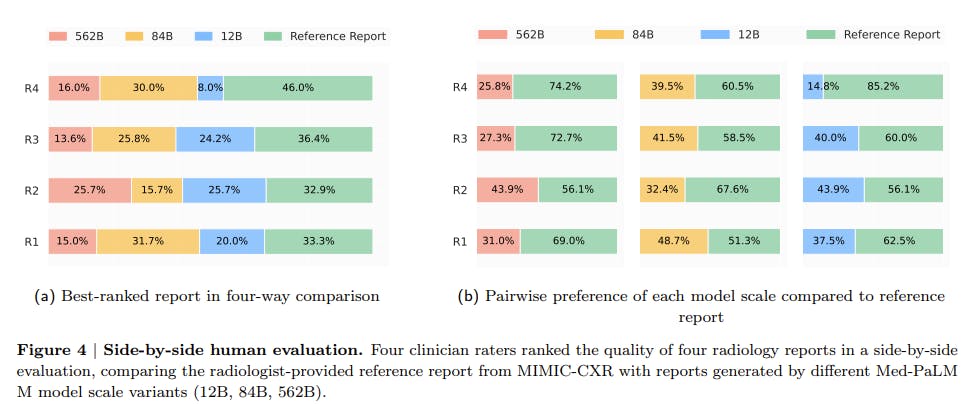
In addition to the automated metrics, the human evaluation of Med-PaLM’s radiology report generation results shows promising outcomes. For this assessment, radiologists blindly ranked 246 retrospective chest X-rays, comparing the reports generated by Med-PaLM across different model scales to those produced by their fellow clinicians.
Towards Generalist Biomedical AI
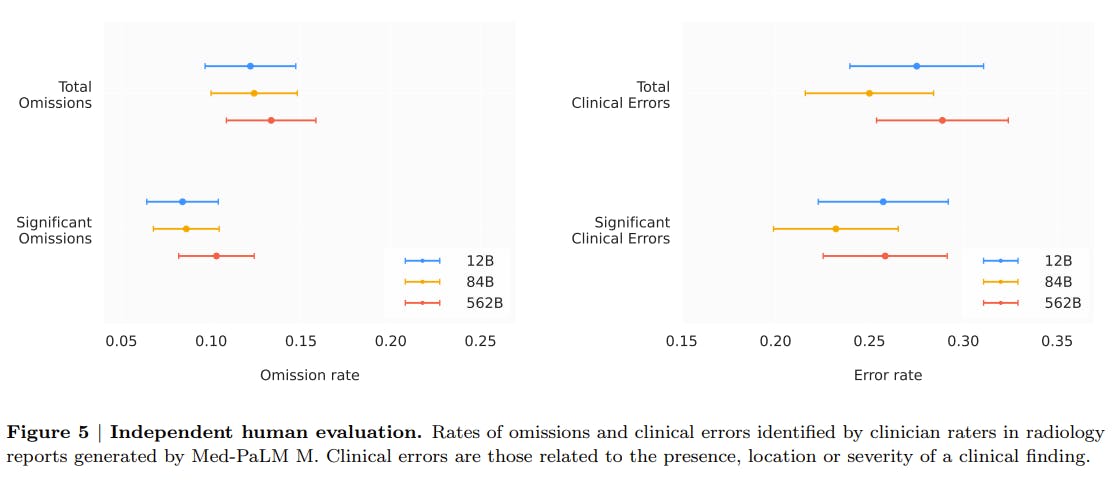
The results indicate that in up to 40% of cases, the radiologists expressed a preference for the Med-PaLM reports over the ones generated by their human counterparts. Moreover, the best-performing Med-PaLM model exhibited an average of only 0.25 clinically significant errors per report.
Towards Generalist Biomedical AI
These findings suggest that Med-PaLM’s reports are of high quality for clinical applications, showcasing its potential as a valuable tool for radiology report generation tasks across various model scales.
Possible Harm
To evaluate possible harm in medical question answering, Google researchers conducted a pairwise ranking analysis. Raters were presented with pairs of answers from different sources, such as physician-generated responses versus those from Med-PaLM-2, for a given question. The rates were then asked to assess the potential harm associated with each answer along two axes: the extent of possible harm and the likelihood of causing harm.

Towards Expert-Level Medical Question Answering with Large Language Models
The results above show that Med-PaLM 2's long-form answers demonstrate a remarkable level of safety, with a significant proportion of responses rated as having "No harm." This indicates that Med-PaLM 2 provides answers that were considered safe and low-risk according to the evaluation criteria.
This evaluation played a crucial role in assessing the safety and reliability of the answers provided by Med-PaLM 2 in comparison to those from human physicians. By considering the potential harm associated with different responses, the researchers gained valuable insights into the safety and risk factors of using AI-generated medical information for decision-making in real-world scenarios.
Bias for Medical Demographics
The evaluation of bias for medical demographics involved a pairwise ranking analysis to assess whether the answers provided by different sources exhibited potential bias towards specific demographic groups. Raters were presented with pairs of answers and asked to determine if any information in the responses was biased towards certain demographics.
For instance, raters assessed if an answer was applicable only to patients of a particular sex. They looked for any indications of favoring or excluding specific demographic groups, which could result in unequal or inadequate medical advice based on factors such as age, gender, ethnicity, or other demographic characteristics.
This evaluation was crucial in understanding if AI-generated medical information, like that from Med-PaLM 2, exhibited any demographic bias that could impact the quality and relevance of the answers provided to different patient populations. Identifying and addressing potential bias is essential to ensure fair and equitable healthcare delivery and to improve the overall reliability of AI-based medical question-answering systems.
Med-PaLM: Limitations
Med-PaLM has demonstrated its capabilities as a generalist biomedical AI system that can handle diverse medical modalities. It achieves close to or surpasses prior state-of-the-art (SOTA) results on various tasks, and generalizes to unseen biomedical concepts. However, there are some limitations and considerations to be acknowledged:
MultiMedQA
While MultiMedBench is a step towards addressing the need for unified benchmarks, it has certain limitations, including (i) the relatively small size of individual datasets (cumulative size of ~1 million samples) and (ii) limited modality and task diversity. The benchmark lacks certain life sciences data like transcriptomics and proteomics.
LLM Capabilities
Med-PaLM exhibits limitations in its language and multimodal capabilities. While it performs well on medical question answering tasks, there are challenges in measuring alignment with human answers.
The current rating rubric may not fully capture dimensions like empathy conveyed in responses. The comparison between model outputs and physician answers lacks specific clinical scenarios, leading to potential limitations in generalizability. The evaluation is also constrained by the single-answer approach by physicians and longer model-generated responses.
The evaluation with adversarial data for safety, bias, and equity considerations is limited in scope and requires expansion to encompass a wider range of health equity topics and sensitive characteristics. Ongoing research is necessary to address these limitations and ensure Med-PaLM's language and multimodal capabilities are robust and clinically applicable.
Fairness & Equity Considerations
Med-PaLM's limitations on fairness and equity considerations arise from the need for continued development in measuring alignment of model outputs. The current evaluation with adversarial data is limited in scope and should not be considered a comprehensive assessment of safety, bias, and equity. To address fairness concerns, future work should systematically expand adversarial data to cover a broader range of health equity topics and facilitate disaggregated evaluation over sensitive characteristics.
Moreover, Med-PaLM's performance on medical question answering tasks might not fully account for potential biases in the data or model predictions. Careful considerations are necessary to ensure that the model's outputs do not perpetuate bias or discrimination against certain demographic groups. This involves investigating the impact of model decisions on different populations and identifying potential sources of bias.
It is essential to approach fairness and equity considerations with a deeper understanding of the lived experiences, expectations, and assumptions of both the model's users and those generating and evaluating physician answers. Understanding the backgrounds and expertise of physicians providing answers and evaluating those answers can contribute to a more principled comparison of model outputs with human responses.
Ethical Considerations
Med-PaLM's ethical considerations include ensuring patient privacy and data protection, addressing potential biases and ensuring fairness in its outputs, ensuring safety and reliability for medical decision-making, providing interpretability for trust-building, conducting rigorous clinical validation, obtaining informed consent from patients, establishing transparent guidelines and accountability for its use in healthcare. Collaboration among AI researchers, medical professionals, ethicists, and policymakers is essential to address these concerns and ensure responsible and ethical deployment of Med-PaLM in medical settings.
AI in Healthcare
AI has emerged as a promising force in healthcare, transforming medical practices and improving patient outcomes. The applications span medical image analysis, disease diagnosis, drug discovery, personalized treatment plans, and more.
Here are some of the ways leading AI Medical teams have improved their workflows and pushed forward their growth:
King’s College London achieved a 6.4x average increase in labeling efficiency for GI videos, automating 97% of the labels and allowing their annotators to spend time on value-add tasks
Med-PaLM: Conclusion
Google’s Med-PaLM and Med-PaLM 2 represent groundbreaking advancements in AI for healthcare. These powerful generative AI language models demonstrate impressive capabilities in medical question-answering and handling diverse biomedical tasks.
The development of benchmarks like MultiMedBench and MultiMedQA fosters collaboration and transparency in biomedical AI research. However, challenges remain, including fairness, ethical considerations, and limitations in large language model (LLM) capabilities, which will only increase as these applications become more widespread.