MEGABYTE, Meta AI’s New Revolutionary Model Architecture, Explained

Unlocking the true potential of content generation in natural language processing (NLP) has always been a challenge. Traditional models struggle with long sequences, scalability, and sluggish generation speed.
But fear not, as Meta AI brings forth MEGABYTE - a groundbreaking model architecture that revolutionizes content generation. In this blog, we will dive deep into the secrets behind MEGABYTE’s potential, its innovative features, and how it tackles the limitations of current approaches.
What is a MEGABYTE?
MEGABYTE is a multiscale decoder architecture that can model sequences of over one million bytes with end-to-end differentiability. The byte sequences are divided into fixed-sized patches roughly equivalent to tokens. The model is divided into three components:
- Patch embedder: It takes an input of a discrete sequence, embeds each element, and chunks it into patches of a fixed length.
- Global Module: It is a large autoregressive transformer that contextualizes patch representations by performing self-attention over previous patches
- Local Module: It is a small local transformer that inputs a contextualized patch representation from the global model, and autoregressively predicts the next patch.
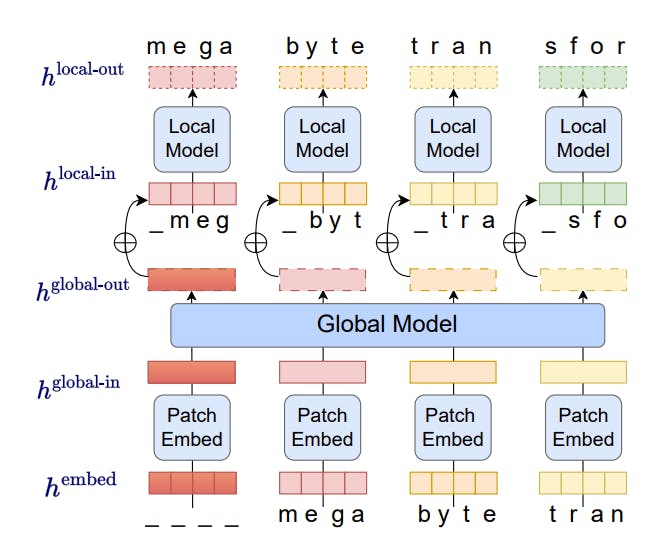
Overview of MEGABYTE’s architecture. Source
Hang on, What are Multiscale Transformers?
Multiscale transformers refer to transformer models that incorporate multiple levels or scales of representation within their architecture. These models aim to capture information at different granularities or resolutions, allowing them to effectively model both local and global patterns in the data.
In a standard transformer architecture, the self-attention mechanism captures dependencies between different positions in a sequence. However, it treats all positions equally and does not explicitly consider different scales of information. Multiscale transformers address this limitation by introducing mechanisms to capture information at various levels of detail.
Multiscale transformers are used in MEGABYTE to stack transformers. Each transformer in the stack operates at a different scale, capturing dependencies at its specific scale. By combining the outputs of transformers with different receptive fields, the model can leverage information at multiple scales. We will discuss these transformers and how they work in a while!
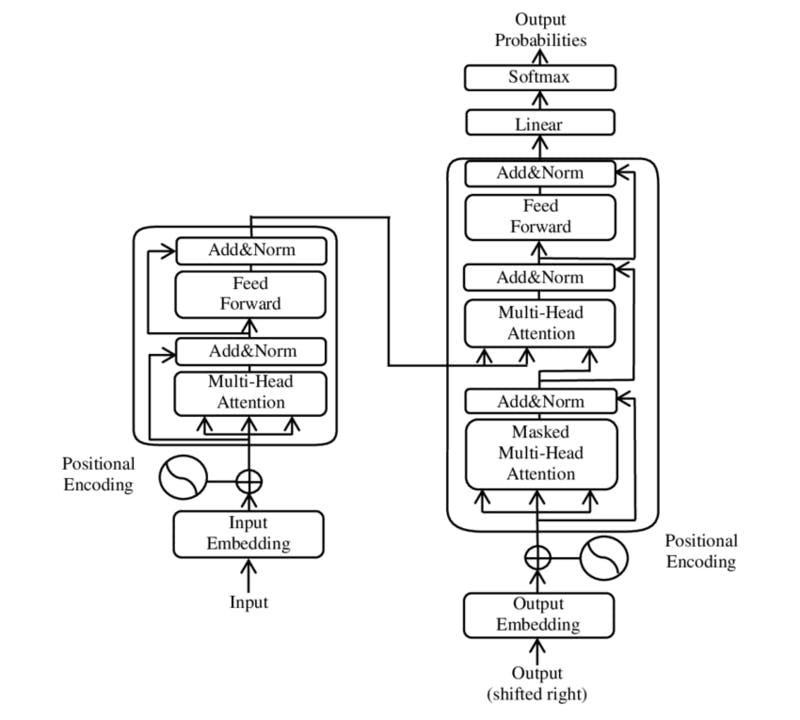
Transformer model architecture. Source
What are Autoregressive Transformers?
Autoregressive transformers, also known as decoders, are a specific type of machine learning model designed for sequence modeling tasks. They are a variant of the transformer architecture, that was introduced in the paper "Attention Is All You Need."
Autoregressive transformers are primarily used in natural language processing (NLP) and are trained on language modeling tasks, where the goal is to predict the next token in a sequence based on the previous tokens. The key characteristic of autoregressive transformers is their ability to generate new sequences autoregressively, meaning that they predict tokens one at a time in a sequential manner.
These models employ a self-attention mechanism that allows them to capture dependencies between different positions in a sequence. By attending to previous tokens, autoregressive transformers can learn the relationship between the context and the current token being generated. This makes them powerful for generating coherent and contextually relevant sequences of text.
What’s Wrong with Current Models?
Tokenization
Typically autoregressive models use some form of tokenization, where sequences need to be tokenized before they can be processed. This complicates pre-processing, multi-modal modeling, and transfer to new domains while hiding useful structures from the model. This process is also time-consuming and error-prone.
Scalability
The current models struggle to scale to long sequences because the self-attention mechanism, which is a key component of transformers, scales quadratically with the sequence length. This makes it difficult to train and deploy models that can handle sequences of millions of bytes.
Generation speed
The current NLP models predict each token one at a time, and they do so in order. This can make it difficult to generate text in real-time, such as for chatbots or interactive applications. Hence, the current models are slow to generate text.

How Does MEGABYTE Address Current Issues?
The architecture of MEGABYTE is designed to address these issues by providing improvements over Transformers for long-sequence modeling:
Sub-Quadratic Self-Attention
The majority of long-sequence model research has been focused on reducing the quadratic cost of the self-attention mechanism. MEGABYTE divides long sequences into two shorter sequences which reduces the self-attention cost to O(N^(4/3)), which is still achievable for long sequences.
Per-Patch Feedforward Layers
More than 98% of FLOPS are used in GPT3-size models to compute position-wise feedforward layers. MEGABYTE allows for much larger and more expensive models at the same cost by using large feedforward layers per patch rather than per position.
Parallelism in Decoding
As we discussed above, transformers must serially process all computations. MEGABYTE allows for greater parallelism during sequence generation by generating sequences for patches in parallel. For example, when trained on the same compute, a MEGABYTE model with 1.5B parameters can generate sequences 40% faster than a conventional 350M Transformer while also increasing perplexity.
What Does it Mean for Content Generation?
Content generation is constantly evolving in the realm of artificial intelligence (AI), and the emergence of MEGABYTE is a testament to this progress. With AI models growing in size and complexity, advancements have primarily been driven by training models with an increasing number of parameters. While the speculated trillion-parameter GPT-4 signifies the pursuit of greater capability, OpenAI's CEO Sam Altman suggests a shift in strategy.
Altman envisions a future where AI models follow a similar trajectory to iPhone chips, where consumers are unaware of the technical specifications but experience continuous improvement. This highlights the importance of optimizing AI models beyond sheer size and parameters. Meta AI, recognizing this trend, introduces their innovative architecture with MEGABYTE at an opportune time.
However, the researchers at Meta AI also acknowledge that there are alternative pathways to optimization. Promising research areas include more efficient encoder models utilizing patching techniques, decode models breaking down sequences into smaller blocks, and preprocessing sequences into compressed tokens. These advancements have the potential to extend the capabilities of the existing Transformer architecture, paving the way for a new generation of AI models.
In essence, the future of content generation lies in striking a balance between model size, computational efficiency, and innovative approaches. While MEGABYTE presents a groundbreaking solution, the ongoing exploration of optimization techniques ensures a continuous evolution in AI content generation, pushing the boundaries of what is possible.
 💡MEGABYTE has generated significant excitement among experts in the field. Read what Andrej Karpathy, a prominent AI engineer at OpenAI and former Senior Director of AI at Tesla has to say about it.
💡MEGABYTE has generated significant excitement among experts in the field. Read what Andrej Karpathy, a prominent AI engineer at OpenAI and former Senior Director of AI at Tesla has to say about it. Meta AI’s other recent releases
Over the past two months, Meta AI has had an incredible run of successful releases on open-source AI tools.
Segment Anything Model 2
SAM 2 brings state-of-the-art segmentation and tracking capabilities for both video and images into a single model. This unification eliminates the need for combining SAM with other video object segmentation models, streamlining the process of video segmentation into a single, efficient tool. It maintains a simple design and fast inference speed, making it accessible and efficient for users.

Meta AI Training Inference Accelerator (MTIA)
Meta AI created MTIA to handle their AI workloads effectively. They created a special Application-Specific Integrated Circuit (ASIC) chip to improve the efficiency of their recommendation systems.
MTIA was built as a response to the realization that GPUs were not always the optimal solution for running Meta AI’s specific recommendation workloads at the required efficiency levels.
The MTIA chip is a component of a full-stack solution that also comprises silicon, PyTorch, and recommendation models. These components were all jointly built to provide Meta AI’s customers with a completely optimized ranking system.
💡Check out the full explainer if you would like to know more about MTIA. DINOv2
DINOv2 is an advanced self-supervised learning technique that can learn visual representation from images without relying on labeled data. For training, DINOv2 doesn’t need a lot of labeled data like supervised learning models need.

Pre-training and fine-tuning are the two stages of the DINOv2 process. The DINO model gains effective visual representation during pretraining from a sizable dataset of unlabeled images. The pre-trained DINO model is adapted to a task-specific dataset, such as image classification or object detection, in the fine-tuning stage.
💡Learn more about DINOv2's training process and application. ImageBIND
ImageBIND introduces a novel method for learning a joint embedding space across six different modalities - text, image/video, audio, depth, thermal, and IMU. It is created by Meta AI’s FAIR Lab and published on GitHub. ImageBIND helps AI models process and analyze data more comprehensively by including information from different modalities, leading to a more humanistic understanding of the information at hand.

In order to generate fixed-dimensional embeddings, the ImageBind architecture uses distinct encoders for each modality along with linear projection heads adapted to each modality. The three primary parts of the architecture are:
- modality-specific encoders
- cross-modal attention module
- joint embedding space
Although the framework’s precise specifications have not been made public, the research paper offers insights into the suggested architecture.
💡Learn more about ImageBIND and its multimodal capabilities. Overall, ImageBIND’s ability to manage multiple modalities and produce a single representation space opens up new avenues for advanced AI systems, improving their understanding of diverse data types and enabling more precise predictions and results.

Conclusion
Meta’s release of MEGABYTE, combined with its track record of open-source contributions, exemplifies the company’s dedication to pushing the boundaries of AI research and development. Meta AI consistently drives innovation in AI, evident in its transformative contributions such as MEGABYTE, Segment Anything Model, DINOv2, MTIA, and ImageBIND. Each of these breakthroughs contributes to the expansion of our knowledge and capabilities in the field of AI, solidifying Meta AI’s contribution to advancing the forefront of AI technology.
The paper was written by Lili Yu, Dániel Simig, Colin Flaherty, Armen Aghajanyan, Luke Zettlemoyer, and Mike Lewis. Frequently asked questions
The types of AI models being developed through the Cortex program largely depend on customer requirements. They can range from object tracking and pattern recognition algorithms to knowledge retrieval systems, showcasing a broad scope tailored to specific needs.
Encord's platform is designed to be versatile, allowing it to adapt to various verticals within AI. This adaptability ensures that companies can optimize their go-to-market strategies and enhance their data workflows according to their specific industry needs.
Encord offers a tool called Encord Index, which facilitates the pre-filtering and curation of large datasets. This helps in narrowing down to the most impactful data, making it more efficient and less costly compared to labeling all data manually.
Encord is capable of processing vast amounts of data, accommodating projects that require handling terabytes of information. The platform is optimized for managing extensive datasets, making it suitable for enterprise-level applications.