Introduction to Multimodal Deep Learning

Product Manager at Encord
Humans perceive the world using the five senses (vision, hearing, taste, smell, and touch). Our brain uses a combination of two, three, or all five senses to perform conscious intellectual activities like reading, thinking, and reasoning. These are our sensory modalities.
In computing terminology, the equivalent of these senses are various data modalities, like text, images, audio, and videos, which are the basis for building intelligent systems. If artificial intelligence (AI) is to truly imitate human intelligence, it needs to combine multiple modalities to solve a problem.
Multimodal learning is a multi-disciplinary approach that can handle the heterogeneity of data sources to build computer agents with intelligent capabilities.
This article will introduce multimodal learning, discuss its implementation, and list some prominent use cases. We will discuss popular multimodal learning techniques, applications, and relevant datasets.

What is Multimodal Learning in Deep Learning?
Multimodal deep learning trains AI models that combine information from several types of data simultaneously to learn their unified data representations and provide contextualized results with higher predictive accuracy for complex AI tasks.
Today, modern AI architectures can learn cross-modal relationships and semantics from diverse data types to solve problems like image captioning, image and text-based document classification, multi-sensor object recognition, autonomous driving, video summarization, multimodal sentiment analysis, etc. For instance, in multimodal autonomous driving, AI models can process data from multiple input sensors and cameras to improve vehicle navigation and maneuverability.
The Significance of Multimodal Data in the Real World
Real-world objects generate data in multiple formats and structures, such as text, image, audio, video, etc. For example, when identifying a bird, we start by looking at the creature itself (visual information). Our understanding grows if it’s sitting on a tree (context). The identification is further solidified if we hear the bird chirping (audio input). Our brain can process this real-world information and quickly identify relationships between sensory inputs to generate an outcome.
However, present-day machine learning models are nowhere as complex and intricate as the human brain. Hence, one of the biggest challenges in building multimodal deep learning models is processing different input modalities simultaneously.
Each data type has a different representation. For example, images consist of pixels, textual data is represented as a set of characters or words, and audio is represented using sound waves. Hence, a multimodal learning architecture requires specialized data transformations or representations for fusing multiple inputs and a complex deep network to understand patterns from the multifaceted training data.
Let’s talk more about how a multimodal model is built.
Dissecting Multimodal Machine Learning
Although the multimodal learning approach has only become popular recently, there have been few experiments in the past. Srivastava and Salakhutdinov demonstrated multimodal learning with Deep Boltzmann Machines back in 2012. Their network created representations or embeddings for images and text data and fused the layers to create a single model that was tested for classification and retrieval tasks. Although the approach was not popular at the time, it formed the basis of many modern architectures.
Modern state-of-the-art (SOTA) multimodal architectures consist of distinct components that transform data into a unified or common representation.
Let’s talk about such components in more detail.
How Multimodal Learning Works in Deep Learning?
The first step in any deep learning project is to transform raw data into a format understood by the model. While this is easier for numerical data, which can be fed directly to the model, other data modalities, like text, must be transformed into word embeddings, i.e., similar words are represented as real-valued numerical vectors that the model can process easily.
With multimodal data, the various modalities have to be individually processed to generate embeddings and then fused. The final representation is an amalgamation of the information from all data modalities. During the training phase, multimodal AI models use this representation to learn the relationship and predict the outcomes for relevant AI tasks.
There are multiple ways to generate embeddings for multimodal data. Let’s talk about these in detail.
Input Embeddings
The traditional method of generating data embeddings uses unimodal encoders to map data to a relevant space. This approach uses embedding techniques like Word2Vec for natural language processing tasks and Convolutional Neural Networks (CNNs) to encode images. These individual encodings are passed via a fusion module to form an aggregation of the original information, which is then fed to the prediction model. Hence, understanding each modality individually requires algorithms that function differently. Also, they need a lot of computational power to learn representations separately.
Today, many state-of-the-art architectures utilize specialized embeddings designed to handle multimodal data and create a singular representation. These embeddings include
- Data2vec 2.0: The original Data2vec model was proposed by Meta AI’s Baevski, Hsu, et al. They proposed a self-supervised embedding model that can handle multiple modalities of speech, vision, and text. It uses the regular encoder-decoder architecture combined with a student-teacher approach. The student-encoder learns to predict masked data points while the teacher is exposed to the entire data. In December 2022, Meta AI proposed version 2.0 for the original framework, providing the same accuracy but 16x better performance in terms of speed.
- JAMIE: The Joint Variational Autoencoder for MultiModal Imputations and Embeddings is an open-source framework for embedding molecular structures. JAMIE solves the challenge of generating multi-modal data by taking partially matched samples across different cellular modalities. The information missing from certain samples is imputed by learning similar representations from other samples.
- ImageBind: ImageBind is a breakthrough model from Meta that can simultaneously fuse information from six modalities. It processes image and video data with added information such as text descriptions, color depth, and audio input from the image scene. It binds the entire sensory experience for the model by generating a single embedding consisting of contextual information from all six modalities.
- VilBERT: The Vision-and-Language BERT model is an upgrade over the original BERT architecture. The model consists of two parallel streams to process the two modalities (text and image) individually. The two streams interact via a co-attention transformer layer, i.e., one encoder transformer block for generating visual embeddings and another for linguistic embeddings.
While these techniques can process multimodal data, each data modality usually creates an individual embedding that must be combined through a fusion module.
Fusion Module
After feature extraction (or generating embeddings), the next step in a multimodal learning pipeline is multimodal fusion. This step combines the embeddings of different modalities into a single representation. Fusion can be achieved with simple operations such as concatenation or summation of the weights of the unimodal embeddings.
However, the simpler approaches do not yield appreciable results. Advanced architectures use complex modules like the cross-attention transformer. With its attention mechanism, the transformer module has the advantage of selecting relevant modalities at each step of the process. Regardless of the approach, the optimal selection of the fusion method is an iterative process. Different approaches can work better in different cases depending on the problem and data type.
Early, Intermediate, & Late Fusion
Another key aspect of the multimodal architecture design is deciding between early, intermediate, and late fusion.
- Early fusion combines data from various modalities early on in the training pipeline. The single modalities are processed individually for feature extraction and then fused together.
- Intermediate fusion, also known as feature-level fusion, concatenates the feature representations from each modality before making predictions. This enables joint or shared representation learning for the AI model, resulting in improved performance.
- Late fusion processes each modality through the model independently and returns individual outputs. The independent predictions are then fused at a later stage using averaging or voting. This technique is less computationally expensive than early fusion but does not capture the relationships between the various modalities effectively.
Popular Multimodal Datasets

Piano Skills Assessment Dataset Sample
A multimodal dataset consists of multiple data types, such as text, speech, and image. Some datasets may contain multiple input modalities, such as images or videos and their background sounds or textual descriptions. Others may contain different modalities in the input and output space, such as images (input) and their text captions (output) for image captioning tasks.
Some popular multimodal datasets include:
- LJ Speech Dataset: A dataset containing public domain speeches published between 1884 and 1964 and their respective 13,100 short audio clips. The audios were recorded between 2016-17 and have a total length of 24 hours. The LJ Speech dataset can be used for audio transcription tasks or speech recognition.
- HowTo100M: A dataset consisting of 136M narrated video clips sourced from 1.2M YouTube videos and their related text descriptions (subtitles). The descriptions cover over 23K activities or domains, such as education, health, handcrafting, cooking, etc. This dataset is more suitable for building video captioning models or video localization tasks.
- MultiModal PISA: Introduced in the Piano Skills Assessment paper, the MultiModal PISA dataset consists of images of the piano being played and relevant annotations regarding the pianist’s skill level and tune difficulty. It also contains processed audio and videos of 61 piano performances. It is suitable for audio-video classification and skill assessment tasks.
- LAION 400K: A dataset containing 413M Image-Text pairs extracted from the Common Crawl web data dump. The dataset contains images with 256, 512, and 1024 dimensions, and images are filtered using OpenAI’s CLIP. The dataset also contains a KNN index that clusters similar images to extract specialized datasets.
Popular Multimodal Deep Learning Models
Many popular multimodal architectures have provided ground-breaking results in tasks like sentiment analysis, visual question-answering, and text-to-image generation. Let’s discuss some popular model architectures that are used with multimodal datasets.
Stable Diffusion
Stable Diffusion (SD) is a widely popular open-source text-to-image model developed by Stability AI. It is categorized under a class of generative models called Diffusion Models.
The model consists of a pre-trained Variational AutoEncoder (VAE) combined with a U-Net architecture based on a cross-attention mechanism to handle various input modalities (text and images). The encoder block of the VAE transforms the input image from pixel space to a latent representation, which downsamples the image to reduce its complexity. The image is denoised using the U-Net architecture iteratively to reverse the diffusion steps and reconstruct a sharp image using the VAE decoder block, as illustrated in the image below.
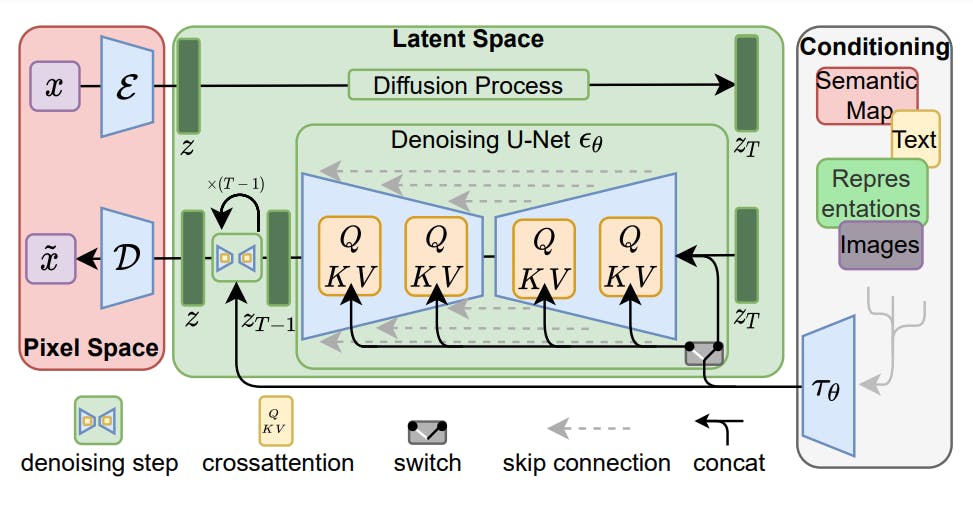
SD can create realistic visuals using short input prompts. For instance, if a user asks the model to create “A painting of the last supper by Picasso”, the model would create the following image or similar variations.

Image Created By Stable Diffusion Using Input Prompt “A painting of the last supper by Picasso.”
Or if the user enters the following input prompt: “A sunset over a mountain range, vector image.” The SD model would create the following image.

Image Created By Stable Diffusion Using Input Prompt “A sunset over a mountain range, vector image.”
Since SD is an open-source model, multiple variations of the SD architecture exist with different sizes and performances that fit different use cases.
Flamingo
Flamingo is a few-shot learning Visual Language Model (VLM) developed by DeepMind. It can perform various image and video understanding tasks such as scene description, scene understanding QA, visual dialog, meme classification, action classification, etc. Since the model supports few-shot learning, it can adapt to various tasks by learning from a few task-specific input-output samples.
The model consists of blocks of a pre-trained NFNet-F6 Vision Encoder that outputs a flattened 1D image representation. The 1D representation is passed to a Perceiver Resampler that maps these features to a fixed number of output visual tokens, as illustrated in the image below.
The Flamingo model comes in three size variants: Flamingo-3B, Flamingo-9B, and Flamingo-80B, and displays ground-breaking performance compared to similar SOTA models.
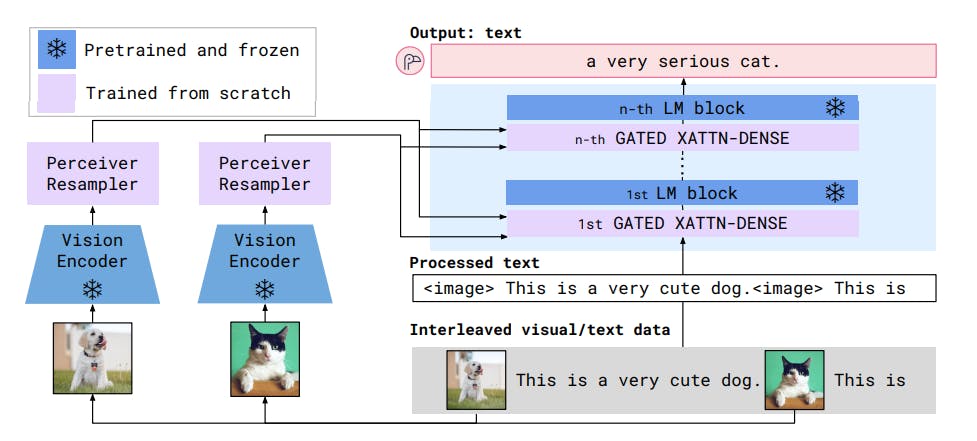
Overview of Flamingo Architecture
Meshed-Memory Transformer
The Meshed-Memory Transformer is an image captioning model based on encoder-decoder architecture. The architecture comprises memory-augmented encoding layers responsible for processing multi-level visual information and a meshed decoding layer for generating text tokens. The proposed model produced state-of-the-art results, topping the MS-COCO online leaderboard and beating SOTA models, including Up-Down and RFNet.
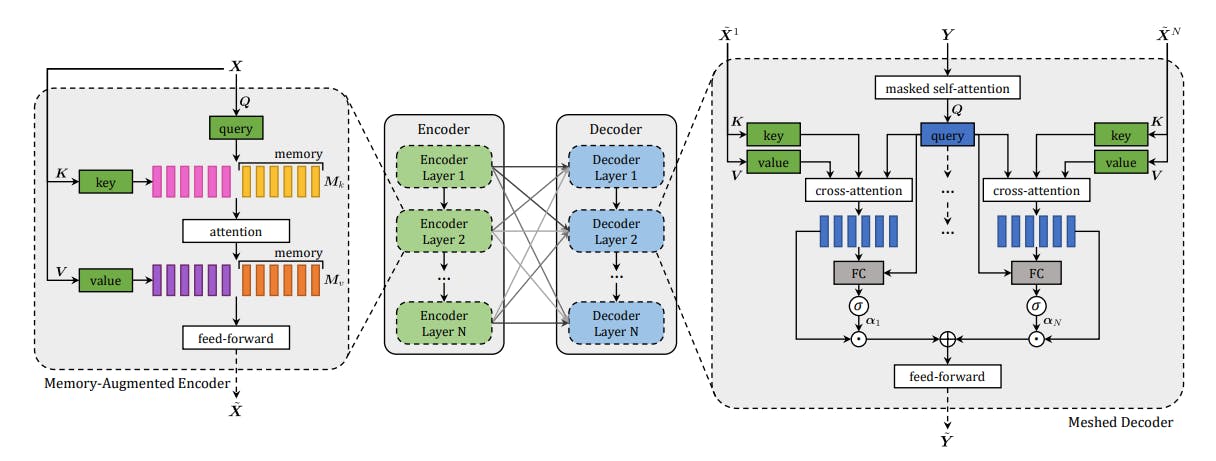
Architecture of Meshed Memory Transformer
Applications of Multimodal Learning
Multimodal deep neural networks have several prominent industry applications by automating media generation and analysis tasks. Let’s discuss some of them below.
Image Captioning
Image captioning is an AI model’s ability to comprehend visual information in an image and describe it in textual form. Such models are trained on image and text data and usually consist of an encoder-decoder infrastructure. The encoder processes the image to generate an intermediate representation, and the decoder maps this representation to the relevant text tokens.
Social media platforms use image captioning models to segregate images into categories and similar clusters. One notable benefit of image captioning models is that people with visual impairment can use them to generate descriptions of images and scenes. This technology becomes even more crucial considering the 4.8 billion people in the world who use social media, as it promotes accessibility and inclusivity across digital platforms

Results of an Image Captioning Model
Image Retrieval
Multimodal learning models can combine computer vision and NLP to link text descriptions to respective images. This ability helps with image retrieval in large databases, where users can input text prompts and retrieve matching images. For instance, OpenAI’s CLIP model provides a wide variety of image classification tasks using natural language text available on the internet. As a real-world example, many modern smartphones provide this feature where users can type prompts like “Trees” or “Landscape” to pull up matching images from the gallery.
Visual Question Answering (VQA)
Visual QA improves upon the image captioning models and allows the model to learn additional details regarding an image or scenario. Instead of generating a single description, the model can answer questions regarding the image iteratively. VQA has several helpful applications, such as allowing doctors to better understand medical scans via cross-questioning or as a virtual instructor to enable visual learning process for students.
Text-to-Image Models
Image generation from text prompts is a popular generative AI application that has already found several use cases in the real world. Models like DALL.E 2, Stable Diffusion, and Midjourney can generate excellent images from carefully curated text prompts. Social media creators, influencers, and marketers are extensively utilizing text-to-image models to generate unique and royalty-free visuals for their content. These models have enhanced the speed and efficiency of the content and art generation process. Today, digital artists can create highly accurate visuals within seconds instead of hours.

Images Generated Using Stable Diffusion Using Various Input Prompts
Text-to-Sound Generation
Text-to-sound generation models can be categorized into speech and music synthesis. While the former can create a human speech that dictates the input text prompt, the latter understands the prompt as a descriptor and generates a musical tune. Both auditory models work on similar principles but have distinctly different applications.
Speech synthesis is already used to generate audio for social media video content. It can also help people with speech impairment. Moreover, artists are using text-to-sound models for AI music generation. They can generate music snippets quickly to add to their creative projects or create complete songs.
For instance, an anonymous artist named Ghostwriter977 on Twitter recently submitted his AI-generated track “Heart on My Sleeve” for Grammy awards. The song sparked controversy for resembling the creative work of two real artists, Drake and The Weeknd. Overall, such models can speed up the content generation process significantly and improve the time to market for various creative projects.
Emotion Recognition
A multimodal emotion recognition AI model grasps various audiovisual cues and contextual information to categorize a person’s emotions. These models analyze features like facial expressions, body language, voice tone, spoken words, and any other contextual information, such as the description of any event. All this knowledge helps the model understand the subject’s emotions and categorize them accordingly.
Emotion recognition has several key applications, such as identifying anxiety and depression in patients, conducting customer analysis, and recognizing whether a customer is enjoying the product. Furthermore, it can also be a key component for building empathetic AI robots, helping them understand human emotions and take necessary action.
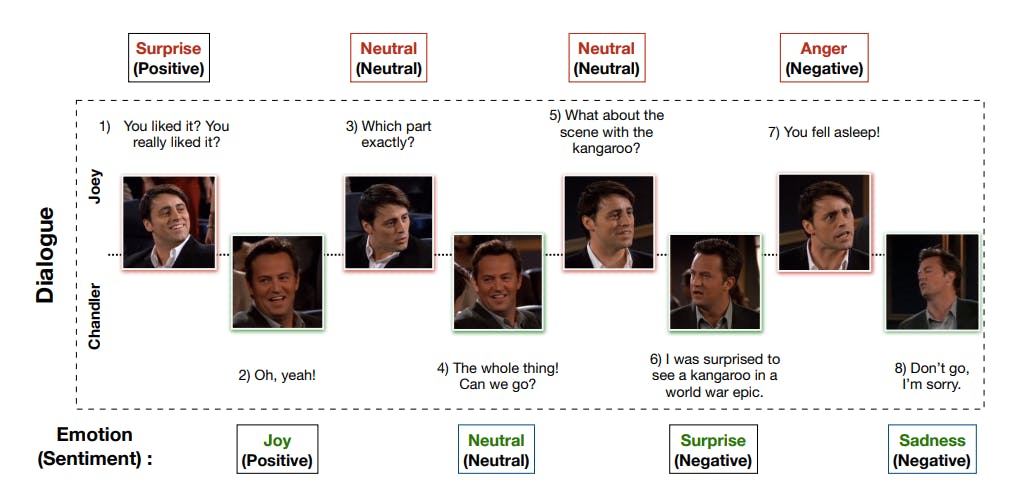
Different Emotions of Speakers in a Dialogue
Multimodal Learning: Challenges & Future Research
While we have seen many breakthroughs in multimodal learning, it is still nascent. Several challenges remain to be solved. Some of these key challenges are:
- Training time: Conventional deep learning models are already computationally expensive and take several hours to train. With multimodal, the model complexity is taken up a notch with various data types and fusion techniques. Reportedly, it can take up to 13 days to train a Stable Diffusion model using 256 A100 GPUs. Future research will primarily focus on generating efficient models that require less training and lower costs.
- Optimal Fusion Techniques: Selecting the correct fusion technique is iterative and time-consuming. Many popular techniques cannot capture modality-specific information and fully replicate the complex relationships between the various modalities. Researchers are creating advanced fusion techniques to comprehend the complexity of multimodal data.
- Interpretability: Lack of interpretation plagues all deep learning models. With multiple complex hidden layers capturing data from various modalities, the confusion only grows. Explaining how a model can comprehend various modalities and generate accurate results is challenging. Though researchers have developed various explainable multimodal techniques, numerous open challenges exist, such as insufficient evaluation metrics, lack of ground truth, and generalizability issues that must be addressed to apply multimodal AI in critical scenarios.
Multimodal Learning: Key Takeaways
- Multimodal deep learning brings AI closer to human-like behavior by processing various modalities simultaneously.
- AI models can generate more accurate outcomes by integrating relevant contextual information from various data sources (text, audio, image).
- A multimodal model requires specialized embeddings and fusion modules to create representations of the different modalities.
- As multimodal learning gains traction, many specialized datasets and model architectures are being introduced. Notable multimodal learning models include Flamingo and Stable Diffusion.
- Multimodal learning has various practical applications, including text-to-image generation, emotion recognition, and image captioning.
- This AI field has yet to overcome certain challenges, such as building simple yet effective architectures to reduce training times and improve accuracy.

Frequently asked questions
Multimodal learning utilizes data from various modalities (text, images, audio, etc.) to train deep neural networks.
A popular example of multimodal learning is image captioning. It inputs an image and outputs a text description of the scene.
Multimodal deep learning allows the model to learn cross-modal relationships for better understanding. More information allows the model to make better-informed decisions.
An example of multimodal deep learning in NLP is text-to-image generation. In this case, text prompts are used to generate images.
Multimodal learning provides better context by combining information from various modalities, hence, better results from the model.
Uni-modal learning deals with a singular data type, while multimodal deals with various types of data.
Multimodal learning is advancing fast but has a few challenges to overcome. Researchers must develop more efficient multimodal architectures and better ways to fuse modality representations.
Emotion detection applications help detect depression and anxiety in patients, and visual question answering can help doctors understand medical scans.
Encord provides a unique multimodal platform that allows users to manage and annotate video, audio, text, and images all in one place. This means you can work with various file types, such as video podcasts alongside their transcriptions and audio files, simplifying the workflow and enhancing collaboration across different media formats.
Encord is designed to facilitate multimodal machine learning by allowing teams to annotate and manage data from various sources seamlessly. This capability is essential for projects that combine different types of data, such as images, text, and sensor data, especially in complex fields like healthcare and retail.
Encord provides a robust platform designed to handle annotation across various modalities, ensuring that teams can efficiently annotate text, images, and voice data. With features that enhance visibility and quality control, Encord helps organizations maintain high standards in their annotation outputs.
The multimodal capabilities of Encord's platform allow for integrated handling of various data types, including text, audio, and video. This versatility is crucial for projects that require comprehensive insights from different data sources, enhancing the quality of model training and evaluation.
Encord plays a crucial role in integrating multimodal models, such as vision and text transformers, to enhance model training. This integration helps in reducing errors and improving the overall performance of models by allowing for more sophisticated approaches to data labeling and feedback.
Encord supports a variety of annotation workflows tailored for multimodal applications, including those involving video, audio, and text. This flexibility allows teams to adapt their annotation processes to meet specific project needs, ensuring efficient collaboration and data management.
Encord provides robust capabilities for multimodal annotations, allowing users to work seamlessly with images, audio, and video content. The platform is designed to facilitate the annotation process across these various data types, improving efficiency and quality in model training.
Encord offers advanced multimodal annotation capabilities, enabling users to annotate images, videos, text files, and PDFs. This flexibility allows teams to engage with different data types using specialized features designed to streamline the annotation process.
Encord supports multimodal annotation by allowing users to correlate image data, such as engine damage pictures, with unstructured text inputs from field reports. This integration enables a more comprehensive understanding of data context during inspections.
Multimodal data is crucial in Encord's approach, as it allows for the integration of various data types to enhance model performance. By leveraging diverse data sources, Encord helps clients build more accurate and effective damage detection models.