Google Launches Gemini, Its New Multimodal AI Model

For the past year, an artificial intelligence (AI) war has been going on between the tech giants OpenAI, Microsoft, Meta, Google Research, and others to build a multimodal AI system.
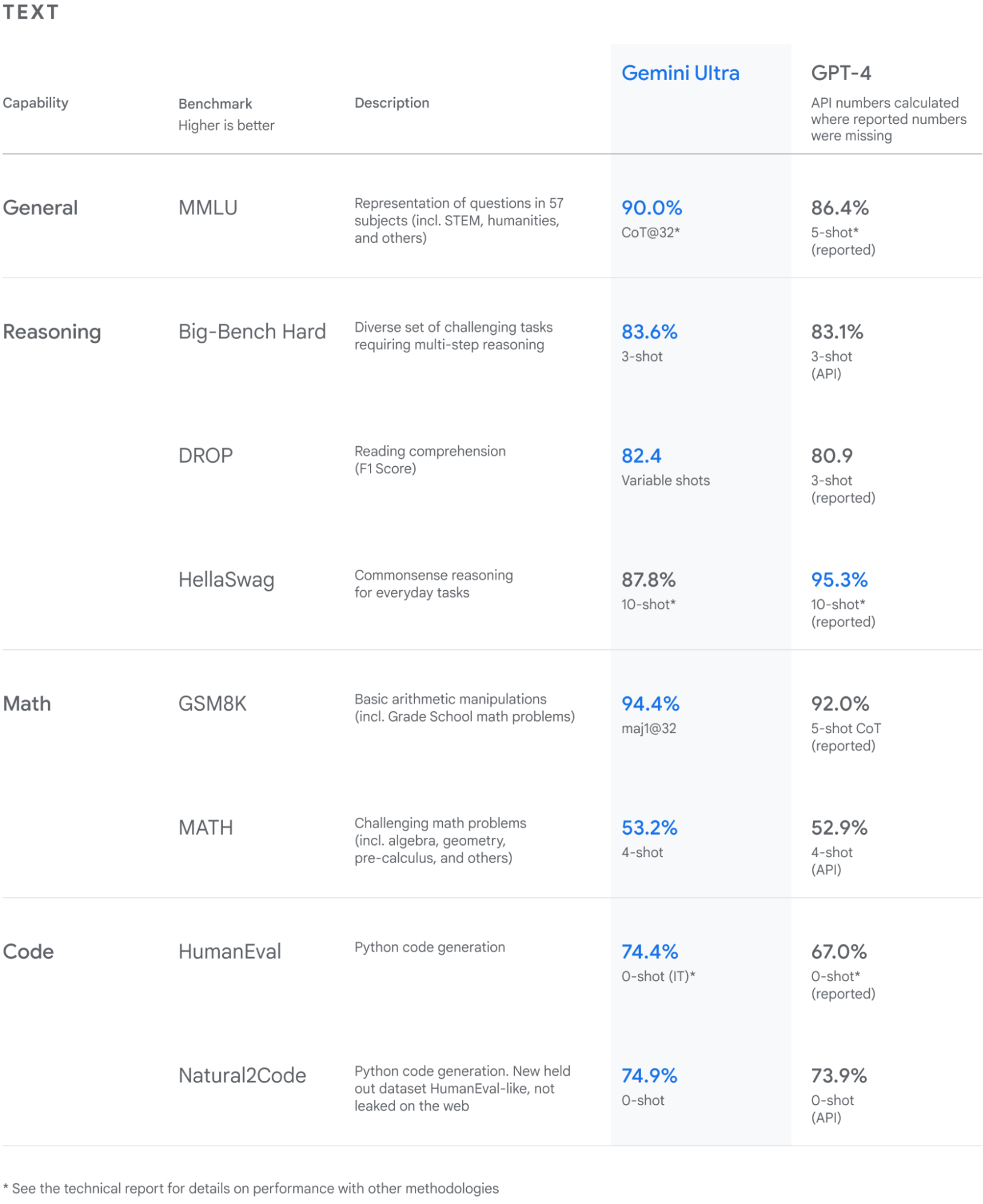
Alphabet and Google’s CEO Sundar Pichai has teamed up with DeepMind’s CEO Demis Hassabis has launch the much-anticipated generative AI system Gemini, their most capable and general artificial intelligence (AI) natively multimodal model—meaning it comprehends and generates texts, audio, code, video, and images. It outperforms OpenAI’s GPT-4 in general tasks, reasoning capabilities, math, and code. This launch follows Google’s very own LLM, PaLM 2 released in April, some of the family of models powering Google’s search engine.
What is Google Gemini?
The inaugural release, Gemini 1.0, represents a pinnacle in artificial intelligence, showcasing remarkable versatility and advancement. This generative AI model is well-equipped for tasks demanding the integration of multiple data types, designed with a high degree of flexibility and scalability to operate seamlessly across diverse platforms, ranging from expansive data centers to portable mobile devices.
The models demonstrate exceptional performance, exceeding current state-of-the-art results in numerous benchmarks. It is capable of sophisticated reasoning and problem-solving, even outperforming human experts in some scenarios.
Now, let's dive into the technical breakthroughs that underpin Gemini's extraordinary capabilities.
Proficiency in Handling - Text, Video, Code, Image, and Audio
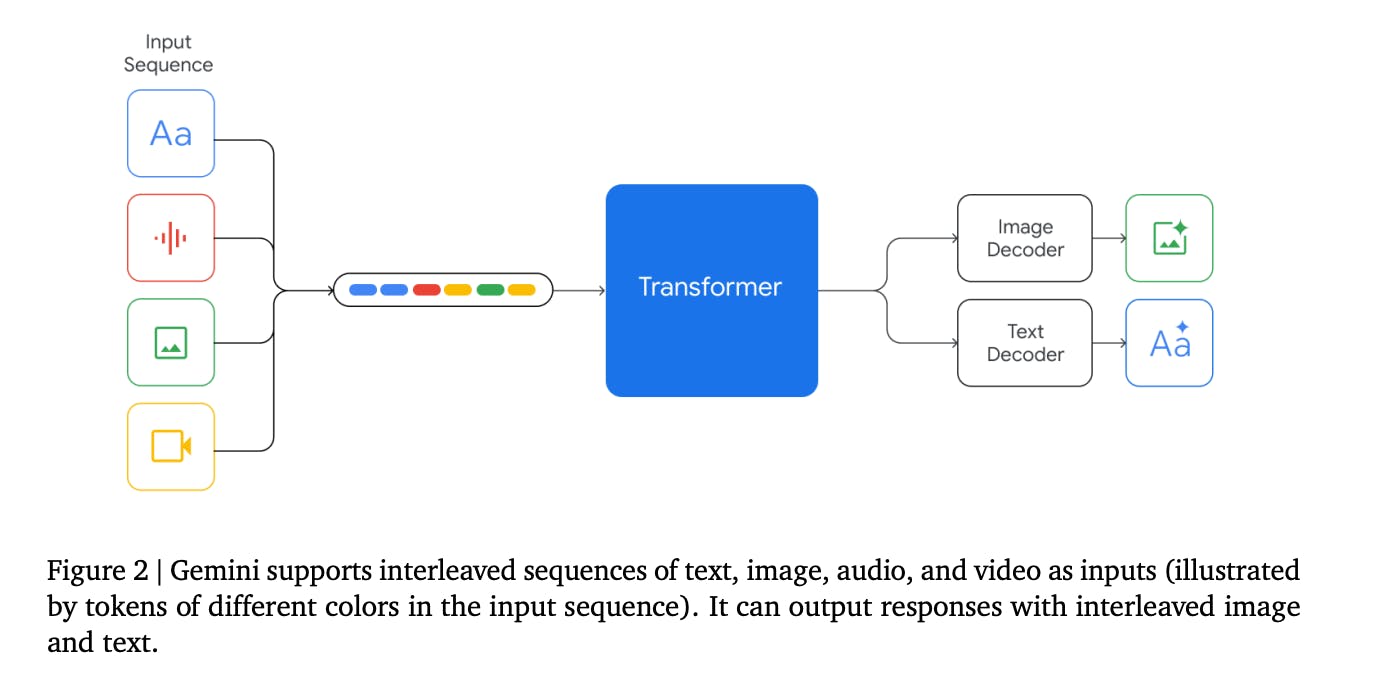
Gemini 1.0 is designed with native multimodal capabilities, as they are trained jointly across text, image, audio, and video. The joint training on diverse data types allows the AI model to seamlessly comprehend and generate content across diverse data types. It exhibits exceptional proficiency in handling:
Text
Gemini's prowess extends to advanced language understanding, reasoning, synthesis, and problem-solving in textual information. Its proficiency in text-based tasks positions it among the top-performing large language models (LLMs), outperforming inference-optimized models like GPT-3.5 and rivaling some of the most capable models like PaLM 2, Claude 2, etc.
Google Gemini: A Family of Highly Capable Multimodal Models
Gemini Ultra excels in coding, a popular use case of current Large Language Models (LLMs). Through extensive evaluation of both conventional and internal benchmarks, Gemini Ultra showcases its prowess in various coding-related tasks. In the HumanEval standard code-completion benchmark, where the model maps function descriptions to Python implementations, instruction-tuned Gemini Ultra correctly implements an impressive 74.4% of problems. Moreover, on a newly introduced held-out evaluation benchmark for Python code generation tasks, Natural2Code, ensuring no web leakage, Gemini Ultra attains the highest score of 74.9%. These results underscore Gemini's exceptional competence in coding scenarios, positioning it at the forefront of AI models in this domain.
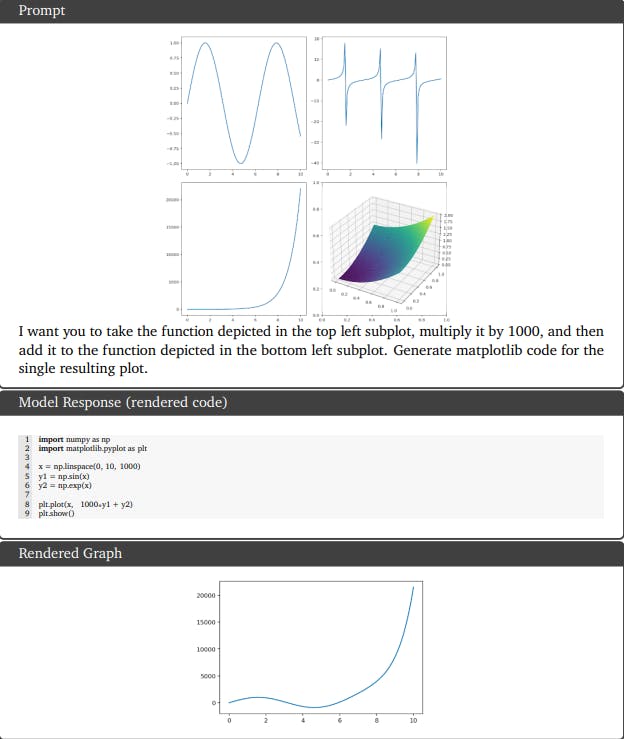
Multimodal reasoning capabilities applied to code generation. Gemini Ultra showcases complex image understanding, code generation, and instructions following.
Image
Gemini performs comparable to OpenAI’s GPT-4V or prior SOTA models in image understanding and generation. Gemini Ultra consistently outperforms the existing approaches even in zero-shot, especially for OCR-related image understanding tasks without any external OCR engine. It achieves strong performance across a diverse set of tasks, such as answering questions on natural images and scanned documents, as well as understanding infographics, charts, and science diagrams.
Gemini can output images natively without having to rely on an intermediate natural language description that can bottleneck the model’s ability to express images. This uniquely enables the model to generate images with prompts using the interleaved image and text sequences in a few-shot setting. For example, the user might prompt the model to design suggestions of images and text for a blog post or a website.

Google Gemini: A Family of Highly Capable Multimodal Models
Video Understanding
Gemini's capacity for video understanding is rigorously evaluated across held-out benchmarks. Sampling 16 frames per video task, Gemini models demonstrate exceptional temporal reasoning. In November 2023, Gemini Ultra achieved state-of-the-art results on few-shot video captioning and zero-shot video question-answering tasks, confirming its robust performance.

Google Gemini: A Family of Highly Capable Multimodal Models
The example above provides a qualitative example, showcasing Gemini Ultra's ability to comprehend ball-striking mechanics in a soccer player's video, demonstrating its prowess in enhancing game-related reasoning. These findings establish Gemini's advanced video understanding capabilities, a pivotal step in crafting a sophisticated and adept generalist agent.
Audio Understanding
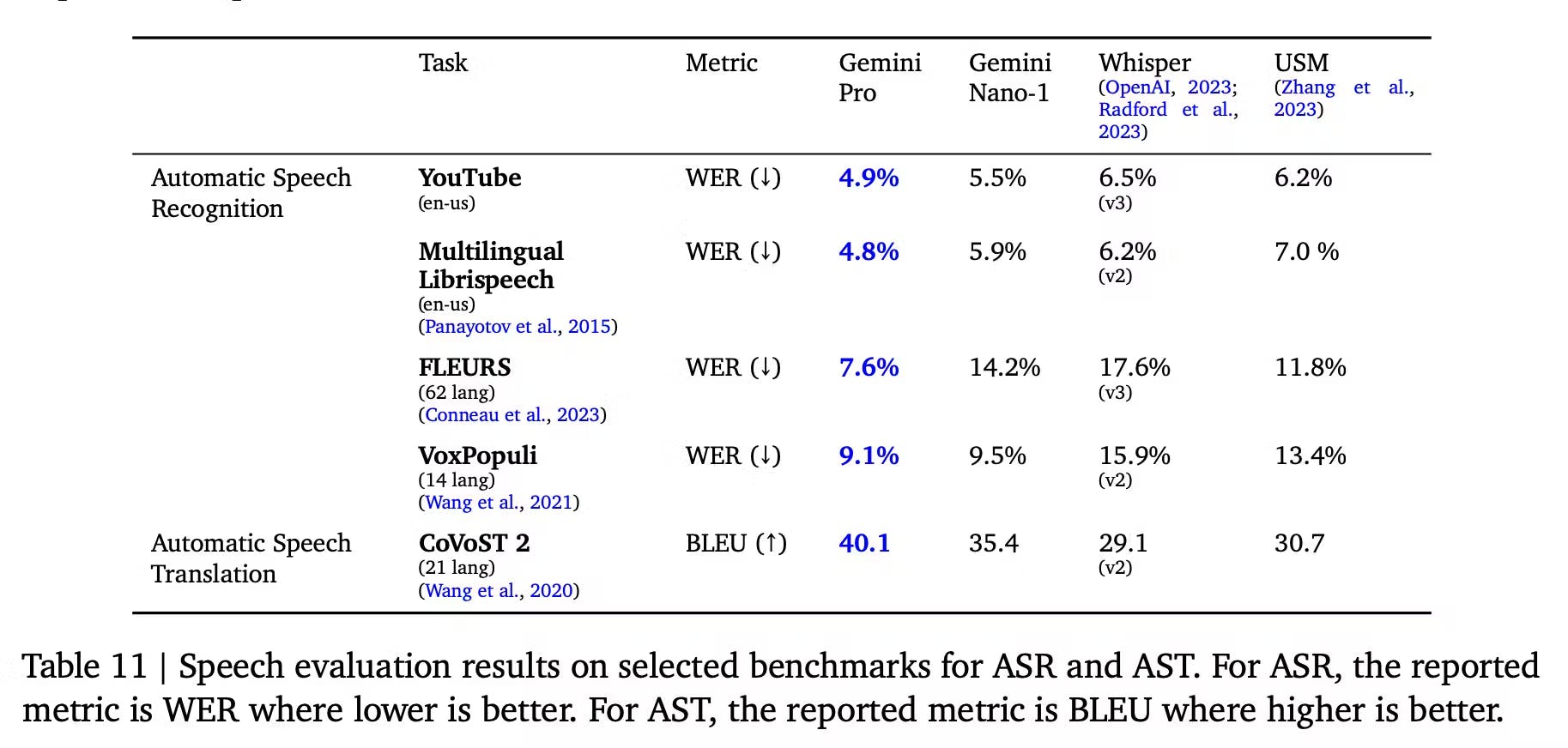
Gemini Nano-1 and Gemini Pro’s performance is evaluated for tasks like automated speed recognition (ASR) and automated speech translation (AST). The Gemini models are compared against the Universal Speech Model (USM) and Whisper across diverse benchmarks.
Google Gemini: A Family of Highly Capable Multimodal Models
Gemini Pro stands out significantly, surpassing USM and Whisper models across all ASR and AST tasks for both English and multilingual test sets. The FLEURS benchmark, in particular, reveals a substantial gain due to Gemini Pro's training with the FLEURS dataset, outperforming its counterparts. Even without FLEURS, Gemini Pro still outperforms Whisper with a WER of 15.8. Gemini Nano-1 also outperforms USM and Whisper on all datasets except FLEURS. While Gemini Ultra's audio performance is yet to be evaluated, expectations are high for enhanced results due to its increased model scale.
Triads of Gemini Model
The model comes in three sizes, with each size specifically tailored to address different computational limitations and application requirements:
Gemini Ultra
The Gemini architecture enables efficient scalability on TPU accelerators, empowering the most capable model, the Gemini Ultra, to achieve state-of-the-art performance across diverse and complex tasks, including reasoning and multimodal functions.
Gemini Pro
An optimized model prioritizing performance, cost, and latency, excelling across diverse tasks. It demonstrates robust reasoning abilities and extensive multimodal capabilities.
Gemini Nano
Gemini Nano is the most efficient mode and is designed to run on-device. It comes in two versions: Nano-1 with 1.8B parameters for low-memory devices and Nano-2 with 3.25B parameters for high-memory devices. Distilled from larger Gemini models, it undergoes 4-bit quantization for optimal deployment, delivering best-in-class performance.
Now, let’s look at the technical capabilities of the Gemini models.
Technical Capabilities
Developing the Gemini models demanded innovations in training algorithms, datasets, and infrastructure. The Pro model benefits from scalable infrastructure, completing pretraining in weeks using a fraction of Ultra's resources. The Nano series excels in distillation and training, creating top-tier small language models for diverse tasks and driving on-device experiences Let’s dive into the technical innovations:
Training Infrastructure
Training Gemini models involved using Tensor Processing Units (TPUs), TPUv5e, and TPUv4, with Gemini Ultra utilizing a large fleet of TPUv4 accelerators across multiple data centers. Scaling up from the prior flagship model, PaLM-2, posed infrastructure challenges, necessitating solutions for hardware failures and network communication at unprecedented scales. The “single controller” programming model of Jax and Pathways simplified the development workflow, while in-memory model state redundancy significantly improved recovery speed on unplanned hardware failures. Addressing Silent Data Corruption (SDC) challenges at this scale involved innovative techniques such as deterministic replay and proactive SDC scanners.
Training Dataset
The Gemini models are trained on a diverse dataset that is both multimodal and multilingual, incorporating web documents, books, code, and media data. Utilizing the SentencePiece tokenizer, training on a large sample of the entire corpus enhances vocabulary and model performance, enabling efficient tokenization of non-Latin scripts. The dataset size for training varies based on model size, with quality and safety filters applied, including heuristic rules and model-based classifiers. Data mixtures and weights are determined through ablations on smaller models, with staged training adjusting the composition for optimal pretraining results.

Gemini’s Architecture
Although the researchers did not reveal complete details, they mention that the Gemini models are built on top of Transformer decoders with architecture and model optimization improvements for stable training at scale. The models are written in Jax and trained using TPUs. The architecture is similar to DeepMind's Flamingo, CoCa, and PaLI, with a separate text and vision encoder.
Google Gemini: A Family of Highly Capable Multimodal Models
Ethical Considerations
Gemini follows a structured approach to responsible deployment to identify, measure, and manage foreseeable downstream societal impacts on the models.
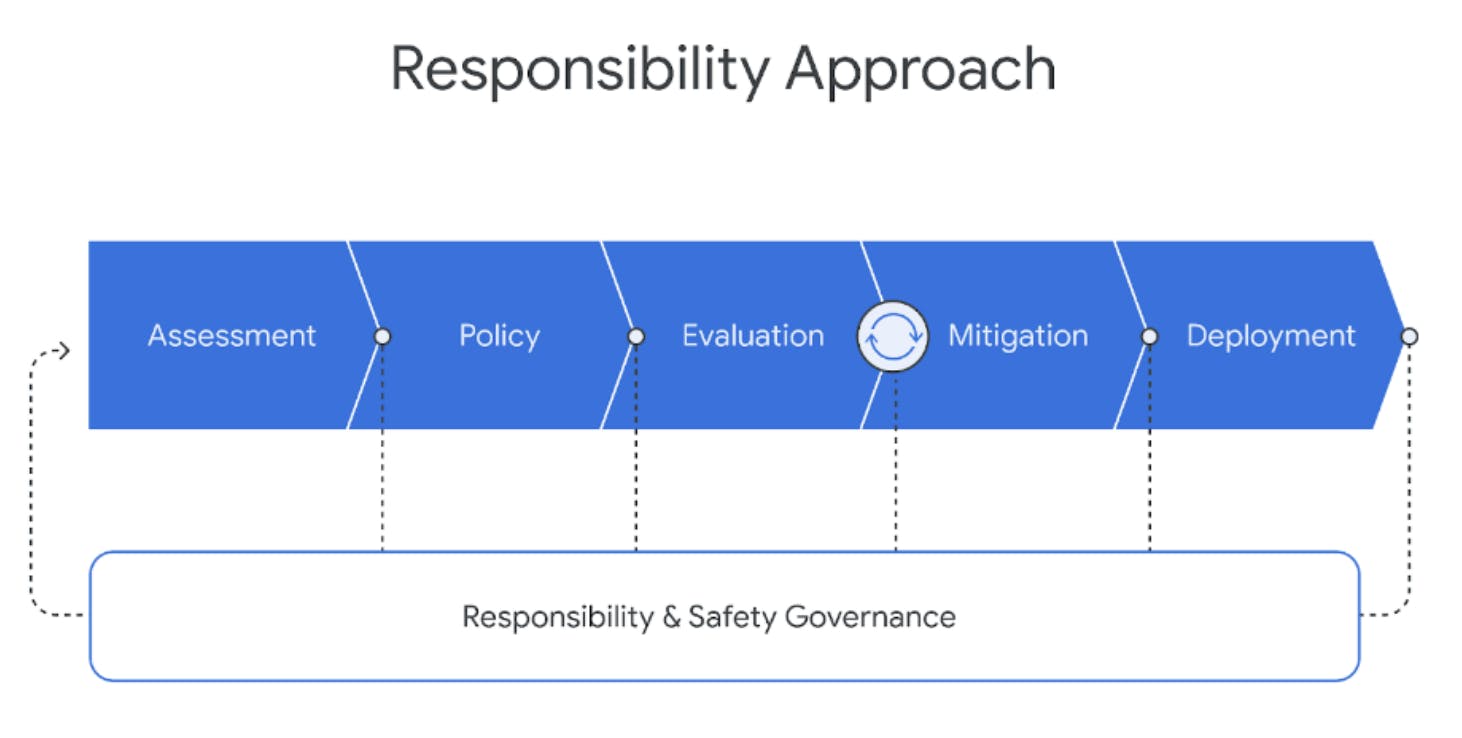
Google Gemini: A Family of Highly Capable Multimodal Models
Safety Testing and Quality Assurance
Within the framework of responsible development, Gemini places a strong emphasis on safety testing and quality assurance. Rigorous evaluation targets, set by Google DeepMind’s Responsibility and Safety Council (RSC) across key policy domains, including but not limited to child safety, underscore Gemini's dedication to upholding ethical standards. This commitment ensures that safety considerations are integral to the development process, guaranteeing that Gemini meets the highest quality and ethical responsibility standards.
Gemini Ultra is currently undergoing thorough trust and safety evaluations, including red-teaming conducted by trusted external parties. The model is further refined through fine-tuning and reinforcement learning from human feedback (RLHF) to ensure its robustness before being made widely available to users.
Potential Risks and Challenges
The creation of a multimodal AI model introduces specific risks. Gemini prioritizes the mitigation of these risks, covering areas such as factuality, child safety, harmful content, cybersecurity, biorisk, representation, and inclusivity. The impact assessments for Gemini encompass various aspects of the model's capabilities, systematically evaluating the potential consequences in alignment with Google’s AI Principles.
Does Gemini Suffer from Hallucinations?
Although Gemini's report does not explicitly reference tests involving hallucination, it details the measures taken to decrease the occurrence of such occurrences. Specifically, Gemini emphasizes instruction tuning to address this concern, concentrating on three essential behaviors aligned with real-world scenarios: attributions, closed-book response generation, and hedging.
Application & Performance Enhancements
Gemini Pro x Google BARD Chatbot
Google’s answer to ChatGPT, Bard is now powered by Gemini Pro. Bard is an experimental conversational AI service developed by Google, which was previously powered by LaMDA (Language Model for Dialogue Applications). It combines extensive knowledge with large language models to provide creative and informative responses, aiming to simplify complex topics and engage users in meaningful conversations.
Gemini Nano x Pixel8 Pro
Gemini Nano, designed for on-device applications, will be released as a feature update on the Pixel 8 Pro. This integration brings forth two enhanced features: Summarize in Recorder and Smart Reply in Gboard. Gemini Nano ensures sensitive data stays on the device, offering offline functionality. Summarize in Recorder provides condensed insights from recorded content without a network connection, while Smart Reply in Gboard, powered by Gemini Nano, suggests high-quality responses with conversational awareness.
Generative Search
Gemini AI will now be used for Search Generative Experience (SGE), with a 40% reduction in latency for English searches in the U.S. This enhancement accelerates the search process and elevates the quality of search results. Gemini's application in Search signifies a significant step toward a more efficient and refined generative search experience, showcasing a potential to redefine how users interact with information through Google Search.
Google Platform Integrations
In the coming months, Gemini is set to extend its footprint across various Google products and services, promising enhanced functionalities and experiences. Users can anticipate Gemini's integration in key platforms such as Search, Ads, Chrome, and Duet AI
What’s Next?
The prospects of Gemini 1.0, as highlighted in the report, are centered around the expansive new applications and use cases enabled by its capabilities. Let’s take a closer look at what could stem from these models.
- Complex image understanding: Gemini's ability to parse complex images such as charts or infographics opens new possibilities in visual data interpretation and analysis.
- Multimodal reasoning: The model can reason over interleaved images, audio, and text sequences and generate responses that combine these modalities. This is particularly promising for applications requiring the integration of various types of information.
- Educational applications: Gemini's advanced reasoning and understanding skills can be applied in educational settings, potentially enhancing personalized learning and intelligent tutoring systems.
- Multilingual communication: Given its proficiency in handling multiple languages, Gemini could greatly improve multilingual communication and translation services.
- Information summarization and extraction: Gemini's ability to process and synthesize large amounts of information makes it ideal for summarization and data extraction tasks, like prior state-of-the-art models (e.g. GPT-4)
- Creative applications: The model's potential for creative tasks, where it can generate novel content or assist in creative processes, is also significant.
Frequently asked questions
Gemini stands out for its native multimodal capabilities, excelling in machine learning tasks across text, video, code, images, and audio. The model's advanced reasoning, novel Chain of Thought (CoT) prompting, and efficient infrastructure contribute to exceptional performance. Gemini surpasses benchmarks and outperforms competitors.
Gemini was developed by a team of researchers at Google and DeepMind. The CEOs of Alphabet (Google's parent company) and Google, Sundar Pichai, and DeepMind, Demis Hassabis, were involved in launching the Gemini project.
Gemini Pro will be available for developers and enterprise customers via the Gemini API starting December 13th.
Gemini Pro will be accessible for integration into applications through Google AI Studio and Google Cloud Vertex AI. Android developers can access Gemini Nano for on-device tasks via AICore.
Gemini's Pro version falls slightly behind state-of-the-art (SOTA) Large Language Models (LLMs) in benchmarks like massive multitask language understanding (MMLU). Its comparison with ChatGPT reveals similar performance levels, indicating competitive capabilities but not surpassing the benchmarks set by the most advanced language models in the field.
The Gemini series is poised to compete with the GPT series, especially with its added audio integration. This feature propels Gemini into the multimodal space, which the GPT series may introduce as early as next year.
Gemini Pro is available on Google AI Studio, a web-based tool that helps quickly develop prompts. Gemini Ultra will only be available to select customers, developers, partners, and safety and responsibility experts for early experimentation and feedback before rolling it out to developers and enterprise customers in 2024. The Ultra version of the model will be charged to access the API.
The release timeline for Gemini Ultra involves completing extensive trust and safety checks, including red-teaming by external parties. Initially, it will be available for select customers, developers, partners, and safety experts for early experimentation and feedback. The broader release to developers and enterprise customers is planned for early next year.