A Complete Guide to Text Annotation

Product Manager at Encord
Have you ever considered the sources from which AI models acquire language? Or the extensive effort required to curate high-quality data to power today's sophisticated language systems?
By the end of the guide, you will be able to answer the following questions:
- What is text annotation?
- What are some types of text annotation?
- How is text annotation?
What is Text Annotation?
Traditionally, text annotation involves adding comments, notes, or footnotes to a body of text. This practice is commonly seen when editors review a draft, adding notes or useful comments (i.e. annotations) before passing it on for corrections.
In the context of machine learning, the term takes on a slightly different meaning. It refers to the systematic process of labeling pieces of text to generate a ground-truth. The labeled data ensures that a supervised machine learning algorithm can accurately interpret and understand the data.
What Does it Mean to Annotate Text?
In the data science world, annotating text is a process that requires a deep understanding of both the problem at hand and the data itself to identify relevant features and label them so. This can be likened to the task of labeling cats and dogs in several images for image classification.
In text classification, annotating text would mean looking at sentences and marking them, putting each in predefined categories; like labeling online reviews as positive or negative, or news clippings as fake or real.
More tasks, such as labeling parts of speech (like nouns, verbs, subjects, etc.), labeling key phrases or words in a text for named entity recognition (ner) or to summarize a long article or research paper in a few hundred words all come under annotating text.
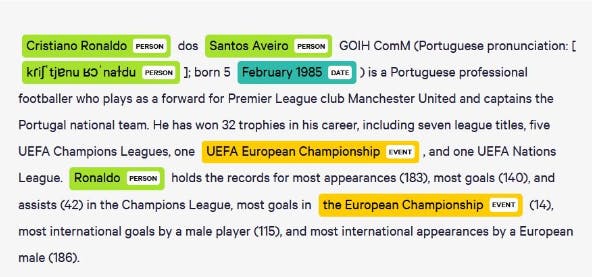
A Comprehensive Guide to Named Entity Recognition (NER) (Turing.com)
What are the Benefits of Text Annotation?
Doing what we described above enables a machine learning algorithm to identify different categories and use the data corresponding to these labels to learn what the data from each category typically looks like. This speeds up the learning task and improves the algorithm’s performance in the real world.
Learning without labels, while common today in NLP, is challenging as it is left to the algorithm to identify the nuances of the English language without any additional help and also recognize them when the model is put out in the real world. In text classification, for instance, a negative piece of text might be veiled in sarcasm—something that a human reader would instantly recognize, but an algorithm might just see the sarcastically positive words as just positive! Text annotations and labels are invaluable in these cases.
Large companies that are developing powerful language models today also, on the other hand, rely on text annotation for a number of important use cases. For social media companies, that includes flagging inappropriate comments or posts, online forums to flag bots and spammy content, or news websites to remove fake or low-quality pieces. Even apps for basic search engines and chatbots can be trained to extract information from their queries. Enhancing document workflows with a PDF editor equipped with document annotation capabilities can further support these tasks by allowing precise and clear marking of text segments.
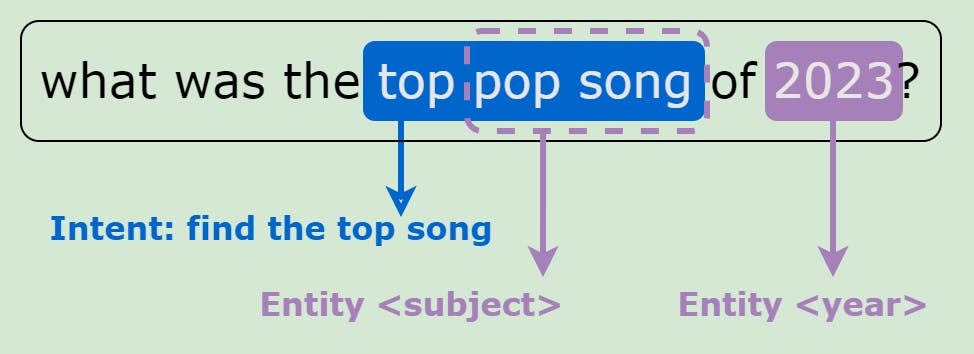
Image by Author
What are Some Types of Annotation Styles?
Since there are several tasks of varying nature for language interpretation in natural language processing, annotating and preparing the training data for each of them has a different objective. However, there are some standard approaches that cover the basic NLP tasks like classifying text and parts of text. While these may not cover generative text tasks like text summarization, they are important in understanding the different approaches to label a text.
Text Classification
Just as it sounds, a text classification model is meant to take a piece of text (sentence, phrase or paragraph) and determine what category it belongs to. Document classification involves the categorization of long texts, often with multiple pages. This annotation process involves the annotators reading every text sample and determining which one of the context-dependent predefined categories each sample belongs to.
Typical examples are binning news clippings into various topics, sorting documents based on their contents, or as simple as looking at movie plot summaries and mapping them to a genre (as shown in some examples below).

Genre Classification Dataset IMDb | Kaggle
Sentiment Annotation
Similar to text classification in process and strategy, the annotator plays a larger role in labeling a dataset for sentiment-related tasks. This task requires the annotator to interpret the text and look for the emotion and implicit context behind it—something that is not readily apparent to humans or machines when looking at the text.
Typical examples include sentiment analysis of a subject from social media data, analyzing customer feedback or product reviews, or gauging the shift in public opinion over a period of time by tracking historical texts.
Entity Annotation
Often understanding natural language extends to recalling or extracting important information from a given text, such as names, various numbers, topics of interest, etc. Annotating such information (in the form of words or phrases) is called entity annotation.
Annotators look for terms in a text of interest and classify them into predefined categories such as dates, countries, topics, names, addresses, zip codes, etc. A user can look up or extract only the pertinent information from large documents by using models trained on such a dataset to quickly label portions of the text. Semantic annotation involves a similar process, but the tags are often concepts and topics.
Keyphrase tagging (looking for topic-dependent keywords), NER (or named entity recognition) (covering a more extensive set of entities), and parts of speech tagging (understanding grammatical structure) come under entity annotation.
Intent Annotation
Another approach to annotating text is to direct the interpretation of a sentence towards an action. Typically used for chatbots, intent annotation helps create datasets that can train machine learning models to determine what the writer of the text wants. In the context of a virtual assistant, a message might be a greeting, an inquiry for information, or an actionable request. A model trained on a dataset where the text is labeled using intent annotation can classify each incoming message into a fixed category and simplify the conversation ahead.
Linguistic Annotation
This kind of text annotation focuses on how humans engage with the language—in pronunciation, phonetic sound, parts of speech, word meanings, and structure. Some of these are important in building a text-to-speech converter that creates human-sounding voices with different accents.
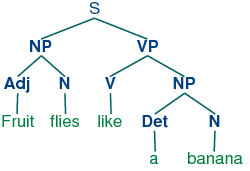
How is Text Annotated?
Now that we have established the various perspectives from which an annotator can look at their task, we can look at what a standard process of text annotation would be and how to annotate text for a machine learning problem. There is no all-encompassing playbook, but a well-defined workflow to go through the process step-by-step and a clear annotation guideline helps a ton.
What are Annotation Guidelines?
Text annotation guidelines are a set of rules and suggestions that act as a reference guide for annotators. An annotator must look at it and be able to understand the modeling objective and the purpose the labels would serve to that end. Since these guidelines dictate what is required of the final annotations, they must be set by the team familiar with the data and will use the annotations.
These guidelines can begin with one of the annotation techniques, or something customized that defines the problem and what to look for in the data. They must also define various cases, common and potentially ambiguous, the annotator might face in the data and actions to perform for each such problem.
For that purpose, they must also cover common examples found in the data and guidelines to deal with outliers, out-of-distribution samples, or other cases that might induce ambiguity while annotating. You can create an annotation workflow by beginning with a skeleton process, as shown below.
- Curate Annotation Guidelines
- Selecting a Labeling Tool
- Defining an Annotation Process
- Review and Quality Control
Curate Annotation Guidelines
- First, define the modeling problem (classification, generation, clustering, etc.) that the team is trying to tackle with the data and the expected outcome of the annotation process like the fixed set of labels/categories, data format, and exporting instructions.
- This can be extended to curating the actual guidelines that are comprehensive yet easy to revisit.
Selecting a Labeling Tool
- Getting the right text annotation tools can make all the difference between a laborious and menial task and a long but efficient process.
- Given the prevalence of text modeling, there are several open-source labeling tools available.
Below is an illustration of Doccano that shows how straightforward annotating intent detection and NER is!
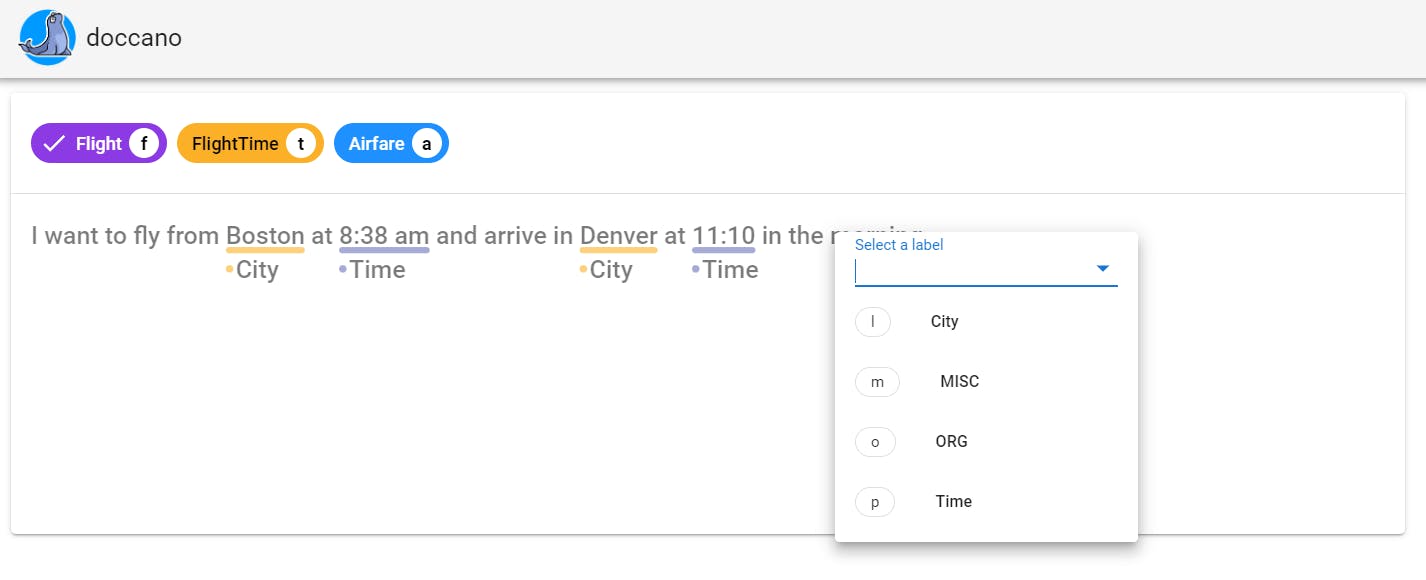
Open Source Annotation Tool for Machine Learning Practitioners
Defining an Annotation Process
- Once the logistics are in place, it is important to have a reproducible and error-free workflow that can accommodate multiple annotators and a uniform collection of labeled samples.
- Defining an annotation process includes organizing the data source and labeled data, defining the usage of the guidelines and the annotation tool, a step-by-step guide to performing the actual text annotation, the format of saving and exporting the annotations, and the review every labeled sample.
- Given the commonly large sizes of text data teams usually work with, ensuring a streamlined flow of incoming samples and outgoing labels and reviewing each sample (which might get challenging as one sample can be as big as a multi-page document) is essential.
Review and Quality Control
- Along with on-the-fly review, have a collective look at the labeled data periodically to avoid generic label errors or any bias in labeling that might have come in over time.
- It is also common to have multiple annotators label the same sample for consistency and to avoid any bias in interpretation, especially in cases where sentiment or contextual interpretation is crucial.
- To check for the bias and reliability of multiple human annotators, there are statistical measures that can be used to highlight undesirable trends. Comparison metrics such as Cohen’s kappa statistic measure how often two annotators agree with each other on the same set of samples, given the likelihood they would agree by chance. An example of interpreting Cohen’s kappa is shown below. Monitoring such metrics would flag disagreement and expose potential caveats in understanding the data and the problem.

Understanding Interobserver Agreement: The Kappa Statistic
Text Annotation: Key Takeaways
This article underlines the roles text annotation plays for natural language processing use cases and details how you can get started with data annotation for text. You saw how:
- high-quality data can significantly impact the training process for a machine learning model.
- different tasks require different approaches and perspectives to annotating a text corpus; some require understanding the meaning of the text, while others require grammar and structure.
- guidelines and choosing the right text annotation tool can simplify large-scale data annotation and improve reliability.
- using strategies such as multiple annotators, quality metrics, and more can help generate high-quality labels.

Frequently asked questions
Systems trained on labeled NER data are regularly used in the medical, judicial, or management industries to process the large quantities of unstructured text they face daily and convert them into electronic records. In the news and blogging space, topics are extracted from online articles, in the form of tags or categories, to sort and provide personalized suggestions to the readers.
In several noted cases, yes, when dealing with domain-specific data or limited data, the quality of annotations is important. The studyTools Impact on the Quality of Annotations for Chat Untangling notes that even the choice of labeling tool affects the quality. However, there are two sides to this debate, and other studies are worth looking at.
The first step would be using reliable data management systems to store and share the required data. These concerns are very real and worth investing some time in based on your infrastructure.
Encord offers a variety of annotation resources to help scale your projects efficiently. This includes access to a pool of expert annotators with specialized knowledge, as well as tools for curation and annotation that facilitate the management of large datasets. Our platform allows users to find quality data and annotate it at scale, catering to specific needs like clinical trial results and insurance coding.
Yes, Encord can manage complex annotation requirements. Users can tag related text segments and define relationships between different annotations to maintain context. This capability is particularly useful in scenarios where multiple pieces of information need to be linked together for clarity and accuracy.
Encord supports various data formats for annotation, including plain text emails and meeting transcripts. The platform can parse raw text from these sources and convert them into a suitable format for annotators, such as markdown, while stripping out unnecessary content like previous messages or signatures.
Encord's text annotation tool is built with advanced functionalities that streamline the annotation process, allowing teams to work collaboratively and efficiently. Users can benefit from sophisticated labeling capabilities that facilitate more accurate data preparation for machine learning models.
Encord offers a comprehensive annotation platform that supports both manual and automated annotation processes. This platform is designed to enhance the quality of training data generation, ensuring that teams can effectively qualify and validate perception stacks for various applications.
The annotator QA ontology can include various question types, such as enums for single-choice responses, checklists for multiple selections, and free text fields for detailed feedback. This variety helps to capture comprehensive quality metrics during the annotation process.
The Encord ontology is essential for structuring the labeling specifications of objects, attributes, and classifications within a project. It ensures that annotations are organized and clean, ultimately leading to higher quality data outputs that meet project needs.
Encord supports a variety of annotation methods, including manual and automated annotation processes. This flexibility allows teams to choose the best approach based on their data needs and project requirements, ensuring high-quality annotations for their datasets.
To annotate printed text in Encord, users can use the 'show text outline' feature to highlight the text. After selecting the relevant text, users can utilize hotkeys to create annotations around the identified areas, ensuring precise and efficient labeling.
To set up an annotation project in Encord, users need three essential components: a dataset to be annotated, an ontology that defines the classes for labeling, and a workflow that outlines the steps for the annotation process.