Model Test Cases: A Practical Approach to Evaluating ML Models

As machine learning models become increasingly complex and ubiquitous, it's crucial to have a practical and methodical approach to evaluating their performance. But what's the best way to evaluate your models?
Traditionally, average accuracy scores like Mean Average Precision (mAP) have been used that are computed over the entire dataset. While these scores are useful during the proof-of-concept phase, they often fall short when models are deployed to production on real-world data. In those cases, you need to know how your models perform under specific scenarios, not just overall.
At Encord, we approach model evaluation using with a data-centric approach using model test cases. Think of them as the "unit tests" of the machine learning world. By running your models through a set of predefined test cases before continuing model deployment or prior to deployment, you can identify any issues or weaknesses and improve your model's accuracy. Even after deployment, model test cases can be used to continuously monitor and optimize your model's performance, ensuring it meets your expectations.

In this article, we will explore the importance of model test cases and how you can define them using quality metrics.
We will use a practical example to put this framework into context. Imagine you’re building a model for a car parking management system that identifies car throughput, measures capacity at different times of the day, and analyzes the distribution of different car types.
You've successfully trained a model that works well on Parking Lot A in Boston with the cameras you've set up to track the parking lot. Your proof of concept is complete, investors are happy, and they ask you to scale it out to different parking lots.

Car parking photos are taken under various weather and daytime conditions.
However, when you deploy the same model in a new parking house in Boston and in another town (e.g., Minnesota), you find that there are a lot of new scenarios you haven't accounted for:
- In the parking lot in Boston, the cameras have slightly blurrier images, different contrast levels, and the cars are closer to the cameras.
- In Minnesota, there is snow on the ground, different types of lines painted on the parking lot, and new types of cars that weren't in your training data.

This is where a practical and methodical approach to testing these scenarios is important.
Let's explore the concept of defining model test cases in detail through five steps:
- Identify Failure Mode Scenarios
- Define Model Test Cases
- Evaluate Granular Performance
- Mitigate Failure Modes
- Automate Model Test Cases
Identify Failure Mode Scenarios
Thoroughly testing a machine learning model requires considering potential failure modes, such as edge cases and outliers, that may impact its performance in real-world scenarios. Identifying these scenarios is a critical first step in the testing process of any model.
Failure mode scenarios may include a wide range of factors that could impact the model's performance, such as changing lighting conditions, unique perspectives, or variations in the environment.
Let's consider our car parking management system. In this case, some of the potential edge cases and outliers could include:
- Snow on the parking lot
- Different types of lines painted on the parking lot
- New types of cars that weren't in your training data
- Different lighting conditions at different times of day
- Different camera angles, perspectives, or distance to cars
- Different weather conditions, such as rain or fog
By identifying scenarios where your model might fail, you can begin to develop model test cases that evaluate the model's ability to handle these scenarios effectively.
It's important to note that identifying model failure modes is not a one-time process and should be revisited throughout the development and deployment of your model. As new scenarios arise, it may be necessary to add new test cases to ensure that your model continues to perform effectively in all possible scenarios.
Furthermore, some scenarios might require specialized attention, such as the addition of new classes to the model's training data or the implementation of more sophisticated algorithms to handle complex scenarios.
For example, in the case of adding new types of cars to the model's training data, it may be necessary to gather additional data to train the model effectively on these new classes.
Define Model Test Cases
Defining model test cases is an important step in the machine learning development process as it enables the evaluation of model performance and the identification of areas for improvement. As mentioned earlier, this involves specifying classes of new inputs beyond those in the original dataset for which the model is supposed to work well, and defining the expected model behavior on these new inputs.
Defining test cases begins by building hypotheses based on the different scenarios the model is likely to encounter in the real world. This can involve considering different environmental conditions, lighting conditions, camera angles, or any other factors that could affect the model's performance. Hereafter you define the expected model behavior under the scenario.
My model should achieve X in the scenario where Y
It is crucial that the test case is quantifiable. That is, you need to be able to measure whether the test case passes or not. In the next section, we’ll get back to how to do this in practice.
For the car parking management system, you could define your model test cases as follows:
- The model should achieve an mAP of 0.75 for car detection when cars are partially covered in or surrounded by snow.
- The model should have an accuracy of 98% on parking spaces when the parking lines are partially covered in snow.
- The model should achieve an mAP of 0.75 for car detection in parking houses under poor light conditions.
Evaluate Granular Performance
Once the model test cases have been defined, the performance can be evaluated using appropriate performance metrics for each model test case.
This might involve measuring the model's mAP, precision, and recall of data slices related to specified test cases.
To find the specific data slices relevant to your model test case we recommend using Quality metrics.
Quality metrics are useful to evaluate your model's performance based on specific criteria, such as object size, blurry images, or time of day. In practice, they are additional parametrizations added on top of your data, labels, and model predictions and they allow you to index your data, labels, and model predictions in semantically relevant ways. Read more here.

Quality metrics can then be used to identify data slices related to your model test cases. To evaluate a specific model text case, you identify a slice of data that has the properties that the test case defines and evaluate your model performance on that slice of data.

Mitigate Failure Modes
If your model test case fails and the model is not performing according to your expectations in the defined scenario, you need to take action to improve performance. This is where targeted data quality improvements come in. These improvements can take various shapes and forms, including:
- Data collection campaigns: Collect new data samples that cover identified scenarios. Remember to ensure data diversity by obtaining samples from different locations and parking lot types. Nonetheless, you should regularly update the dataset to account for new scenarios and maintain model performance.
- Relabeling Campaigns: If your failure modes are due to label errors in the existing dataset it would be beneficial to correct any inaccuracies or inconsistencies in labels before collecting new data. If your use case is complex, we recommend collaborating with domain experts to ensure high-quality annotations.
- Data augmentation: By applying methods such as rotation, color adjustment, and cropping, you can increase the diversity of your dataset. Additionally, you can utilize techniques to simulate various lighting conditions, camera angles, or environmental factors that the model might encounter in real-world scenarios. Implementing domain-specific augmentation techniques, such as adding snow or rain to images, can further enhance the model's ability to generalize to various situations.
- Synthetic data generation: Creating artificial data samples can help expand the dataset, but it is essential to ensure that the generated data closely resembles real-world scenarios to maintain model performance. Combining synthetic data with real data can increase the dataset size and diversity, potentially leading to more robust models.
Automated Model Test Cases
Once you've defined your model test cases, you need a way to select data slices and test them in practice. This is where quality metrics and Encord Active comes in.
Encord Active is an open-source data-centric toolkit that allows you to investigate and analyze your data distribution and model performance against these quality metrics, in an easy and convenient way.
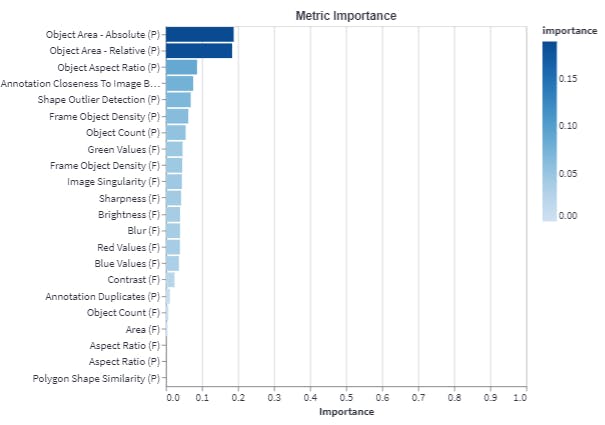
The chart above is automatically generated by Encord Active using uploaded model predictions. The chart shows the dependency between model performance and each metric - how much is model performance affected by each metric.
With quality metrics, you identify areas where the model is underperforming, even if it's still achieving high overall accuracy. Thus they are perfect for testing your model test cases in practice.
For example, the quality metric that specifically measures the model's performance in low-light conditions (see “Brightness” among quality metrics in the figure above) will help you to understand if your car parking management system model will struggle to detect cars in low-light conditions.
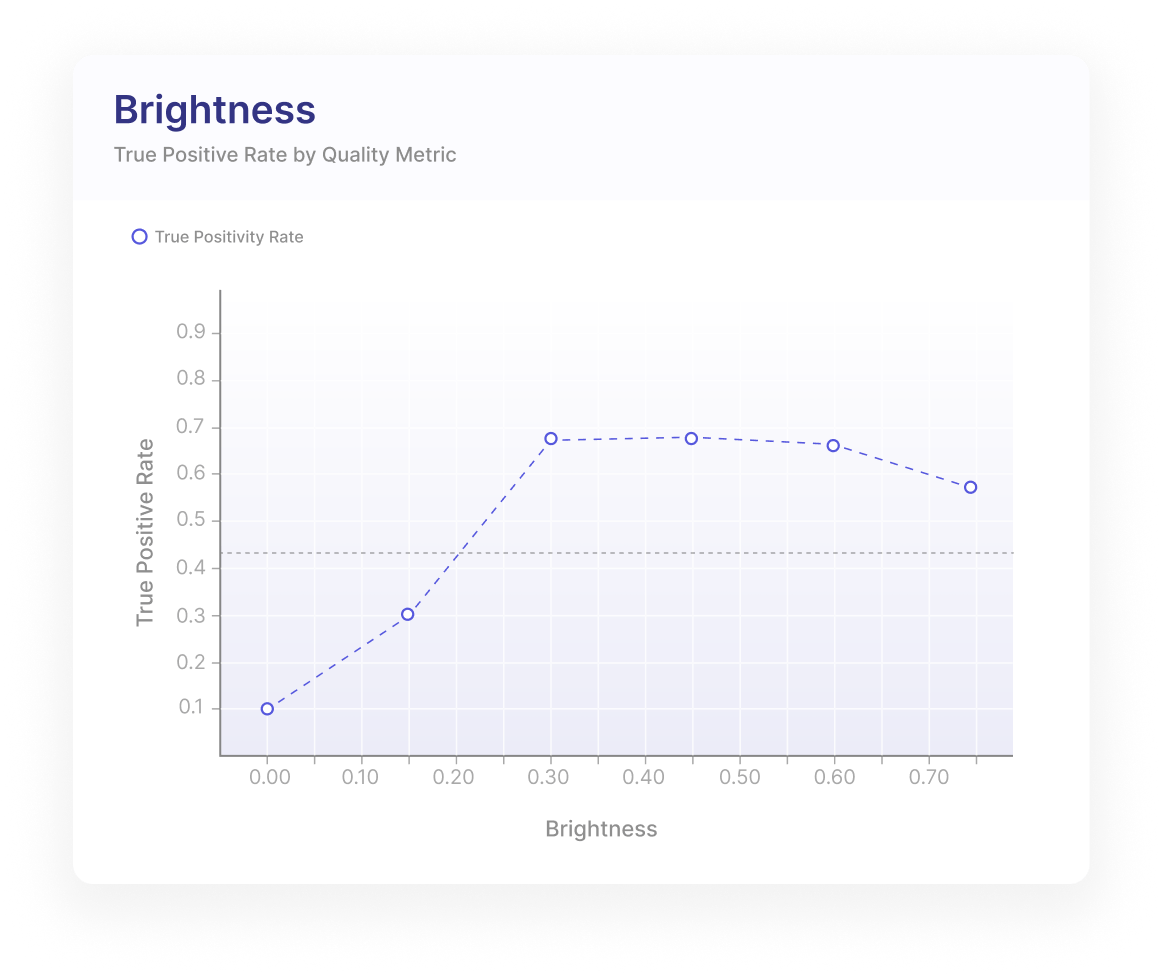
You could also use the “Object Area” quality metric to create a model test case that checks if your model has issues with different sizes of objects (different distance to cars results in different object areas).
One of the benefits of Encord Active is that it is open-source and it enables you to write your own custom quality metrics to test your hypotheses around different scenarios.
Tip: If you have any specific things you’d like to test please get in touch with us and we would gladly help you get started.
This means that you can define quality metrics that are specific to your use case and evaluate your model's performance against them. For example, you might define a quality metric that measures the model's performance in heavy rain conditions (a combination of low Brightness and Blur).
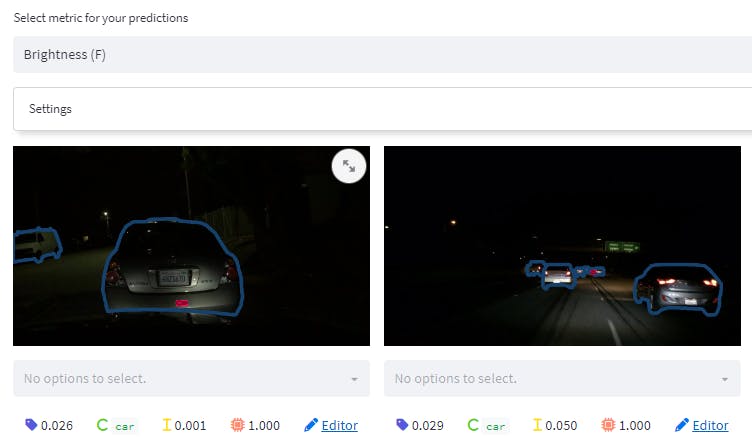
Finally, if you would like to visually inspect the slices that your model is struggling with you can visualize model predictions (both TP, FP, and FNs) if you.
Tip: You can use Encord Annotate to directly correct labels if you spot any outright label errors.
Back to the car parking management system example:
Once you have defined your model test cases and evaluated your model's performance against using the quality metrics, you can find low-performing "slices" of data.
If you've defined a model test case for the scenario where there is snow on the ground in Minnesota, you can:
- Compute the quality metric that measures its performance in snowy conditions.
- Investigate how much this metric affects the overall performance.
- Filter the slice of images where your model performance is low.
- Set in motion a data collection campaign for images in similar conditions.
- Set up an automated model test that always tests for performance on snowy images in your future models.
Tip: If you already have a database of unlabeled data you can leverage similarity search to find images of interest for your data collection campaigns.
Benefits of The Model Test Case Framework
As machine learning models continue to evolve, evaluating them is becoming more important than ever. By using a model test case framework, you can gain a more comprehensive understanding of your model's performance and identify areas for improvement. This approach is far more effective and safe than relying solely on high-level accuracy metrics, which can be insufficient in evaluating your model performance in real-world scenarios.

So to summarize, the benefits of using model test cases instead of only high level accuracy performance metrics are:
Enhanced understanding of your model: You gain a thorough understanding of your model by evaluating it in detail (rather than depending on one overall metric). systematically analyzing its performance will improve your (and your team's) confidence in its effectiveness during deployment and augments the model's credibility.
Allows you to concentrate on addressing model failure modes: Armed with an in-depth evaluation from Encord Active, efforts to improve a model can be directed toward its weak areas. Focusing on the weaker aspects of your model accelerates its development, optimizes engineering time, and minimizes data collection and labeling expenses.
Fully customizable to your specific case: One of the benefits of using open-source tools like Encord Active is that it enables you to write your own custom quality metrics and set up automated triggers without having to rely on proprietary software.
If you're interested in incorporating model test cases into your data annotation and model development workflow, don't hesitate to reach out.
Conclusion
In this article, we start off by understanding why defining model test cases and using quality metrics to evaluate model performance against them is essential. It is a practical and methodical approach for identifying data-centric failure modes in machine learning models.
By defining model test cases, evaluating model performance against quality metrics, and setting up automated triggers to test them, you can identify areas where the model needs improvement, prioritize data labeling efforts accordingly, and improve the model's credibility with your team.
Furthermore, it changes the development cycle from reactive to proactive, where you can find and fix potential issues before they occur, instead of deploying your model in a new scenario and finding out that you have poor performance and trying to fix it.
Open-source tools like Encord Active enable users to write their own quality metrics and set up automated triggers without having to rely on proprietary software. This can lead to more collaboration and knowledge sharing across the machine-learning community, ultimately leading to more robust and effective machine-learning models in the long run.
Frequently asked questions
A systematic approach to testing machine learning models is crucial for identifying persistent issues and understanding their origins. Encord emphasizes this methodology, enabling teams to conduct thorough analyses and implement informed improvements, rather than reacting to individual errors as they arise.
Encord enables users to streamline the training and testing process by facilitating the collection of data from various environments. It allows for the creation of comprehensive test sets and training sets simultaneously, addressing known issues while also accommodating new, unforeseen challenges.
Encord enhances model testing and data validation by providing tools to identify issues quickly and prioritize better data for annotation. This allows teams to iterate on their models faster, ensuring that they can address problems effectively and improve overall model performance.
Post-sale, customers can expect dedicated support from a Customer Success Manager who will serve as the primary point of contact. The Encord team is committed to ensuring customers have the resources they need to effectively utilize the platform to meet their goals.
Encord provides a variety of case studies on its website, showcasing how different clients across industries use the platform to enhance their data annotation processes and improve model performance, including notable companies in warehouse safety and robotics.
Encord is designed to scale alongside your needs, accommodating both increased volume of annotations and the addition of more team members. This flexibility ensures that as your projects grow, Encord can adapt to support your expanding requirements.
Encord provides dedicated customer success management and support teams to assist users with any tool-related issues. Regular check-ins and a Slack channel for communication ensure that teams receive timely support to address their needs.
Encord assists in model evaluation by identifying edge cases where models may be failing. This critical feedback loop helps teams refine their models, ensuring they address specific scenarios that could impact performance.