A Guide to Machine Learning Model Observability

Artificial intelligence (AI) is solving some of society's most critical issues. But, lack of transparency and visibility in building models make AI a black box. Users cannot understand what goes on behind the scenes when AI answers a question, gives a prediction, or makes a critical decision.
What happens when large language models (LLMs), like GPT-4 and LLaMA, make errors, but users fail to realize the mistake? Or how badly is the model’s credibility affected when users identify errors in the model outcome?
Customers lose trust, and the company behind the model can face serious legal and financial consequences. Remember how a minor factual error in Bard’s demo reportedly cost Google $100 billion in market value?
That’s where model observability comes into play. It helps understand how a model reaches an outcome using different techniques. In this article, you will:
- Understand model observability and the importance
- Challenges related to model observability
- How model observability applies to modern AI domains, like computer vision and natural language processing (NLP)
What is Model Observability?
Model observability is a practice to validate and monitor machine learning (ML) model performance and behavior by measuring critical metrics, indicators, and processes to ensure that the model works as expected in production.
It involves end-to-end event logging and tracing to track and diagnose issues quickly during training, inference, and decision-making cycles. It lets you monitor and validate training data to check if it meets the required quality standards. It also assists in model profiling, detecting bias and anomalies that could affect the ML model's performance
Through observability, ML engineers can conduct root-cause analysis to understand the reason behind a particular issue. This practice allows for continuous performance improvement using a streamlined ML workflow that enables scalability and reduces time to resolution.
A significant component of observability is model explainability, which operates under explainable AI or XAI. XAI facilitates root-cause analysis by enabling you to investigate a model’s decision-making process. XAI optimizes model development, debugging, and testing cycles using tools and frameworks.
ML model observability is often used interchangeably with ML monitoring. However, an emphasis on model explainability and a focus on why a specific issue occurred makes ML observability broader than ML monitoring. While model monitoring only tells you where and what the problem is, observability goes further by helping you understand the primary reason behind a particular situation.
Significance of Model Observability
ML models in production can encounter several issues that can cause performance degradation and result in poor user experience. These issues can go unnoticed if model observability practices are not followed.
With a robust model observability pipeline, data scientists can prevent such problems and speed up the development lifecycle.
Below are a few factors that can go wrong during production and warrant the need for model observability.
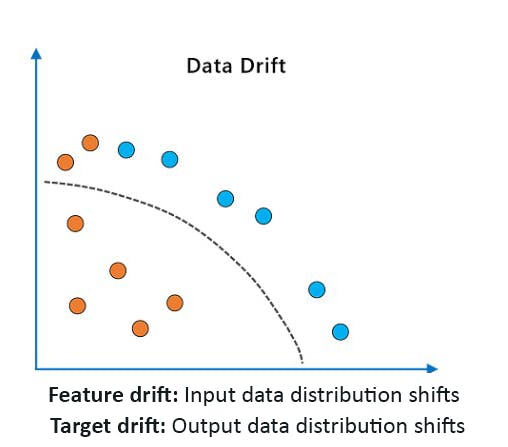
Data Drift
Data drift occurs when the statistical properties of a machine learning model’s training data change. It can be a covariate shift where input feature distributions change or a model drift where the relationship between the input and target variables becomes invalid. The divergence between the real-world and training data distribution can occur for multiple reasons, such as changes in underlying customer behavior, changes in the external environment, demographic shifts, product upgrades, etc.
Performance Degradation
As the machine learning application attracts more users, model performance can deteriorate over time due to model overfitting, outliers, adversarial attacks, and changing data patterns.
Data Quality
Ensuring consistent data quality during production is challenging as it relies heavily on data collection methods, pipelines, storage platforms, pre-processing techniques, etc. Problems such as missing data, labeling errors, disparate data sources, privacy restraints, inconsistent formatting, and lack of representativeness can severely damage data quality and cause significant prediction errors.
Let’s discuss how model observability helps.
Faster Detection and Resolution of Issues
Model observability solutions track various data and performance metrics in real-time to quickly notify teams if particular metrics breach thresholds and enhance model interpretability to fix the root cause of the problem.
Regulatory Compliance
Since observability tools maintain logs of model behavior, datasets, performance, predictions, etc., they help with compliance audits and ensure that the model development process aligns with regulatory guidelines. Moreover, they help detect bias by making the model decision-making process transparent through XAI.
Fostering Customer Trust
Model observability enables you to build unbiased models with consistent behavior and reduces major model failures. Customers begin to trust applications based on these models and become more willing to provide honest feedback, allowing for further optimization opportunities.
Now, let’s discuss how model observability improves the ML pipeline for different domains.
Model Observability in Large Language Models (LLMs) and Computer Vision (CV)
Standard machine learning observability involves model validation, monitoring, root-cause analysis, and improvement. During validation, an observability platform evaluates model performance on unseen test datasets and assesses whether a model suffers from bias or variance. It helps you detect issues during production through automated metrics. Finally, insights from the root-cause analysis help you improve the model and prevent similar problems from occurring again.
While the flow above applies to all ML models, monitoring and evaluation methods can differ according to model complexity.
For instance, LLMs and CV models process unstructured data and have complex inference procedures. So, model observability requires advanced explainability, evaluation, and monitoring techniques to ensure that the models perform as expected.
Let’s discuss the main challenges of such models and understand the critical components required to make model observability effective in these domains.
Model Observability in Large Language Models
LLMs can suffer from unique issues, as discussed below.
- Hallucinations: Occurs when LLMs generate non-sensical or inaccurate responses to user prompts.
- No single ground truth: A significant challenge in evaluating an LLM's response is the absence of a single ground truth. LLMs can generate multiple plausible answers, and assessing which is accurate is problematic.
- Response quality: While responses may be factually accurate, they may not be relevant to a user’s prompt. Also, the language may be ambiguous with an inappropriate tone. The challenge here is to monitor response and prompt quality together, as a poorly crafted prompt will generate sub-optimal responses.
- Jailbreaks: Specific prompts can cause LLMs to disregard security protocols and generate harmful, biased, and offensive responses.
- Cost of retraining: Retraining LLMs is necessary to ensure that they generate relevant responses using the latest information. However, retraining is costly. It demands a robust infrastructure involving advanced hardware, personnel expenses, data management costs, etc.
You can mitigate the above challenges using a tailored model observability strategy that will allow for better evaluation techniques. Below are common techniques to evaluate LLMs.
- User feedback: Users can quickly identify and report problems, such as bias, misinformation, and unethical LLM responses to specific prompts. Collecting and assessing user feedback can help improve response quality.
- Embedding visualization: Comparing the model response and input prompt embeddings in a semantic space can reveal how close the responses to particular prompts are. The method can help evaluate response relevance and accuracy.
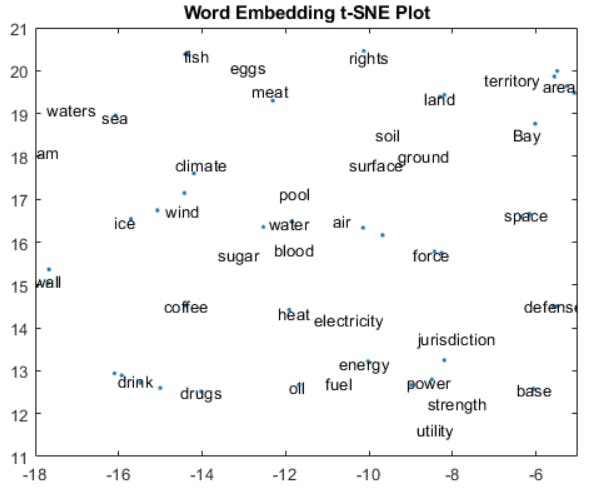
A Word Embedding Plot Showcasing Relevance of Similar Words
- Prompt engineering: You can enhance LLM performance by investigating how it responds to several prompt types. It can also help reveal jailbreaking prompts early in the development process.
- Retrieval systems: A retrieval system can help you assess whether an LLM fetches the correct information from relevant sources. You can experiment by feeding different data sources into the model and trying various user queries to see if the LLM retrieves relevant content.
- Fine-tuning: Instead of re-training the entire LLM from scratch, you can fine-tune the model on domain-specific input data.
Model Observability in Computer Vision
Similar to LLMs, CV models have specific issues that require adapting model observability techniques for effectiveness. Below are a few problems with CV modeling.
- Image drift: Image data drift occurs when image properties change over time. For instance, certain images may have poor lighting, different background environments, different camera angles, etc.
- Occlusion: Occlusion happens when another object blocks or hides an image's primary object of interest. It causes object detection models to classify objects wrongly and reduces model performance.

- Lack of annotated samples: CV models often require labeled images for training. However, finding sufficient domain-specific images with correct labels is challenging. Labeling platforms like Encord can help you mitigate these issues.
- Sensitive use cases: CV models usually operate in safety-critical applications like medical diagnosis and self-driving cars. Minor errors can lead to disastrous consequences.
As such, model observability in CV must have the following components to address the problems mentioned above.
- Monitoring metrics: Use appropriate metrics to measure image quality and model performance.
- Specialized workforce: Domain experts must be a part of the model observability pipeline to help annotators with the image labeling process.
- Quality of edge devices: Image data collection through edge devices, such as remote cameras, drones, sensors, etc., requires real-time monitoring methods to track a device’s health, bandwidth, latency, etc.
- Label quality: Ensuring high label quality is essential for effective model training. Automation in the labeling process with a regular review system can help achieve quality standards. Smart labeling techniques, such as active, zero-shot, and few-shot learning, should be part of the observability framework to mitigate annotation challenges.
- Domain adaptation: CV observability should help indicate when fine-tuning a CV model is suitable by measuring the divergence between source and target data distribution. It should also help inform the appropriate adaptation technique.
Now, let’s explore the two crucial aspects of model observability: monitoring and explainability. We’ll discuss various techniques that you can employ in your ML pipelines.
Model Monitoring Techniques
The following model metrics are commonly used for evaluating the performance of standard ML systems, LLMs, and CV models.
- Standard ML monitoring metrics: Precision, recall, F1 score, AUC ROC, and Mean Absolute Error (MAE) are common techniques for assessing model performance by evaluating true positives and negatives against false positives and negatives.
- LLM monitoring metrics: Automated scores like BLEU, ROUGE, METEOR, and CiDER help measure the model response quality by matching n-grams in candidate and target texts. Moreover, human-level monitoring is preferable in generative AI domains due to the absence of a single ground truth. User feedback, custom metrics, and manually evaluating response relevance are a few ways to conduct human-based assessments. You can also implement reinforcement learning with human feedback (RLHF) to ensure LLM output aligns with human preferences.
- CV monitoring metrics: Metrics for monitoring CV models include mean average precision (mAP), intersection-over-union (IoU), panoptic quality (PQ), etc., for various tasks, such as object detection, image classification, and segmentation.
Model Explainability Techniques
The primary difference between ML observability and monitoring is that the former encompasses a variety of explainability techniques (XAI) to help you understand the fundamental reason behind an anomaly or error.
XAI techniques can be classified into three levels of explainability:
- Global,
- Cohort,
- Local.
Global explainability tells you which feature has the most significant contribution across all predictions on average. Global explainability helps people without a data science domain to interpret the model reasoning process.
For instance, the diagram below shows a model for predicting credit limits for individuals relies heavily on age. This behavior can be problematic since the model will always predict a lower credit limit for younger individuals, despite their ability to pay more.
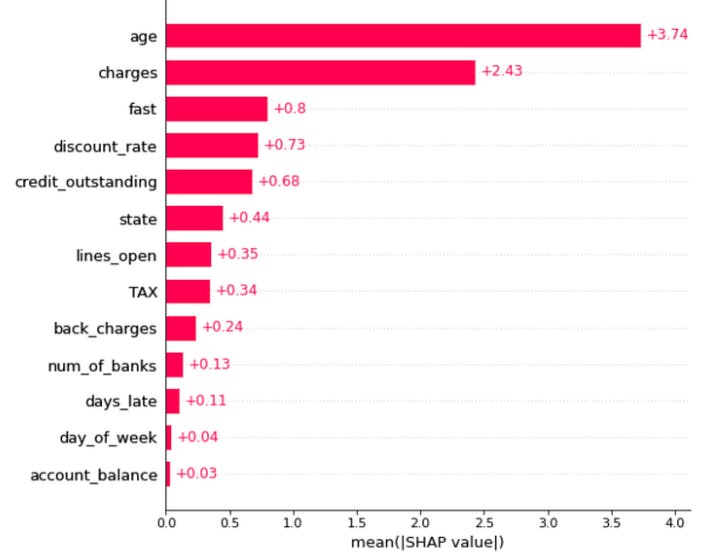
Global Explainability for a Model’s Features
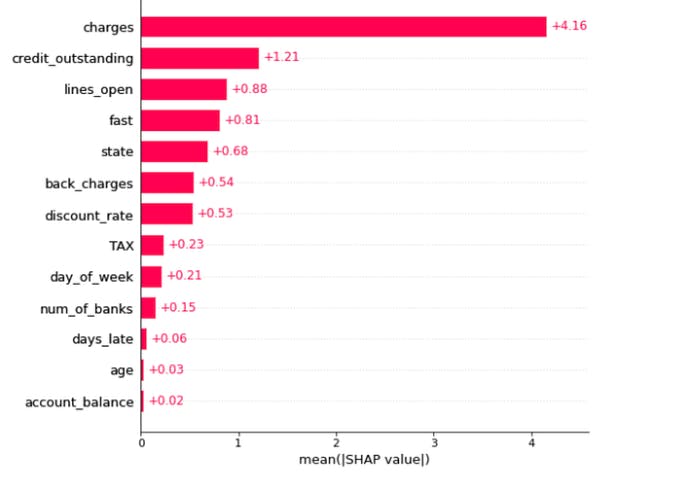
Similarly, cohort explainability techniques reveal which features are essential for predicting outputs on a validation or test dataset. A model may assign importance to one feature in the training phase but use another during validation. You can use cohort explainability to identify these differences and understand model behavior more deeply. The illustration below suggests the model uses “charges” as the primary feature for predicting credit limits for people under 30.
Finally, local explainability methods allow you to see which feature the model used for making a particular prediction in a specific context during production. For instance, the credit limit model may predict a lower credit limit for someone over 50. Analyzing this case may reveal that the model used account balance as the primary predictor instead of age. Such a level of detail can help diagnose an issue more efficiently and indicate the necessary improvements.
Explainability Techniques in Standard ML Systems
Let’s briefly discuss the two techniques you can use to interpret a model’s decision-making process.
- SHAP: Shapley Additive Explanations (SHAP) computes the Shapley value of each feature, indicating feature importance for global and local explainability.
- LIME: Local Interpretable Model-Agnostic Explanations (LIME) perturbs input data to generate fake predictions. It then trains a simpler model on the generated values to measure feature importance.
Explainability Techniques in LLMs
LLM explainability is challenging since the models have complex deep-learning architectures with many parameters. However, the explainability techniques mentioned below can be helpful.
- Attention-based techniques: Modern LLMs, such as ChatGPT, BERT, T5, etc., use the transformer architecture, which relies on the attention mechanism to perform NLP tasks. The attention-based explainability technique considers multiple words and relates them to their context for predictions. With attention visualization, you can see which words in an input sequence the model considered the most for predictions.
- Saliency-based techniques: Saliency methods consist of computing output gradients with respect to input features for measuring importance. The intuition is that features with high gradient values are essential for predictions. Similarly, you can erase or mask a particular input feature and analyze output variation. High variations mean that the feature is important.
Explainability Techniques in CV
While saliency-based methods are applicable for explaining CV model predictions, other methods specific to CV tasks can do a better job, such as:
Integrated gradients
The idea behind integrated gradients (IG) is to build a baseline image that contains no relevant information about an object. For instance, a baseline image can only have random noise. You can gradually add features, or pixels to the image and compute gradients at each stage. Adding up the gradients for each feature along the path will reveal the most important features for predicting the object within the image.
![]()
IG Showing Which Pixels Are Important For Predicting the Image of a Cockatoo
XRAI
XRAIenhances the IG approach by highlighting pixel regions instead of single pixels by segmenting similar image patches and then computing the saliency of each region through gradients.

XRAI Showing the Important Regions for Prediction
Grad-CAM
Gradient-weighted Class Activation Mapping (Grad-CAM) generates a heatmap for models based on Convolutional Neural Nets (CNNs). The heatmap highlights the regions of importance by overlaying it on the original image.

Model Observability with Encord Active
Encord Active is an evaluation platform for computer vision models. It helps you understand and improve your data, labels, and models at all stages of your computer vision journey. Here are some observability workflows you can use Encord Active to execute:
Understanding Model Failure Using Detailed Explainability Reports
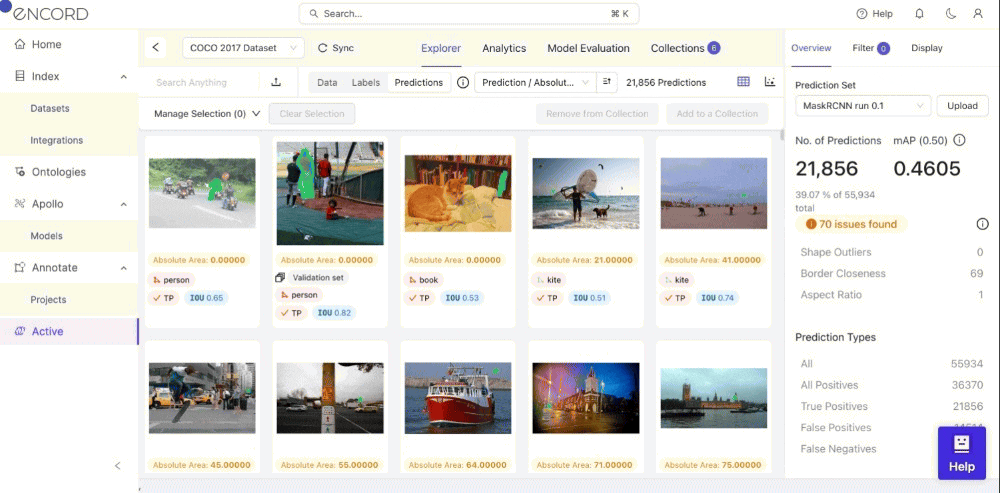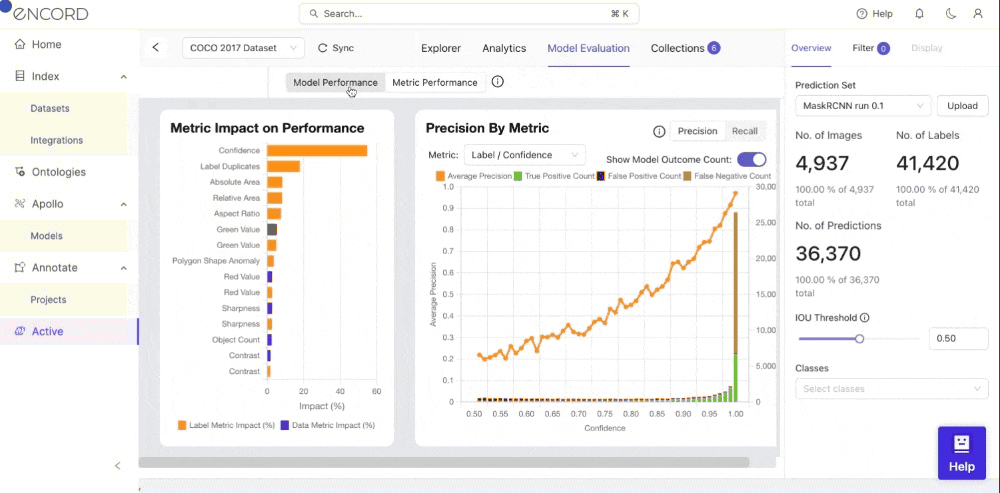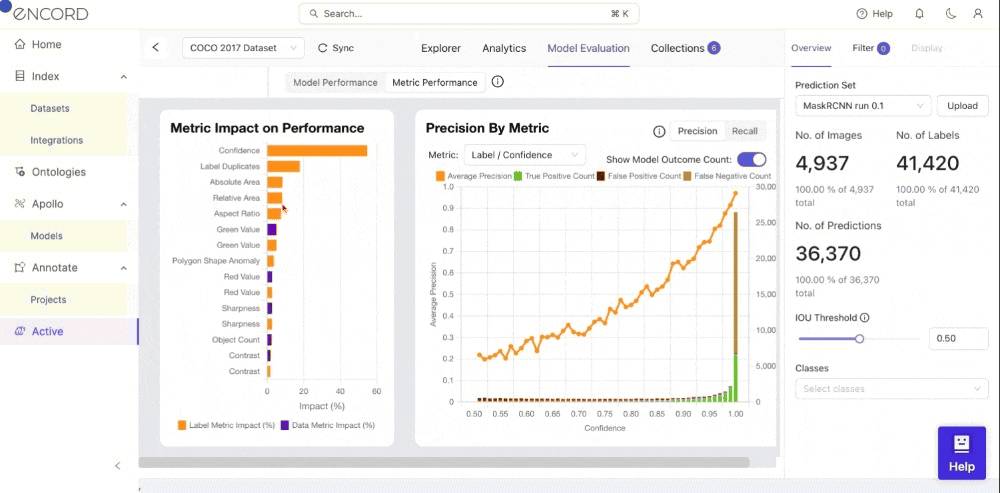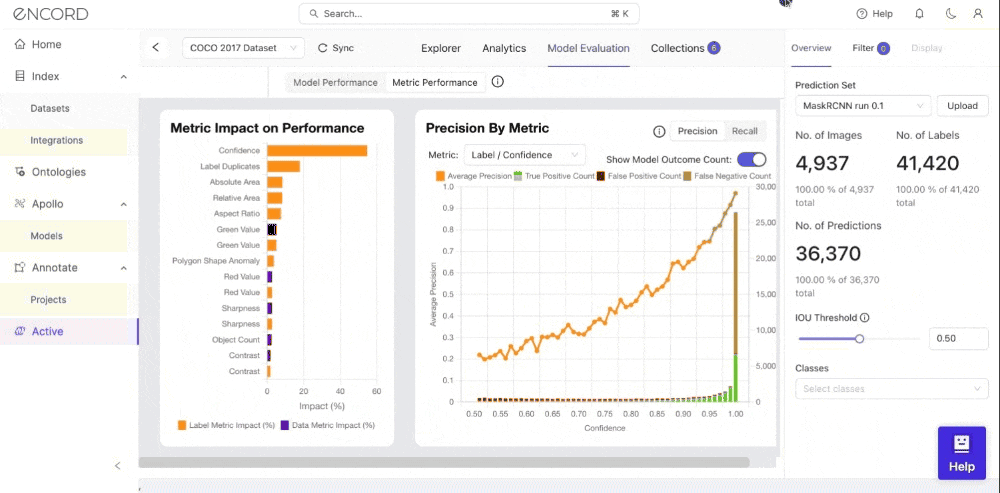
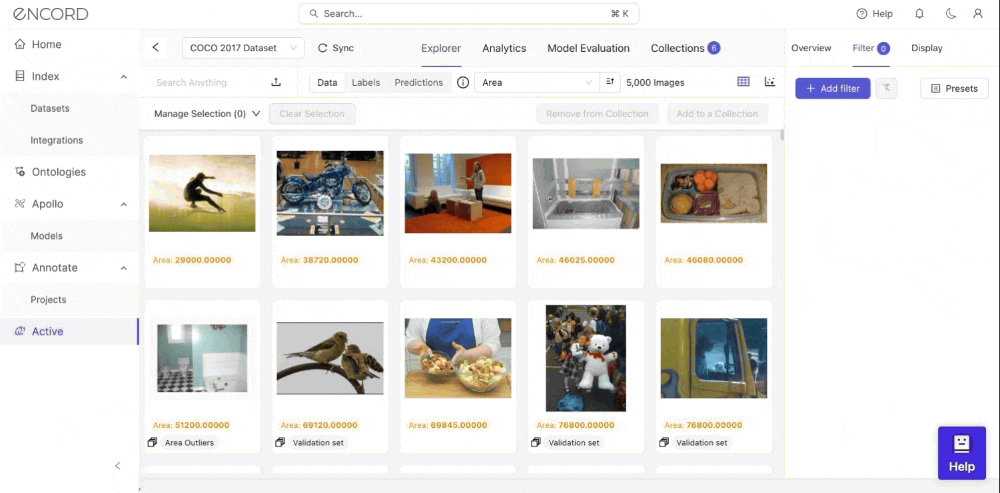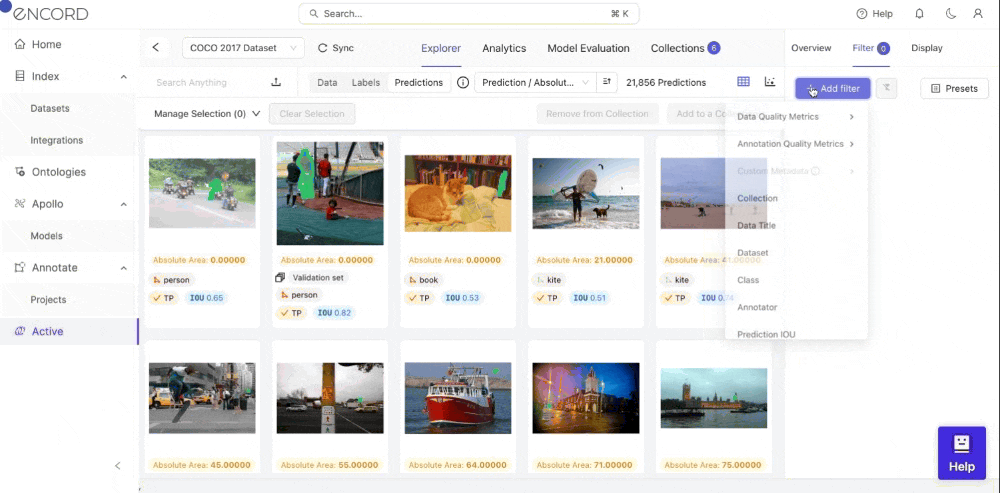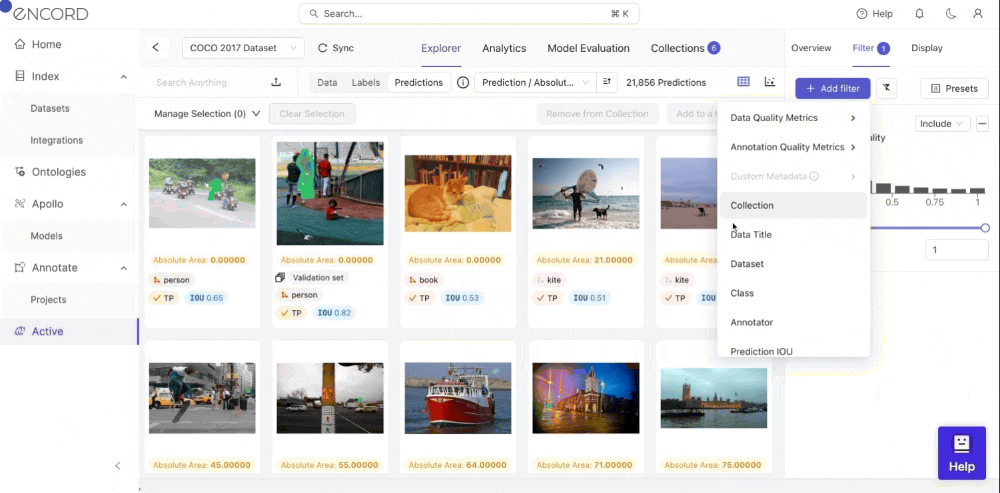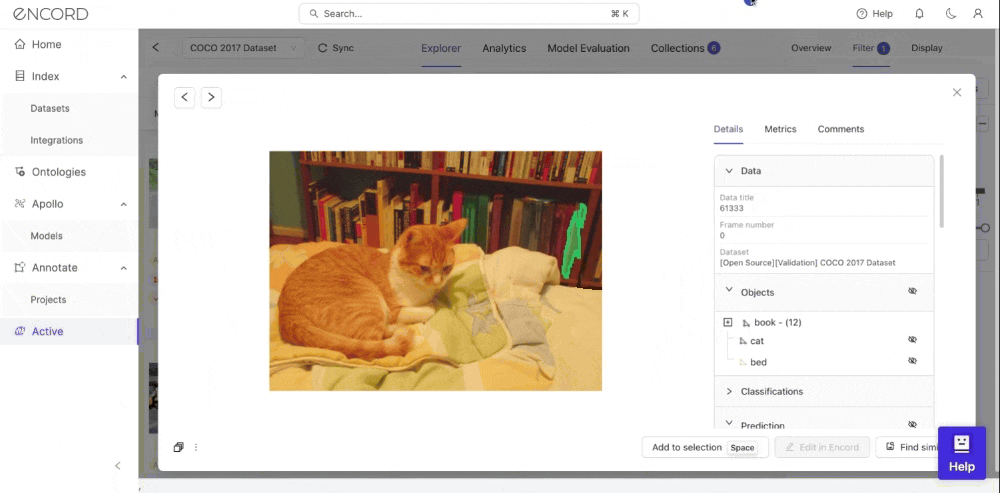
Within Encord Active, you can visualize the impact of data and label quality metrics on your model's performance. This can also visualize Precision or Recall by Metric based on the model results to know which instances it needs to predict better. Let’s see how you can achieve this step-by-step within Encord Active.
- Step 1: Navigate to the Model Evaluation tab.
- Step 2: Toggle the Metric Performance button. You will see a graph of your model’s performance based on the precision by the quality metric you select to identify model failure modes.
Debug Data Annotation Errors
When developing ML systems or running them in production, one key issue to look out for is the quality of your annotations. They can make or break the ML systems because they are only as good as the ground truth they are trained on. Here’s how you could do it within Active Cloud:
- Step 1: Navigate to Explorer and Click Predictions
- Step 2: Click Add Filter >> Annotation Quality Metrics, and select a metric you want to inspect.
Perform Root-Cause Analysis
Encord Active provides a quick method to filter unwanted or problematic images by auto-discovering the issues in your model predictions. Here’s how to do it:
- Ensure you are on the Explorer tab.
- Click on Predictions and on the right hand side of your scream, you should see model prediction issues Active has surfaced including the types.
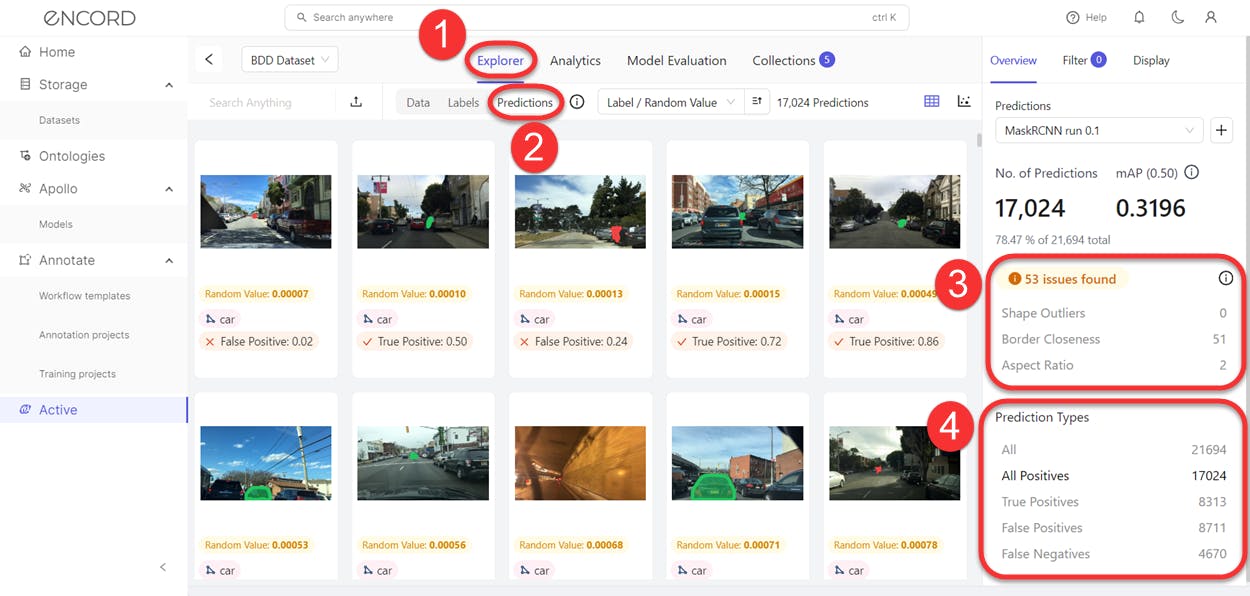
Those are shortcuts to improving datasets and model performance. They give you a quick launch pad to improve your data and model performance.
With Encord Active, you can also:
- Use automated CV pipelines to build robust models.
- Use pre-built or custom quality metrics to assess CV model performance.
- Run robustness checks on your model before and after deployment.

Challenges of Model Observability
Despite effective tools, implementing an end-to-end model observability pipeline takes time and effort. The list below highlights the most pressing issues you must address before building an efficient observability workflow.
- Increasing model complexity: Modern AI models are highly complex, with many integrated modules, deep neural nets, pre-processing layers, etc. Validating, monitoring, and performing root-cause analysis on these sophisticated architectures is tedious and time-consuming.
- XAI in multimodal models: Explaining models that use multiple modalities - text, image, audio, etc. - is difficult. For instance, using salience-based methods to explain vision-language models that combine NLP and visual information for inferencing would be incredibly costly due to the sheer number of parameters.
- Privacy concerns: Privacy restrictions mean you cannot freely analyze model performance on sensitive data, which may lead to compliance issues. This in turn, could hurt customer retention if the end user feels like their data is under threat.
- Scalability: Observing models that receive considerable inference requests requires a robust infrastructure to manage large data volumes.
- Human understanding and bias: This challenge concerns XAI, where explanations can differ based on the model used. Also, understanding explainability results requires background knowledge that teams outside of data science may not have.
Future Trends in Model Observability
While the above challenges make optimal model observability difficult to achieve, research in the direction of XAI shows promising future trends.
For instance, there is considerable focus on making XAI more user-friendly by building techniques that generate simple explanations. Also, research into AI model fairness is ongoing, emphasizing using XAI to visualize learned features and employing other methods to detect bias.
In addition, studies that combine insights from other disciplines, such as psychology and philosophy, are attempting to find more human-centric explainability methods.
Finally, causal AI is a novel research area that aims to find techniques to highlight why a model uses a particular feature for predictions. This method can add value to explanations and increase model robustness.
Model Observability: Key Takeaways
As AI becomes more complex, observability will be crucial for optimizing model performance. Below are a few critical points you must remember about model observability.
- Observability for optimality: Model observability is essential for optimizing modern AI models through efficient validation, monitoring, and root-cause analysis.
- Better productivity: Observability improves resource allocations, reduces the cost of re-training, builds customer trust, ensures regulatory compliance, and speeds up error detection and resolution.
- LLM and CV observability: Observability for LLMs and CV models differs slightly from standard ML observability due to issues specific to NLP and CV tasks.
- Monitoring and explainability: Model monitoring and explainability are two primary components of observability, each with different techniques.
- Challenges and future trends: Model complexity is the primary issue with observability and will require better explainability techniques to help users understand how modern models think.
Frequently asked questions
Model observability is the process of validating, monitoring, and finding the root cause of issues in machine learning models.
ML observability is a broader concept that deals with understanding how and why a model makes a particular prediction. In contrast, ML monitoring only identifies issues by measuring relevant model metrics to evaluate performance.
Model monitoring and explainability are two critical components of observability. Monitoring helps detect errors, and explainability helps understand the fundamental reason behind the error.
The primary challenges include increasing model complexity, scalability, privacy concerns, explainability in multimodal domains, and differences in model deployment and explanation strategies.
Yes. Experts can apply observability to simple and complex models to delve deeper into the model’s decision-making process.
Model explainability is interpreting a model’s behavior by understanding how it reaches a particular conclusion during inference.
Encord utilise une approche basée sur des modèles préexistants que nous personnalisons et affinons selon les besoins spécifiques de chaque client. Cela inclut l'entraînement de modèles sur des données propres au projet afin de garantir des performances optimales dans des environnements variés.
Encord offers robust security features, including role-based access control, which ensures that only authorized users can access sensitive data and functionalities. Additionally, the platform includes backup and restore mechanisms to protect your data integrity.
Encord includes robust security integrations to ensure data protection throughout the annotation process. This encompasses auditability and traceability features that help safeguard sensitive information while maintaining compliance with industry standards.
Encord implements role-based access control to ensure that only authorized personnel can access sensitive data and manage different stages of the annotation process. This enhances security while allowing for effective management of expertise within teams.
Encord prioritizes data security by ensuring that client data is handled with care. We do not take physical copies of sensitive data, which is especially important for clients in industries like defense and medical where data protection is critical.
Encord prioritizes infrastructure stability, cloud data security, and adherence to regulations, providing peace of mind for teams handling sensitive data in their AI projects.