Meta AI’s I-JEPA, Image-based Joint-Embedding Predictive Architecture, Explained

If you thought the AI landscape could not move any faster with Large Language Models and Generative AI, then think again! The next innovation in artificial intelligence is already here.
Meta AI unveiled Image-based Joint-Embedding Predictive Architecture (I-JEPA) this week, a computer vision model that learns like humans do.
This release is a meaningful first step towards the vision of Chief AI Scientist, Yann LeCun, to create machines that can learn internal models of how the world works so that they can accomplish difficult tasks and adapt to unfamiliar situations.
Before diving into the details of I-JEPA, let’s discuss self-supervised learning.

What is Self-Supervised Learning?
Self-supervised learning is an approach to machine learning that enables models to learn from unlabeled dataset. By leveraging self-generated labels through pretext tasks, such as contrastive learning or image inpainting, self-supervised learning unlocks the potential to discover meaningful patterns and representations. This technique enhances model performance and scalability across various domains.
There are two common approaches to self-supervised learning in computer vision: invariance-based methods and generative methods.
Invariance-based Methods
Invariance-based pre-training methods focus on training models to capture different views of an image by using techniques such as data augmentation and contrastive learning.
While these methods can produce semantically rich representations, they may introduce biases. Generalizing these biases across tasks requiring different levels of abstraction, such as image classification and instance segmentation, can be challenging.
Generative Methods
Using generative methods involves training models to generate realistic samples from a given distribution and indirectly learning meaningful representations in the process. Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs) are two examples of generative methods, where the models learn to generate images that resemble the training data distribution.
Generative methods may prioritize capturing low-level details and pixel-level accuracy, at the expense of higher-level semantic information. This drawback can make the learned representations less effective for tasks that require understanding complex semantics or reasoning of objects and scenes.
 💡 To learn more about self-supervised learning, read Self-supervised Learning Explained.
💡 To learn more about self-supervised learning, read Self-supervised Learning Explained. Joint-Embedding Architecture
Joint Embedding Architecture (JEA) is an architecture that learns to produce similar embeddings for compatible inputs and dissimilar embeddings for incompatible inputs. By mapping related inputs close together, it creates a shared representation space and facilitates tasks such as similarity comparison or retrieval.
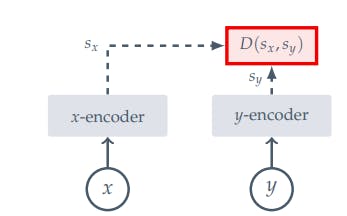
The main challenge with JEAs is representation collapse, where the encoder produces a constant output regardless of the input.
Generative Architecture
Generative architecture is a type of machine learning model or neural network that can generate new samples resembling the training data distribution, such as images or text. This architecture utilizes a decoder network and learns by removing or distorting elements in the input data, like erasing parts of an image, in order to capture the underlying patterns and predict the corrupted or missing pixels to produce realistic outputs.
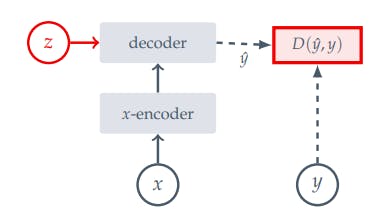
Generative methods aim to fill in all missing information and disregard the inherent unpredictability of the world. Consequently, these methods may make mistakes that a human would not, as they prioritize irrelevant details over capturing high-level predictable concepts.
Joint-Embedding Predictive Architecture
Joint Embedding Predictive Architecture (JEPA) is an architecture that learns to predict representations of different target blocks in an image from a single context block, using a masking strategy to guide the model toward producing semantic representations.
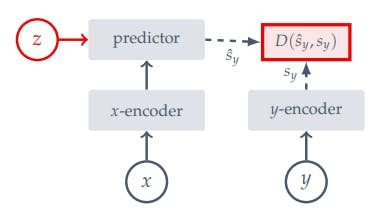
JEPAs focus on learning representations that predict each other when additional information is provided, rather than seeking invariance to data augmentations like JEAs. Unlike generative methods that predict in pixel space, JEPAs utilize abstract prediction targets, allowing the model to prioritize semantic features over unnecessary pixel-level details. This approach encourages the learning of more meaningful and high-level representations.
Watch the lecture by Yann LeCun on A Path Towards Autonomous Machine Learning where he explains the Joint Embedding Predictive Architecture. I-JEPA: Image-based Joint-Embedding Predictive Architecture
Image-based Joint Embedding Predictive Architecture (I-JEPA) is a non-generative approach for self-supervised learning from images. This aims to predict missing information in an abstract representation space. For example, given a single context block, the goal is to predict the representations of different target blocks within the same image. The target representations are computed using a learned target-encoder network, enabling the model to capture and predict meaningful features and structures.

💡Use your embeddings live in Encord Active. Try it here or get in touch for a demo. I-JEPA Core Design
The framework of Image-based Joint Embedding Predictive Architecture (I-JEPA) contains 3 blocks: context block, target block, and predictor.
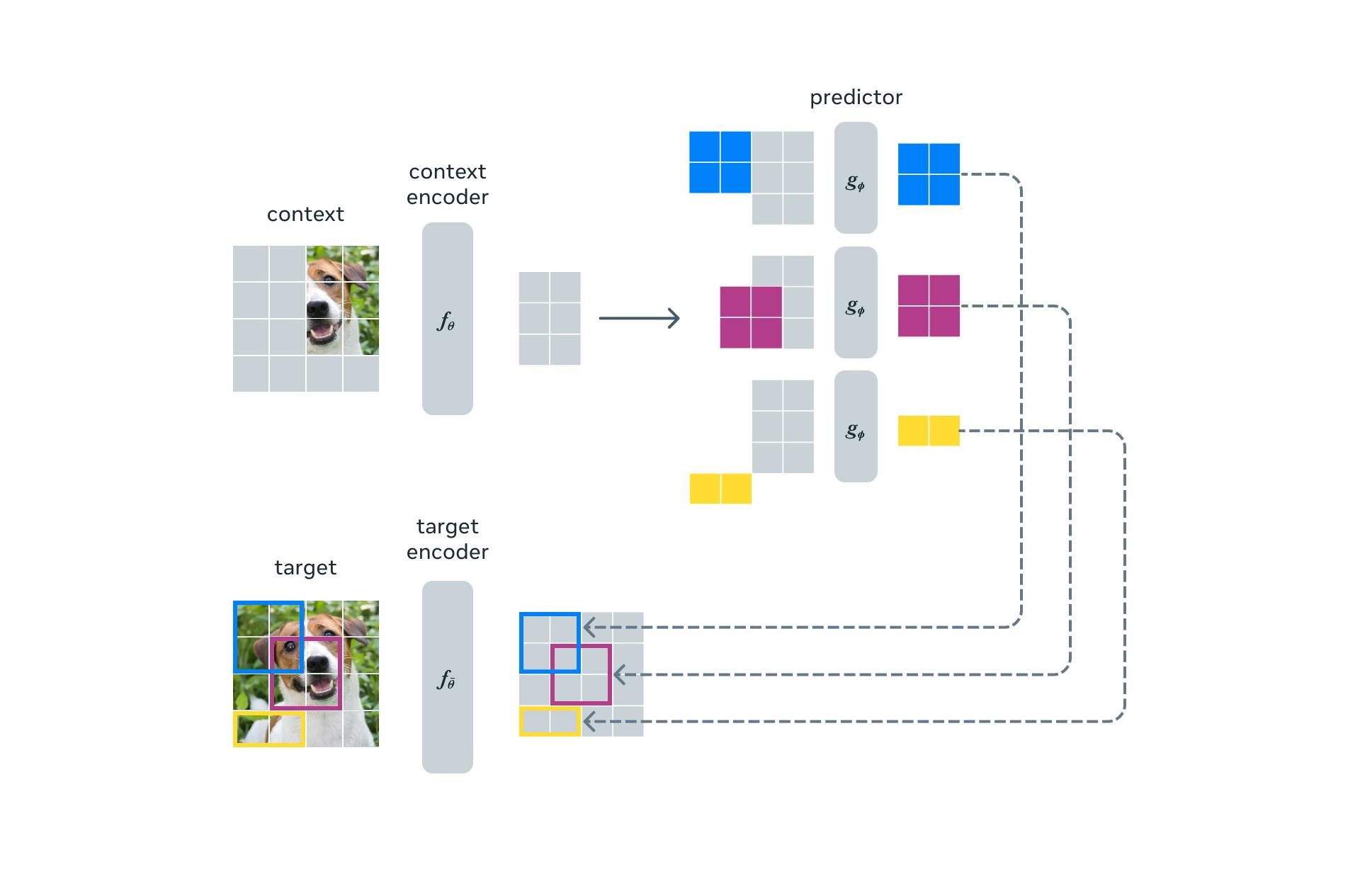
I-JEPA incorporates a multi-block masking strategy to promote the generation of semantic segmentations. This strategy emphasizes the significance of predicting adequately large target blocks within the image and utilizing an informative context block that is spatially distributed.

Context Block
I-JEPA uses a single context block to predict the representations of multiple target blocks within the same image. The context encoder is based on a Vision Transformer (ViT) and focuses on processing the visible context patches to generate meaningful representations.
Target Block
The target block represents the image blocks' representation and is predicted using a single context block. These representations are generated by the target encoder, and their weights are updated during each iteration of the context block using an exponential moving average algorithm based on the context weights. To obtain the target blocks, masking is applied to the output of the target encoder, rather than the input.

Prediction
The predictor in I-JEPA is a narrower version of the Vision Transformer (ViT). It takes the output from the context encoder and predicts the representations of a target block located at a specific position with the guidance of positional tokens.
The loss is the average L2 distance between the predicted patch-level representations and the target patch-level representations. The parameters of the predictor and the context encoder are learned through gradient-based optimization while the parameters of the target encoder are learned using the exponential moving average of the context-encoder parameters.
💡If you want to test it yourself, access the code and model checkpoints on GitHub. How does I-JEPA perform?
Predictor Visualizations
The predictor in I-JEPA captures spatial uncertainty within a static image, using only a partially observable context. It focuses on predicting high-level information rather than pixel-level details about unseen regions in the image.
A stochastic decoder is trained to convert the predicted representations from I-JEPA into pixel space. This enables visualizing how the model’s predictions translate into tangible pixel-level outputs. This evaluation demonstrates the model's ability to accurately capture positional uncertainty and generate high-level object parts with correct poses (e.g., the head of a dog or the front legs of a wolf) when making predictions within the specified blue box.

As illustrated in the above image, I-JEPA successfully learns high-level representations of object parts while preserving their localized positional information in the image.
Performance Evaluation
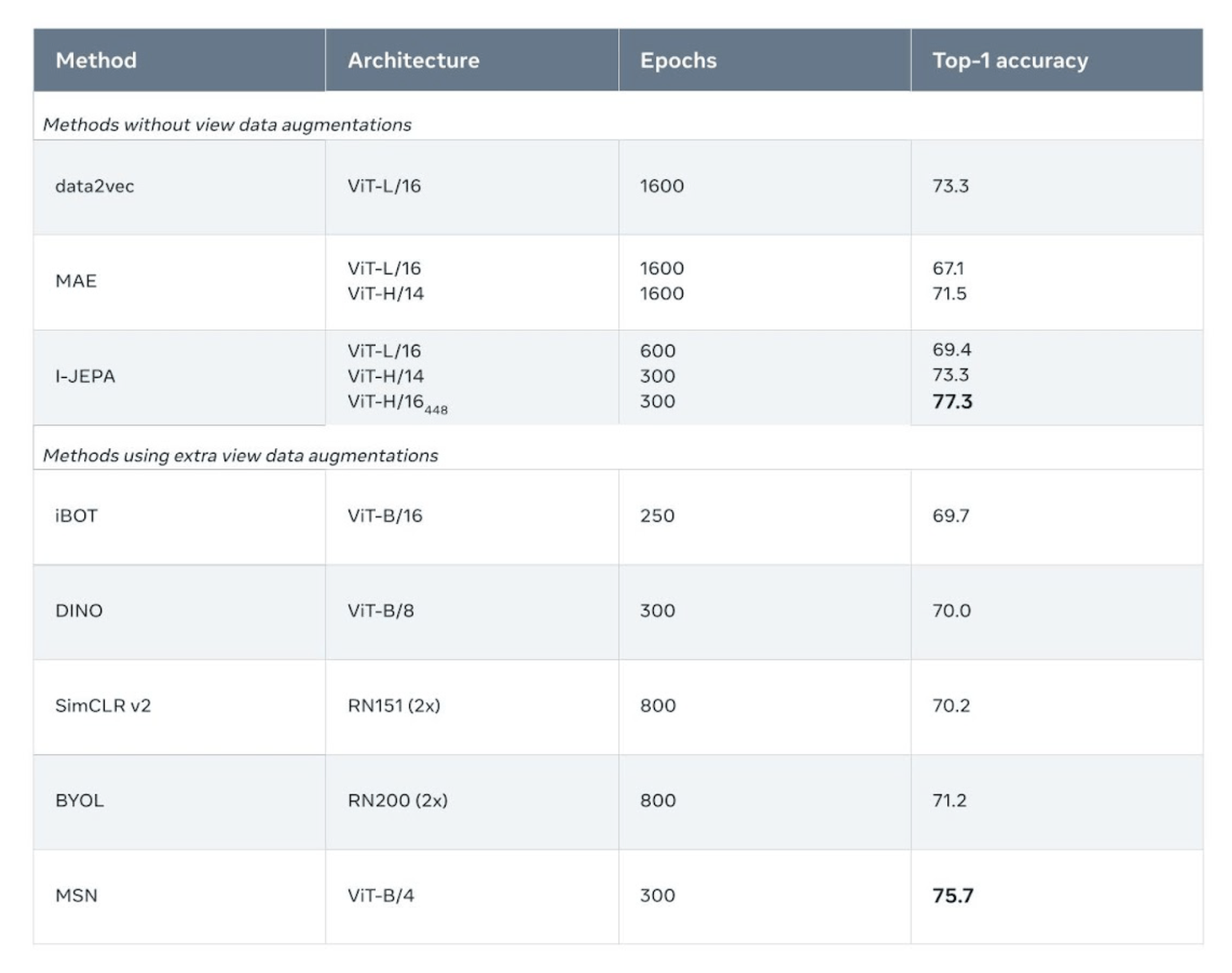
I-JEPA sets itself apart by efficiently learning semantic representations without using view augmentation. It outperforms pixel-reconstruction methods such as Masked Autoencoders (MAE) on ImageNet-1K linear probing and semi-supervised evaluation.
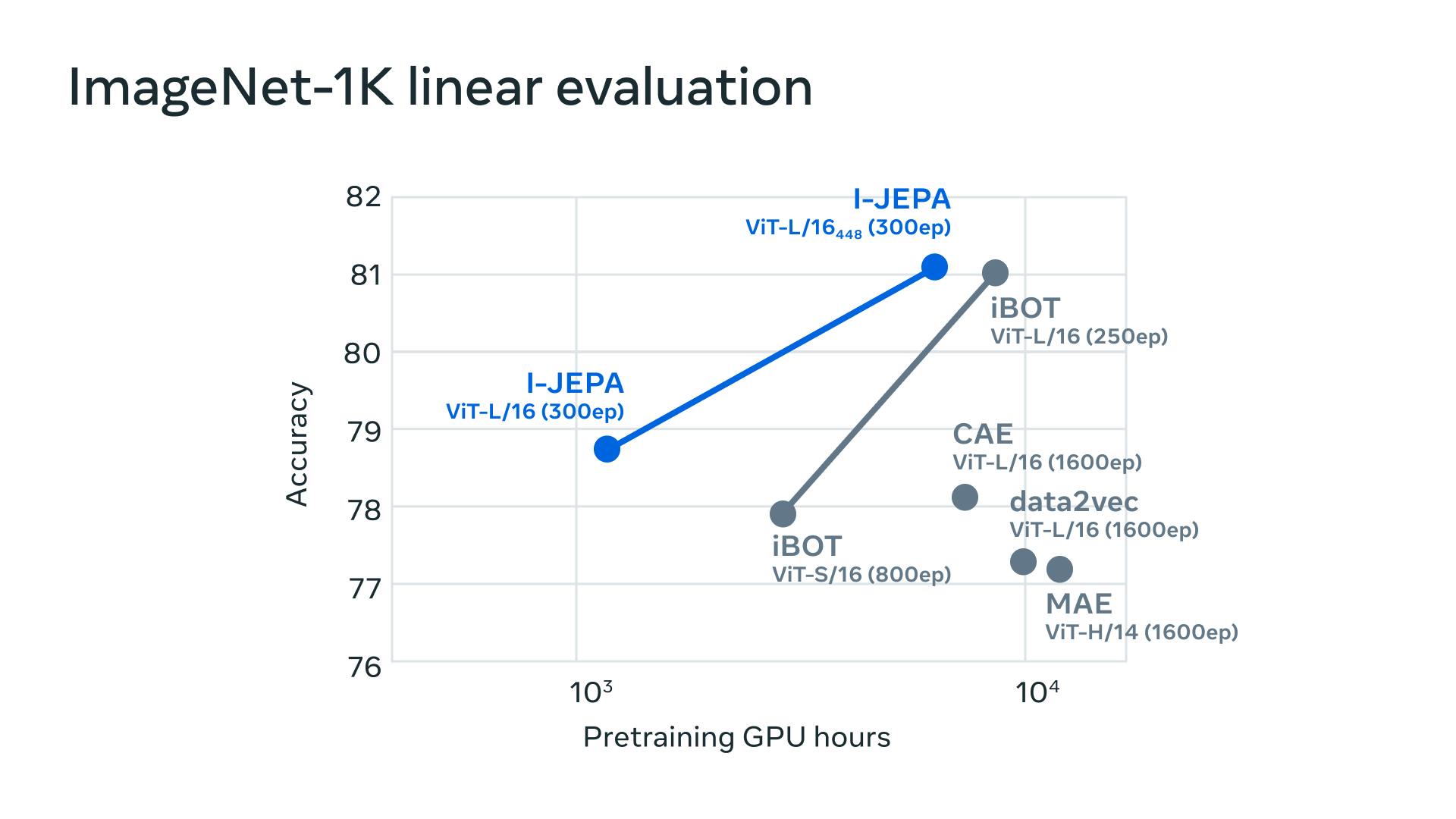
Notably, I-JEPA surpasses pre-training approaches that heavily relied on data augmentations for semantic tasks, exhibiting stronger performance in low-level vision tasks such as object counting and depth prediction. By employing a simpler model with a more flexible inductive bias, I-JEPA showcases versatility across a wider range of tasks.
I-JEPA also impresses with its scalability and efficiency. Pre-training a ViT-H/14 model on ImageNet requires under 1200 GPU hours, making it over 2.5x faster than ViTS/16 pre-trained with iBOT. In comparison to ViT-H/14 pre-trained with MAE, I-JEPA proves to be more than 10x more efficient. Leveraging representation space predictions significantly reduces the computation required for self-supervised pre-training.
I-JEPA: Key Takeaways
- Image-based Joint Embedding Predictive Architecture (I-JEPA) is an approach for self-supervised learning from images without relying on data augmentations.
- The concept behind I-JEPA: predict the representations of various target blocks in the same image from a single context block.
- This method improves the semantic level of self-supervised representations without using extra prior knowledge encoded through image transformations
- It is scalable and efficient.
💡Read the original paper here. Recommended Articles
Read more on other recent releases from Meta AI:
- MEGABYTE, Meta AI’s New Revolutionary Model Architecture | Explained
- Meta Training Inference Accelerator (MTIA) Explained
- ImageBind MultiJoint Embedding Model from Meta Explained
- DINOv2: Self-supervised Learning Model Explained
- Meta AI's New Breakthrough: Segment Anything Model (SAM) Explained
Frequently asked questions
JEPA (Joint Embedding Predictive Architecture) is an image architecture that predicts representations of target blocks from a single context block, using a masking strategy for semantic representation. It prioritizes semantic features over pixel-level details, focusing on meaningful, high-level representations rather than data augmentations or pixel space predictions.
In the context of AI, the metaverse refers to a shared digital reality integrating artificial intelligence with virtual reality, augmented reality, 3D animation, and blockchain. It enables users to interact, work, communicate, and conduct activities in a virtual universe through avatars, fostering immersive and interconnected experiences.
Joint Embedding Predictive Architecture (JEPA) predicts target block representations from a single context block in images, emphasizing semantic features over pixel-level details. It uses a masking strategy to guide the model and prioritize meaningful, high-level representations. JEPA focuses on predicting representations of different blocks that complement each other when additional information is provided.
AI (Artificial Intelligence) refers to technology enabling machines to perform tasks requiring human-like intelligence. The metaverse, however, is a shared digital reality where users interact, work, and socialize in a virtual universe. While AI powers functionalities within the metaverse, the latter encompasses a broader concept of interconnected virtual environments.
Meta AI is an AI assistant recently launched by Meta, incorporating generative AI. Users can engage in 1-on-1 chats or group conversations with Meta AI. It offers suggestions, generates images, and facilitates web searches. Meta AI serves as a versatile assistant for various tasks, leveraging AI capabilities for user interaction and support.
For now, Meta AI assistant is available in US only.
Embedding refers to mapping high-dimensional data into a lower-dimensional space while preserving important features. It's often used in machine learning for tasks like natural language processing and image recognition. Latent space, on the other hand, refers to the hidden space where data points are represented after encoding in a model, typically used in unsupervised learning for feature extraction or generation. While embedding is a deliberate transformation, latent space emerges as a result of model training.
In Natural Language Processing (NLP), embedding techniques map words or phrases from a high-dimensional space (vocabulary) into a lower-dimensional continuous space, preserving semantic relationships. Techniques like Word Embeddings (e.g., Word2Vec, GloVe) and Contextual Embeddings (e.g., BERT, GPT) facilitate tasks like sentiment analysis, language translation, and document classification by capturing contextual and semantic meanings of words.
Meta AI Imagine, accessible on imagine.meta.com, generates custom images through AI. Users submit prompts to the image generator, receiving four images based on the input. They can download the generated images, re-generate based on the same prompt, or submit new prompts. The system leverages AI to interpret and create visuals accordingly.
Yes, AI can generate fake images of human faces using techniques like Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs). These models learn to generate highly realistic and diverse synthetic faces by capturing underlying patterns in large datasets, enabling applications in art, entertainment, and potentially deceptive practices.