Gemini 1.5: Google's Generative AI Model with Mixture of Experts Architecture

In December 2023, Google launched the Gemini 1.0 family of models that outperformed state-of-the-art (SoTA) models in multimodal AI capabilities. Fast-forward to February 2024, and the Google Deepmind research team has launched Gemini 1.5 Pro with up to 10 million context windows! Not only that, it maintains near-perfect across the entire context and uses a mixture-of-experts (MoE) architecture for more efficient training & higher-quality responses.
In this article, you will learn about:
- The superior performance benchmarks of Gemini 1.5
- Why it performs better than SoTA at textual, visual, and audio capabilities
- How well it handles long-context tasks, especially with MoE as it’s architectural backbone
- How you can get started using it
Before we jump into it, let’s set the tone with an overview of the MoE architecture that backs Gemini 1.5.
- Gemini 1.5 is a Sparse mixture-of-experts (MoE) multimodal model with a context window of up to 10 million tokens. It excels at long-term recall and retrieval; generalizes zero-shot to long instructions like analyzing 3 hours of video, and 22 hours of audio with near-perfect recall.
- It performs better than Gemini 1.0 Pro and 1.0 Ultra but performs worse than 1.0 Ultra for audio and vision.
- Although there are no detailed insights on the model size, architectural experiments, or the number of experts, the model performs well at in-context memorization and generalization
Mixture-of-Experts (MoE) Architecture
Gemini 1.5 Pro uses a mixture-of-experts (MoE) architecture for efficient training & higher-quality responses, building on a long line of Google research efforts on sparse models.
At its core, MoE diverges from traditional deep learning and Transformer architectures by introducing a dynamic routing mechanism that selectively activates different subsets of parameters (referred to as "experts") depending on the input data. It learns to selectively activate only the most relevant expert pathways in its neural network for nuanced and contextually aware outputs.
This approach enables the model to scale more effectively in terms of computational efficiency and capacity without a linear increase in computational demands. In the context of Gemini 1.5, the MoE architecture contributes to efficient training and serving. Concentrating computational resources on the most relevant parts of the model for each input allows for faster convergence and improved performance without necessitating the proportional increase in computational power typically associated with scaling up the model size.
Gemini 1.5 - Model Functionalities
Gemini 1.5 drops with some impressive functionalities that beat SoTA models:
- Huge context window that spans up to 10 million-token context length
- Reduced training compute with the mixture-of-experts architecture
- Superior performance compared to Gemini 1.0 models, GPT-4, and other SoTA
Huge Context Window
A model’s “context window” comprises tokens, the building blocks for processing a user’s query. Tokens can be entire parts or subsections of words, images, videos, audio, or code. The bigger a model’s context window, the more information it can take in and process at a given prompt.
Gemini 1.5 is a highly capable multimodal model with token context lengths ranging from 128K to 1 million token context lengths for production applications and up to 10 million for research.
This unlocks a lot of use cases:
- Across reasoning about long text documents
- Making sense of an hour of video (full movies)
- 11 hours of audio
- Entire podcast series
- 700,000 words
- 30,000 lines of code simultaneously
These capabilities are several times greater than other AI models, including OpenAI’s GPT-4, which powers ChatGPT.

Context lengths of foundation models with Gemini 1.5 scaling up to 10 million tokens in research
Reduced Training Compute
The training compute required to train Gemini 1.5 were TPUv4 accelerators of multiple 4096-chip pods. This underscored the model's reliance on high-performance computing resources to perform well, but it also needed training efficiency techniques with the MoE architecture to be optimal.
Gemini 1.5 significantly reduced compute requirements for training despite the larger context windows. This achievement is pivotal in the progress of AI model training efficiency, addressing one of the most pressing challenges in the field: the environmental and economic costs associated with training large-scale AI models.
The reduction in training compute is primarily down to the Mixture-of-Experts (MoE) architectural backbone, which Gemini 1.5 uses to optimize computational resources.
Beyond that, Gemini 1.5 incorporates state-of-the-art techniques such as sparsity in the model's parameters, which means that only a subset of the model's weights is updated during each training step. This approach reduces the computational load, leading to faster training times and lower energy consumption.
According to the technical report, combining those processes to train the model led to remarkable performance without the proportional increase in resource consumption typically seen in less advanced models.
Recalling and Reasoning
Google Gemini 1.5 Pro sets a new standard in AI's ability to recall and reason across extensive multimodal contexts. The ten million-token context window—the largest of any foundational model, so far—enables Gemini 1.5 Pro to demonstrate unparalleled proficiency in synthesizing and interpreting vast amounts of information. Gemini 1.5 Pro achieves near-perfect recall in complex retrieval tasks across long text documents, videos, and audio, which shows its understanding of the input.
In tests from the report, Gemini 1.5 Pro learned new languages from sparse instructional materials 🤯. This model's proficiency in recalling specific details from large datasets and its capability to apply this knowledge in reasoning tasks usher in a new era in AI applications—ranging from academic research and comprehensive code analysis to nuanced content creation.



Superior Performance Benchmark
Gemini 1.5 Pro demonstrates remarkable improvements over state-of-the-art (SotA) models, including GPT-4V, in tasks spanning text, code, vision, and audio. Some of the benchmarks for which Gemini 1.5 Pro achieves SotA accuracy include 1H-VideoQA and EgoSchema. This indicates Gemini 1.5 Pro's advanced long-context multimodal understanding.
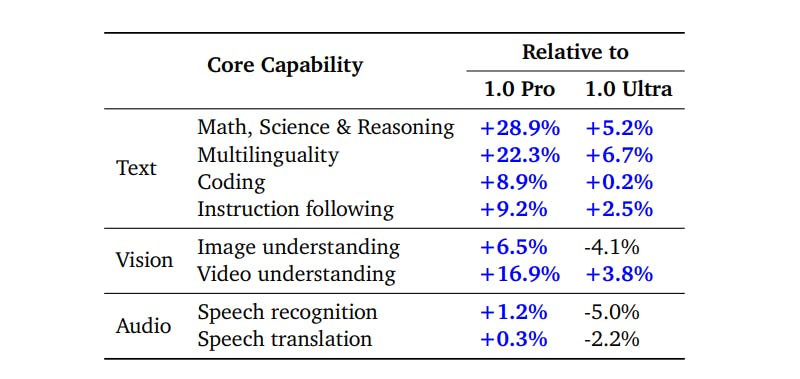
In core text evaluations, Gemini 1.5 Pro consistently outperforms its predecessors (Gemini 1.0 Pro and Ultra) in various domains such as Math, Science & Reasoning, Coding, Multilinguality, and Instruction Following. The model shows substantial improvements, particularly in Math and Science Reasoning, where it outperforms Gemini 1.0 Ultra, and in Coding tasks, it sets a new SotA accuracy benchmark on EgoSchema.
Gemini 1.5 Pro's performance in multilingual evaluations highlights its enhanced ability to process and understand multiple languages. It shows significant improvements over both Gemini 1.0 models and other specialist models like USM and Whisper in speech understanding tasks.
Needle In A Haystack (NIAH) Evaluation
The Needle In A Haystack (NIAH) evaluation showcases Gemini 1.5 Pro's capability to retrieve specific information ("needle") from a massive amount of data ("haystack") across different modalities. This evaluation underscores the model's efficiency in long-context understanding and recall accuracy.
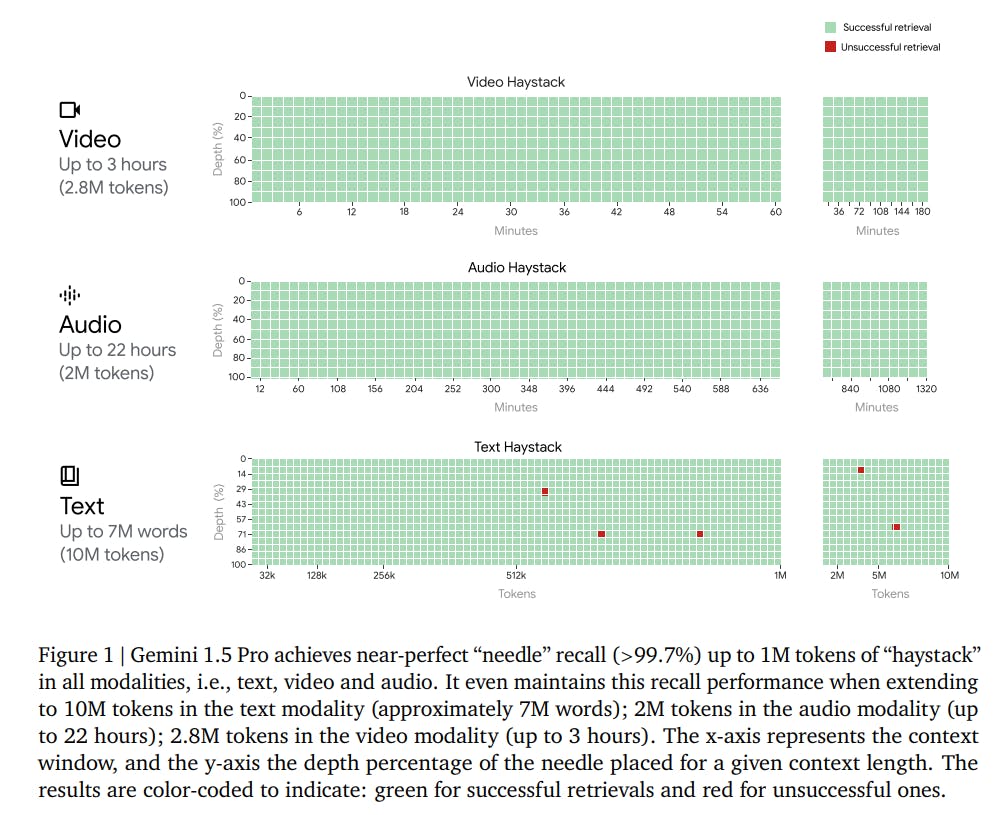
Context Window - Text Modality: Recall to Token Count
Gemini 1.5 Pro excels in the text modality, with the model achieving over 99% recall for up to 10 million tokens, or approximately 7 million words. This capacity for deep, nuanced understanding and recall from vast quantities of text sets a new benchmark for AI performance in natural language processing. It can sift through large volumes of text to find specific information.
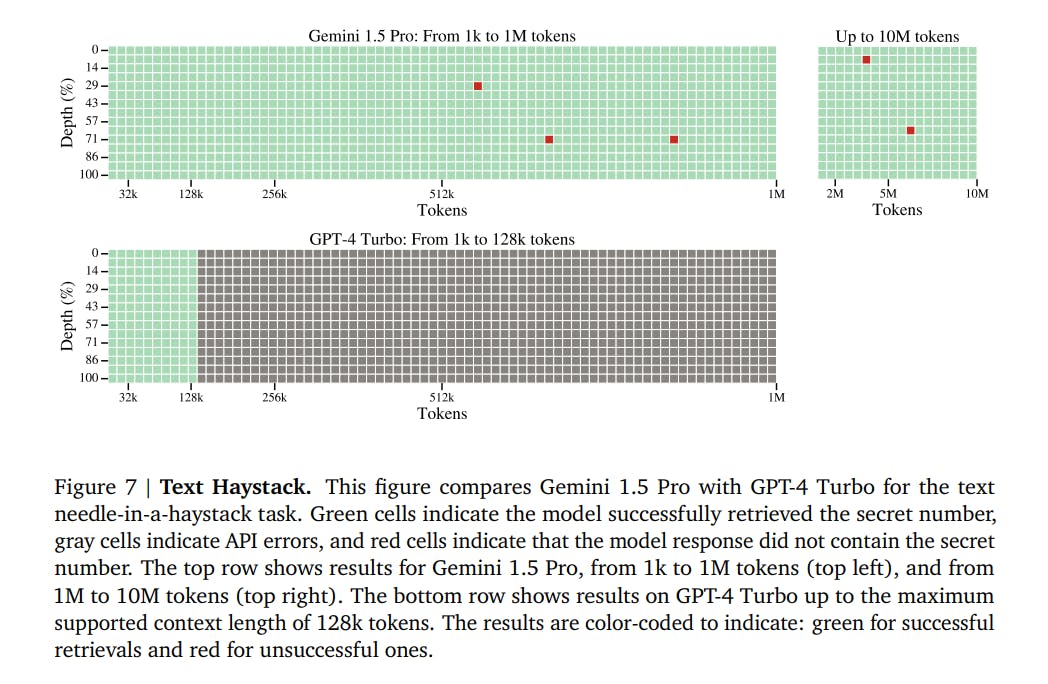
Text needle-in-a-haystack task comparison between Gemini 1.5 Pro and GPT-4 Turbo
The model demonstrates high recall rates for identifying exact text segments within extensive documents.
Context Window - Audio Modality: Recall to Token Count
Gemini 1.5 Pro demonstrates an exceptional ability to recall information from audio data, achieving near-perfect recall (>99.7%) up to 2 million tokens, equivalent to approximately 22 hours of audio content. It was able to recall and identify specific audio segments ("needles") embedded within long audio streams ("haystacks").
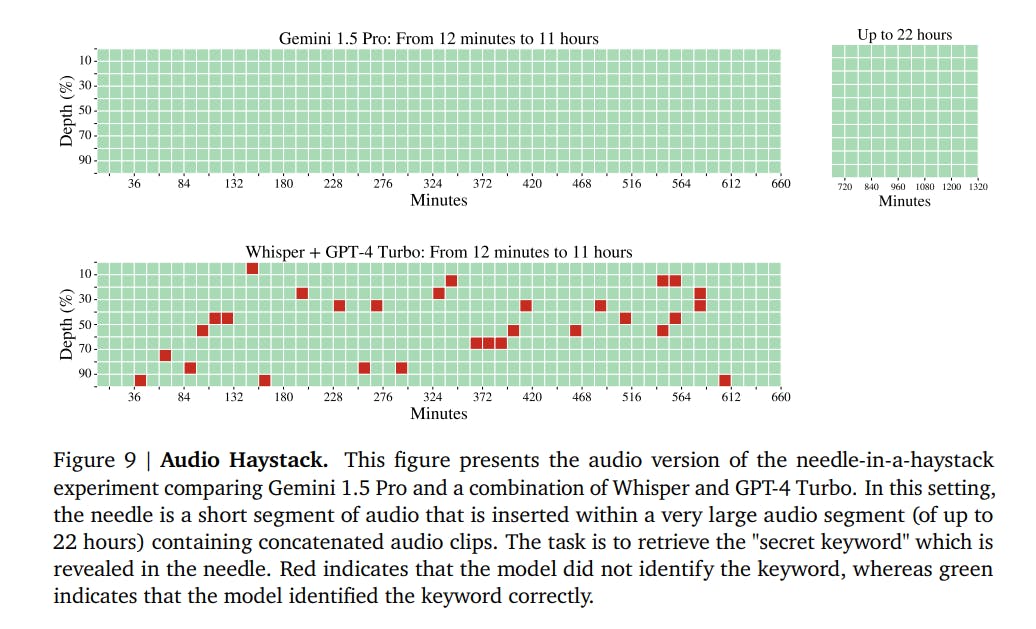
This represents a significant advancement over combining two SoTA models like Whisper + GPT-4 Turbo in a recall-to-token count comparison, which struggles with long-context audio processing.
Context Window - Video Modality: Recall to Token Count
Gemini 1.5 Pro maintains high recall performance in the video modality, successfully retrieving information from video data up to 2.8 million tokens, correlating to around 3 hours of video content. The "Video Needle In A Haystack" task tested the model's performance in recalling specific video frames from lengthy videos.
This is critical for tasks requiring detailed understanding and analysis of long-duration video sequences. It can accurately pinpoint and recall specific moments or information from extensive video sequences.
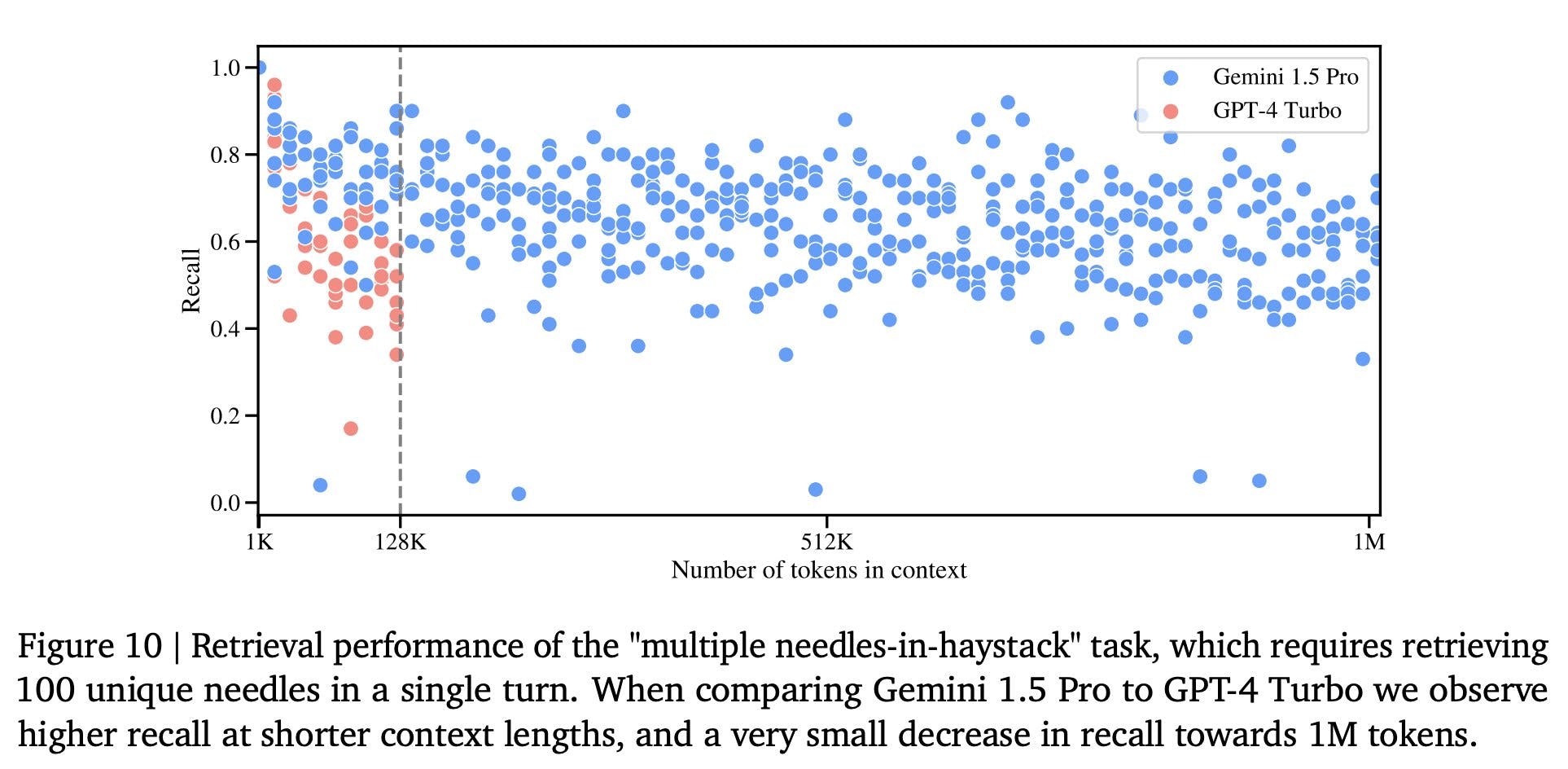
Multineedle in Haystack Test
The researchers created a generalized version of the needle in a haystack test, where the model must retrieve 100 different needles hidden in the context window.
The results? Gemini 1.5 Pro’s performance was above that of GPT-4 Turbo at small context lengths and remains relatively steady across the entire 1M context window. At the same time, the GPT-4 Turbo model drops off more quickly (and cannot go past 128k tokens).
Textual Capabilities of Gemini 1.5
Mathematical and Scientific Textual Reasoning
Gemini 1.5 Pro shows a +28.9% improvement over Gemini 1.0 Pro and a +5.2% improvement over Gemini 1.0 Ultra. This indicates a substantial increase in its ability to handle complex reasoning and problem-solving tasks. This proficiency is attributed to its extensive training dataset, which includes a wide array of scientific literature and mathematical problems, so the model can grasp and apply complex concepts accurately.
Coding
In Coding tasks, Gemini 1.5 Pro marked a +8.9% improvement over 1.0 Pro and +0.2% over 1.0 Ultra, showcasing its superior algorithmic understanding and code generation capabilities.
The model can 𝐚𝐜𝐜𝐮𝐫𝐚𝐭𝐞𝐥𝐲 𝐚𝐧𝐚𝐥𝐲𝐳𝐞 an entire code library in a single prompt, without the need to fine-tune the model, including understanding and reasoning over small details that a developer might easily miss.
Problem Solving Capability across 100,633 lines of code
Instructional Understanding
Gemini 1.5 Pro excels in Instruction Following, surpassing the 1.0 series in comprehending and executing complex (+9.2% over 1.0 Pro and +2.5% over 1.0 Ultra), multi-step instructions across various data formats and tasks. This indicates its advanced natural language understanding and ability to process and apply knowledge in a contextually relevant manner.
Multilinguality
The model also shows improvements in handling multiple languages, with a +22.3% improvement over 1.0 Pro and a slight +6.7% improvement over 1.0 Ultra. This highlights its capacity for language understanding and translation across diverse linguistic datasets. This makes it an invaluable tool for global communication and preserving and revitalizing endangered languages.
Visual Capabilities of Gemini 1.5
The model's multimodal understanding is outstanding in Image and Video Understanding tasks. Gemini 1.5 Pro's performance in these areas reflects its ability to interpret and analyze visual data, making it an indispensable tool for tasks requiring a nuanced understanding of text and media.
Image and Video Understanding
For image understanding, there's a +6.5% improvement over 1.0 Pro but a -4.1% difference compared to 1.0 Ultra. In video understanding, however, Gemini 1.5 Pro shows a significant +16.9% improvement over 1.0 Pro and +3.8% over 1.0 Ultra, indicating robust enhancements in processing and understanding visual content.
These are some areas Gemini 1.5 performs great at:
- Contextual Understanding: Gemini 1.5 integrates visual data with textual descriptions, enabling it to understand the context and significance of visual elements in a comprehensive manner. This allows for nuanced interpretations that go beyond mere object recognition.
- Video Analysis: For video content, Gemini 1.5 demonstrates an advanced ability to track changes over time, recognize patterns, and predict outcomes. This includes understanding actions, events, and even the emotional tone of scenes and providing detailed analyses of video data.
- Image Processing: In image understanding, Gemini 1.5 utilizes state-of-the-art techniques to analyze and interpret images. This includes recognizing and categorizing objects, understanding spatial relationships, and extracting meaningful information from still visuals.
Audio Capabilities of Gemini 1.5
Speech Recognition and Translation
In an internal YouTube video-based benchmark, Gemini 1.5 Pro was evaluated on 15-minute segments, showing a remarkable ability to understand and transcribe speech with a word error rate (WER) significantly lower than that of its predecessors and other contemporary models.
This capability is especially notable given the challenges posed by long audio segments, where the model maintains high accuracy without the need for segmentation or additional preprocessing.
Gemini 1.5 Pro also performed well at translating spoken language from one language to another, maintaining the meaning and context of the original speech. This is particularly important for applications that require real-time or near-real-time translation.
Overall, there are mixed results in the audio domain, with a +1.2% improvement in speech recognition over 1.0 Pro but a -5.0% change compared to 1.0 Ultra. In speech translation, Gemini 1.5 Pro shows a slight +0.3% improvement over 1.0 Pro but a -2.2% difference compared to 1.0 Ultra.
Long Context Understanding
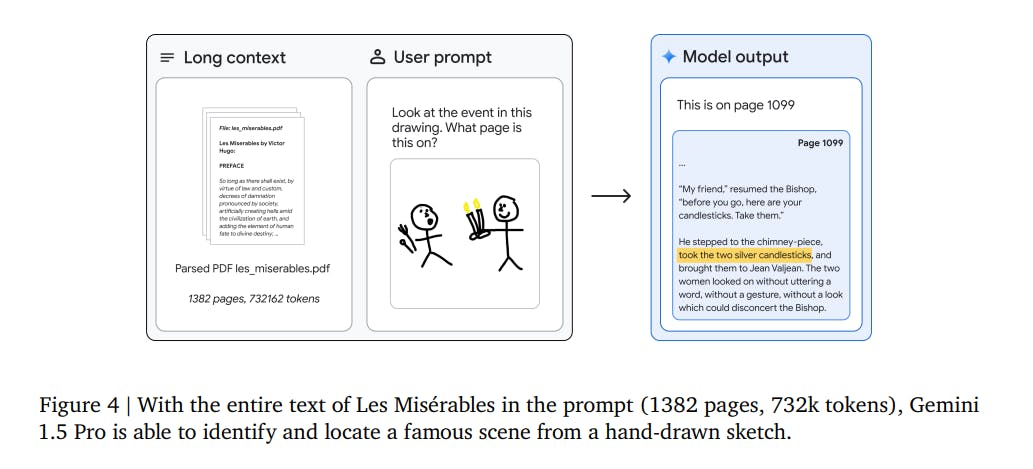
Gemini 1.5 Pro significantly expands the context length to multiple millions of tokens, enabling the model to process larger inputs effectively. This is a substantial improvement over models like Claude 2.1, which has a 200k token context window. Gemini 1.5 Pro maintains a 100% recall at 200k tokens and shows minimal reduction in recall up to 10 million tokens, highlighting its superior ability to manage and analyze extensive data sets.
In one example, the model analyzed long, complex text documents, like Victor Hugo’s five-volume novel “Les Misérables” (1382 pages, 732k tokens). The researchers demonstrated multimodal capabilities by coarsely sketching a scene and saying, “Look at the event in this drawing. What page is this on?”
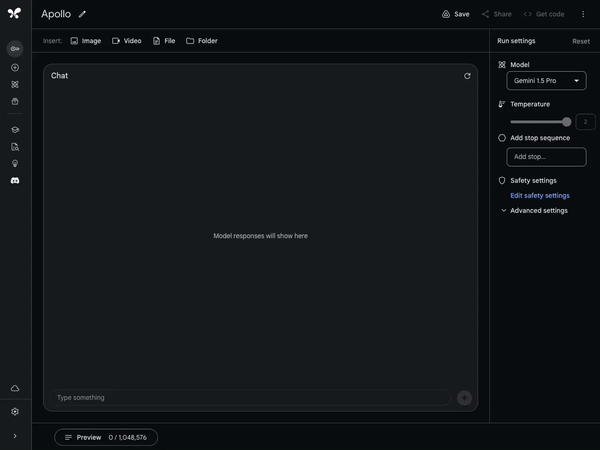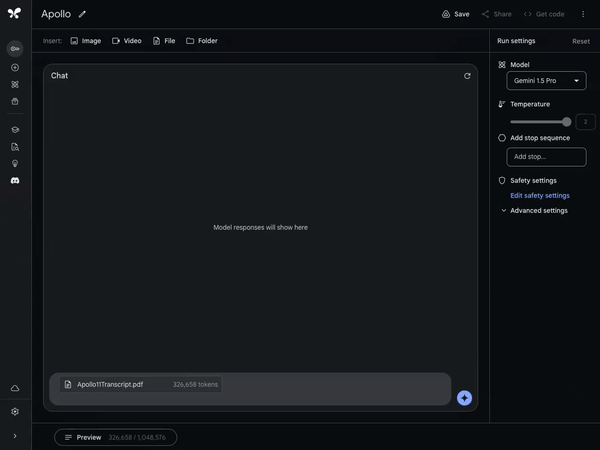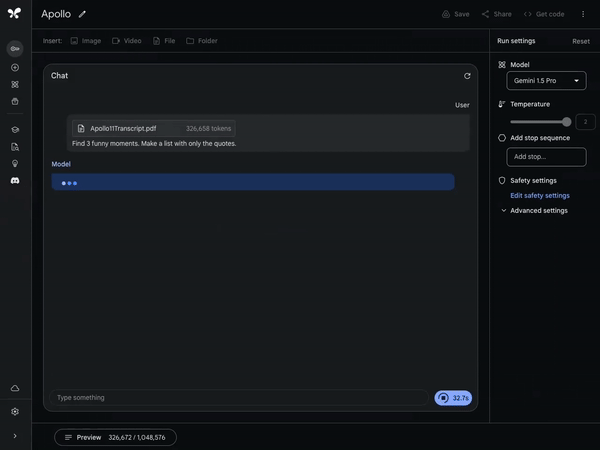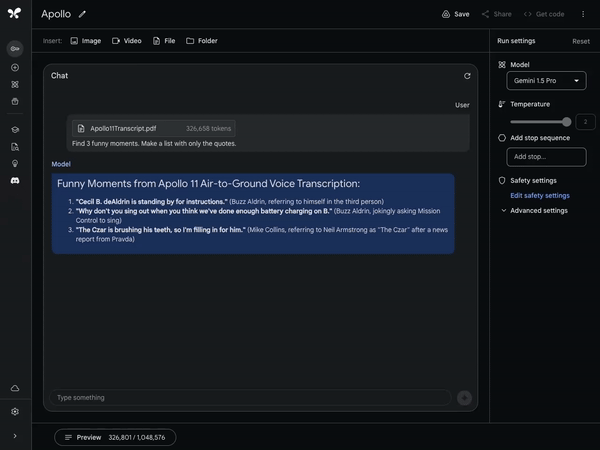
In another example, Gemini 1.5 Pro analyzed and summarized the 402-page transcripts from Apollo 11’s mission to the moon.
“One small step for man, one giant leap for mankind.”
Demo of Long Context Understanding
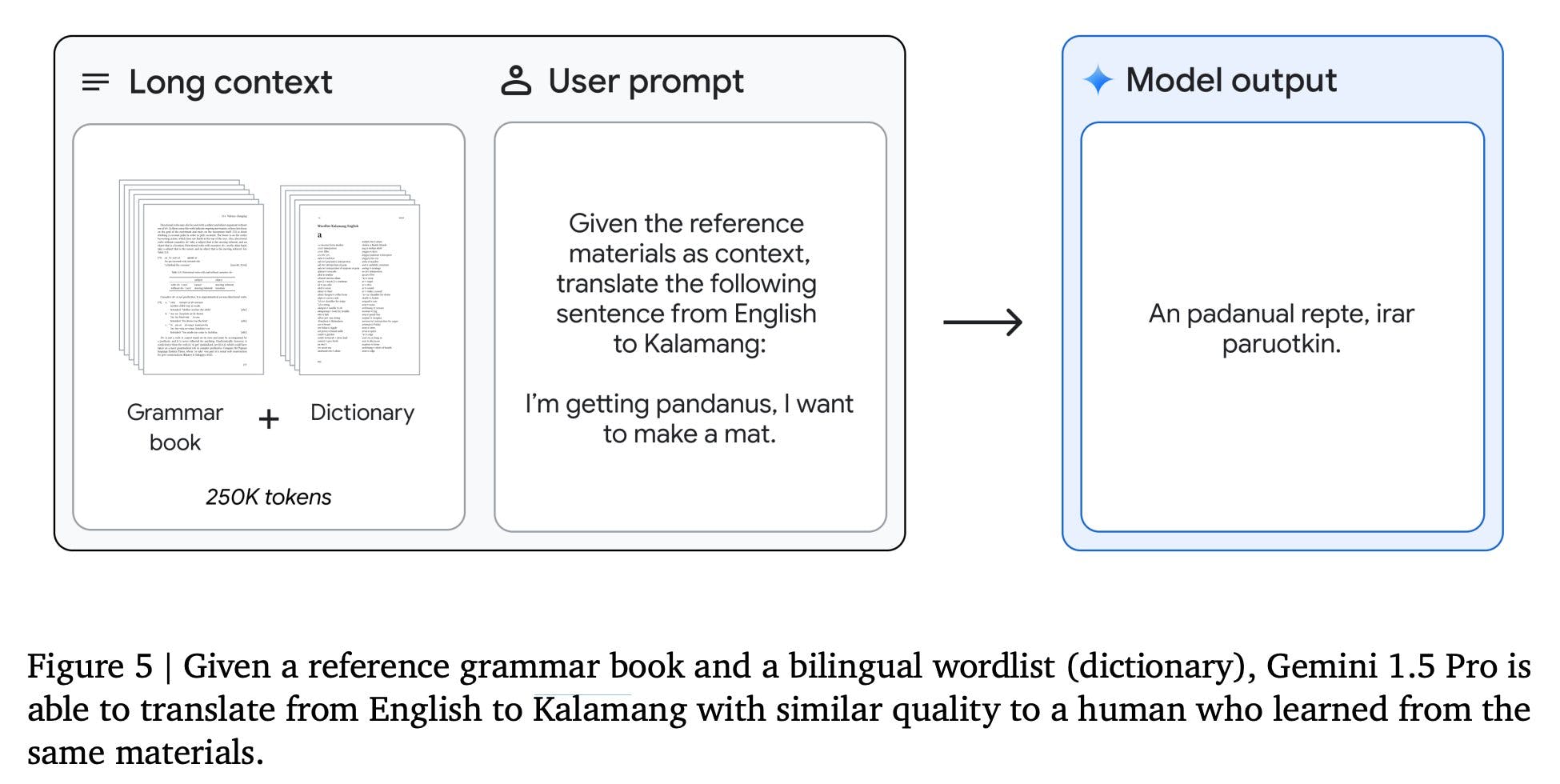
Prompt In-Context Learning and the Machine Translation from One Book (MTOB) Benchmark
Gemini 1.5 Pro can adapt and generate accurate responses based on minimal instruction. This capability is especially evident in complex tasks requiring understanding nuanced instructions or learning new concepts from a limited amount of information in the prompt.
Gemini 1.5 Pro's in-context learning capabilities show its performance on the challenging Machine Translation from One Book (MTOB) benchmark. This benchmark tests the model's ability to learn to translate a new language from a single source of instructional material.
In the MTOB benchmark, Gemini 1.5 Pro was tasked with translating between English and Kalamang, a language with a limited online presence and fewer than 200 speakers. Despite these challenges, the report showed that Gemini 1.5 Pro achieved translation quality comparable to that of human learners with the same instructional materials.
This underscores the model's potential to support language learning and translation for underrepresented languages, opening new avenues for research and application in linguistics and beyond.
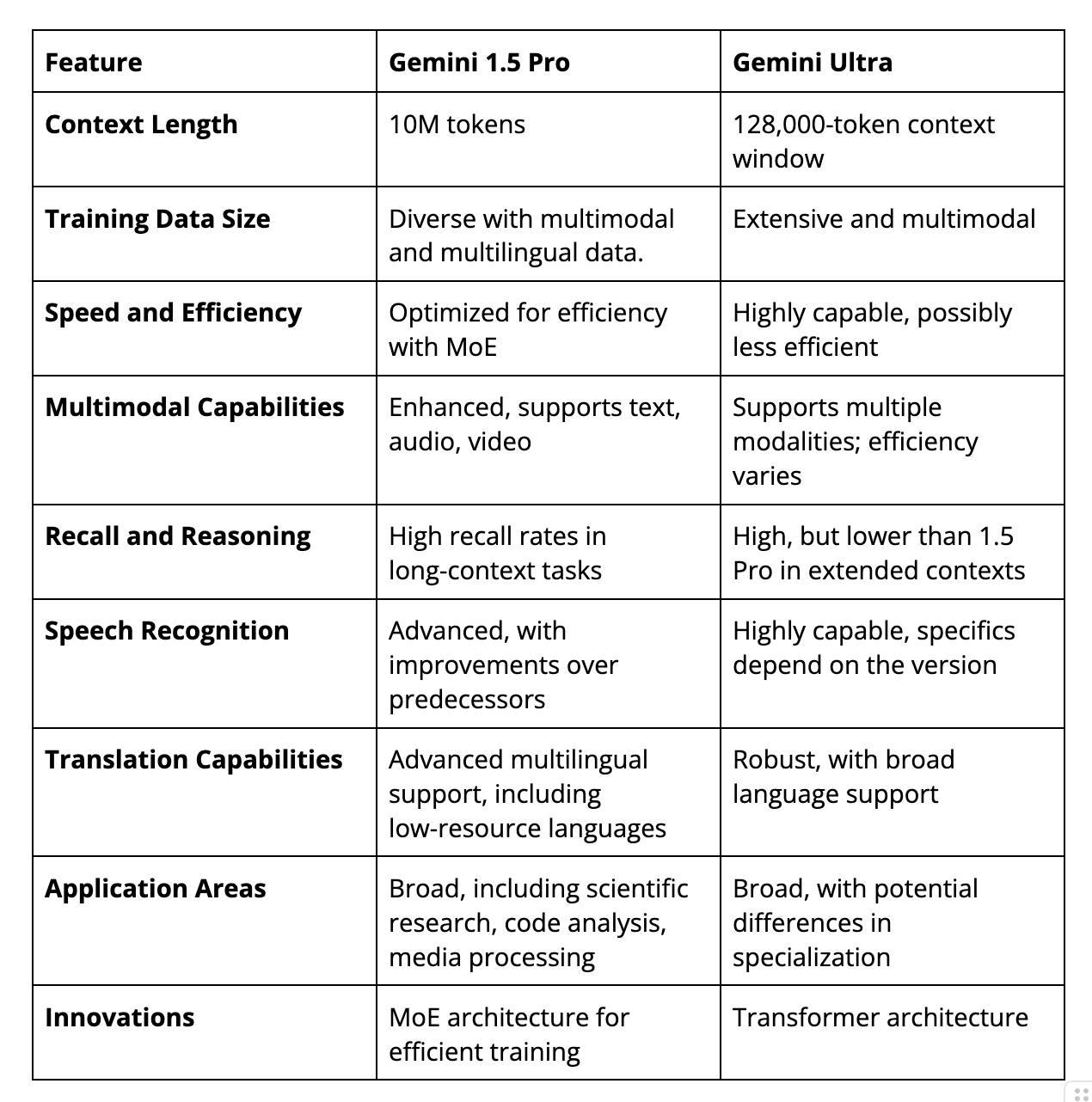
Gemini 1.5 Pro Vs. Gemini Ultra
While Gemini 1.5 Pro (2024) and Gemini Ultra (2023) are at the forefront of AI research and application, Gemini Pro 1.5 introduces several key advancements that differentiate it from Gemini Ultra.
The table below provides an overview and comparison of both models.
Use Cases
Analyzing Lengthy Videos
Analyzing videos is another great capability brought by the fact that Gemini models are naturally multimodal, and this becomes even more compelling with long contexts. In the technical report, Gemini 1.5 Pro was able to analyze movies, like Buster Keaton’s silent 45-minute “Sherlock Jr.” movie. Using one frame per second, the researchers turned the movie into an input context of 684k tokens.
The model can then answer fairly complex questions about the video content, such as: “Tell me some key information from the piece of paper that is removed from the person’s pocket and the timecode of that moment.” Or, a very cursory line drawing of something that happened, combined with “What is the timecode when this happens?”

Gemini 1.5 analyzing and reasoning over the 45-minute “Sherlock Jr.” movie
You can see this interaction here:
Multimodal prompting with a 44-minute movie
Navigating Large and Unfamiliar Codebases
As another code-related example, imagine you’re unfamiliar with a large codebase and want the model to help you understand the code or find where a particular functionality is implemented. In another example, the model can ingest an entire 116-file JAX code base (746k tokens) and help users identify the specific spot in the code that implements the backward pass for auto differentiation.
It’s easy to see how the long context capabilities can be invaluable when diving into an unfamiliar code base or working with one you use daily.
According to a technical lead, many Gemini team members have been finding it very useful to use Gemini 1.5 Pro’s long context capabilities on our Gemini code base.
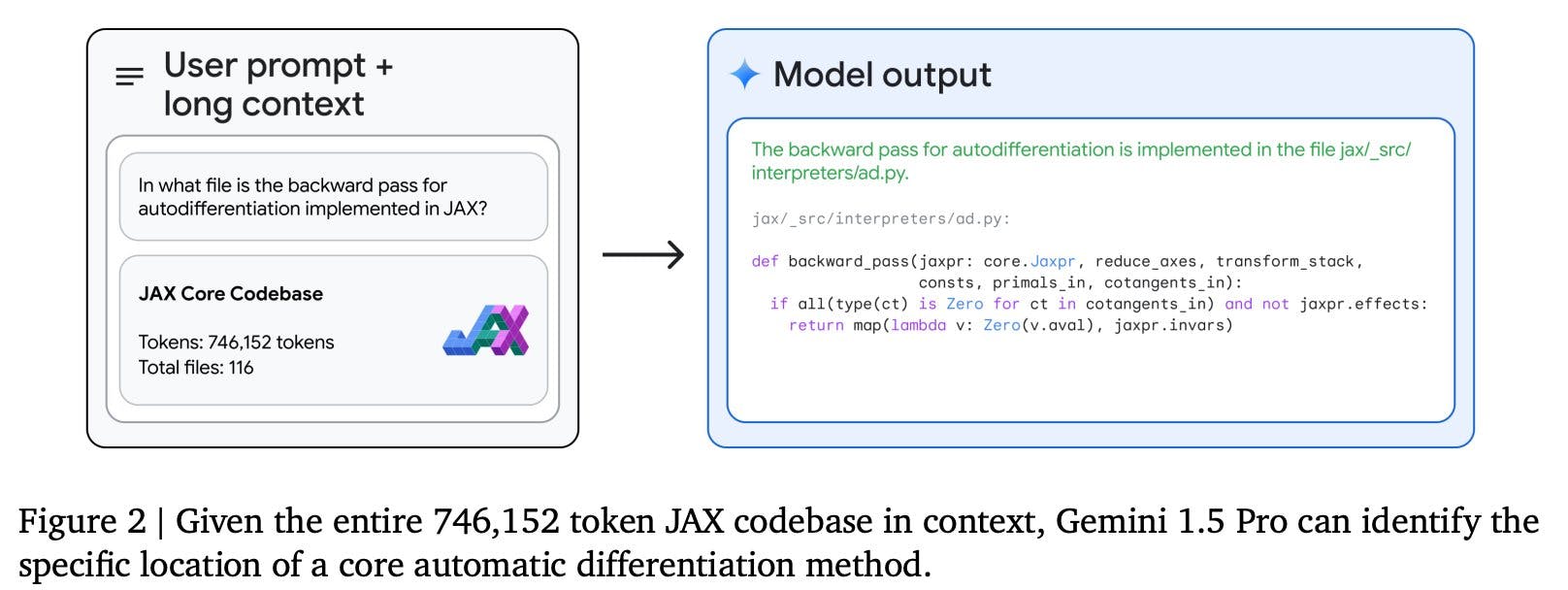
Gemini 1.5 navigating large and unfamiliar codebases
What’s Next?
According to a Google blog post, Gemini 1.5 Pro is currently in private preview, and its general availability with a standard 128,000-token context window will come later. Developers and enterprise customers can sign up to try Gemini 1.5 Pro with a context window of up to an experimental 1 million tokens via AI Studio and Google Vertex AI to upload hundreds of pages of text, entire code repos, and long videos and let Gemini reason across them.
That’s all for now. In the meantime, check out our resources on multimodal AI:
Frequently asked questions
It performs better than Gemini 1.0 Pro and 1.0 Ultra on text evaluations but worse than 1.0 Ultra for audio and vision tasks.
As of February 15, 2024, developers + customers can sign up for the limited Private Preview to try out 1.5 Pro with the experimental 1 million token context window for developers and customers to upload hundreds of pages of text, entire code repos, and long videos and let Gemini reason across them.
Upload multiple files and ask questions, query an entire code repository, and add full-length videos, among other long-context tasks.
Gemini 1.0 Ultra, Gemini 1.0 Pro, Gemini Nano, and Gemini 1.5 Pro.
Gemini 1.5 exemplifies Google's commitment to pioneering multimodal AI systems that are more efficient, scalable, and capable of understanding complex, real-world data across various domains.
The comparison between Gemini 1.5 and ChatGPT depends on specific use cases, capabilities, and context lengths each model can handle. Gemini 1.5, with its extended context windows, and efficient training, is designed for tasks requiring deep understanding across text, audio, and video.