Guide to Transfer Learning

Transfer learning has become an essential technique in the artificial intelligence (AI) domain due to the emergence of deep learning and the availability of large-scale datasets.
This comprehensive guide will discuss the fundamentals of transfer learning, explore its various types, and provide step-by-step instructions for implementing it. We’ll also address the challenges and practical applications of transfer learning.

What is Transfer Learning?
In machine learning, a model's knowledge resides in its trained weights and biases. These weights are generated after extensive training over a comprehensive training dataset and help understand data patterns for the targeted problem.
Transfer learning is a type of fine-tuning in which the weights of a pre-trained model for an upstream AI task are applied to another AI model to achieve optimal performance on a similar downstream task using a smaller task-specificdataset. In other words, it leverages knowledge gained from solving one task to improve the performance of a related but different task. Since the model already has some knowledge related to the new task, it can learn well from a smaller dataset using fewer training epochs.
Intuitive Examples Of Transfer Learning
Transfer learning has applications in numerous deep learning projects, such as computer vision tasks like object detection or natural language processing tasks like sentiment analysis. For example, an image classification model trained to recognize cats can be fine-tuned to classify dogs. Since both animals have similar features, the weights from the cat classifier can be fine-tuned to create a high-performing dog classifier.
Pre-trained Models
Rather than starting a new task from scratch, pre-trained models capture patterns and representations from the training data, providing a foundation that can be leveraged for various tasks. Usually, these models are deep neural networks trained on large datasets, such as the ImageNet dataset for image-related tasks or TriviaQA for natural language processing tasks. Through training, the model acquires a thorough understanding of features, feature representations, hierarchies, and relationships within the data.
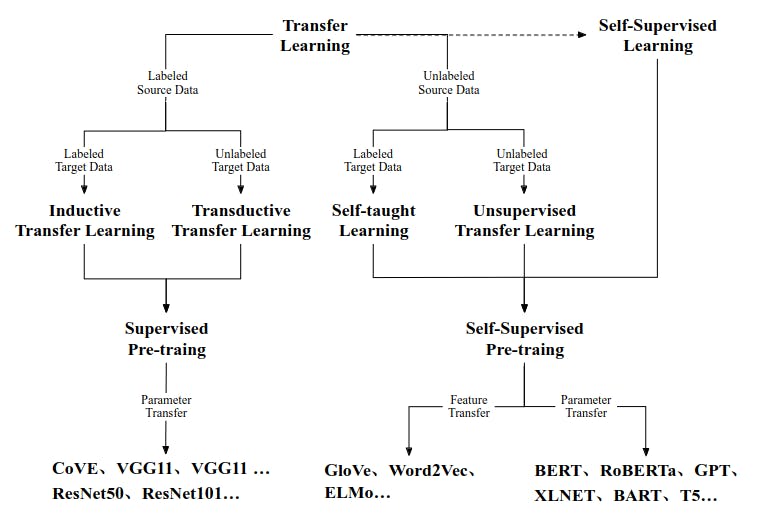
The Spectrum of Pre-training Methods
Several popular pre-trained architectures have epitomized the essence of transfer learning across domains. These include:
- VGG (Visual Geometry Group), a convolutional neural network architecture widely recognized for its straightforward design and remarkable effectiveness in image classification. Its architecture is defined by stacking layers with small filters, consistently preserving the spatial dimensions of the input. VGG is a starting point for more advanced models like VGG16 and VGG19.
- ResNet (Residual Network), a convolutional neural network architecture that addresses the vanishing gradient problem using skip connections, enabling the training of very deep networks. It excels in image classification and object detection tasks.
- BERT (Bidirectional Encoder Representations from Transformers), a pre-trained NLP model that has the ability to understand the context from both directions in a text sequence. Its proficiency in contextual understanding is used in various language-related tasks, such as text classification, sentiment analysis, and more.
- InceptionV3, a deep learning model based on the CNN architecture. It is widely used for image classification and computer vision tasks. It is a variant of the original GoogLeNet architecture known for its "inception" modules that allow it to capture information at multiple scales and levels of abstraction. Using prior knowledge of images during pre-training, InceptionV3's features can be adapted to perform well on narrower, more specialized tasks.
Transferable Knowledge
In transfer learning, transferable knowledge serves as the foundation that enables a model's expertise in one area to enhance its performance in another. Throughout the training process, a model accumulates insights that are either domain-specific or generic.
Domain-specific knowledge are relevant to a particular field, like medical imaging. Conversely, generic knowledge tackles more universal patterns that apply across domains, such as recognizing shapes or sentiments.
Transferable knowledge can be categorized into two types: low-level features and high-level semantics. Low-level features encompass basic patterns like edges or textures, which are useful across many tasks. High-level semantics, on the other hand, delve into the meaning behind patterns and relationships, making them valuable for tasks requiring context-understanding.
Task Similarity & Domains
Understanding task similarity is critical to choosing an effective transfer learning approach – fine-tuning or feature extraction – and whether to transfer knowledge within the same domain or bridge gaps across diverse domains.
- Fine-tuning vs. Feature Extraction: When reusing pre-trained models, there are two main strategies to enhance model performance: fine-tuning and feature extraction. Fine-tuning involves adjusting the pre-trained model's parameters and activations while retraining its learned features. For specific fine-tuning tasks, a dense layer is added to the pre-trained layers to customize the model's outputs and minimize the loss on the new task, aligning them with the specific outcomes needed for the target task.
- On the other hand, feature extraction involves extracting the embeddings from the final layer or multiple layers of a pre-trained model. The extracted features are fed into a new model designed for the specific task to achieve better results. Usually, feature extraction does not modify the original network structure. It simply computes features from the training data that are leveraged for downstream tasks.
- Same-domain vs. Cross-domain Transfer: Transfer learning can work within the same domain or across different domains. In same-domain transfer, the source and target tasks are closely related, like recognizing different car models within the automotive domain. Cross-domain transfer involves applying knowledge from a source domain to an unrelated target domain, such as using image recognition expertise from art to enhance medical image analysis.
Types of Transfer Learning
Transfer learning can be categorized into different types based on the context in which knowledge is transferred. These types offer insights into how models reuse their learned features to excel in new situations.
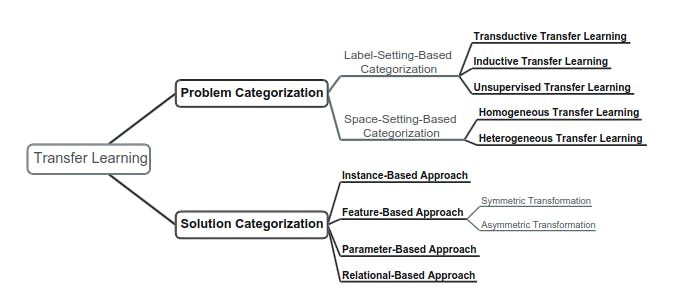
Categorizations of Transfer Learning
Let’s discuss two common types of transfer learning.
Inductive Transfer Learning
Inductive transfer learning is a technique used when labeled data is consistent across the source and target domains, but the tasks undertaken by the models are distinct. It involves transferring knowledge across tasks or domains. When transferring across tasks, a model's understanding from one task aids in solving a different yet related task. For instance, using a model trained on image classification improves object detection performance. Transferring across domains extends this concept to different datasets. For instance, a model initially trained on photos of animals can be fine-tuned for medical image analysis.
Transductive Transfer Learning
In transductive learning, the model has encountered training and testing data beforehand. Learning from the familiar training dataset, transductive learning makes predictions on the testing dataset. While the labels for the testing dataset might be unknown, the model uses its learned patterns to navigate the prediction process.
Transductive transfer learning is applied to scenarios where the domains of the source and target tasks share a strong resemblance but are not precisely the same. Consider a model trained to classify different types of flowers from labeled images (source domain). The target task is identifying flowers in artistic paintings without labels (target domain). Here, the model's learned flower recognition abilities from labeled images are used to predict the types of flowers depicted in the paintings.
How to Implement Transfer Learning
Transfer learning is a nuanced process that requires deliberate planning, strategic choices, and meticulous adjustments. By piecing together the appropriate strategy and components, practitioners can effectively harness the power of transfer learning. Given a pre-trained model, here are detailed steps for transfer learning implementation.
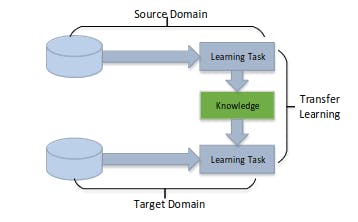
Learning Process of Transfer Learning
Dataset Preparation
In transfer learning, dataset preparation includes data collection and preprocessing for the target domain. Practitioners acquire labeled data for the target domain. Even though the tasks may differ, the fine-tuning training data should have similar characteristics to the source domain. During data preprocessing, employing techniques like data augmentation can significantly enhance the model's performance.
Model Selection & Architecture
The process of model selection and architecture design sets the foundation for successful transfer learning. It involves choosing a suitable pre-trained model and intricately adjusting it to align with the downstream task. Deep learning models like VGG, ResNet, and BERT offer a solid foundation to build upon. Freeze the top layers of the chosen pre-trained model to build a base model for the downstream task that captures the general features of the source domain. Then, add layers to the base model to learn task-specific features.
Transfer Strategy
Transfer learning requires finding the right path to adapt a model's knowledge. Here are three distinct strategies to consider, tailored to different scenarios and data availability.
- Full Fine-tuning: This approach uses the target data to conduct fine-tuning across the entire model. It's effective when a considerable amount of labeled training data is available for the target task.
- Layer-wise Fine-tuning: It involves fine-tuning specific layers to adapt the pre-trained model's expertise. This strategy is appropriate when target data is limited.
- Feature Extraction: It involves holding the pre-trained layers constant and extracting their learned features. New model is trained based on the learned features for the downstream task. This method works well when the target dataset is small. The new model capitalizes on the pre-trained layers' general knowledge.
Hyperparameter Tuning
Hyperparameter tuning fine-tunes model's performance. These adjustable settings are pivotal in how the model learns and generalizes from data. Here are the key hyperparameters to focus on during transfer learning:
- Learning Rate: Tune the learning rate for the fine-tuning stage to determine how quickly the model updates its weights by learning from the downstream training data.
- Batch Size: Adjust the batch size to balance fast convergence and memory efficiency. Experiment to find the sweet spot.
- Regularization Techniques: Apply regularization methods like dropout or weight decay to prevent overfitting and improve model generalization.
Training & Evaluation
Train and compile the downstream model and modify the output layer according to the chosen transfer strategy on the target data. Keep a watchful eye on loss and accuracy as the model learns. Select evaluation metrics that align with the downstream task's objectives. For instance, model accuracy is the usual go-to metric for classification tasks, while the F1 score is preferred for imbalanced datasets. Ensure the model's capabilities are validated on a validation set, providing a fair assessment of its readiness for real-world challenges.
Practical Applications of Transfer Learning
Transfer learning offers practical applications in many industries, fueling innovation across AI tasks. Let's delve into some real-world applications where transfer learning has made a tangible difference:
Autonomous Vehicles
The autonomous vehicles industry benefits immensely from transfer learning. Models trained to recognize objects, pedestrians, and road signs from vast datasets can be fine-tuned to suit specific driving environments.
For instance, a model originally developed for urban settings can be adapted to navigate rural roads with minimal data. Waymo, a prominent player in autonomous vehicles, uses transfer learning to enhance its vehicle's perception capabilities across various conditions.
Healthcare Diagnostics
AI applications in the healthcare domain use transfer learning to streamline medical processes and enhance patient care. One notable use is interpreting medical images such as X-rays, MRIs, and CT scans. Pre-trained models can be fine-tuned to detect anomalies or specific conditions, expediting diagnoses swiftly.
By leveraging knowledge from existing patient data, models can forecast disease progression and tailor treatment plans. This proves especially valuable in personalized medicine. Moreover, transfer learning aids in extracting insights from vast medical texts, helping researchers stay updated with the latest findings and enabling faster discoveries.
The importance of transfer learning is evident in a recent study regarding its use in COVID-19 detection from chest X-ray images. The experiment proposed using a pre-trained network (ResNet50) to identify COVID-19 cases. By repurposing the network's expertise, the model provided swift COVID diagnosis with 96% performance accuracy, demonstrating how transfer learning algorithms accelerate medical advancements.
Gaming
In game development, pre-trained models can be repurposed to generate characters, landscapes, or animations. Reinforcement learning models can use transfer learning capabilities to initialize agents with pre-trained policies, accelerating the learning process. For example, OpenAI's Dota 2 bot, OpenAI Five, blends reinforcement and transfer learning to master complex real-time gaming scenarios.
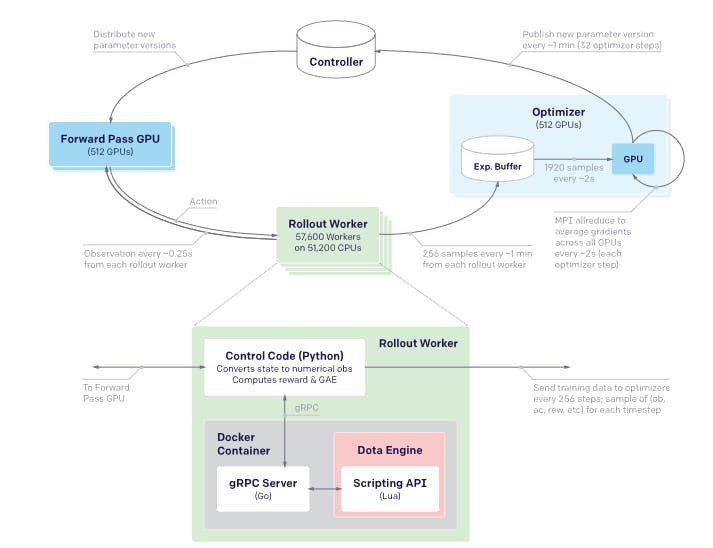
System Overview of Dota 2 with Large-Scale Deep Reinforcement Learning
E-commerce
In e-commerce, recommendations based on user behavior and preferences can be optimized using transfer learning from similar user interactions. Models trained on extensive purchasing patterns can be fine-tuned to adapt to specific user segments.
Moreover, NLP techniques like Word2Vec's pre-trained word embeddings enable e-commerce platforms to transfer knowledge from large text corpora effectively. This enhances their understanding of customer feedback and enables them to tailor strategies that enhance the shopping experience. Amazon, for instance, tailors product recommendations to individual customers through the transfer learning technique.
Cross-lingual Translations
The availability of extensive training data predominantly biased toward the English language creates a disparity in translation capabilities across languages. Transfer learning bridges this gap and enables effective cross-lingual translations.
Large-scale pre-trained language models can be fine-tuned to other languages with limited training data. Transfer learning mitigates the need for vast language-specific datasets by transferring language characteristics from English language datasets.
For example, Google's Multilingual Neural Machine Translation system, Google Translate, leverages transfer learning to provide cross-lingual translations. This system employs a shared encoder for multiple languages, utilizing pre-trained models on extensive English language datasets.
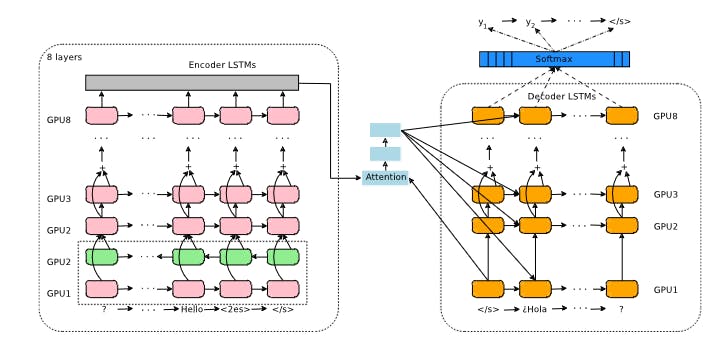
Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation
Limitations of Transfer Learning
While transfer learning enables knowledge sharing, it's essential to acknowledge its limitations. These challenges offer deeper insights to data scientists about areas that demand further attention and innovation. Here are several areas where transfer learning shows limitations:
Dataset Bias & Mismatch
Transfer learning's effectiveness hinges on the similarity between the source and target domains. If the source data doesn't adequately represent the target domain, models might struggle to adapt accurately. This dataset mismatch can lead to degraded performance, as the model inherits biases or assumptions from the source domain that do not apply to the target domain.
Overfitting & Generalization
Despite its prowess, transfer learning is not immune to overfitting. When transferring knowledge from a vastly different domain, models might over-adapt to the nuances of the source data, resulting in poor generalization to the target task. Striking the right balance using learned features and not overemphasizing source domain characteristics is a persistent challenge.
Catastrophic Forgetting
Models mastering a new task may inadvertently lose proficiency in the original task. This phenomenon, known as catastrophic forgetting, occurs when sequential retraining for a new task overrides previously acquired knowledge. The new data changes the knowledge-heavy, pre-trained weights of the model, causing the model to lose prior knowledge. Balancing the preservation of existing expertise while acquiring new skills is crucial, particularly in continual learning scenarios.
Ethical & Privacy Concerns
The emergence of transfer learning has raised ethical questions regarding the origin and fairness of the source data. Fine-tuned models inheriting biases or sensitive information from source domains might perpetuate inequalities or breach privacy boundaries. Ensuring models are ethically trained and the transfer process adheres to privacy norms is an ongoing challenge.
Advanced Topics in Transfer Learning
As transfer learning advances, it ventures into uncharted territories with various advanced techniques that redefine its capabilities. These innovative methods revolutionize the process of transferring knowledge across domains, enriching model performance and adaptability. Here's a glimpse into some of the advanced topics in transfer learning:
Domain Adaptation Techniques
Domain adaptation is a critical aspect of transfer learning that addresses the challenge of applying models trained on one domain to perform well in another related domain. Here are two domain adaptation techniques:
- Self-training: Self-training iteratively labels unlabeled target domain data using the model's predictions. For example, training a sentiment analysis model using labeled data for positive and negative sentiment but unlabeled data for neutral sentiment. The model starts by making predictions on the neutral data and then uses them as "pseudo-labels" to fine-tune itself on the neutral sentiment, gradually improving its performance in this class.
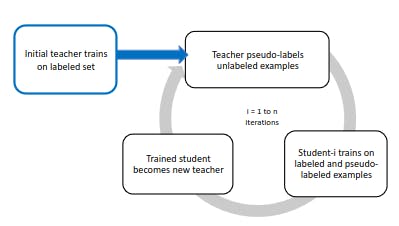
Basic Iterative Self-training Pipeline
- Adversarial Training: Adversarial training pits two models against each other – one adapts to the target domain, while the other attempts to distinguish between source and target data. This sharpens the model's skills in adapting to new domains. Adversarial training also plays a crucial role in strengthening models against adversarial attacks. Exposing the model to these adversarial inputs during training teaches them to recognize and resist such attacks in real-world scenarios.
Zero-shot & Few-shot Learning
Zero-shot learning involves training a model to recognize classes it has never seen during training, making predictions with no direct examples of those classes. Conversely, few-shot learning empowers a model to generalize from a few examples per class, allowing it to learn and make accurate predictions with minimal training data.
Other learning strategies include one-shot learning and meta-learning. With one example per class, one-shot learning replicates the human ability to learn from a single instance. For example, training a model to identify rare plant species using just one image of each species. On the other hand, meta-learning involves training the model on a range of tasks, facilitating its swift transition to novel tasks with minimal data. Consider a model trained on various tasks, such as classifying animals, objects, and text sentiments. When given a new task, like identifying different types of trees, the model adapts swiftly due to its exposure to diverse tasks during meta-training.
Multi-modal Transfer Learning
Multi-modal transfer learning involves training models to process and understand information from different modalities, such as text, images, audio, and more. These techniques elevate models to become versatile communicators across different sensory domains.
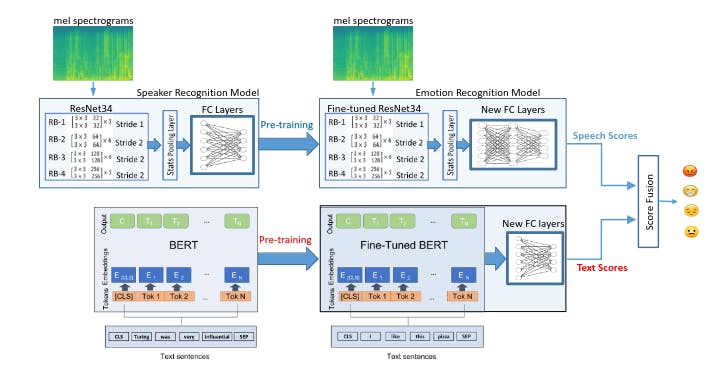
Two prominent types of multi-modal transfer learning are:
- Image-Text Transfer: This type of transfer learning uses text and visual information to generate outcomes. It is most appropriate for image captioning tasks.
- Audio-Visual Transfer: Audio-visual transfer learning enables tasks like recognizing objects through sound. This multi-sensory approach enriches the model's understanding and proficiency in decoding complex audio information.
Future Trends in Transfer Learning
The transfer learning landscape is transformative, with trends set to redefine how models adapt and specialize across various domains. These new directions offer a glimpse into the exciting future of knowledge transfer.
Continual Learning & Lifelong Adaptation
The future of transfer learning lies in models that continuously evolve to tackle new challenges. Continual learning involves training models on tasks over time, allowing them to retain knowledge and adapt to new tasks without forgetting what they've learned before. This lifelong adaptation reflects how humans learn and specialize over their lifetimes. As models become more sophisticated, the ability to learn from a constant stream of tasks promises to make them even more intelligent and versatile.
Federated Transfer Learning
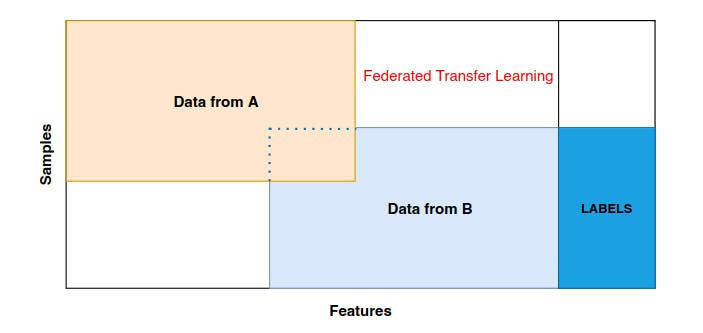
Imagine a decentralized network of models collaborating to enhance each other's knowledge. Federated transfer learning envisions models distributed across different devices and locations, collectively learning from their local data while sharing global knowledge.
This approach respects privacy, as sensitive data remains local while still benefiting from the network's collective intelligence. Federated learning's synergy with transfer learning can democratize AI by enabling models to improve without centralizing data.
Improved Pre-training Strategies
Pre-training, a key element of transfer learning, is expected to become even more effective and efficient. Models will likely become adept at learning from fewer examples and faster convergence. Innovations in unsupervised pre-training can unlock latent patterns in data, leading to better transfer performance.
Techniques like self-supervised learning, where models learn from the data without human-labeled annotations, can further refine pre-training strategies, enabling models to grasp complex features from raw data.
Ethical & Fair Transfer Learning
The ethical dimension of transfer learning gains importance as models become more integral to decision-making. Future trends will focus on developing fair and unbiased transfer learning methods, ensuring that models don't perpetuate biases in the source data. Techniques that enable models to adapt while preserving fairness and avoiding discrimination will be crucial in building AI systems that are ethical, transparent, and accountable.
Transfer Learning: Key Takeaways
- Transfer learning is a dynamic ML technique that leverages pre-trained models to develop new models, saving time and resources while boosting performance.
- Transfer learning has proven its versatility, from its role in accelerating model training, enhancing performance, and reducing data requirements to its practical applications across industries like healthcare, gaming, and language translation.
- In transfer learning, it is vital to carefully select pre-trained models, understand the nuances of different transfer strategies, and navigate the limitations and ethical considerations of this approach.
- Techniques like domain adaptation, zero-shot learning, meta-learning, and multi-modal transfer learning offer more depth in the transfer learning domain.
- The future of transfer learning promises advanced federated techniques, continual learning, fair adaptation, and improved pre-training strategies.

Frequently asked questions
An example of transfer learning is using a pre-trained image classification model, such as ResNet, and fine-tuning it on the MNIST dataset for number detection.
You should consider using transfer learning when you have limited data, your source and target tasks share similarities, resources are limited, or you need to adapt models quickly.
Transfer learning uses knowledge from a source task to improve performance on a target task. It leverages pre-trained models to transfer learned features and representations. Contrarily, supervised learning involves training a model from scratch on labeled data for a specific task. It does not rely on pre-existing knowledge from other tasks.
Machine learning is a broader concept encompassing various techniques for training models to learn patterns from data. Transfer learning, on the other hand, is a specific approach within machine learning where knowledge gained from one task is applied to improve performance on a different but related task.
Fine-tuning is the process of adjusting a pre-trained model's parameters for a specific task. It optimizes the model's performance using a smaller dataset. Transfer learning, on the other hand, involves using knowledge from a source task to improve results on a target task. While fine-tuning is a step within transfer learning, transfer learning encompasses broader strategies beyond fine-tuning to leverage existing knowledge for improved performance.
Transfer learning may not work well when the source and target domains are too dissimilar or when there is insufficient relevant data available for adaptation.
Transfer learning works by initializing a model with knowledge from a related task and then adapting it to a target task using techniques such as fine-tuning or feature extraction.
Pre-trained vision models for image classification can be found on various platforms like TensorFlow Hub, Keras, PyTorch Hub, Hugging Face, and more.
Active learning is the process of selecting the most impactful samples from a dataset to label. These samples are information-rich and provide the model with the most performance. Transfer learning takes pre-trained weights and fine-tunes them over unseen data. This process helps the new model gain amazing performance with very little training.
Transfer learning involves three main components: a) source task on which a model is pre-trained using a large dataset. It captures general features and knowledge. b) Transfer strategy to adapt the pre-trained model to a target task. This can involve fine-tuning specific layers, adding task-specific layers, or using the model as a feature extractor. c) Target task for which the pre-trained model is adjusted. It typically has a smaller dataset and specific requirements compared to the source task.