What is Retrieval Augmented Generation (RAG)?

Technical Writer at Encord
The large-scale adoption of Artificial Intelligence continues to have a transformative effect on the world. Foundation models, especially Large Language Models (LLMs) like OpenAI's GPT, have gained widespread attention and captivated the general public's imagination. Trained on a vast corpus of online data and possessing the ability to understand and output natural language, LLMs are challenging the very nature of intelligence and creativity.
Yet the precise mechanisms that make state-of-the-art LLMs so effective are also the source of their biggest flaw - their tendency to provide inaccurate, as well as out of date information. LLMs are prone to making things up, and as generative models, they don’t cite sources in their responses.
What is Retrieval Augmented Generation (RAG)?
Enter Retrieval Augmented Generation, known as RAG, a framework promising to optimize generative AI and ensure its responses are up-to-date, relevant to the prompt, and most importantly, true.
How does RAG work?
The main idea behind RAG is surprisingly simple; combining LLMs with a separate store of content outside of the language model containing sourced and up-to-date information for the LLM to consult before generating a response for its users. In other words, this approach merges information retrieval with text generation.
To truly appreciate how this works, it's essential to delve into the realm of deep learning and understand how language models process our prompts and produce responses in natural language. LLMs generate responses based purely on the user’s input and skillful prompt engineering is vital for maximizing the accuracy of the generated responses. This input is turned into embeddings, which are numerical representations of concepts that allow the AI to compute the semantics of what the user is asking.
In the RAG framework, the language model identifies relevant information in an external dataset after computing the embeddings of a user’s query. The LLM then performs a similarity search on the prompt and the external dataset, before fine-tuning the user’s prompt using the relevant information it retrieved. Only then is the prompt sent to the LLM to generate an output for the user.
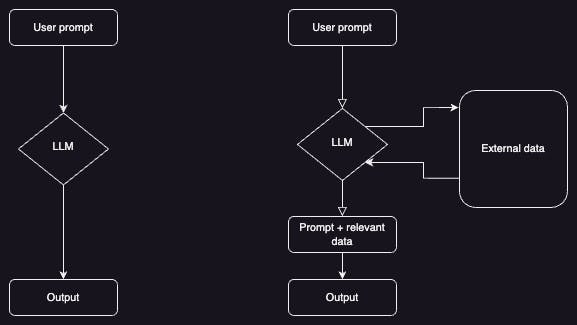
Classic LLM (left) vs one using the RAG framework (right)
What makes this framework so effective is that ‘external dataset’ can mean any number of things. For example, these could be APIs, databases that are updated in real-time, or even open domains such as Wikipedia or GitHub.
Benefits of Retrieval Augmented Generation (RAG)
Combining the user’s prompt with a separate store of information before generating an output has multiple benefits, not least that it allows the LLM to provide sources for the responses it provides.
‘Classic’ LLMs can only obtain new information during retraining, which is a very expensive and time-consuming process. However, the RAG framework overcomes this challenge by enabling real-time updates and new sources to be incorporated into the external dataset without having to re-train the entire model. This provides LLMs with valuable and specialized knowledge in addition to what’s included in their initial training data.
Studies have demonstrated that RAG models surpass non-RAG models across various metrics, including reduced susceptibility to hallucinations and increased accuracy in responses. They are also less likely to leak sensitive personal information.
Applications for Retrieval Augmented Generation (RAG)
RAG has a wide range of applications across all domains that require specialized on-demand knowledge. Its applications includes, but are not limited to:
- Chatbots and AI assistants: RAG models can be leveraged to build advanced question-answering systems superior to classic retrieval based chatbots. They can retrieve relevant information from a knowledge base and generate detailed, context-aware answers to user queries. The AI assistant found in our documentation is a perfect example of this.
- Education tools: RAG can be employed to develop educational tools that provide students with answers to questions, explanations, and additional context based on textbooks and reference materials.
- Legal Research and document review: Legal professionals can use RAG models to quickly search and summarize legal documents, statutes, and case law to aid in legal research and document review.
- Medical diagnosis and healthcare: In the healthcare domain, RAG models can help doctors and other medical professionals access the latest medical literature and clinical guidelines to assist in diagnosis and treatment recommendations.
- Language translation (with context): By considering the context from a knowledge base, RAG can assist in language translation tasks, resulting in more accurate translations that account for specific terminology or domain knowledge.
Retrieval Augmented Generation (RAG): Summary
RAG principles have been shown to reduce the frequency and severity of issues related to LLMs in a host of different metrics. The external knowledge sources that LLMs are given access to can vary and easily be kept up-to-date, providing the language models with sources as well as much-needed context for specific tasks and use cases. These embeddings are subsequently combined with the user's input to generate accurate responses.
Maintaining objectivity and accuracy in an online space rife with misinformation is extremely challenging, and since hallucinations are baked into the very fabric of how generative models work it currently seems impossible to imagine a generative AI model that is 100% accurate. However, RAG reminds us that improvements in AI depend as much on well-designed frameworks as they do on advancements in technology. This serves as a reminder as we work on advancing the next generation of deep learning technologies.

Frequently asked questions
Encord provides a flexible platform that allows organizations to integrate various annotation tools seamlessly. This capability is particularly useful when merging different systems, as it enables teams to streamline their workflows and ensure consistency across projects, regardless of the origin of the annotation tools.
Encord addresses challenges related to platform stability and the complexities of managing annotation projects. By providing a robust platform designed specifically for these needs, Encord aims to enhance the overall efficiency and effectiveness of the annotation process.
Encord prioritizes user experience by providing a streamlined search mechanism for attributes. Users can quickly find and change attributes, such as turn indicators, without navigating through complex menus, enhancing efficiency when handling large datasets.
Yes, Encord's software is equipped to handle projects with multiple variations of similar items, providing tools to aid in the review process and ensure accurate labeling, which is essential in industries like food service where ambiguity may exist.
Encord incorporates human evaluation as part of its human-in-the-loop analysis to assess the quality of outputs from RAG systems. This allows for a combination of automated processes and human judgment to ensure high-quality responses are achieved.
Yes, users can apply multiple filters in the new interface. The system allows for an easy search and application process, enabling users to filter through various criteria seamlessly, improving the overall efficiency of their tasks.
Encord supports key features such as slicing, tagging, and the ability to import custom tags. These features are essential for users transitioning from Tenex to maintain their existing workflows.
Encord's platform is designed to adapt to various use cases, offering tailored solutions to meet the unique challenges faced by different teams in their annotation workflows.